Geo-Social Top-k and Skyline Keyword Queries on Road Networks

 ,
, 

 , and
, and
Abstract
:1. Introduction
- We introduce geo-social top-k keyword (GSTK) queries on road networks that ranks data objects based on spatial, textual and social relevance.
- We extend our work to propose geo-social skyline keyword (GSSK) queries that return data objects that are not dominated by any other data object.
- We present an indexing technique to retrieve data objects. Furthermore, we present efficient algorithms that exploit the indexing technique to process these queries.
- Finally, we conduct extensive experiments on real road network datasets to demonstrate the efficiency of the proposed techniques.
2. Related Work
2.1. Top-k Keyword Queries
2.2. Skyline Queries
2.3. Geo-Social Queries
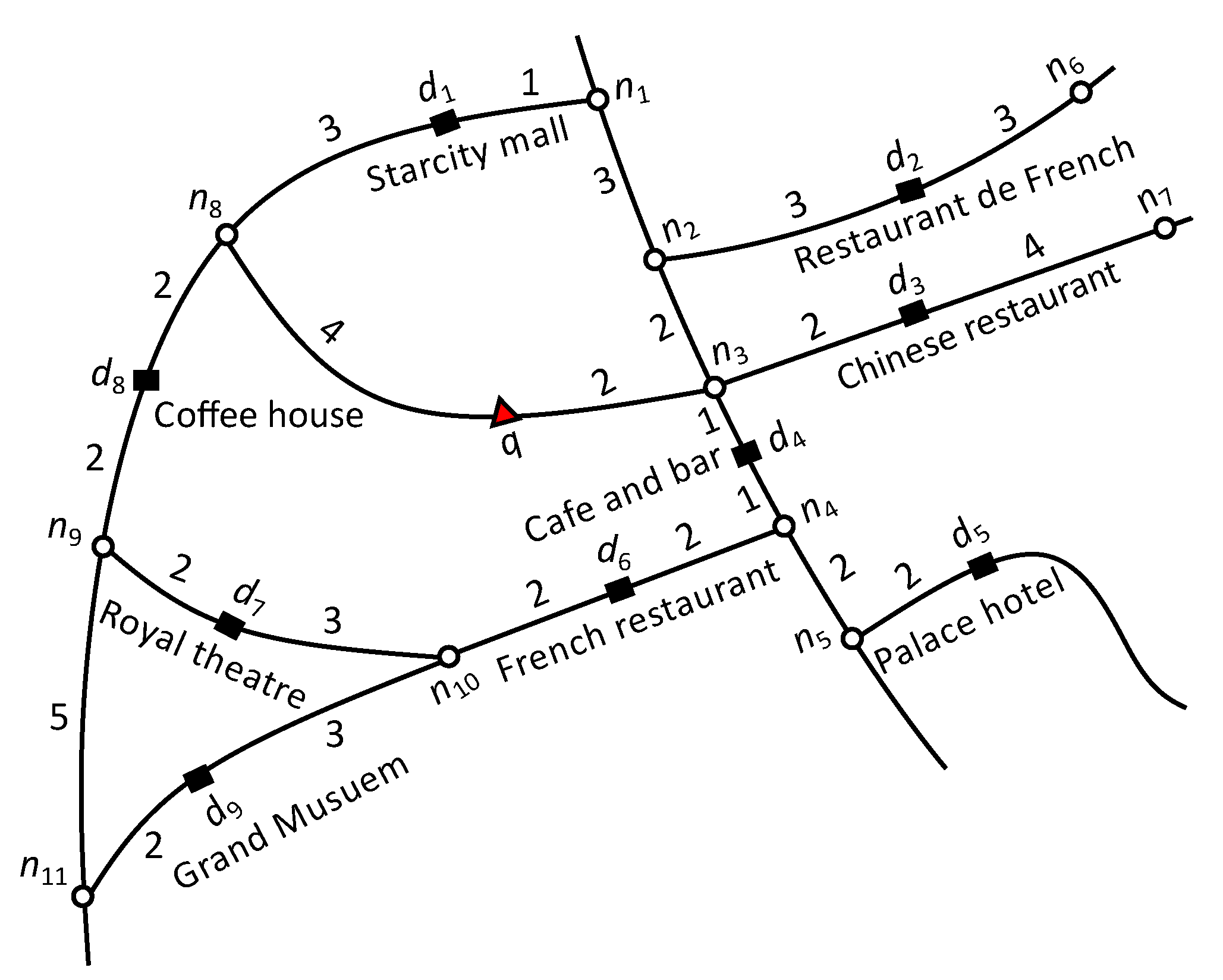
3. Preliminaries
4. Geo-Social Top-k Keyword Queries
4.1. Problem Formulation
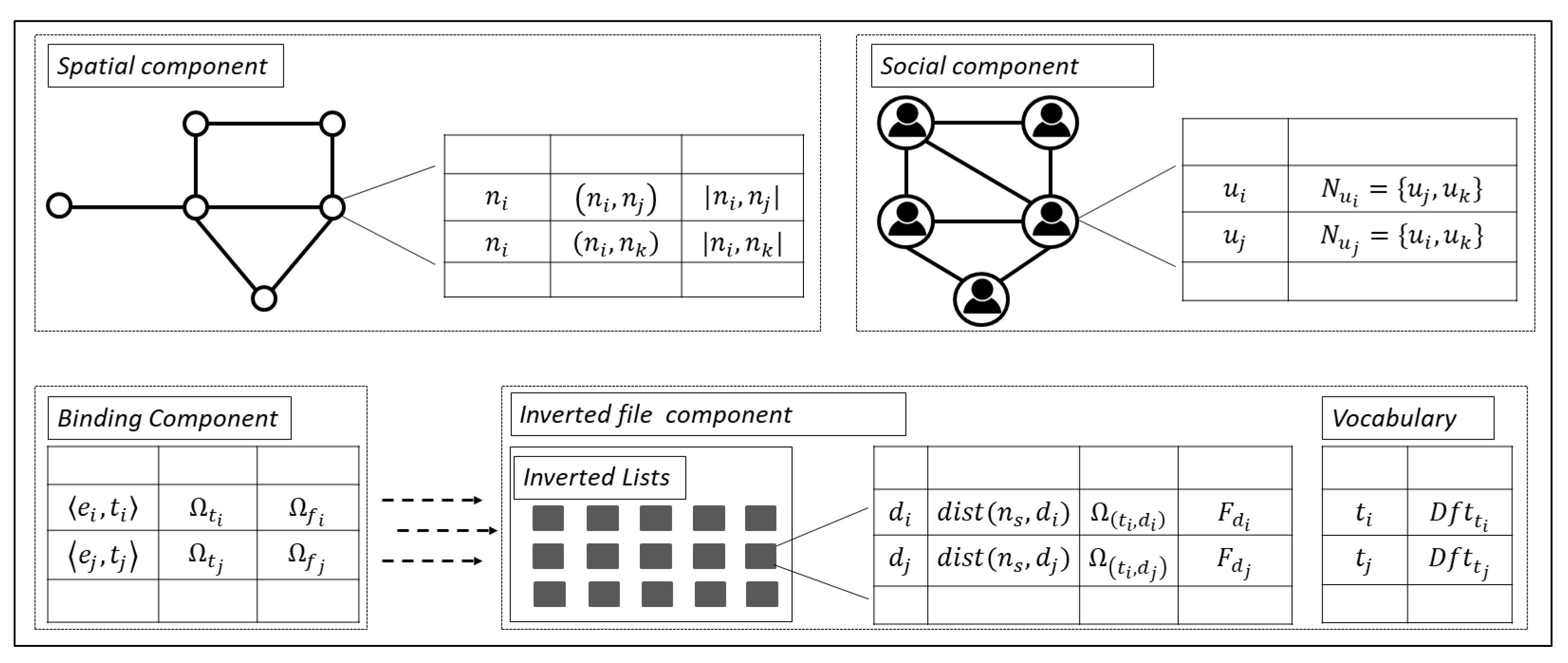
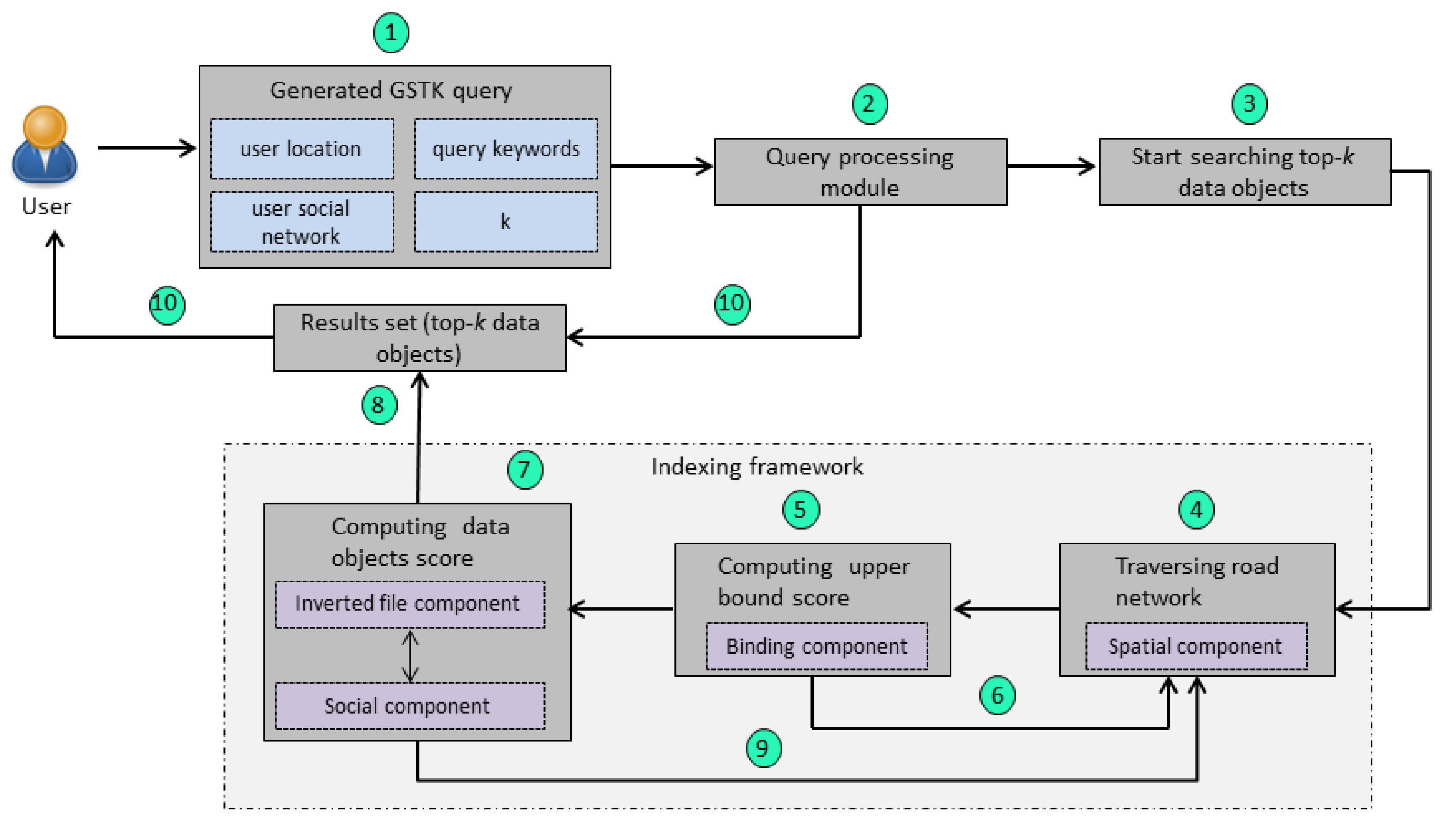
4.2. Indexing Framework
4.3. Methodology
4.4. Query Processing Algorithm


4.5. Index Maintenance
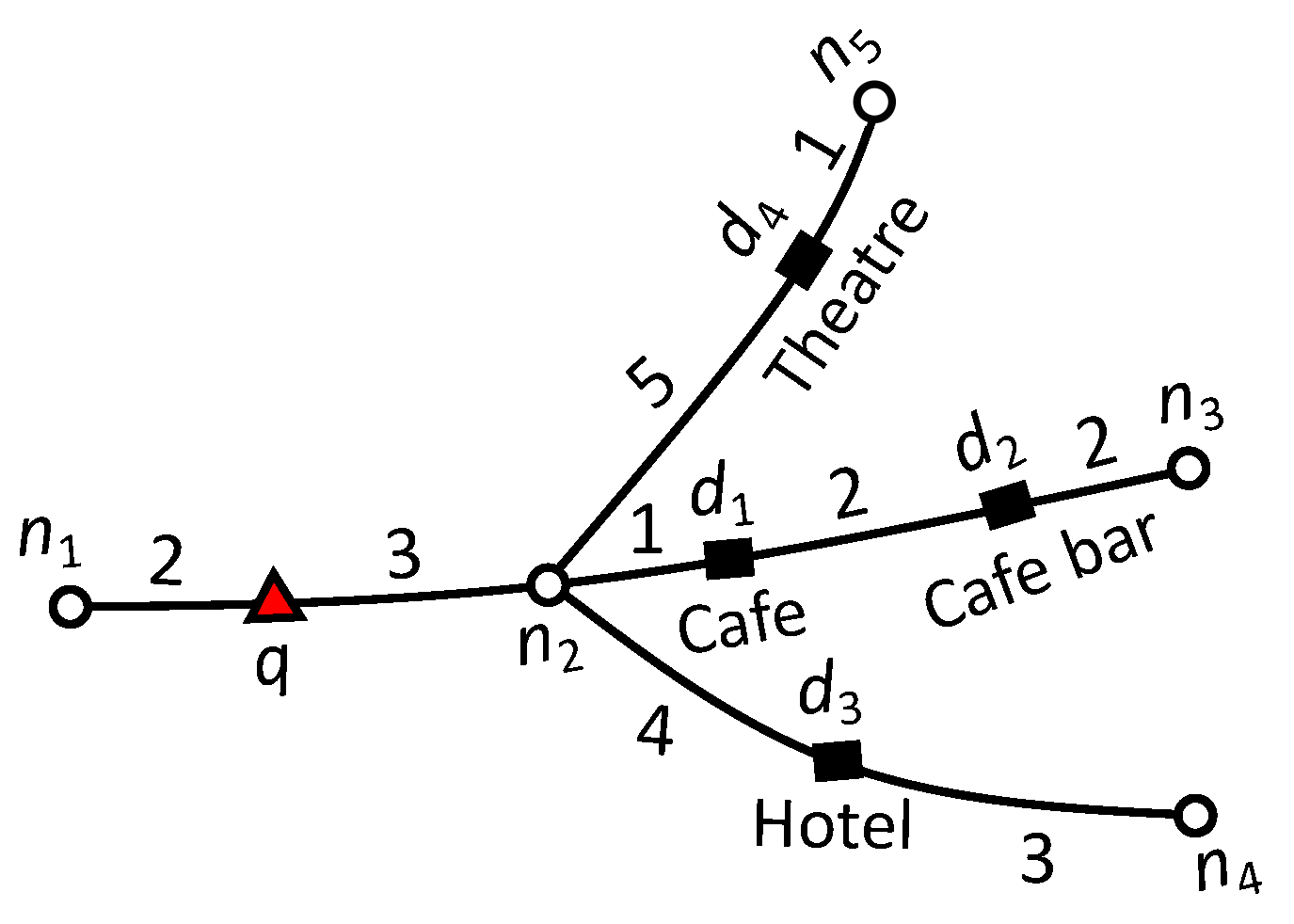
5. Geo-Social Skyline Keyword Queries
5.1. Problem Formulation
5.2. Query Processing Algorithm

6. Performance Evaluation
6.1. Experimental Settings
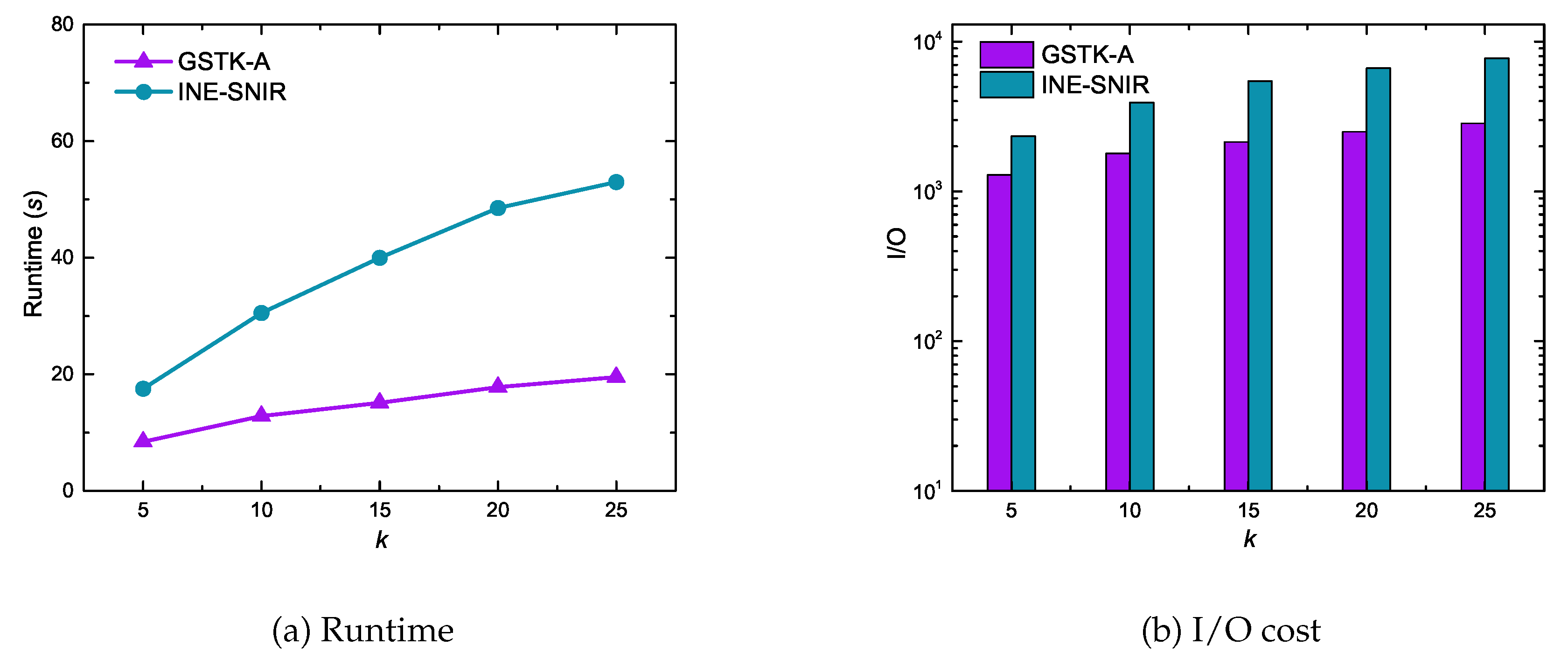
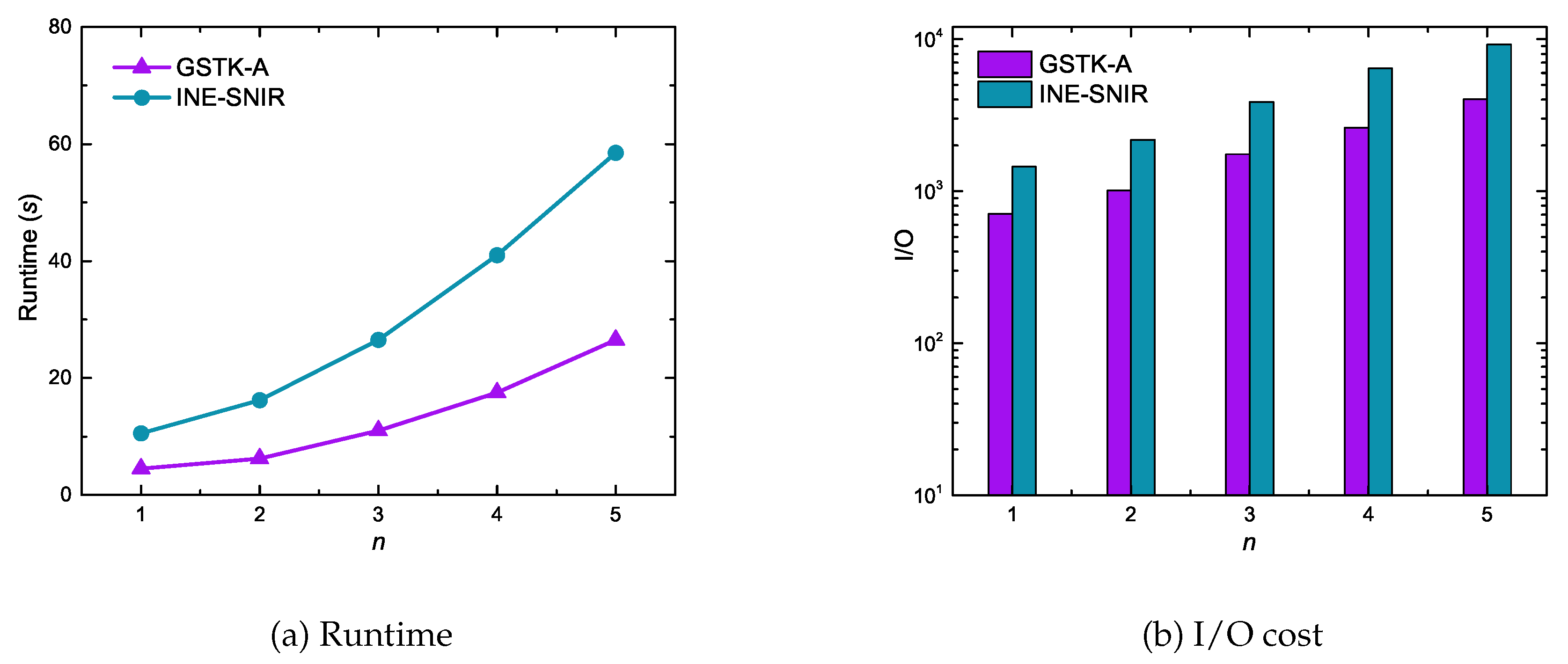
6.2. Experimental Results of Geo-Social Top-k Keyword Queries
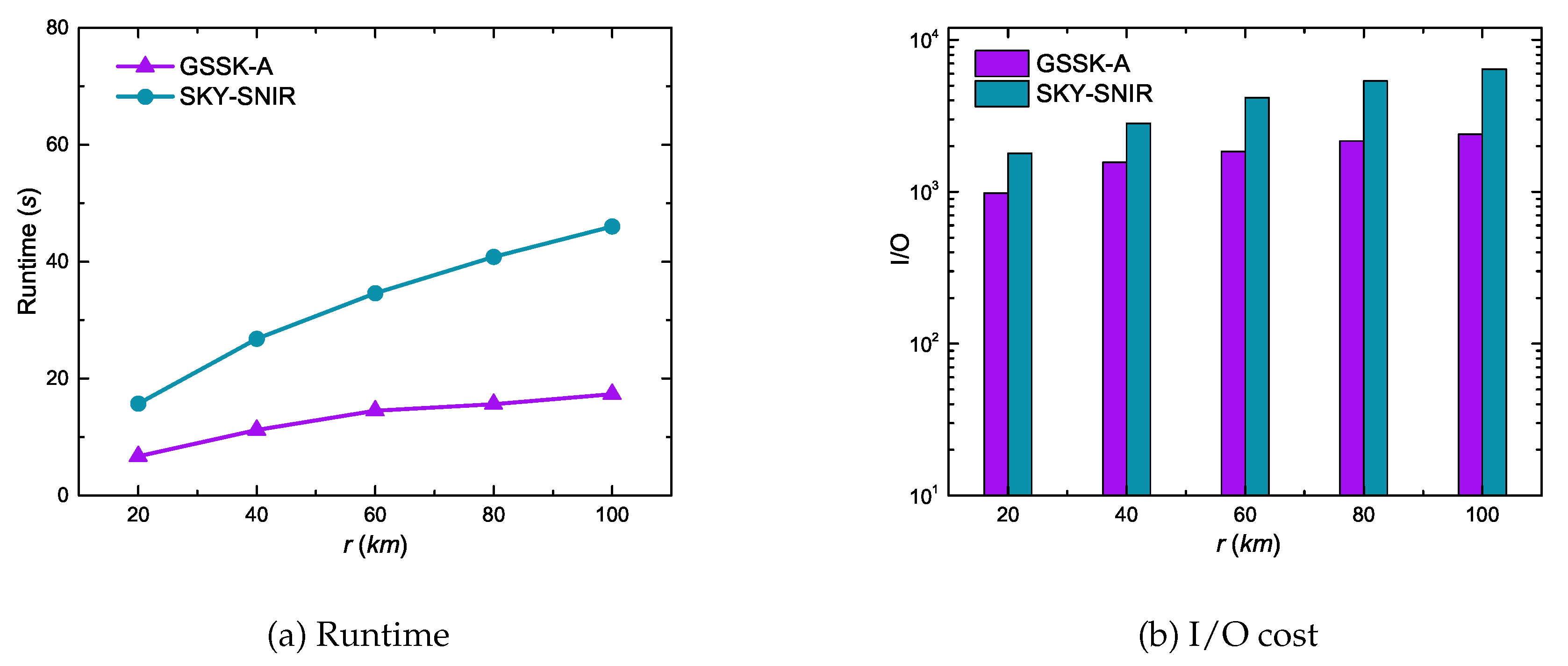
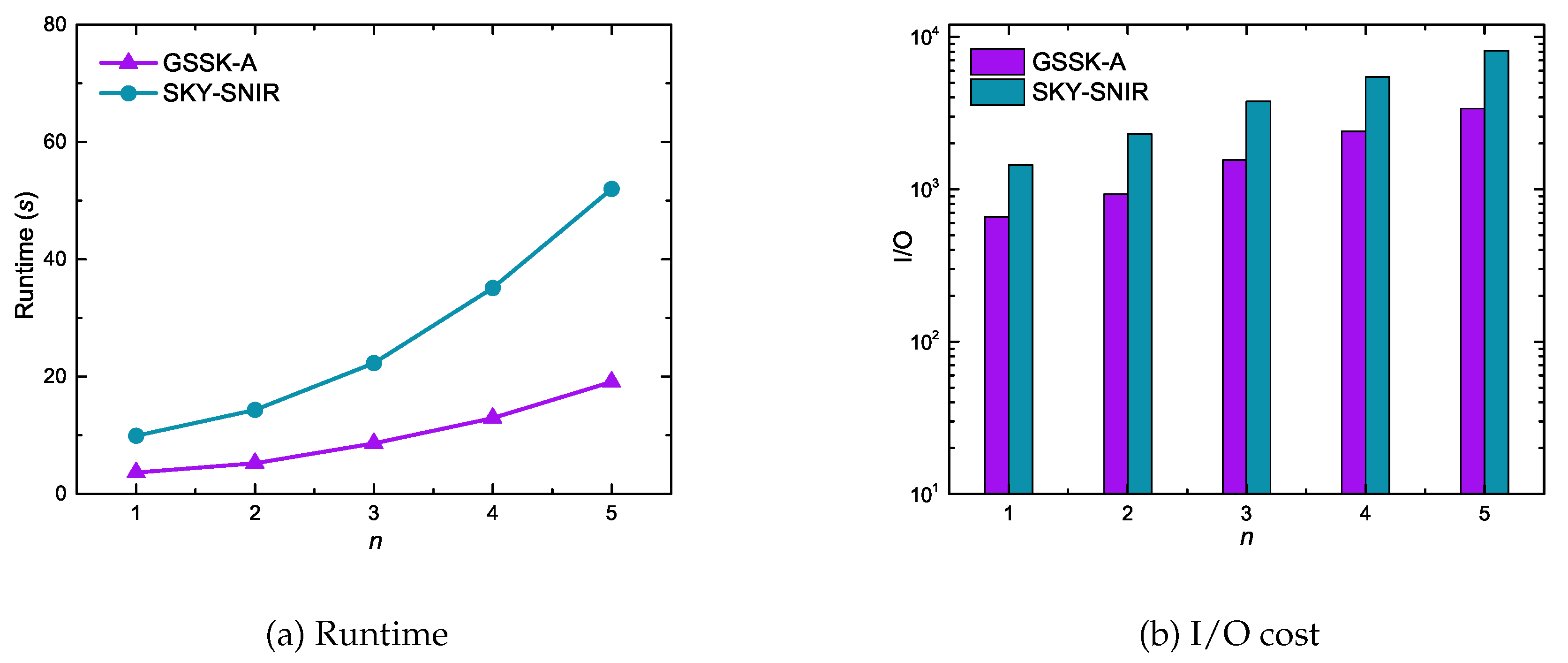
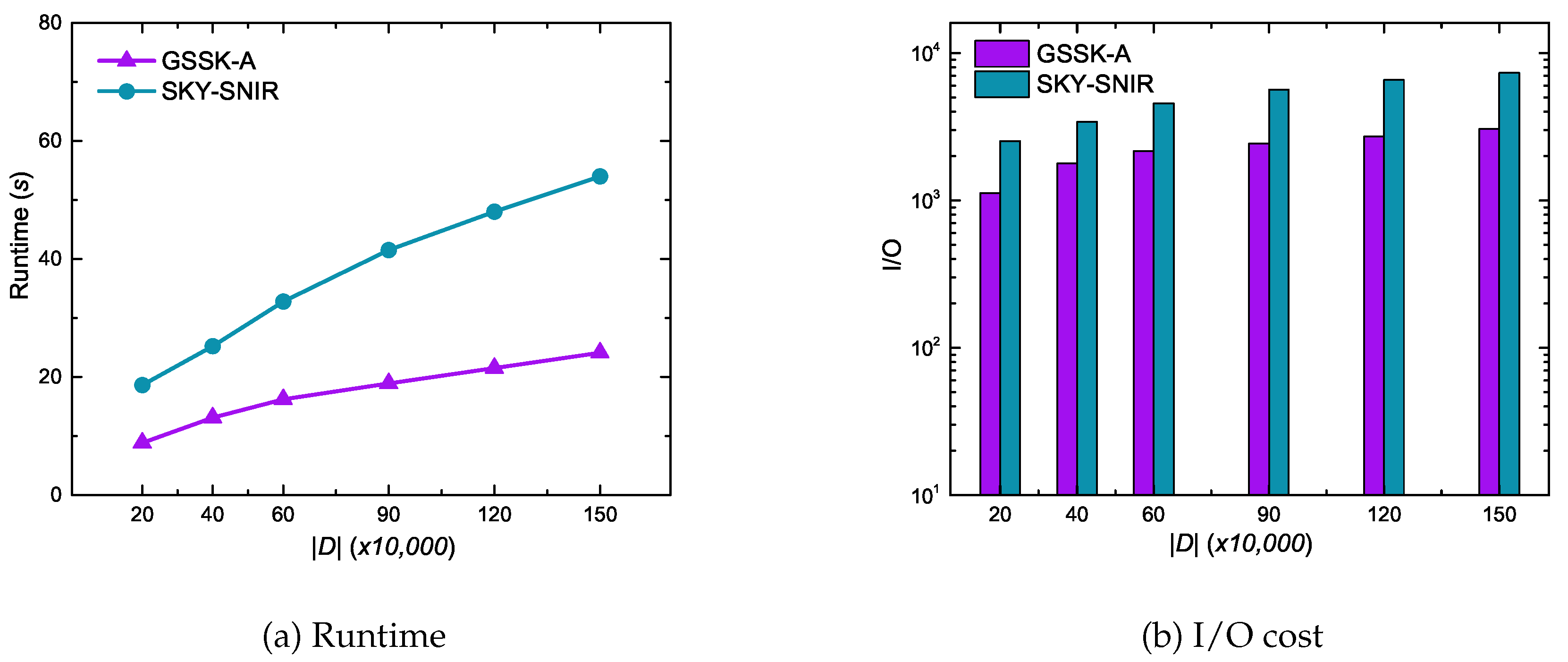
6.3. Experimental Results of Geo-Social Skyline Keyword Queries
