Wireless Sensor Networks for Noise Measurement and Acoustic Event Recognitions in Urban Environments

 , ,
, , 
Abstract
:1. Introduction
- (1)
- The large-scale acoustic sensor networks, especially those deployed for acoustic events recognition, generate a large amount of data from each sensor node, which brings the large pressure on transmission of network.
- (2)
- The sounds of interest are superimposed to a significant level of background noise in real-life scenario, which might have an infaust influence on the accuracy of recognition.
- (3)
- The limitation of long-term outdoor monitoring: (1) The dependence of the sensor nodes on the restricted power supplies (batteries) is a defect, as it impedes the longevity of the network; (2) the waterproof measures of sensor nodes are not enough to be resistant to extreme outdoor weather.
- (1)
- Every acoustic sensor node in our system is powered by a solar panel and is waterproof with the package, which is well-suitable for long-term outdoor monitoring. Of course, it can also be powered by a directly available power if the outdoor power is possible.
- (2)
- The combination of endpoint detection and compression with the Adaptive Differential Pulse Code Modulation (ADPCM), which is performed on the embedded processing board, makes it efficient to reduce the amount of data.
- (3)
- The acoustic database is made up of live recordings created by sensor nodes, which is helpful in improving recognition accuracy.
- (4)
- A novel monitoring platform is designed to intuitively present noise maps, acoustic event information, and noise statistics, which allows users to conveniently get information on the noise situation.
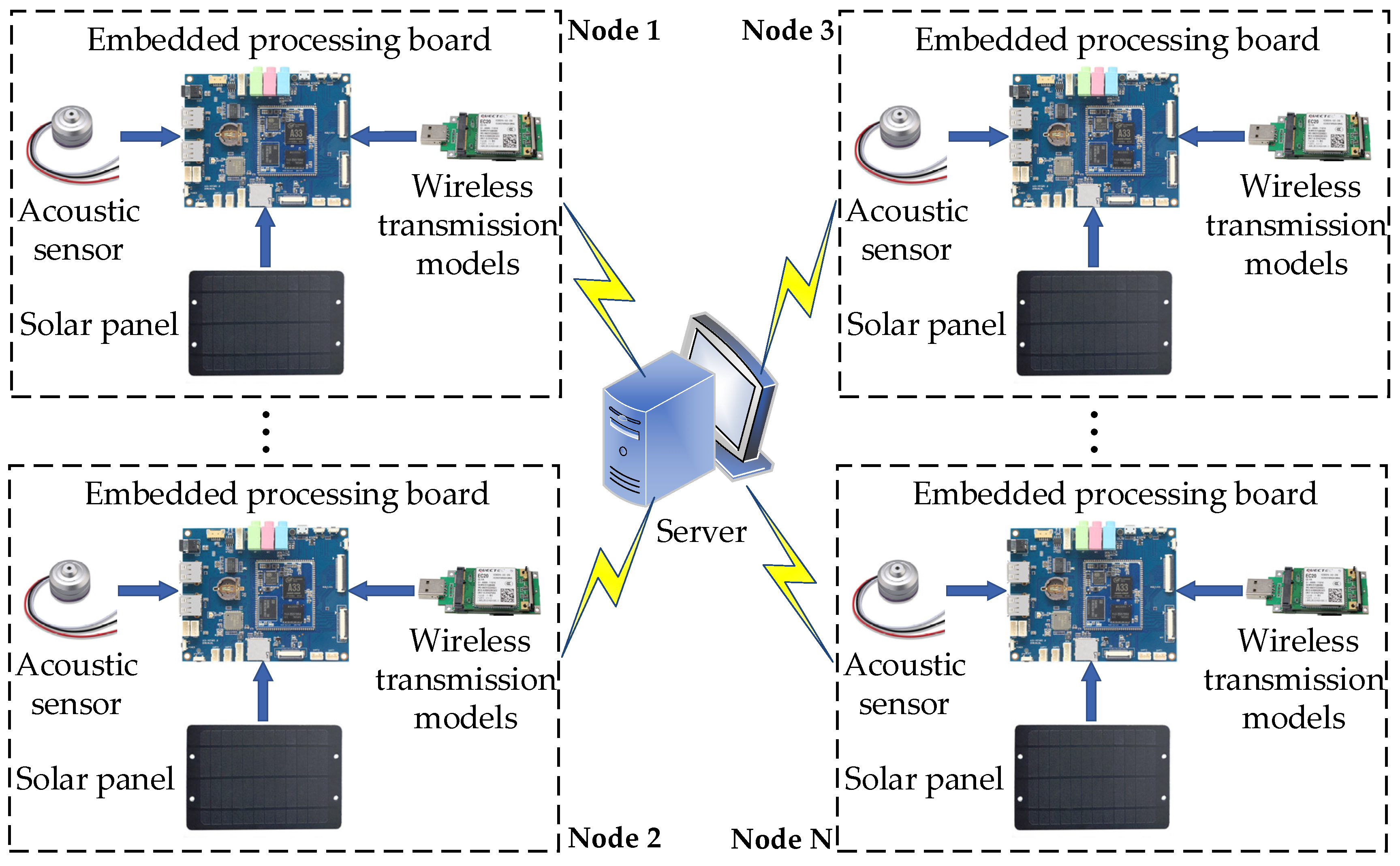
2. Design Details of the Proposed System
2.1. Hardware Details
- (1)
- Acoustic sensor: Since the frequency range of sound audible to the human ear is 20–20 kHz and there is a large background noise in the outdoor environment, we prefer to select the sensor from the two aspects of frequency response and noise reduction. The sensor has the frequency range of 20–20 kHz and the maximum monitoring area of 80 square meters. The sensor has an amplification circuit, filter circuit, and noise reduction circuit inside, which can effectively filter out background noise.
