Automatic Distortion Rectification of Wide-Angle Images Using Outlier Refinement for Streamlining Vision Tasks




Abstract
1. Introduction
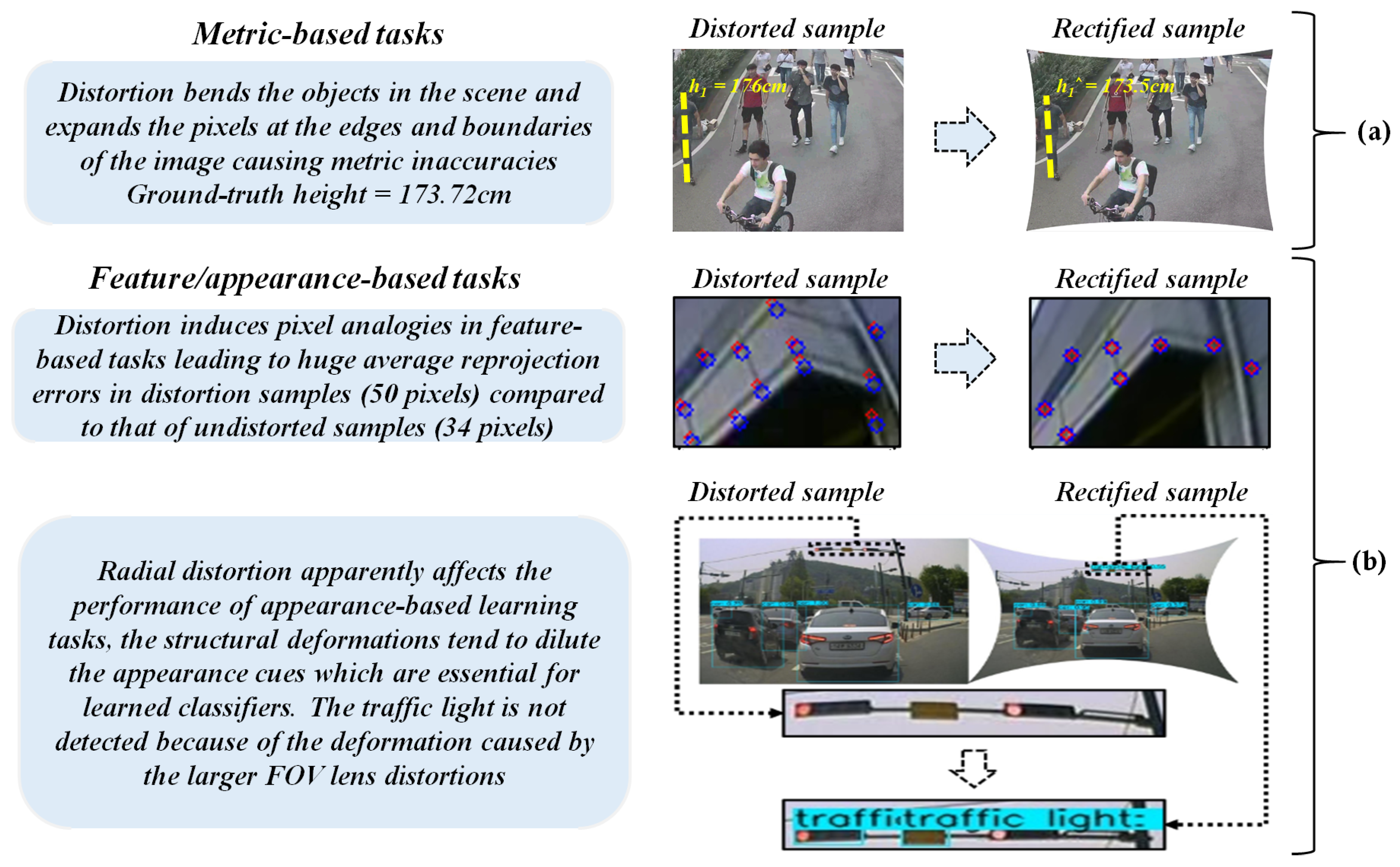
1.1. Challenges
1.2. Purpose of Study
2. Literature Review
2.1. Automatic Distortion Rectification
2.2. Previous Works
- The segregation of robust line candidates was done on the basis of threshold heuristics in the previous work [19], which made some outliers raise some complications while dealing with heavy distortions FOV > 165, thereby creating a need for model-specific residual factors.
