Explora: Interactive Querying of Multidimensional Data in the Context of Smart Cities


Abstract
:1. Introduction
- lInstrumented systems that enable capturing live real-world data describing the operation of both physical and virtual systems of the city (sensors, smartphones, cameras, and social media, among others.)
- lInterconnected systems enabling the instrumented systems to communicate and interact not only among themselves but also with the multiple IT systems supporting the operation of the city’s services.
- Intelligent systems able to analyze, model, and visualize the above interconnected data and to derive from the valuable insights that drive decisions and actions to optimize the operation of the city’s services and infrastructure.
- Typical visual exploration applications for this kind of georeferenced time series present the user with a sort of dashboard containing a map and a number of controls allowing them to perform visual queries on said data on a per region (e.g., by interacting with the map) and a per time period (e.g., by setting an interval of dates) basis [10]. However, these applications are not able to deliver sensible and predictable response times when operating over highly dynamic data such as the raw readings coming from smart city sensors due to its unbounded size: queries can take from several seconds to minutes over a few million sensor measurements. Considering that these queries define restrictions on the spatial and temporal dimensions of data, it is appealing to establish a fragmentation strategy over these two dimensions in order to reduce the cardinality of the search space by computing continuous data summaries. These summaries amount to a fraction of the number of raw observations, allowing data exploration applications to remain responsive to user queries at the expense of some accuracy.
- These summaries being proactively derived out of the incoming stream of sensor readings enables data management systems to provide client applications with information about the current state of the measured variables without incurring expensive scan operations over the whole raw data. For said summaries to be relevant, frequent user requests as well as interaction patterns when visually exploring spatiotemporal data should be considered to drive the design of the stream processing pipeline and to determine which technologies could support its operation. By abstracting a generic framework embracing these requirements, it is possible to test to what extent existing data technologies support time-sensitive applications and to estimate their limitations in terms of scalability and reliability.
2. Related Work
2.1. Spatiotemporal Data Management
2.2. Visual Exploratory Analysis on Smart City Data
2.3. Big Data Frameworks for Smart Cities
3. Explora: Interactive Exploration of Spatiotemporal Data through Continuous Aggregation
3.1. Framework Requirements and Features
- R1.
- Support elementary and general visual exploratory tasks on spatiotemporal data generated by mobile sensors in a smart city setup.
- R2.
- Provide fast answers (sub-second timescales as target) to queries serving the two basic visual exploratory tasks stated inR1.
3.2. Enabling Techniques
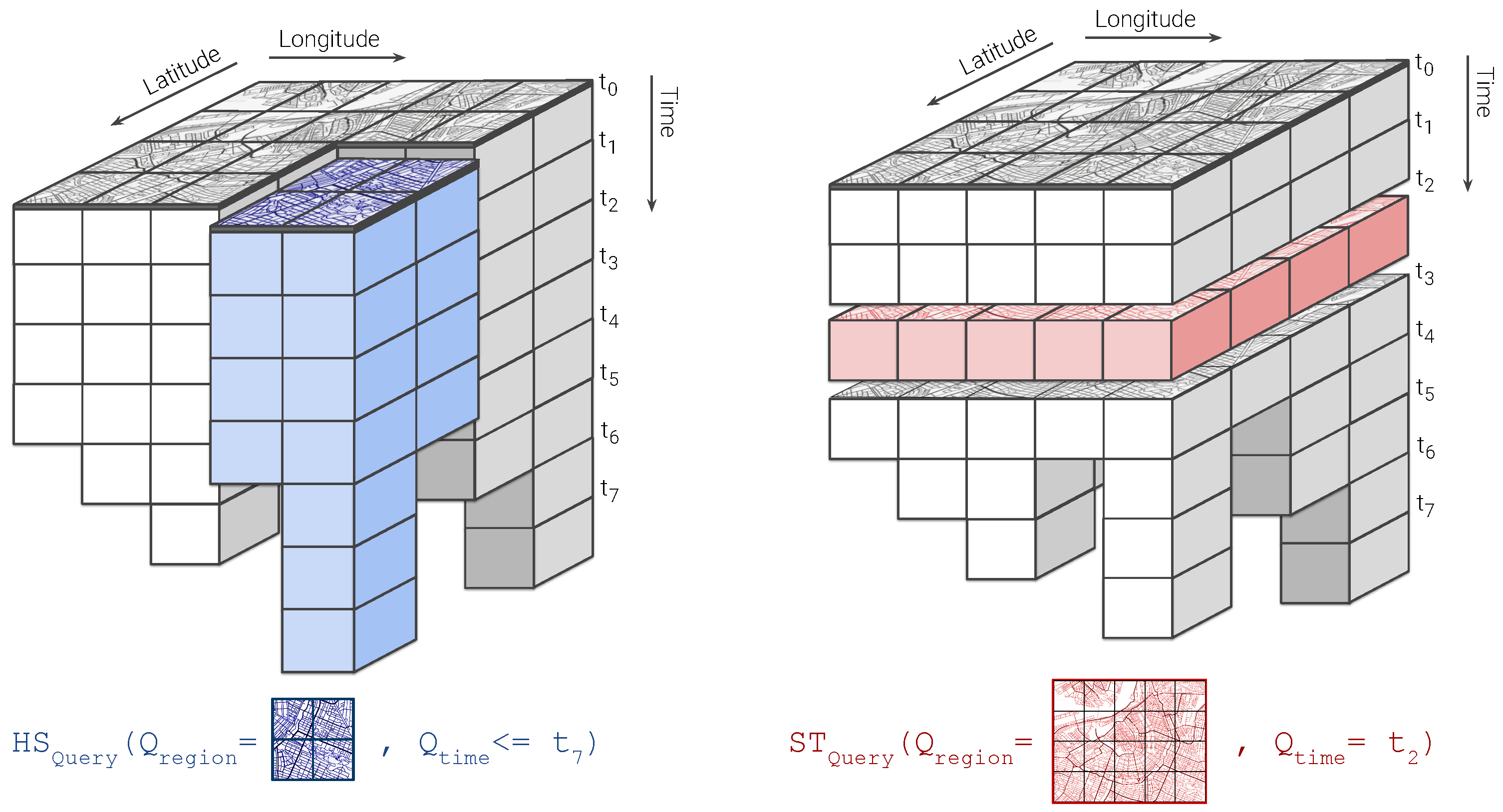
3.2.1. Query Categorization
3.2.2. Data Synopsis and Spatiotemporal Fragmentation
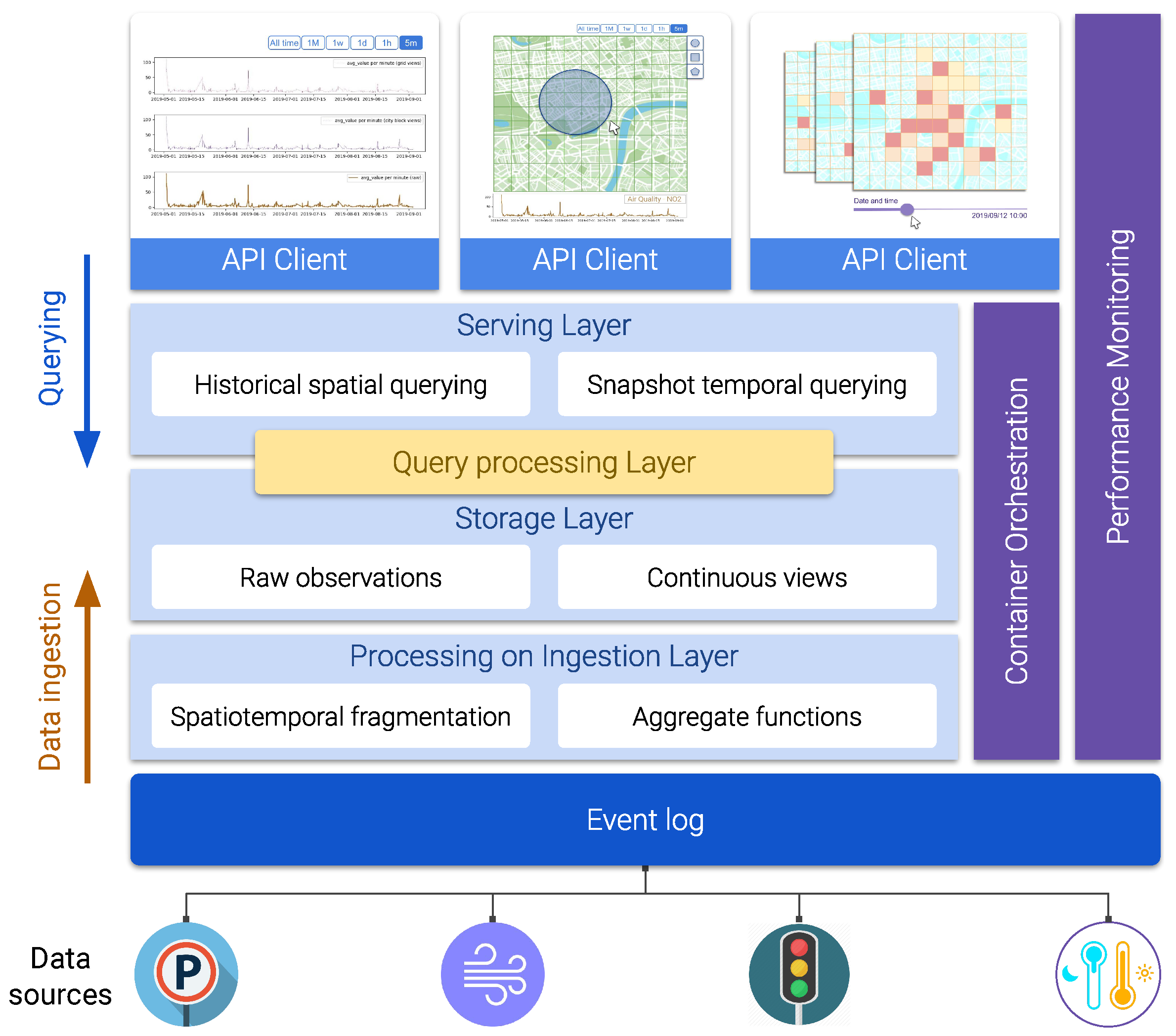
3.3. The Explora Framework: Components and Architecture
- Event log
- This layer serves as an interface between the framework and the sensor data providers. It collects the raw sensor data and hands it over to the upper layers for scalable and reliable consumption and further processing. This tier can be realized through a distributed append-only log that implements a publish–subscribe pattern, allowing data producers to post raw sensor observations to logical channels (topics) that are eventually consumed by client applications in an asynchronous way.