- (2)
- Embedded processing board: Based on the low cost and the slow power consumption, we chose the extra processing board with a rich audio interface and high-performance audio encoder to improve audio quality. The board is paired with the A33 processor which uses a quad-core CPU (CortexTM-A7: Advanced RISC Machines, Cambridge, UK) and a GPU (Mali-400 MP2: ARM Norway, Trondheim, Norway) at frequencies up to 1.2 GHz and has 1 GB DRAM and 8 GB FLASH. In addition, it allows users to expand the storage space by using SD cards.
- (3)
- Wireless transmission module: Adopting the 3GPP Rel-11 LTE technology, the Quectel-EC20 4 G module delivers 150 Mbps downlink and 50 Mbps uplink data rates. A rich set of Internet protocols, industry-standard interfaces, and abundant functionalities extend the applicability of the module to a wide range. The module also combines high-speed wireless connectivity with an embedded multi-constellation high-sensitivity GPS + GLONASS receiver for positioning.
- (4)
- Solar panel: Since our system is used for the long-term outdoor monitoring, we chose the solar panel with a battery and a power controller inside. During the day, the solar panel absorbs energy to charge the battery, and supplies power to the embedded processing board at the same time. It is only used to power the processing board at night. In addition, the solar panel we chose is embedded with a 5 V and 10,500 mAh battery, which allows the processing board to work continuously about two days without sunshine.
2.2. Software Details
3. System Implementation
3.1. Sampling and Recording
3.2. Compress and Transmit
3.3. Receive and Storage
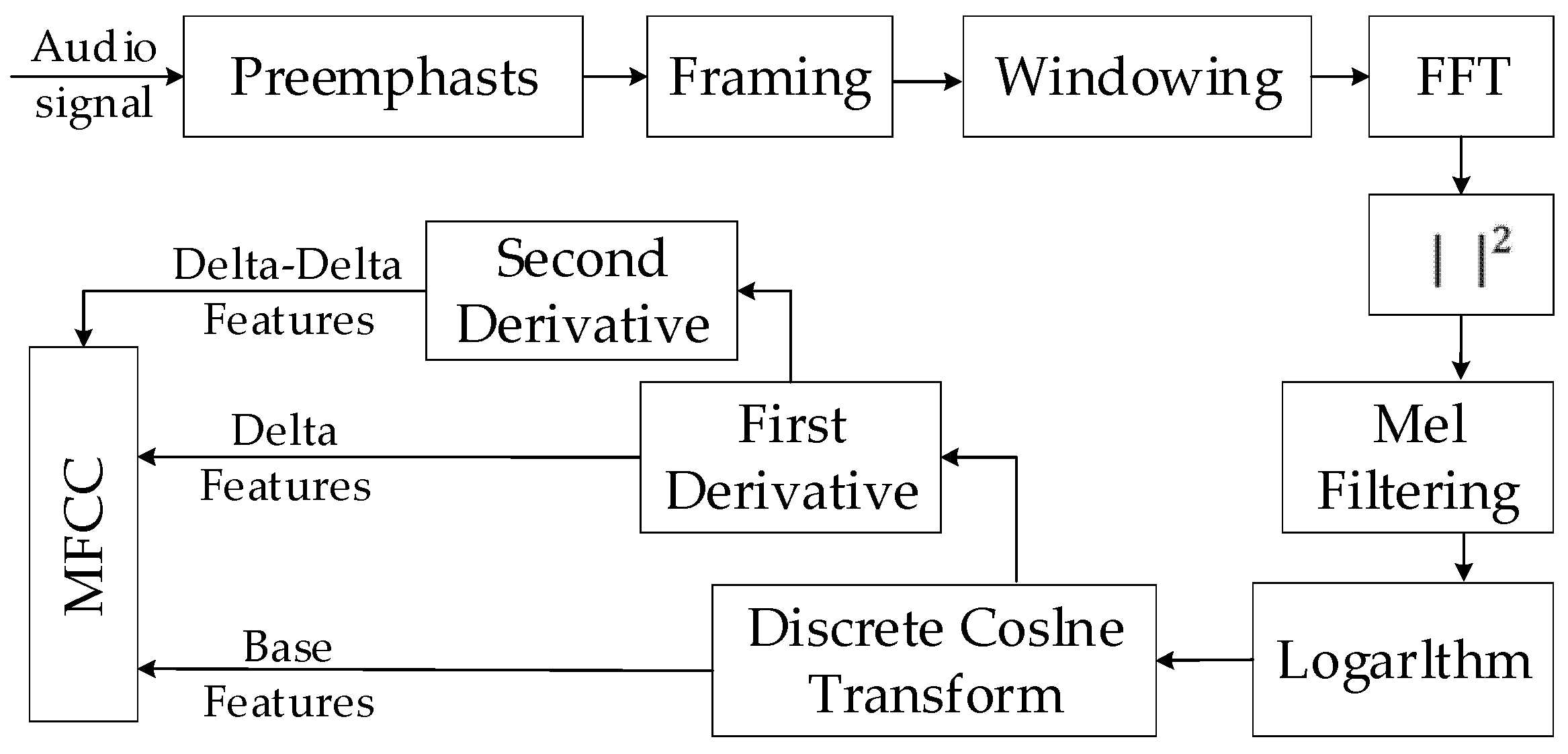
3.4. Feature Extraction
- (1)
- Frame the signal into short frames. An audio signal is constantly changing, so to simplify things we assume that on short time scales the audio signal does not change much. We frame the signal into 25 ms frames. The continuous audio signal is blocked into frames of N samples, with adjacent frames being separated by M. We take the value of M as a half of N.
- (2)
- Calculate the power spectrum of each frame by the following:
- (3)
- Apply the mel filterbank to the power spectra and sum of the energy in each filter. In this step, we calculate the mel frequency by:
- (4)
- Take the logarithm of all filterbank energies.
- (5)
- Take the DCT of the logarithmic filterbank energies. We keep the DCT coefficients from 2 to 13 and discard the rest.
- (6)
- Obtain delta and delta-delta features by the derivative. The following formula is used:
- (7)
- The MFCC consists of base features, delta features, and delta-delta features.
