
Real-Time Small Drones Detection Based on Pruned YOLOv4


Abstract
1. Introduction
2. Related Work
- RetinaNet: RetinaNet is a one-stage object detector that can address the problem of class imbalance by using a loss function called focal loss. Class imbalance is the situation in which the number of background instances is considerably larger than that of the target object instances. Thus, class imbalance wastes the network’s attention on the background, and the features of the target object cannot be learned sufficiently. Focal loss enables the network to focus on hard examples of the object of interest and prevents a large number of background examples from inhibiting method training.
- FCOS: Like RetinaNet, FCOS is a fully convolutional one-stage object detector to solve object detection in a per-pixel prediction, analog to semantic segmentation [18]. FCOS disregards the predefined anchor boxes, which play an important role in all state-of-the-art object detectors, such as Faster RCNN [27], RetinaNet, YOLOv4 and single shot multi-box detector [28]. Instead of anchor boxes, FCOS predicts a 4D vector (l, t, r, b) that encodes the location of a bounding box at each foreground pixel. Given its fully convolutional networks [29], FCOS can eliminate the fixed size of the input image. The network architecture of FCOS is composed of a backbone, a feature pyramid, and center-ness. ResNet-50 can be used as FCOS’s backbone, and the same hyper-parameters as those in RetinaNet are used.
