1. Introduction
Linear feedback shift registers (LFSR) have always been a basic resource for the pseudorandom number generation (PRNG) due to their low cost implementation, the good statistical properties of the values produced and the simplicity of their mathematical model that allows a priori analysis of the behavior of the system [
1]. The uniform distribution of the generated numbers allows LFSR to be widely used in communication and cryptographic applications, as part of the core of CDMA systems [
2] and stream ciphers [
3] belonging to the security standards and protocols of wireless and mobile telecommunication systems such as Bluetooth [
4], IEEE 802.11 WLAN [
5], GSM [
6] and LTE [
7]. LFSR are also employed to design true random number generators (TRNG) [
8] in radio frequency identification (RFID) systems [
9].
On the other hand, quantum key distribution schemes (QKD) are evolving from the initial discrete variable proposals (DV-QKD) [
10] based on the transmission of polarized photons using non-orthogonal states towards continuous variable systems (CV-QKD) [
11] based in the transmission of coherent states which allow the use of standard communications components and, therefore, lower implementation cost. CV-QKD schemes employ Gaussian modulation to send random amplitude and phase values that must be generated following a Gaussian distribution [
12,
13,
14].
Although initially motivated by the potential cryptographic application, we explore in this paper the utilization of LFSR as a general purpose PRNG with Gaussian distribution instead of their native uniform distribution. Some authors have previously proposed Gaussian PRNG using LFSR. In 2010, Kang [
15] presented a method employing an LFSR of length
bits to generate pseudorandom numbers with
bits. The generation algorithm was based on an accumulator operated over decimated
M-bits numbers, producing a final period of
which yields on an oversize LFSR. More recently, in 2015, Condo et al [
16] have proposed a PRNG using permutations over the successive states of an LFSR. This generator, designed using a unique LFSR of length 17, reduces the cost of implementation. However, as the own authors claim, not all permutations can be applied. Furthermore, a high computational cost is required for the searching of valid permutations. Once these permutations have been applied in the PRNG, the numbers generated follow a Gaussian distribution according to the results of the normality tests. In other words, only when the tests results are greater than a given threshold, the permutation is considered a valid one.
All of these proposals are focused on the application of the central limit theorem (CLT) [
17] that states that the distribution of samples mean approximates a normal distribution, as the sample size becomes larger, assuming that all samples are identical in size, and regardless of the population distribution shape. In this case, the samples produced by LFSR follow a uniform distribution. The use of several of these sequences leads us to obtain an approximation of a Gaussian distribution by means of the sum of all of them. Some authors [
18] propose the utilization of several LFSR to generate different and independent uniform distributed sequences to be summed later. Other proposals Kang [
15] and Condo [
16] are based on a unique LFSR that produces all the sequences in order to decrease the global complexity of the PRNG.
Although the application of CLT is not the only method to generate Gaussian random numbers [
19], it will always be a reference to take in mind. In [
18], a comparison is performed among the hardware implementation of three of the best-known methods: CLT, Box–Muller algorithm [
20,
21] and polarization decision algorithm [
22]. The comparison reveals that the number of gates and other hardware resources are very similar, while the CLT, implemented in a field-programmable gate array (FPGA) using directly the numbers produced by several LFSR, showed worse results in the normality tests.
However, the proposals based on a unique LFSR require a lower implementation cost. For this reason, we present in this article a much simpler implementation of the CLT method, mainly oriented to a hardware implementation, following the same strategy than Kang [
15] and Condo et al [
16], that is, using only one LFSR. The proposal requires the same resources than Condo et al’s PRNG but overcomes the oversize of Kang’s PRNG [
15] and the inconvenient of Condo et al’s PRNG [
16] related to the searching algorithm for valid configurations and reduces its computational cost. It is achieved by means of rotations, instead of generic permutations, reducing the complexity of precomputation performed to obtain the valid configurations (rotations). This fact turns the proposal into a really usable PRNG.
Next
Section 1 and
Section 2, describe the fundamentals of the LFSR and the previous proposals on CLT implementations based on LFSR.