- Processing on ingestion
- This layer subscribes to the event log to consume the stream of raw sensor observations and processes them to continuously generate the data synopsis structures that the framework thrives on. The stream processing mechanism this layer implements is subject to the particular designated spatiotemporal fragmentation strategy and the set of supported aggregate functions used to compute the corresponding data summaries. This layer represents one of the core components of the Explora framework, as it comprises the modules in charge of applying the ingestion procedure that will be further discussed later in this section (Algorithm 1).
- Storage layer
- This tier comprises the artifacts responsible for providing persistent storage for both the continuous views generated in the ingestion layer and the stream of raw sensor observations being consumed from the event log, along with the corresponding programming interfaces (APIs) for enabling modules in adjacent tiers to conduct basic data retrieval tasks. Complex requests—such as those supporting the elementary and general exploratory tasks discussed back in Section 3.1—might be handled in cooperation with the serving layer at the top, depending on querying capabilities offered by the data storage technologies implemented in this layer.
- Serving layer
- This tier provides an entry point for visual exploratory applications to interact with the framework and to access the available sensor data. The serving layer implements a uniform API allowing client applications to issue historical-spatial and snapshot-temporal queries against the data persisted in the storage layer (both raw observations and continuous views). Depending on the storage technologies used in the underlying storage layer, the serving tier might also take part in the query resolution process. This is why query processing is represented as a separate layer, sitting in between the two upper tiers.
- Query processing
- As stated above, responsibilities of this tier overlap those from the contiguous layers (serving and storage). The processing performed in this layer supports query answering for both historical-spatial and snapshot-temporal inquiries (according to the procedures detailed in Algorithms 2 and 3, discussed later in Section 3.4). Where this processing takes place is determined by the capabilities of query API provided by the data storage being used. Thus, for instance, a data store offering an expressive SQL interface would be able to handle most of the query processing tasks, while a typical key-value store offering simple lookup operations would require a large part of the query processing to be performed programmatically in the serving layer.
- Container orchestration
- All the functional components of the Explora framework are implemented as containerized microservices. The container orchestration layer is in charge of the automatic deployment, scaling, load balancing, networking, and life-cycle management of the containers that these components operate on. Examples of existing technologies able to support the functionality required from this layer are Kubernetes [42]—deemed as the de facto standard for container orchestration to date—OpenShift [43], and Apache Mesos [44].
- Performance monitoring
- The role of this layer is to keep track of a number of metrics accounting for the computing requirements (memory and CPU usage) and overall performance of a system implementing the Explora framework (query response time and accuracy). To that end, this layer relies on tools provided by the container orchestrator, the operating system, and third-party libraries for statistical analysis and data visualization. Performance information such as that reported later in Section 5 is compiled in this layer.
- Client applications
- Finally, visual exploratory applications consume the API available through the serving layer to support different data exploration use cases based on the two abstracted categories of exploratory tasks: elementary and general. Section 4 provides a number of examples of said use cases, presented as part of proof-of-concept implementations of the proposed framework.
3.4. The Explora Framework: Formal Methods and Algorithms
3.4.1. Data Ingestion: Continuous Computation of Data Synopsis Structures
| Algorithm 1 Explora ingestion procedure. | |
| 1: Let be a stream of sensor observations of a variable | |
| 2: | ▹ Unbounded set of sensor readings |
| 3: Let be a spatial fragmentation strategy | |
| 4: | |
| 5: Let be the frequency of aggregation | ▹ e.g., minutely, hourly, daily |
| 6: Let be a set of aggregate operations | ▹ e.g., AVG, SUM, COUNT |
| 7: Create persistent storage for view | |
| 8: for each reading in do | |
| 9: | ▹ Get the spatial fragment and temporal bin for |
