A Multi-Modal Person Perception Framework for Socially Interactive Mobile Service Robots

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- The introduction of a modular multi-modal tracking framework, which realizes the fusion of independent asynchronous detections in different sensors to form a probabilistic model of all persons in the robot’s surroundings.
- The usage of various properties of tracked persons (face and appearance-based features) for an implicit re-identification of persons after tracking interruption. Therefore, a probabilistic data association step is introduced, which is coupling the individual trackers to their independent properties.
- A benchmark on a published multi-modal dataset shows the improvement of tracking consistency when individual features are added to the standard position tracker.
2. Related Work
2.1. Sensor Fusion in Mobile Robot Person Tracking
2.2. Multi Target Tracking
2.3. Out of Sequence Measurements in Online Tracking
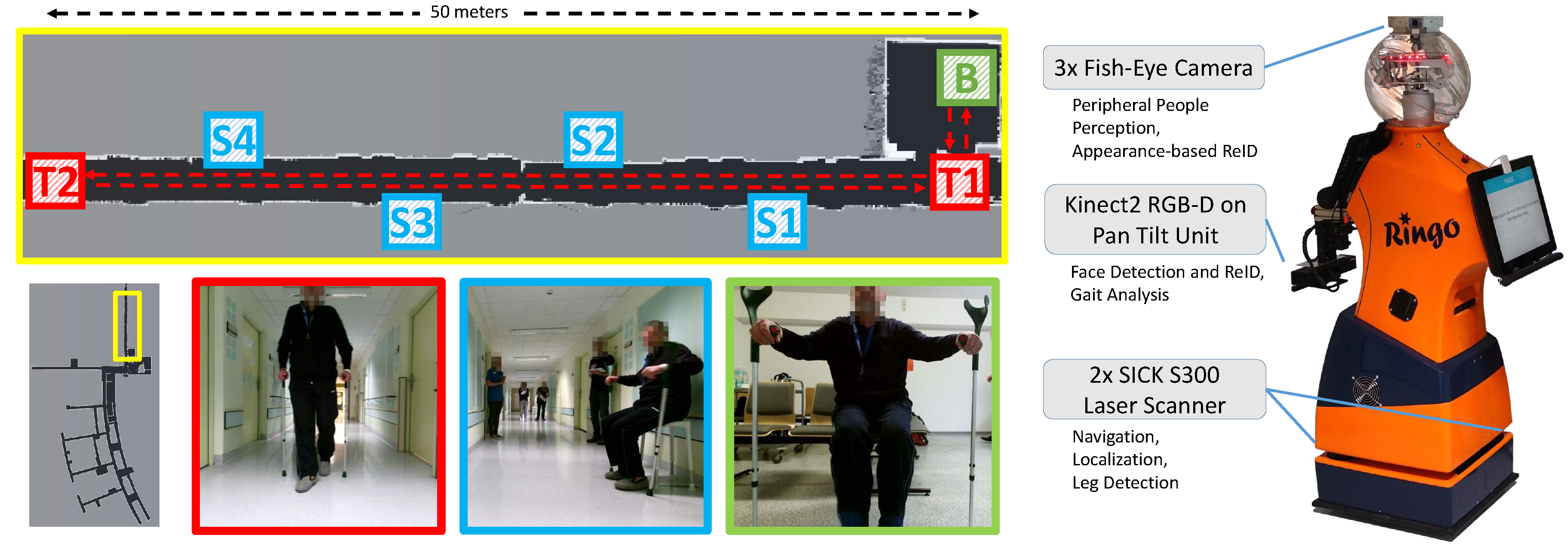
3. System Overview
3.1. Detection Modules
3.2. Feature Extraction
3.2.1. Position in 3D World Coordinates
3.2.2. Posture and Orientation
3.2.3. Re-Identification
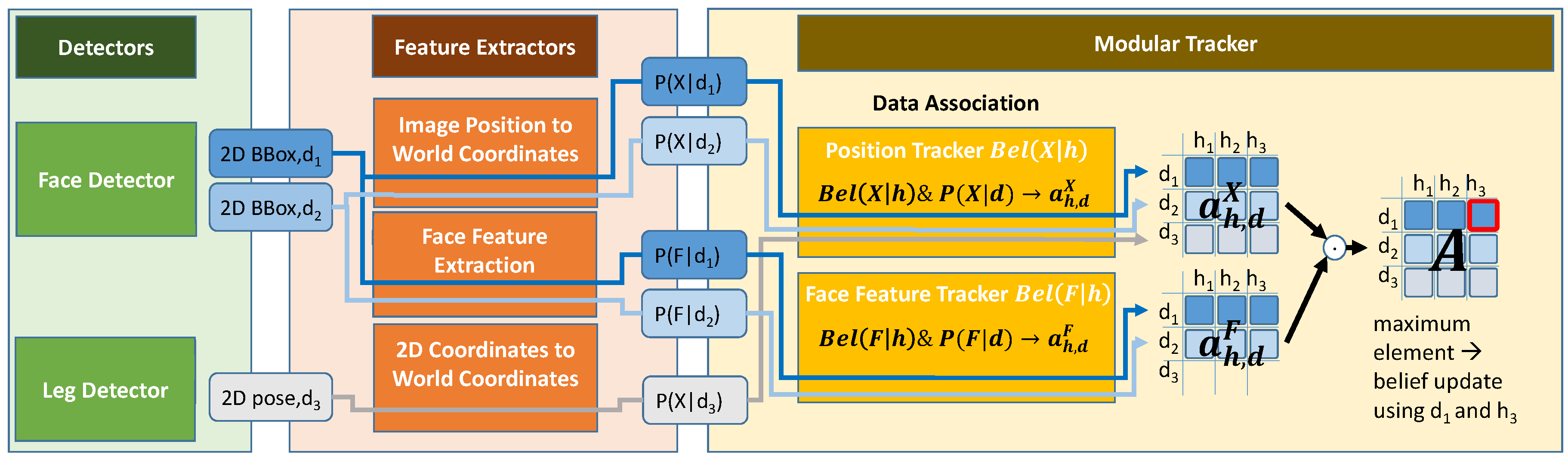
4. Multimodal Tracking Framework
| Algorithm 1: Tracking cycle | |
| 1 | for all tracking modules do |
| 2 | reset belief to begin of rewind interval; |
| 3 | for all detection timestamps t in rewind interval do |
| 4 | for all tracking modules do |
| 5 | predict belief using from previous detection; |
| 6 | while unprocessed detections at time t do |
| 7 | compute matrix element of all association probabilities to unprocessed detections at t; |
| 8 | find maximum element ; |
| 9 | update hypothesis h using detection d; end |
| 10 | for all tracking modules do |
| 11 | predict belief to current time; |
| 12 | return belief state of current time; |
Modeling of Detectors’ Uncertainties
5. Belief Representation in the Individual Tacker Modules
5.1. Position and Velocity
5.2. Posture and Orientation
5.3. Face and Color Features
6. Experimental Results
6.1. Benchmark on Labeled Dataset
6.2. Real-World User Trials