3.5. Recognition
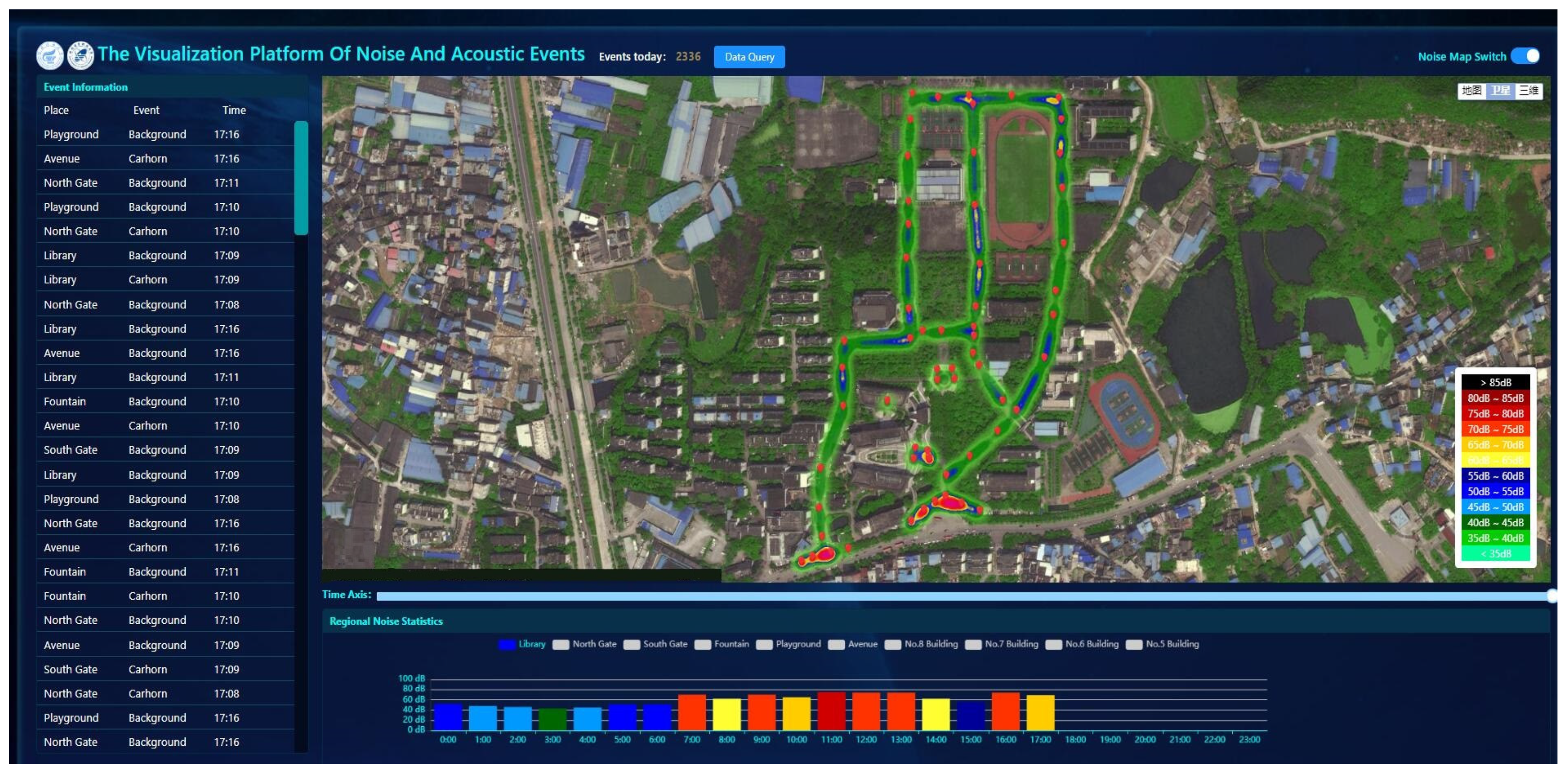
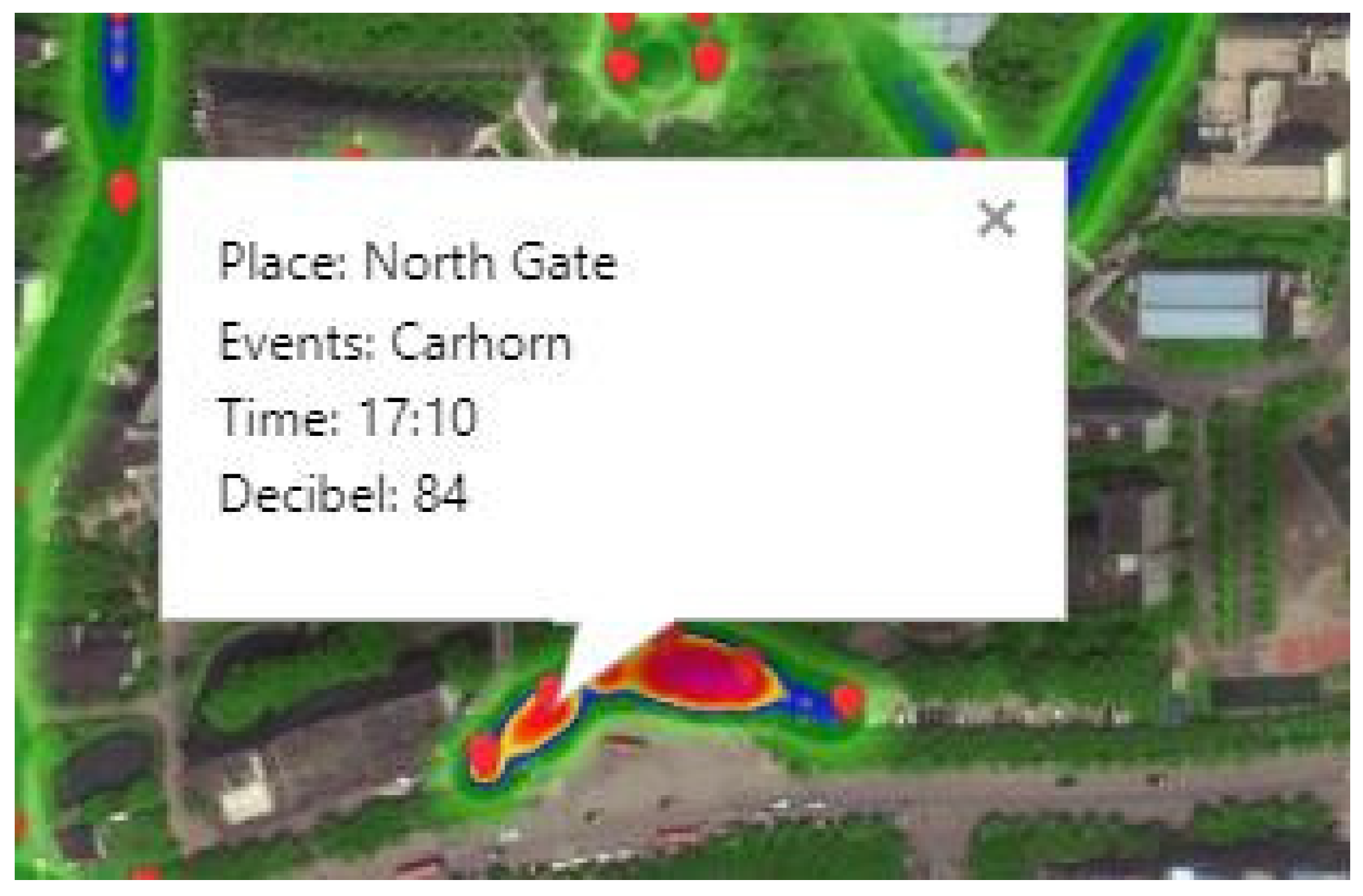
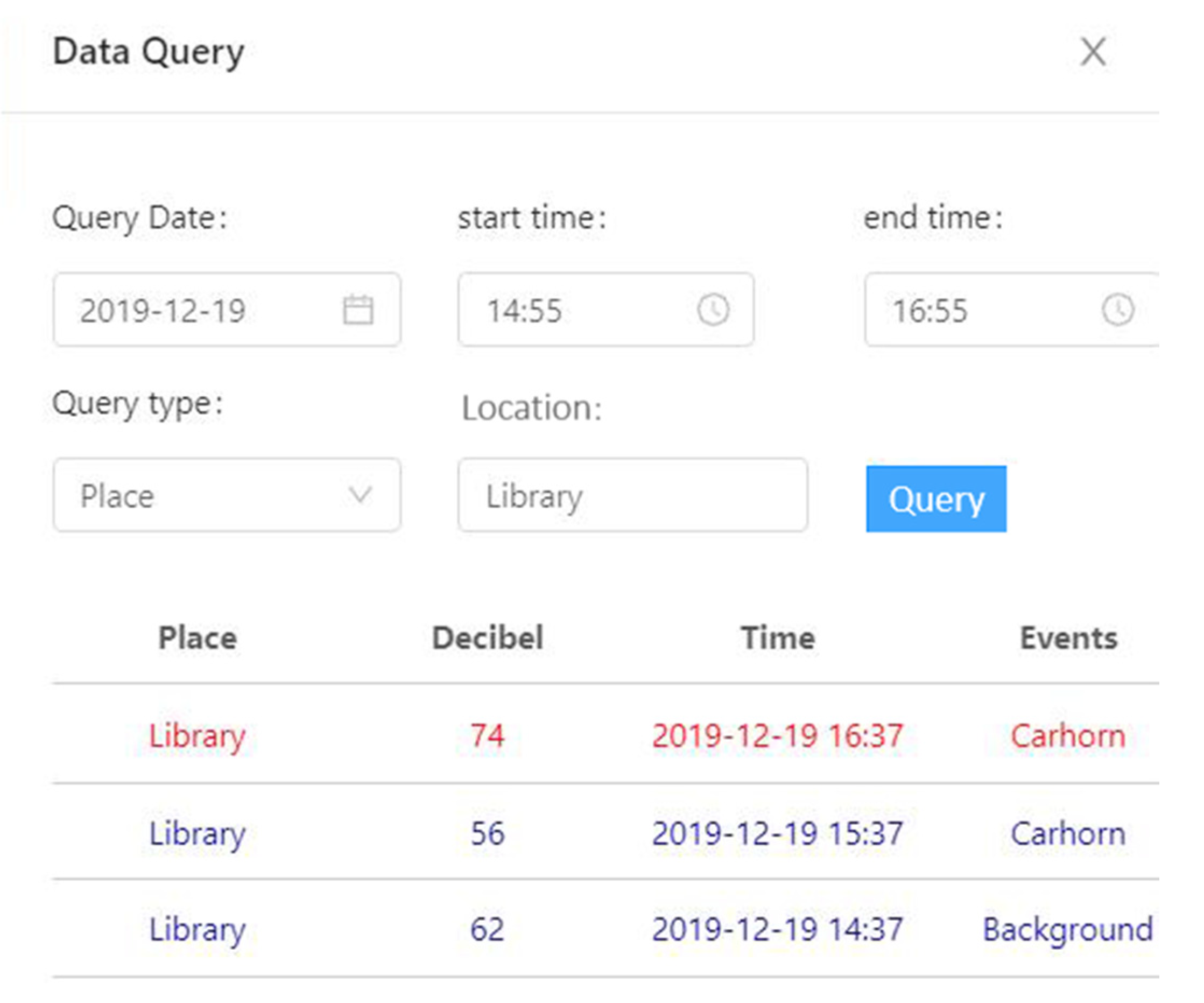
3.6. Monitoring Platform
4. Results and Analysis
4.1. Node-Based Analysis
4.1.1. Packaging for the Outdoor Deployment
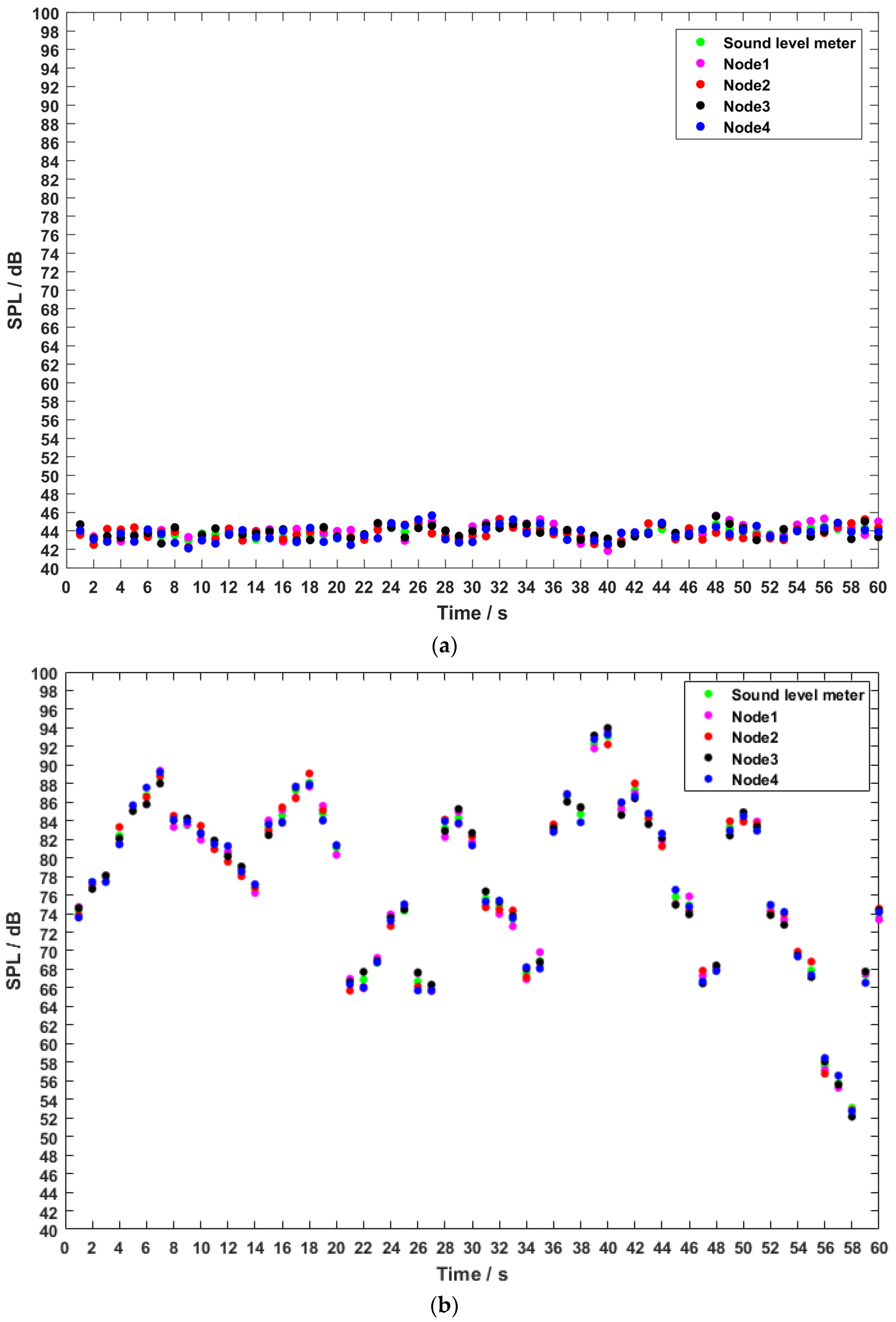
4.1.2. The Accuracy of the Sound Level
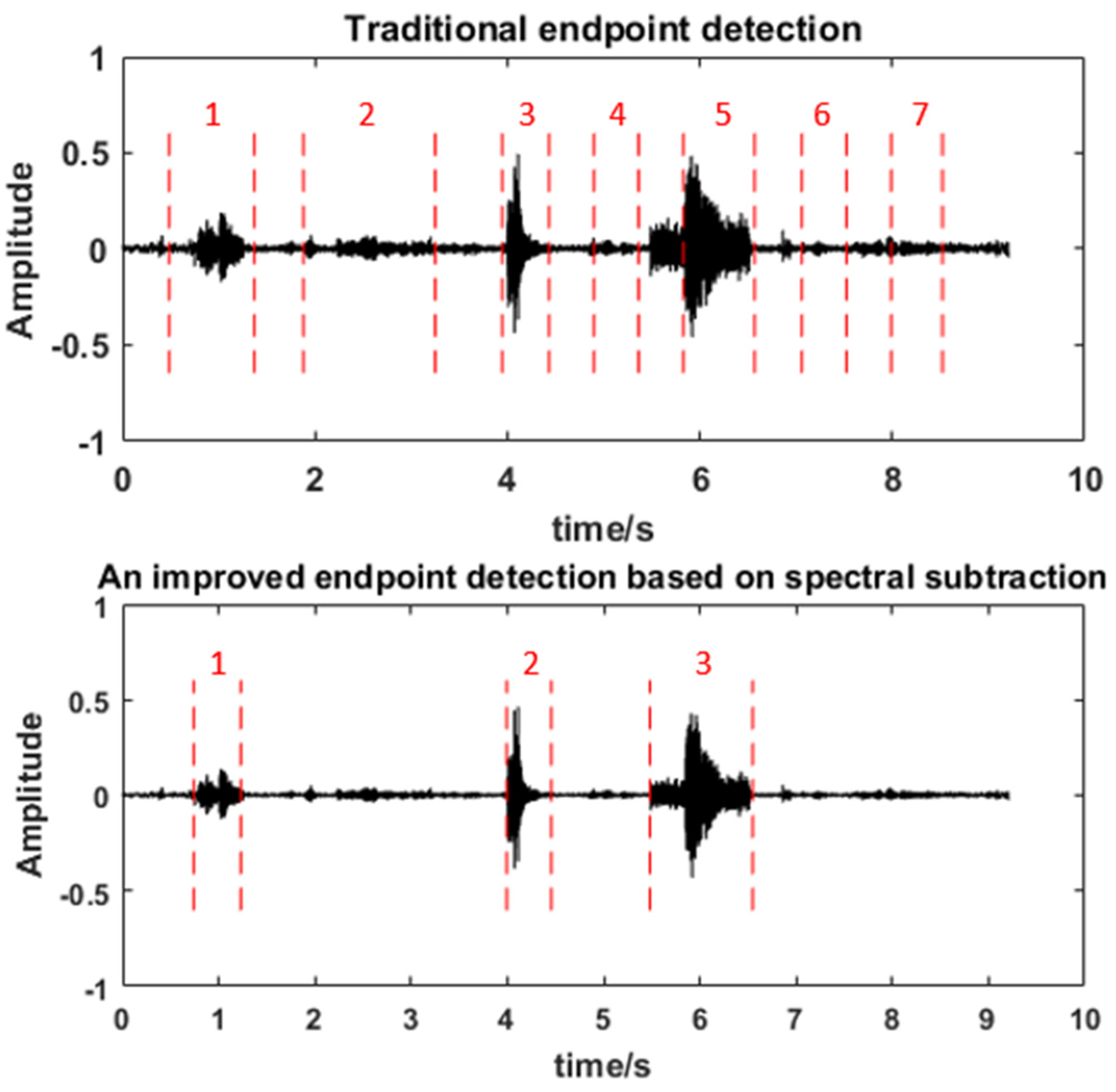
4.1.3. The Quality of Recording Data
4.1.4. The Reliability of Transmission
4.2. Performance Analysis of the CNN in this Work
4.3. WASN-Based Analysis in Real-Life Scenarios
4.3.1. The Recognition Accuracy Before and After Compression
4.3.2. The Recognition Accuracy of Audio Streaming
- (1)
- Recall: The capacity of the system to detect car horns only when they occur.
- (2)
- Precision: The capacity of the system to detect car horns. It is the ratio of true positives to the number of car horns.
- (3)
- F1-score: A harmonic average of model accuracy and recall.
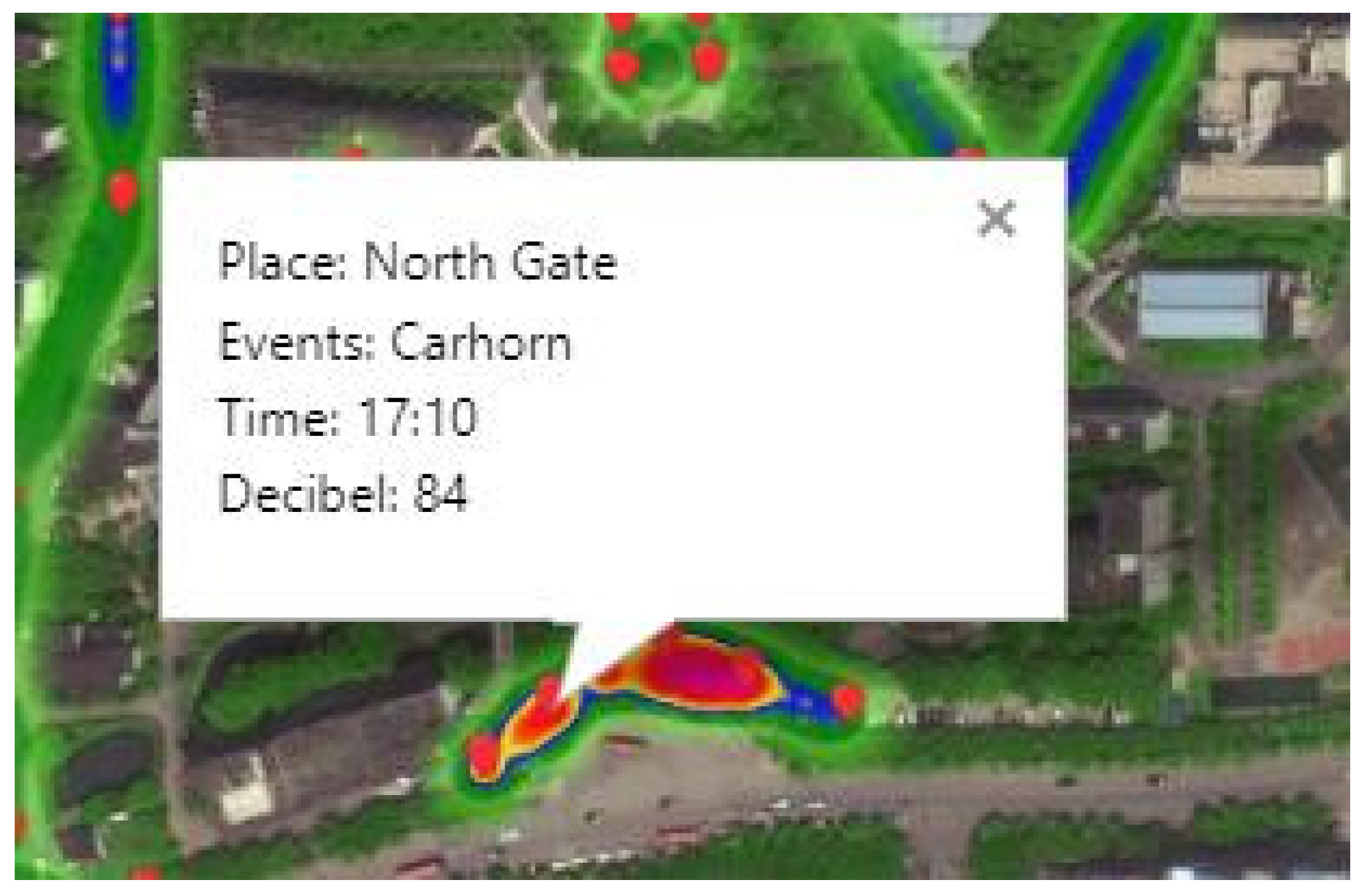
4.3.3. The Visualization of Monitoring Platform
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| WASN | Wireless Acoustic Sensor Network |
| CNNs | Convolutional Neural Networks |
| GIS | Geographic Information System |
| 3GPP | Third Generation Partnership Project |
| PCM | Pulse Code Modulation |
| ADPCM | Adaptive Differential Pulse Code Modulation |
| CPU | Central Processing Unit |
| GPU | Graphic Processing Unit |
| DRAM | Dynamic Random Access Memory |
| IDE | Integrated Development Environment |
| API | Application Programming Interface |
| MFCC | Mel Frequency Cepstrum Coefficient |
| DCT | Discrete Cosine Transform |
| ABS | Acrylonitrile Butadiene Styrene |
| SNR | Signal to Noise Ratio |
| RF | Random Forest |
| KNN | K-Nearest Neighbor |
| SVM | Support Vector Machine |
| URL | Uniform Resource Locator |
Appendix A
References