| 10: | ▹ Get the data summary should be aggregated into |
| 11: for each operation in do | ▹ Update data summary aggregates |
| 12: | |
| 13: if then | ▹ If there is no aggregate for AGGR yet, then initialize it with |
| 14: | |
| 15: else | ▹ Otherwise, update the current aggregate for AGGR with |
| 16: Update with | |
| 17: end if | |
| 18: Update in | |
| 19: Persist in | ▹ Finally, update the continuous view |
| 20: end for | |
| 21: end for | |
3.4.2. Query Processing: Historical-Spatial Queries
| Algorithm 2 Explora query processing for historical-spatial queries. | |
| 1: Let be a continuous view being fed with sensor observations from a variable , with spatial fragmentation and aggregation frequency | |
| 2: Let be a set of aggregate operations | ▹ e.g. AVG, SUM, COUNT |
| 3: procedure () | |
| 4: input: an arbitraty polygonal selection from a 2D map () and a time interval () | |
| 5: output: summary time-series () | |
| 6: | ▹ Get the set of spatial fragments inside |
| 7: | ▹ Starting temporal bin |
| 8: | ▹ Ending temporal bin |
| 9: | ▹ Initialize result set |
| 10: for to do | |
| 11: | ▹ Initialize empty aggregated summary for |
| 12: for each fragment in do | |
| 13: | ▹ Get the data summary for and |
| 14: for each operation in do | |
| 15: | |
| 16: if then | ▹ If there is no aggregate for AGGR yet, then initialize it with |
| 17: | |
| 18: else | ▹ Otherwise, combine the existing aggregate for AGGR with |
| 19: Combine with | |
| 20: end if | |
| 21: Update in | ▹ Update the aggregated summary |
| 22: end for | |
| 23: end for | |
| 24: Append to | |
| 25: end for | |
| 26: return | ▹ The time series of aggregated summaries |
| 27: end procedure | |
3.4.3. Query Processing: Snapshot-Temporal Queries
| Algorithm 3 Explora query processing for snapshot-temporal queries. | |
| 1: Let be a continuous view being fed with sensor observations from a variable , with spatial fragmentation and aggregation frequency | |
| 2: procedure () | |
| 3: input: a snapshot timestamp () and a polygonal selection from a 2D map () | |
| 4: output: temporal snapshot () | |
| 5: | ▹ Get the set of spatial fragments inside |
| 6: | ▹ Get the querying temporal bin |
| 7: | ▹ Initialize result set |
| 8: for each fragment in do | |
| 9: | ▹ Get the data summary for and |
| 10: if then | ▹ If there is a data summary under |
| 11: Append to | |
| 12: end if | |
| 13: end for | |
| 14: return | ▹ Snapshot of , over at |
| 15: end procedure | |
4. Prototype Implementation
4.1. Application Scenario: The Bel-Air Project
4.2. Target Use Cases for Visual Exploratory Applications on Spatiotemporal Data
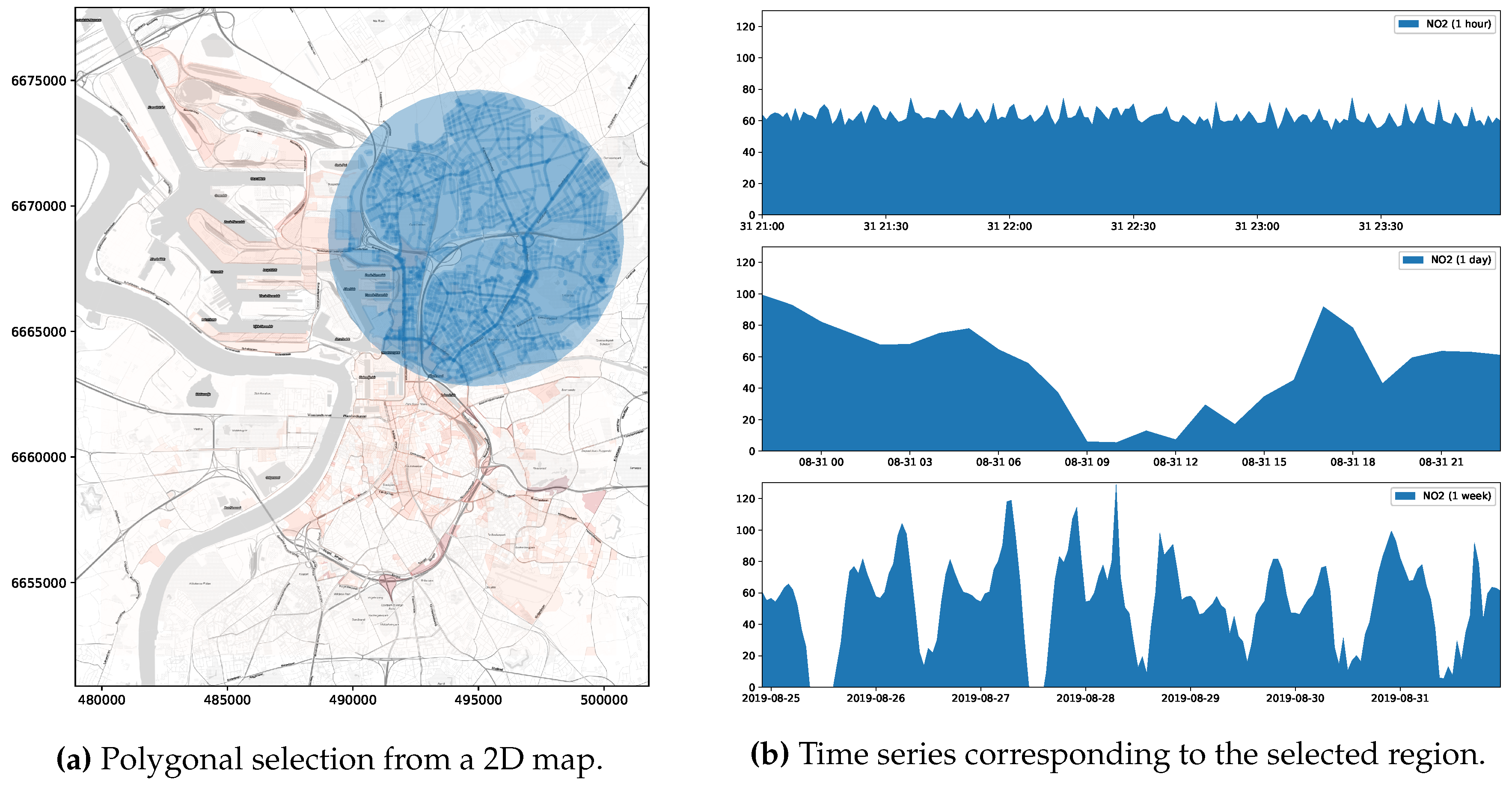
4.2.1. Visualizing the Temporal Change of an Observed Variable over a Certain Region
4.2.2. Progressive Approximate Query Answering
4.2.3. Dynamic Choropleth Map
4.3. Proof-of-Concept Implementations of Explora
- Event log
- Apache Kafka is used to implement this layer of the architecture. Kafka provides a number of tools for processing and analyzing streams of data, including a distributed message broker that adopts the publish–subscribe pattern. This Kafka broker allows for registering each of the incoming sensor observations into a partitioned append-only log, maintaining them over a fixed configurable retention period, which enable multiple consumers (as many as the number of partitions) to read and process the collected data in an asynchronous-concurrent way.
- Container orchestration
- The components in the serving, storage, and processing on ingestion layers are built as Docker containers and are deployed on a Kubernetes cluster, consisting of one master node and three working nodes, all of them running Ubuntu 18.04.3 LTS.
- Performance monitoring
- Data regarding query response time, query accuracy, and computing resources usage for all the components of the system is captured via bash and Python scripting. Once collected, this information is analyzed and visualized through a series of Jupyter notebooks that make use of the Pandas and Matplotlib Python libraries.
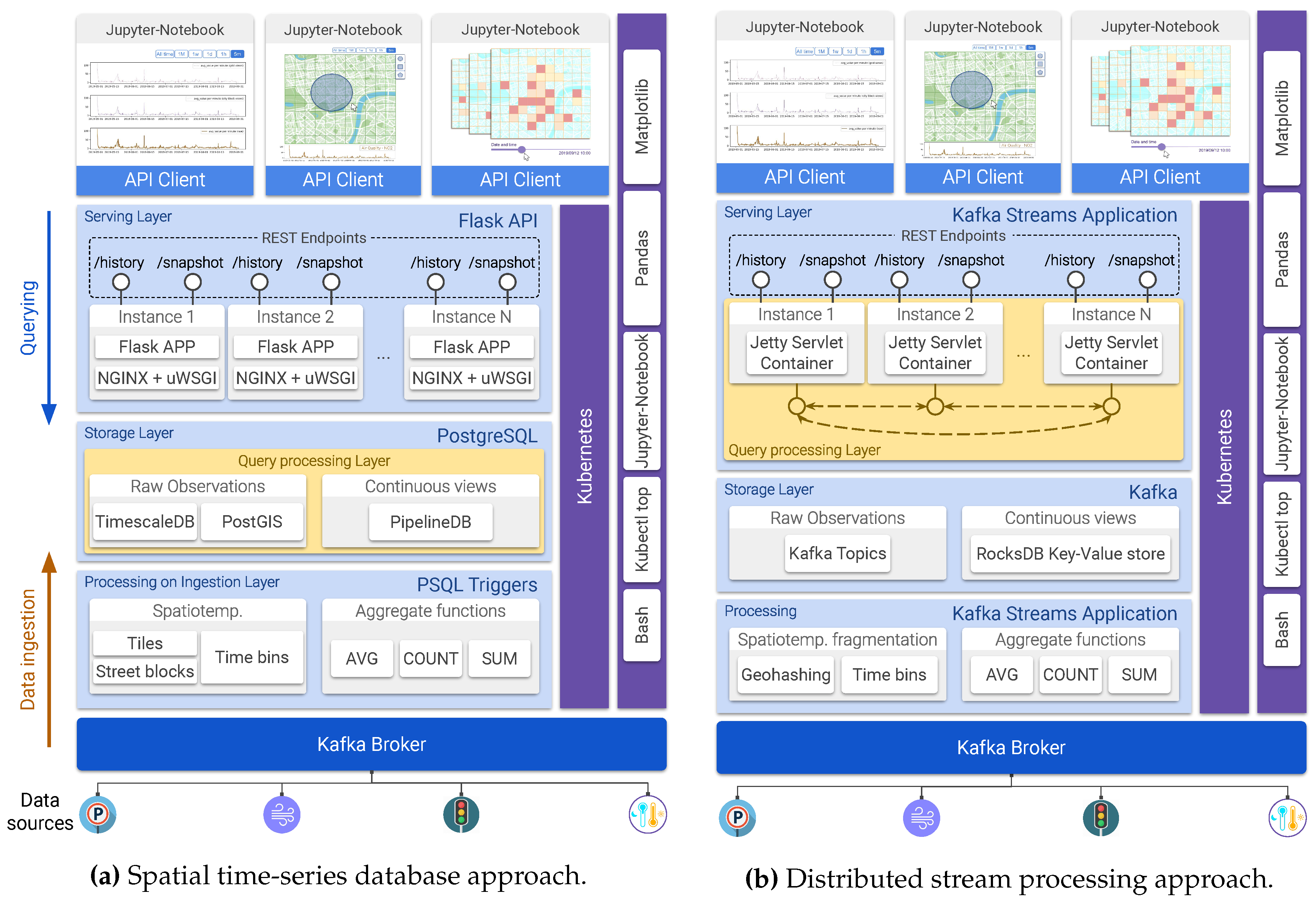
- Serving Layer
- A REST API is implemented for serving client applications. In the PostgreSQL-based implementation (see Figure 10a), this API is provided by using the Flask web framework for Python and NGINX+uWSGI as an application server, while in the distributed stream processing approach (Figure 10b), this API runs on a Jetty servlet container. This REST API consists of two endpoints: one for handling historical-spatial queries and the other for snapshot-temporal queries. The specification of each of the API endpoints is presented below in Table 1. Multiple instances of the API server are deployed to balance the load and to provide high availability.
