A Fast Radio Map Construction Method Merging Self-Adaptive Local Linear Embedding (LLE) and Graph-Based Label Propagation in WLAN Fingerprint Localization Systems


Abstract
:1. Introduction
2. Related Work
3. Proposed Method Merging SLLE and GLP
3.1. Feasibility Analysis of RSSI Sample Semi-Supervised Manifold Learning
3.2. Method Design
- (1)
- Execution propagation: .
- (2)
- Lock the marked data by replacing the first rows of with : .
- (3)
- Repeat steps (1) and (2) until converges.
- (4)
- Assign labels to unlabeled data according to .
3.3. Radio Map Construction by Proposed Method and Online Positioning
3.3.1. Radio Map Construction
- (1)
- For each RSSI sample , use the self-adaptive method to calculate its most suitable neighbor number .
- (2)
- The nearest neighbor samples are obtained by comparing the Euclidean distance between and other samples.
- (3)
- The SLLE algorithm is used to reduce the dimension of the RSSI sample , to obtain its low-dimensional embedding .
- (4)
- Replace the high-dimensional data with low-dimensional data to establish a new sample set.
- (5)
- Use the GLP algorithm to label the physical location of and get the matrix . Each row in the matrix represents the probability of a low-dimensional sample appearing at a physical location. The probability distribution of is , and this satisfies .
- (6)
- The weighted sum of the probability distribution of is used to estimate its physical location:
3.3.2. Online Positioning
- (1)
- Use the self-adaptive method to calculate the most suitable neighbor number for the RSSI samples collected online.
- (2)
- Find the nearest neighbor sample points by comparing the Euclidean distance between and other sample points.
- (3)
- Construct the weight for and its neighbors according to the SLLE algorithm.