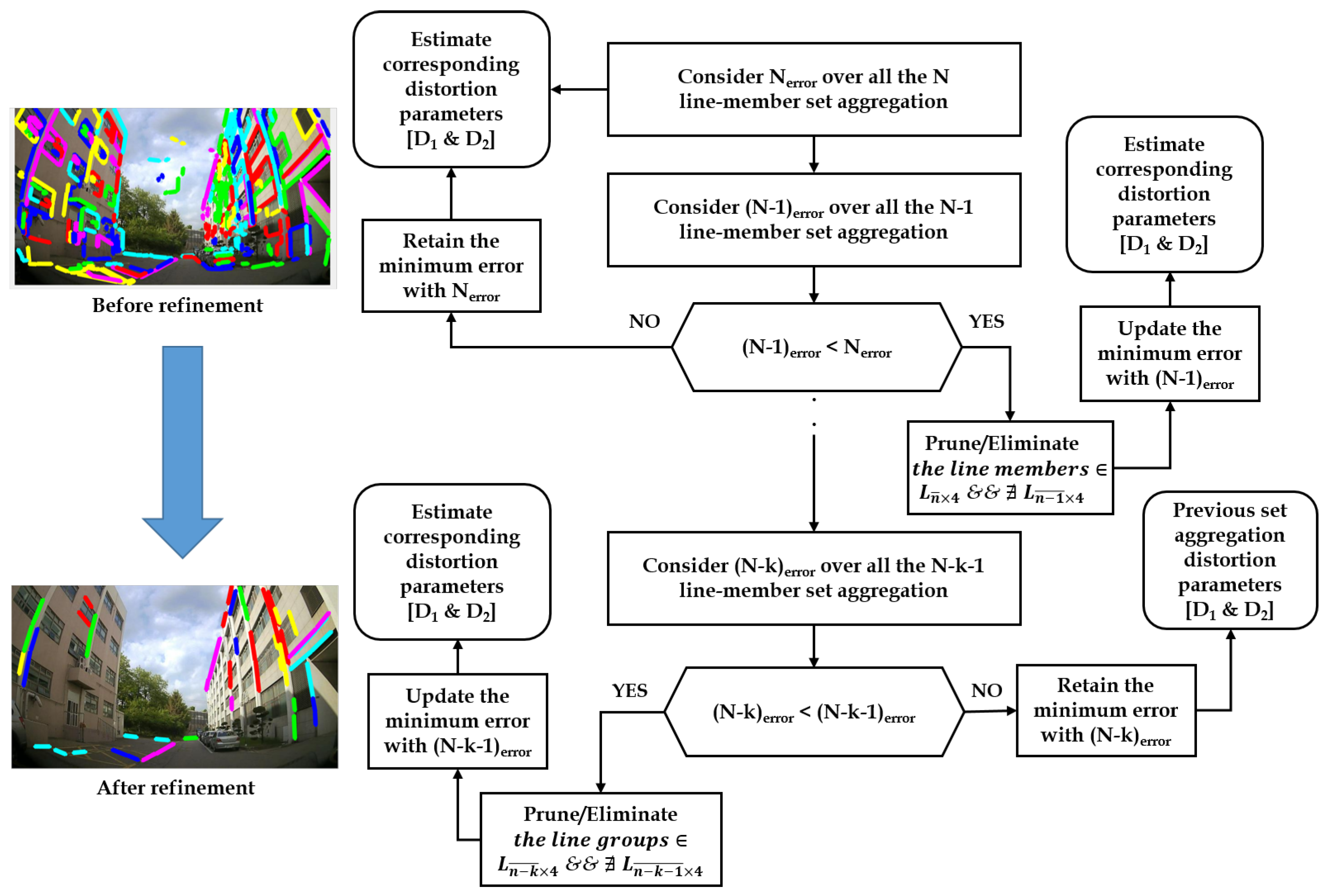
- Unlike [19], the current study employs an iterative outlier refinement scheme which basically considers the aggregation of robust line members into a set and iterating the sets over the plumbline angular loss constraint. The loss over the cumulative line-member sets and corresponding estimated distortion parameters are used to eliminate the outliers, thereby using the new set of robust line candidates to update parameters for distortion rectification.
- The current plumbline angular loss constraint with respect to optimization scheme is analogous to that of [19], but the optimization is altered to consider the loss over the cumulative line-member sets to estimate the distortion parameters with simultaneous outlier elimination.
3. Outlier-Refinement-Enabled Distortion Estimation
3.1. Lens Distortion Parameter Modeling
3.2. Plumbline Angular Loss Estimation
