A Novel Method for Estimating Monocular Depth Using Cycle GAN and Segmentation



Abstract
:1. Introduction
2. Literature Review
2.1. Depth Estimation Methods Before GAN
2.2. Monocular Depth Estimation Methods
2.3. Depth Estimation Methods After GAN
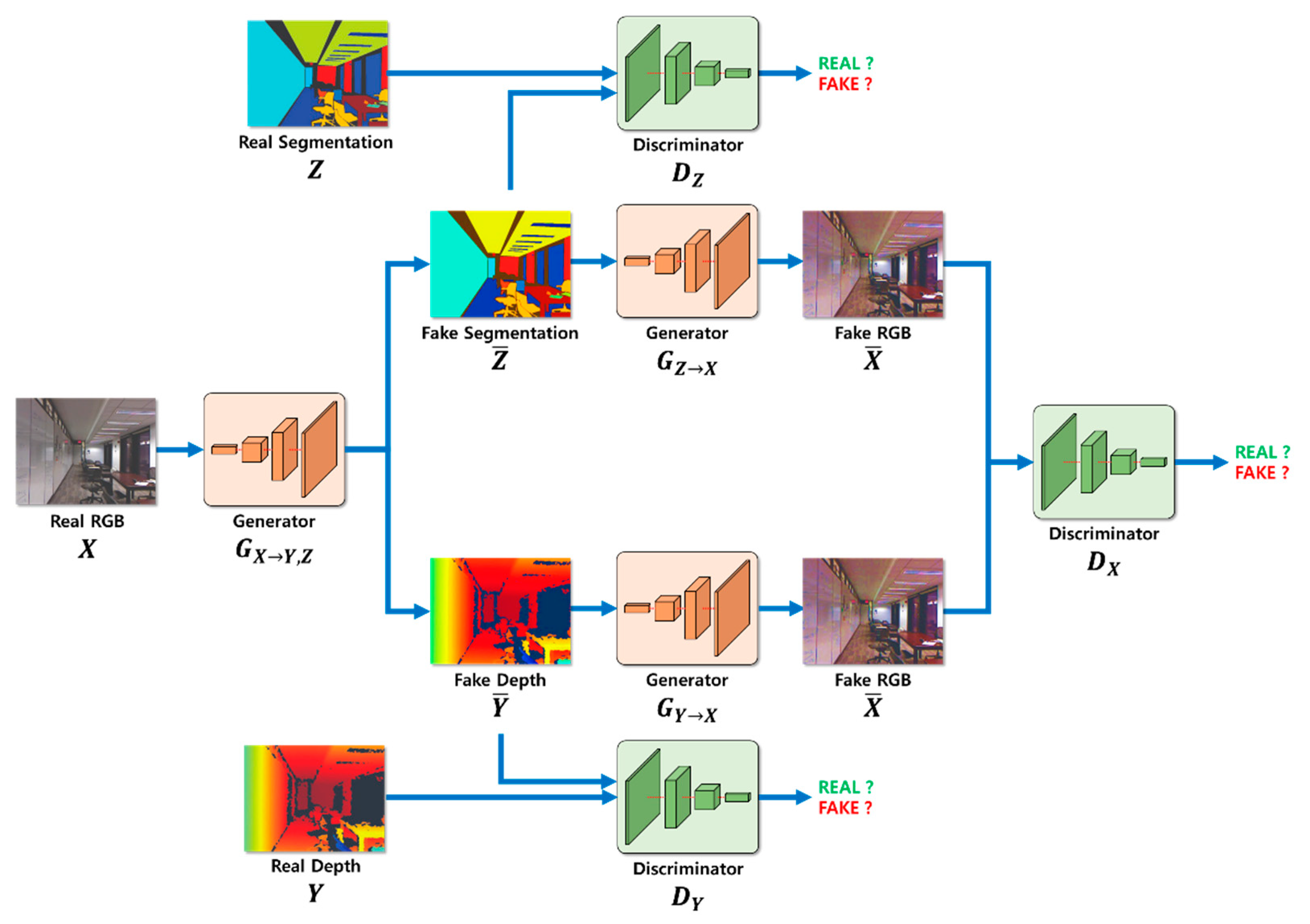
3. Depth Estimation Using Cycle GAN and Segmentation
3.1. Segmentation and Depth Estimation During the Learning Process
3.2. Calculation of Adversarial Loss During the Learning Process
3.3. Calculation of Cycle Consistency Loss During the Learning Process
3.4. Backpropagation
3.5. Operating Sequence for the Learning Process
3.5.1. Segmentation and Depth Estimation Process
3.5.2. Adversarial Loss Calculation Process
3.5.3. Cycle Consistency Loss Calculation Process
3.6. Depth and Segmentation Information Estimation Inference Process
4. Results and Discussion
4.1. NYU Depth Dataset V2 Result
4.2. Custom Result
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Gokturk, S.B.; Hakan, Y.; Cyrus, B. A time-of-flight depth sensor-system description, issues, and solutions. In Proceedings of the 2004 Conference on Computer Vision and Pattern Recognition Workshop, Washington, DC, USA, 27 June–2 July 2004; IEEE: Piscataway, NJ, USA, 2004. [Google Scholar]
- Scharstein, D.; Richard, S. High-accuracy stereo depth maps using structured light. In Proceedings of the 2003 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Madison, WI, USA, 18–20 June 2003; IEEE: Piscataway, NJ, USA, 2003; Volume 1. [Google Scholar]
- Zbontar, J.; Yann, L. Stereo matching by training a convolutional neural network to compare image patches. J. Mach. Learn. Res. 2016, 17, 1–32. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 3431–3440. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems; NIPS Proceedings: San Diego, CA, USA, 2007; pp. 1097–1105. [Google Scholar]
- Mikolov, T.; Karafiát, M.; Burget, L.; Černocký, J.; Khudanpur, S. Recurrent neural network based language model. In Proceedings of the 11th Annual Conference of the Iternational Speech Communication Association, Makuhari, Japan, 26–30 September 2010. [Google Scholar]
- Fanello, S.R. Learning to be a depth camera for close-range human capture and interaction. ACM. Trans. Gr. 2014, 33, 4–86. [Google Scholar] [CrossRef]
- Ha, H. High-quality depth from uncalibrated small motion clip. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar]
- Kong, N.; Black, M.J. Intrinsic depth: Improving depth transfer with intrinsic images. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; IEEE: Piscataway, NJ, USA, 2015. [Google Scholar]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth map prediction from a single image using a multi-scale deep network. In Advances in Neural Information Processing Systems 27; NIPS Proceedings: San Diego, CA, USA, 2014; pp. 2366–2374. [Google Scholar]
- Karsch, K.; Liu, C.; Kang, S.B. Depth transfer: Depth extraction from video using non-parametric sampling. IEEE Trans. Pat. Anal. Mach. Int. 2014, 36, 2144–2158. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, F.; Chunhua, S.; Guosheng, L. Deep convolutional neural fields for depth estimation from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; IEEE: Piscataway, NJ, USA, 2015. [Google Scholar]