- YOLOv4: Similar to RetinaNet, YOLOv4 is also a one-stage object detector. YOLOv4 is an improved version of YOLOv3. The YOLOv4’s backbone is CSPDarknet53 and the detector head is as same as YOLOv3 [30]. YOLOv3 predicts bounding boxes at three different scales to more accurately match objects of varying sizes. YOLOv3 extracts features from scales by using a concept similar to a feature pyramid network. For its backbone, YOLOv3 uses Darknet-53 because it provides high accuracy and requires fewer operations compared with other architectures. Darknet-53 uses successive 3 × 3 and 1 × 1 convolutional layers and several shortcut connections. Backbone networks extract features and generate three feature maps with different scales. The feature maps are divided into S × S grids. For each grid, YOLOv3 predicts the offset of bounding boxes, an objectness score, and class probabilities. YOLOv3 predicts an objectness score for each bounding box by using logistic regression. Compared with YOLOv3, YOLOv4 also adopts SPP and PAN structures to improve the ability of feature extraction. Meanwhile, probabilities are predicted for each class contained in the dataset. In this study, the number of classes is one, i.e., UAV.
- The integration of the advanced object detectors and pruned YOLOv4 which can detect drone in real-time;
- Our detector can be not only good at detecting large drones but also small drones.
3. Small Drones Detection
3.1. Data Acquisition
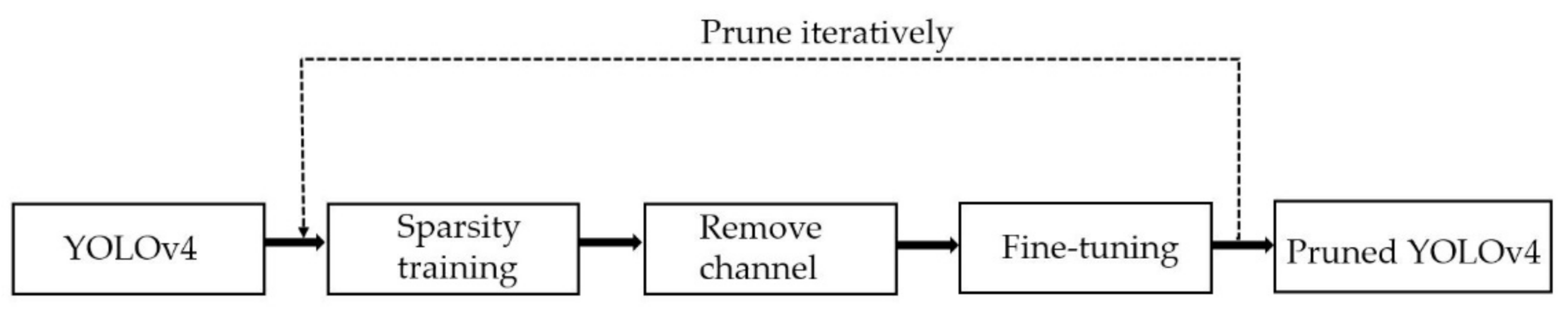
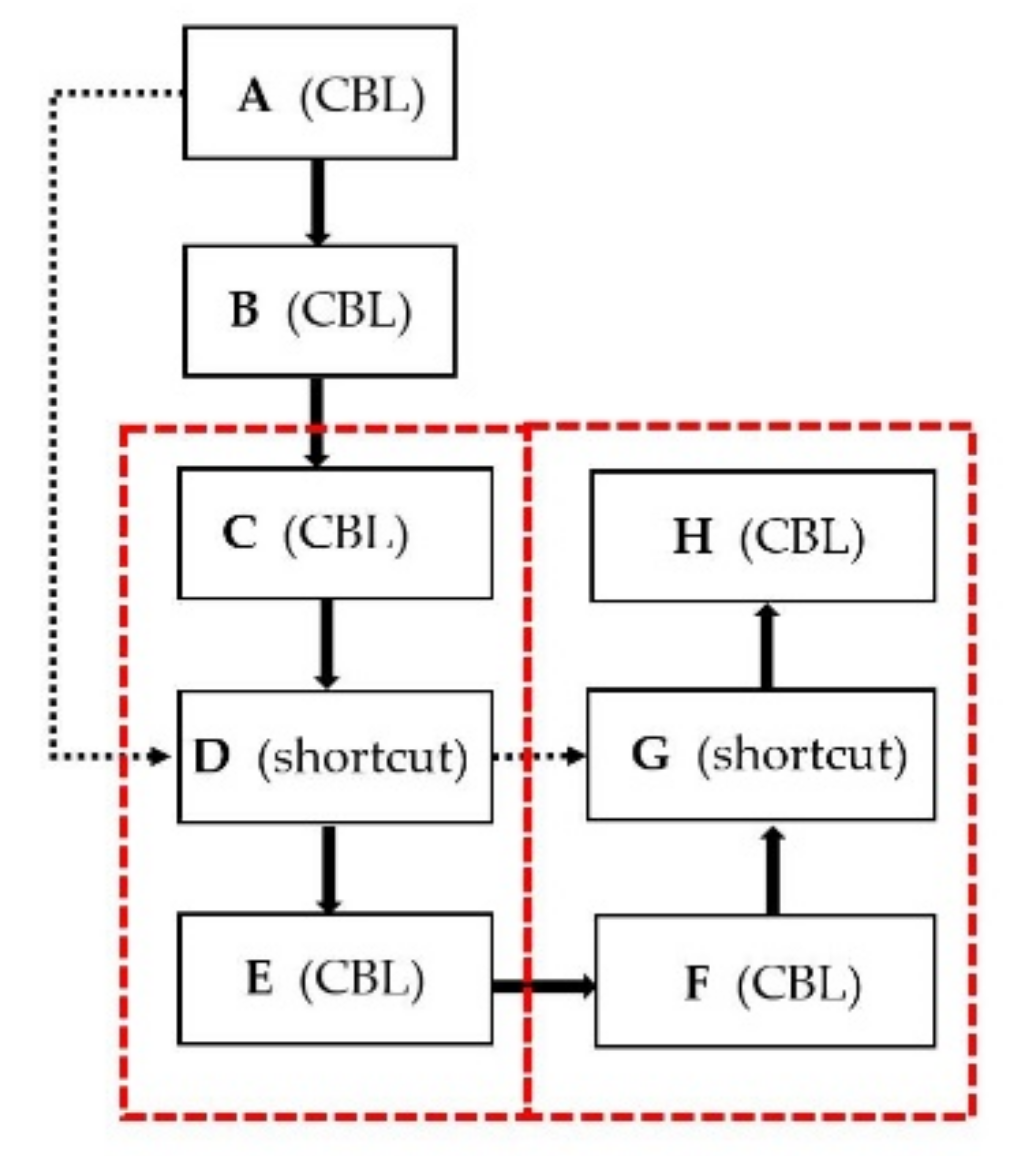
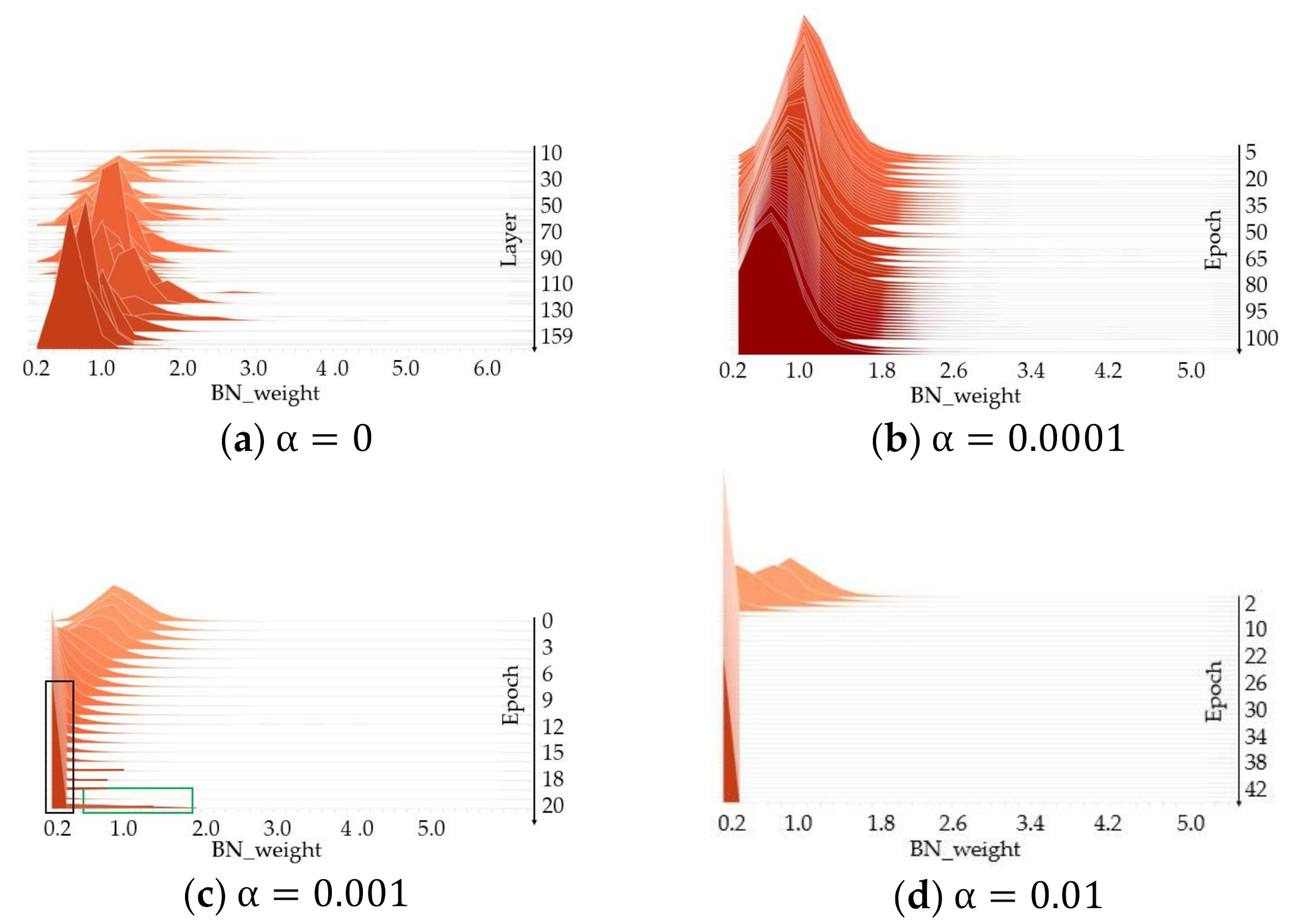
