Keys for Action: An Efficient Keyframe-Based Approach for 3D Action Recognition Using a Deep Neural Network



Abstract
:1. Introduction
2. Related Work
2.1. Conventional Learning-Based Approaches
2.2. Deep-Learning-Based Approaches
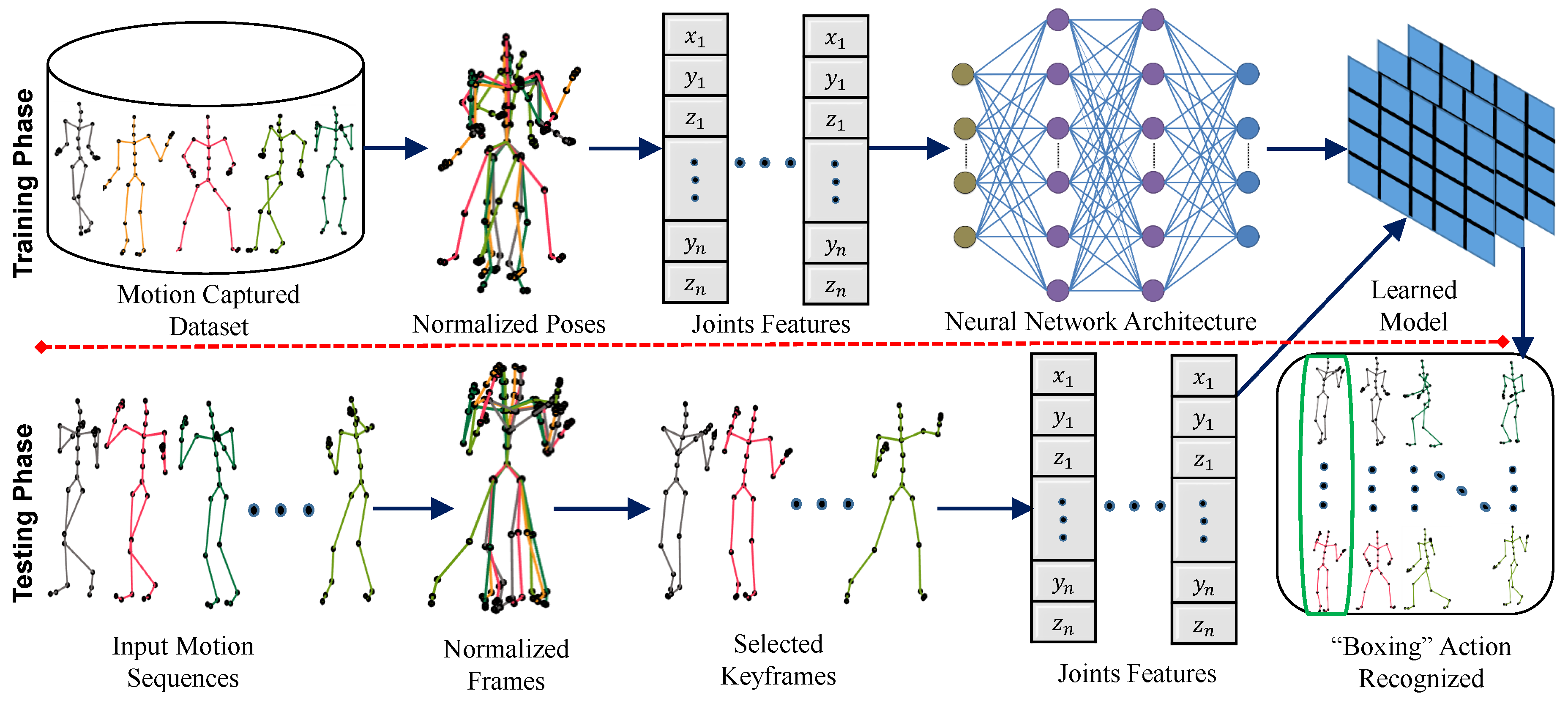
3. Methodology
3.1. Normalization
3.2. Keyframes
Implementation Details
| Algorithm 1 Keyframe Extraction Algorithm |
|
3.3. Deep Network
Implementation Details
3.4. Action Score
4. Experiments
4.1. Datasets
4.1.1. HDM05 Dataset
