Multi-View Visual Question Answering with Active Viewpoint Selection


Abstract
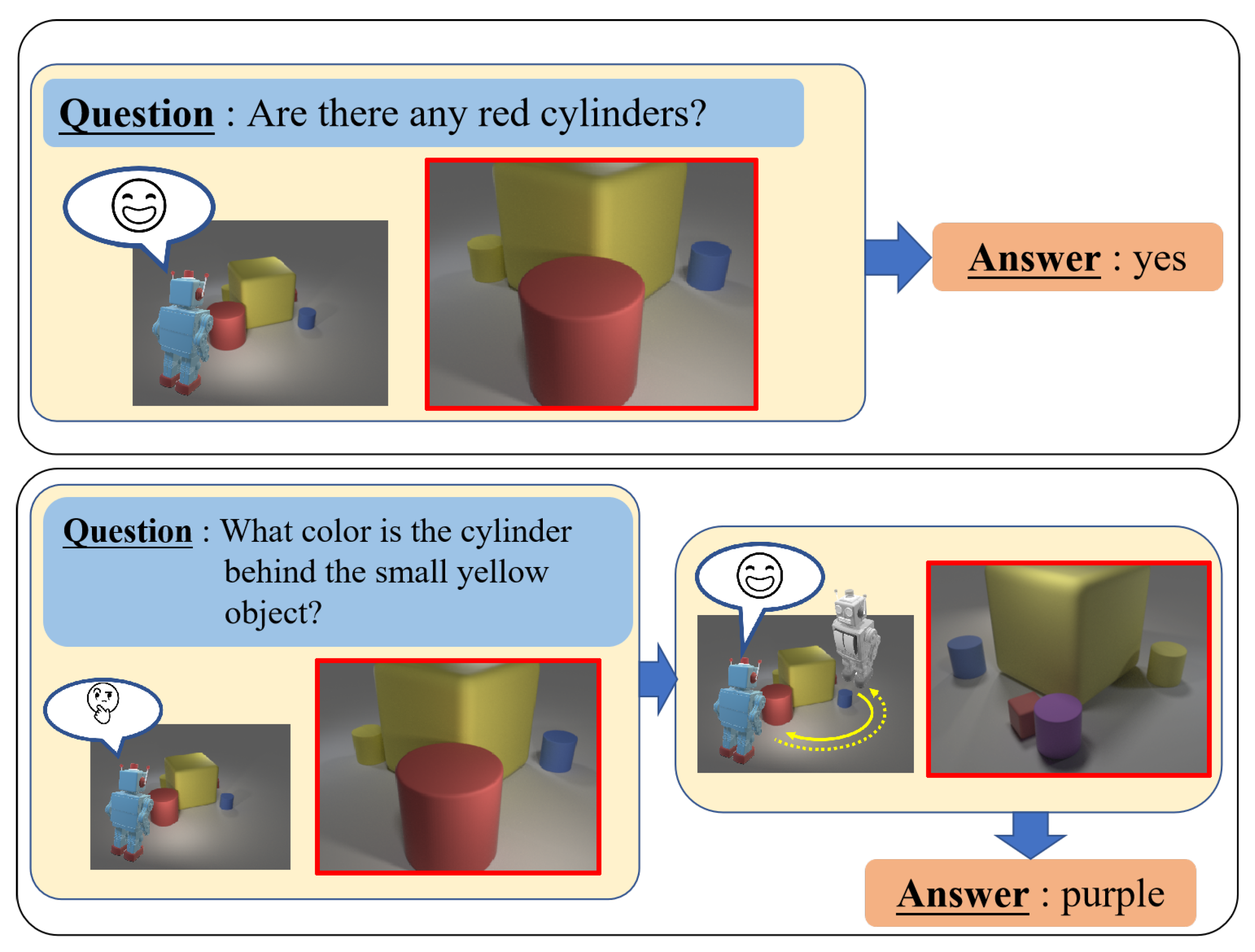
1. Introduction
- we discuss the VQA task under a multi-view and interactive setting, which is more representative of a real-world environment compared to traditional single-view VQA settings. We also built a dataset for this purpose.