Section 3 presents the proposed PRNG based on LFSR rotations, while
Section 4 and
Section 5 contain the statistical tests applied to check the distribution of the generated numbers and the results of their application, respectively. In
Section 6, a further improvement of the proposed scheme is presented by means of two coefficients, computed by the simulated annealing algorithm that helps the generated values to be better adjusted to the normal distribution. Conclusions are presented in
Section 7.
2. Lfsr Fundamentals
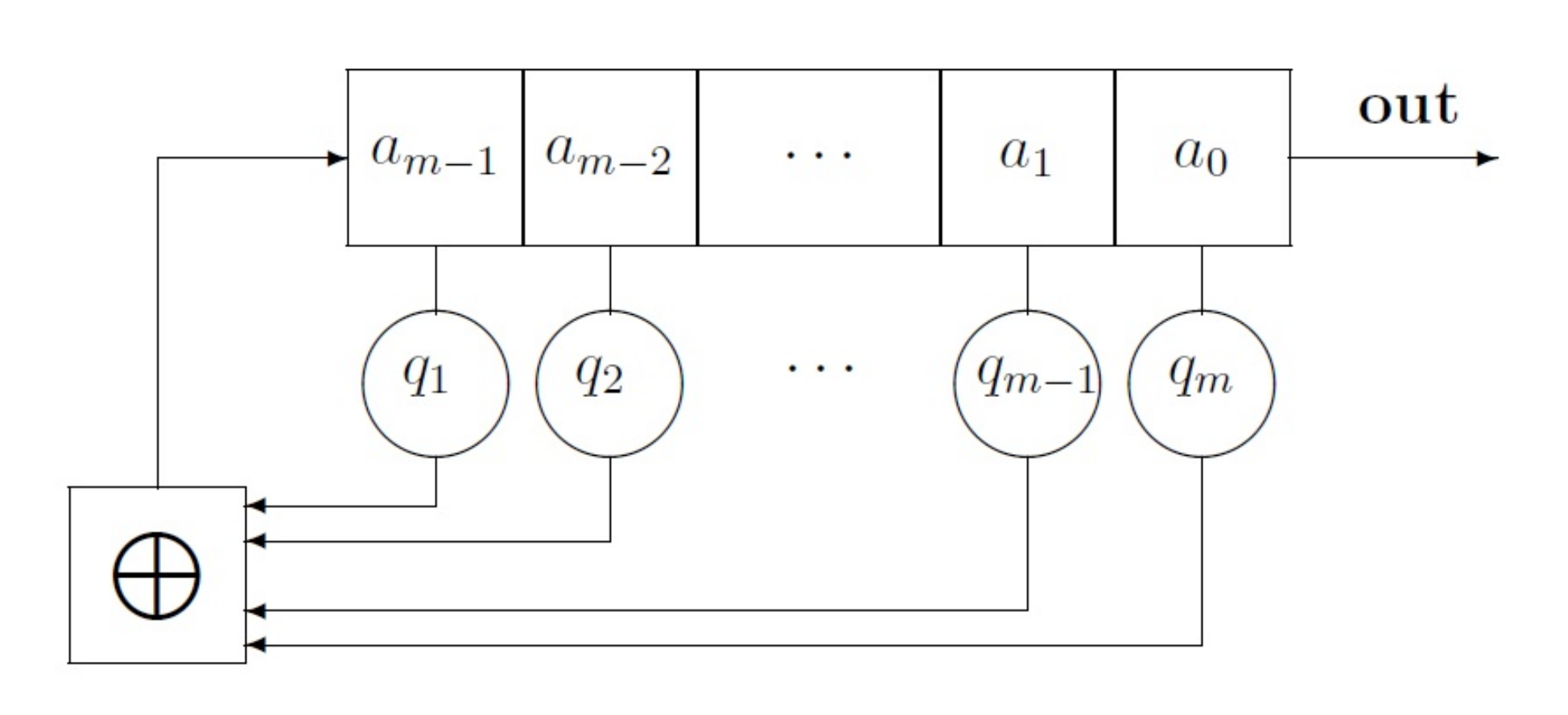
In this section the basic properties of the LFSR (see
Figure 1), and its generated sequences are described.