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zachiotis, G.A.; Andrikopoulos, G.; Gornez, R.; Nakamura, K.; Nikolakopoulos, G. A Survey on the Application Trends of Home Service Robotics. In Proceedings of the 2018 IEEE International Conference on Robotics and Biomimetics (ROBIO), Kuala Lumpur, Malaysia, 12–15 December 2018; pp. 1999–2006. [Google Scholar]
- Triebel, R.; Arras, K.; Alami, R.; Beyer, L.; Breuers, S.; Chatila, R.; Chetouani, M.; Cremers, D.; Evers, V.; Fiore, M.; et al. Spencer: A socially aware service robot for passenger guidance and help in busy airports. In Field and Service Robotics; Springer: Berlin, Germany, 2016; pp. 607–622. [Google Scholar]
- Veloso, M.; Biswas, J.; Coltin, B.; Rosenthal, S.; Kollar, T.; Mericli, C.; Samadi, M.; Brandao, S.; Ventura, R. Cobots: Collaborative robots servicing multi-floor buildings. In Proceedings of the 2012 IEEE/RSJ international conference on intelligent robots and systems, Vilamoura, Portugal, 7–12 October 2012; pp. 5446–5447. [Google Scholar]
- Gockley, R.; Bruce, A.; Forlizzi, J.; Michalowski, M.; Mundell, A.; Rosenthal, S.; Sellner, B.; Simmons, R.; Snipes, K.; Schultz, A.C.; et al. Designing robots for long-term social interaction. In Proceedings of the 2005 IEEE/RSJ International Conference on Intelligent Robots and Systems, Edmonton, AB, Canada, 2–6 August 2005; pp. 1338–1343. [Google Scholar]
- Al-Wazzan, A.; Al-Farhan, R.; Al-Ali, F.; El-Abd, M. Tour-guide robot. In Proceedings of the 2016 International Conference on Industrial Informatics and Computer Systems (CIICS), Sharjah, UAE, 13–15 March 2016; pp. 1–5. [Google Scholar]
- Charalampous, K.; Kostavelis, I.; Gasteratos, A. Recent trends in social aware robot navigation: A survey. Rob. Autom. Syst. 2017, 93, 85–104. [Google Scholar] [CrossRef]
- Scheidig, A.; Jaeschke, B.; Schuetz, B.; Trinh, T.Q.; Vorndran, A.; Mayfarth, A.; Gross, H.M. May I Keep an Eye on Your Training? Gait Assessment Assisted by a Mobile Robot. In Proceedings of the 2019 IEEE 16th International Conference on Rehabilitation Robotics (ICORR), Toronto, ON, Canada, 24–28 June 2019; pp. 701–708. [Google Scholar]
- Nuitrack. Nuitrack Full Body Skeletal Tracking Software. Available online: https://nuitrack.com/ (accessed on 1 October 2019).
