A Maximum Likelihood Ensemble Filter via a Modified Cholesky Decomposition for Non-Gaussian Data Assimilation

 , , and
, , and
Abstract
:1. Introduction
2. Preliminaries
2.1. Ensemble-Based Data Assimilation
2.2. Line-Search Optimization Methods
- C-A
- A lower bound of exists on , where is available.
- C-B
- There is a constant L such aswhere B is an open convex set which contains . These conditions together with iterates of the formensure global convergence [48] as long as is chosen as an (approximated) minimizer of
3. A Maximum Likelihood Ensemble Filter via a Modified Cholesky Decomposition
3.1. Filter Derivation
3.2. Computational Cost of the MLEF-MC
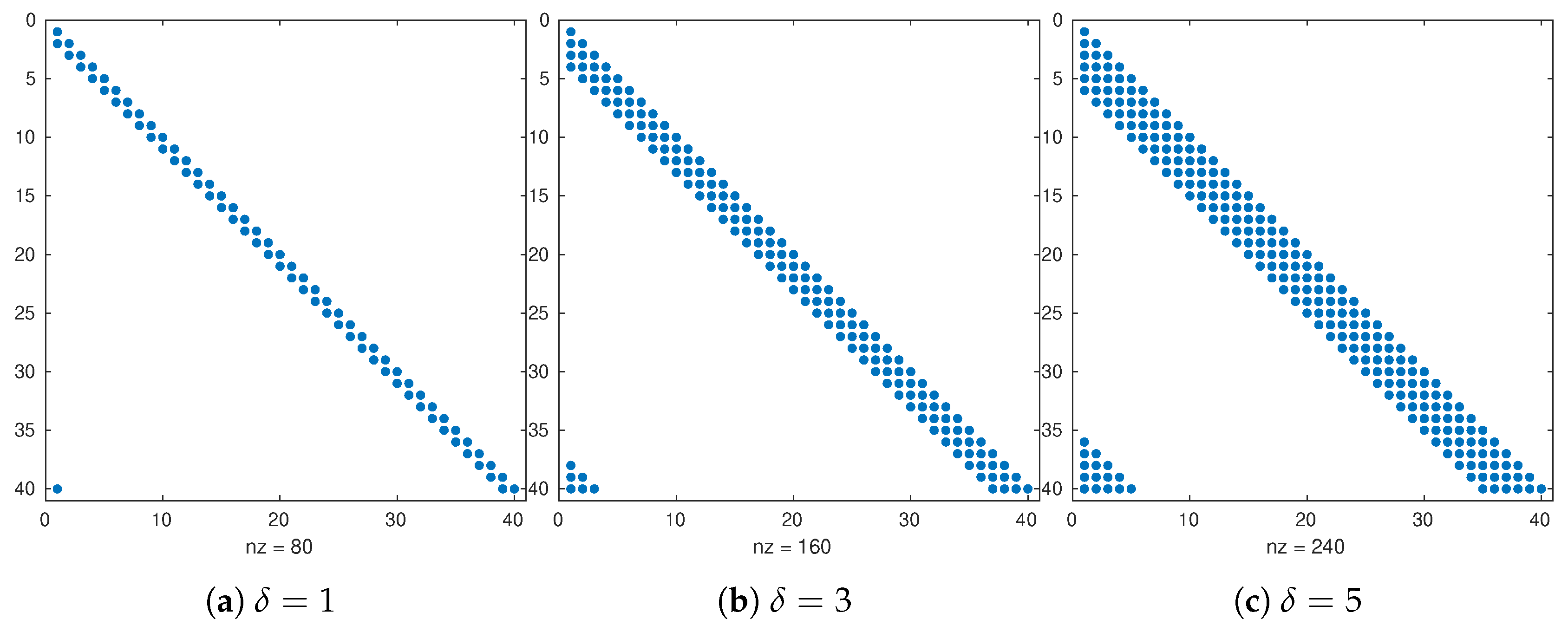
- In Line 1, the direct inversion of matrix is not actually needed. Note that the optimization variable in Equation (17d) can be expressed in terms of a new control variable as follows:and in this manner, we can exploit the special structure of and to perform forward and backward substitutions on the optimal weights . Thus, the number of computations to solve Equation (20) reads where is the maximum number of nonzero entries across all rows in with . is commonly some function of the radius of influence r.