- By minimizing error and refining the accumulated line-member set such that the unwanted curves and outliers in the image can be pruned.
- Additionally, through minimizing the error equation, we can estimate the distortion parameter.
3.3. Refinement Optimization Scheme
4. Ablation Study
Practical Significance Analysis
- Quantitative: Investigation of proposed cumulative set aggregation loss and refinement scheme with respect to image quality, edge stretching, pixel-point error, and processing time on distorted KITTI dataset and distortion center benchmark.
- Qualitative: Investigation of proposed cumulative set aggregation loss and refinement scheme with respect to real-time adaptability and feasible undistortion on severe distortions (FOV: 140 and 165) with respect to private CV Lab Larger FOV real dataset.
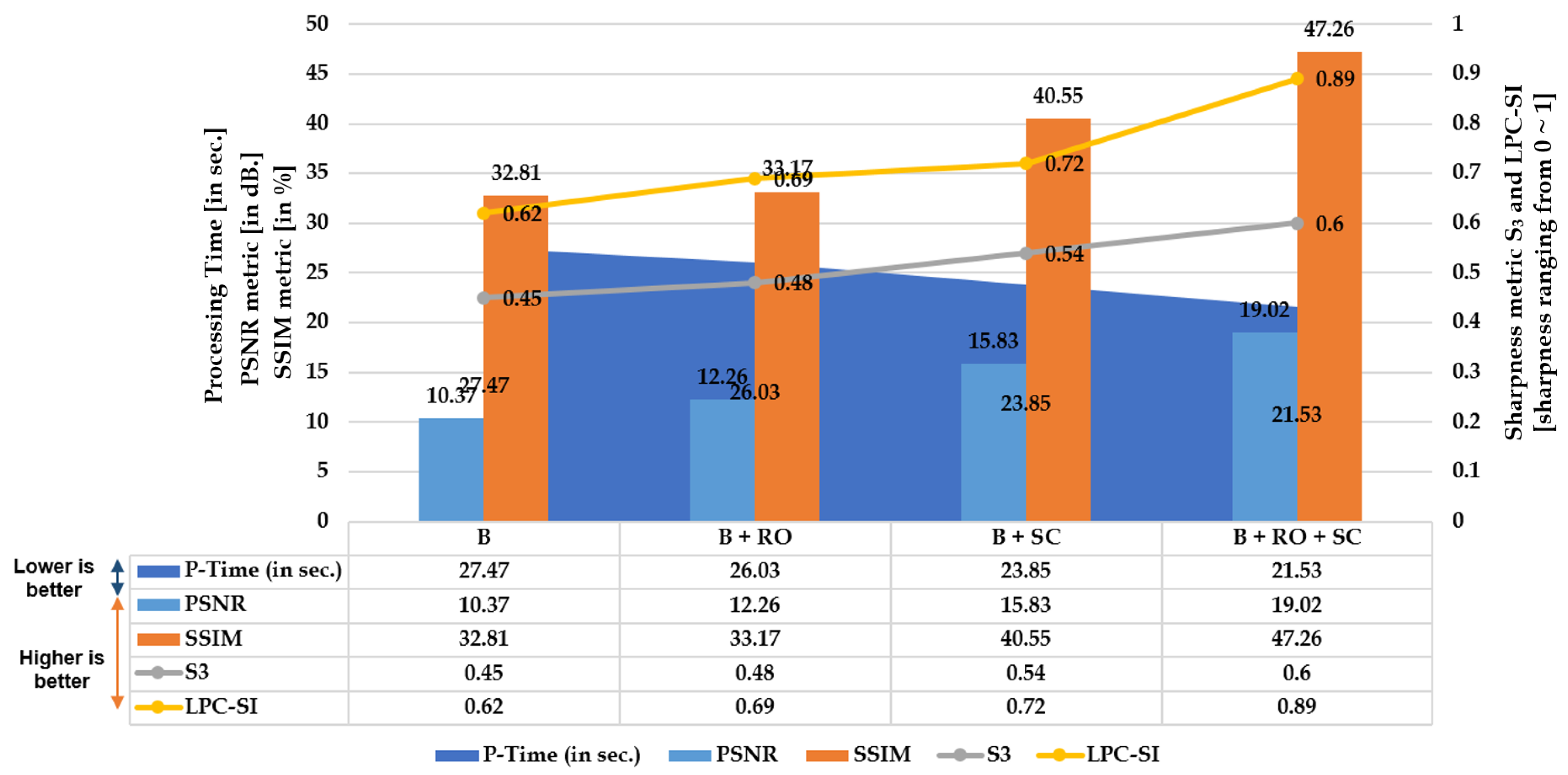
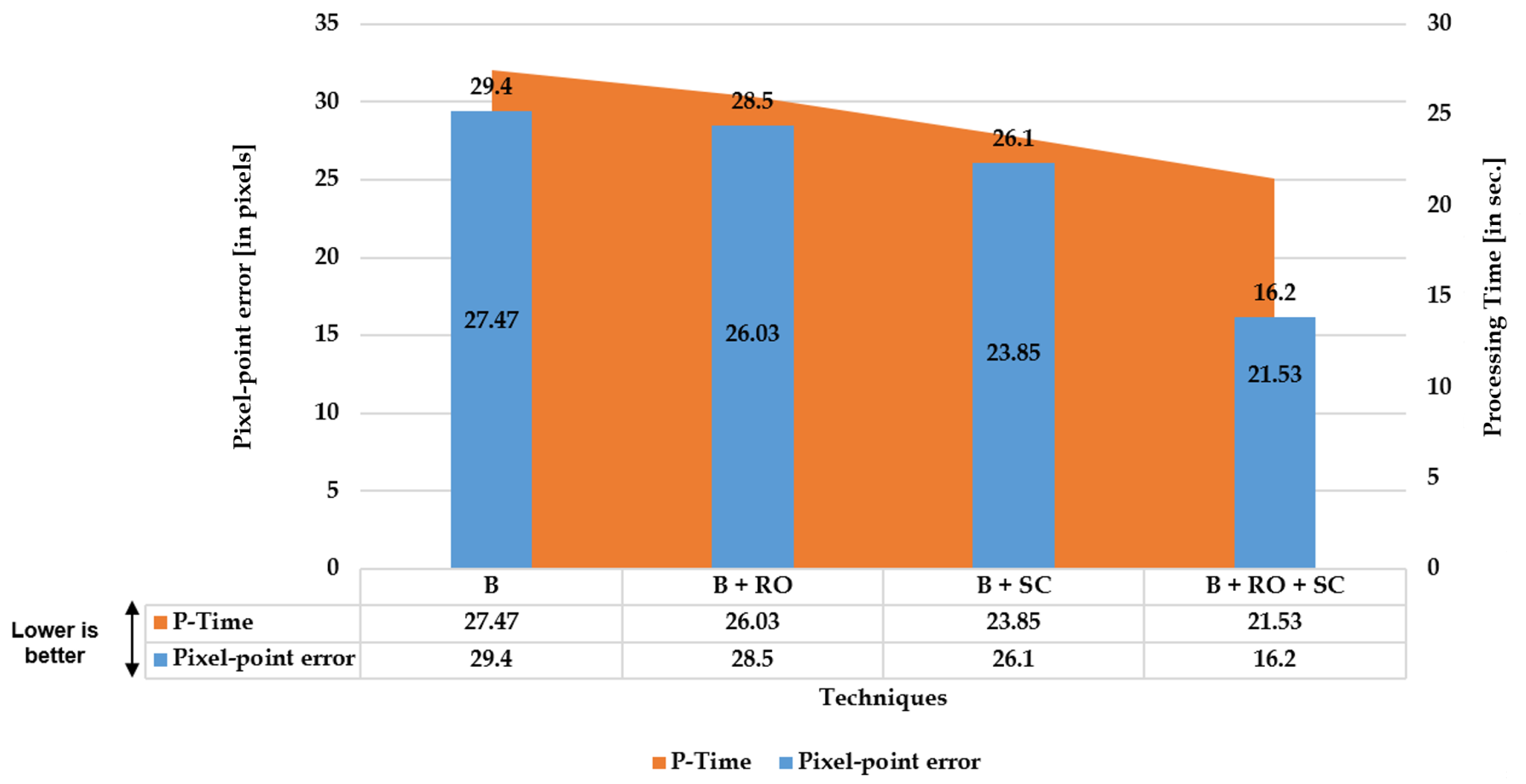
- B: Uses the basic straightness loss constraint between line members (without outlier refinement) to estimate distortion parameters.