3.2. Pruned YOLOv4
| Algorithm 1. Approach of pruning channel and layer in YOLOv4 |
| Input: layers and shortcut layers of YOLOv4, channel pruning rate and layer pruning |
| Output: The remaining layers after pruning Sparsity training layers and shortcut layers and get of the - channel of - layer Sort of layers and shortcut layers from small to large and then get array Threshold for to do if Remove these channels of - layer end for is shown as Figure 3. is the layer of - shortcut layer structure. for to do if Mark which is the index of channels of layer for to [,,] do Remove channels of layer end for end for Evalute the mean value of for each shortcut layers, then sort from small to large for to do Get the index of shortcut layer Remove and layers end for |
3.3. Small Object Augmentation
4. Experimental Results
4.1. Result of Four DCNN-Based Model
4.2. Result of Pruned YOLOv4
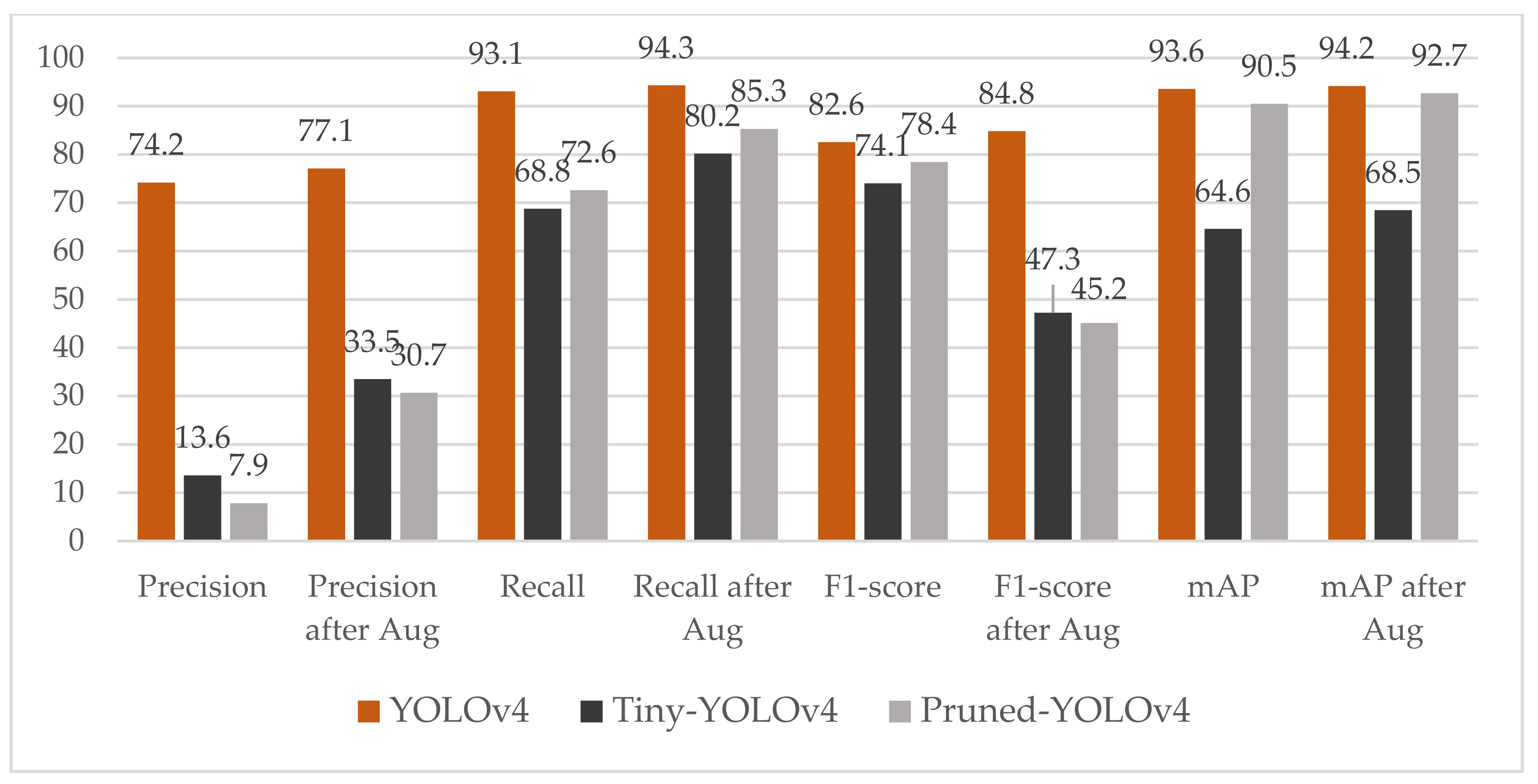
4.3. Result of Data with Small Object Augmentation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shi, X.; Yang, C.; Xie, W.; Liang, C.; Shi, Z.; Chen, J. Anti-Drone System with Multiple Surveillance Technologies: Architecture, Implementation, and Challenges. IEEE Commun. Mag. 2018, 56, 68–74. [Google Scholar] [CrossRef]
- Anwar, M.Z.; Kaleem, Z.; Jamalipour, A. Machine Learning Inspired Sound-Based Amateur Drone Detection for Public Safety Applications. IEEE Trans. Veh. Technol. 2019, 68, 2526–2534. [Google Scholar] [CrossRef]
