1. Introduction
Biometric systems in which the physiological or behavioral characteristics of humans, e.g., fingerprints, electrocardiogram (ECG), gait, iris, and face, are captured and utilized for authentication are increasingly used. Fingerprints are among the most extensively employed biometrics owing to their several advantages, such as acceptability, collectability, and high authentication accuracy [
1]. The widespread availability of fingerprint-based systems has made them vulnerable to numerous attacks, mainly presentation attacks (PAs). ISO/IEC 30107 defines a PA as the presentation of a fraudulent sample, such as an artefact or a fake biological sample, to an input biometric sensor with the intention of circumventing the system policy [
2]. An artefact can be an artificial or synthetic fingerprint presented as a copy of a real fingerprint, which is also known as a spoof [
3].
Figure 1 shows examples of numerous artefact fingerprint samples created by different artificial materials, such as gelatin, Play-Doh, and silicon [
4]. For fake biological sample-based attacks, a severed or altered finger, or a finger of a cadaver, is presented to deceive a biometric sensor. The automated process used for detecting a PA in a biometric system is called PA detection (PAD) [
2]. The aim of PAD is discriminating the bona fide (i.e., real or live) biometric samples from PA (i.e., artefact) samples.
Fingerprint PAD methods can be divided into hardware- and software-based methods [
5]. In a hardware-based method, additional hardware devices are added to the biometric system to capture additional characteristics indicating the liveness of the fingerprint, such as blood pressure in the fingers, skin transformation, and skin odor [
6,
7,
8]. With software-based methods, in contrast, the PAs of the fingerprints are analyzed by applying image processing techniques on fingerprint images. By exploring software-based techniques for fingerprint PAD studied in the literature, these methods can be grouped into handcrafted feature- and deep-learning-based techniques. In handcrafted feature-based techniques, expert knowledge is required to formulate the feature descriptors, whereas in deep-learning-based techniques, no such expert knowledge is required.
The local binary pattern (LBP) is one of the earliest and most common handcrafted techniques that has been investigated for fingerprint liveness detection, in which LBP histograms are applied to extract the texture liveness information using binary coding [
9]. Measuring the loss of information while fabricating fake fingerprints is utilized in local phase quantization (LPQ) to differentiate between bona fide and artefact fingerprint images [
10]. The Weber local descriptor (WLD) is applied for fingerprint liveness detection, in which 2D histograms representing differential excitation and orientation features are applied [
11]. Combining these local descriptors such as WLD with LPQ [
11], or WLD with LBP [
12], improves the accuracy of detecting the liveness of a fingerprint. A new local contrast phase descriptor is proposed for fingerprint liveness detection as 2D histogram features composed of spatial and phase information [
13].
Deep learning techniques have recently proven their superiority over traditional approaches in image classification problems [
14,
15]. Deep learning techniques have also proven their advantages on 1D signals, including ECG [
16,
17,
18,
19]. Several studies have investigated the utilization of deep learning techniques in biometrics systems [
20,
21,
22], and for fingerprint PAD [
23,
24,
25,
26]. Convolutional neural network (CNN) networks have exhibited continuous improvements for spoof detection compared with handcrafted techniques. An early work that introduced CNN for fingerprint PAD [
23] employed transfer learning using a pre-trained CNN model for detecting fake fingerprints, which achieved the best results in the LivDet 2015 competition [
27]. Another use of deep learning for fingerprint PAD is presented in [
28], where local patches of minutiae have been extracted and processed using a well-known CNN model called Inception-V3, which achieved state-of-the-art accuracy in fingerprint liveness detection. A CNN model with improved residual blocks was proposed to balance between the accuracy and the convergence time in a fingerprint liveness system [
29], wherein they extracted local patches using the statistical histogram and center of gravity. This approach won first place in the LivDet 2017 competition. A small CNN network was proposed to overcome the difficulties in the deployment of a fingerprint liveness detection system in mobile systems by utilizing the structure of the SqueezNet fire module and removing the fully connected layers [
24].