- Quinones, E.E.; Bustillo, C.F.; Mehrvar, M. A traffic noise model for road intersections in the city of Cartagena de Indias Colombia. Transp. Environ. 2016, 47, 149–161. [Google Scholar]
- Bulkin, V.; Khromulina, D.; Kirillov, N. Analysis of the Acoustically Noise Situation in an Urbanized Area. In the Presence of Vehicular and Industrial Noise. In Proceedings of the IOP Conference Series: Earth and Environmental Science, Surakarta, Indonesia, 6–7 November 2019; pp. 222–237. [Google Scholar]
- Hughes, J.; Yan, J.; Soga, K. Development of wireless sensor network using bluetooth low energy (BLE) for construction noise monitoring. Int. J. Smart Sens. Intell. Syst. 2015, 8, 1379–1405. [Google Scholar] [CrossRef] [Green Version]
- Hunashal, R.B.; Patil, Y.B. Assessment of noise pollution indices in the city of Kolhapur, India. Procedia-Soc. Behav. Sci. 2012, 37, 448–457. [Google Scholar] [CrossRef] [Green Version]
- Ilic, P.; Stojanovic, L.; Janjus, Z. Noise Pollution near Health Institutions. Qual. Life. 2018, 16, 1–2. [Google Scholar]
- Zamora, W.; Calafate, C.T.; Cano, J.C. Accurate ambient noise assessment using smartphones. Sensors 2017, 17, 917. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Aumond, P.; Lavandier, C.; Ribeiro, C. A study of the accuracy of mobile technology for measuring urban noise pollution in large scale participatory sensing campaigns. Appl. Acoust. 2017, 117, 219–226. [Google Scholar] [CrossRef]
- Garg, S.; Lim, K.M.; Lee, H.P. An averaging method for accurately calibrating smartphone microphones for environmental noise measurement. Appl. Acoust. 2019, 143, 222–228. [Google Scholar] [CrossRef]
- Hakala, I.; Kivela, I.; Ihalainen, J. Design of low-cost noise measurement sensor network: Sensor function design. In Proceedings of the First International Conference on Sensor Device Technologies and Applications (SENSORDEVICES 2010), Venice, Italy, 18–25 July 2010; pp. 172–179. [Google Scholar]