- Client applications
- Two Jupyter notebooks are deployed as client applications, one implementing the first two use cases described in Section 4.2 and another implementing the third use case. Figure 11 shows screen captures taken from these implementations.These notebooks consume the API available in the serving layer to resolve the historical-spatial and snapshot-temporal queries that support the interaction with end users.
4.3.1. Spatial Time-Series Database Approach
- Processing on ingestion
- PostgreSQL triggers are used to implement the ingestion procedure described in Algorithm 1. These trigger functions are invoked for each of the sensor readings being consumed from the Kafka broker, relaying them to the corresponding continuous views for aggregation before being persisted into the time-series storage. Two spatial fragmentation schemas have been laid over the region covered by the mobile sensors, namely a tile grid built according to the geohash encoding algorithm by Niemeyer G. [48] (see Figure 1a for reference) and a grid corresponding to the street-blocks of the city of Antwerp (see Figure 1b). Additionally, four aggregation frequencies were considered, fragmenting time into minutely, hourly, daily, and monthly bins. In consequence, under this setup, eight continuous views (2-spatial fragmentation schemas × 4-aggregation frequencies) are computed, holding data summaries that comprise the results of three aggregate functions applied over the incoming stream of sensor observations: the arithmetic average of the measured values (AVG), the sum of the measurements (SUM), and number of reported readings (COUNT).
- Storage and query processing layer
- For these layers, three open-source extensions of PostgreSQL are set up on top of this database engine, enabling it to store and query time-series data, to support geospatial operations, and to incrementally create and persist continuous views:
- TimescaleDB [49] is a time-series database working on top of PostgreSQL, thus being able to offer a full SQL querying interface while supporting fast data ingestion. Raw sensor readings consumed from the Kafka broker are formatted and stored into a TimescaleDB Hypertable, which partitions data in the temporal dimension for efficient ingestion and fast retrieval.
- PostGIS [50] is a spatial extension that allows PostgreSQL to store and query information about location and mapping. With PostGIS in place, the GeoJSON specifications of the tile and street-block grids are stored as two spatial tables, for which the records correspond to individual tile/street-block from the spatial fragmentation schemes. Likewise, each one of the records from the TimescaleDB Hypertable are augmented with a PostGIS geography object that corresponds to the sensor reading location. This enables the execution of spatial join operations required later during the querying stage to address calculations such as point-in-polygon and polygon intersection.
- PipelineDB [51] is an extension that enables the computation of continuous aggregates on time-series data, storing the results into regular PostgreSQL tables. The eight continuous views mentioned earlier are created in PipelineDB and incrementally computed as continuous queries running against the stream of sensor observations being handed in through the trigger functions in the ingestion layer. For illustration, Listing 1 presents the SQL statement used in PipelineDB for creating a view that computes the three stated aggregates on a per-minute basis.
| Listing 1: Example of a view creation statement in PipelineDB. |
| CREATE VIEW aq_no2_minutely_view WITH (action = materialize) AS |
| SELECT fragment_id, observed_var, minute (time) AS ts, |
| COUNT (*) AS count, |
| SUM (value) AS sum_value, |
| AVG (value) AS avg_value |
| FROM aq_no2_stream -- stream of NO2 sensor measurements |
| GROUP BY fragment_id, observed_var, ts; |
| Listing 2: Example of a HS query statement running on PipelineDB. | |
| SELECT observed_var, ts, combine (avg_value) AS avg_value | |
| FROM aq_no2_minutely_view | |
| INNER JOIN tile_grid ON aq_no2_minutely_view. fragment_id = tile_grid.id | |
| WHERE ST_Contains (ST_GeomFromText (’<QUERY_POLYGON>’), tile_grid.geom) | |
| GROUP BY observed_var, ts | |
| ORDER BY ts; | -- QUERY_POLYGON: Well - Known Text (WKT) representation |
| -- of the user’s polygonal selection. | |
4.3.2. Distributed Stream Processing Approach
- Processing on ingestion
- A Kafka streams application is implemented for this layer, according to the procedure in Algorithm 1. The Kafka streams library provides an API for conducting distributed stateful transformations on the feed of sensor observations being pushed to the Kafka broker by enabling multiple stream processor instances to consume the partitioned Kafka topics that the sensor readings are being written to. In consequence, the global application state is also partitioned into a distributed key-value store, instances of which are collocated with the working stream processors. Since Kafka streams does not support spatial operations out-of-the-box, in order to set up a statiotemporal fragmentation schema, a compound record key was associated to each of the incoming sensor observations, consisting of their geohash code (a base 32 sequence of 12 characters encoding the latitude and longitude of the measurement), along with their correponding timestamp, formatted as in the example shown below:
| Listing 3: Example of a continuous view with hourly time bins in Kafka Streams. The segment presented corresponds to the spatial fragment identified by the geohash prefix u14dhq. |
| … |
| u14dhq #20191101:140000:000: {AVG: 54.32, SUM: 182678.16, COUNT:3363}, |
| u14dhq #20191101:150000:000: {AVG: 32.10, SUM: 111964.80, COUNT:3488}, |
| u14dhq #20191101:160000:000: {AVG: 45.13, SUM: 147755.62, COUNT:3274}, |
| u14dhq #20191101:170000:000: {AVG: 90.08, SUM: 304560.48, COUNT:3381}, |
| … |
- Storage layer
- This layer is also supported by tools provided by Kafka: raw sensor observations are stored into Kafka topics, while continuous views generated in the ingestion layer are stored into a distributed key-value database known as RocksDB [52], which Kafka uses as the default state store for stream applications. While records stored in Kafka topics are not directly queryable, continuous views in RocksDB allow simple key-based lookup and range queries. This is why a major part of the query processing needs to be conducted in the serving layer, when handling the client application requests.
- Query processing and serving layer
- In this distributed setup, an instance of the REST API serving client requests is hosted on each of the Kafka stream processors. Each of these instances is only capable of answering queries on the portion of the application state available to the hosting stream processor. Therefore, resolving a query on the global state requires combining the results computed on the state available to each of the stream processor thus far. Consider for instance the example presented in Figure 12, illustrating the procedure for a setup with three stream processors, resolving a historical-spatial query: (1) The query reaches one of the instances of the serving layer API. This instance processes the query against the version of the continuous view persisted on its own state store. (2) Then, the query is relayed to a second instance to retrieve the data summaries from its corresponding state store and to combine them with those obtained from the first instance. (3) This process is repeated until the query reaches the last API instance. Finally, the resulting sequence of aggregated data summaries is retrieved to the client application.It is worth noting that the simplicity of the querying interface offered by the state stores—limited basically to key-based lookups and range queries—along with the key-value data model they adopt pay off in terms of query processing time, as will be shown when discussing the performance of these proof-of-concept implementations in the following section.
