Adaptive 3D Model-Based Facial Expression Synthesis and Pose Frontalization



Abstract
:1. Introduction
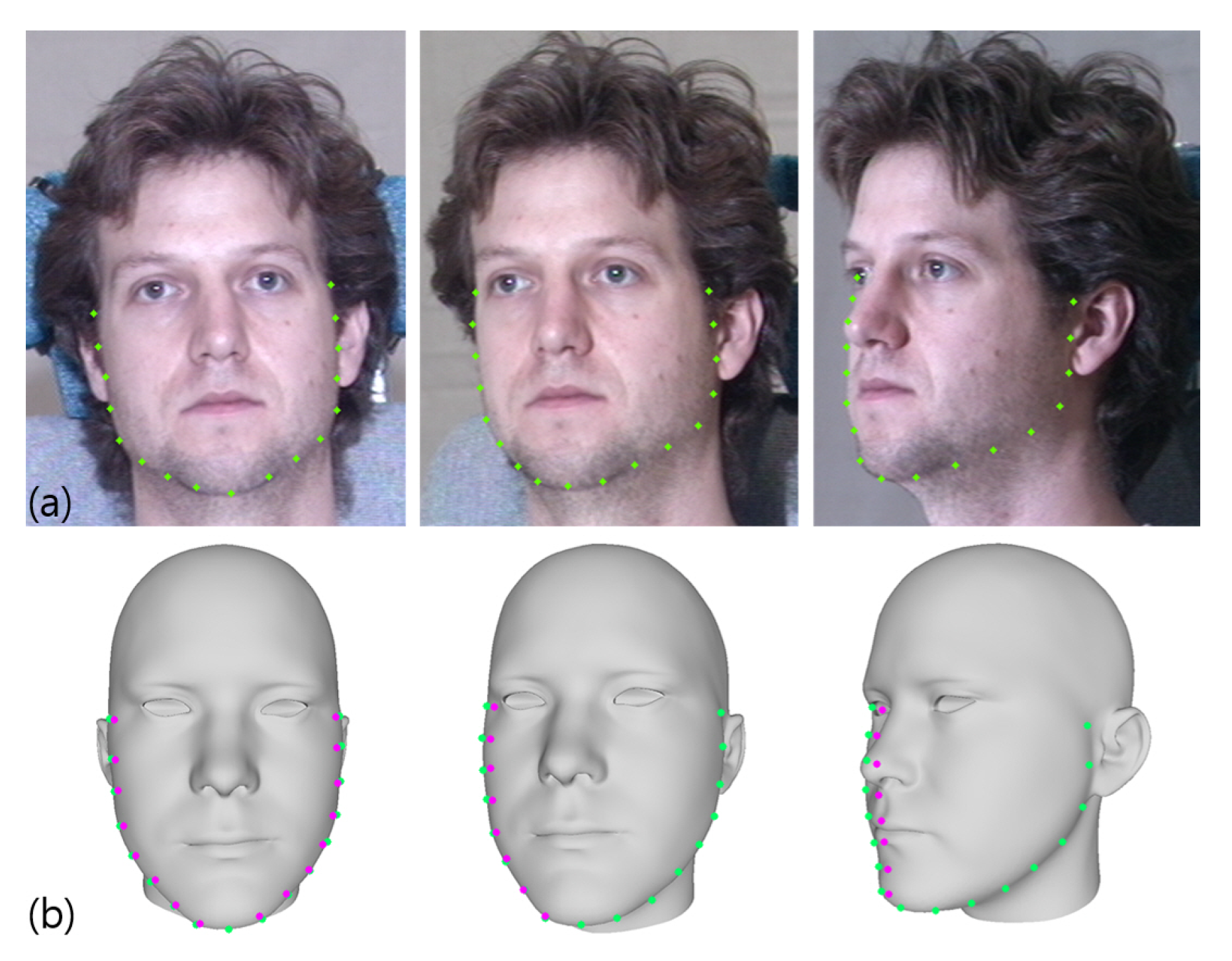
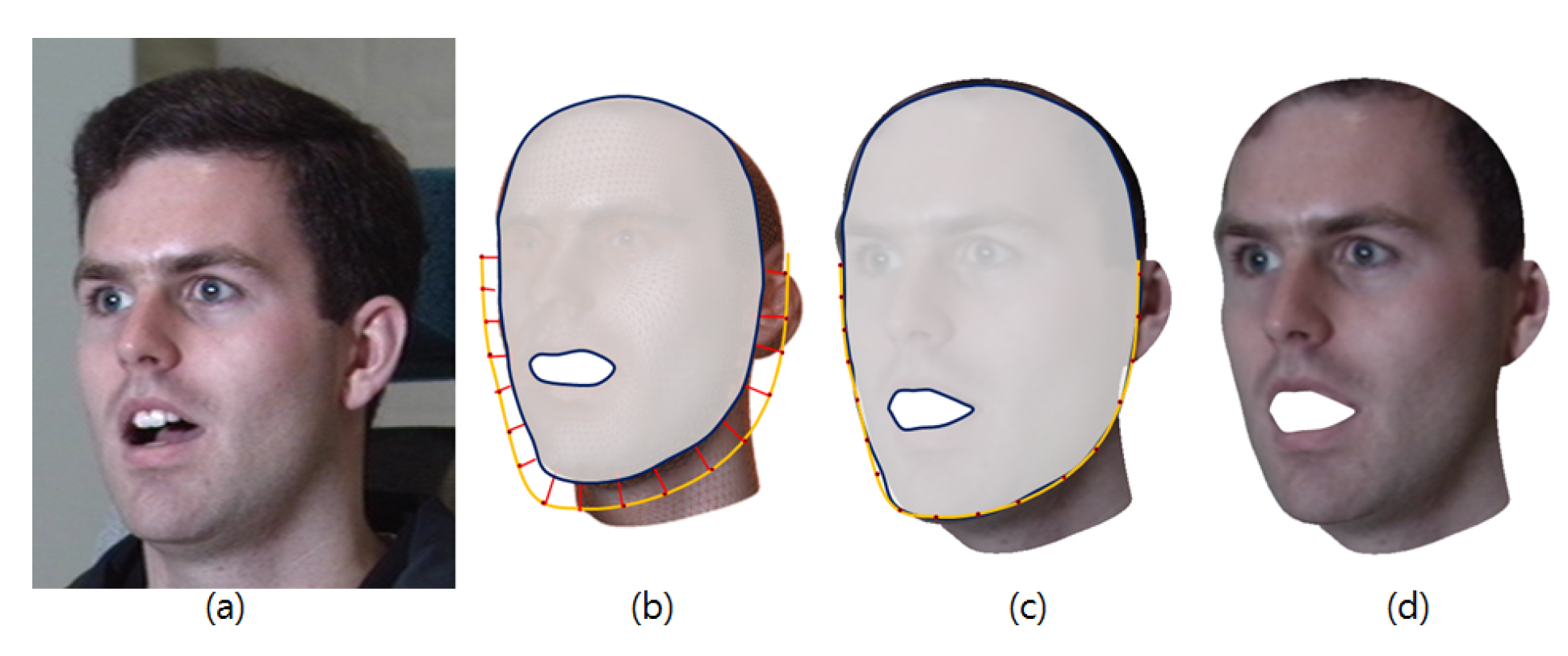
- We propose a contour-fitting method to fit a 3D model to an input image to manage self-occluded facial regions, such as facial contours owing to a variety of expressions and poses through a 3D landmark reassignment through an iterative fitting process.