- Barbieri, L.; Kral, S.T.; Bailey, S.C.; Frazier, A.E.; Jacob, J.D.; Reuder, J.; Doddi, A. Intercomparison of small unmanned aircraft system (sUAS) measurements for atmospheric science during the LAPSE-RATE campaign. Sensors 2019, 19, 2179. [Google Scholar] [CrossRef] [PubMed]
- Nowak, A.; Naus, K.; Maksimiuk, D. A method of fast and simultaneous calibration of many mobile FMCW radars operating in a network anti-drone system. Remote Sens. 2019, 11, 2617. [Google Scholar] [CrossRef]
- Farlik, J.; Kratky, M.; Casar, J.; Stary, V. Radar cross section and detection of small unmanned aerial vehicles. In Proceedings of the International Conference on Mechatronics-mechatronika, Prague, Czech Republic, 7–9 December 2017; pp. 1–7. [Google Scholar]
- Hoffmann, F.; Ritchie, M.; Fioranelli, F.; Charlish, A.; Griffiths, H. Micro-Doppler Based Detection and Tracking of UAVs with Multistatic Radar. In Proceedings of the 2016 IEEE Radar Conference (RadarConf), Philadelphia, PA, USA, 1–6 May 2016; pp. 1–6. [Google Scholar]
- Yang, C.; Wu, Z.; Chang, X.; Shi, X.; Wo, J.; Shi, Z. DOA Estimation using amateur drones harmonic acoustic signals. In Proceedings of the 2018 IEEE 10th Sensor Array and Multichannel Signal Processing Workshop (SAM), Sheffield, UK, 8–11 July 2018; pp. 587–591. [Google Scholar]
- Busset, J.; Perrodin, F.; Wellig, P.; Ott, B.; Heutschi, K.; Rühl, T.; Nussbaumer, T. Detection and tracking of drones using advanced acoustic cameras. In Proceedings of the Unmanned/Unattended Sensors and Sensor Networks XI; and Advanced Free-Space Optical Communication Techniques and Applications, Toulouse, France, 23–24 September 2015; Volume 9647, p. 96470F. [Google Scholar]