- The computation of in Line 5 can be performed similarly to Equation (20). On the basis of the dimensions of , a bound for computing is as follows: .
- In Line 7, the bounds for computations are as follows:where the implicit linear system involving can be solved, for instance, via the iterative Sherman Morrison formula [53] with no more than computations. Thus, the computational effort of computing Equation (18e) readsThis bound is valid for Lines 9, 12, and 13. Since Lines 12 and 13 are performed N times, their computational cost reads . Since all computations are performed K times, the overall cost of the MLEF-MC is as follows:
| Algorithm 1 Forecasts and Analysis Steps of the MLEF-MC |
|
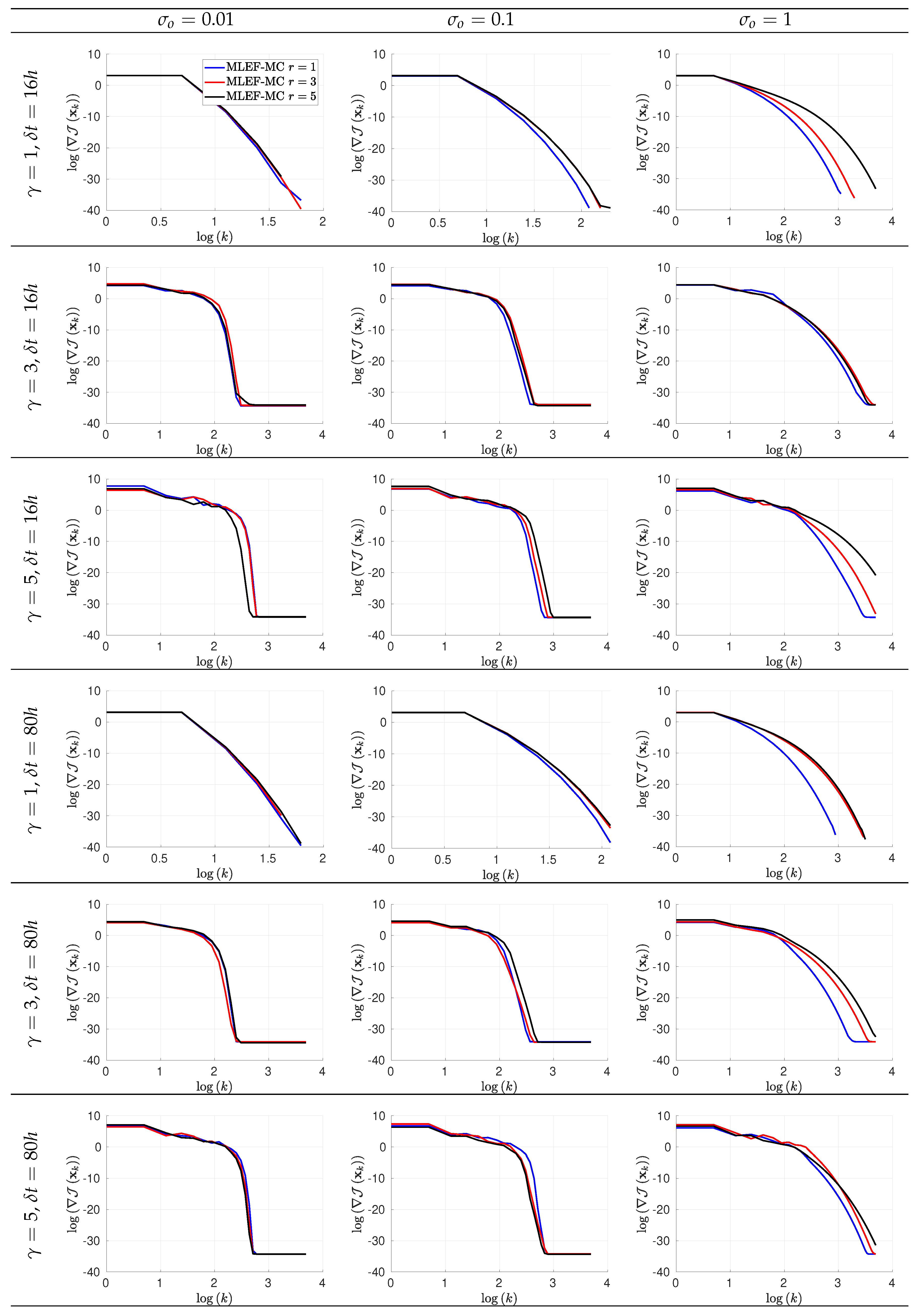
3.3. Global Convergence of the Analysis Step in the MLEF-MC
3.4. Further Comments
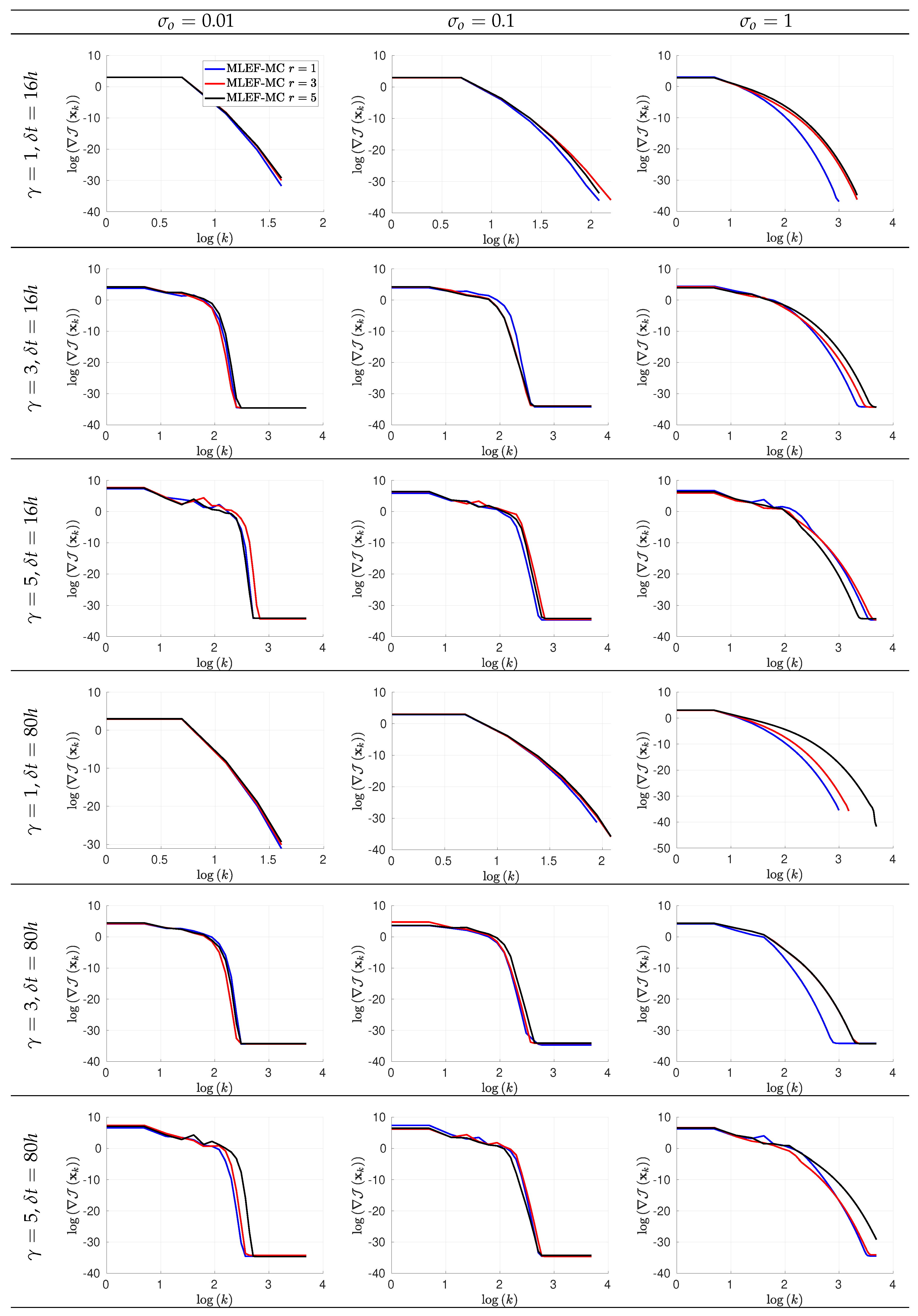
4. Numerical Simulations
- Starting with a random solution, we employ the numerical model to obtain an initial condition which is consistent with the model dynamics. In a similar fashion, the background state, the actual state, and the initial ensemble are computed;
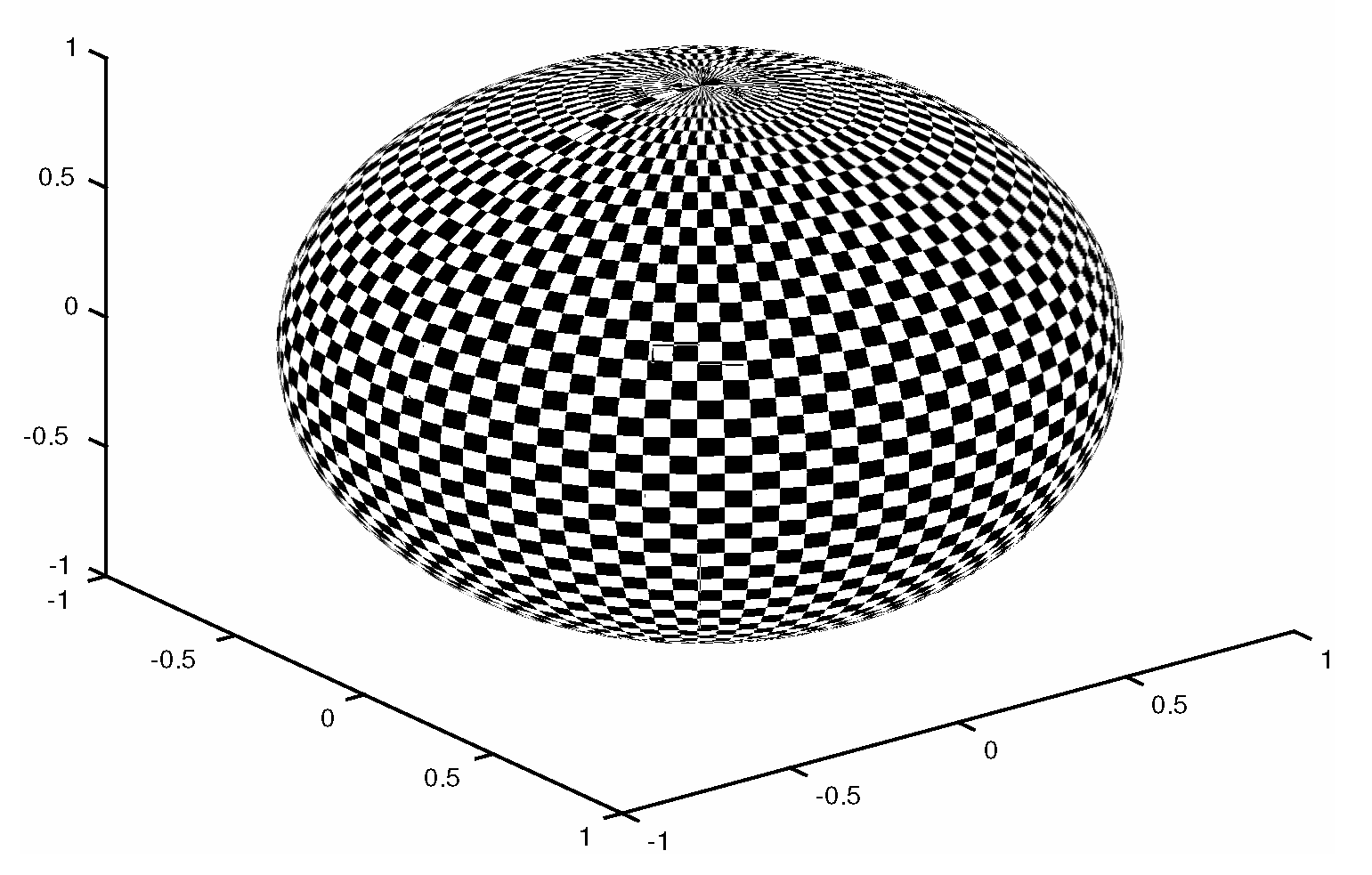