- B + RO: Uses the basic straightness loss constraint between line members (with outlier refinement) to estimate distortion parameters.
- B + SC: Uses the basic straightness loss constraint over set cumulative line-member sets (without outlier refinement) to estimate distortion parameters.
- B + SC + RO: Uses the basic straightness loss constraint over set cumulative line-member sets (with outlier refinement) to estimate distortion parameters.
5. Experiments and Evaluations
5.1. Pixel Quality and Consistency Experiments
5.1.1. Image Quality Evaluations
- Peak Signal-to-Noise Ratio (PSNR): The pixel consistency of the output (undistorted image) with respect to the original distortion-free image can be assessed using PSNR value. The mathematical measure is directly proportional to the quality of the output, i.e., if the PSNR value is high, the signal information in the output image corresponding to that of the distortion-free image is high and vice versa.
- Structural Similarity Index (SSIM): SSIM is one of the most prominent metrics, which is analogous to human visual perception. The fundamental blocks in the estimation of SSIM are luminance (L), contrast (C), and structural difference (S), which are calculated using the combinations of mean, standard deviation, and covariance [28].
- Spectral spatial sharpness (): The metric was proposed by [29] and is best suited to examine the sharpness of an image without the reference ground truth. This metric can be retrieved from the pixel properties of the image in terms of spectral and spatial attributes. First, the color image is converted to grayscale and then and are extracted from the grayscale image. The metric represents the spectral sharpness map which is the local magnitude spectrum slope; and the metric represents the spatial sharpness map which is the local total variation. The geometric mean of these and is termed as final sharpness map , which is the overall perceived sharpness of the entire image.
- Local phase coherence sharpness index (LPC-SI): This metric was introduced by [30] to evaluate the sharpness of an image from a different perspective rather than using edge, gradient, and frequency content. This sharpness metric quantifies the sharpness of an image with strong local phase coherence.
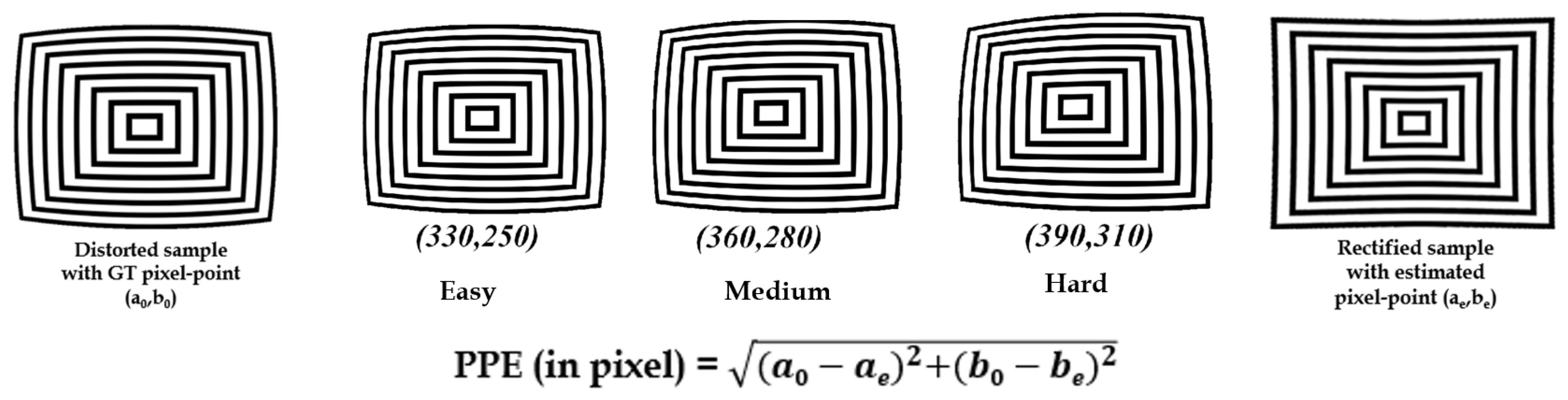
5.1.2. Pixel-Point Error Evaluation
5.2. High-Level Metrics: ADAS and Video-Surveillance Experiments
5.2.1. Datasets Used
- Public-Synthetic dataset: The publicly available KITTI dataset was synthetically modified using open-sourced distortion induction codes [26]. This dataset can be used to quantitatively measure the performance of distortion rectification algorithms and high-level metrics.
- Private-Real dataset: This dataset has been collected using various cameras with diverse lens models such as fish-eye (190) and wide-angle (120). This real dataset tests the robustness of the rectification algorithms with respect to the object detection scenarios.
- Public- and Private-Real dataset: This dataset has been collected using various cameras with diverse lens models such as super wide-angle (150) and wide-angle (120). This real dataset tests the robustness of the rectification algorithms with respect to the height estimation and metric-level information.