- Azari, M.M.; Sallouha, H.; Chiumento, A.; Rajendran, S.; Vinogradov, E.; Pollin, S. Key Technologies and System Trade-offs for Detection and Localization of Amateur Drones. IEEE Commun. Mag. 2018, 56, 51–57. [Google Scholar] [CrossRef]
- Lian, D.; Gao, C.; Qi, F.; Wang, C.; Jiang, L. Small UAV Detection in Videos from a Single Moving Camera. In Proceedings of the CCF Chinese Conference on Computer Vision, Tianjin, China, 11–14 October 2017; Springer: Singapore, 2017; pp. 187–197. [Google Scholar]
- Wang, C.; Wang, T.; Wang, E.; Sun, E.; Luo, Z. Flying Small Target Detection for Anti-UAV Based on a Gaussian Mixture Model in a Compressive Sensing Domain. Sensors 2019, 19, 2168. [Google Scholar] [CrossRef] [PubMed]
- Napoletano, P.; Piccoli, F.; Schettini, R. Anomaly detection in nanofibrous materials by cnn-based self-similarity. Sensors 2018, 18, 209. [Google Scholar] [CrossRef] [PubMed]
- Koga, Y.; Miyazaki, H.; Shibasaki, R. A CNN-based method of vehicle detection from aerial images using hard example mining. Remote Sens. 2018, 10, 124. [Google Scholar]
- Chen, Y.; Zhang, Y.; Xin, J.; Wang, G.; Liu, D. UAV Image-based Forest Fire Detection Approach Using Convolutional Neural Network. In Proceedings of the IEEE Conference on Industrial Electronics & Applications, Xi’an, China, 19–21 June 2019; pp. 2118–2123. [Google Scholar]