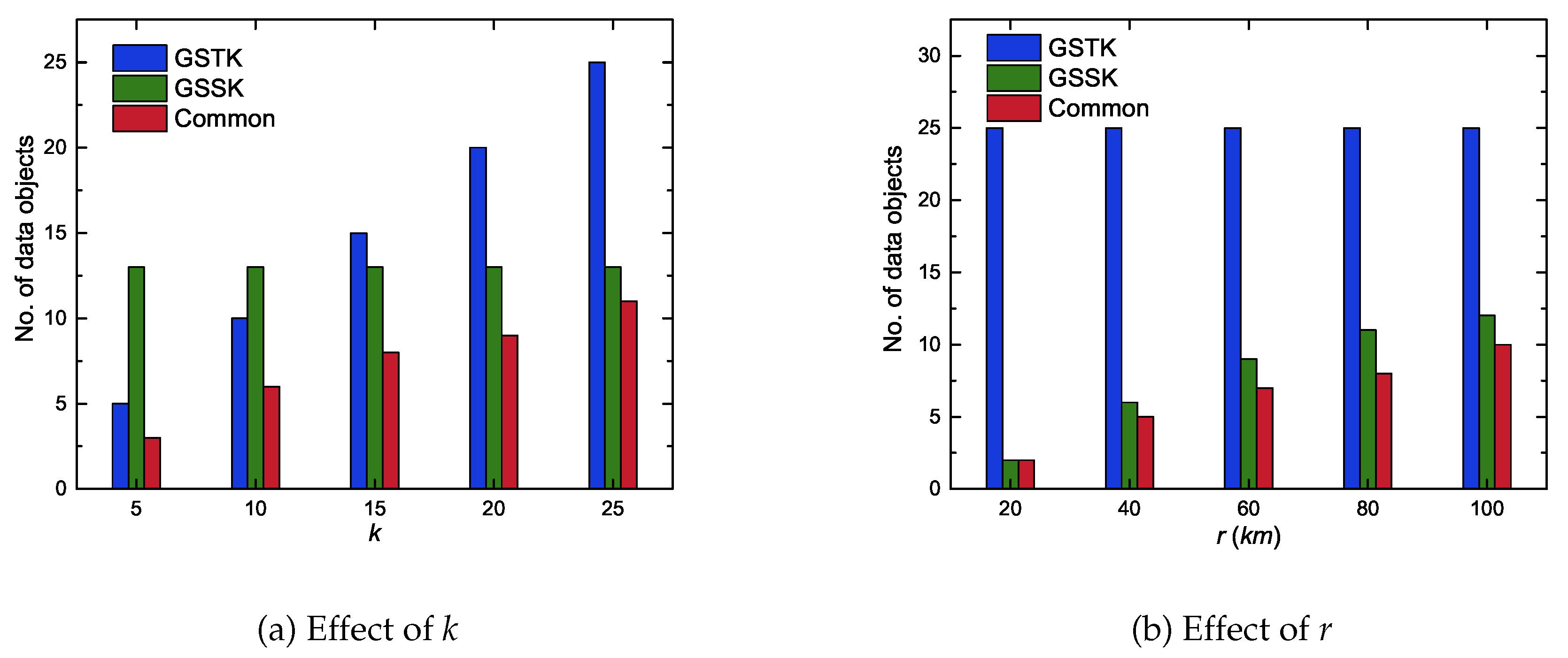
6.4. Comparison of Results Returned by GSTK and GSSK Queries
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Cao, X.; Chen, L.; Cong, G.; Jensen, C.S.; Qu, Q.; Skovsgaard, A.; Wu, D.; Yiu, M.L. Spatial keyword querying. In Proceedings of the International Conference on Conceptual Modeling, Berlin, Germany, 15 October 2012; pp. 16–29. [Google Scholar]
- Zheng, K.; Su, H.; Zheng, B.; Shang, S.; Xu, J.; Liu, J.; Zhou, X. Interactive top-k spatial keyword queries. In Proceedings of the 2015 IEEE 31st International Conference on Data Engineering, Seoul, Korea, 13–17 April 2015; pp. 423–434. [Google Scholar]
- De Felipe, I.; Hristidis, V.; Rishe, N. Keyword search on spatial databases. In Proceedings of the 2008 IEEE 24th International Conference on Data Engineering, Cancun, Mexico, 7–12 April 2008; pp. 656–665. [Google Scholar]
- Cong, G.; Jensen, C.S.; Wu, D. Efficient retrieval of the top-k most relevant spatial web objects. Proc. VLDB Endowment 2009, 2, 337–348. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Lee, K.C.; Zheng, B.; Lee, W.C.; Lee, D.; Wang, X. Ir-tree: An efficient index for geographic document search. IEEE Trans. Knowl. Data Eng. 2011, 23, 585–599. [Google Scholar] [CrossRef]
- Guo, L.; Shao, J.; Aung, H.H.; Tan, K.L. Efficient continuous top-k spatial keyword queries on road networks. GeoInformatica 2015, 19, 29–60. [Google Scholar] [CrossRef]
- Rocha-Junior, J.B.; Nørvåg, K. Top-k spatial keyword queries on road networks. In Proceedings of the 15th International Conference on Extending Database Technology, Berlin, Germany, 24 August 2011; pp. 168–179. [Google Scholar]