Definition 1. (cf. [3]) A linear feedback shift register (LFSR) of length m consists of m stages numbered , each capable of storing one bit and having one input and one output; and a clock which controls the movement of data. During each unit of time the following operations are performed: The content of stage 0 is output and forms part of the output sequence (out).
The content of stage i is moved to stage for each i where .
The new content content of state is the feedback bit which is calculated by adding together modulo 2 the previous contents of a fixed subset of stages .
From this definition follows that the value
is either 0 or 1 (
Figure 1) and the feedback bit
is the modulo 2 sum of the contents of those stages
i,
, for which
. As a consequence, the output sequence of the LFSR is
and is uniquely determined by the following recursion:
The behavior of the LFSR and the sequences generated can be performed by means of a polynomial whose coefficients are the values that represents the stages used to compute the feedback bit . For this reason, the LFSR is denoted , where is the connection polynomial.
The LFSR is said to be nonsingular if the degree of is m (that is, ). If the initial content of stage i is for each i, , then is called the initial state or seed of the LFSR.
On the other hand, the state of the LFSR at the time
t is denoted as
, which corresponds to the application of the recursion in the Equation (
1)
t consecutive times starting with the seed
Example 1. Consider the LFSR . If the initial state of the LFSR is , the output sequence is the zero sequence . For the initial state , the sequence has a length of 15. The Table 1 shows the successive states . Note that the right-most bit of each state constitutes the output sequence . Definition 2. (cf. [3]) An output sequenceA generated by an LFSR , is said to be periodic if there exits such that . Such is called period of the sequence. From this definition, the sequence of the example is a periodic sequence with period .
One of the advantages of LFSR is the mathematical model that allows one to predict the length of the sequences generated. The following definition and theorem states how and when the maximal length is reached by the sequences.
Definition 3. (cf. [3]) If is a connection polynomial of degree m, then is called a maximum length LFSR if the output sequence, with non-zero initial state, has period . This sequence is called m-sequence. Theorem 1. (cf. [1]) An output sequenceAgenerated by an LFSR is an m-sequence if and only if the connection polynomial is a primitive polynomial. The sequence length is independent of the initial state. Consequently, a primitive polynomial of degree m will generate a sequence of length and the LFSR will run through different nonzero states, that is, all possible nonzero states. Hence, if we consider each state as an m-bit pseudorandom number, we can say that LFSR produce numbers with uniform distribution.
Besides its maximal length, the
m-sequences have many desirable statistical properties that can be summarized in the three Golomb’s postulates [
1]. Given a periodic binary sequence
with period length
, it is said to be pseudoradom if the following postulates hold.
Distribution test. In every period, the number of ones is nearly equal to the number of zeros, more precisely the difference between the two numbers is at most 1:
Serial test. A sequence of consecutive ones is called a block and a sequence of consecutive zeros is called a gap. A run is either a block or a gap. In every period, one half of the runs has length 1, one quarter of the runs has length 2, and soon, as long as the number of runs indicated by these fractions is greater than 1. Moreover, for each of these lengths the number of blocks is equal to the number of gaps.
Autocorrelation test. The auto-correlation function
is two-valued.
3. Gaussian Generators Based on Lfsr
Several authors [
15,
16,
18] have proposed the utilization of LFSR to generate random numbers with Gaussian distribution performing direct implementations of the CLT, that is, producing several sequences of uniform distributed random numbers that are then summed to approximate to the normal distribution.
In order to obtain low cost implementations, Kang [
15] in 2010 and Condo [
16] in 2015 have proposed PRNG with only one LFSR. Kang’s proposal uses one LFSR to generate 4 different sequences of numbers that are summed to produce the final Gaussian random value. To do that, the state of an LFSR of
bits is splitted into
-bit numbers that are summed. The result of the addition is stored in an accumulator.
N clock cycles later the LFSR state is splitted again to produce a new input into the accumulator. This operation is repeated 8 times to finally obtain a
-bit pseudorandom number at the accumulator output. This numbers follow a Gaussian distribution. However, the PRNG is not efficient due to the oversizing required for the LFSR.