- We consider the following nonlinear observation operator [55]:where j denotes the j-th observed component from the model state, for . Likewise, we vary in . Note that we start with a linear observation operator and end up with a highly nonlinear one. Since this observation operator is nondifferentiable, we employ the sign function to approximate its derivative:
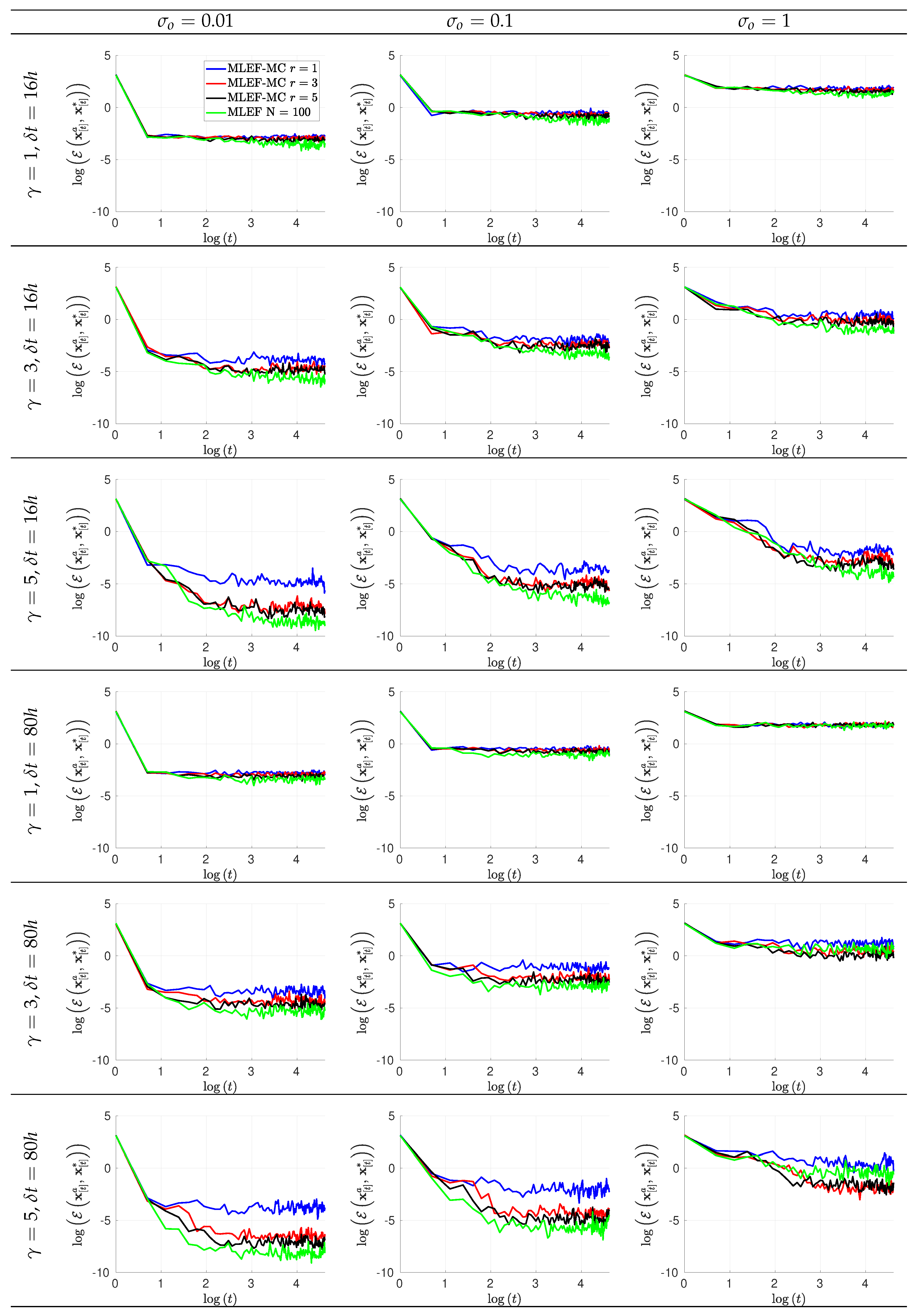
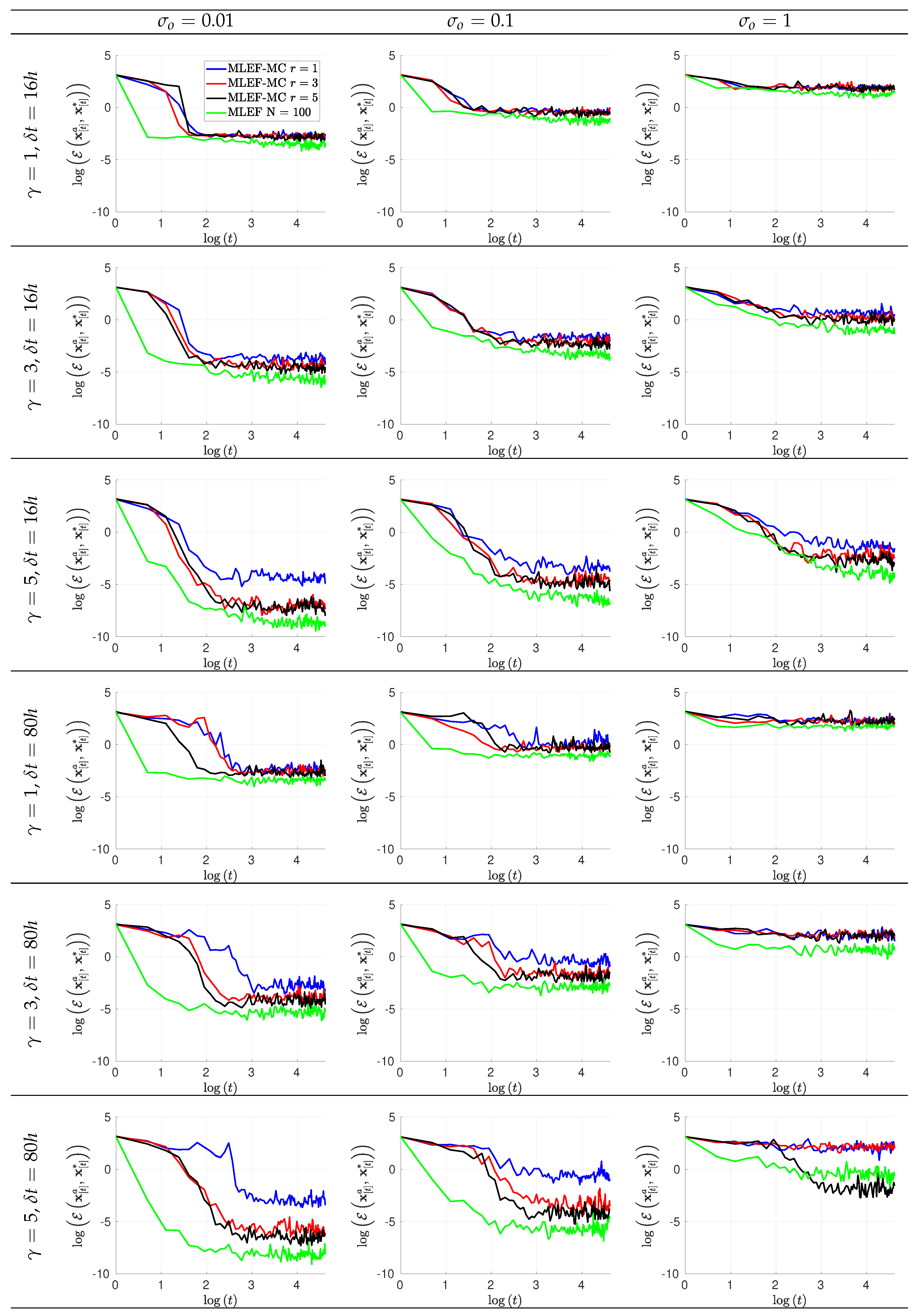
- The norm measures the accuracy of analysis states at assimilation stages,where and are the reference and the analysis solution at the assimilation step t, respectively;
- We employ the Root Mean Square Error (RMSE) as a measure of accuracy (average) for an entire set of time-spaced observations,
- We employ a Truncated Singular Value Decomposition (T-SVD) to fit the models (Equation (9));
- All experiments were performed under perfect model assumptions. No model errors were present during the assimilation steps;
- We employ the MLEF formulation proposed by Zupansky in [23].
4.1. The Lorenz-96 Model
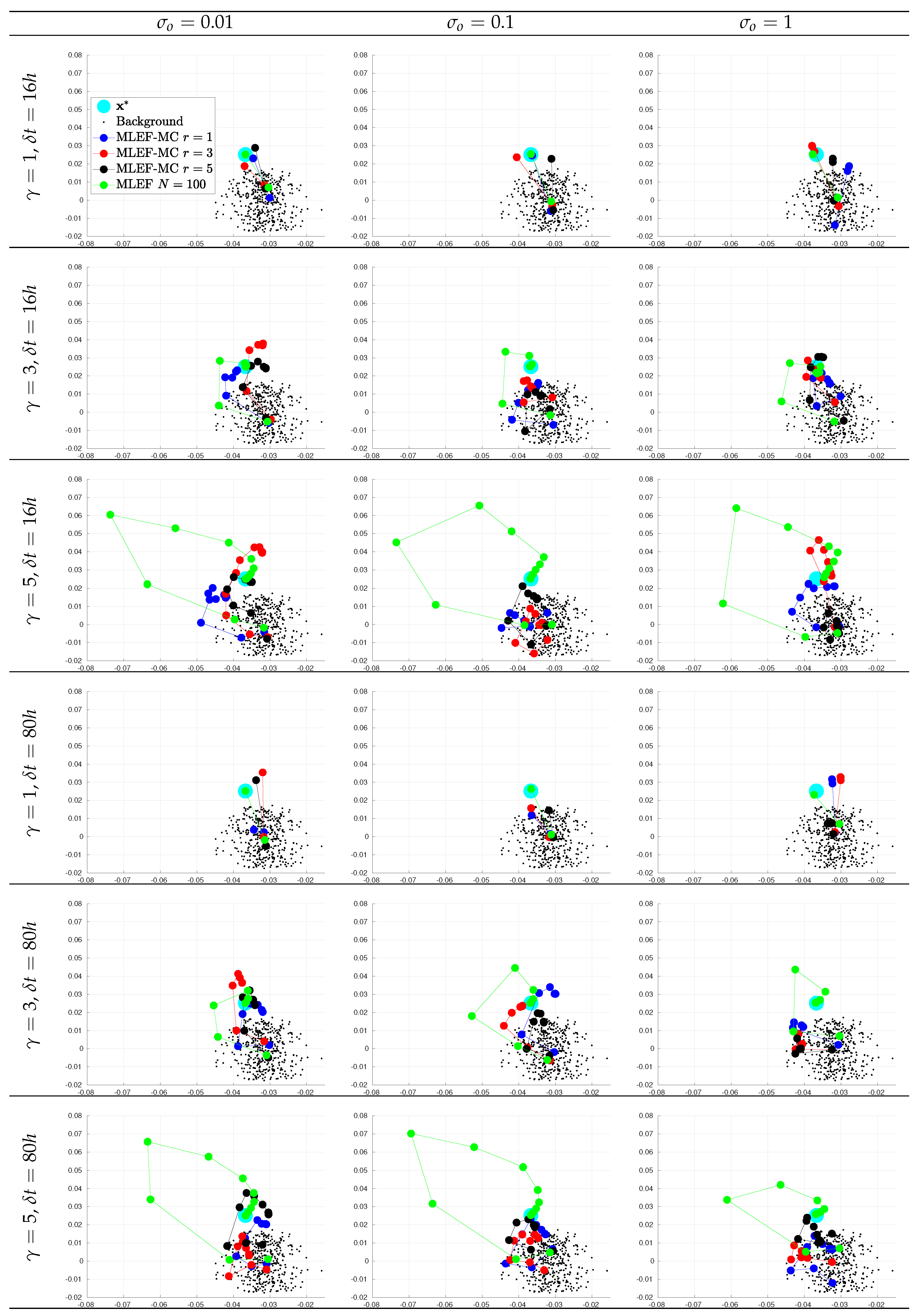
- We create an initial pool of ensemble members. For each experiment, we sample members from to obtain the initial ensemble . Two-dimensional projections of the initial pool making use of its two leading directions are shown in Figure 2;
- The assimilation window consists of time-spaced observations. Two observation frequencies are employed during the experiments: 16 h (time step of 0.1 time units) and 80 h (time step of 0.5 time units). We denote by the time between two subsequent observations;
- At assimilation times, observational errors are characterized by Gaussian distributions with parameterswhere is the actual state of the system, and is the noise level. We tried three different noise levels for the observations ;
- We consider two percentage of observations (s): of model components () and of model components (). The components are randomly chosen at the different assimilation steps;
- The radii of influence to compute control spaces are ranged in ;
- The ensemble size for the MLEF-MC reads ;
- For a reference, we employ a MLEF method with an ensemble size of members and a full observational network . Note that this ensemble size is more than twice the model resolution . In this manner, we can have an idea about how errors should evolve for large ensemble sizes and full observational networks. We refer to this as the ideal case.