- Emrich, T.; Franzke, M.; Mamoulis, N.; Renz, M.; Züfle, A. Geo-social skyline queries. In Proceedings of the International Conference on Database Systems for Advanced Applications, Chiang Mai, Thailand, 22–25 April 2014; pp. 77–91. [Google Scholar]
- Sohail, A.; Cheema, M.A.; Taniar, D. Social-aware spatial top-k and skyline queries. Comput. J. 2018, 61, 1620–1638. [Google Scholar] [CrossRef]
- Wu, D.; Li, Y.; Choi, B.; Xu, J. Social-aware top-k spatial keyword search. In Proceedings of the 2014 IEEE 15th International Conference on Mobile Data Management, Brisbane, Australia, 14–18 July 2014; pp. 235–244. [Google Scholar]
- Zhou, Y.; Xie, X.; Wang, C.; Gong, Y.; Ma, W.Y. Hybrid index structures for location-based web search. In Proceedings of the 14th ACM International Conference on Information and Knowledge Management, Bremen, Germany, 31 October 2005; pp. 155–162. [Google Scholar]
- Zobel, J.; Moffat, A. Inverted files for text search engines. ACM Comput. Surv. (CSUR) 2006, 38, 6. [Google Scholar] [CrossRef]
- Beckmann, N.; Kriegel, H.P.; Schneider, R.; Seeger, B. The R*-tree: An efficient and robust access method for points and rectangles. In Proceedings of the 1990 ACM SIGMOD International Conference on Management of Data, Atlantic City, NJ, USA, 1 May 1990; Volume 19, pp. 322–331. [Google Scholar]
- Rocha-Junior, J.B.; Gkorgkas, O.; Jonassen, S.; Nørvåg, K. Efficient processing of top-k spatial keyword queries. In Proceedings of the International Symposium on Spatial and Temporal Databases, Minneapolis, MN, USA, 24–26 August 2011; pp. 205–222. [Google Scholar]