- Xie, S.; Zhuowen, T. Holistically-nested edge detection. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; IEEE: Piscataway, NJ, USA, 2015. [Google Scholar]
- Xu, D.; Wei, W.; Hao, T.; Hong, L.; Nicu, S.; Elisa, R. Structured attention guided convolutional neural fields for monocular depth estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Zhou, T.; Matthew, B.; Noah, S.; David, G.L. Unsupervised learning of depth and ego-motion from video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Goodfellow, I. Generative adversarial nets. In Advances in Neural Information Processing Systems 27; NIPS Proceedings: San Diego, CA, USA, 2014; pp. 2672–2680. [Google Scholar]
- Pilzer, A. Unsupervised adversarial depth estimation using cycled generative networks. In Proceedings of the 2018 International Conference on 3D Vision (3DV), Verona, Italy, 5–8 September 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Nath, K. Adadepth: Unsupervised content congruent adaptation for depth estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Zheng, C.; Cham, T.J.; Cai, J. T2net: Synthetic-to-realistic translation for solving single-image depth estimation tasks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Springer International Publishing: Cham, Switzerland, 2018; pp. 767–783. [Google Scholar]
- Mirza, M.; Simon, O. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Isola, P. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Gwn, L.K. Generative adversarial networks for depth map estimation from RGB video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Kumar, A.C.S.; Bhandarkar, S.M.; Prasad, M. Monocular depth prediction using generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Zhu, J.Y. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 770–778. [Google Scholar]
- Silberman, N. Indoor segmentation and support inference from rgbd images. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Lee, H.Y.; Lee, S.H. A study on memory optimization for applying deep learning to PC. J. IKEEE 2017, 21, 136–141. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | RMSE↓ | RMSLE↓ | δ1↑ | δ2↑ | δ3↑ |
|---|---|---|---|---|---|
| Zheng et al. [19] | 0.915 | 0.305 | 0.540 | 0.832 | 0.948 |
| Eigen et al. [10] | 0.909 | - | 0.602 | 0.879 | 0.970 |
| Liu et al. [12] | 0.824 | - | 0.615 | 0.883 | 0.971 |
| The Proposed Method | 0.652 | 0.217 | 0.834 | 0.941 | 0.976 |
| Method | RMSE↓ | RMSLE↓ | δ1↑ | δ2↑ | δ3↑ |
|---|---|---|---|---|---|
| Depth only | 0.687 | 0.228 | 0.819 | 0.936 | 0.972 |
| The Proposed Method | 0.652 | 0.217 | 0.834 | 0.941 | 0.976 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kwak, D.-h.; Lee, S.-h. A Novel Method for Estimating Monocular Depth Using Cycle GAN and Segmentation. Sensors 2020, 20, 2567. https://doi.org/10.3390/s20092567
Kwak D-h, Lee S-h. A Novel Method for Estimating Monocular Depth Using Cycle GAN and Segmentation. Sensors. 2020; 20(9):2567. https://doi.org/10.3390/s20092567
Chicago/Turabian StyleKwak, Dong-hoon, and Seung-ho Lee. 2020. "A Novel Method for Estimating Monocular Depth Using Cycle GAN and Segmentation" Sensors 20, no. 9: 2567. https://doi.org/10.3390/s20092567