4.1.2. CMU Dataset
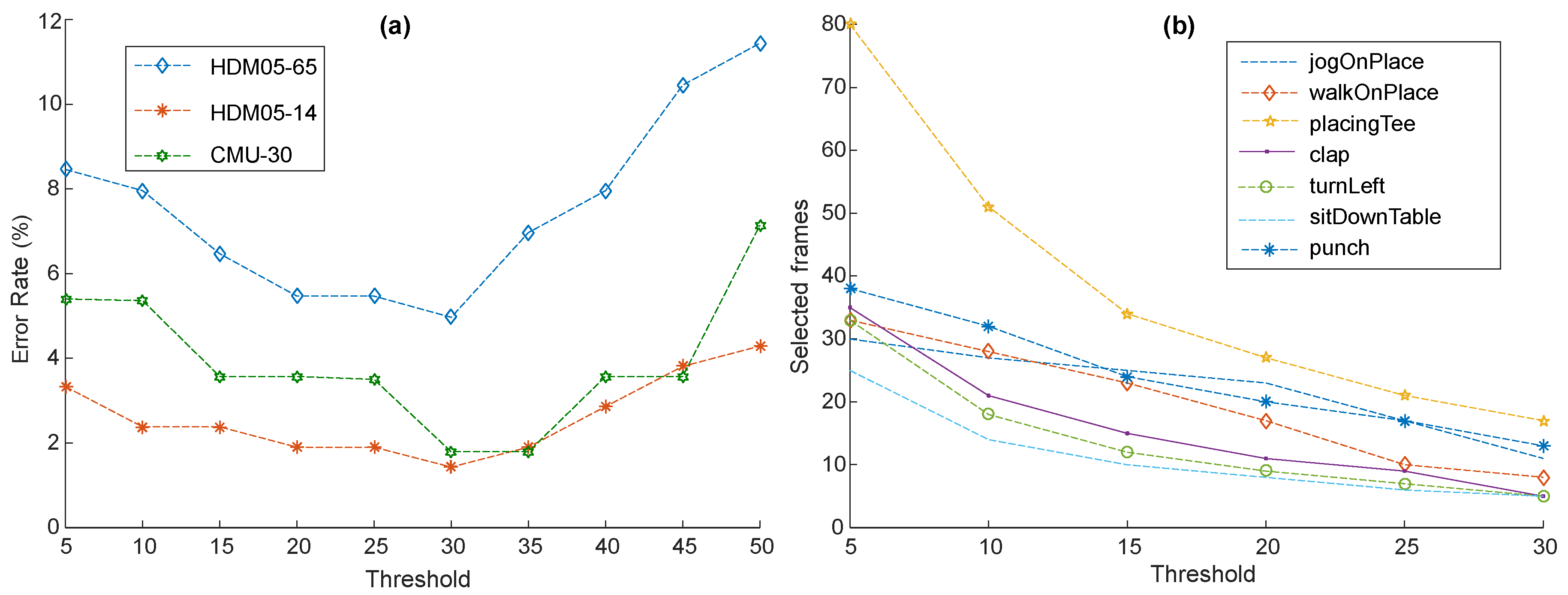
4.2. Parameters
4.2.1. Threshold
4.2.2. Deep Network
4.3. Comparison with State-of-the-Art Methods
4.3.1. Keyframes
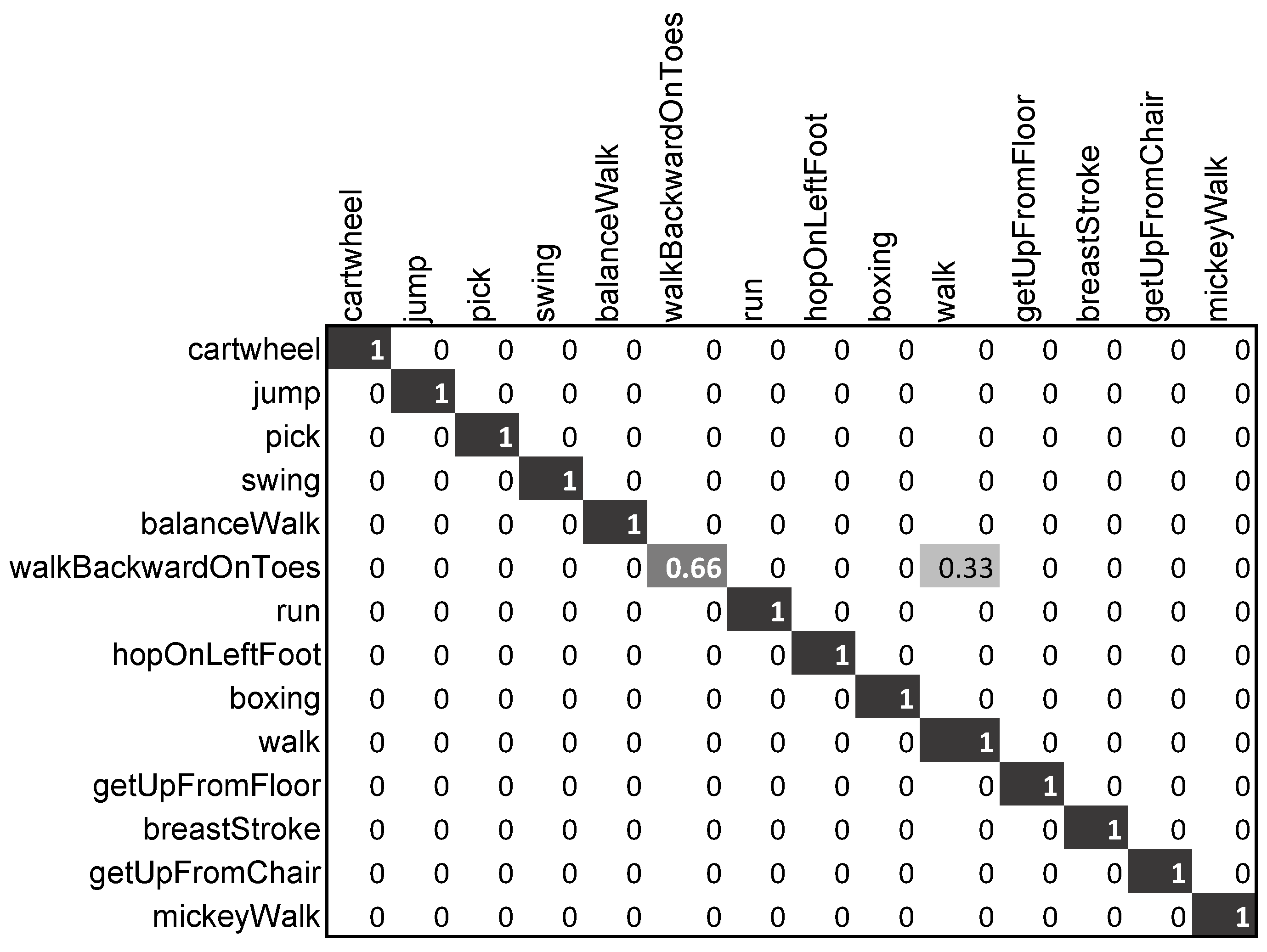
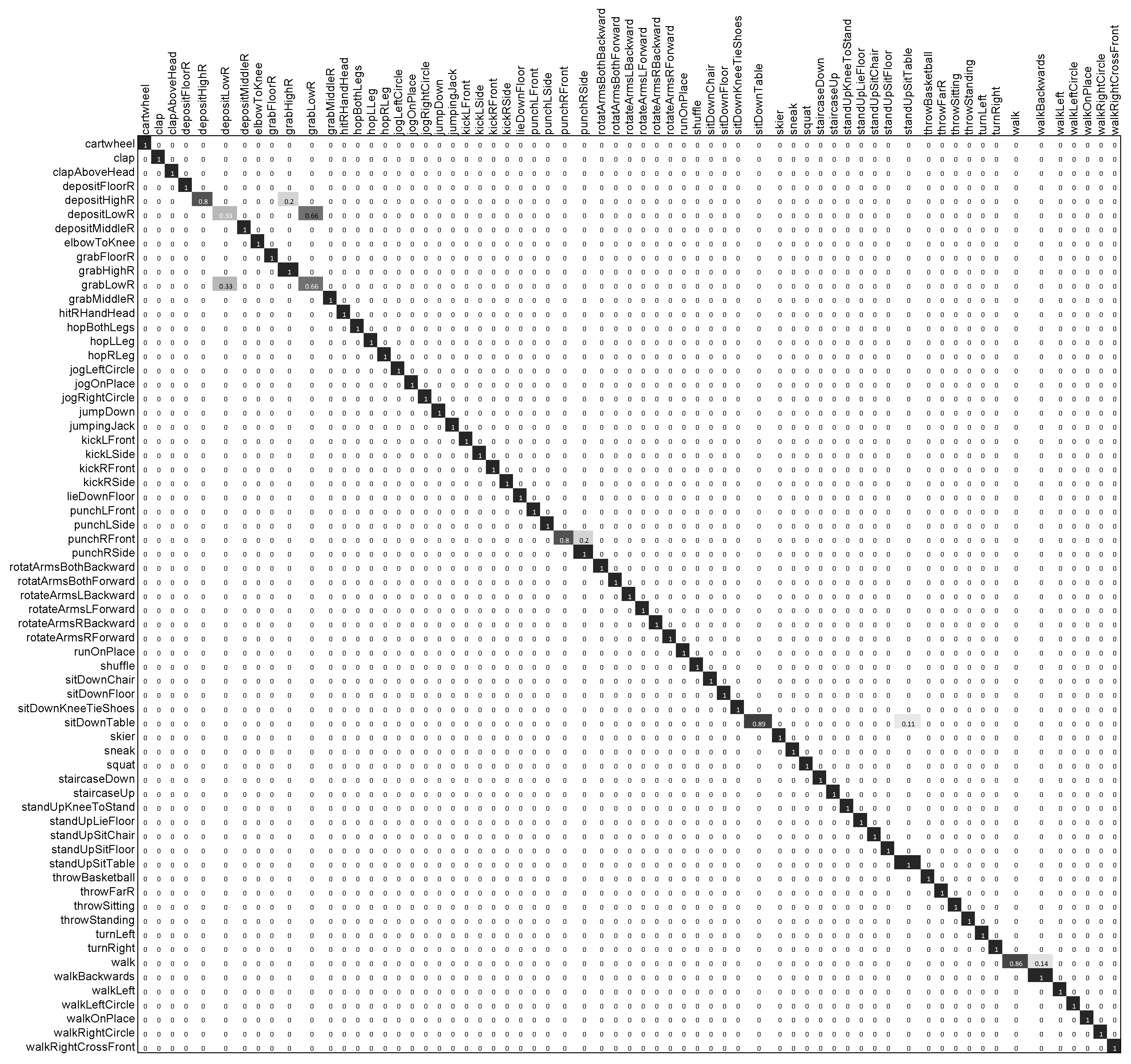
4.3.2. Action Recognition
Evaluation on HDM05-65
Evaluation on HDM05-14
Evaluation on CMU-30
Evaluation on CMU-14
4.3.3. Processing Time
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Sedmidubsky, J.; Elias, P.; Zezula, P. Effective and efficient similarity searching in motion capture data. Multimed. Tools Appl. 2018, 77, 12073–12094. [Google Scholar] [CrossRef]
- An, K.N.; Jacobsen, M.; Berglund, L.; Chao, E. Application of a magnetic tracking device to kinesiologic studies. J. Biomech. 1988, 21, 613–620. [Google Scholar] [CrossRef]
- VICONPEAK. Camera MX 40. Available online: http://www.vicon.com/products/mx40.html (accessed on 27 January 2020).
- PHASE SPACE INC. Impulse Camera. Available online: http://www.phasespace.com (accessed on 27 January 2020).