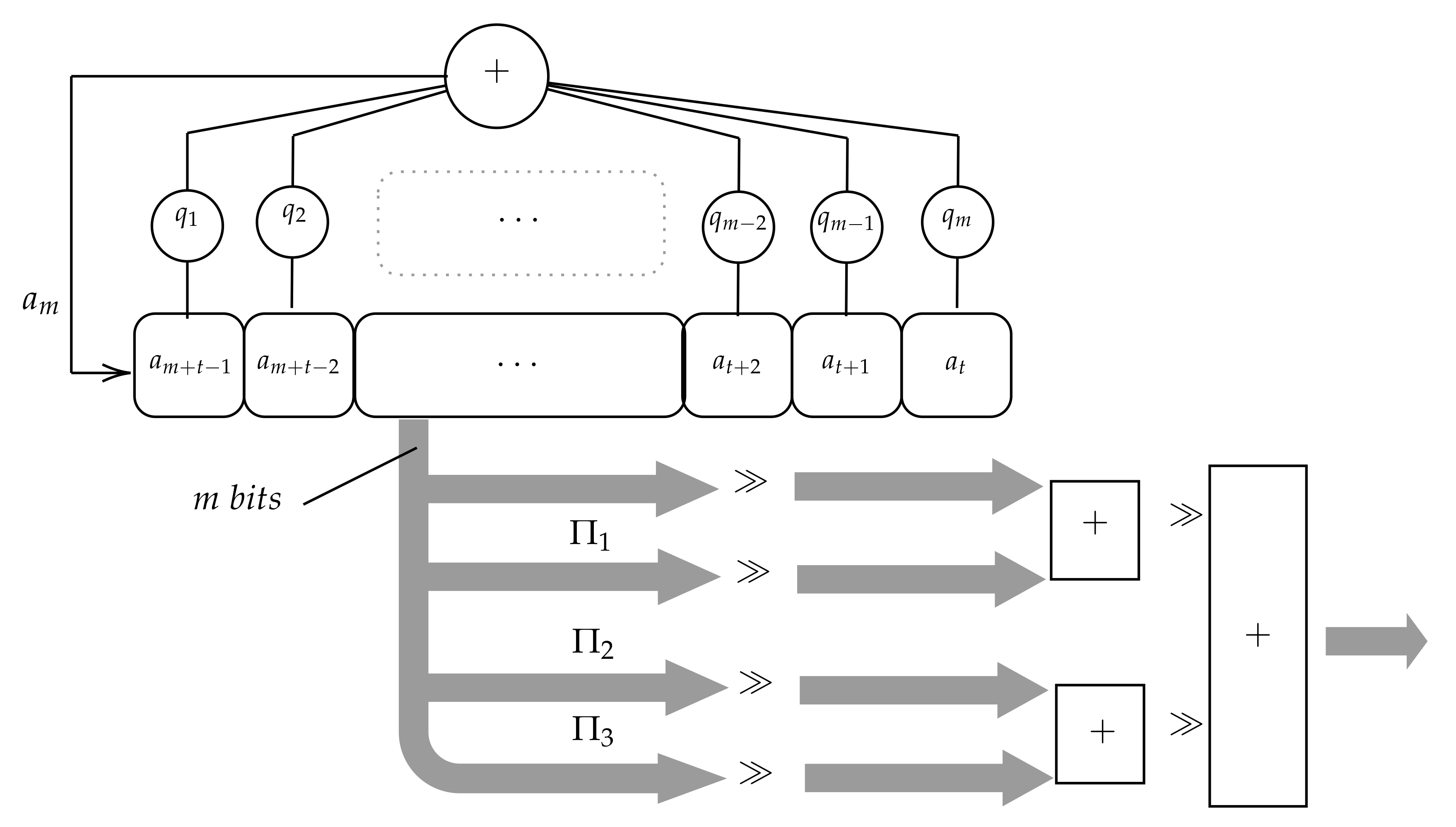
In 2015, Condo et al. [
16] proposed also a Gaussian PRNG using only one LFSR. In this case, instead of splitting the state, the system generates several uniform distributed sequences applying several permutations to every LFSR state. More precisely, two PRNG versions are proposed in [
16]. The first one, depicted in
Figure 2, produces four sequences of numbers or, in other words, four numbers at every instant
t: the LFSR state
and three additional numbers obtained applying three different permutations
,
,
to
. The second version produces only 3 sequences of numbers because it only applies two permutations
,
to every state
.