- Wang, C.; Chen, G.; Dong, R. Traffic noise monitoring and simulation research in Xiamen City based on the Environmental Internet of Things. Int. J. Sustain. Dev. World Ecol. 2013, 20, 248–253. [Google Scholar] [CrossRef]
- Bellucci, P.; Peruzzi, L.; Zambon, G. The Life Dynamap project: Towards the future of real time noise mapping. In Proceedings of the 22nd International Congress on Sound and Vibration (ICSV), Florence, Italy, 23–25 July 2015; pp. 12–16. [Google Scholar]
- Alías, F.; Alsina-Pagès, R.; Carrié, J.C. DYNAMAP: A low-cost wasn for real-time road traffic noise mapping. Proc. Tech. Acust. 2018, 18, 24–26. [Google Scholar]
- Nencini, L. DYNAMAP monitoring network hardware development. In Proceedings of the 22nd International Congress on Sound and Vibration (ICSV), Florence, Italy, 23–25 July 2015; pp. 12–16. [Google Scholar]
- Sevillano, X.; Socoró, J.C.; Alías, F. DYNAMAP—Development of Low Cost Sensors Networks for Real Time Noise Mapping. Noise Mapp. 2016, 3, 172–189. [Google Scholar] [CrossRef]
- Alías, F.; Alsina-Pagès, R. Review of Wireless Acoustic Sensor Networks for Environmental Noise Monitoring in Smart Cities. J. Sens. 2019. [CrossRef] [Green Version]
- Jakob, A.; Marco, G.; Stephanie, K. A distributed sensor network for monitoring noise level and noise sources in urban environments. In Proceedings of the 2018 IEEE 6th International Conference on Future Internet of Things and Cloud (FiCloud), Barcelona, Spain, 6–8 August 2018; pp. 318–324. [Google Scholar]
- Bello, J.P.; Silva, C. SONYC: A System for Monitoring, Analyzing, and Mitigating Urban Noise Pollution. Commun. Acm. 2019, 62, 68–77. [Google Scholar] [CrossRef]