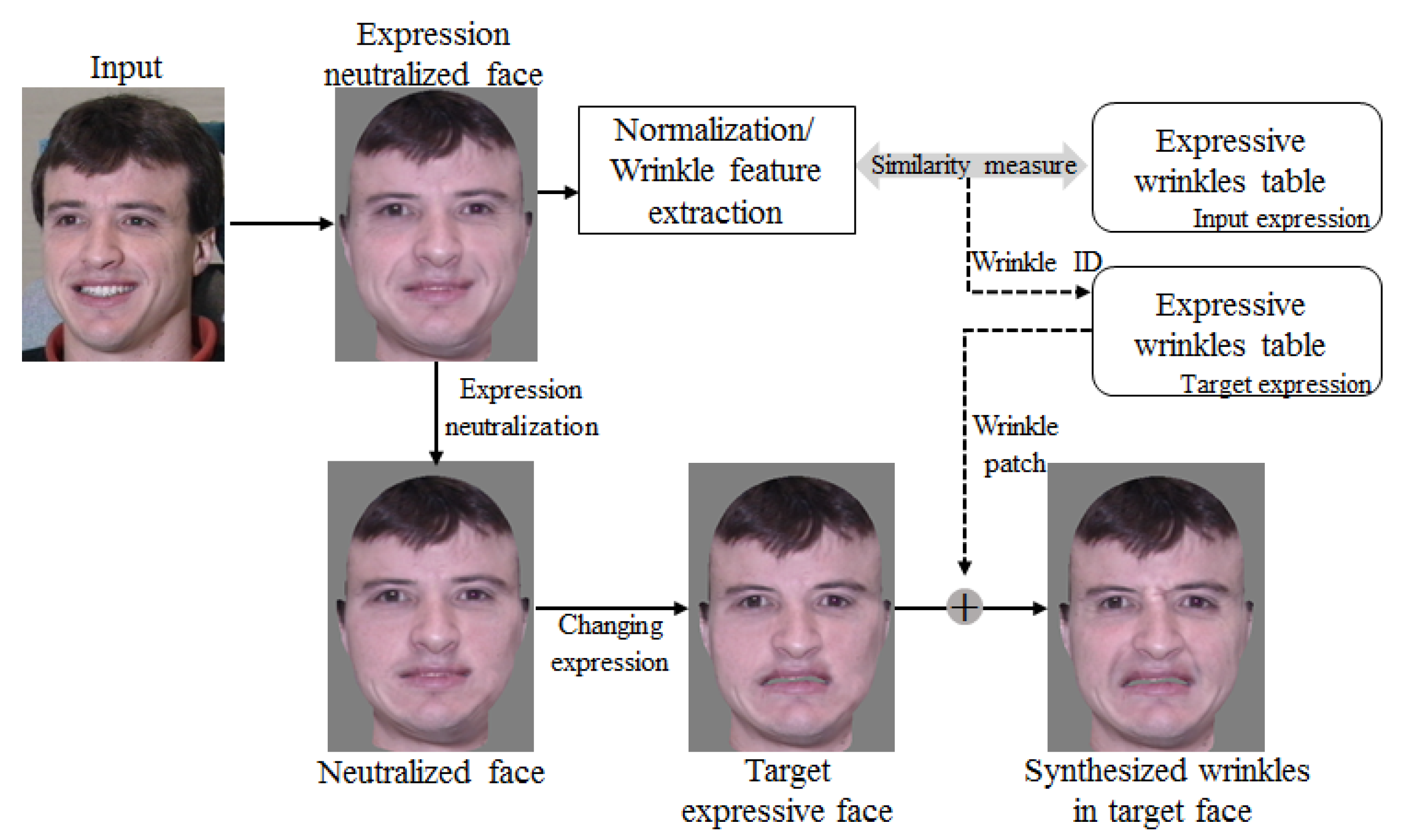
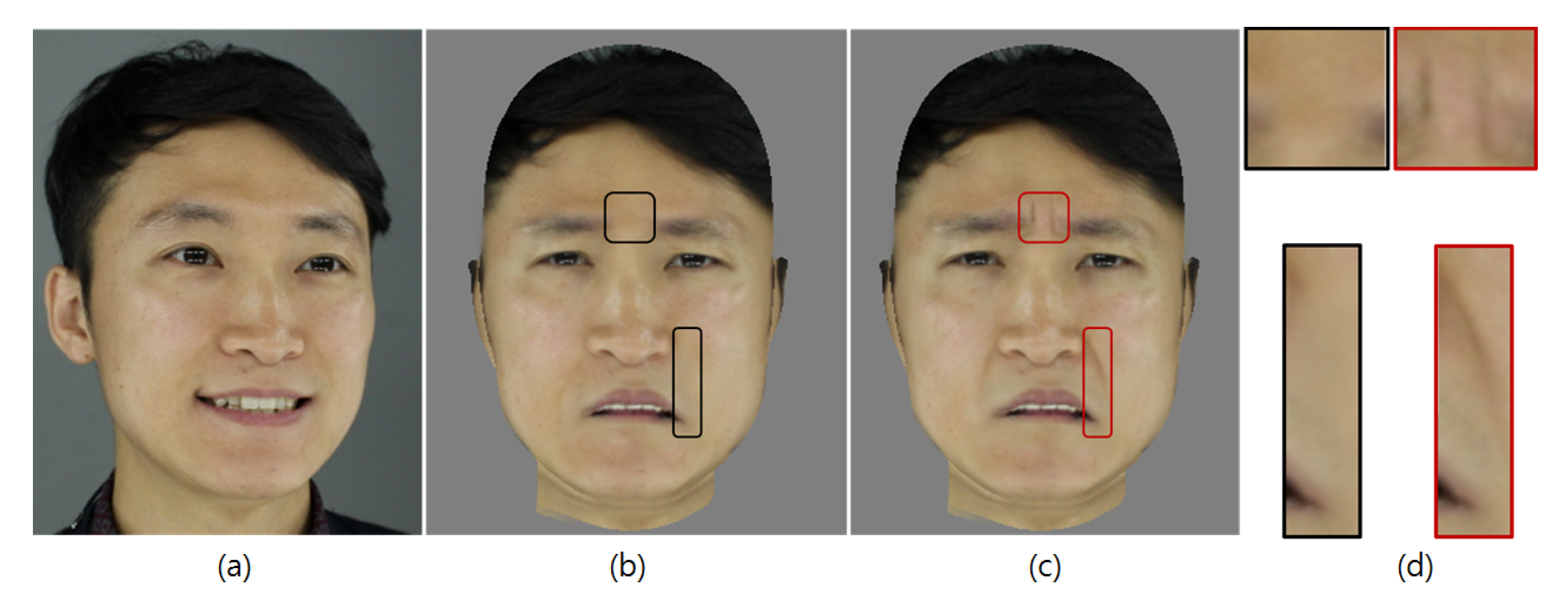
- We propose a method for generating images of natural facial expressions by resolving the problem of inconsistent wrinkles that occur when transferring various facial expressions. We built a wrinkle and patch database, from which wrinkle features comparable to the input expressive faces can be found, and their corresponding wrinkle patches are then synthesized with the transferred expressive facial images.