- Bao, J.; Chow, C.Y.; Mokbel, M.F.; Ku, W.S. Efficient evaluation of k-range nearest neighbor queries in road networks. In Proceedings of the 2010 Eleventh International Conference on Mobile Data Management, Kansas City, MO, USA, 23–26 May 2010; pp. 115–124. [Google Scholar]
- Attique, M.; Cho, H.J.; Jin, R.; Chung, T.S. Top-k spatial preference queries in directed road networks. ISPRS Int. J. Geo-Inf. 2016, 5, 170. [Google Scholar] [CrossRef] [Green Version]
- Huang, Y.K.; Chen, Z.W.; Lee, C. Continuous k-nearest neighbor query over moving objects in road networks. In Advances in Data and Web Management; Springer: Berlin, Germany, 2009; pp. 27–38. [Google Scholar]
- Cho, H.J.; Ryu, K.; Chung, T.S. An efficient algorithm for computing safe exit points of moving range queries in directed road networks. Inf. Syst. 2014, 41, 1–19. [Google Scholar] [CrossRef]
- Attique, M.; Gudeta, Y.H.; Ayele, S.G.; Cho, H.J.; Chung, T.S. A safe exit approach for continuous monitoring of reverse k-nearest neighbors in road networks. Int. Arab J. Inf. Technol. 2015, 12, 540–549. [Google Scholar]
- Gao, Y.; Qin, X.; Zheng, B.; Chen, G. Efficient reverse top-k boolean spatial keyword queries on road networks. IEEE Trans. Knowl. Data Eng. 2014, 27, 1205–1218. [Google Scholar] [CrossRef]
- Attique, M.; Cho, H.J.; Chung, T.S. Efficient Processing of Moving Top-k Spatial Keyword Queries in Directed and Dynamic Road Networks. Wirel. Commun. Mob. Comput. 2018. [Google Scholar] [CrossRef] [Green Version]