- Microsoft. Kinect for Windows SDK 2.0. Available online: https://developer.microsoft.com/en-us/windows/kinect (accessed on 1 October 2019).
- Luo, W.; Xing, J.; Milan, A.; Zhang, X.; Liu, W.; Zhao, X.; Kim, T.K. Multiple object tracking: A literature review. arXiv 2014, arXiv:1409.7618. [Google Scholar]
- Linder, T.; Breuers, S.; Leibe, B.; Arras, K.O. On multi-modal people tracking from mobile platforms in very crowded and dynamic environments. In Proceedings of the International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 5512–5519. [Google Scholar] [CrossRef]
- Arras, K.O.; Grzonka, S.; Luber, M.; Burgard, W. Efficient people tracking in laser range data using a multi-hypothesis leg-tracker with adaptive occlusion probabilities. In Proceedings of the International Conference on Robotics and Automation (ICRA), Pasadena, CA, USA, 19–23 May 2008; pp. 1710–1715. [Google Scholar] [CrossRef] [Green Version]
- Dondrup, C.; Bellotto, N.; Jovan, F.; Hanheide, M. Real-time multisensor people tracking for human-robot spatial interaction. In Proceedings of the Workshop on Machine Learning for Social Robotics at International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–31 May 2015. [Google Scholar]
- Thrun, S.; Burgard, W.; Fox, D. Probabilistic robotics; MIT Press: Cambridge, MA, USA, 2005; pp. 13–38. [Google Scholar]
- Bellotto, N.; Hu, H. Computationally efficient solutions for tracking people with a mobile robot: An experimental evaluation of bayesian filters. Auton. Robots 2010, 28, 425–438. [Google Scholar] [CrossRef]
- Volkhardt, M.; Weinrich, C.H.; Gross, H.M. People Tracking on a Mobile Companion Robot. In Proceedings of the 2013 IEEE International Conference on Systems, Man, and Cybernetics, Manchester, UK, 13–16 October 2013; pp. 4354–4359. [Google Scholar]
- Geiger, A.; Lauer, M.; Wojek, C.; Stiller, C.; Urtasun, R. 3d traffic scene understanding from movable platforms. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 1012–1025. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fortmann, T.E.; Bar-Shalom, Y.; Scheffe, M. Multi-target tracking using joint probabilistic data association. In Proceedings of the 1980 19th IEEE Conference on Decision and Control including the Symposium on Adaptive Processes IEEE, Albuquerque, NM, USA, 10–12 December 1980; pp. 807–812. [Google Scholar]
- Streit, R.L.; Luginbuhl, T.E. Probabilistic Multi-hypothesis Tracking; NUWC-NPT Tech. Rep. 10,428; Naval Undersea Warfare Center Division: Newport, RI, USA, 1995. [Google Scholar]
- Leal-Taixé, L.; Canton-Ferrer, C.; Schindler, K. Learning by tracking: Siamese CNN for robust target association. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 33–40. [Google Scholar]
- Mallick, M.; Marrs, A. Comparison of the KF and particle filter based out-of-sequence measurement filtering algorithms. In Proceedings of the 6th International Conference on Information Fusion, Cairns, Australia, 8–11 July 2003; pp. 422–430. [Google Scholar]
- Wengefeld, T.; Müller, S.; Lewandowski, B.; Gross, H.M. A Multi Modal People Tracker for Real Time Human Robot Interaction. In Proceedings of the 2019 28th IEEE International Conference on Robot and Human Interactive Communication (RO-MAN), New Delhi, India, 14–18 October 2019. [Google Scholar] [CrossRef]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA,, 22–25 July 2017. [Google Scholar]
- Lewandowski, B.; Liebner, J.; Wengefeld, T.; Mueller, S.T.; Gross, H.M. A Fast and Robust 3D Person Detector and Posture Estimator for Mobile Robotic Application. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 4869–4875. [Google Scholar]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef] [Green Version]