- Benjdira, B.; Khursheed, T.; Koubaa, A.; Ammar, A.; Ouni, K. Car Detection using Unmanned Aerial Vehicles: Comparison between Faster R-CNN and YOLOv3. In Proceedings of the 2019 1st International Conference on Unmanned Vehicle Systems-Oman (UVS), Muscat, Oman, 5–7 February 2019; pp. 1–6. [Google Scholar]
- dos Santos, A.A.; Junior, J.M.; Araújo, M.S.; Martini, D.R.; Di Gonalves, W.N. Assessment of CNN-Based Methods for Individual Tree Detection on Images Captured by RGB Cameras Attached to UAVs. Sensors 2019, 19, 3595. [Google Scholar] [CrossRef] [PubMed]
- Samaras, S.; Diamantidou, E.; Ataloglou, D.; Sakellariou, N.; Vafeiadis, A.; Magoulianitis, V.; Lalas, A.; Dimou, A.; Zarpalas, D.; Votis, K.; et al. Deep Learning on Multi Sensor Data for Counter UAV Applications-A Systematic Review. Sensors 2019, 19, 4837. [Google Scholar] [CrossRef] [PubMed]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 9626–9635. [Google Scholar]
- Liu, Z.; Li, J.; Shen, Z.; Huang, G.; Yan, S.; Zhang, C. Learning Efficient Convolutional Networks through Network Slimming. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2755–2763. [Google Scholar]
- Liu, Z.; Sun, M.; Zhou, T.; Huang, G.; Darrell, T. Rethinking the value of network pruning. arXiv 2019, arXiv:1810.05270. [Google Scholar]
- Zhang, P.; Zhong, Y.; Li, X. SlimYOLOv3: Narrower, Faster and Better for Real-Time UAV Applications. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27–28 October 2019; pp. 37–45. [Google Scholar]
- Chen, G.; Choi, W.; Yu, X.; Han, T.; Chandraker, M. Learning Efficient Object Detection Models with Knowledge Distillation. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 742–751. [Google Scholar]