Recently, a new group of fingerprint PAD methods have also been considered, which fall outside of software- and hardware-based approaches and are based on the fusion of fingerprint with a more secure biometric modality [
30,
31]. Several researchers investigated the fusion of fingerprints with a variety of biometric modalities, such as face, ECG, and fingerprint dynamics, to improve the accuracy and security of biometric systems [
19,
32,
33,
34,
35,
36,
37,
38,
39,
40,
41]. The fusion of an ECG with other biometric modalities [
37,
38,
42,
43,
44,
45,
46] has also received attention because the ECG has certain biometric advantages, such as a natural inherence of the liveness characteristic and a continuous authentication over time [
47]. The crucial location of the heart in the body enables this biometric to be used as a secure modality. Moreover, a high-quality ECG can be captured from fingers, which make this modality a convenient candidate for a multimodal fusion with fingerprints [
48]. These characteristics render ECG biometrics robust against PAs and provide them with advantages over other traditional biometrics. Several studies have considered the fusion of fingerprints and an ECG for PAD in fingerprint biometrics. A sequential score level fusion between an ECG and a fingerprint was proposed in [
37]. Later, this approach was improved to be appropriate for fingerprint PAD in an authentication system [
38]. Another study on fusing a fingerprint with an ECG was proposed in [
36], in which the fusion is achieved at the score level by applying an automatic updating of the ECG templates. In this study, the authors fused an ECG matching score with the liveness score to evaluate the liveness of the fingerprint sample, demonstrating a good performance.