5.2.2. Object Detection Using Pretrained Models
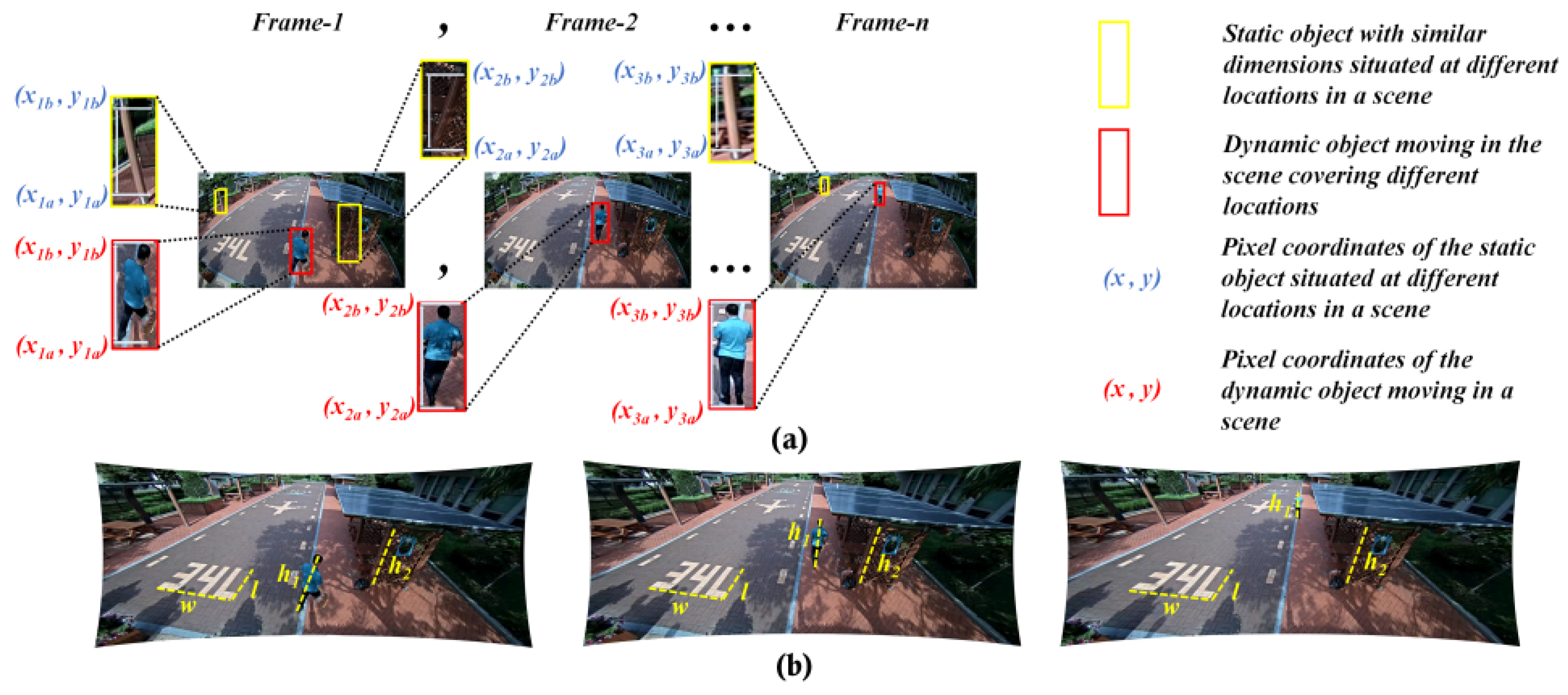
5.2.3. Height Estimation on Fixed Monocamera Sensor
6. Results and Discussions
6.1. Pixel Quality and Consistency
6.1.1. Quantitative Analysis: Image Quality
6.1.2. Quantitative Analysis: Pixel-Point Error
6.2. High-Level Metrics: ADAS Use-Case
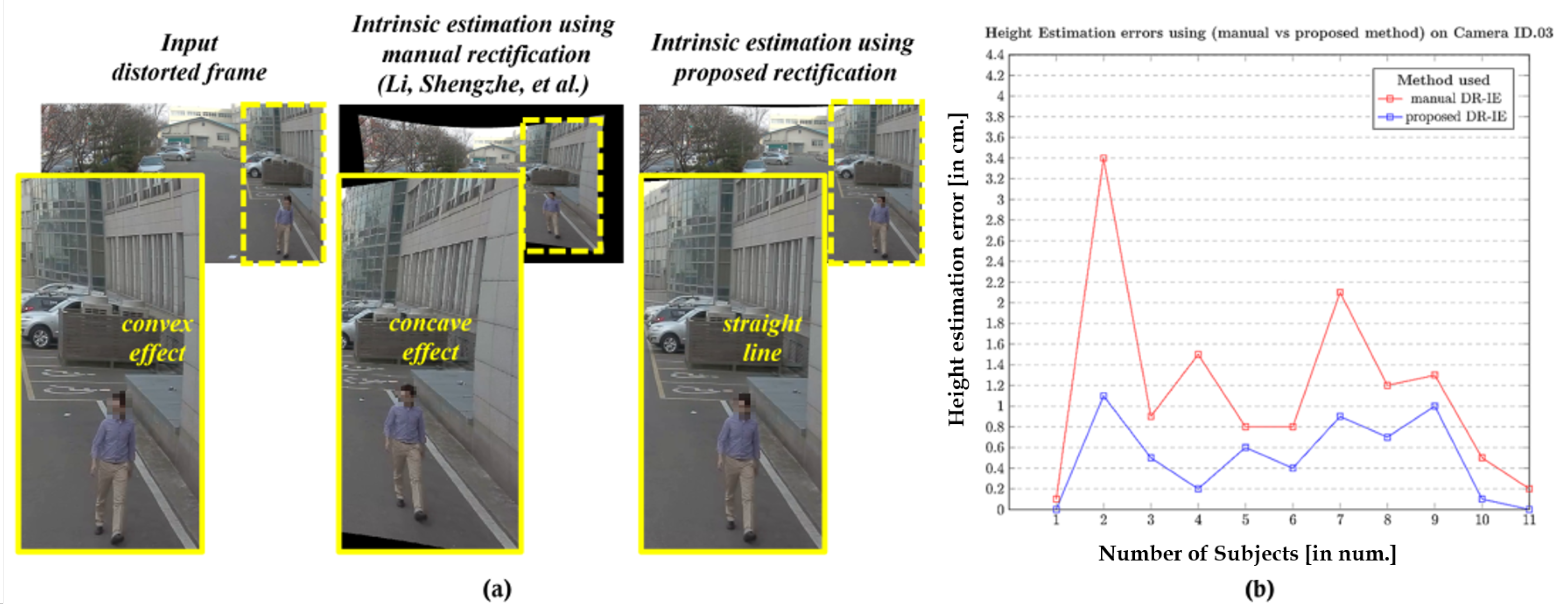
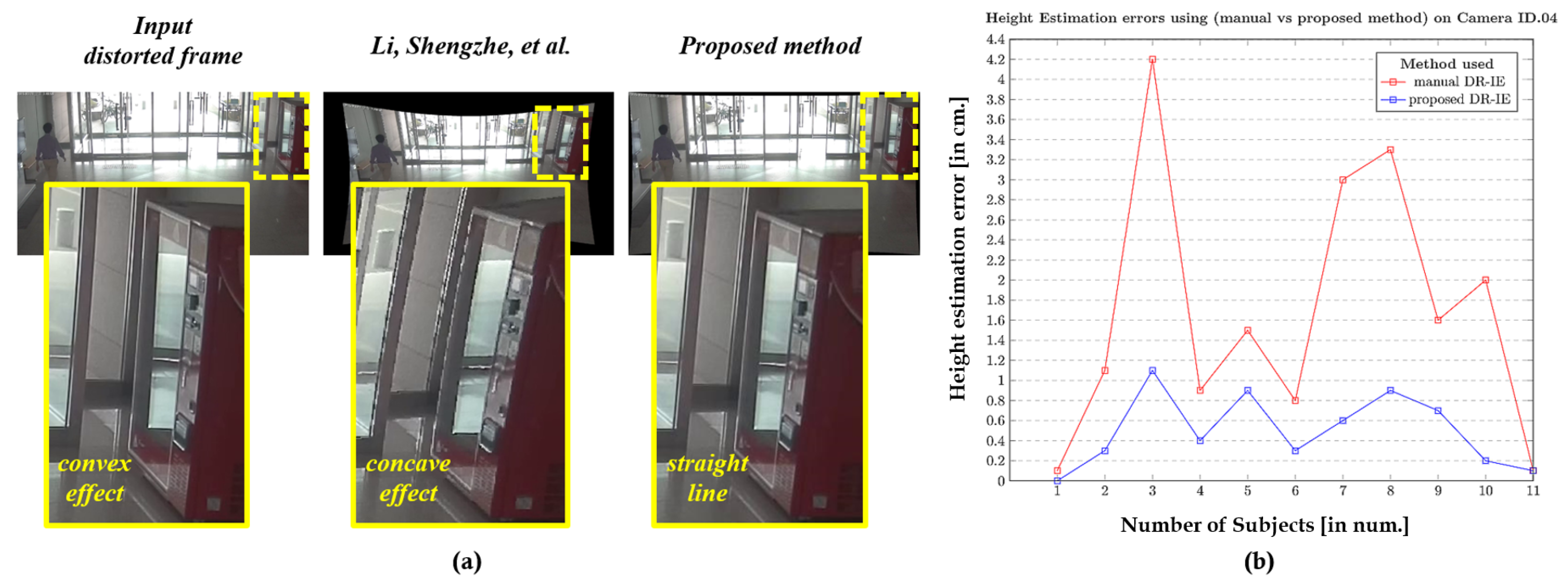
6.2.1. Qualitative Performance Analysis
6.2.2. Quantitative Performance Analysis
6.3. High-Level Metrics: Video-Surveillance Use-Case
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Shah, S.; Aggarwal, J. A simple calibration procedure for fish-eye (high distortion) lens camera. In Proceedings of the 1994 IEEE International Conference on Robotics and Automation, San Diego, CA, USA, 8–13 May 1994; pp. 3422–3427. [Google Scholar]
- Nayar, S.K. Catadioptric omnidirectional camera. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Juan, PR, USA, 17–19 June 1997; pp. 482–488. [Google Scholar]
- Alemán-Flores, M.; Alvarez, L.; Gomez, L.; Santana-Cedrés, D. Automatic lens distortion correction using one-parameter division models. Image Process. Line 2014, 4, 327–343. [Google Scholar] [CrossRef]
- Bukhari, F.; Dailey, M.N. Automatic radial distortion estimation from a single image. J. Math. Imaging Vis. 2013, 45, 31–45. [Google Scholar] [CrossRef]
- Santana-Cedrés, D.; Gomez, L.; Alemán-Flores, M.; Salgado, A.; Esclarín, J.; Mazorra, L.; Alvarez, L. An iterative optimization algorithm for lens distortion correction using two-parameter models. Image Process. Line 2016, 6, 326–364. [Google Scholar] [CrossRef]
- Schwalbe, E. Geometric Modelling and Calibration of Fisheye Lens Camera Systems; Institute of Photogrammetry and Remote Sensing-Dresden University of Technology: Dresden, Germany, 2005. [Google Scholar]
- Ho, T.H.; Davis, C.C.; Milner, S.D. Using geometric constraints for fisheye camera calibration. In Proceedings of the IEEE OMNIVIS Workshop, Beijing, China, 17–20 October 2005. [Google Scholar]
- Thirthala, S.; Pollefeys, M. The radial trifocal tensor: A tool for calibrating the radial distortion of wide-angle cameras. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 321–328. [Google Scholar]
- Tardif, J.P.; Sturm, P.; Roy, S. Self-calibration of a general radially symmetric distortion model. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2006; pp. 186–199. [Google Scholar]
- Podbreznik, P.; Potocnik, B. Influence of temperature variations on calibrated cameras. Int. J. Comput. Inf. Sci. Eng. 2008, 2, 261–267. [Google Scholar]
- Handel, H. Analyzing the influence of camera temperature on the image acquisition process. In Three-Dimensional Image Capture and Applications 2008; International Society for Optics and Photonics: Bellingham, WA USA, 2008; Volume 6805, p. 68050X. [Google Scholar]