- Oh, S.; Jang, T.; Choo, K.D. A 4.7 μW switched-bias MEMS microphone preamplifier for ultra-low-power voice interfaces. In Proceedings of the 2017 Symposium on VLSI Circuits, Kyoto, Japan, 5–8 June 2017; pp. 314–315. [Google Scholar]
- Nathan, G.; Britten, F.; Burnett, J. Sound Intensity Levels of Volume Settings on Cardiovascular Entertainment Systems in a University Wellness Center. Recreat. Sports J. 2017, 41, 20–26. [Google Scholar] [CrossRef]
- Zuo, J.; Xia, H.; Liu, S. Mapping urban environmental noise using smartphones. Sensors. 2016, 16, 1692. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rosao, V.; Aguileira, A. Method to calculate LAFmax noise map from LAeq noise maps, for roads and railways. In Proceedings of the INTER-NOISE and NOISE-CON Congress and Conference Proceedings, Madrid, Spain, 16–19 June 2019; pp. 5337–5345. [Google Scholar]
- Rana, R.; Chou, C.T.; Bulusu, N. Ear-Phone: A context-aware noise mapping using smart phones. Pervasive Mob. Comput. 2015, 17, 1–22. [Google Scholar] [CrossRef] [Green Version]
- Zhang, C.; Dong, M. An improved speech endpoint detection based on adaptive sub-band selection spectral variance. In Proceedings of the 2016 35th Chinese Control Conference (CCC), Chengdu, China, 27–29 July 2016; pp. 5033–5037. [Google Scholar]
- Zhang, Y.; Wang, K.; Yan, B. Speech endpoint detection algorithm with low signal-to-noise based on improved conventional spectral entropy. In Proceedings of the 2016 12th World Congress on Intelligent Control and Automation (WCICA), Guilin, China, 12–15 June 2016; pp. 3307–3311. [Google Scholar]
- Sayood, K. Introduction to Data Compression, 3rd ed.; Katey Bircher: Cambridge, MA, USA, 2017; pp. 47–53. [Google Scholar]
- Magno, M.; Vultier, F.; Szebedy, B. Long-term monitoring of small-sized birds using a miniaturized bluetooth-low-energy sensor node. In Proceedings of the 2017 IEEE SENSORS, Glasgow, UK, 29–31 October 2017; pp. 1–3. [Google Scholar]