The sequences generated by the two versions have been analyzed in [
16] using only the LFSR
. However, the authors in [
16] have provided an estimation of the implementation cost for a generic PRNG with an LFSR of
N stages. This generic design requires one
bit register,
-bit adders (or
-bit adders for the second version) and J XOR gates, J being the number of stages to implement the LFSR feedback. Note also that permutations can be implemented by scrambling the order of the wires connecting the LFSR to the adder. Hence, they do not require additional hardware resources, such as gates or registers, thus helping to not increase the total implementation cost. As a result, this PRNG has lower cost than Kang’s PRNG [
15]. In order to generate
N-bit random numbers, the Kang’s PRNG requires one LFSR with
stages,
-bit adders and J XOR gates.
Despite the low implementation complexity, this generator has some drawbacks:
4. Gaussian Generator Based on Lfsr Rotations
This section describes the proposed generator that follows the same approach as in [
16]; i.e., the implementation of the CLT applied over samples with uniform distribution generated by means of only one LFSR. The main difference is that all sequences of numbers are generated from the unique LFSR by applying cyclic rotations (a particular case of permutations) instead of the generic permutations proposed in [
16]. The rotation is just a cyclic shift of the content of a given state of the LFSR. Considering the state as a binary vector, the rotation implies the shift to the right of every component. The right-most component is then moved to the left-most one. A
rotation implies
k single rotations. The rotations are always applies to the right. As a consequence, since the rotations, as well as permutations, can be implemented by scrambling the wires connecting the LFSR to the adder, the implementation cost is the same, one
register, 3 or
-bit adders and J XOR gates. However, the percentage of rotations that produce Gaussian random numbers is much greater than that of generic permutations. This fact allows one to randomly select the rotations with a high probability that they can be applied in the Gaussian generation. In this way, we solve the main drawback of the Condo et al PRNG.
The proposed generator is also designed in two different versions (the first using three rotations; the second only two) in order to facilitate the comparison to the PRNG in [
16]. In both versions, the LFSR is defined by a primitive polynomial
, hence producing an
sequence.
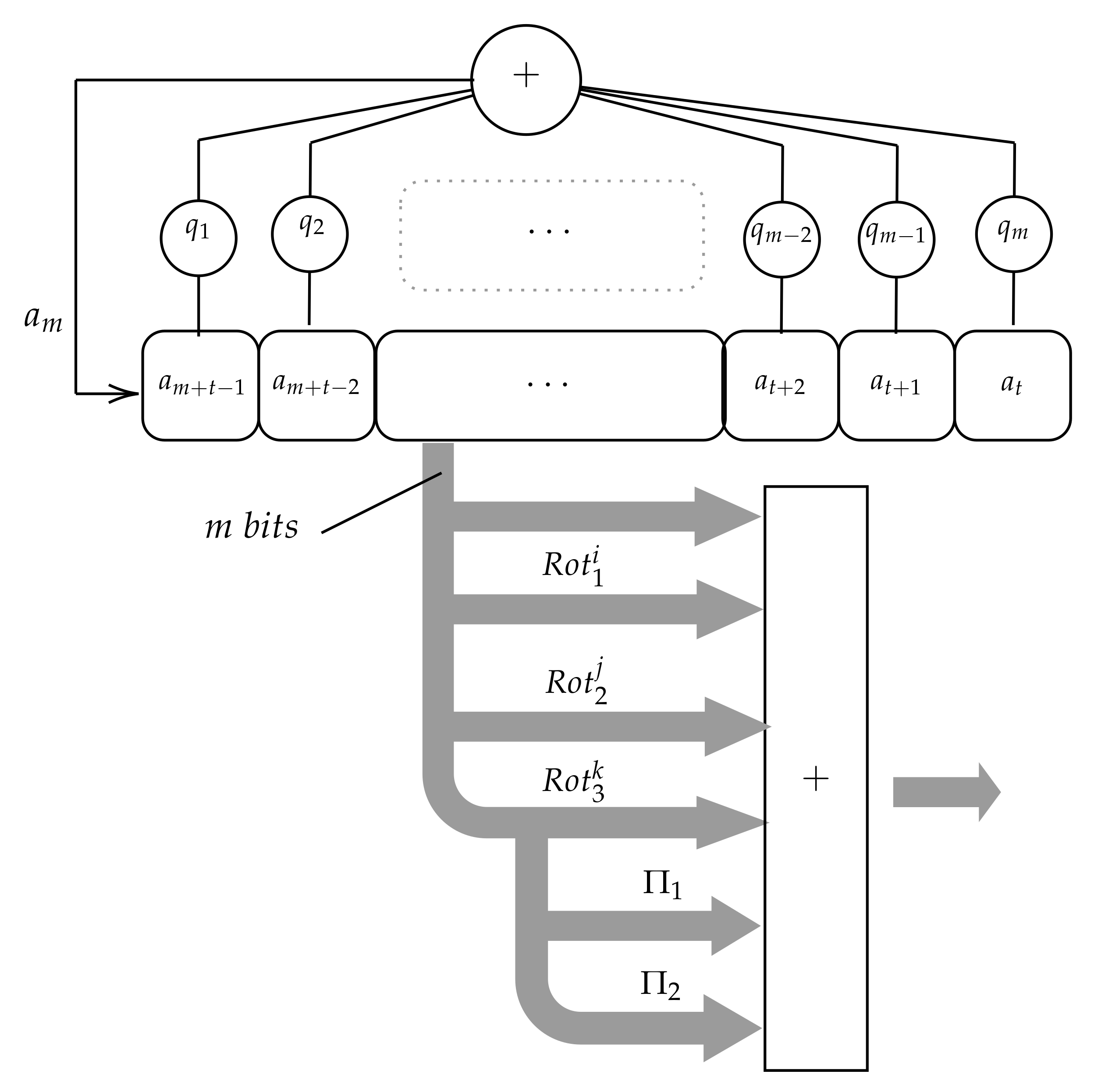
In
Figure 3, the first version is shown, in which the LFSR runs over