5. Experimental Evaluation
5.1. Query Accuracy Metric
5.2. Experimental Setup
5.3. Results
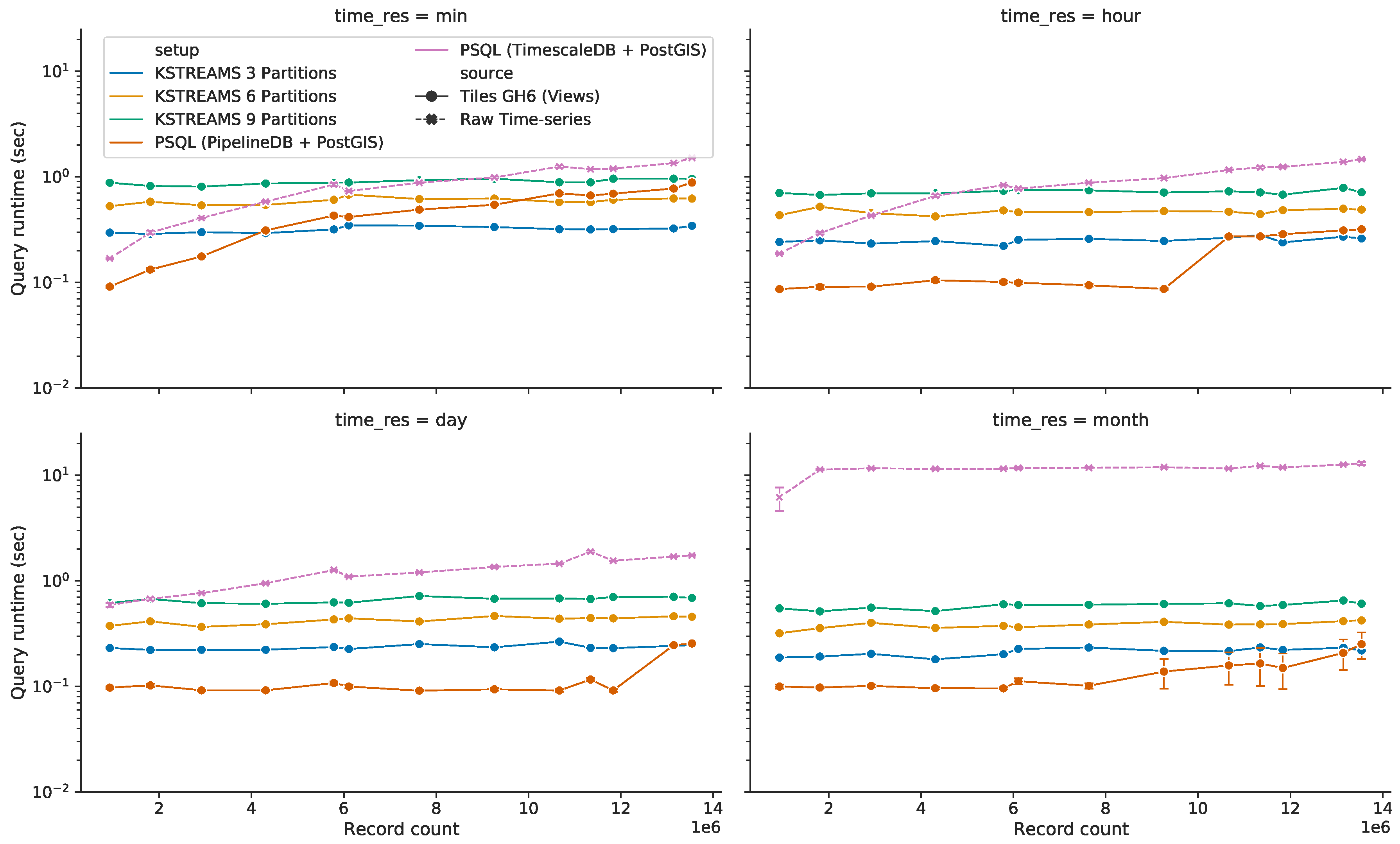
5.3.1. Continuous Views Storage Footprint
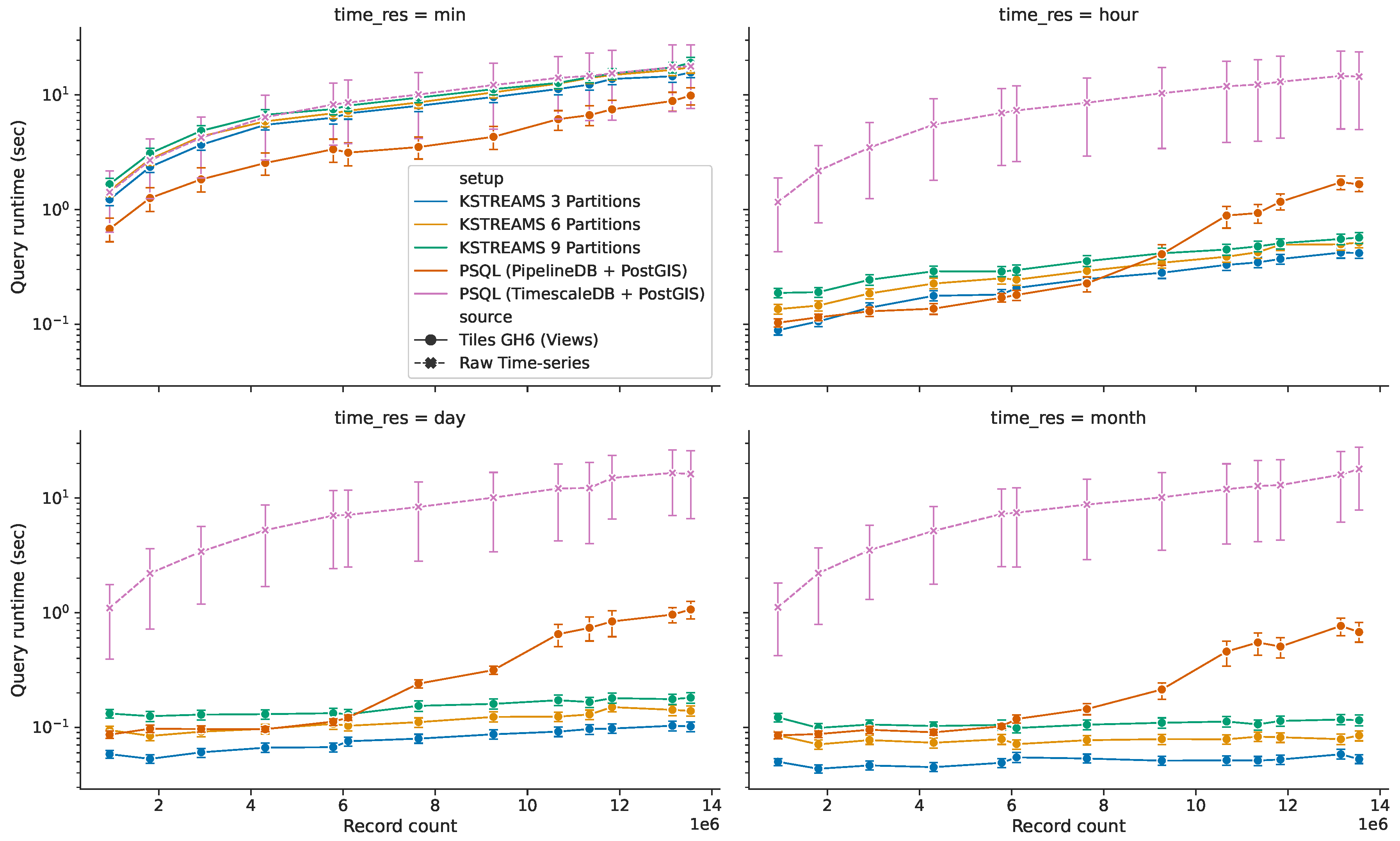
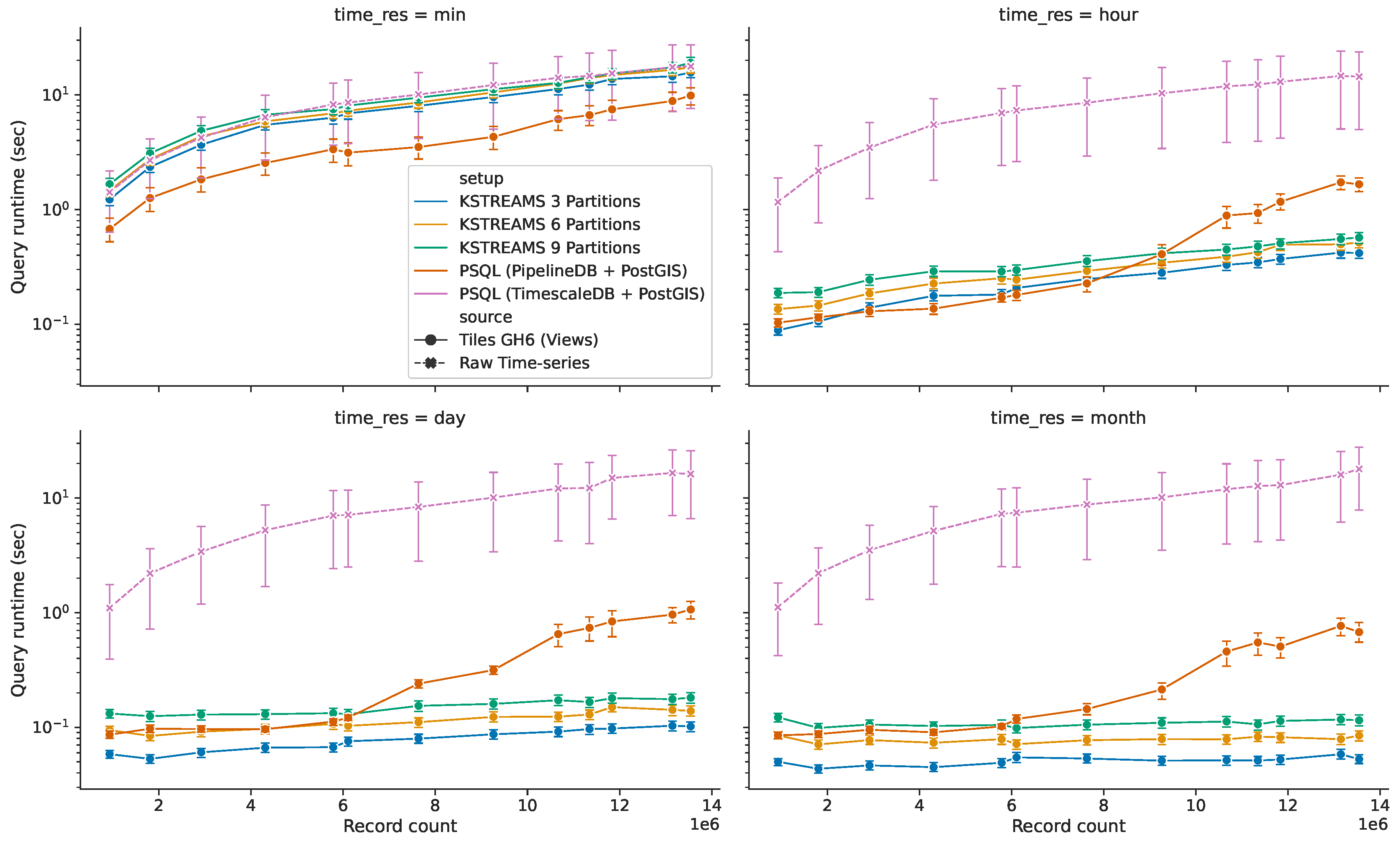
5.3.2. Query Response Time for HS Queries without Time Predicate
- (i)
- Query response time on the raw data (dashed line in Figure 14) behaves nearly the same along the four temporal resolutions, displaying a linear increase as the amount of data ingested grows larger. This describes an expected system’s response, since each of these queries involves running expensive sequential scan operations over the full collection of raw sensor readings. This way, response time for these requests increases proportional to the amount of ingested sensor observations, regardless of the requested temporal resolution.
- (ii)
- Continuous views (solid lines in Figure 14) in general outperform the base raw data for both implementations of Explora. Only for views with per-minute temporal bins the performance benefit from using these synopsis structures is compromised due to the considerable size of said structures relative to the raw data (and to the remaining views, as evidenced earlier in Figure 13). However, even in this case, queries perform 1.1–1.3× faster in the 3-partition/3-processors Kafka setup and 1.8–2.9× faster in the PipelineDB + PostGIS setup compared to queries running against the raw data. For the other considered time resolutions, queries running on the corresponding views perform up to two orders of magnitude faster than the reference setup, reaching sub-second response times in all cases.
- (iii)
- When it comes to distributed stream processing, increasing parallelism—i.e., adding partitions and stream processors accordingly—actually leads to a slight decline in performance, which can be attributed to the overhead due to the process of combining the partial aggregates computed on each of the stream processors, which also implies data exchange among said processors (network overhead). That said, this approach still delivers a more stable response as the data volume grows compared to the spatial time-series approach, describing a linear-time trend for which the slope tends to zero as the temporal resolution of the aggregates decreases—notice the almost constant time for views with per-month temporal bins.
- (iv)
- For ingested data under 6–8 million sensor observations, queries on the spatial time-series approach either outperform or closely follow the performance of those from distributed streaming setups. From 8 million records onwards, the query response time for the PipelineDB + PostGIS setup branches out, describing an exponential growth. In this situation, given the increased volume of data, indexed tables can no longer fit in the available memory; in consequence, parts of the index are repeatedly swap in and out of the database buffer pool, leading to a performance degradation.
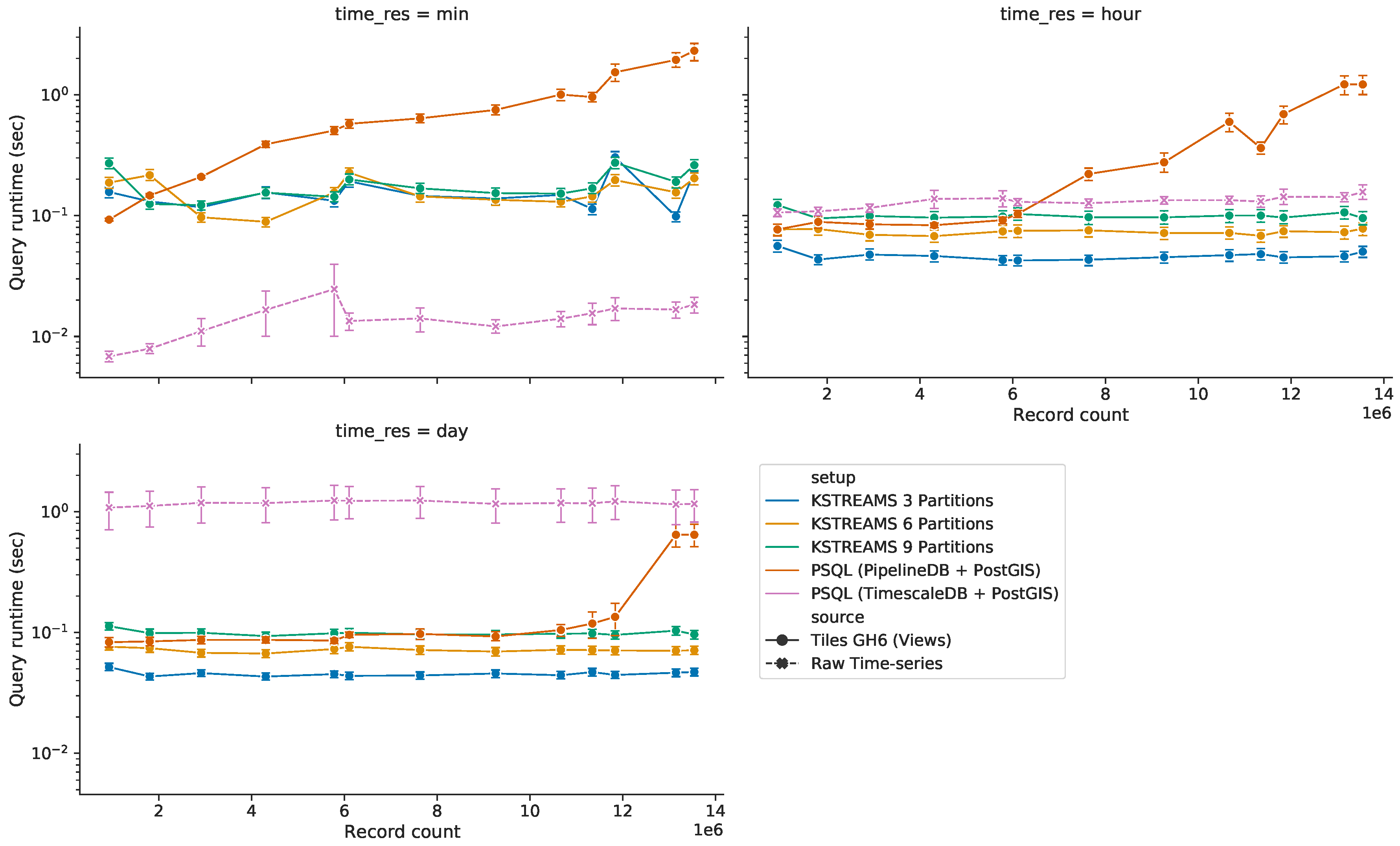
5.3.3. Query Response Time for HS Queries with Time Predicate
5.3.4. Query Response Time for ST Queries
5.3.5. Query Accuracy on Continuous Views
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| API | Application programming interface |
| CSV | Comma-separated values |
| JSON | Javascript object notation |
| RDF | Resource description framework |
| SQL | Structured query language |
References
- Sánchez-Corcuera, R.; Nuñez-Marcos, A.; Sesma-Solance, J.; Bilbao-Jayo, A.; Mulero, R.; Zulaika, U.; Azkune, G.; Almeida, A. Smart cities survey: Technologies, application domains and challenges for the cities of the future. Int. J. Distrib. Sens. Netw. 2019, 15. [Google Scholar] [CrossRef] [Green Version]