- Frankle, J.; Carbin, M. The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks. arXiv 2018, arXiv:1803.03635. [Google Scholar]
- Frankle, J.; Dziugaite, G.K.; Roy, D.M.; Carbin, M. Stabilizing Lottery Ticket Hypothesis. arXiv 2019, arXiv:1903.01611. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934,2020. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- TtShelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Denton, E.L.; Zaremba, W.; Bruna, J.; LeCun, Y.; Fergus, R. Exploiting Linear Structure Within Convolutional Networks for Efficient Evaluation. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 1269–1277. [Google Scholar]
- Wojna, Z.; Murawski, J.; Naruniec, J. Augmentation for small object detection. arXiv 2019, arXiv:1902.07296. [Google Scholar]
- Han, S.; Pool, J.; Tran, J.; Dally, W. Learning both weights and connections for efficient neural network. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 7–12 December 2015; pp. 1135–1143. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Object | Min Rectangle Area | Max Rectangle Area |
|---|---|---|
| Small Object | 0 × 0 | 32 × 32 |
| Medium Object | 32 × 32 | 96 × 96 |
| Large Object | 96 × 96 | ∞ × ∞ |
| Model | Precision | Recall | F1-Score | mAP |
|---|---|---|---|---|
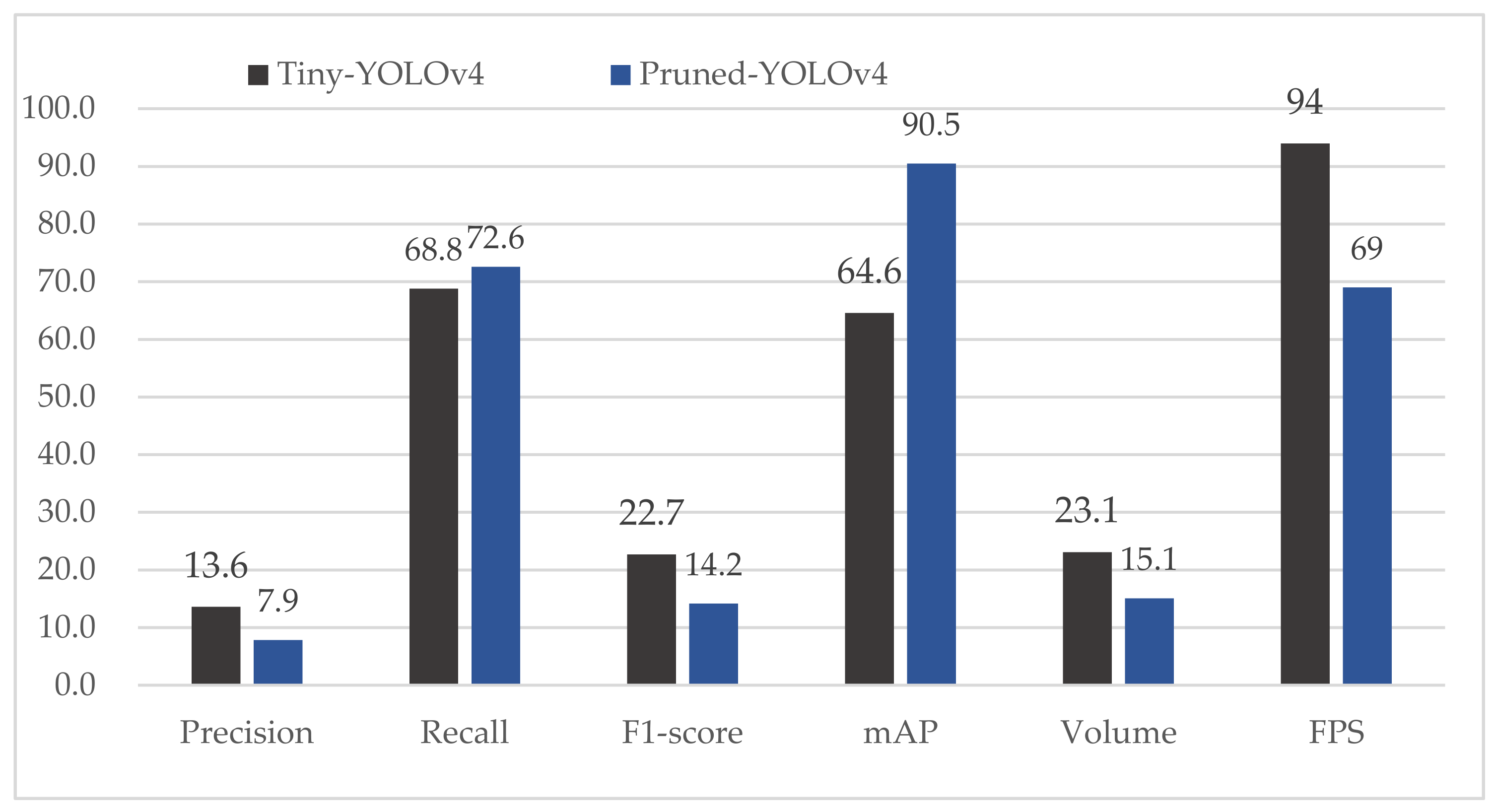
| ResNet-50 | 12.9 | 94.9 | 22.7 | 85.5 |
| ResNet-101 | 26.7 | 78.6 | 39.9 | 90.3 |
| RetinaNet | 68.5 | 91.7 | 78.4 | 90.5 |
| YOLOv3 | 61.7 | 91.5 | 73.7 | 89.1 |
| YOLOv4 | 74.2 | 93.1 | 82.6 | 93.6 |