- Zhao, D.; Ma, H.; Liu, L. Event classification for living environment surveillance using audio sensor networks. In Proceedings of the 2010 IEEE International Conference on Multimedia and Expo, Suntec City, Singapore, 23 September 2010; pp. 528–533. [Google Scholar]
- Salamon, J.; Bello, J.P. Deep convolutional neural networks and data augmentation for environmental sound classification. IEEE Signal Process. Lett. 2017, 24, 279–283. [Google Scholar] [CrossRef]
- Noriega, J.E.; Navarro, J.M. On the application of the raspberry Pi as an advanced acoustic sensor network for noise monitoring. Electronic 2016, 5, 74. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Jiang, H.; Li, C. Deep feature extraction and classification of hyperspectral images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef] [Green Version]
- Gemmeke, J.F.; Ellis, D.P.; Freedman, D. Audio set: An ontology and human-labeled dataset for audio events. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 776–780. [Google Scholar]
- Cheffena, M. Fall detection using smartphone audio features. IEEE J. Biomed. Health Inform. 2015, 20, 1073–1080. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Description | Material Cost |
|---|---|
| Acoustic sensor | $12.8 |
| Embedded processing board | $34.3 |
| Wireless transmission module | $28.5 |
| Solar panel | $10.9 |
| Num | Time | Coords (latitude, longitude) | IMEI | dB |
|---|---|---|---|---|
| 158 | 20190702143712 | 25.289270, 110.343036 | 0005 | 56 |
| 159 | 20190702143714 | 25.288436, 110.343405 | 0003 | 49 |
| 160 | 20190702143715 | 25.289270, 110.342036 | 0004 | 50 |
| Node Number | The Number of Data Received on the Server | Missing Rate |
|---|---|---|
| 1 | 2997 | 0.10% |
| 2 | 2995 | 0.16% |
| 3 | 2998 | 0.07% |
| 4 | 2997 | 0.10% |