2. Proposed Method
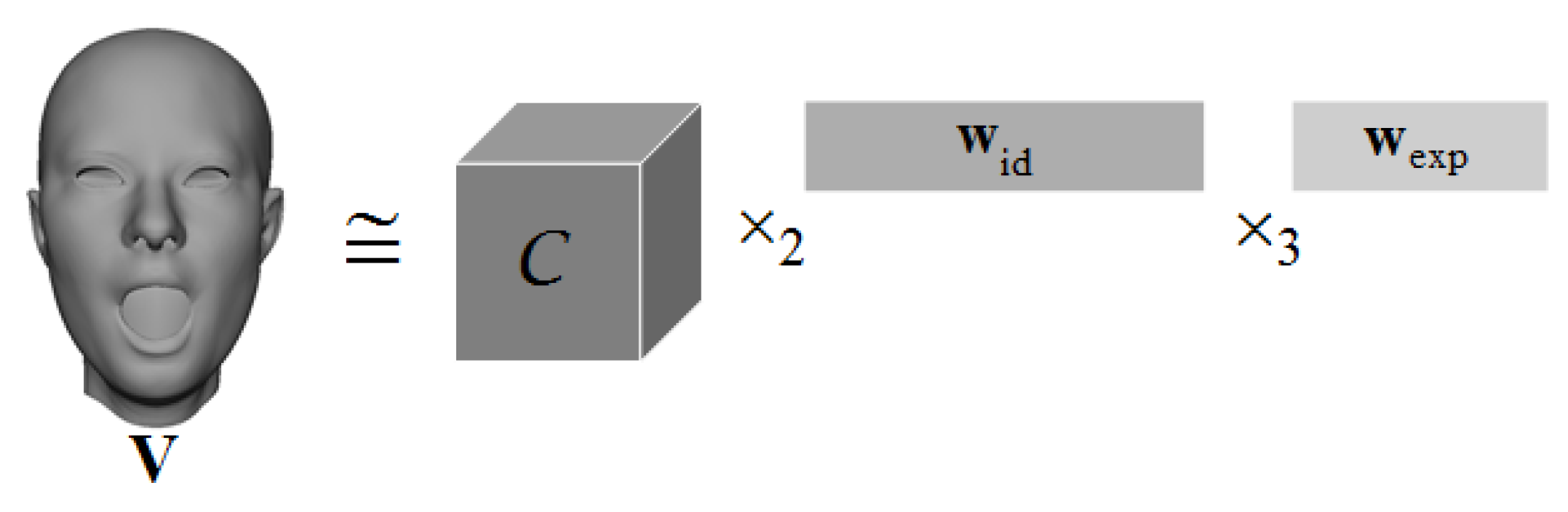
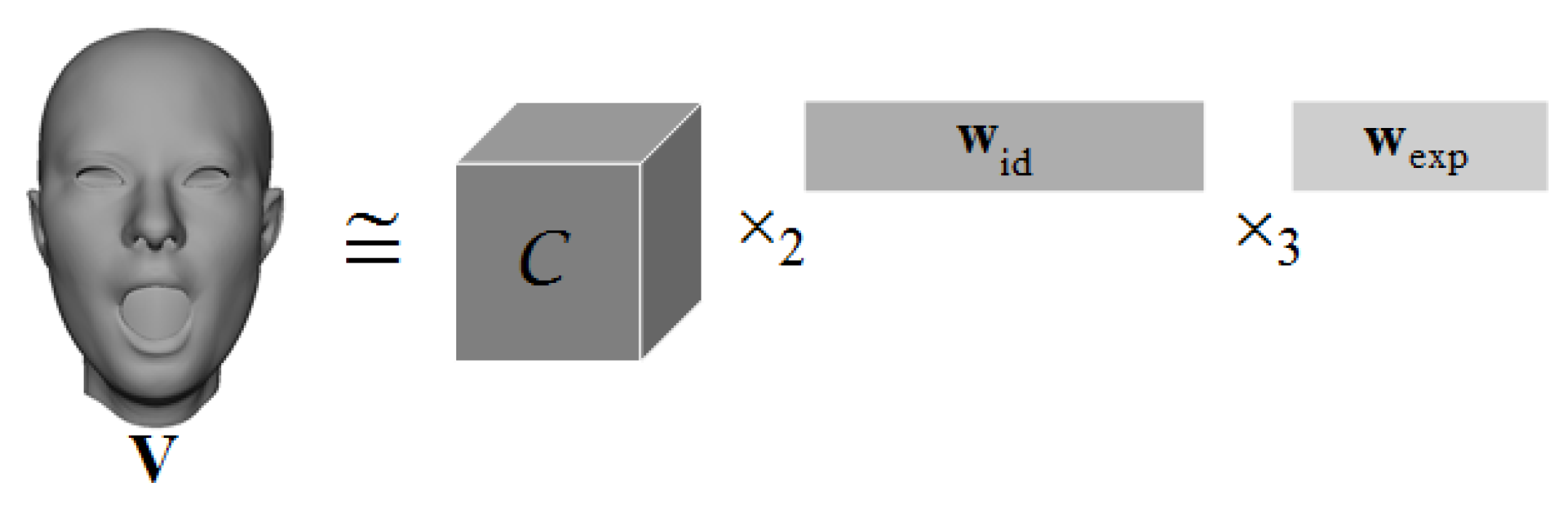
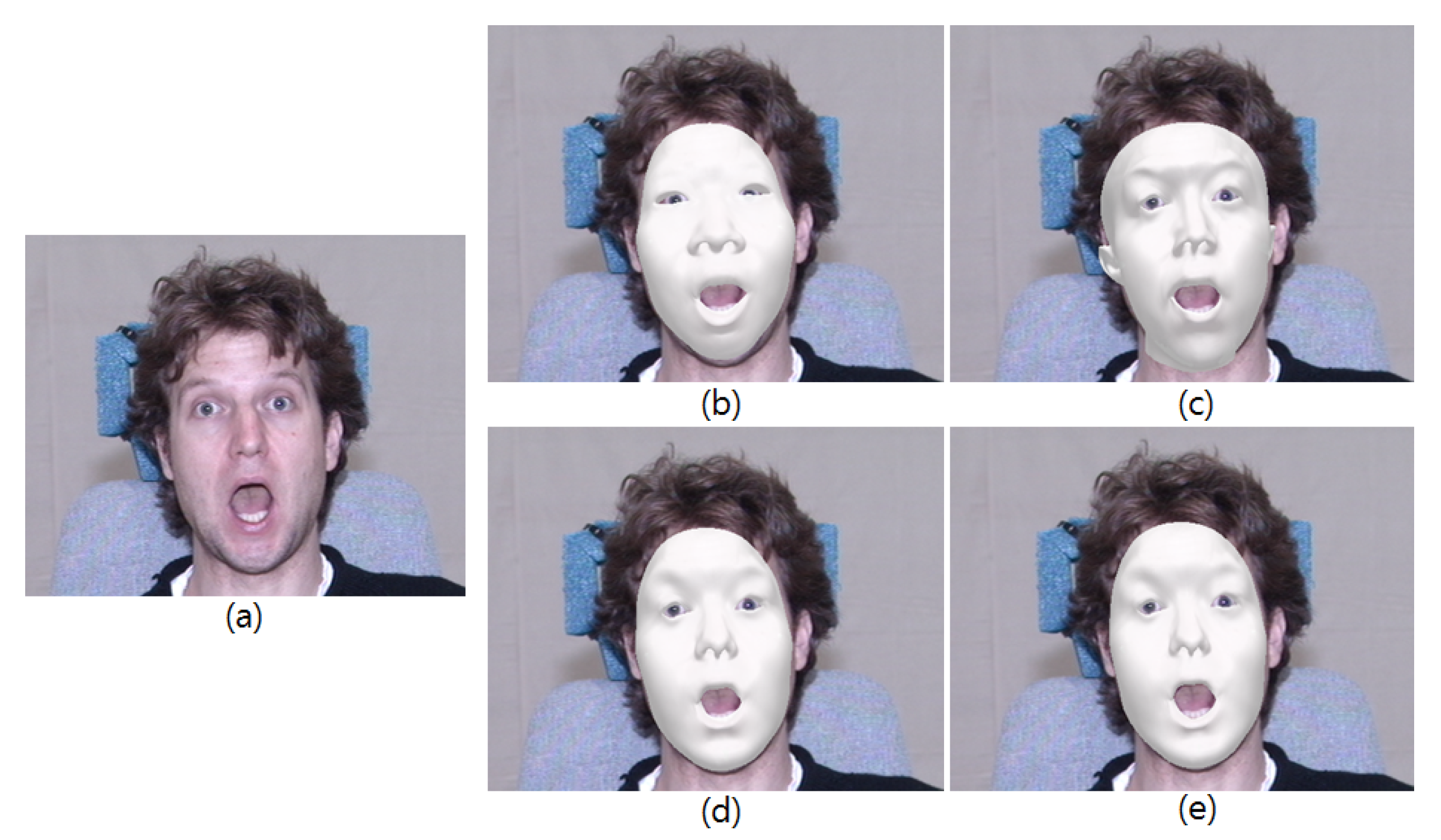
2.1. 3D Fitting Using a Multilinear Model
2.1.1. Pose Fitting Process
| Algorithm 1. Contour fitting algorithm |
| Input: 2D face landmarks and 3D mesh V. |
| Output: Final 3D facial landmarks (). |
| 1: Set V based on an initial guess. |
| 2: Repeat: |
| 3: Project all vertices of V onto an image plane and construct a convex hull of the projected V. |
| 4: Calculate normal directions of the contour landmarks in the image. |
| 5: Consider a point contacting the convex hull as a contact point. |
| 6: Find the closest vertex of V from the contact point only if the vertex is visible at the current view. |
| 7: Update it as the new vertex of V. |
| 8: Update V with Equation (4). |
| 9: Continue Until: the matching errors are minimized in Equation (4). |
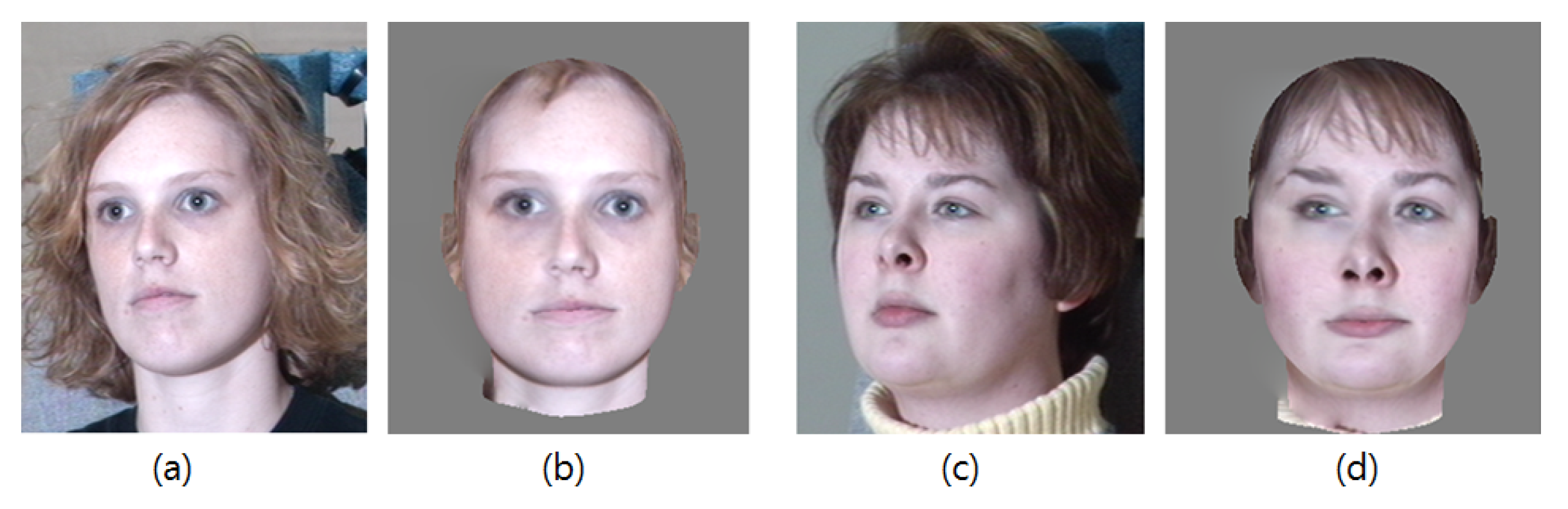
2.1.2. Frontalization
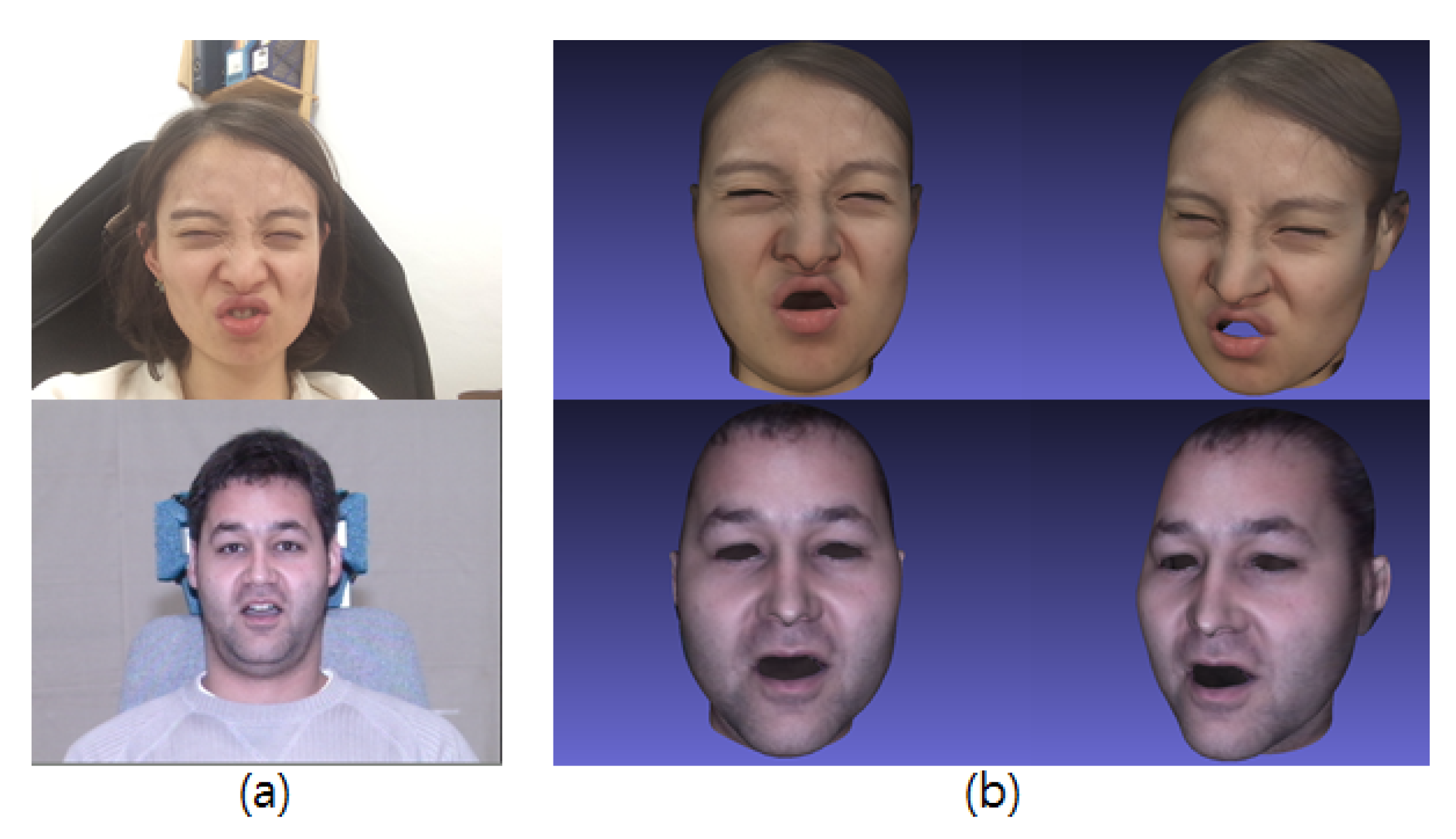
2.2. Facial Expression Generation
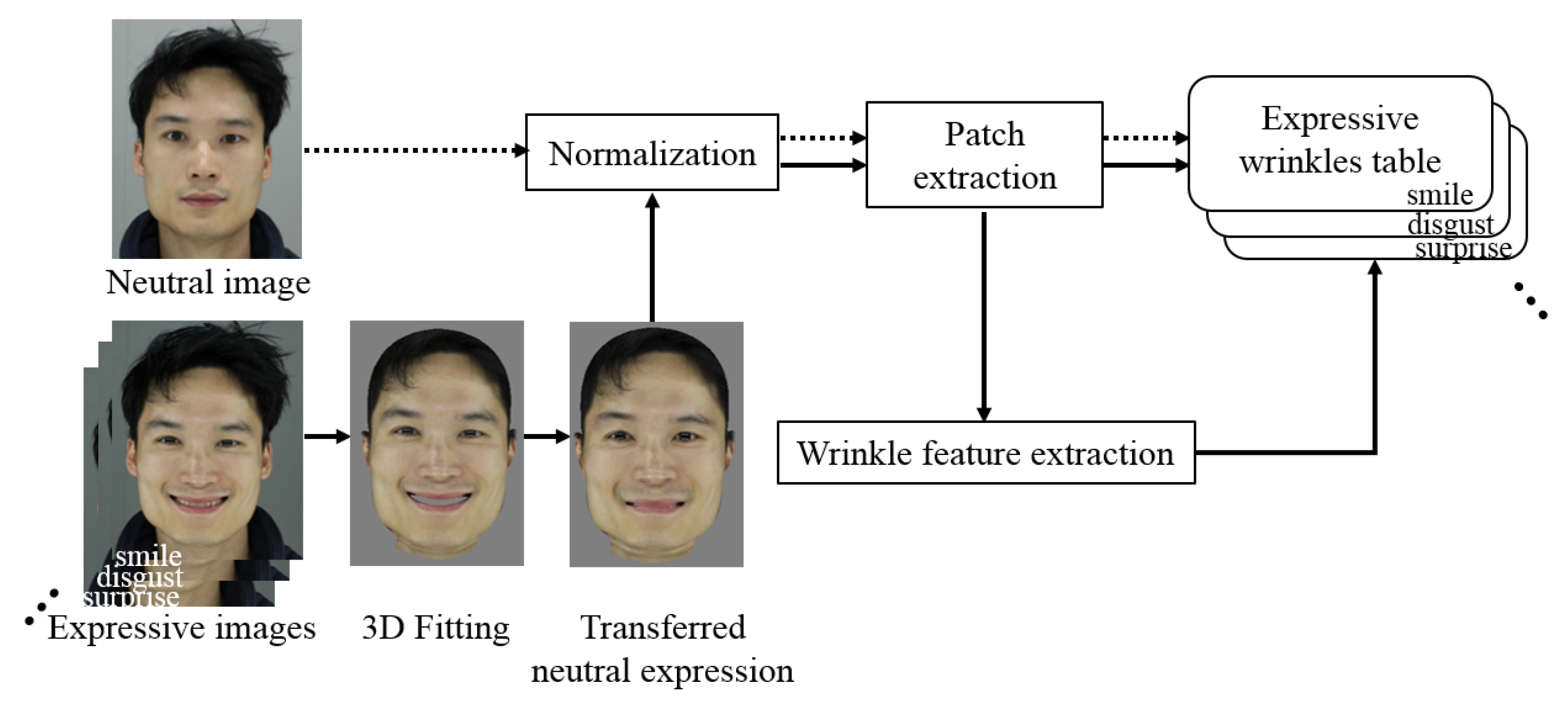
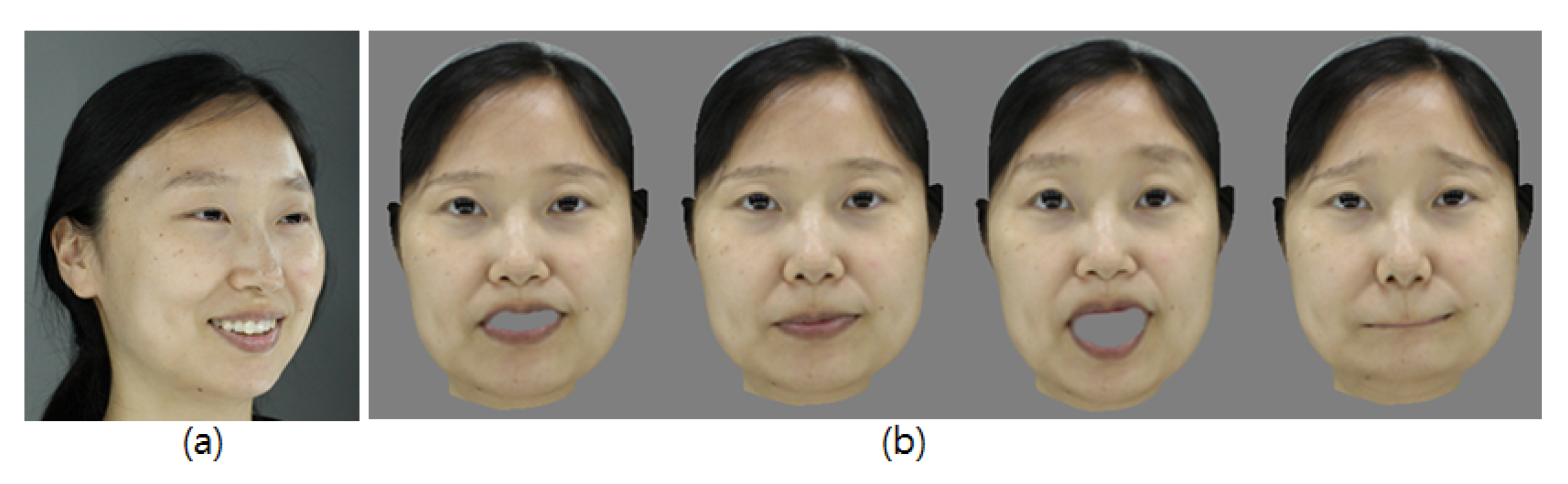
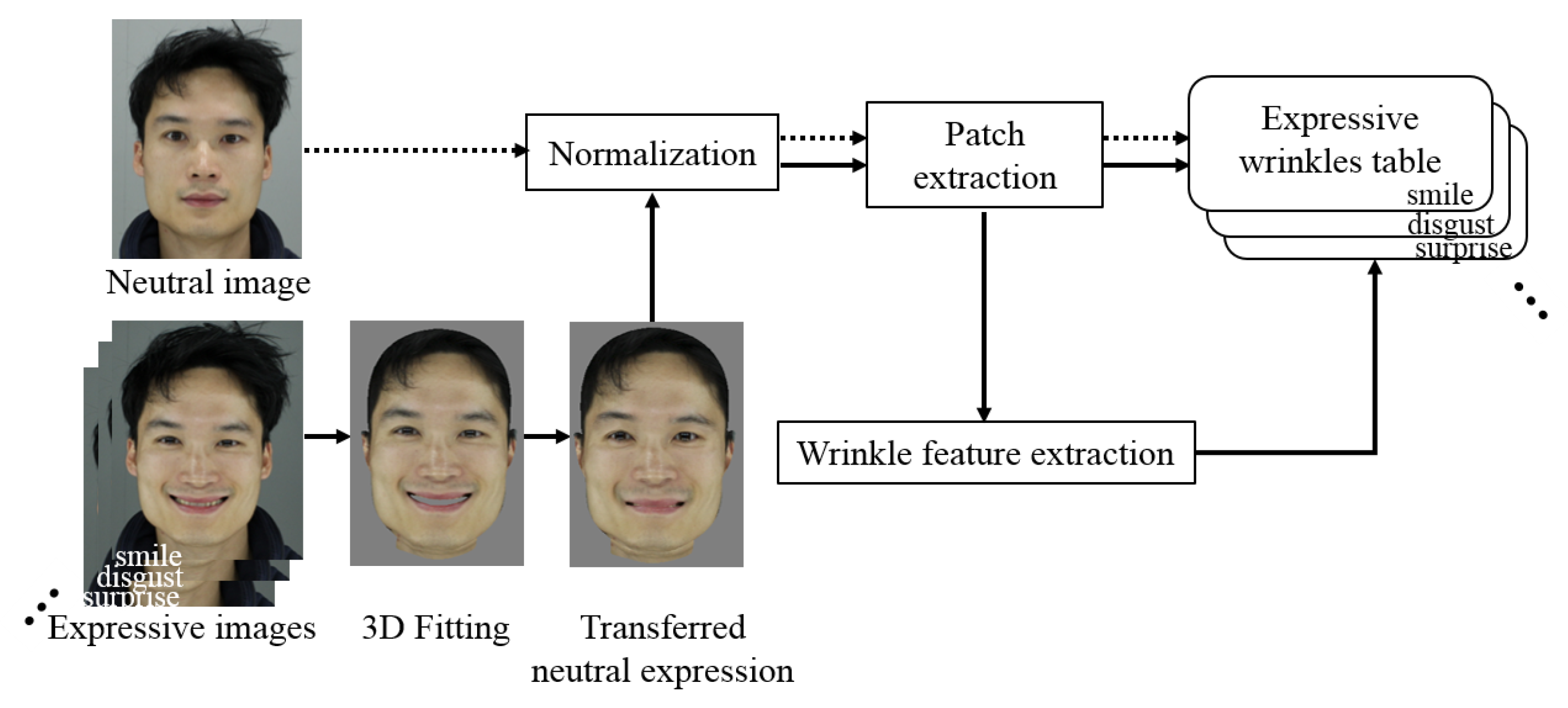
2.2.1. Building of Expressive Wrinkle Table
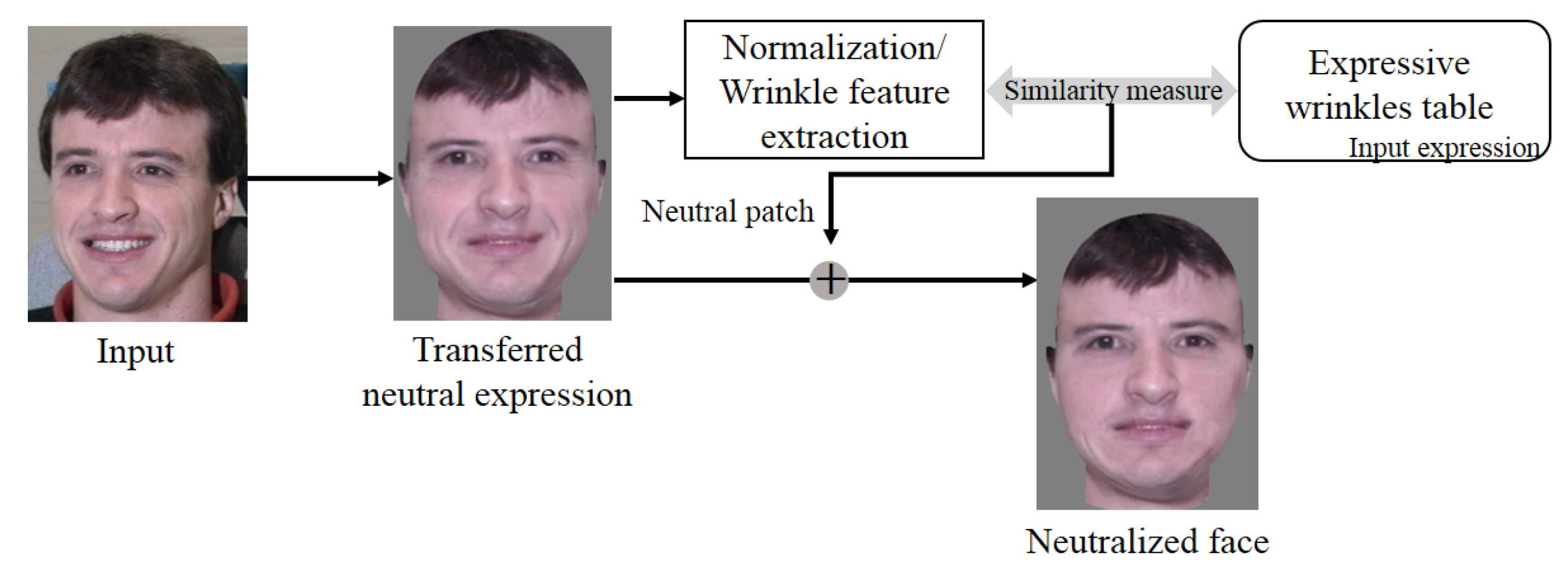
2.2.2. Expression Synthesis with Expressive Wrinkles
3. Experiment
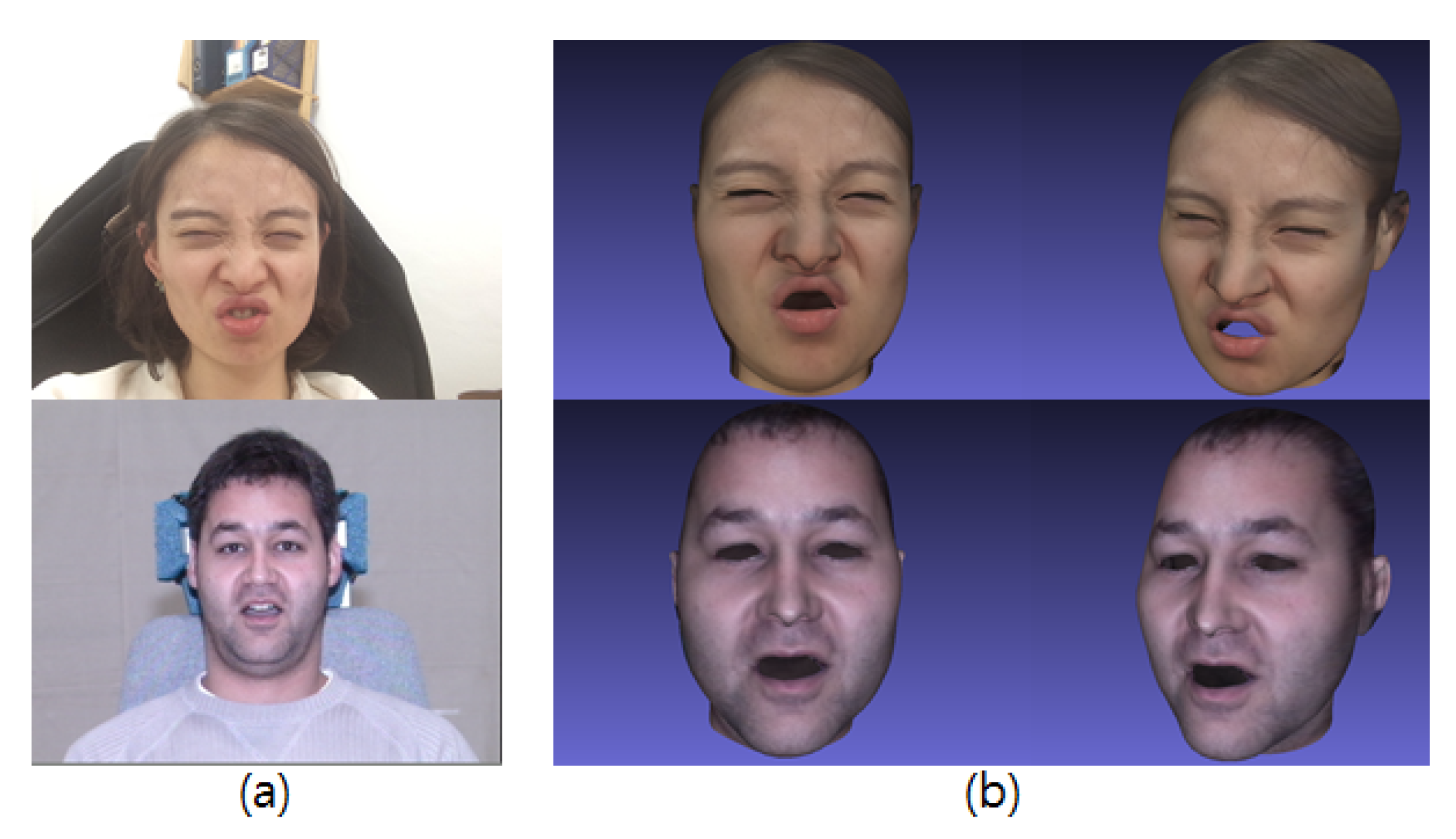
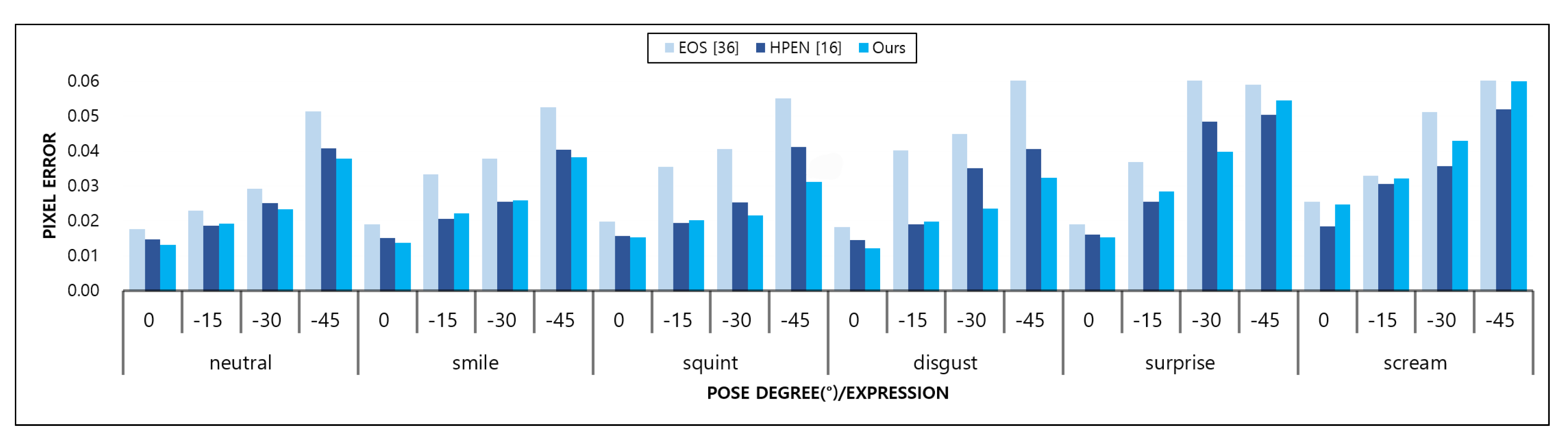
3.1. Comparison Pose Fitting
3.2. Face Recognition
3.3. Recognition Performance
3.3.1. Performance: Pose Frontalization
3.3.2. Performance: Pose Frontalization and Expression Neutralization
3.3.3. User Study
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Gunes, H.; Schuller, B. Categorical and dimensional affect analysis in continuous input: Current trends and future directions. Image Vis. Comp. 2013, 31, 120–136. [Google Scholar] [CrossRef]