- Zhang, Z.; Matsushita, Y.; Ma, Y. Camera calibration with lens distortion from low-rank textures. In Proceedings of the CVPR 2011, Providence, RI, USA, 20–25 June 2011; pp. 2321–2328. [Google Scholar]
- Barreto, J.; Roquette, J.; Sturm, P.; Fonseca, F. Automatic camera calibration applied to medical endoscopy. In Proceedings of the BMVC 2009—20th British Machine Vision Conference, London, UK, 7–10 September 2009; pp. 1–10. [Google Scholar]
- Duane, C.B. Close-range camera calibration. Photogramm. Eng. 1971, 37, 855–866. [Google Scholar]
- Brauer-Burchardt, C.; Voss, K. A new algorithm to correct fish-eye-and strong wide-angle-lens-distortion from single images. In Proceedings of the 2001 International Conference on Image Processing (Cat. No. 01CH37205), Thessaloniki, Greece, 7–10 October 2001; Volume 1, pp. 225–228. [Google Scholar]
- Fitzgibbon, A.W. Simultaneous linear estimation of multiple view geometry and lens distortion. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001; Volume 1, pp. 125–132. [Google Scholar]
- Cipolla, R.; Drummond, T.; Robertson, D.P. Camera Calibration from Vanishing Points in Image of Architectural Scenes. In Proceedings of the BMVC 1999, Nottingham, UK, 13–16 September 1999; Volume 99, pp. 382–391. [Google Scholar]
- Alvarez, L.; Gomez, L.; Sendra, J.R. Algebraic lens distortion model estimation. Image Process. Line 2010, 1, 1–10. [Google Scholar] [CrossRef][Green Version]
- Kakani, V.; Kim, H.; Kumbham, M.; Park, D.; Jin, C.B.; Nguyen, V.H. Feasible Self-Calibration of Larger Field-of-View (FOV) Camera Sensors for the Advanced Driver-Assistance System (ADAS). Sensors 2019, 19, 3369. [Google Scholar] [CrossRef] [PubMed]
- Kakani, V.; Kim, H. Adaptive Self-Calibration of Fisheye and Wide-Angle Cameras. In Proceedings of the TENCON 2019—2019 IEEE Region 10 Conference (TENCON), Kochi, India, 17–20 October 2019; pp. 976–981. [Google Scholar]
- Bogdan, O.; Eckstein, V.; Rameau, F.; Bazin, J.C. DeepCalib: A deep learning approach for automatic intrinsic calibration of wide field-of-view cameras. In Proceedings of the 15th ACM SIGGRAPH European Conference on Visual Media Production, London, UK, 13–14 December 2018; ACM: New York, NY, USA, 2018; p. 6. [Google Scholar]
- Lopez, M.; Mari, R.; Gargallo, P.; Kuang, Y.; Gonzalez-Jimenez, J.; Haro, G. Deep Single Image Camera Calibration With Radial Distortion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 11817–11825. [Google Scholar]
- Liao, K.; Lin, C.; Zhao, Y.; Gabbouj, M. DR-GAN: Automatic Radial Distortion Rectification Using Conditional GAN in Real-Time. IEEE Trans. Circuits Syst. Video Technol. 2019. [Google Scholar] [CrossRef]
- Park, D.H.; Kakani, V.; Kim, H.I. Automatic Radial Un-distortion using Conditional Generative Adversarial Network. J. Inst. Control Robot. Syst. 2019, 25, 1007–1013. [Google Scholar] [CrossRef]