- Liu, Y.; Zhang, X.; Cui, J.; Wu, C.; Aghajan, H.; Zha, H. Visual analysis of child-adult interactive behaviors in video sequences. In Proceedings of the 2010 16th International Conference on Virtual Systems and Multimedia, Seoul, Korea, 20–23 October 2010; pp. 26–33. [Google Scholar]
- Raskar, R.; Nii, H.; deDecker, B.; Hashimoto, Y.; Summet, J.; Moore, D.; Zhao, Y.; Westhues, J.; Dietz, P.; Barnwell, J.; et al. Prakash: Lighting Aware Motion Capture Using Photosensing Markers and Multiplexed Illuminators. ACM Trans. Graph. 2007, 26, 36. [Google Scholar] [CrossRef]
- XSENS. Inertial Sensors. Available online: http://www.xsens.com (accessed on 25 November 2019).
- Lu, Y.; Wei, Y.; Liu, L.; Zhong, J.; Sun, L.; Liu, Y. Towards unsupervised physical activity recognition using smartphone accelerometers. Multimed. Tools Appl. 2017, 76, 10701–10719. [Google Scholar] [CrossRef]
- Vlasic, D.; Adelsberger, R.; Vannucci, G.; Barnwell, J.; Gross, M.; Matusik, W.; Popović, J. Practical Motion Capture in Everyday Surroundings. ACM Trans. Graph. 2007, 26, 35. [Google Scholar] [CrossRef]
- Yasin, H.; Iqbal, U.; Krüger, B.; Weber, A.; Gall, J. A Dual-Source Approach for 3D Pose Estimation from a Single Image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Wang, C.; Wang, Y.; Lin, Z.; Yuille, A.L.; Gao, W. Robust Estimation of 3D Human Poses from a Single Image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 24–27 June 2014. [Google Scholar]
- Dantone, M.; Leistner, C.; Gall, J.; Van Gool, L. Body Parts Dependent Joint Regressors for Human Pose Estimation in Still Images. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 2131–2143. [Google Scholar] [CrossRef] [Green Version]
- Yasin, H.; Krüger, B.; Weber, A. Model based Full Body Human Motion Reconstruction from Video Data. In Proceedings of the 6th International Conference on Computer Vision/Computer Graphics Collaboration Techniques and Applications, Berlin, Germany, 6–7 June 2013. [Google Scholar]
- Simo-Serra, E.; Ramisa, A.; Alenyà, G.; Torras, C.; Moreno-Noguer, F. Single Image 3D Human Pose Estimation from Noisy Observations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Rhode Island, RI, USA, 18–20 June 2012. [Google Scholar]
- Tautges, J.; Zinke, A.; Krüger, B.; Baumann, J.; Weber, A.; Helten, T.; Müller, M.; Seidel, H.P.; Eberhardt, B. Motion reconstruction using sparse accelerometer data. ACM Trans. Graph. 2011, 30, 1–12. [Google Scholar] [CrossRef]
- Riaz, Q.; Guanhong, T.; Krüger, B.; Weber, A. Motion Reconstruction Using Very Few Accelerometers and Ground Contacts. Graph. Models 2015, 79, 23–38. [Google Scholar] [CrossRef]
- Wang, L.; Huynh, D.Q.; Koniusz, P. A Comparative Review of Recent Kinect-Based Action Recognition Algorithms. IEEE Trans. Image Process. 2020, 29, 15–28. [Google Scholar] [CrossRef] [Green Version]
- Cho, K.; Chen, X. Classifying and visualizing motion capture sequences using deep neural networks. In Proceedings of the 2014 International Conference on Computer Vision Theory and Applications (VISAPP), Lisbon, Portugal, 5–8 January 2014; pp. 122–130. [Google Scholar]
- Du, Y.; Wang, W.; Wang, L. Hierarchical recurrent neural network for skeleton based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1110–1118. [Google Scholar]
- Ke, Q.; An, S.; Bennamoun, M.; Sohel, F.A.; Boussaïd, F. SkeletonNet: Mining Deep Part Features for 3-D Action Recognition. IEEE Signal Process. Lett. 2017, 24, 731–735. [Google Scholar] [CrossRef] [Green Version]
- Lv, N.; Feng, Z.; Ran, L.; Zhao, X. Action recognition of motion capture data. In Proceedings of the 2014 7th International Congress on Image and Signal Processing, Dalian, China, 14–16 October 2014; pp. 22–26. [Google Scholar]
- Gong, D.; Medioni, G.; Zhao, X. Structured Time Series Analysis for Human Action Segmentation and Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1414–1427. [Google Scholar] [CrossRef] [PubMed]
- Kim, H.; Kim, I. Human Activity Recognition as Time-Series Analysis. Math. Probl. Eng. 2015, 2015, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Li, K.; Fu, Y. Prediction of Human Activity by Discovering Temporal Sequence Patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1644–1657. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Tian, Y. EigenJoints-based action recognition using Naïve-Bayes-Nearest-Neighbor. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; pp. 14–19. [Google Scholar]
- Vemulapalli, R.; Arrate, F.; Chellappa, R. Human Action Recognition by Representing 3D Skeletons as Points in a Lie Group. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 24–27 June 2014; pp. 588–595. [Google Scholar]
- Ke, Q.; Bennamoun, M.; An, S.; Sohel, F.; Boussaid, F. A new representation of skeleton sequences for 3D action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017; pp. 4570–4579. [Google Scholar]
- Kapsouras, I.; Nikolaidis, N. Action recognition on motion capture data using a dynemes and forward differences representation. J. Vis. Commun. Image Represent. 2014, 25, 1432–1445. [Google Scholar] [CrossRef]
- Koniusz, P.; Cherian, A.; Porikli, F. Tensor Representations via Kernel Linearization for Action Recognition from 3D Skeletons. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 37–53. [Google Scholar]
- Yan, S.; Xiong, Y.; Lin, D. Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 7444–7452. [Google Scholar]
- Amor, B.B.; Su, J.; Srivastava, A. Action Recognition Using Rate-Invariant Analysis of Skeletal Shape Trajectories. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1–13. [Google Scholar] [CrossRef]
- Müller, M.; Röder, T.; Clausen, M.; Eberhardt, B.; Krüger, B.; Weber, A. Documentation Mocap Database HDM05; Technical Report CG-2007-2; Universität Bonn: Bonn, Germany, 2007. [Google Scholar]
- CMU. CMU Motion Capture Database. Available online: http://mocap.cs.cmu.edu/ (accessed on 20 September 2019).