- Ekman, P.; Friesen, W.V. Constants across cultures in the face and emotion. J. Pers. Soc. Psychol. 1971, 17, 124–129. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pighin, F.; Hecker, J.; Lischinski, D.; Szeliski, R.; Salesin, D.H. Synthesizing realistic facial expressions from photographs. In Proceedings of the SIGGRAPH ’98: 25th Annual Conference on Computer Graphics and Interactive Techniques, Orlando, FL, USA, 19–24 July 1998; pp. 75–84. [Google Scholar]
- Kemelmacher-Shlizerman, I.; Seitz, S.M. Face reconstruction in the wild. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 1746–1753. [Google Scholar]
- Blanz, V.; Vetter, T. A morphable model for the synthesis of 3D faces. In Proceedings of the SIGGRAPH ’99: 26th Annual Conference on Computer Graphics and Interactive Techniques, Los Angeles, CA, USA, 8–13 August 1999; pp. 187–194. [Google Scholar]
- Paysan, P.; Knothe, R.; Amberg, B.; Romdhani, S.; Vetter, T. A 3D face model for pose and illumination invariant face recognition. In Proceedings of the IEEE Conference on Advanced Video and Signal Based Surveillance, Genova, Italy, 2–4 September 2009; pp. 296–301. [Google Scholar]
- Amberg, B.; Romdhani, S.; Vetter, T. Optimal step nonrigid ICP algorithms for surface registration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Koppen, P.; Feng, Z.H.; Kittler, J.; Awais, M.; Christmas, W.; Wu, X.J.; Yin, H.F. Gaussian mixture 3D morphable face model. Pattern Recognit. 2018, 74, 617–628. [Google Scholar] [CrossRef]
- Vlasic, D.; Brand, M.; Pfister, H.; Popović, J. Face transfer with multilinear models. ACM Trans. Graph. 2005, 24, 426–433. [Google Scholar] [CrossRef]
- Cao, C.; Weng, Y.; Lin, S.; Zhou, K. 3D shape regression for real-time facial animation. ACM Trans. Graph. 2013, 32, 41:1–41:10. [Google Scholar] [CrossRef]
- Cao, C.; Weng, Y.; Zhou, S.; Tong, Y.; Zhou, K. FaceWarehouse: A 3D facial expression database for visual computing. IEEE Trans. Vis. Comput. Graph. 2014, 20, 413–425. [Google Scholar]
- Cao, C.; Hou, Q.; Zhou, K. Displaced dynamic expression regression for real-time facial tracking and animation. ACM Trans. Graphics 2014, 33, 1–10. [Google Scholar] [CrossRef]