states. At every clock pulse t the state
is then considered as an
m-bit number and added to other three m-bit numbers produced by applying three rotations to the state
. The rotations are defined as follows.
Let’s consider an LFSR
where
is a primitive polynomial of degree
m in order to produce an
sequence, according to Theorem 1. For every LFSR state
a rotation function
is defined as the cyclic
k shifts to the right of the state content. Hence, as
we have
Note that . We denote the three rotations applied to the state in the first version of the PRNG, with without loss of generality. Similarly, we denote , the two rotations applied to the state in the second version of the PRNG, with without loss of generality.
Finally, the random number
produced at time
t by this generator is computed as follows:
where
D is the function that maps an
bit vector into a decimal value, that is,
It is also important to note that the sequence generated by the LFSR is always of length and independent from the seed, provided that is primitive and the seed is a nonzero state. This fact allows the utilization of any primitive polynomial and any nonzero seed and, hence, the turns the PRNG into a real usable one.
We should take into consideration the fact that these equations only appear in order to keep the mathematical formalism but it has not to be implemented in hardware since the electronic components works directly with the binary representation of the numbers.
It is also important to highlight that the sequence generated by the LFSR is always of length and independent from the seed, provided that is primitive and the seed is a nonzero state. This fact allows the utilization of any primitive polynomial and any nonzero seed and, hence, the turns the PRNG into a real usable one.
6. Improvements in the Results Obtained
In previous sections, we have shown that the proposed PRNGs imrove the results obtained by Condo [
16] and by Kang [
15]. The proposed PRNG has been designed as a direct particularization of Condo’s system, using only rotations instead of a generic permutation, trying to obtain the easiest solution (with the minimum modification) to the problems detected in [
16]. Nevertheless, the accuracy of the distribution in the proposed PRNG can be further improved, that is, the
p-values can be increased. Since the results are more stable in the version of three rotations we have decided to build on this version. Though the number of valid rotations is more or less the same, a substantial improvement in terms of their accuracy has been obtained. For this, an LFSR based on a primitive polynomial has been considered.