Several recent studies have proposed utilizing a CNN to deal with two-branch networks for processing video data [
49,
50,
51]. A CNN network has been introduced into a multimodal biometric system combining an ECG with a fingerprint [
19,
52], in which the CNN is used for extracting ECG and fingerprint features. Although CNN was used in these studies, they did not achieve an end-to-end fusion in which the CNN is only used as features extractor and the classification carried out by an independent classifier. Furthermore, these studies focused on authentication performance rather than fingerprint PAD.
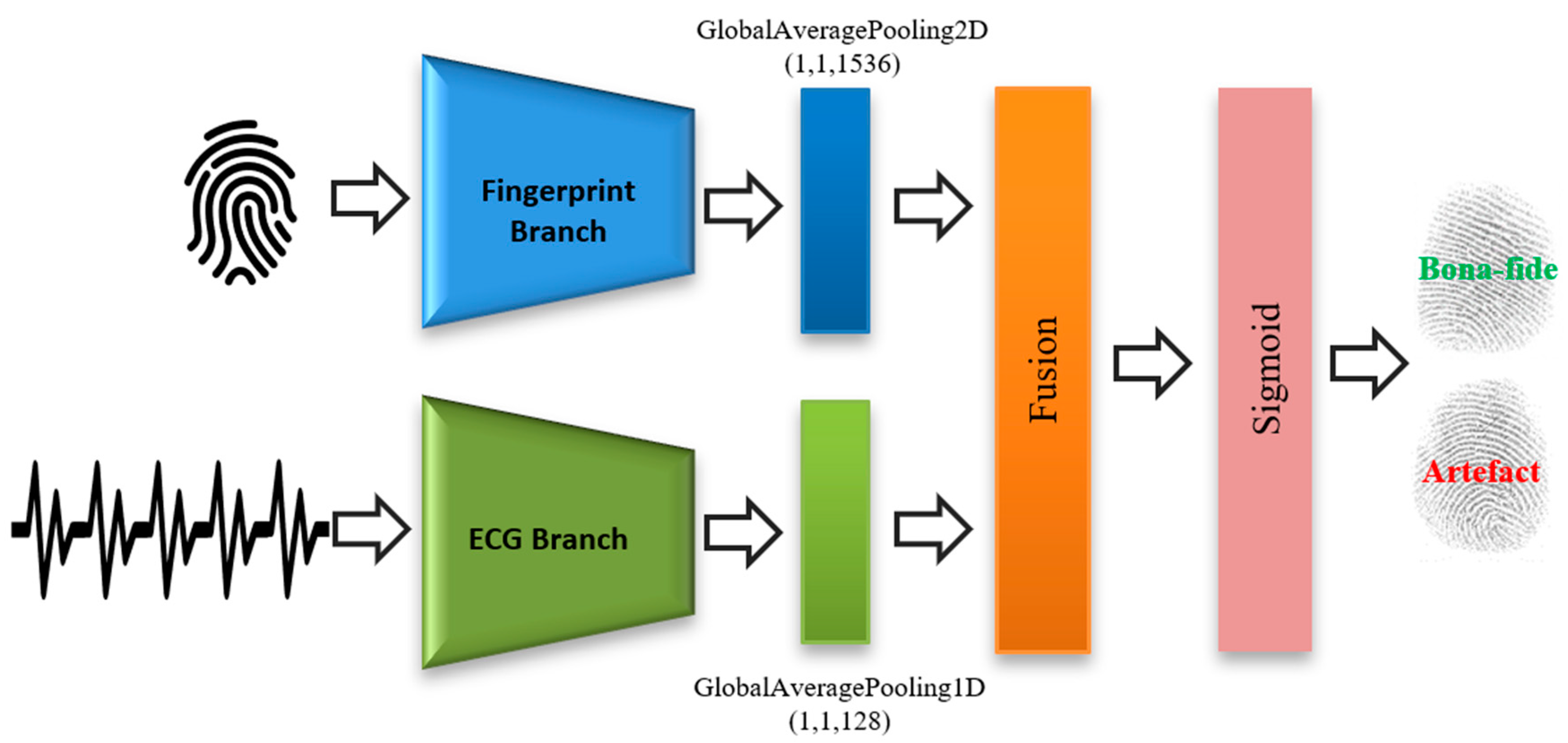
In this study, we propose a novel architecture for fusing a fingerprint and an ECG to detect and prevent fingerprint PAs. The proposed architecture is learnable end-to-end from the signal level to the final decision. The proposed method is intended to achieve a high degree of robustness against the PA targeting of a fingerprint modality. We evaluated the proposed system using a customized dataset composed of fingerprints and ECG signals.
The main contributions of this paper are listed as follows:
Proposal of a novel end-to-end neural fusion architecture for fingerprints and ECG signals.
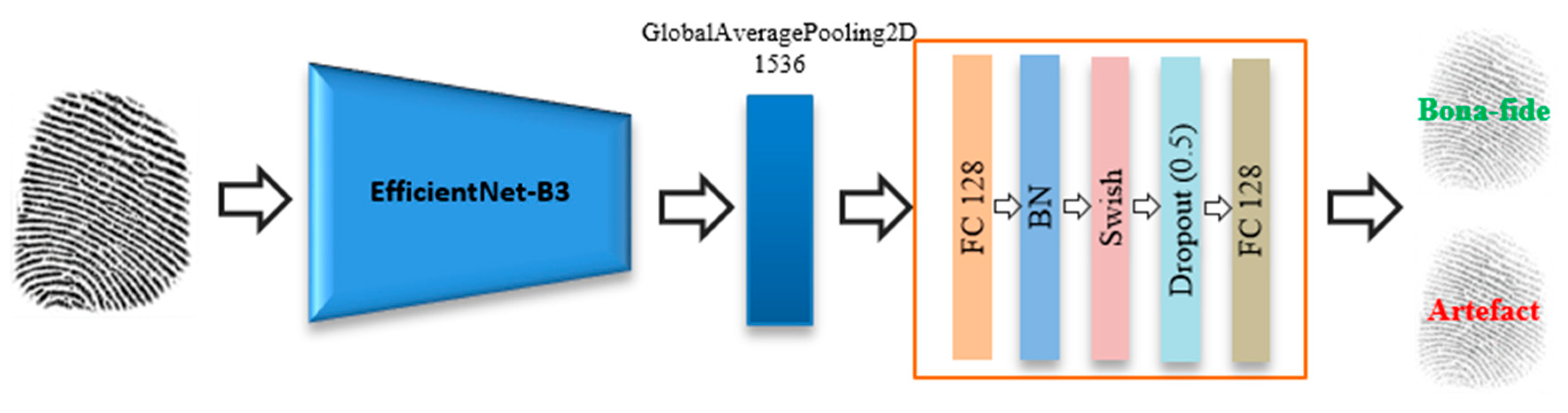
A novel application of state-of-the-art EfficientNets for fingerprint PAD.
Proposal of a 2D-convolutional neural network (2D-CNN) architecture for converting 1D ECG features into 2D images, yielding a better representation for ECG features compared to standard models based on fully-connected layers (FC) and 1D-convolutional neural networks (1D-CNNs).