- Harrison, C.; Eckman, B.; Hamilton, R.; Hartswick, P.; Kalagnanam, J.; Paraszczak, J.; Williams, P. Foundations for smarter cities. IBM J. Res. Dev. 2010, 54, 1–16. [Google Scholar] [CrossRef]
- Lea, R.; Blackstock, M.; Giang, N.; Vogt, D. Smart cities: Engaging users and developers to foster innovation ecosystems. In Adjunct Proceedings of the 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2015 ACM International Symposium on Wearable Computers, Osaka, Japan, 7–11 September 2015; pp. 1535–1542. [Google Scholar]
- Veeckman, C.; Van Der Graaf, S. The city as living laboratory: Empowering citizens with the citadel toolkit. Technol. Innov. Manag. Rev. 2015, 5, 6–17. [Google Scholar] [CrossRef]
- Gascó-Hernandez, M. Building a Smart City: Lessons from Barcelona. Commun. ACM 2018, 61, 50–57. [Google Scholar] [CrossRef]
- Chauhan, S.; Agarwal, N.; Kar, A.K. Addressing big data challenges in smart cities: A systematic literature review. Info 2016, 18. [Google Scholar] [CrossRef] [Green Version]
- Silva, B.N.; Khan, M.; Han, K. Towards sustainable smart cities: A review of trends, architectures, components, and open challenges in smart cities. Sustain. Cities Soc. 2018, 38, 697–713. [Google Scholar] [CrossRef]
- Marcu, O.C.; Costan, A.; Antoniu, G.; Pérez-Hernández, M.; Tudoran, R.; Bortoli, S.; Nicolae, B. Storage and Ingestion Systems in Support of Stream Processing: A Survey; RT-0501; INRIA Rennes-Bretagne Atlantique and University of Rennes 1: Rennes, France, December 2018. [Google Scholar]
- Zoumpatianos, K.; Palpanas, T. Data Series Management: Fulfilling the Need for Big Sequence Analytics. In Proceedings of the 2018 IEEE 34th International Conference on Data Engineering (ICDE), Paris, France, 16–19 April 2018; pp. 1677–1678. [Google Scholar] [CrossRef]
- Doraiswamy, H.; Tzirita Zacharatou, E.; Miranda, F.; Lage, M.; Ailamaki, A.; Silva, C.T.; Freire, J. Interactive Visual Exploration of Spatio-Temporal Urban Data Sets Using Urbane. In Proceedings of the 2018 International Conference on Management of Data, Hoston, TX, USA, 10–15 June 2018; pp. 1693–1696. [Google Scholar] [CrossRef] [Green Version]
- Yang, C.; Clarke, K.; Shekhar, S.; Tao, C.V. Big Spatiotemporal Data Analytics: A research and innovation frontier. Int. J. Geogr. Inf. Sci. 2019, 34, 1–14. [Google Scholar] [CrossRef] [Green Version]
- He, J.; Chen, H.; Chen, Y.; Tang, X.; Zou, Y. Diverse visualization techniques and methods of moving-object-trajectory data: A review. ISPRS Int. J. Geo-Inf. 2019, 8, 63. [Google Scholar] [CrossRef] [Green Version]
- Ganti, R.; Srivatsa, M.; Agrawal, D.; Zerfos, P.; Ortiz, J. MP-Trie: Fast Spatial Queries on Moving Objects. In Proceedings of the Industrial Track of the 17th International Middleware Conference, Trento, Italy, 12–16 December 2016. [Google Scholar] [CrossRef]
- Agrawal, D.; Ganti, R.; Jonas, J.; Srivatsa, M. STB: Space time boxes. CCF Trans. Pervasive Comput. Interact. 2019, 1, 114–124. [Google Scholar] [CrossRef] [Green Version]
- Beckmann, N.; Kriegel, H.P.; Schneider, R.; Seeger, B. The R*-tree: An efficient and robust access method for points and rectangles. In Proceedings of the 1990 ACM SIGMOD International Conference on Management of Data, Atlantic City, NJ, USA, 23–25 May 1990; pp. 322–331. [Google Scholar]
- Kempke, R.A.; McAuley, A.J. Ternary CAM Memory Architecture and Methodology, 1998. US5841874A, 19 February 1998. [Google Scholar]
- Vo, H.; Aji, A.; Wang, F. SATO: A spatial data partitioning framework for scalable query processing. In Proceedings of the 22nd ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Dallas, TX, USA, 4–7 November 2014; pp. 545–548. [Google Scholar]
- Aly, A.M.; Mahmood, A.R.; Hassan, M.S.; Aref, W.G.; Ouzzani, M.; Elmeleegy, H.; Qadah, T. AQWA: Adaptive query workload aware partitioning of big spatial data. Proc. VlDB Endow. 2015, 8, 2062–2073. [Google Scholar] [CrossRef]