We consider a LSFR controlled by a primitive polynomial of degree
m,
. Let
be a state of the LFSR. Then we define the projections
and
as follows
and
Then, the random number is now generated as follows:
where the function
D is defined in the Equation (
5).
Figure 6 shows the implementation of this improvement. As one can see, the projections do not increase the implementation cost as they do not need gates or registers.
We have analyzed for all
n that verifies
. The number of valid rotations and variables is similar to those of the previous model, however the acceptance minimum level has been set to
which corresponds to a maximum estimation error below the treshold of
. The
Table 5 shows that values that have been achieved.
In this particular case where the projections have been applied, we have tested that, although the acceptance level has been set to we obtain more or less the same number of valid rotations. In other words, we have not only found a method that exceeds the models proposed to date, but also that the system has been refined to adapt the set of values to a Normal distribution. Although the system has given good experimental results, we have been able to verify that when we have increased the value of the degree of the polynomial in order to obtain a greater number of observations, then there was a decrease in the number of valid rotations.
Once these results have been obtained, we have tried to find a method that allows us to obtain a similar number of valid rotations similar to that obtained in the previous section and in the same way, if possible, increase the efficiency of the system. For this, we have used the simulated annealing method. The Simulated annealing method [
26] is a method for solving unconstrained and bound-constrained optimization problems. The method models the physical process of heating a material and then slowly lowering the temperature to decrease defects, thus minimizing the system energy.
At each iteration of the simulated annealing algorithm, a new point is randomly generated. The distance of the new point from the current point, or the extent of the search, is based on a probability distribution with a scale proportional to the temperature. The algorithm accepts all new points that lower the objective, but also, with a certain probability, points that raise the objective. By accepting points that raise the objective, the algorithm avoids being trapped in local minima, and is able to explore globally for more possible solutions. An annealing schedule is selected to systematically decrease the temperature as the algorithm proceeds. As the temperature decreases, the algorithm reduces the extent of its search to converge to a minimum.
To illustrate how this method has been implemented, we will illustrate the procedure through an example. If we take the case where the degree of the polynomial , we start with vectors of dimension 12 in which we are applying the method of rotations described in the previous section. Once this method has been applied, it has been determined which of the possible rotations has the highest coefficient and therefore a distribution of values closer to the normal distribution. In this case the values to be taken are those of , , , , . If we use this combination of rotations, a p test value close to is obtained. From this point on, this distribution of values will be taken as a fixed reference.
Once this distribution of values has been fixed, a function has been defined in which the values obtained by the projections, defined in Equations (
17) and (
18), are multiplied by two coeffcients
and
. Then the values have been obtained by working out the decimal sum defined by:
where the function
D is defined in the Equation (
5).
In order to apply the method, a function has been defined that depends on the sequence and the parameters of and and whose output will be the normal p-test value. This function is to which we will apply the simulated annealing method in order to minimize the value of this function. In the case where it has been obtained that . There has been a significant increase in the number of valid rotations and in the same way it has been achieved that they are much closer to the Normal distribution.
For other values of n as is the case in which it takes the values of are obtained following the same method the values for and are: and for and and for the case where , the remaining cases will be considered for future study.