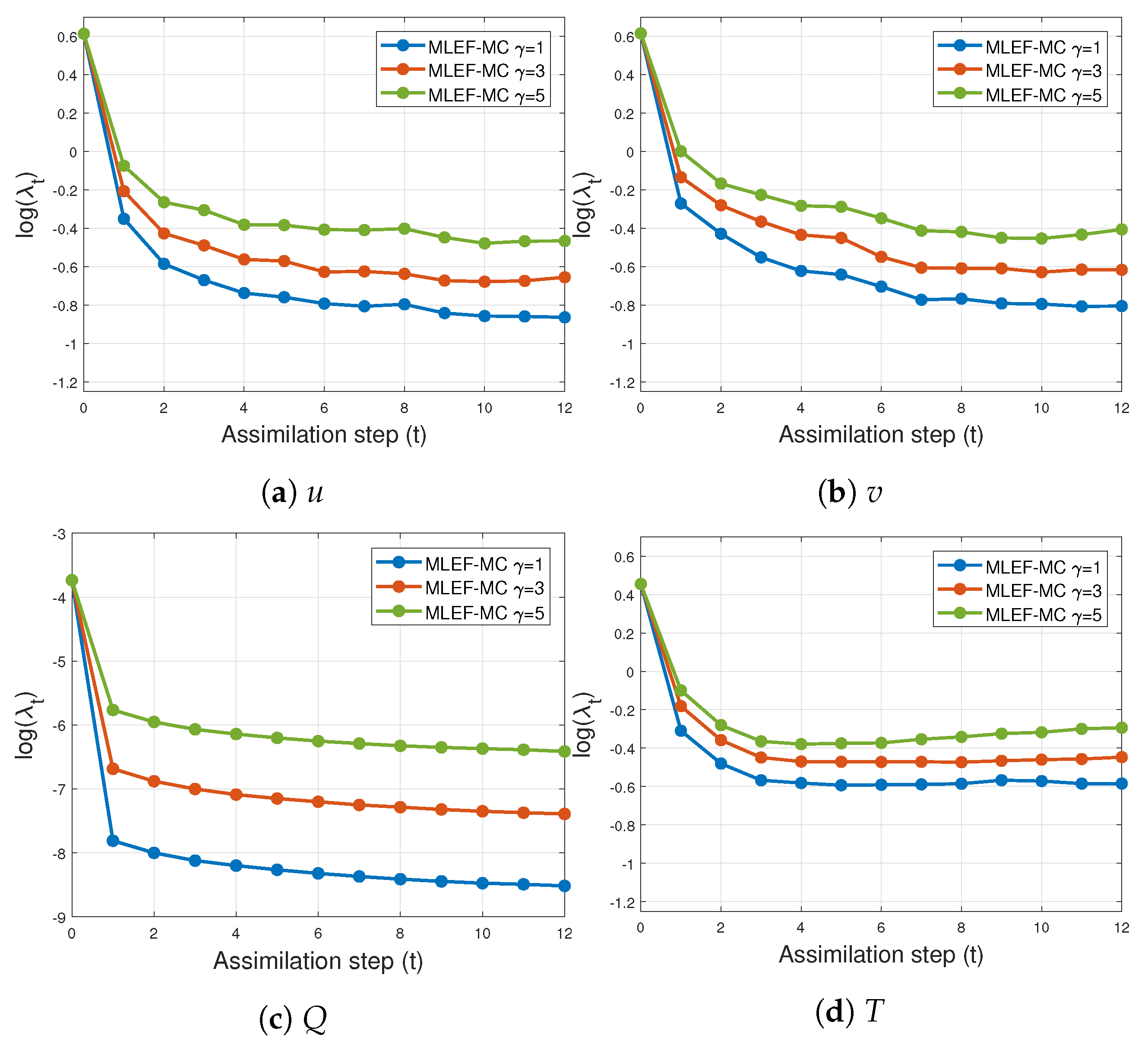
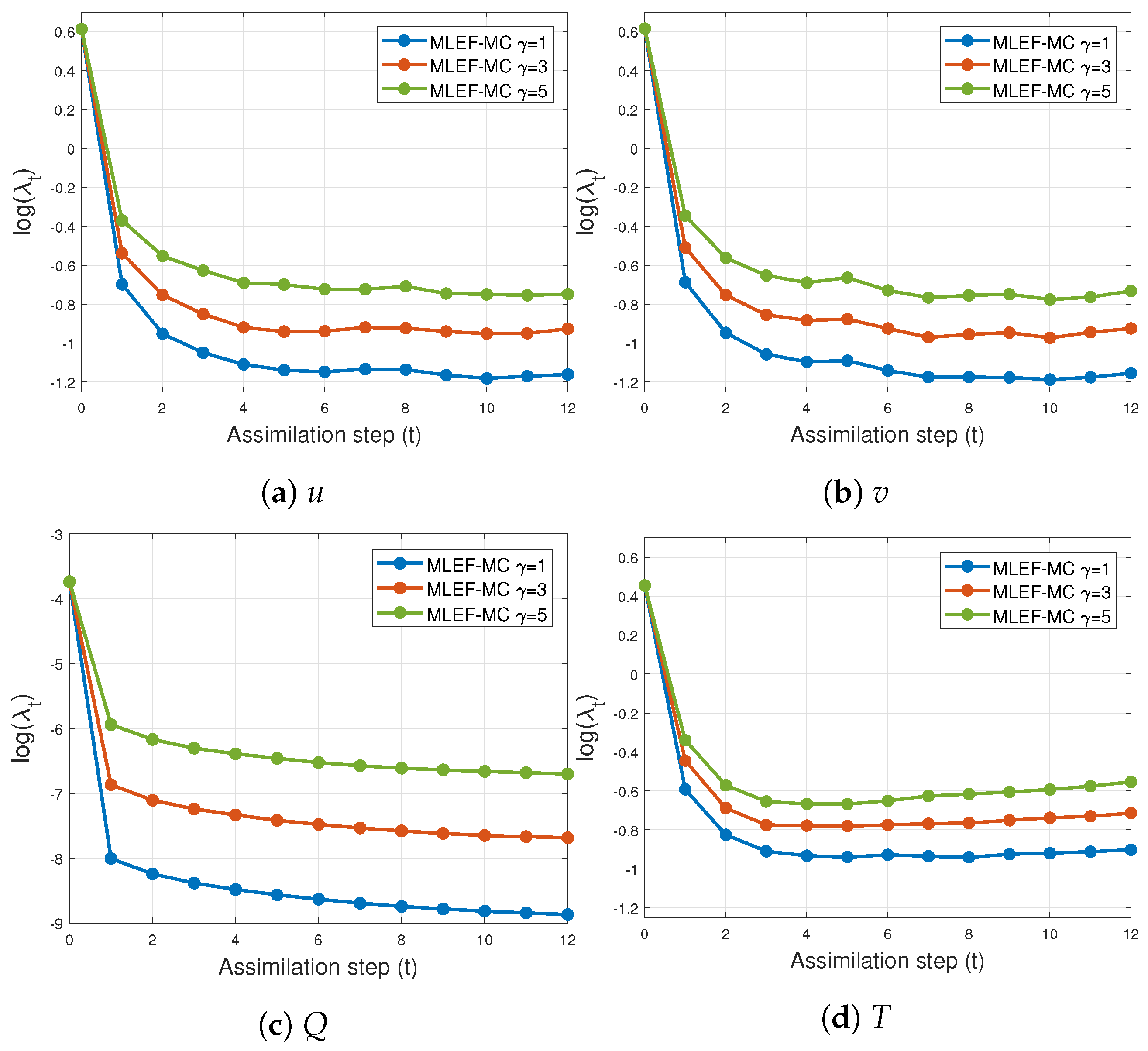
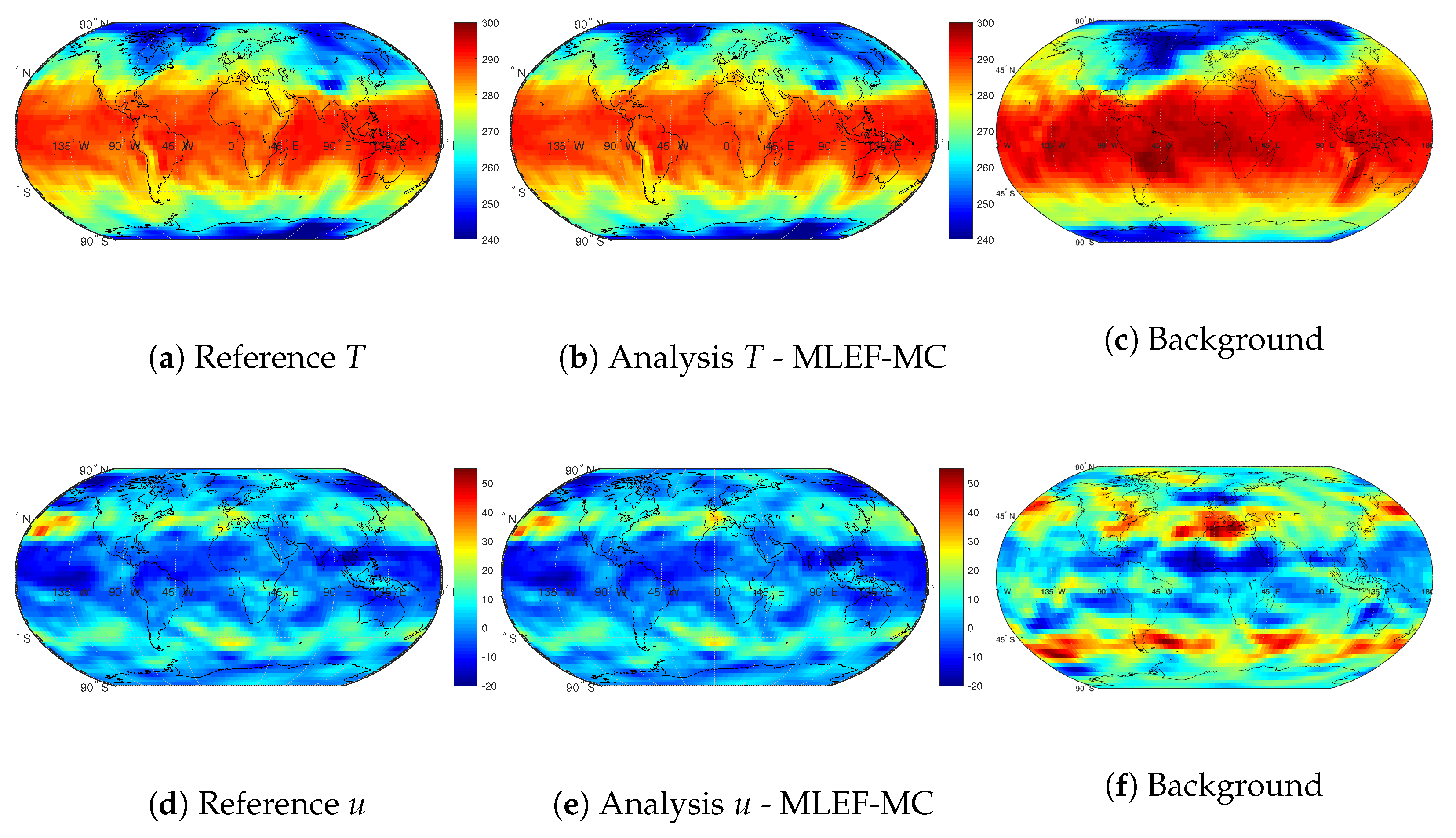
4.2. An Atmospheric General Circulation Model (AT-GCM)
- Starting with a system in equilibrium, the model is integrated over a long time period to obtain an initial condition whose dynamics are consistent with those of the SPEEDY model;
- The initial condition is perturbed N times and propagated over a long time period from which the initial background ensemble is obtained;
- We employ the trajectory of the initial condition as the reference. This reference trajectory serves to build synthetic observations;
- We set the standard deviations of errors in the observations as follows:
- -
- Temperature 1 K;
- -
- Zonal Wind Component 1 m/s;
- -
- Meridional Wind Component 1 m/s;
- -
- Specific Humidity g/kg;
- Two percentages of observations are tried during the experiments: and . Figure 10 shows an example of this operator;
- Observations are available every six hours (6 h);
- The experiments are performed under perfect model assumptions;
- The number of assimilation steps is . Thus, the total simulation time is 7.5 days.