- Shi, F.; Wu, H.T.; Tong, X.; Chai, J. Automatic acquisition of high-fidelity facial performances using monocular videos. ACM Trans. Graph. 2014, 33, 1–13. [Google Scholar] [CrossRef]
- Tran, L.; Liu, X. On learning 3D face morphable model from in-the-wild images. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 1. [Google Scholar] [CrossRef] [Green Version]
- Gecer, B.; Ploumpis, S.; Kotsia, I.; Zafeiriou, S. GANFIT: Generative adversarial network fitting for high fidelity 3D face reconstruction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1155–1164. [Google Scholar]
- Zhu, X.; Lei, Z.; Yan, J.; Yi, D.; Li, S.Z. High-fidelity pose and expression normalization for face recognition in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 787–796. [Google Scholar]
- Zhao, J.; Cheng, Y.; Xu, Y.; Xiong, L.; Li, J.; Zhao, F.; Jayashree, K.; Pranata, S.; Shen, S.; Xing, J.; et al. Towards pose invariant face recognition in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2207–2216. [Google Scholar]
- Cao, J.; Hu, Y.; Zhang, H.; He, R.; Sun, Z. Learning a high fidelity pose invariant model for high-resolution face frontalization. In Proceedings of the Advances in Neural Information Processing Systems 31, Montréal, QC, Canada, 3–8 December 2018; pp. 2867–2877. [Google Scholar]
- Shi, L.; Song, X.; Zhang, T.; Zhu, Y. Histogram-based CRC for 3D-aided pose-invariant face recognition. Sensors 2019, 19, 759. [Google Scholar] [CrossRef] [Green Version]
- Blanz, V.; Basso, C.; Poggio, T.; Vetter, T. Reanimating faces in images and video. Comput. Graph. Forum 2003, 22, 641–650. [Google Scholar] [CrossRef]
- Yang, F.; Bourdev, L.; Shechtman, E.; Wang, J.; Metaxas, D. Facial expression editing in video using a temporally-smooth factorization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 861–868. [Google Scholar]
- Lee, Y.; Terzopoulos, D.; Waters, K. Realistic modeling for facial animation. In Proceedings of the SIGGRAPH’95: 22nd Annual Conference on Computer Graphics and Interactive Techniques, Los Angeles, CA, USA, 6–11 August 1995; pp. 55–62. [Google Scholar]