The remainder of this paper is organized as follows. In
Section 2, we introduce our proposed end-to-end deep learning approaches. In
Section 3, we present the datasets and experimental setup applied. In
Section 4, we present experimental results and discussions. Finally, in
Section 5, we provide some concluding remarks and suggest areas of future study.
4. Results and Discussions
4.1. Experiments Using Fingerprint Modality Only
Initially, we examined the performance of the proposed fingerprint network based on EfficientNet. This evaluation allows us to compare the performances of this network in terms of fingerprint PAD with that of the methods proposed in the LivDet 2015 competition [
27].
Table 4 shows the results after training the network for 50 iterations.
We can see from the results in
Table 4 that the proposed fingerprint network achieves an overall classification accuracy of 94.87%. A comparison of the reported accuracy of the proposed network with those reported from the LivDet 2015 competition shows that our method would have been the second-best approach. Moreover, the proposed method follows the same behavior as the other two algorithms in terms of its accuracy for the individual sensors, achieving a high accuracy of 97.29% for the Crossmatch sensor (i.e., an easy to learn sensor) and a relatively lower accuracy of 91.96% for the Digital Persona sensor (i.e., a difficult to learn sensor). Furthermore, the proposed method achieves moderately high accuracies of 94.68% and 95.12% for the Green bit and Biometrika sensors, respectively.
Figure 11 shows the progress of the loss function during the training on the LivDet 2015 dataset (training part). Note that the loss converges at a low number of iterations (nearly 25 iterations). The reported results confirm the promising capability of the network in detecting PAs, motivating us to improve it further by proposing a multimodal solution that fuses fingerprints with ECG signals.
4.2. Fusion of Fingerprints and ECGs
As mentioned previously, owing to the lack of a multimodal dataset containing fingerprints and ECG modalities, we built a mini-livdet2015 dataset and fused it with the ECG dataset. We used a Digital Persona sensor, the most difficult sensor used for the LivDet 2015 dataset, as demonstrated in the previous experiment, and achieved the lowest accuracy 91.96% in comparison to the other sensors. This mini-livdet2015 contains 70 subjects, each of which has 10 bona fide and 12 artefact fingerprint samples. We constructed the multimodal dataset by randomly linking each subject from the mini-livdet2015 dataset to a subject from the ECG dataset, as previously discussed. Before running the fusion network on this multimodal dataset, we first trained the fingerprint network on the mini-livdet2015 dataset to obtain an indication regarding its performance, which is considered a baseline for our fusion mechanism. We obtained an accuracy of 92.98% using 50% of the subjects for training and 50% for testing, i.e., 35 subjects for training and the other 35 subjects for testing.
After this step, we evaluated the complete architecture using the three proposed feature extraction solutions (i.e., FC, 1D-CNN, and 2D-CNN).
Table 5 shows the average classification accuracy of the three fusion architectures. Furthermore, the average classification accuracy of the fingerprint network on the mini-livdet2015 dataset is reported.
The reported results show that fusing fingerprints with ECG data clearly improves the accuracy of artefact fingerprint detection. The different architectures, namely, FC, 1D-CNN, and 2D-CNN, achieve accuracies of 94.99%, 94.84%, and 95.32%, respectively, thereby outperforming the accuracy achieved by fingerprint net (i.e., without applying a fusion). As the results indicate, the 2D-CNN model achieves the highest accuracy (95.32%) compared with the other two fusion architectures. The high performance of the 2D-CNN model can be attributed to the conversion of ECG signals into images, thus utilizing the power of 2D convolution and pooling operations, in addition to the introduction of MBConv blocks as the main blocks for learning the representative features.
4.3. Sensitivity Analysis of the Number of Training Subjects
During this experiment, we discuss how the number of subjects used for training can affect the level of accuracy. We repeated the above experiment with different percentages of subjects used for training (between 20% and 80%), the average accuracy of which is reported in
Table 6.