- Wu, Q.; Xu, G.; Chen, L.; Luo, A.; Zhang, S. Human action recognition based on kinematic similarity in real time. PLoS ONE 2017, 12, e0185719. [Google Scholar] [CrossRef] [Green Version]
- Laraba, S.; Brahimi, M.; Tilmanne, J.; Dutoit, T. 3D skeleton-based action recognition by representing motion capture sequences as 2D-RGB images. Comput. Animat. Virtual Worlds 2017, 28, e1782. [Google Scholar] [CrossRef]
- Slama, R.; Wannous, H.; Daoudi, M.; Srivastava, A. Accurate 3D Action Recognition Using Learning on the Grassmann Manifold. Pattern Recogn. 2015, 48, 556–567. [Google Scholar] [CrossRef] [Green Version]
- Kadu, H.; Kuo, C.C.J. Automatic human mocap data classification. IEEE Trans. Multimed. 2014, 16, 2191–2202. [Google Scholar] [CrossRef]
- Moussa, M.M.; Hemayed, E.E.; El Nemr, H.A.; Fayek, M.B. Human action recognition utilizing variations in skeleton dimensions. Arab. J. Sci. Eng. 2018, 43, 597–610. [Google Scholar] [CrossRef]
- Vantigodi, S.; Babu, R.V. Real-time human action recognition from motion capture data. In Proceedings of the Fourth National Conference on Computer Vision, Pattern Recognition, Image Processing and Graphics (NCVPRIPG), Jodhpur, India, 18–21 December 2013; pp. 1–4. [Google Scholar]
- Hussein, M.E.; Torki, M.; Gowayyed, M.A.; El-Saban, M. Human Action Recognition Using a Temporal Hierarchy of Covariance Descriptors on 3D Joint Locations. In Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence, Beijing, China, 3–9 August 2013; pp. 2466–2472. [Google Scholar]
- Talha, S.A.W.; Fleury, A.; Ambellouis, S. Human Action Recognition from Body-Part Directional Velocity Using Hidden Markov Models. In Proceedings of the 16th IEEE International Conference on Machine Learning and Applications (ICMLA), Cancun, Mexico, 18–21 December 2017; pp. 1035–1040. [Google Scholar]
- Liang, Y.; Lu, W.; Liang, W.; Wang, Y. Action recognition using local joints structure and histograms of 3d joints. In Proceedings of the Tenth International Conference on Computational Intelligence and Security, Kunming, China, 15–16 November 2014; pp. 185–188. [Google Scholar]
- Ko, C.H.; Li, J.Y.; Lu, T.C. Automatic Key-frames Extraction of Humanoid Motions. J. Technol. 2017, 32, 39–47. [Google Scholar]
- Wu, S.; Wang, Z.; Xia, S. Indexing and retrieval of human motion data by a hierarchical tree. In Proceedings of the 16th ACM Symposium on Virtual Reality Software and Technology, Kyoto, Japan, 18–20 November 2009; pp. 207–214. [Google Scholar]
- Xiao, Q.; Song, R. Human motion retrieval based on statistical learning and bayesian fusion. PLoS ONE 2016, 11, e0164610. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Tian, Y. Effective 3d action recognition using eigenjoints. J. Visual Commun. Image Represent. 2014, 25, 2–11. [Google Scholar] [CrossRef]
- Kovar, L.; Gleicher, M. Automated extraction and parameterization of motions in large data sets. ACM Trans. Graph. 2004, 23, 559–568. [Google Scholar] [CrossRef] [Green Version]
- Wu, S.; Xia, S.; Wang, Z.; Li, C. Efficient motion data indexing and retrieval with local similarity measure of motion strings. Vis. Comput. 2009, 25, 499–508. [Google Scholar] [CrossRef]
- Barnachon, M.; Bouakaz, S.; Boufama, B.; Guillou, E. Ongoing human action recognition with motion capture. Pattern Recognit. 2014, 47, 238–247. [Google Scholar] [CrossRef]