- (4)
- Use and location labels corresponding to known low-dimensional data to estimate the location to be measured , .
4. Experiments and Discussion
4.1. Experimental Testbed Introduction
4.2. Algorithm Performance Test and Analysis
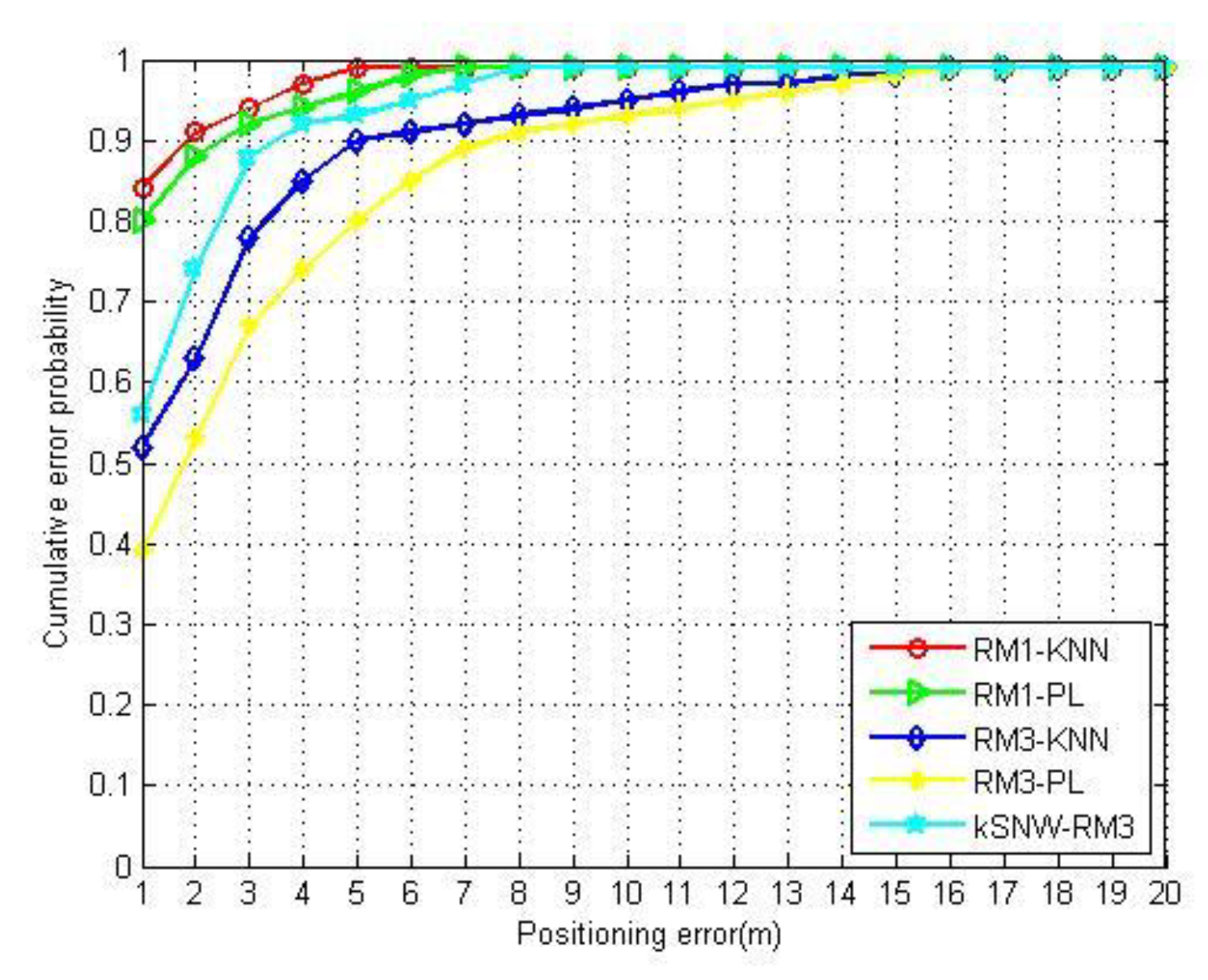
4.2.1. Dimensionality Reduction Performance
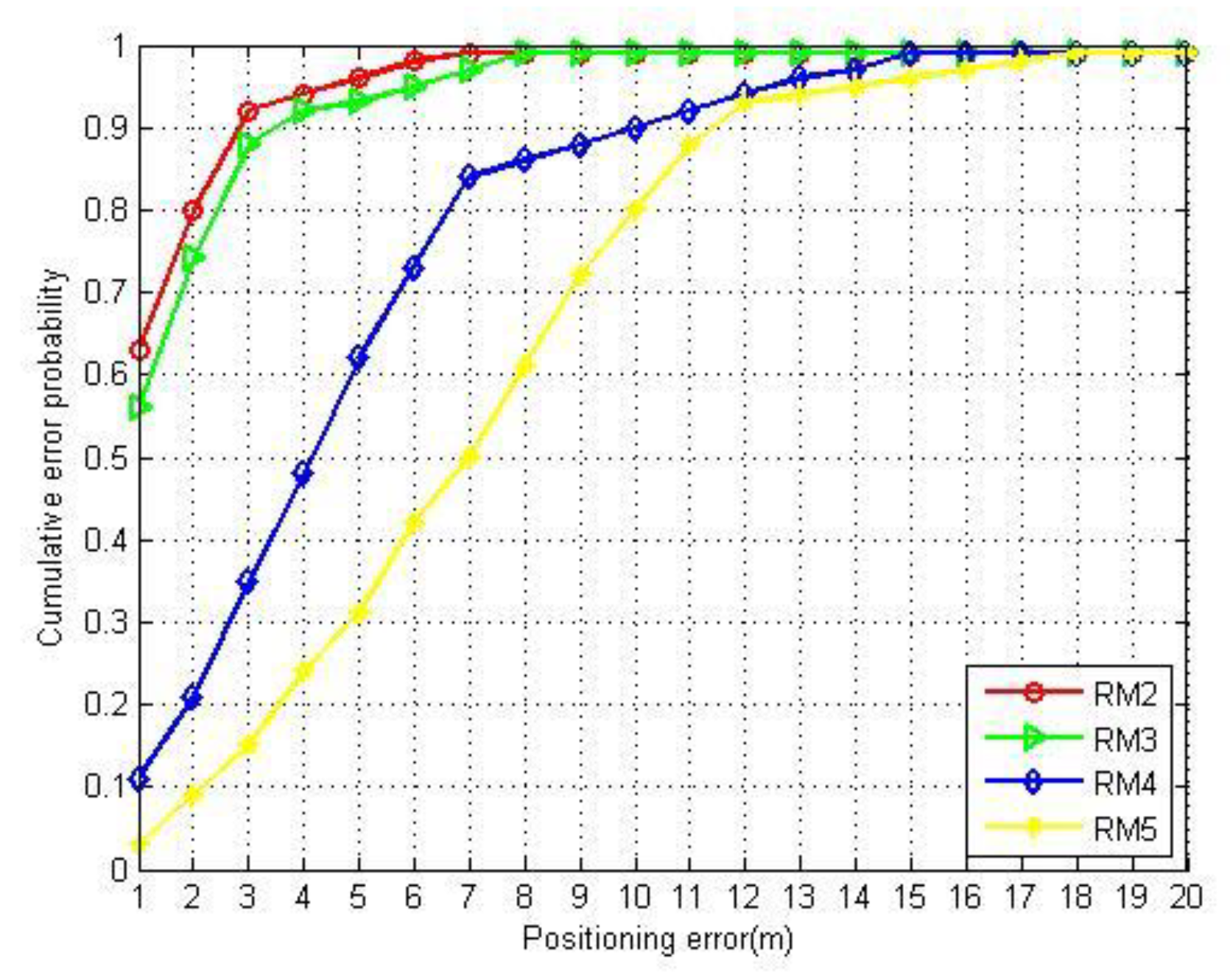
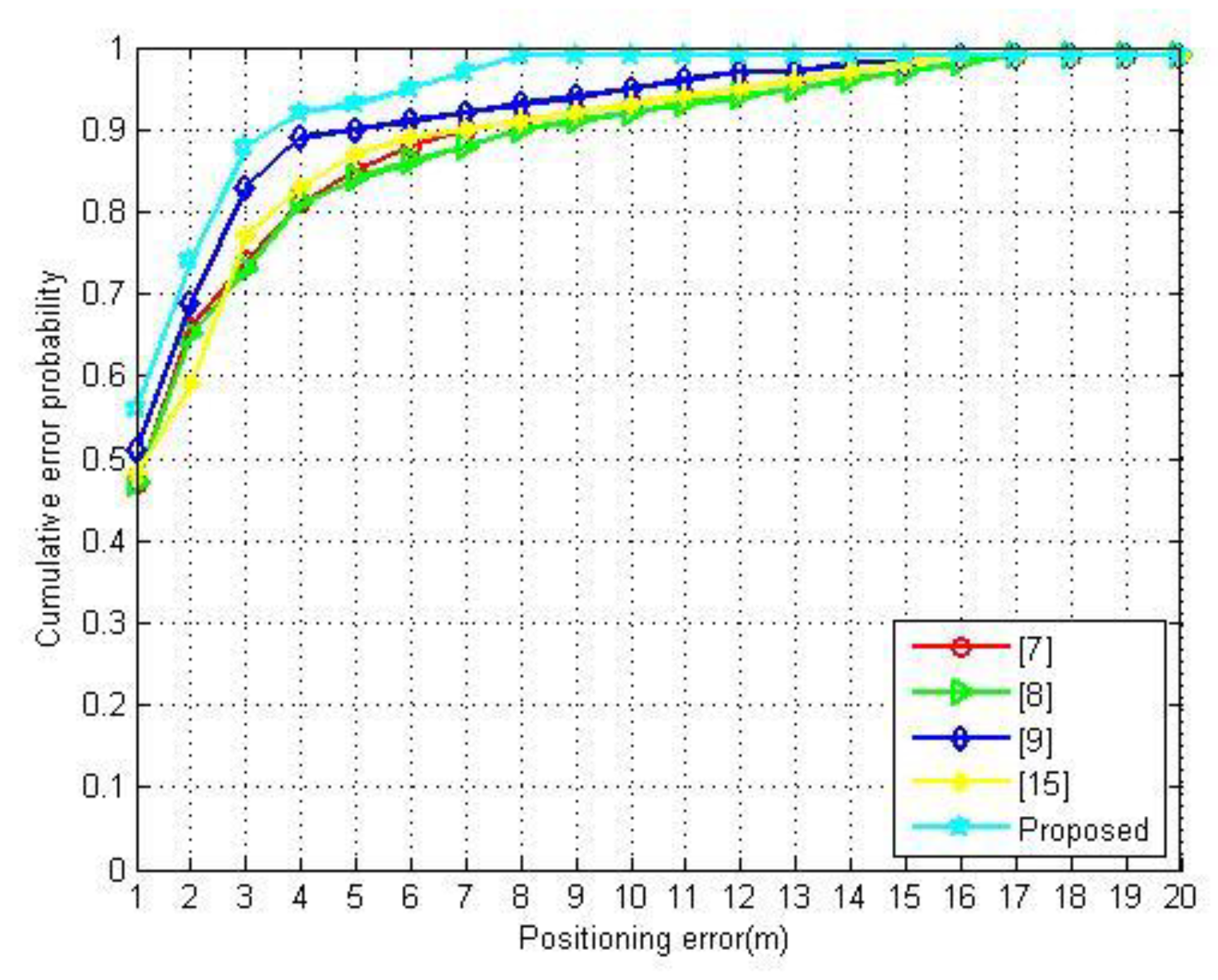
4.2.2. Localization Performance
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Liu, H.; Darabi, H.; Banerjee, P.; Liu, J. Survey of Wireless Indoor Positioning Techniques and Systems. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2007, 37, 1067–1080. [Google Scholar] [CrossRef]
- Honkavirta, V.; Perälä, T.; Ali-Loytty, S.; Piche, R. A comparative survey of WLAN location fingerprinting methods. In Proceedings of the 2009 6th Workshop on Positioning, Navigation and Communication, Hannover, Germany, 19 March 2009; pp. 243–251. [Google Scholar]
- Tang, J.; Hong, R.; Yan, S.; Chua, T.-S.; Qi, G.-J.; Jain, R. Image annotation by k NN-sparse graph-based label propagation over noisily tagged web images. ACM Trans. Intell. Syst. Technol. 2011, 2, 1–15. [Google Scholar] [CrossRef]
- Roweis, S.T.; Saul, L.K. Nonlinear Dimensionality Reduction by Locally Linear Embedding. Science 2000, 290, 2323–2326. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ledlie, J.; Park, J.-G.; Curtis, D.; Cavalcante, A.; Câmara, L.; Costa, A.; Vieira, R. Molé: A scalable, user-generated WiFi positioning engine. J. Locat. Based Serv. 2012, 6, 55–80. [Google Scholar] [CrossRef]
- Yang, S.; Dessai, P.; Verma, M.; Gerla, M.; Verma, M. FreeLoc: Calibration-free crowdsourced indoor localization. In Proceedings of the 2013 IEEE INFOCOM, Turin, Italy, 14–19 April 2013; pp. 2481–2489. [Google Scholar]