- Terzopoulos, D.; Waters, K. Physically-based facial modelling, analysis, and animation. J. Vis. Comput. Animat. 1990, 1, 73–80. [Google Scholar] [CrossRef]
- Chuang, E.; Bregler, C. Performance driven facial animation using blendshape interpolation. Tech. Rep. 2002, 2, 3. [Google Scholar]
- Lewis, J.P.; Anjyo, K.; Rhee, T.; Zhang, M.; Pighin, F.H.; Deng, Z. Practice and theory of blendshape facial models. In Proceedings of the Eurographics 2014—State of the Art Reports, Strasbourg, France, 7–11 April 2014; pp. 199–218. [Google Scholar]
- Ekman, P.; Friesen, W. Facial Action Coding System: A Technique for the Measurement of Facial Movement; Consulting Psychologist Press: Palo Alto, CA, USA, 1978. [Google Scholar]
- Thies, J.; Zollhöfer, M.; Stamminger, M.; Theobalt, C.; Nießner, M. Face2Face: Real-time face capture and reenactment of RGB videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2387–2395. [Google Scholar]
- Kim, H.; Garrido, P.; Tewari, A.; Xu, W.; Thies, J.; Niessner, M.; Pérez, P.; Richardt, C.; Zollhöfer, M.; Theobalt, C. Deep video portraits. ACM Trans. Graphics 2018, 37. [Google Scholar] [CrossRef]
- Choi, Y.; Choi, M.J.; Kim, M.; Ha, J.W.; Kim, S.; Choo, J. StarGAN: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8789–8797. [Google Scholar]
- Zhou, Y.; Shi, B.E. Photorealistic facial expression synthesis by the conditional difference adversarial autoencoder. In Proceedings of the International Conference on Affective Computing and Intelligent Interaction, San Antonio, TX, USA, 23–26 October 2017; pp. 370–376. [Google Scholar]
- De Lathauwer, L.; De Moor, B.; Vandewalle, J. A multilinear singular value decomposition. SIAM J. Matrix Anal. Appl. 2000, 21, 1253–1278. [Google Scholar] [CrossRef] [Green Version]
- King, D.E. Dlib-Ml: A machine learning toolkit. J. Mach. Learn. Res. 2009, 10, 1755–1758. [Google Scholar]