- Pavlovic, M.; Sidlauskas, D.; Heinis, T.; Ailamaki, A. QUASII: QUery-Aware Spatial Incremental Index. In Proceedings of the 21st International Conference on Extending Database Technology (EDBT), Vienna, Austria, 26–29 March 2018; pp. 325–336. [Google Scholar]
- García-García, F.; Corral, A.; Iribarne, L.; Vassilakopoulos, M. Voronoi-diagram based partitioning for distance join query processing in spatialhadoop. In Proceedings of the International Conference on Model and Data Engineering, Marrakesh, Morocco, 24–26 October 2018; pp. 251–267. [Google Scholar]
- Zacharatou, E.T.; Šidlauskas, D.; Tauheed, F.; Heinis, T.; Ailamaki, A. Efficient Bundled Spatial Range Queries. In Proceedings of the 27th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Chicago, IL, USA, 5–8 November 2019; pp. 139–148. [Google Scholar] [CrossRef] [Green Version]
- Wan, S.; Zhao, Y.; Wang, T.; Gu, Z.; Abbasi, Q.H.; Choo, K.K.R. Multi-dimensional data indexing and range query processing via Voronoi diagram for internet of things. Future Gener. Comput. Syst. 2019, 91, 382–391. [Google Scholar] [CrossRef] [Green Version]
- Ferreira, N.; Lage, M.; Doraiswamy, H.; Vo, H.; Wilson, L.; Werner, H.; Park, M.; Silva, C. Urbane: A 3D framework to support data driven decision making in urban development. In Proceedings of the 2015 IEEE Conference on Visual Analytics Science and Technology (VAST), Chicago, IL, USA, 25–30 October 2015; pp. 97–104. [Google Scholar]
- Murshed, S.M.; Al-Hyari, A.M.; Wendel, J.; Ansart, L. Design and implementation of a 4D web application for analytical visualization of smart city applications. Isprs. Int. J. Geo-Inf. 2018, 7, 276. [Google Scholar] [CrossRef] [Green Version]
- Cesium-Consortium. CesiumJS-Geospatial 3D Mapping and Virtual Globe Platform. Available online: https://cesium.com/cesiumjs/ (accessed on 3 February 2020).
- Li, Z.; Huang, Q.; Jiang, Y.; Hu, F. SOVAS: A scalable online visual analytic system for big climate data analysis. Int. J. Geogr. Inf. Sci. 2019, 34, 1–22. [Google Scholar] [CrossRef]
- Ramakrishna, A.; Chang, Y.H.; Maheswaran, R. An Interactive Web Based Spatio-Temporal Visualization System. In Proceedings of the Advances in Visual Computing, Crete, Greece, 29–31 July 2013; pp. 673–680. [Google Scholar]
- Zhang, X.; Zhang, M.; Jiang, L.; Yue, P. An interactive 4D spatio-temporal visualization system for hydrometeorological data in natural disasters. Int. J. Digit. Earth 2019, 1–21. [Google Scholar] [CrossRef]
- Cao, N.; Lin, C.; Zhu, Q.; Lin, Y.R.; Teng, X.; Wen, X. Voila: Visual anomaly detection and monitoring with streaming spatiotemporal data. IEEE Trans. Vis. Comput. Graph. 2017, 24, 23–33. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.J.; Ho, Y.H.; Hsieh, H.H.; Huang, S.T.; Lee, H.C.; Mahajan, S. ADF: An anomaly detection framework for large-scale PM2.5 sensing systems. IEEE Internet Things J. 2017, 5, 559–570. [Google Scholar] [CrossRef]
- Osman, A.M.S. A novel big data analytics framework for smart cities. Future Gener. Comput. Syst. 2019, 91, 620–633. [Google Scholar] [CrossRef]
- Badii, C.; Belay, E.G.; Bellini, P.; Marazzini, M.; Mesiti, M.; Nesi, P.; Pantaleo, G.; Paolucci, M.; Valtolina, S.; Soderi, M.; et al. Snap4City: A scalable IOT/IOE platform for developing smart city applications. In Proceedings of the 2018 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computing, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation (SmartWorld/SCALCOM/UIC/ATC/CBDCom/IOP/SCI), Guangzhou, China, 8–12 October 2018; pp. 2109–2116. [Google Scholar]
- Badii, C.; Bellini, P.; Difino, A.; Nesi, P.; Pantaleo, G.; Paolucci, M. MicroServices Suite for Smart City Applications. Sensors 2019, 19, 4798. [Google Scholar] [CrossRef] [Green Version]
- Node-Red, A. Visual Tool for Wiring the Internet-of-Things. Available online: http://nodered.org (accessed on 3 February 2020).