- Borzsony, S.; Kossmann, D.; Stocker, K. The skyline operator. In Proceedings of the 17th International Conference on Data Engineering, Heidelberg, Germany, 2–6 April 2001; pp. 421–430. [Google Scholar]
- Chomicki, J.; Godfrey, P.; Gryz, J.; Liang, D. Skyline with presorting: Theory and optimizations. In Intelligent Information Processing and Web Mining; Springer: Berlin, Germany, 2005; pp. 595–604. [Google Scholar]
- Sharifzadeh, M.; Shahabi, C. The spatial skyline queries. In Proceedings of the 32nd International Conference on Very Large Data Bases, VLDB Endowment, Seoul, Korea, 12–15 September 2006; pp. 751–762. [Google Scholar]
- Deng, K.; Zhou, X.; Tao, H. Multi-source skyline query processing in road networks. In Proceedings of the 2007 IEEE 23rd International Conference on Data Engineering, Istanbul, Turkey, 15–20 April 2007; pp. 796–805. [Google Scholar]
- Choi, H.; Jung, H.; Lee, K.Y.; Chung, Y.D. Skyline queries on keyword-matched data. Inf. Sci. 2013, 232, 449–463. [Google Scholar] [CrossRef]
- Regalado, A.; Goncalves, M.; Abad-Mota, S. Evaluating skyline queries on spatial web objects. In Proceedings of the International Conference on Database and Expert Systems Applications, Vienna, Austria, 3–6 September 2012; pp. 416–423. [Google Scholar]
- Shi, J.; Wu, D.; Mamoulis, N. Textually relevant spatial skylines. IEEE Trans. Knowl. Data Eng. 2015, 28, 224–237. [Google Scholar] [CrossRef] [Green Version]
- Ahuja, R.; Armenatzoglou, N.; Papadias, D.; Fakas, G.J. Geo-social keyword search. In Proceedings of the International Symposium on Spatial and Temporal Databases, Hong Kong, China, 26–28 August 2015; pp. 431–450. [Google Scholar]