- Liu, D.C.; Nocedal, J. On the limited memory BFGS method for large scale optimization. Math. Program. Ser. A B 1989, 45, 503–528. [Google Scholar] [CrossRef] [Green Version]
- Pérez, P.; Gangnet, M.; Blake, A. Poisson image editing. ACM Trans. Graph. 2003, 22, 313–318. [Google Scholar] [CrossRef]
- Vasilescu, M.A.O.; Terzopoulos, D. Multilinear analysis of image ensembles: TensorFaces. In Proceedings of the European Conference on Computer Vision, Copenhagen, Denmark, 28–31 May 2002; pp. 447–460. [Google Scholar]
- Wang, H.; Ahuja, N. Facial expression decomposition. In Proceedings of the IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003; pp. 958–965. [Google Scholar]
- Choi, S.E.; Jo, J.; Lee, S.; Choi, H.; Kim, I.J.; Kim, J. Age face simulation using aging functions on global and local features with residual images. Expert Syst. 2017, 80, 107–125. [Google Scholar] [CrossRef]
- Huber, P.; Hu, G.; Tena, R.; Mortazavian, P.; Koppen, W.P.; Christmas, W.J.; Rätsch, M.; Kittler, J. A multiresolution 3D morphable face model and fitting framework. In Proceedings of the Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, Rome, Italy, 27–29 February 2016; pp. 79–86. [Google Scholar]
- Gross, R.; Matthews, I.; Cohn, J.; Kanade, T.; Baker, S. Multi-PIE. In Proceedings of the 8th IEEE International Conference on Automatic Face Gesture Recognition, Amsterdam, The Netherlands, 17–19 September 2008; pp. 1–8. [Google Scholar]
- Cristinacce, D.; Cootes, T.F. Feature detection and tracking with constrained local models. Pattern Recognit. 2006, 41, 929–938. [Google Scholar]
- Chen, D.; Cao, X.; Wen, F.; Sun, J. Blessing of dimensionality: High-dimensional feature and its efficient compression for face verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3025–3032. [Google Scholar]
- Ojala, T.; Pietikäinen, M.; Matti, T.; Mäenpää, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Chen, D.; Cao, X.; Wang, L.; Wen, F.; Sun, J. Bayesian face revisited: A joint formulation. In Proceedings of the European Conference on Computer Vision, Firenze, Italy, 7–13 October 2012; pp. 566–579. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Pose/Method | Original Image | HPEN [16] | Proposed Method |