- Sorour, S.; Lostanlen, Y.; Valaee, S.; Majeed, K. Joint Indoor Localization and Radio Map Construction with Limited Deployment Load. IEEE Trans. Mob. Comput. 2015, 14, 1031–1043. [Google Scholar] [CrossRef] [Green Version]
- Song, C.; Wang, J. WLAN Fingerprint Indoor Positioning Strategy Based on Implicit Crowdsourcing and Semi-Supervised Learning. ISPRS Int. J. Geo-Inf. 2017, 6, 356. [Google Scholar] [CrossRef] [Green Version]
- Zhou, M.; Tang, Y.; Tian, Z.; Xie, L.; Nie, W. Robust Neighborhood Graphing for Semi-Supervised Indoor Localization with Light-Loaded Location Fingerprinting. IEEE Internet Things J. 2017, 5, 3378–3387. [Google Scholar] [CrossRef]
- Wallbaum, M.; Wasch, T. Markov Localization of Wireless Local Area Network Clients; Springer: Berlin/Heidelberg, Germany, 2014; pp. 1–15. [Google Scholar]
- Wallbaum, M.; Spaniol, O. In Indoor positioning usingwireless local area networks. In Proceedings of the IEEE John Vincent Atanasoff International Symposium on Modern Computing, Sofia, Bulgaria, 3–6 October 2016; pp. 17–26. [Google Scholar]
- Liu, J.; Chen, R.; Pei, L.; Chen, W.; Tenhunen, T.; Kuusniemi, H.; KröGer, T.; Chen, Y. In Accelerometer assisted robust wireless signal positioning based on a hidden Markov model. In Proceedings of the Position Location & Navigation Symposium, Indian Wells, CA, USA, 4–6 May 2010; pp. 488–497. [Google Scholar]
- Ye, A.; Yang, X.; Xu, L.; Li, Q. A Novel Adaptive Radio-Map for RSS-Based Indoor Positioning. In Proceedings of the 2017 International Conference on Green Informatics (ICGI), Fuzhou, China, 15–17 August 2017; pp. 205–210. [Google Scholar]