- Yang, D.N.; Shen, C.Y.; Lee, W.C.; Chen, M.S. On socio-spatial group query for location-based social networks. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12 August 2012; pp. 949–957. [Google Scholar]
- Zhao, J.; Gao, Y.; Chen, G.; Jensen, C.S.; Chen, R.; Cai, D. Reverse top-k geo-social keyword queries in road networks. In Proceedings of the 2017 IEEE 33rd International Conference on Data Engineering (ICDE), San Diego, CA, USA, 19–22 April 2017; pp. 387–398. [Google Scholar]
- Zhang, J.; Meng, X.; Zhou, X.; Liu, D. Co-spatial searcher: Efficient tag-based collaborative spatial search on geo-social network. In Proceedings of the International Conference on Database Systems for Advanced Applications, Busan, South Korea, 15–19 April 2012; pp. 560–575. [Google Scholar]
- Jiang, J.; Lu, H.; Yang, B.; Cui, B. Finding top-k local users in geo-tagged social media data. In Proceedings of the 2015 IEEE 31st International Conference on Data Engineering, Seoul, Korea, 13–17 April 2015; pp. 267–278. [Google Scholar]
- Huang, Q.; Liu, Y. On geo-social network services. In Proceedings of the IEEE 2009 17th International Conference on Geoinformatics, Fairfax, VA, USA, 12–14 August 2009; pp. 1–6. [Google Scholar]
- Ye, M.; Yin, P.; Lee, W.C. Location recommendation for location-based social networks. In Proceedings of the 18th Sigspatial International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 458–461. [Google Scholar]