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Asner, G.P.; Warner, A.S. Canopy shadow in IKONOS satellite observations of tropical forests and savannas. Remote Sens. Environ. 2003, 87, 521–533. [Google Scholar] [CrossRef]
- Mayr, S.; Kuenzer, C.; Gessner, U.; Klein, I.; Rutzinger, M. Validation of Earth Observation Time-Series: A Review for Large-Area and Temporally Dense Land Surface Products. Remote Sens. 2019, 11, 2616. [Google Scholar] [CrossRef] [Green Version]
- Jin, X.; Kumar, L.; Li, Z.; Feng, H.; Xu, X.; Yang, G.; Wang, J. A review of data assimilation of remote sensing and crop models. Eur. J. Agron. 2018, 92, 141–152. [Google Scholar] [CrossRef]
- Khaki, M. Data Assimilation and Remote Sensing Data. In Satellite Remote Sensing in Hydrological Data Assimilation; Springer: Basel, Switzerland, 2020; pp. 7–9. [Google Scholar]
- Evensen, G. The Ensemble Kalman Filter: Theoretical formulation and practical implementation. Ocean Dyn. 2003, 53, 343–367. [Google Scholar] [CrossRef]
- Evensen, G. Sequential data assimilation with a nonlinear quasi-geostrophic model using Monte Carlo methods to forecast error statistics. J. Geophys. Res. Oceans 1994, 99, 10143–10162. [Google Scholar] [CrossRef]
- Nino-Ruiz, E.D.; Sandu, A. Ensemble Kalman filter implementations based on shrinkage covariance matrix estimation. Ocean Dyn. 2015, 65, 1423–1439. [Google Scholar] [CrossRef] [Green Version]
- Nino-Ruiz, E.D.; Sandu, A.; Deng, X. An Ensemble Kalman Filter Implementation Based on Modified Cholesky Decomposition for Inverse Covariance Matrix Estimation. SIAM J. Sci. Comput. 2018, 40, A867–A886. [Google Scholar] [CrossRef]
- Bishop, C.H.; Etherton, B.J.; Majumdar, S.J. Adaptive sampling with the ensemble transform Kalman filter. Part I: Theoretical aspects. Mon. Weather Rev. 2001, 129, 420–436. [Google Scholar] [CrossRef]
- Hunt, B.R.; Kostelich, E.J.; Szunyogh, I. Efficient data assimilation for spatiotemporal chaos: A local ensemble transform Kalman filter. Physica D 2007, 230, 112–126. [Google Scholar]
- Petrie, R.E. Localization in the Ensemble Kalman Filter. Master’s Thesis, University of Reading, Reading, UK, August 2008. [Google Scholar]
- Hamill, T.M.; Whitaker, J.S.; Snyder, C. Distance-Dependent Filtering of Background Error Covariance Estimates in an Ensemble Kalman Filter. Mon. Weather Rev. 2001, 129, 2776–2790. [Google Scholar] [CrossRef] [Green Version]
- Nino-Ruiz, E.D.; Sandu, A.; Deng, X. A parallel ensemble Kalman filter implementation based on modified Cholesky decomposition. In Proceedings of the 6th Workshop on Latest Advances in Scalable Algorithms for Large-Scale Systems, Austin, TX, USA, 15–20 November 2015; pp. 1–8. [Google Scholar]
- Nino-Ruiz, E.D.; Sandu, A.; Deng, X. A parallel implementation of the ensemble Kalman filter based on modified Cholesky decomposition. J. Comput. Sci. 2019, 36, 100654. [Google Scholar]
- Nino-Ruiz, E. A matrix-free posterior ensemble kalman filter implementation based on a modified cholesky decomposition. Atmosphere 2017, 8, 125. [Google Scholar]
- Bickel, P.J.; Levina, E. Regularized estimation of large covariance matrices. Ann. Stat. 2008, 36, 199–227. [Google Scholar] [CrossRef]
- Dellaportas, P.; Pourahmadi, M. Cholesky-GARCH models with applications to finance. Stat. Comput. 2012, 22, 849–855. [Google Scholar] [CrossRef]
- Rajaratnam, B.; Salzman, J. Best permutation analysis. J. Multivar. Anal. 2013, 121, 193–223. [Google Scholar]
- Kang, X.; Deng, X.; Tsui, K.W.; Pourahmadi, M. On variable ordination of modified Cholesky decomposition for estimating time-varying covariance matrices. Int. Stat. Rev. 2019, 1, 1–26. [Google Scholar]
- Zheng, H.; Tsui, K.W.; Kang, X.; Deng, X. Cholesky-based model averaging for covariance matrix estimation. Stat. Theor. Relat. Fields 2017, 1, 48–58. [Google Scholar] [CrossRef]
- Bertino, L.; Evensen, G.; Wackernagel, H. Sequential Data Assimilation Techniques in Oceanography. Int. Stat. Rev. 2007, 71, 223–241. [Google Scholar] [CrossRef]
- Zupanski, M.; Navon, I.M.; Zupanski, D. The Maximum Likelihood Ensemble Filter as a non-differentiable minimization algorithm. Q. J. R. Meteorol. Soc. 2008, 134, 1039–1050. [Google Scholar] [CrossRef] [Green Version]
- Zupanski, M. Maximum Likelihood Ensemble Filter: Theoretical Aspects. Mon. Weather Rev. 2005, 133, 1710–1726. [Google Scholar] [CrossRef]
- Fletcher, S.J.; Zupanski, M. A study of ensemble size and shallow water dynamics with the Maximum Likelihood Ensemble Filter. Tellus A 2008, 60, 348–360. [Google Scholar] [CrossRef]
- Carrassi, A.; Vannitsem, S.; Zupanski, D.; Zupanski, M. The maximum likelihood ensemble filter performances in chaotic systems. Tellus A 2009, 61, 587–600. [Google Scholar] [CrossRef] [Green Version]
- Tran, A.P.; Vanclooster, M.; Zupanski, M.; Lambot, S. Joint estimation of soil moisture profile and hydraulic parameters by ground-penetrating radar data assimilation with maximum likelihood ensemble filter. Water Resour. Res. 2014, 50, 3131–3146. [Google Scholar] [CrossRef]
- Zupanski, D.; Zupanski, M. Model Error Estimation Employing an Ensemble Data Assimilation Approach. Mon. Weather Rev. 2006, 134, 1337–1354. [Google Scholar] [CrossRef] [Green Version]
- Vanderplaats, G.N. Numerical Optimization Techniques for Engineering Design: With Applications; McGraw-Hill: New York, NY, USA, 1984; Volume 1. [Google Scholar]
- Wright, S.; Nocedal, J. Numerical optimization; Springer Science: Berlin, Germany, 1999; Volume 35, p. 7. [Google Scholar]
- Savard, G.; Gauvin, J. The steepest descent direction for the nonlinear bilevel programming problem. Oper. Res. Lett. 1994, 15, 265–272. [Google Scholar] [CrossRef]
- Hager, W.W.; Zhang, H. A survey of nonlinear conjugate gradient methods. Pac. J. Optim. 2006, 2, 35–58. [Google Scholar]
- Fletcher, R.; Reeves, C.M. Function minimization by conjugate gradients. Comput. J. 1964, 7, 149–154. [Google Scholar] [CrossRef] [Green Version]
- Lewis, R.M.; Torczon, V.; Trosset, M.W. Direct search methods: Then and now. J. Comput. Appl. Math. 2000, 124, 191–207. [Google Scholar] [CrossRef] [Green Version]
- Battiti, R. First-and second-order methods for learning: Between steepest descent and Newton’s method. Neural Comput. 1992, 4, 141–166. [Google Scholar] [CrossRef]