- Talvitie, J.; Renfors, M.; Lohan, E.S. Distance-Based Interpolation and Extrapolation Methods for RSS-Based Localization with Indoor Wireless Signals. IEEE Trans. Veh. Technol. 2015, 64, 1340–1353. [Google Scholar] [CrossRef]
- Jan, S.-S.; Yeh, S.-J.; Liu, Y.-W. Received Signal Strength Database Interpolation by Kriging for a Wi-Fi Indoor Positioning System. Sensors 2015, 15, 21377–21393. [Google Scholar] [CrossRef] [PubMed]
- Bi, J.; Wang, Y.; Li, Z.; Xu, S.; Zhou, J.; Sun, M.; Si, M. Fast Radio Map Construction by using Adaptive Path Loss Model Interpolation in Large-Scale Building. Sensors 2019, 19, 712. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Piotr, I.; Motwani, R. Approximate nearest neighbors: Towards removing the curse of dimensionality. In Proceedings of the Thirtieth Annual ACM Symposium on Theory of Computing, Dallas, TX, USA, 24–26 May 1998. [Google Scholar]
- Krishna, K.; Murty, M.N. Genetic K-means algorithm. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 1999, 29, 433–439. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Saul, L.K.; Roweis, S.T. Think globally, fit locally: Unsupervised learning of low dimensional manifolds. J. Mach. Learn. Res. 2003, 4, 119–155. [Google Scholar]
- Pettis, K.W.; Bailey, T.A.; Jain, A.K.; Dubes, R.C. An Intrinsic Dimensionality Estimator from Near-Neighbor Information. IEEE Trans. Pattern Anal. Mach. Intell. 1979, 1, 25–37. [Google Scholar] [CrossRef] [PubMed]
- Matthew, B. Charting a Manifold. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2003. [Google Scholar]
- Balázs, K. Intrinsic dimension estimation using packing numbers. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2003. [Google Scholar]
- Fang, S.-H.; Lin, T. Principal Component Localization in Indoor WLAN Environments. IEEE Trans. Mob. Comput. 2011, 11, 100–110. [Google Scholar] [CrossRef]