- Baumann, J.; Wessel, R.; Krüger, B.; Weber, A. Action graph a versatile data structure for action recognition. In Proceedings of the 2014 International Conference on Computer Graphics Theory and Applications (GRAPP), Lisbon, Portugal, 5–8 January 2014; pp. 1–10. [Google Scholar]
- Xia, L.; Chen, C.; Aggarwal, J.K. View invariant human action recognition using histograms of 3D joints. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; pp. 20–27. [Google Scholar]
- Ofli, F.; Chaudhry, R.; Kurillo, G.; Vidal, R.; Bajcsy, R. Sequence of the Most Informative Joints (SMIJ). J. Vis. Commun. Image Represent. 2014, 25, 24–38. [Google Scholar] [CrossRef] [Green Version]
- Lillo, I.; Soto, A.; Niebles, J.C. Discriminative Hierarchical Modeling of Spatio-Temporally Composable Human Activities. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 24–27 June 2014; pp. 812–819. [Google Scholar]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.r.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N.; et al. Deep neural networks for acoustic modeling in speech recognition. IEEE Signal Process Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Liu, J.; Akhtar, N.; Mian, A. Skepxels: Spatio-temporal Image Representation of Human Skeleton Joints for Action Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Ijjina, E.P.; Mohan, C.K. Human action recognition based on motion capture information using fuzzy convolution neural networks. In Proceedings of the Eighth International Conference on Advances in Pattern Recognition (ICAPR), Kolkata, India, 4–7 January 2015; pp. 1–6. [Google Scholar]
- Pham, H.H.; Salmane, H.; Khoudour, L.; Crouzil, A.; Zegers, P.; Velastin, S.A. Spatio-Temporal Image Representation of 3D Skeletal Movements for View-Invariant Action Recognition with Deep Convolutional Neural Networks. Sensors 2019, 19, 1932. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Shahroudy, A.; Xu, D.; Wang, G. Spatio-Temporal LSTM with Trust Gates for 3D Human Action Recognition. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Zhang, S.; Liu, X.; Xiao, J. On Geometric Features for Skeleton-Based Action Recognition Using Multilayer LSTM Networks. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 148–157. [Google Scholar]
- Veeriah, V.; Zhuang, N.; Qi, G.J. Differential Recurrent Neural Networks for Action Recognition. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 13–16 December 2015; pp. 4041–4049. [Google Scholar]
- Tang, Y.; Tian, Y.; Lu, J.; Li, P.; Zhou, J. Deep Progressive Reinforcement Learning for Skeleton-Based Action Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Elias, P.; Sedmidubsky, J.; Zezula, P. Motion images: An effective representation of motion capture data for similarity search. In Proceedings of the International Conference on Similarity Search and Applications, Glasgow, UK, 12–14 October 2015; pp. 250–255. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
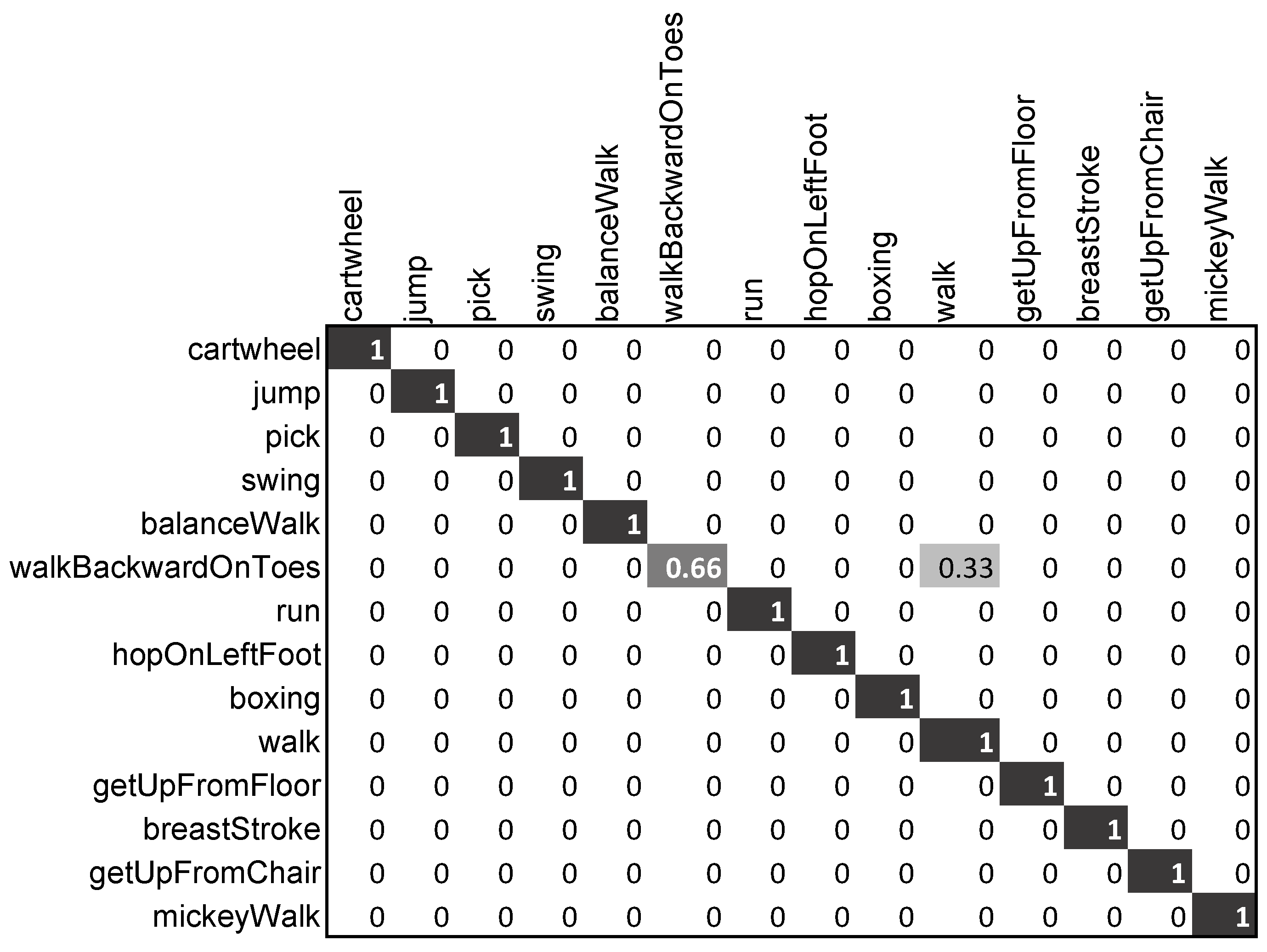{kind=link}
| Input Layer | Hidden Layer 1 | Hidden Layer 2 | Hidden Layer 3 | Output Layer | Accuracy (%) |
|---|---|---|---|---|---|
| 93 | 75 | - | - | 65 | 89.55% |
| 93 | 100 | - | - | 65 | 90.54% |
| 93 | 125 | - | - | 65 | 91.04% |
| 93 | 150 | - | - | 65 | 92.53% |
| 93 | 175 | - | - | 65 | 92.53% |
| 93 | 200 | - | - | 65 | 93.03% |
| 93 | 225 | - | - | 65 | 93.53% |
| 93 | 250 | - | - | 65 | 93.53% |
| 93 | 275 | - | - | 65 | 93.03% |
| 93 | 300 | - | - | 65 | 93.03% |
| 93 | 75 | 75 | - | 65 | 91.54% |
| 93 | 75 | 80 | - | 65 | 91.54% |
| 93 | 75 | 85 | - | 65 | 92.04% |
| 93 | 75 | 90 | - | 65 | 92.04% |