- we propose a framework that actively observes scenes and answers questions based on previously observed scene information. Our framework achieves high accuracy for question answering with high efficiency in terms of the number of observation viewpoints. In addition, our framework can be applied in applications that have restricted observation viewpoints.
- we conduct experiments on a multi-view VQA dataset that consists of real images. This dataset can be used to evaluate the generalization ability of VQA methods. The proposed framework shows high performance for this dataset, which indicates the suitability of our framework for realistic settings.
2. Related Work
2.1. Visual Question Answering
2.2. Learned Scene Representation
2.3. Deep Q-Learning Networks
2.4. Embodied Question Answering
3. Approach
3.1. Scene Representation
3.2. Viewpoint Selection
3.3. Visual Question Answering
4. Experiments
4.1. Implementation Details
4.2. Experiments with CG Images
4.3. Experiments with Real Images
4.3.1. Training on CG Images and Testing on the Real Images Dataset
4.3.2. Fine-Tuning on the Semi-CG Dataset
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| VQA | Visual Question Answering |
| HRI | Human–Robot Interaction |
| 3D | Three-Dimensional |
| SRN | Scene Representation Network |
| CG | Computer Graphics |
| FiLM | Feature-wise Linear Modulation |
| CLEVR | Compositional Language and Elementary Visual Reasoning |
| CNNs | Convolutional Neural Networks |
| DQNs | Deep Q-learning Networks |
| MLP | Multi-Layer Perceptron |
| EQA | Embodied Question Answering |
| LSTM | Long Short-Term Memory |
| 3DMFP | 3D photography studio, 3D MFP, Ortery |
References
- Antol, S.; Agrawal, A.; Lu, J.; Mitchell, M.; Batra, D.; Zitnick, C.L.; Parikh, D. Vqa: Visual question answering. In Proceedings of the IEEE International Conference on Computer Vision, Las Condes, Chile, 11–18 December 2015; pp. 2425–2433. [Google Scholar]
- Goyal, Y.; Khot, T.; Summers-Stay, D.; Batra, D.; Parikh, D. Making the V in VQA matter: Elevating the role of image understanding in Visual Question Answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6904–6913. [Google Scholar]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-up and top-down attention for image captioning and visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–24 June 2018; pp. 6077–6086. [Google Scholar]
- Fukui, A.; Park, D.H.; Yang, D.; Rohrbach, A.; Darrell, T.; Rohrbach, M. Multimodal compact bilinear pooling for visual question answering and visual grounding. arXiv 2016, arXiv:1606.01847. [Google Scholar]
- Hudson, D.A.; Manning, C.D. Compositional attention networks for machine reasoning. arXiv 2018, arXiv:1803.03067. [Google Scholar]
- Kim, J.H.; Jun, J.; Zhang, B.T. Bilinear attention networks. arXiv 2018, arXiv:1805.07932v2. [Google Scholar]
- Das, A.; Kottur, S.; Gupta, K.; Singh, A.; Yadav, D.; Moura, J.M.F.; Parikh, D.; Batra, D. Visual dialog. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 326–335. [Google Scholar]
- Das, A.; Kottur, S.; Moura, J.M.F.; Lee, S.; Batra, D. Learning cooperative visual dialog agents with deep reinforcement learning. In Proceedings of the IEEE international conference on computer vision, Venice, Italy, 22–29 October 2017; pp. 2951–2960. [Google Scholar]
- Qiu, Y.; Satoh, Y.; Suzuki, R.; Kataoka, H. Incorporating 3D Information into Visual Question Answering. In Proceedings of the IEEE International Conference on 3D Vision (3DV), Quebec City, QB, Canada, 16–19 September 2019; pp. 756–765. [Google Scholar]
- Perez, E.; Strub, F.; De Vries, H.; Dumoulin, V.; Courville, A. Film: Visual reasoning with a general conditioning layer. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.C.; Zitnick, L.; Dollar, P. Microsoft Coco: Common Objects in Context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Swityerland, 2014; pp. 740–755. [Google Scholar]