The reported results show that increasing the number of subjects (70% and 80%) during the training improves the testing accuracy. Although this behavior is the same for the three proposed architectures, we can see that the 2D-CNN model consistently outperforms the other two models with an accuracy of 97.10% when using 80% of the subjects in the dataset for training. In contrast, decreasing the number of subjects during the training degrades the testing accuracy. Despite the decrease in testing accuracy, the level achieved is still acceptable (89.71%, 89.31%, and 90.79%) for the FC, 1D-CNN, and 2D-CNN, respectively when using 20% of the subjects for training.
4.4. Sensitivity with Respect to the Pre-Trained CNN
In order to further assess the sensitivity of the proposed approach with respect to the pre-trained CNN model, we carried out additional experiments using other well-known pre-trained CNN models: Inception-v3 [
61], DenseNet [
62], and residual network (ResNet) [
63]. We used these recent pre-trained models for this experiment as they require a comparatively small number of parameters as shown in
Table 7.
Inception-v3 is one of Inception models family developed by Google [
61], in which they introduced the concept of factorizing of convolutions. Inceptions models are based on increasing the width and depth of the network, by utilizing a module called inception [
64], which contains several convolutional layers with different filter sizes. The utilization of the inception module allows the Inception model for a better deal with scale and spatial variations. DenseNet was proposed by Szegedy et al. [
62] for better utilization of computing resources. DeneNet is based on adding connections between each layer and every other layer in feed-forward fashion, in which each layer receives the feature maps of all preceding layers as input and feeds its own feature maps as input into all subsequent layers. ResNet was proposed by He et al. [
63] to overcome the difficulties in training deeper networks by learning residual functions. These residual networks achieved better optimization and generalization as the depth increases.
We note from the results in
Table 7, that EfficientNet-B3 achieves the highest accuracies in the three architectures and outperforms the other pre-trained CNNs. The accuracies of EfficientNet-B3 in the three architecture (94.99%, 94.84%, and 95.32%) consistently exceed the best accuracies of the other models except for Inception-v3 which achieves a comparable result in the case of 2D-CNN (95.20%). However, EfficientNet-B3 requires the minimum number of parameters (10 M after removing the top layers), whereas Inception-v3 and resNet-50 require 21 M and 23 M, respectively (after removing the top layers). Finally, from the reported accuracies, we note that 2D-CNN outperforms the FC and 1D-CNN for all the pre-trained models (i.e., 95.32%, 95.20%, 93.29%, and 94.00% for EffieicentNet-B3, Inception-v3, DenseNet-169, and ResNet-50 respectively).