| 93 | 80 | 75 | - | 65 | 92.04% |
| 93 | 80 | 80 | - | 65 | 93.53% |
| 93 | 80 | 85 | - | 65 | 93.53% |
| 93 | 80 | 90 | - | 65 | 93.03% |
| 93 | 85 | 75 | - | 65 | 92.53% |
| 93 | 85 | 80 | - | 65 | 95.14% |
| 93 | 85 | 85 | - | 65 | 93.53% |
| 93 | 85 | 90 | - | 65 | 93.53% |
| 93 | 90 | 75 | - | 65 | 92.04% |
| 93 | 90 | 80 | - | 65 | 94.53% |
| 93 | 90 | 85 | - | 65 | 92.53% |
| 93 | 90 | 90 | - | 65 | 92.04% |
| 93 | 85 | 80 | 75 | 65 | 93.53% |
| 93 | 85 | 80 | 80 | 65 | 94.03% |
| 93 | 85 | 80 | 85 | 65 | 94.03% |
| 93 | 85 | 80 | 90 | 65 | 93.53% |
| Motions | (i) All Frames | (ii) Keyframes | (iii) | (iv) | ||||
|---|---|---|---|---|---|---|---|---|
| Frames | Acc. | Frames | Acc. | Frames | Acc. | Frames | Acc. | |
| standUpLie | 327 | 50% | 93 | 100% | 93 | 40% | 186 | 50% |
| lieDownFloor | 277 | 50% | 81 | 100% | 81 | 50% | 162 | 50% |
| throwStandingHighR | 239 | 66.66% | 98 | 100% | 98 | 69.97% | 196 | 66.66% |
| standUpSitChair | 172 | 50% | 31 | 100% | 31 | 55% | 62 | 50% |
| grabMiddleR | 151 | 66.66% | 35 | 100% | 35 | 59.99% | 70 | 69.94% |
| depositMiddleR | 142 | 100% | 20 | 100% | 20 | 70% | 40 | 100% |
| sitDownTable | 117 | 50% | 11 | 100% | 11 | 55% | 22 | 40% |
| standUpSitTable | 177 | 100% | 24 | 100% | 24 | 90% | 48 | 80% |
| grabLowR | 186 | 66.66% | 47 | 66.66% | 47 | 43.32% | 94 | 39.97% |
| turnLeft | 145 | 100% | 29 | 100% | 29 | 79.99% | 58 | 100% |
| punchLFront | 226 | 100% | 77 | 100% | 77 | 85% | 154 | 97.75% |
| sitDownFloor | 159 | 100% | 54 | 100% | 54 | 75% | 108 | 100% |
| depositLowR | 224 | 33.33% | 52 | 33.33% | 52 | 33.33% | 104 | 33.33% |
| squat | 536 | 100% | 89 | 100% | 89 | 98.57% | 178 | 100% |
| elbowToKnee | 409 | 100% | 162 | 100% | 162 | 100% | 324 | 100% |
| Dataset | Approach | Algorithm | Features | Training | Accuracy |
|---|---|---|---|---|---|
| HDM05-65 | Du et al. [19] | HBRNN-L | NT | ||
| HURNN-L | NT | ||||
| DBRNN-L | NT | ||||
| DURNN-L | NT | ||||
| Cho et al. [18] | Hybrid MLP | PO+TD | |||
| Hybrid MLP | PO+TD | ||||
| Hybrid MLP | PO+TD | ||||
| Hybrid MLP | PO+TD+NT | ||||
| MLP | PO+TD | ||||
| Our approach | DNN | NT+Keyframes | |||
| Cho et al. [18] | SVM | PO+TD+NT | |||
| Hybrid MLP | PO+TD+NT | ||||
| SVM | PO+TD | ||||
| MLP | PO+TD+NT | ||||
| Hybrid MLP | PO+TD+NT | ||||
| Du et al. [19] | DBRNN-T | NT | |||
| DURNN-T | NT | ||||
| Sedmidubsky et al. [1] | CNN+KNN | NT | |||
| Cho et al. [18] | ELM | PO+TD+NT | |||
| ELM | PO+TD | ||||
| HDM05-14 | Our approach | DNN | NT+Keyframes | ||
| Sedmidubsky et al. [1] | CNN+KNN | NT | |||
| Elias et al. [62] | CNN+KNN | NT | |||
| CMU-30 | Kadu and Kuo [37] | Two-Step SVM Fusion | TSVQ | ||
| Our approach | DNN | NT+Keyframes | |||
| Kadu and Kuo [37] | Two-Step Score Fusion | TSVQ | |||
| Pose-Histogram Classifier | B-PL04 | ||||
| B-PL06 | |||||
| Motion-String Similarity | A-SL12 | ||||
| A-SL13 | |||||
| Pose-Histogram Classifier | B-PL05 | ||||
| B-PL03 | |||||
| Motion-String Similarity | A-ML12 | ||||
| A-ML13 | |||||
| CMU-14 | Our approach | DNN | NT+Keyframes | ||
| Wu et al. [44]* | Hierarchical Tree | 3D Trajectories | |||
| Wu et al. [48]* | Smith–Waterman | 3D Trajectories |
| Motion Categories | A-ML12 | A-ML13 | A-SL12 | A-SL13 | B-PL03 | B-PL04 | B-PL05 | B-PL06 | (C) | (D) | Ours |
|---|---|---|---|---|---|---|---|---|---|---|---|
| run(27) | 96% | 96% | 100% | 96% | 96% | 100% | 96% | 96% | 100% | 100% | 100% |
| walk(47) | 85% | 85% | 97% | 100% | 97% | 97% | 97% | 97% | 100% | 100% | 100% |