- Grippo, L.; Lampariello, F.; Lucidi, S. A truncated Newton method with nonmonotone line search for unconstrained optimization. J. Optim. Theory Appl. 1989, 60, 401–419. [Google Scholar] [CrossRef]
- Pan, V.Y.; Branham, S.; Rosholt, R.E.; Zheng, A.L. Newton’s iteration for structured matrices. In Fast Reliable Algorithms for Matrices with Structure; SIAM: Philadelphia, PA, USA, 1999; pp. 189–210. [Google Scholar]
- Shanno, D.F. Conditioning of quasi-Newton methods for function minimization. Math. Comput. 1970, 24, 647–656. [Google Scholar] [CrossRef]
- Nocedal, J. Updating quasi-Newton matrices with limited storage. Math. Comput. 1980, 35, 773–782. [Google Scholar] [CrossRef]
- Loke, M.H.; Barker, R. Rapid least-squares inversion of apparent resistivity pseudosections by a quasi-Newton method. Geophys. Prospect. 1996, 44, 131–152. [Google Scholar] [CrossRef]
- Knoll, D.A.; Keyes, D.E. Jacobian-free Newton–Krylov methods: A survey of approaches and applications. J. Comput. Phys. 2004, 193, 357–397. [Google Scholar] [CrossRef] [Green Version]
- Grippo, L.; Lampariello, F.; Lucidi, S. A nonmonotone line search technique for Newton’s method. SIAM J. Numer. Anal. 1986, 23, 707–716. [Google Scholar] [CrossRef]
- Uschmajew, A.; Vandereycken, B. Line-search methods and rank increase on low-rank matrix varieties. In Proceedings of the 2014 International Symposium on Nonlinear Theory and Its Applications (NOLTA2014), Luzern, Switzerland, 14–18 September 2014; pp. 52–55. [Google Scholar]
- Hosseini, S.; Huang, W.; Yousefpour, R. Line search algorithms for locally Lipschitz functions on Riemannian manifolds. SIAM J. Optim. 2018, 28, 596–619. [Google Scholar] [CrossRef] [Green Version]
- Conn, A.R.; Gould, N.I.; Toint, P.L. Trust Region Methods; SIAM: Philadelphia, PA, USA, 2000; Volume 1. [Google Scholar]
- Moré, J.J.; Sorensen, D.C. Computing a trust region step. SIAM J. Sci. Comput. 1983, 4, 553–572. [Google Scholar] [CrossRef] [Green Version]
- Curtis, F.E.; Robinson, D.P.; Samadi, M. A trust region algorithm with a worst-case iteration complexity of (ϵ−3/2) for nonconvex optimization. Math. Program. 2017, 162, 1–32. [Google Scholar] [CrossRef]
- Shi, Z.J. Convergence of line search methods for unconstrained optimization. Appl. Math. Comput. 2004, 157, 393–405. [Google Scholar] [CrossRef]
- Zhou, W.; Akrotirianakis, I.; Yektamaram, S.; Griffin, J. A matrix-free line-search algorithm for nonconvex optimization. Optim. Methods Softw. 2017, 34, 1–24. [Google Scholar] [CrossRef]
- Dunn, J.C. Newton’s method and the Goldstein step-length rule for constrained minimization problems. SIAM J. Control Optim. 1980, 18, 659–674. [Google Scholar] [CrossRef]
- Dai, Y.H.; Yuan, Y. A nonlinear conjugate gradient method with a strong global convergence property. SIAM J. Optim. 1999, 10, 177–182. [Google Scholar] [CrossRef] [Green Version]
- Ravindran, A.; Reklaitis, G.V.; Ragsdell, K.M. Engineering Optimization: Methods and Applications; John Wiley & Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- Attia, A.; Moosavi, A.; Sandu, A. Cluster sampling filters for non-Gaussian data assimilation. Atmosphere 2018, 9, 213. [Google Scholar] [CrossRef] [Green Version]
- Nino-Ruiz, E.D.; Sandu, A.; Anderson, J. An efficient implementation of the ensemble Kalman filter based on an iterative Sherman–Morrison formula. Stat. Comput. 2015, 25, 561–577. [Google Scholar] [CrossRef] [Green Version]
- Lorenz, E.N. Designing Chaotic Models. J. Atmos. Sci. 2005, 62, 1574–1587. [Google Scholar] [CrossRef]
- Van Leeuwen, P.J. Nonlinear data assimilation in geosciences: An extremely efficient particle filter. Q. J. R. Meteorol. Soc. 2010, 136, 1991–1999. [Google Scholar] [CrossRef] [Green Version]
- Gottwald, G.A.; Melbourne, I. Testing for chaos in deterministic systems with noise. Physica D 2005, 212, 100–110. [Google Scholar] [CrossRef] [Green Version]
- Karimi, A.; Paul, M. Extensive Chaos in the Lorenz-96 Model. Chaos 2010, 20, 043105. [Google Scholar] [CrossRef] [Green Version]
- Bracco, A.; Kucharski, F.; Kallummal, R.; Molteni, F. Internal variability, external forcing and climate trends in multi-decadal AGCM ensembles. Clim. Dyn. 2004, 23, 659–678. [Google Scholar] [CrossRef]
- Miyoshi, T. The Gaussian approach to adaptive covariance inflation and its implementation with the local ensemble transform Kalman filter. Mon. Weather Rev. 2011, 139, 1519–1535. [Google Scholar] [CrossRef]
- Molteni, F. Atmospheric simulations using a GCM with simplified physical parametrizations. I: Model climatology and variability in multi-decadal experiments. Clim. Dyn. 2003, 20, 175–191. [Google Scholar] [CrossRef]
- Kucharski, F.; Molteni, F.; Bracco, A. Decadal interactions between the western tropical Pacific and the North Atlantic Oscillation. Clim. Dyn. 2006, 26, 79–91. [Google Scholar] [CrossRef]
- Miyoshi, T.; Kondo, K.; Imamura, T. The 10,240-member ensemble Kalman filtering with an intermediate AGCM. Geophys. Res. Lett. 2014, 41, 5264–5271. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Notation | Units | Number of Layers |
|---|---|---|---|
| Temperature | T | K | 7 |
| Zonal Wind Component | u | m/s | 7 |
| Meridional Wind Component | v | m/s | 7 |
| Specific Humidity | Q | g/kg | 7 |
| Variable | NODA | s = 0.7 | s = 1 | ||||
|---|---|---|---|---|---|---|---|
| u (m/s) | 0.6315 | 0.7113 | 0.7990 | 0.4703 | 0.5447 | 0.6232 | |
| v (m/s) | 0.5974 | 0.6742 | 0.7717 | 0.4708 | 0.5436 | 0.6266 | |
| T (K) | 0.6828 | 0.7416 | 0.8029 | 0.5402 | 0.6048 | 0.6629 | |
| Q (g/kg) | 0.0032 | 0.0070 | 0.0135 | 0.0026 | 0.0058 | 0.0113 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nino-Ruiz, E.D.; Mancilla-Herrera, A.; Lopez-Restrepo, S.; Quintero-Montoya, O. A Maximum Likelihood Ensemble Filter via a Modified Cholesky Decomposition for Non-Gaussian Data Assimilation. Sensors 2020, 20, 877. https://doi.org/10.3390/s20030877
Nino-Ruiz ED, Mancilla-Herrera A, Lopez-Restrepo S, Quintero-Montoya O. A Maximum Likelihood Ensemble Filter via a Modified Cholesky Decomposition for Non-Gaussian Data Assimilation. Sensors. 2020; 20(3):877. https://doi.org/10.3390/s20030877
Chicago/Turabian StyleNino-Ruiz, Elias David, Alfonso Mancilla-Herrera, Santiago Lopez-Restrepo, and Olga Quintero-Montoya. 2020. "A Maximum Likelihood Ensemble Filter via a Modified Cholesky Decomposition for Non-Gaussian Data Assimilation" Sensors 20, no. 3: 877. https://doi.org/10.3390/s20030877