- Johnson, J.; Hariharan, B.; van der Maaten, L.; Li, F.-F.C.; Zitnick, L.; Girshick, R. Clevr: A diagnostic dataset for compositional language and elementary visual reasoning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2901–2910. [Google Scholar]
- Su, H.; Jampani, V.; Sun, D.; Maji, S.; Kalogerakis, E.; Yang, M.-H.; Kautz, J. Splatnet: Sparse lattice networks for point cloud processing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2530–2539. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Gkioxari, G.; Malik, J.; Johnson, J. Mesh r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 9785–9795. [Google Scholar]
- Liu, Z.; Tang, H.; Lin, Y.; Han, S. Point-Voxel CNN for efficient 3D deep learning. Advances in Neural Information Processing Systems. In Proceedings of the Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 963–973. [Google Scholar]
- Eslami, S.M.A.; Rezende, D.J.; Besse, F.; Viola, F.; Morcos, A.S.; Garnelo, M.; Ruderman, A.; Rusu, A.A.; Danihelka, I.; Gregor, K.; et al. Neural scene representation and rendering. Science 2018, 360, 1204–1210. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Mohamed, S.; Rezende, D.J.; Mohamed, S.; Welling, M. Semi-supervised learning with deep generative models. arXiv 2014, arXiv:1406.5298. [Google Scholar]
- Park, J.J.; Florence, P.; Straub, J.; Newcombe, R.; Lovegrove, S. Deepsdf: Learning continuous signed distance functions for shape representation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 January 2019; pp. 165–174. [Google Scholar]
- Sitzmann, V.; Zollhöfer, M.; Wetzstein, G. Scene representation networks: Continuous 3D-structure-aware neural scene representations. arXiv 2019, arXiv:1906.01618 2019. [Google Scholar]
- Watkins, C.J.C.H.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Levine, S.; Finn, C.; Darrell, T.; Abbeel, P. End-to-end training of deep visuomotor policies. J. Mach. Learn. Res. 2016, 17, 1334–1373. [Google Scholar]
- Das, A.; Datta, S.; Gkioxari, G.; Lee, S.; Parikh, D.; Batra, D. Embodied question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2054–2063. [Google Scholar]
- Yu, L.; Chen, X.; Gkioxari, G.; Bansal, M.; Berg, T.L.; Batra, D. Multi-target embodied question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 6309–6318. [Google Scholar]
- Wijmans, E.; Datta, S.; Maksymets, O.; Das, A.; Gkioxari, G.; Lee, S.; Essa, I.; Parikh, D.; Batra, D. Embodied question answering in photorealistic environments with point cloud perception. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 Junuary 2019; pp. 6659–6668. [Google Scholar]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to forget: Continual prediction with LSTM. Neural Comput. 2000, 12, 2451–2471. [Google Scholar] [CrossRef] [PubMed]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antigaet, L.; et al. PyTorch: An imperative style, high-performance deep learning library. arXiv 2019, arXiv:1912.01703. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhinl, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- FiLM Implementation Code. Available online: https://github.com/ethanjperez/film (accessed on 8 April 2020).
- Su, H.; Maji, S.; Kalogerakis, E.; Learned-Miller, E. Multi-view convolutional neural networks for 3D shape recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 945–953. [Google Scholar]
- Kanezaki, A.; Matsushita, Y.; Nishida, Y. Rotationnet: Joint object categorization and pose estimation using multiviews from unsupervised viewpoints. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 January 2018; pp. 5010–5019. [Google Scholar]
- Software Blender Site. Available online: https://www.blender.org/ (accessed on 8 April 2020).
- CLEVR Dataset Generation Implementation Code. Available online: https://github.com/facebookresearch/clevr-dataset-gen (accessed on 8 April 2020).