- Del Esposte, A.d.M.; Santana, E.F.; Kanashiro, L.; Costa, F.M.; Braghetto, K.R.; Lago, N.; Kon, F. Design and evaluation of a scalable smart city software platform with large-scale simulations. Future Gener. Comput. Syst. 2019, 93, 427–441. [Google Scholar] [CrossRef]
- Scattone, F.F.; Braghetto, K.R. A Microservices Architecture for Distributed Complex Event Processing in Smart Cities. In Proceedings of the 2018 IEEE 37th International Symposium on Reliable Distributed Systems Workshops (SRDSW), Salvador, Brazil, 2–5 October 2018; pp. 6–9. [Google Scholar]
- Aguilera, U.; Peña, O.; Belmonte, O.; López-de Ipiña, D. Citizen-centric data services for smarter cities. Future Gener. Comput. Syst. 2017, 76, 234–247. [Google Scholar] [CrossRef] [Green Version]
- Andrienko, N.; Andrienko, G.; Gatalsky, P. Exploratory spatio-temporal visualization: An analytical review. J. Vis. Lang. Comput. 2003, 14, 503–541. [Google Scholar] [CrossRef]
- Roth, R.E.; Çöltekin, A.; Delazari, L.; Filho, H.F.; Griffin, A.; Hall, A.; Korpi, J.; Lokka, I.; Mendonça, A.; Ooms, K.; et al. User studies in cartography: Opportunities for empirical research on interactive maps and visualizations. Int. J. Cartogr. 2017, 3, 61–89. [Google Scholar] [CrossRef]
- Liu, Z.; Heer, J. The effects of interactive latency on exploratory visual analysis. IEEE Trans. Vis. Comput. Graph. 2014, 20, 2122–2131. [Google Scholar] [CrossRef] [PubMed]
- Liu, L.; Özsu, M.T. Encyclopedia of Database Systems; Springer: New York, NY, USA, 2009. [Google Scholar]
- Kubernetes, I. Kubernetes: Production-Grade Container Orchestration. Available online: https://kubernetes.io/ (accessed on 3 March 2020).
- Red Hat OpenShift. Available online: https://www.openshift.com/ (accessed on 3 March 2020).
- Apache, S.F. Apache Mesos. Available online: http://mesos.apache.org/ (accessed on 3 March 2020).
- Han, J.; Kamber, M.; Pei, J. (Eds.) Chapter 4 Data Warehousing and Online Analytical Processing. In Data Mining, 3rd ed.; Elsevier: Waltham, MA, USA, 2012; pp. 125–185. [Google Scholar] [CrossRef]
- Latre, S.; Leroux, P.; Coenen, T.; Braem, B.; Ballon, P.; Demeester, P. City of things: An integrated and multi-technology testbed for IoT smart city experiments. In Proceedings of the 2016 IEEE International Smart Cities Conference (ISC2), Trento, Italy, 12–15 September 2016; pp. 1–8. [Google Scholar] [CrossRef]
- Apache, S.F. Apache Kafka. Available online: https://kafka.apache.org/ (accessed on 3 March 2020).
- Niemeyer, G. Geohashing. Available online: https://obelisk.ilabt.imec.be/api/v2/docs/documentation/concepts/geohash/ (accessed on 3 March 2020).
- Timescale, I. TimescaleDB: An Open Source Time-Series SQL Database Optimized for Fast Ingest and Complex Queries, Powered by PostgreSQL. Available online: https://www.timescale.com/products (accessed on 3 March 2020).
- PostGIS. Spatial and Geographic Objects for PostgreSQL. Available online: https://postgis.net/ (accessed on 3 March 2020).
- Nelson, D.; Ferguson, J. PipelineDB: High-Performance Time-Series Aggregation for PostgreSQL. Available online: https://www.pipelinedb.com (accessed on 3 March 2020).
- Facebook, O.S. RocksDB: A Persistent Key-Value Store for Fast Storage Environments. Available online: https://rocksdb.org/ (accessed on 3 March 2020).
- Gold, O.; Sharir, M. Dynamic time warping and geometric edit distance: Breaking the quadratic barrier. ACM Trans. Algorithms (TALG) 2018, 14, 1–17. [Google Scholar] [CrossRef]
- imec/IDLab. Virtual Wall: Perform Large Networking and Cloud Experiments. Available online: https://doc.ilabt.imec.be/ilabt/virtualwall/index.html (accessed on 11 March 2020).
- Ordonez-Ante, L.; Van Seghbroeck, G.; Wauters, T.; Volckaert, B.; De Turck, F. A Workload-Driven Approach for View Selection in Large Dimensional Datasets. J Netw. Syst. Manag. 2020. [Google Scholar] [CrossRef]
- Verborgh, R.; Vander Sande, M.; Colpaert, P.; Coppens, S.; Mannens, E.; Van de Walle, R. Web-Scale Querying through Linked Data Fragments. In Proceedings of the 7th Workshop on Linked Data on the Web, Seoul, Korea, 8 April 2014. [Google Scholar]
- Rojas Melendez, J.A.; Sedrakyan, G.; Colpaert, P.; Vander Sande, M.; Verborgh, R. Supporting sustainable publishing and consuming of live Linked Time Series Streams. In Proceedings of the European Semantic Web Conference, Heraklion, Greece, 3–7 June 2018; pp. 148–152. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| HS queries: GET /airquality/{metric_id}/aggregate/{aggregate}/history | |
| Path parameters |
|
| Query paramenters |
|
| ST queries: GET/airquality/{metric_id}/aggregate/{aggregate}/snapshot | |
| Path parameters | Same as for the previous endpoint |
| Query paramenters |
|
| Software | Version |
|---|---|
| Kubectl | 0.15.10 |
| Linux Kernel | 4.15.0-66-generic |
| Operating System | Ubuntu 18.04.3 LTS |
| Container Runtime Version | containerd://1.2.6 |
| PostgreSQL (TimescaleDB + PostGIS + PipelineDB) | 11.5 (1.4.2 + 2.5.2 + 1.0.0) |
| Apache Kafka | 2.3.0 |
| NGINX + uWSGI | 1.14.2 + 2.0.17.1 |
| Jetty Server | 9.4.20.v20190813 |
| Java (OpenJDK) | 14-ea |
| Python | 3.7.5 |
| Query Type | # Queries |
|---|---|
| HS (w/temporal predicate) | 90 |
| HS (w/o temporal predicate) | 52 |
| ST | 80 |
| Total | 222 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ordonez-Ante, L.; Van Seghbroeck, G.; Wauters, T.; Volckaert, B.; De Turck, F. Explora: Interactive Querying of Multidimensional Data in the Context of Smart Cities. Sensors 2020, 20, 2737. https://doi.org/10.3390/s20092737
Ordonez-Ante L, Van Seghbroeck G, Wauters T, Volckaert B, De Turck F. Explora: Interactive Querying of Multidimensional Data in the Context of Smart Cities. Sensors. 2020; 20(9):2737. https://doi.org/10.3390/s20092737
Chicago/Turabian StyleOrdonez-Ante, Leandro, Gregory Van Seghbroeck, Tim Wauters, Bruno Volckaert, and Filip De Turck. 2020. "Explora: Interactive Querying of Multidimensional Data in the Context of Smart Cities" Sensors 20, no. 9: 2737. https://doi.org/10.3390/s20092737
APA StyleOrdonez-Ante, L., Van Seghbroeck, G., Wauters, T., Volckaert, B., & De Turck, F. (2020). Explora: Interactive Querying of Multidimensional Data in the Context of Smart Cities. Sensors, 20(9), 2737. https://doi.org/10.3390/s20092737