| Methods | Gunshots | Screams | Car Horns |
|---|---|---|---|
| RF | 83% | 78.5% | 77% |
| KNN | 79% | 56.3% | 86.2% |
| SVM | 80.7% | 70.7% | 73.1% |
| CNN | 97.3% | 88.5% | 94% |
| Samples Size | Samples Length (ms) | Time-Consuming of Feature Extraction (ms) | Time-Consuming of Recognition (ms) | Time-Consuming of Extraction and Recognition (ms) |
|---|---|---|---|---|
| 10,000 | 139,120,15 | 182,100,1 | 2340 | 18,233,41 |
| Species | Car Horn | Background |
|---|---|---|
| Train | 1160 | 1052 |
| Test | 523 | 474 |
| C-V | 59 | 53 |
| Total | 1742 | 1579 |
| Car Horn | Background | |
|---|---|---|
| Car Horn | 491 | 32 |
| Background | 10 | 464 |
| Car Horn | Background | |
|---|---|---|
| Car Horn | 480 | 43 |
| Background | 9 | 465 |
| Metric | Result |
|---|---|
| TP | 71 |
| FP | 16 |
| FN | 3 |
| Recall | 95.9% |
| Precision | 81.6% |
| F1-score | 88.2% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, L.; Qin, H.; Song, X.; Wang, M.; Qiu, H.; Zhou, Z. Wireless Sensor Networks for Noise Measurement and Acoustic Event Recognitions in Urban Environments. Sensors 2020, 20, 2093. https://doi.org/10.3390/s20072093
Luo L, Qin H, Song X, Wang M, Qiu H, Zhou Z. Wireless Sensor Networks for Noise Measurement and Acoustic Event Recognitions in Urban Environments. Sensors. 2020; 20(7):2093. https://doi.org/10.3390/s20072093
Chicago/Turabian StyleLuo, Liyan, Hongming Qin, Xiyu Song, Mei Wang, Hongbing Qiu, and Zou Zhou. 2020. "Wireless Sensor Networks for Noise Measurement and Acoustic Event Recognitions in Urban Environments" Sensors 20, no. 7: 2093. https://doi.org/10.3390/s20072093
APA StyleLuo, L., Qin, H., Song, X., Wang, M., Qiu, H., & Zhou, Z. (2020). Wireless Sensor Networks for Noise Measurement and Acoustic Event Recognitions in Urban Environments. Sensors, 20(7), 2093. https://doi.org/10.3390/s20072093