- Akinlar, C.; Topal, C. EDPF: A real-time parameter-free edge segment detector with a false detection control. Int. J. Pattern Recognit. Artif. Intell. 2012, 26, 1255002. [Google Scholar] [CrossRef]
- Vass, G.; Perlaki, T. Applying and removing lens distortion in post production. In Proceedings of the 2nd Hungarian Conference on Computer Graphics and Geometry, Budapest, Hungary, 3 June 2003; pp. 9–16. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Hore, A.; Ziou, D. Image quality metrics: PSNR vs. SSIM. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2366–2369. [Google Scholar]
- Vu, C.T.; Chandler, D.M. S3: A spectral and spatial sharpness measure. In Proceedings of the 2009 First International Conference on Advances in Multimedia, Colmar, France, 20–25 July 2009; pp. 37–43. [Google Scholar]
- Hassen, R.; Wang, Z.; Salama, M.M. Image sharpness assessment based on local phase coherence. IEEE Trans. Image Process. 2013, 22, 2798–2810. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Collins, R.T.; Liu, Y. Surveillance camera autocalibration based on pedestrian height distributions. In Proceedings of the British Machine Vision Conference (BMVC 2011), Dundee, UK, 29 August–2 September 2011; Volume 2. [Google Scholar]
- Li, S.; Nguyen, V.H.; Ma, M.; Jin, C.B.; Do, T.D.; Kim, H. A simplified nonlinear regression method for human height estimation in video surveillance. EURASIP J. Image Video Process. 2015, 2015, 32. [Google Scholar] [CrossRef]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Method | Dataset | Limitations |
|---|---|---|---|
| Alvarez et al. [18] | 2D Euclidean distance | Synthetic dataset with symmetrical patterns | Semiautomatic. Not robust for real-time usage (illumination changes, etc.) |
| Bukhari et al. [4] | Circular arcs algebra | Synthetic dataset with salient point GT | Severe stretching along the edges. Long processing time for heavy distortion samples |
| Aleman et al. [3] | Hough parametric space | A private dataset using Nikon D90 | Unstable outputs for larger FOV lens camera samples. Heavy hyperparameter-dependent |
| Santana et al. [5] | Iterative optimization of Hough transforms | Wide angle lens distortion image | Lacking robustness towards blurred images and low-light conditions |
| Kakani et al. [19] | Straightness cost constraint loss with model-specific empirical -residual rectification factor | Real data with varying distortion ranges 120< FOV < 200 Synthetic distorted KITTI samples | Requires prior model-specific knowledge to deal with -residual rectification factors |
| Bogdan et al. [21] | Dual CNN network on radial distortions | Panoramic images of the SUN360 dataset | Fails to rectify samples in illumination changes, motion blur samples |
| Lopez et al. [22] | CNN Parameterization for radial distortions | SUN360 panorama dataset | Network can only undistort in cropped mode rising an issue of pixel loss ≥30% |