- Pascal, S.; Mineau, G.W. A simple KNN algorithm for text categorization. In Proceedings of the 2001 IEEE International Conference on Data Mining, San Jose, CA, USA, 29 November–2 December 2001. [Google Scholar]
- Castro, P.; Chiu, P.; Kremenek, T.; Muntz, R. A Probabilistic Room Location Service for Wireless Networked Environments. In Proceedings of the International Conference on Ubiquitous Computing, Atlanta, GA, USA, 30 September–2 October 2001. [Google Scholar]
- Madigan, D.; Einahrawy, E.; Martin, R.P.; Ju, W.-H.; Krishnan, P.; Krishnakumar, A. Bayesian indoor positioning systems. In Proceedings of the IEEE 24th Annual Joint Conference of the IEEE Computer and Communications Societies, Miami, FL, USA, 13–17 March 2005; Volume 2, pp. 1217–1227. [Google Scholar]
- Le, D.V.; Meratnia, N.; Havinga, P.J. Unsupervised Deep Feature Learning to Reduce the Collection of Fingerprints for Indoor Localization Using Deep Belief Networks. In Proceedings of the 2018 International Conference on Indoor Positioning and Indoor Navigation (IPIN), Nantes, France, 24–27 September 2018; pp. 1–7. [Google Scholar]
- Bisio, I.; Garibotto, C.; Lavagetto, F.; Sciarrone, A.; Zappatore, S. Unauthorized Amateur UAV Detection Based on WiFi Statistical Fingerprint Analysis. IEEE Commun. Mag. 2018, 56, 106–111. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Location | RSSI (dBm) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| −86 | −73 | −69 | −63 | −78 | −58 | −88 | −65 | −76 | −56 | −72 | −80 | −88 | |
| −86 | −74 | −70 | −63 | −76 | −57 | −87 | −69 | −79 | −56 | −74 | −80 | −89 | |
| −85 | −73 | −68 | −61 | −75 | −55 | −90 | −70 | −80 | −57 | −77 | −82 | −90 | |
| −85 | −73 | −68 | −62 | −77 | −56 | −89 | −66 | −76 | −56 | −78 | −82 | −90 | |