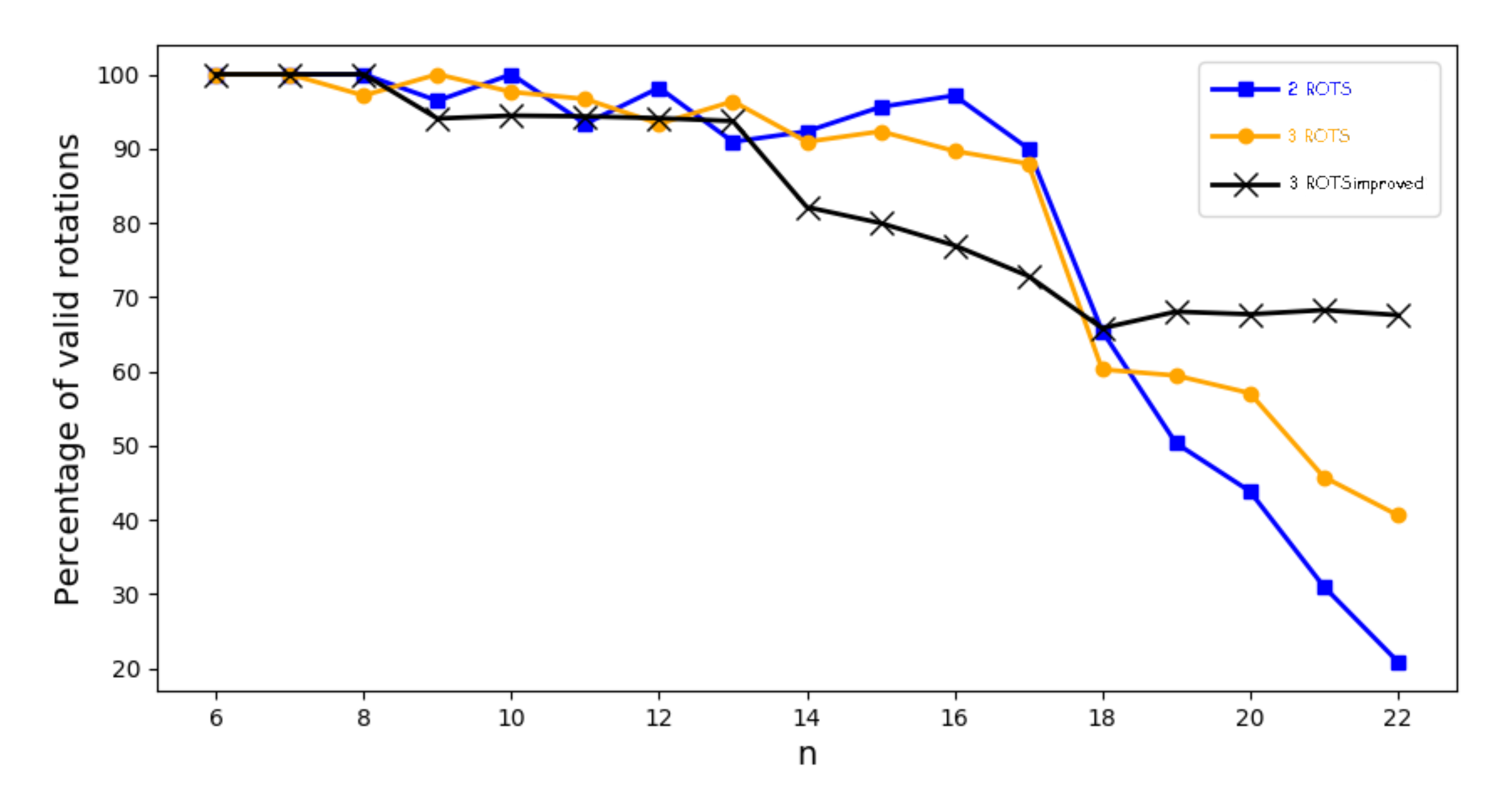
In
Figure 7 we can observe the evolution of the percentage of valid rotations for each degree of the primitive polynomial and for each model (2 rotations, 3 rotations and 3 rotations with 2 projections). As seen on the trend line with squares, representing the tendency for the 2 rotations model, the percentage of valid rotations decreases as we increase the degree of the primitive polynomial. The situation improves in the case of the trend line with circles where the 3 rotations model is analyzed. For primitive polynomials with small degree the situation is acceptable, however as the degree of the polynomial increases, the percentage of valid rotations decreases. This decrease is not as noticeable, however, adequate values are not obtained. Finally, in the trend line of the crosses representing the case of the 3 rotations and the 2 projections, it is observed that the percentages of valid rotations are acceptable and constant, even for large values of the degree of the primitive polynomial.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}