|---|---|---|---|
| 99.2647 | - | - | |
| 97.3985 | 97.8875 | 98.8435 | |
| 94.8325 | 96.775 | 96.817 | |
| 75.5446 | 93.1578 | 92.5905 |
| Original Image | HPEN [16] | Proposed | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Smile# | Surprise | Squint | Disgust | Scream | Smile# | Surprise | Squint | Disgust | Scream | Smile# | Surprise | Squint | Disgust | Scream | |
| 95.9152 | 93.2103 | 98.6928 | 93.9189 | 93.4039 | 96.4101 | 94.1558 | 98.0392 | 95.2305 | 94 | 96.8233 | 94.2113 | 97.4809 | 95.8739 | 93.4333 | |
| 91.3701 | 89.4938 | 96.8152 | 92.5424 | 92.4516 | 93.3701 | 90.9872 | 96.3624 | 91.8304 | 93.5263 | 94.5310 | 91.2475 | 97.8047 | 93.7581 | 92.1842 | |
| 90.0689 | 81.3001 | 87.6666 | 85.0130 | 70.2653 | 91.2222 | 86.7556 | 91.4615 | 90.2075 | 85.7518 | 91.9109 | 85.5640 | 90.3672 | 89.2809 | 83.6842 | |
| 78.8131 | 69.2453 | 75.7044 | 76.6013 | 65.7579 | 89.0257 | 85.6274 | 88.4313 | 89.4693 | 80.3333 | 89.5263 | 84.3549 | 88.7527 | 89.7608 | 78.6436 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hong, Y.-J.; Choi, S.E.; Nam, G.P.; Choi, H.; Cho, J.; Kim, I.-J. Adaptive 3D Model-Based Facial Expression Synthesis and Pose Frontalization. Sensors 2020, 20, 2578. https://doi.org/10.3390/s20092578
Hong Y-J, Choi SE, Nam GP, Choi H, Cho J, Kim I-J. Adaptive 3D Model-Based Facial Expression Synthesis and Pose Frontalization. Sensors. 2020; 20(9):2578. https://doi.org/10.3390/s20092578
Chicago/Turabian StyleHong, Yu-Jin, Sung Eun Choi, Gi Pyo Nam, Heeseung Choi, Junghyun Cho, and Ig-Jae Kim. 2020. "Adaptive 3D Model-Based Facial Expression Synthesis and Pose Frontalization" Sensors 20, no. 9: 2578. https://doi.org/10.3390/s20092578
APA StyleHong, Y.-J., Choi, S. E., Nam, G. P., Choi, H., Cho, J., & Kim, I.-J. (2020). Adaptive 3D Model-Based Facial Expression Synthesis and Pose Frontalization. Sensors, 20(9), 2578. https://doi.org/10.3390/s20092578