- Levandoski, J.J.; Sarwat, M.; Eldawy, A.; Mokbel, M.F. Lars: A location-aware recommender system. In Proceedings of the 2012 IEEE 28th International Conference on Data Engineering, Washington, DC, USA, 1–5 April 2012; pp. 450–461. [Google Scholar]
- Liu, W.; Sun, W.; Chen, C.; Huang, Y.; Jing, Y.; Chen, K. Circle of friend query in geo-social networks. In Proceedings of the International Conference on Database Systems for Advanced Applications, Busan, Korea, 15–19 April 2012; pp. 126–137. [Google Scholar]
- Salton, G.; Buckley, C. Term-weighting approaches in automatic text retrieval. Inf. Process. Manag. 1988, 24, 513–523. [Google Scholar] [CrossRef] [Green Version]
- Anh, V.N.; de Kretser, O.; Moffat, A. Vector-space ranking with effective early termination. In Proceedings of the 24th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, New Orleans, LA, USA, 9–13 September 2001; pp. 35–42. [Google Scholar]
- Papadias, D.; Zhang, J.; Mamoulis, N.; Tao, Y. Query processing in spatial network databases. In Proceedings of the 29th International Conference on Very Large Data Bases, VLDB Endowment, Berlin, Germany, 9–12 September 2003; Volume 29, pp. 802–813. [Google Scholar]
- Dijkstra, E.W. A note on two problems in connexion with graphs. Numer. Math. 1959, 1, 269–271. [Google Scholar] [CrossRef] [Green Version]
- Papadias, D.; Tao, Y.; Fu, G.; Seeger, B. Progressive skyline computation in database systems. ACM Trans. Database Syst. (TODS) 2005, 30, 41–82. [Google Scholar] [CrossRef]
- Real Datasets for Spatial Databases. Available online: https://www.cs.utah.edu/~lifeifei/SpatialDataset.htm (accessed on 12 January 2019).