| Park et al. [24] | U-Net-based GAN for radial distortions | Real and synthetic distortion dataset | Cannot handle heavy distortions FOV > 160 |
| Liao, Kang et al. [23] | U-Net-based GAN for radial distortions | Synthetic dataset with distortion ranging | Limited distortion ranges (cannot handle distortions <) |
| Image Quality Metrics | Distortion Rectification Algorithm | |||
|---|---|---|---|---|
| Traditional OpenCV | Bukhari et al. [4] | Santana et al. [5] | Proposed Method | |
| PSNR [in dB.] | 8.75 | 13.61 | 17.5 | 19 |
| SSIM [in %] | 22.9 | 30.3 | 43.2 | 47.2 |
| S3 [∼] | 0.44 | 0.34 | 0.41 | 0.51 |
| LPC-SI [∼] | 0.78 | 0.82 | 0.86 | 0.92 |
| Synthetic Distortion Pixel-Point (GT) | Pixel-Point Errors on Distortion-Rectified Samples [in px.] | ||
|---|---|---|---|
| Alvarez et al. [18] | Santana et al. [5] | Proposed Method | |
| Easy (330,250) | 21.3 | 14.1 | 10.1 |
| Medium (360,280) | 17.0 | 18.4 | 15.9 |
| Hard (390,310) | 49.5 | 39.9 | 28.8 |
| Average point error [in px.] | 29.2 | 24.1 | 18.3 |
| Subject ID | Height Estimation Errors with Respect to Various Cameras on 11 Subjects [in cm] | |||||||
|---|---|---|---|---|---|---|---|---|
| Cam1 | Cam2 | Cam6 | Cam7 | |||||
| Manual | Automatic | Manual | Automatic | Manual | Automatic | Manual | Automatic | |
| S1 | 0.1 | 0 | 0.1 | 0.2 | 0.1 | 0 | 0.1 | 0.1 |
| S2 | 1 | 0.4 | 2 | 0.7 | 0.5 | 0.2 | 0.1 | 0.2 |
| S3 | 0.1 | 0 | 0.2 | 0.1 | 1.2 | 0.7 | 0.6 | 0.5 |
| S4 | 0.1 | 0 | 0.8 | 0.4 | 1.3 | 0.9 | 2.2 | 0.4 |
| S5 | 4.2 | 1.5 | 0.2 | 0.3 | 3 | 0.6 | 3 | 1.2 |
| S6 | 0.5 | 0.3 | 1.4 | 0.5 | 0.4 | 0.2 | 2.4 | 0.8 |
| S7 | 2.6 | 0.7 | 3 | 0.8 | 0.3 | 0.2 | 0 | 0.1 |
| S8 | 1.1 | 0.9 | 0.9 | 0.6 | 1.2 | 0.7 | 1.1 | 0.7 |
| S9 | 2 | 0.6 | 0.3 | 0.2 | 0.4 | 0.3 | 0.9 | 0.8 |
| S10 | 4.1 | 1.1 | 0.9 | 0.3 | 0.8 | 0.1 | 2.1 | 0.6 |
| S11 | 2.8 | 1.3 | 1.3 | 0.2 | 1.4 | 0.4 | 0.8 | 0.5 |
| Average Errors [in cm] | 1.69 | 0.61 | 1.01 | 0.39 | 0.96 | 0.39 | 1.20 | 0.53 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kakani, V.; Kim, H.; Lee, J.; Ryu, C.; Kumbham, M. Automatic Distortion Rectification of Wide-Angle Images Using Outlier Refinement for Streamlining Vision Tasks. Sensors 2020, 20, 894. https://doi.org/10.3390/s20030894
Kakani V, Kim H, Lee J, Ryu C, Kumbham M. Automatic Distortion Rectification of Wide-Angle Images Using Outlier Refinement for Streamlining Vision Tasks. Sensors. 2020; 20(3):894. https://doi.org/10.3390/s20030894
Chicago/Turabian StyleKakani, Vijay, Hakil Kim, Jongseo Lee, Choonwoo Ryu, and Mahendar Kumbham. 2020. "Automatic Distortion Rectification of Wide-Angle Images Using Outlier Refinement for Streamlining Vision Tasks" Sensors 20, no. 3: 894. https://doi.org/10.3390/s20030894
APA StyleKakani, V., Kim, H., Lee, J., Ryu, C., & Kumbham, M. (2020). Automatic Distortion Rectification of Wide-Angle Images Using Outlier Refinement for Streamlining Vision Tasks. Sensors, 20(3), 894. https://doi.org/10.3390/s20030894