| forwardJump(9) | 88% | 88% | 88% | 100% | 88% | 88% | 77% | 100% | 100% | 100% | 100% |
| forwardDribble(5) | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% |
| cartWheel(5) | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% |
| kickball(6) | 100% | 100% | 100% | 100% | 83% | 83% | 83% | 83% | 100% | 100% | 100% |
| boxing(7) | 0% | 0% | 85% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% |
| mickeyWalk(7) | 100% | 100% | 100% | 100% | 85% | 100% | 100% | 100% | 100% | 100% | 100% |
| sitAndStandUp(5) | 80% | 80% | 100% | 100% | 100% | 100% | 100% | 80% | 100% | 100% | 100% |
| laugh(6) | 66% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% |
| sweepFloor(5) | 40% | 40% | 100% | 100% | 80% | 100% | 100% | 100% | 100% | 100% | 100% |
| washWindows(5) | 640% | 60% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% |
| climbLadder(5) | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% |
| steps(7) | 57% | 85% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% |
| eating(5) | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% |
| tiptoe(5) | 100% | 60% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% |
| pickBoxBendWaist(6) | 100% | 100% | 83% | 100% | 83% | 83% | 100% | 100% | 100% | 100% | 100% |
| limp(5) | 100% | 80% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% |
| balancingWalk(12) | 83% | 75% | 100% | 100% | 83% | 100% | 91% | 91% | 100% | 100% | 100% |
| getUpFromChair(5) | 80% | 80% | 100% | 80% | 80% | 100% | 100% | 60% | 100% | 100% | 100% |
| breastStroke(6) | 50% | 16% | 83% | 83% | 100% | 100% | 83% | 83% | 83% | 100% | 100% |
| hopOnLeftFoot(6) | 66% | 100% | 100% | 100% | 100% | 83% | 100% | 100% | 100% | 100% | 100% |
| bouncyWalk(6) | 66% | 66% | 100% | 100% | 50% | 66% | 83% | 100% | 100% | 100% | 75% |
| marching(10) | 100% | 100% | 100% | 90% | 100% | 100% | 100% | 100% | 100% | 100% | 100% |
| rhymeTeaPot(16) | 81% | 81% | 75% | 75% | 75% | 87% | 87% | 87% | 75% | 93% | 100% |
| rhymeCockRobin(10) | 60% | 40% | 86% | 86% | 93% | 86% | 80% | 100% | 100% | 100% | 100% |
| swing(10) | 100% | 100% | 90% | 100% | 100% | 100% | 100% | 100% | 100% | 100% | 100% |
| placingTee(5) | 100% | 100% | 100% | 80% | 80% | 80% | 100% | 80% | 100% | 100% | 100% |
| salsaDance(15) | 86% | 73% | 100% | 95% | 100% | 100% | 100% | 100% | 100% | 100% | 100% |
| getUpFromFloor(10) | 80% | 80% | 100% | 100% | 80% | 100% | 100% | 80% | 100% | 100% | 100% |
| Total(278) | 82.3% | 80.5% | 95.6% | 95.6% | 92.8% | 95.6% | 95.3% | 95.6% | 98.2% | 99.6% | 99.3% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yasin, H.; Hussain, M.; Weber, A. Keys for Action: An Efficient Keyframe-Based Approach for 3D Action Recognition Using a Deep Neural Network. Sensors 2020, 20, 2226. https://doi.org/10.3390/s20082226
Yasin H, Hussain M, Weber A. Keys for Action: An Efficient Keyframe-Based Approach for 3D Action Recognition Using a Deep Neural Network. Sensors. 2020; 20(8):2226. https://doi.org/10.3390/s20082226
Chicago/Turabian StyleYasin, Hashim, Mazhar Hussain, and Andreas Weber. 2020. "Keys for Action: An Efficient Keyframe-Based Approach for 3D Action Recognition Using a Deep Neural Network" Sensors 20, no. 8: 2226. https://doi.org/10.3390/s20082226
APA StyleYasin, H., Hussain, M., & Weber, A. (2020). Keys for Action: An Efficient Keyframe-Based Approach for 3D Action Recognition Using a Deep Neural Network. Sensors, 20(8), 2226. https://doi.org/10.3390/s20082226