- Cho, E.; Myers, S.A.; Leskovec, J. Friendship and mobility: User movement in location-based social networks. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 21–24 August 2011; pp. 1082–1090. [Google Scholar]
- Twitter. Available online: https://twitter.com (accessed on 12 January 2019).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Definition |
|---|---|
| Score of data object d | |
| Textual relevance of data object d with query keywords | |
| Social relevance of data object d with query user | |
| Spatial relevance of data object d with query location | |
| Preference parameters that represent the importance of textual, social and spatial relevance, respectively | |
| Preference parameter that controls the importance between query user friends and other users | |
| Set of fans of data object d | |
| One-hop neighbors of q in social network | |
| Highest significance of a given term t among the description of the data objects lying on edge | |
| Highest significance of fans of any data object lying on edge with term t | |
| Aggregated social and textual score used in GSSK queries |
| d | in | |||||
|---|---|---|---|---|---|---|
| 7 | 0.66 | 20 | 5 | 0.35 | 0.033 | |
| 4 | 0.50 | 23 | 1 | 0.165 | 0.020 | |
| 6 | 1 | 9 | 2 | 0.145 | 0.024 |
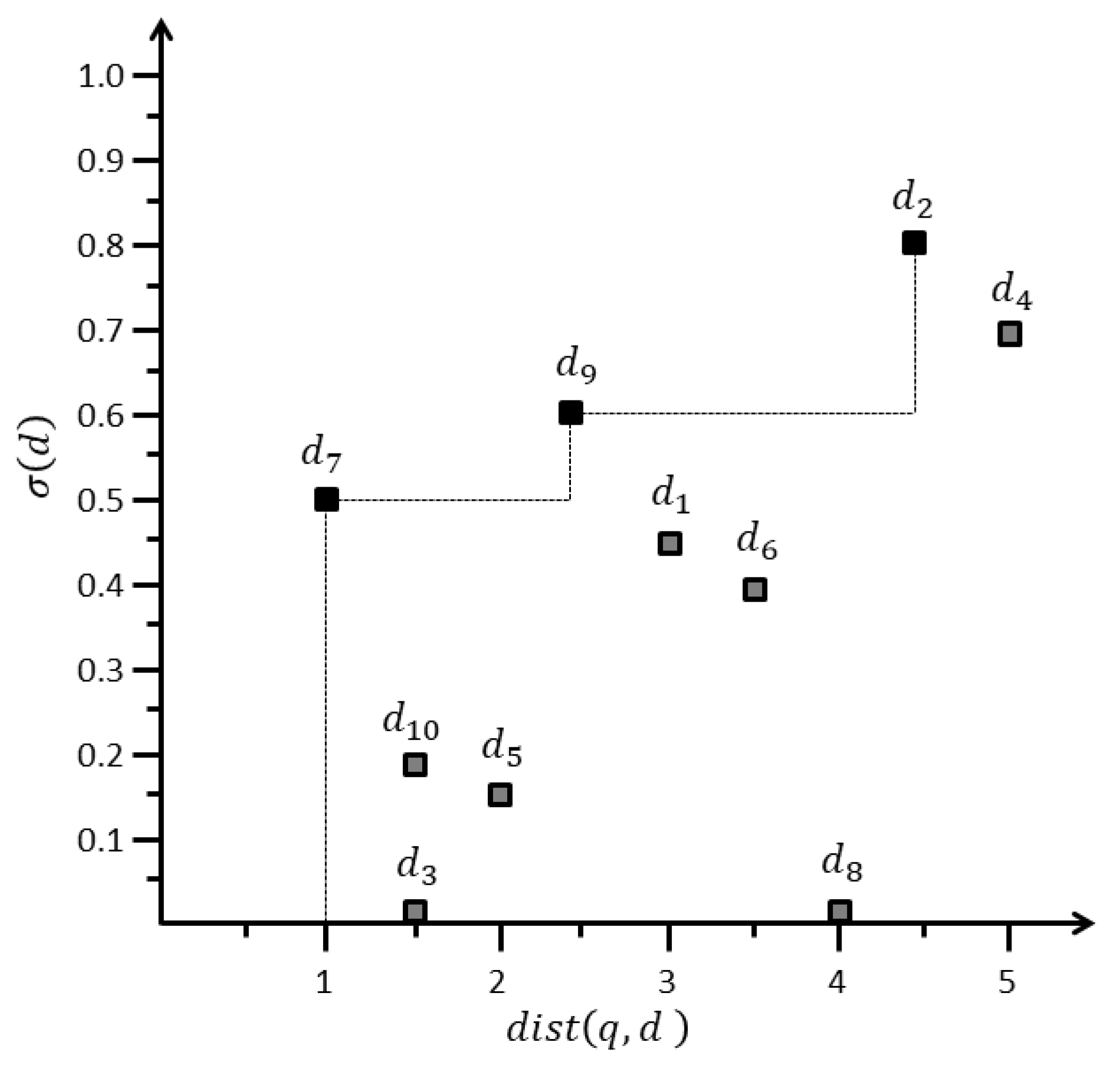
| Data Object | Cscore | |
|---|---|---|
| 3 | 0.45 | |
| 4.5 | 0.8 | |
| 1.5 | 0 | |
| 5 | 0.7 | |
| 2 | 0.15 | |
| 3.5 | 0.4 | |
| 1 | 0.5 | |
| 4 | 0 | |
| 2.5 | 0.6 | |
| 1.5 | 0.2 |
| Attribute | Gowalla | Synthetic |
|---|---|---|
| Total Size | 1.62 GB | 1.87 GB |
| Total data objects | 1,280,956 | 1,500,000 |
| Total users | 196,591 | 150,654 |
| Total friendships | 950,327 | 830,683 |
| Total check-ins | 6,442,890 | 7,364,130 |
| Average fans per data object | 3.4 | 5.8 |
| Total words | 8,198,118 | 11,420,957 |
| Total distinct words | 798,118 | 112,957 |
| Average distinct words per data object | 4.8 | 6.2 |
| Parameter | Values |
|---|---|
| Number of results (k) | 5, 10, 15, 20, 25 |
| Number of keywords (n) | 1, 2, 3, 4, 5 |
| Number of data objects () | 20, 40, 60, 90, 120, 1300, 1500 (x10,000) |
| Range (r) | 20, 40, 60, 80, 100 |
| 0.2, 0.4, 0.6, 0.8, 1.0 | |
| 0.5 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Attique, M.; Afzal, M.; Ali, F.; Mehmood, I.; Ijaz, M.F.; Cho, H.-J. Geo-Social Top-k and Skyline Keyword Queries on Road Networks. Sensors 2020, 20, 798. https://doi.org/10.3390/s20030798
Attique M, Afzal M, Ali F, Mehmood I, Ijaz MF, Cho H-J. Geo-Social Top-k and Skyline Keyword Queries on Road Networks. Sensors. 2020; 20(3):798. https://doi.org/10.3390/s20030798
Chicago/Turabian StyleAttique, Muhammad, Muhammad Afzal, Farman Ali, Irfan Mehmood, Muhammad Fazal Ijaz, and Hyung-Ju Cho. 2020. "Geo-Social Top-k and Skyline Keyword Queries on Road Networks" Sensors 20, no. 3: 798. https://doi.org/10.3390/s20030798
APA StyleAttique, M., Afzal, M., Ali, F., Mehmood, I., Ijaz, M. F., & Cho, H.-J. (2020). Geo-Social Top-k and Skyline Keyword Queries on Road Networks. Sensors, 20(3), 798. https://doi.org/10.3390/s20030798