- Sony Alpha 7 III Mirrorless Single Lens Digital Camera Site. Available online: https://www.sony.jp/ichigan/products/ILCE-7RM3/ (accessed on 8 April 2020).
- 3D-MFP Site. Available online: https://www.ortery.jp/photography-equipment/3d-photography-ja/3d-mfp/ (accessed on 8 April 2020).
- 3DSOM Pro V5 Site. Available online: http://www.3dsom.com/new-release-v5-markerless-workflow/ (accessed on 8 April 2020).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | No. of Scenes | No. of Q–A Pairs | Spatial | Non-Spatial | ||
|---|---|---|---|---|---|---|
| (Train/Test) | (Train/Test) | Exist | Query Color | Exist | Query Color | |
| Multi-view-CLEVR_12views_CG (CG) | (40,000 / 3,000) | (157,232 / 11,801) | 43,000 | 42,993 | 43,000 | 40,040 |
| Multi-view-CLEVR_4views_CG (CG) | (40,000 / 3000) | (158,860 / 11,928) | 43,000 | 42,997 | 43,000 | 41,791 |
| Multi-view-CLEVR_4views_3DMFP (CG) | (10,000 / 0) | (39,694 / 0) | 10,000 | 9994 | 10,000 | 9,700 |
| Multi-view-CLEVR_4views_Real (Real) | (0 / 500) | (0 / 1974) | 500 | 500 | 500 | 474 |
| Method | Overall Accuracy | Spatial | Non-Spatial | Average no. of Used Viewpoints | ||
|---|---|---|---|---|---|---|
| Exist | Query Color | Exist | Query Color | |||
| SRN_FiLM | 97.37% | 94.20% | 98.20% | 99.03% | 98.11% | 12 |
| SRN_FiLM_VS | 97.11% | 95.27% | 96.90% | 99.03% | 97.25% | 2.98 |
| Method (No. of Used Viewpoints) | Overall Accuracy |
|---|---|
| SRN_FiLM_Random (1 view) | 66.71% |
| SRN_FiLM_Random (3 views) | 81.39% |
| SRN_FiLM_Equal (3 views) | 82.90% |
| SRN_FiLM_VS (2.98 views) | 97.11% |
| Method | Accuracy | No. of Used Viewpoints |
|---|---|---|
| SRN_FiLM | 97.67% | 4 |
| SRN_FiLM_VS | 97.64% | 2.02 |
| Method | Fine-Tuning | Accuracy | |
|---|---|---|---|
| SRN | FiLM | ||
| SRN_FiLM | - | - | 67.88% |
| SRN_FiLM | - | ✓ | 76.14% |
| SRN_FiLM | ✓ | - | 77.30% |
| SRN_FiLM | ✓ | ✓ | 82.62% |
| SRN_FiLM_VS | - | - | 66.82% |
| SRN_FiLM_VS | - | ✓ | 79.99% |
| SRN_FiLM_VS | ✓ | - | 91.56% |
| SRN_FiLM_VS | ✓ | ✓ | 94.01% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiu, Y.; Satoh, Y.; Suzuki, R.; Iwata, K.; Kataoka, H. Multi-View Visual Question Answering with Active Viewpoint Selection. Sensors 2020, 20, 2281. https://doi.org/10.3390/s20082281
Qiu Y, Satoh Y, Suzuki R, Iwata K, Kataoka H. Multi-View Visual Question Answering with Active Viewpoint Selection. Sensors. 2020; 20(8):2281. https://doi.org/10.3390/s20082281
Chicago/Turabian StyleQiu, Yue, Yutaka Satoh, Ryota Suzuki, Kenji Iwata, and Hirokatsu Kataoka. 2020. "Multi-View Visual Question Answering with Active Viewpoint Selection" Sensors 20, no. 8: 2281. https://doi.org/10.3390/s20082281
APA StyleQiu, Y., Satoh, Y., Suzuki, R., Iwata, K., & Kataoka, H. (2020). Multi-View Visual Question Answering with Active Viewpoint Selection. Sensors, 20(8), 2281. https://doi.org/10.3390/s20082281