| −87 | −75 | −71 | −64 | −79 | −60 | −86 | −64 | −73 | −55 | −69 | −79 | −87 | |
| Localization Area | Status | RSSI Dimension | KNN Algorithm Complexity |
|---|---|---|---|
| Fourth floor of the YiFu building | Before dimensionality reduction | 13 | |
| After dimensionality reduction | 4 | ||
| Library | Before dimensionality reduction | 19 | |
| After dimensionality reduction | 3 |
| Number | East–West Interval | North–South Interval | Labeled Fingerprint | Unlabeled RSSI Sample |
|---|---|---|---|---|
| DS 1 | 2 m | 2 m | 600 | 0 |
| DS 2 | 4 m | 2 m | 300 | 300 |
| DS 3 | 4 m | 4 m | 150 | 450 |
| DS 4 | 6 m | 4 m | 100 | 500 |
| DS 5 | 6 m | 8 m | 50 | 550 |
| Number | Computation Time of kSWN | Computation Time of Merging Method |
|---|---|---|
| 1 | 108 ms | 951 ms |
| 2 | 98 ms | 871 ms |
| 3 | 121 ms | 784 m |
| 4 | 78 ms | 610 m |
| 5 | 89 ms | 709 ms |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ni, Y.; Chai, J.; Wang, Y.; Fang, W. A Fast Radio Map Construction Method Merging Self-Adaptive Local Linear Embedding (LLE) and Graph-Based Label Propagation in WLAN Fingerprint Localization Systems. Sensors 2020, 20, 767. https://doi.org/10.3390/s20030767
Ni Y, Chai J, Wang Y, Fang W. A Fast Radio Map Construction Method Merging Self-Adaptive Local Linear Embedding (LLE) and Graph-Based Label Propagation in WLAN Fingerprint Localization Systems. Sensors. 2020; 20(3):767. https://doi.org/10.3390/s20030767
Chicago/Turabian StyleNi, Yepeng, Jianping Chai, Yan Wang, and Weidong Fang. 2020. "A Fast Radio Map Construction Method Merging Self-Adaptive Local Linear Embedding (LLE) and Graph-Based Label Propagation in WLAN Fingerprint Localization Systems" Sensors 20, no. 3: 767. https://doi.org/10.3390/s20030767