| Pruned Ratio | mAP | Parameters(M) | FPS |
|---|---|---|---|
| 0 | 93.6 | 63.9 | 43 |
| 0.10 | 91.2 | 52.1 | 46 |
| 0.15 | 69.3 | 47.6 | 55 |
| 0.20 | 12.9 | 43.4 | 60 |
| 0.85 | 0.0 | 8.3 | 79 |
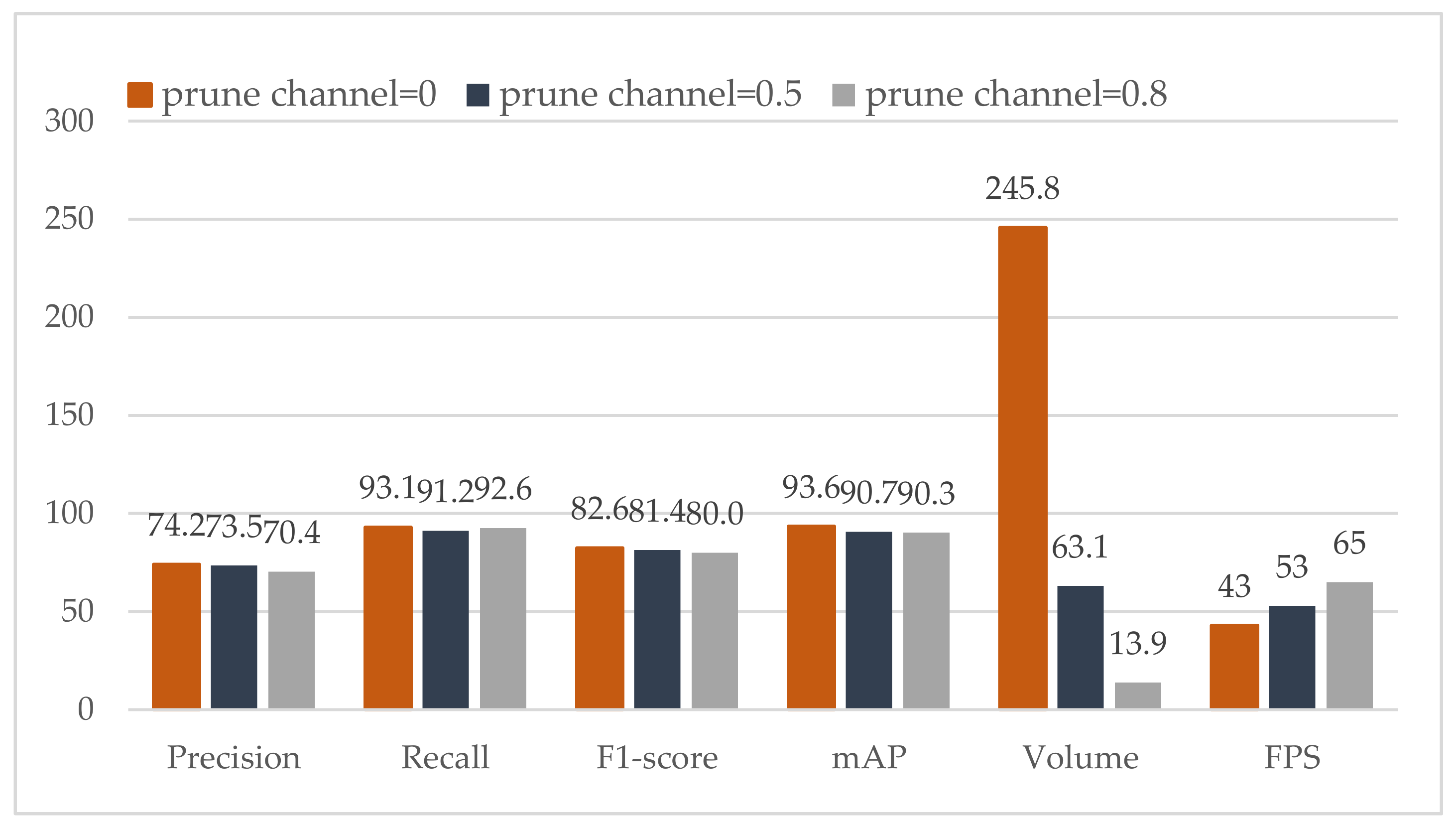
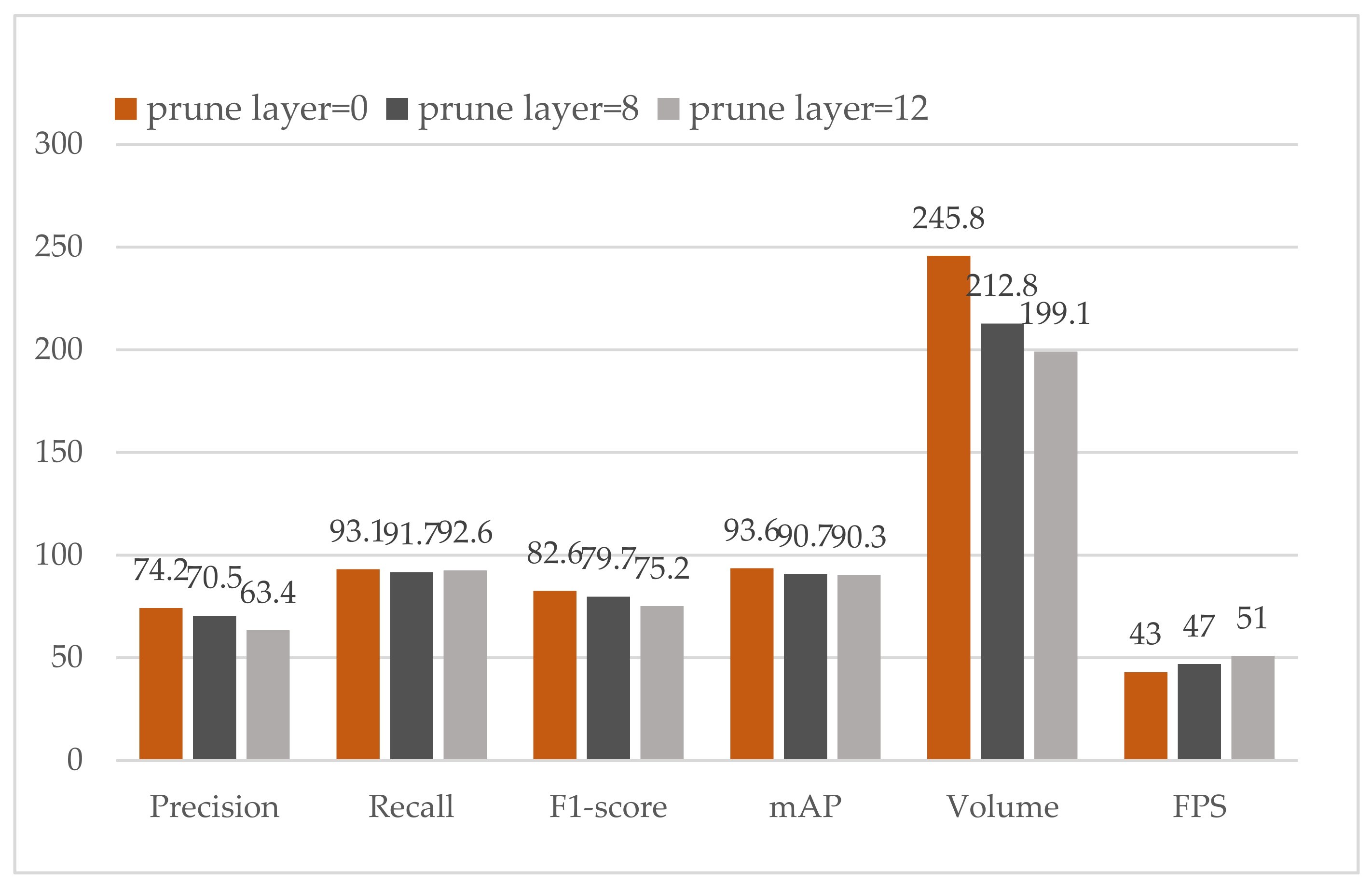
| Channel Prune | Layer Prune | Keep Channel | mAP | Volume(MB) | FPS |
|---|---|---|---|---|---|
| 0 | 0 | 1 | 93.6 | 245.8 | 43 |
| 0.5 | 0 | 0.01 | 90.8 | 63.1 | 53 |
| 0.8 | 0 | 0.01 | 86.3 | 13.9 | 65 |
| 0.9 | 0 | 0.01 | 64.1 | 6.61 | 79 |
| 0 | 8 | 1 | 90.7 | 212.8 | 47 |
| 0 | 12 | 1 | 90.3 | 199.1 | 51 |
| 0.5 | 12 | 0.1 | 90.8 | 52.9 | 64 |
| 0.8 | 8 | 0.1 | 90.5 | 15.1 | 69 |
| 0.8 | 8 | 0.01 | 83.6 | 10.9 | 71 |
| 0.8 | 12 | 0.1 | 78.4 | 9.9 | 75 |
| 0.9 | 8 | 0.01 | 66.5 | 7.4 | 77 |
| 0.9 | 8 | 0.1 | 68.3 | 7.9 | 76 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, H.; Fan, K.; Ouyang, Q.; Li, N. Real-Time Small Drones Detection Based on Pruned YOLOv4. Sensors 2021, 21, 3374. https://doi.org/10.3390/s21103374
Liu H, Fan K, Ouyang Q, Li N. Real-Time Small Drones Detection Based on Pruned YOLOv4. Sensors. 2021; 21(10):3374. https://doi.org/10.3390/s21103374
Chicago/Turabian StyleLiu, Hansen, Kuangang Fan, Qinghua Ouyang, and Na Li. 2021. "Real-Time Small Drones Detection Based on Pruned YOLOv4" Sensors 21, no. 10: 3374. https://doi.org/10.3390/s21103374
APA StyleLiu, H., Fan, K., Ouyang, Q., & Li, N. (2021). Real-Time Small Drones Detection Based on Pruned YOLOv4. Sensors, 21(10), 3374. https://doi.org/10.3390/s21103374