- Weinrich, C.H.; Wengefeld, T.; Schroeter, C.H.; Gross, H.M. People Detection and Distinction of their Walking Aids in 2D Laser Range Data based on Generic Distance-Invariant Features. In Proceedings of the 23rd IEEE International Symposium on Robot and Human Interactive Communication, Edinburgh, UK, 25–29 August 2014; pp. 767–773. [Google Scholar]
- Lewandowski, B.; Seichter, D.; Wengefeld, T.; Pfennig, L.; Drumm, H.; Gross, H.M. Deep Orientation: Fast and Robust Upper Body Orientation Estimation for Mobile Robotic Applications. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macao, China, 4–8 November 2019. [Google Scholar]
- Eisenbach, M.; Vorndran, A.; Sorge, S.; Gross, H.M. User Recognition for Guiding and Following People with a Mobile Robot in a Clinical Environment. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 3600–3607. [Google Scholar]
- Liu, W.; Wen, Y.; Yu, Z.; Li, M.; Raj, B.; Song, L. Sphereface: Deep hypersphere embedding for face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017. [Google Scholar]
- Yi, D.; Lei, Z.; Liao, S.; Li, S.Z. Learning face representation from scratch. arXiv 2014, arXiv:1411.7923. [Google Scholar]
- Linder, T.; Girrbach, F.; Arras, K.O. Towards a robust people tracking framework for service robots in crowded, dynamic environments. In Proceedings of the Assistance and Service Robotics Workshop (ASROB-15) at the International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015. [Google Scholar]
- Wengefeld, T.; Lewandowski, B.; Seichter, D.; Pfennig, L.; Gross, H.M. Real-time Person Orientation Estimation using Colored Pointclouds. In Proceedings of the 2019 European Conference on Mobile Robots (ECMR), Prague, Czech Republic, 4–6 September 2019; pp. 1–7. [Google Scholar]
- Qiu, C.; Zhang, Z.; Lu, H.; Luo, H. A survey of motion-based multitarget tracking methods. Prog. Electromagnetics Res. 2015, 62, 195–223. [Google Scholar] [CrossRef] [Green Version]
- Eisenbach, M.; Kolarow, A.; Vorndran, A.; Niebling, J.; Gross, H.M. Evaluation of Multi Feature Fusion at Score-Level for Appearance-based Person Re-Identification. In Proceedings of the 2015 International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–17 July 2015; pp. 469–476. [Google Scholar]
- Bernardin, K.; Elbs, A.; Stiefelhagen, R. Multiple object tracking performance metrics and evaluation in a smart room environment. In Proceedings of the Sixth IEEE International Workshop on Visual Surveillance, in Conjunction with ECCV, Graz, Austria, 7–13 May 2006; Volume 90, p. 91. [Google Scholar]
- Vorndran, A.; Trinh, T.Q.; Mueller, S.T.; Scheidig, A.; Gross, H.M. How to Always Keep an Eye on the User with a Mobile Robot? In Proceedings of the ISR 2018, 50th International Symposium on Robotics, Munich, Germany, 20–21 June 2018; pp. 219–225. [Google Scholar]




© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Müller, S.; Wengefeld, T.; Trinh, T.Q.; Aganian, D.; Eisenbach, M.; Gross, H.-M. A Multi-Modal Person Perception Framework for Socially Interactive Mobile Service Robots. Sensors 2020, 20, 722. https://doi.org/10.3390/s20030722
Müller S, Wengefeld T, Trinh TQ, Aganian D, Eisenbach M, Gross H-M. A Multi-Modal Person Perception Framework for Socially Interactive Mobile Service Robots. Sensors. 2020; 20(3):722. https://doi.org/10.3390/s20030722
Chicago/Turabian StyleMüller, Steffen, Tim Wengefeld, Thanh Quang Trinh, Dustin Aganian, Markus Eisenbach, and Horst-Michael Gross. 2020. "A Multi-Modal Person Perception Framework for Socially Interactive Mobile Service Robots" Sensors 20, no. 3: 722. https://doi.org/10.3390/s20030722
APA StyleMüller, S., Wengefeld, T., Trinh, T. Q., Aganian, D., Eisenbach, M., & Gross, H. -M. (2020). A Multi-Modal Person Perception Framework for Socially Interactive Mobile Service Robots. Sensors, 20(3), 722. https://doi.org/10.3390/s20030722