4.5. Sensitivity of the ECG Network Architecture
In order to further assess the sensitivity of the proposed approach with different configurations, we carried out additional experiments to show the effect of using different configurations of the ECG branch net on the overall accuracy. Considering that the 2D-CNN architecture proves its superiority over the FC and 1D-CNN as shown in the previous sections, we reported the experiments that cover applying different configurations using 2D-CNN architecture. We tested 8 different configurations as described in
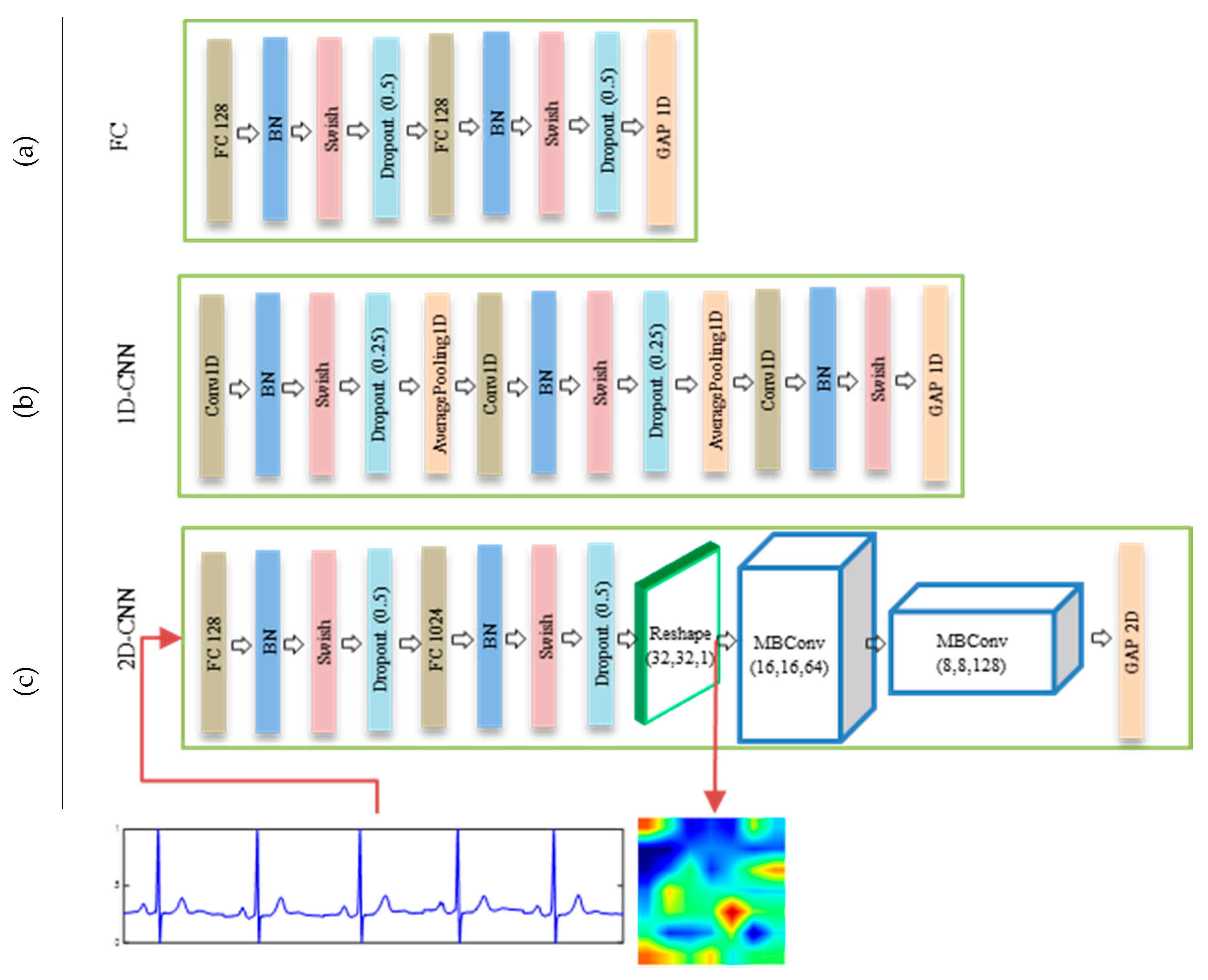
Table 8. Let us consider the configuration #8, which is shown in
Figure 6c: (2 fc = (128, 1024), 2 blocks MBConv (64, 128), fc = 128), this means we use two consecutive fully-connected layers of size 128 and 1024, respectively, in addition to using two consecutive MBConv blocks, of depth 64 and 128, respectively, and finally one fully-connected layer of size 128. The second fully-connected layer fc (1024) means that the feature vector is reshaped into (32 × 32 × 1) as shown in
Figure 6c.
From the reported results in
Table 8, we note the following points. Removing the first fully-connected layer fc (128) in configuration #1, degraded the accuracy (91.90%), whereas increasing the feature map in configuration #2 by replacing the second fully-connected layer fc (1024) with fc (4096); i.e., the feature vector is reshaped into (64 × 64 × 1); will not significantly improve the accuracy (93.56%). Furthermore, changing the number and sizes of MBConv blocks up to 3 (configurations #6 & #7) or down to 1 (configurations #3, #4, & #5), produces better accuracies up to 95.56% in configuration #4. In the proposed configuration #8, we used 2 MBConv blocks, in which the networks achieved the second best accuracy of 95.32%.
4.6. Classification Time
In this study, we used an EfficientNet with 12 million parameters as the main building block for the fingerprint branch. This model provides impressive results with a low computational cost. In particular, our models converge using only 50 epochs. The complete architecture provides an average classification time for one subject (i.e., fingerprint image + ECG signal) of 30–35 ms (depending on the architecture), which is faster than previous state-of-the-art approaches (i.e., 128 ms [
24] and 800 ms [
28]). Recall that the approaches described in [
21] and [
24] applied solutions using only the fingerprint modality and networks with a larger number of weights.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}