
Benchmarking Audio Signal Representation Techniques for Classification with Convolutional Neural Networks


Abstract
:1. Introduction
2. Literature Review
3. Audio Signal Representation Techniques
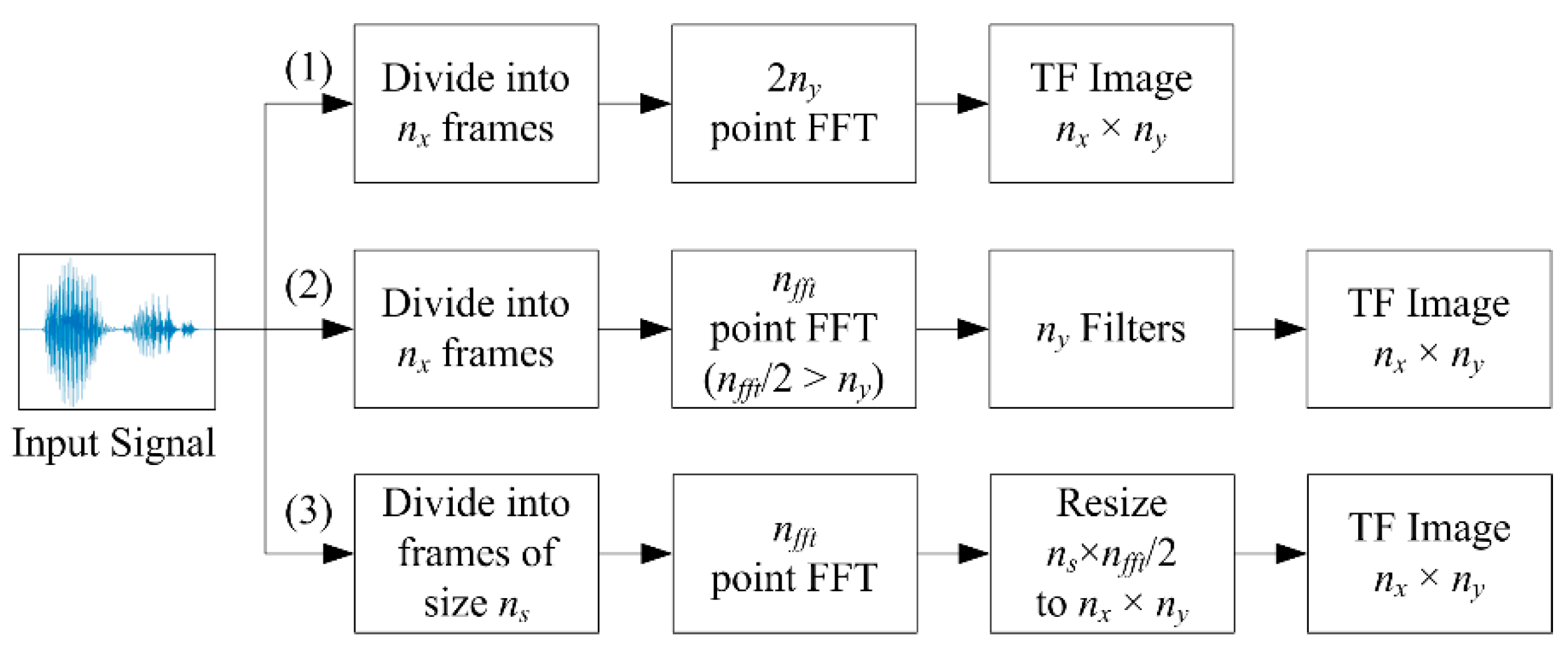
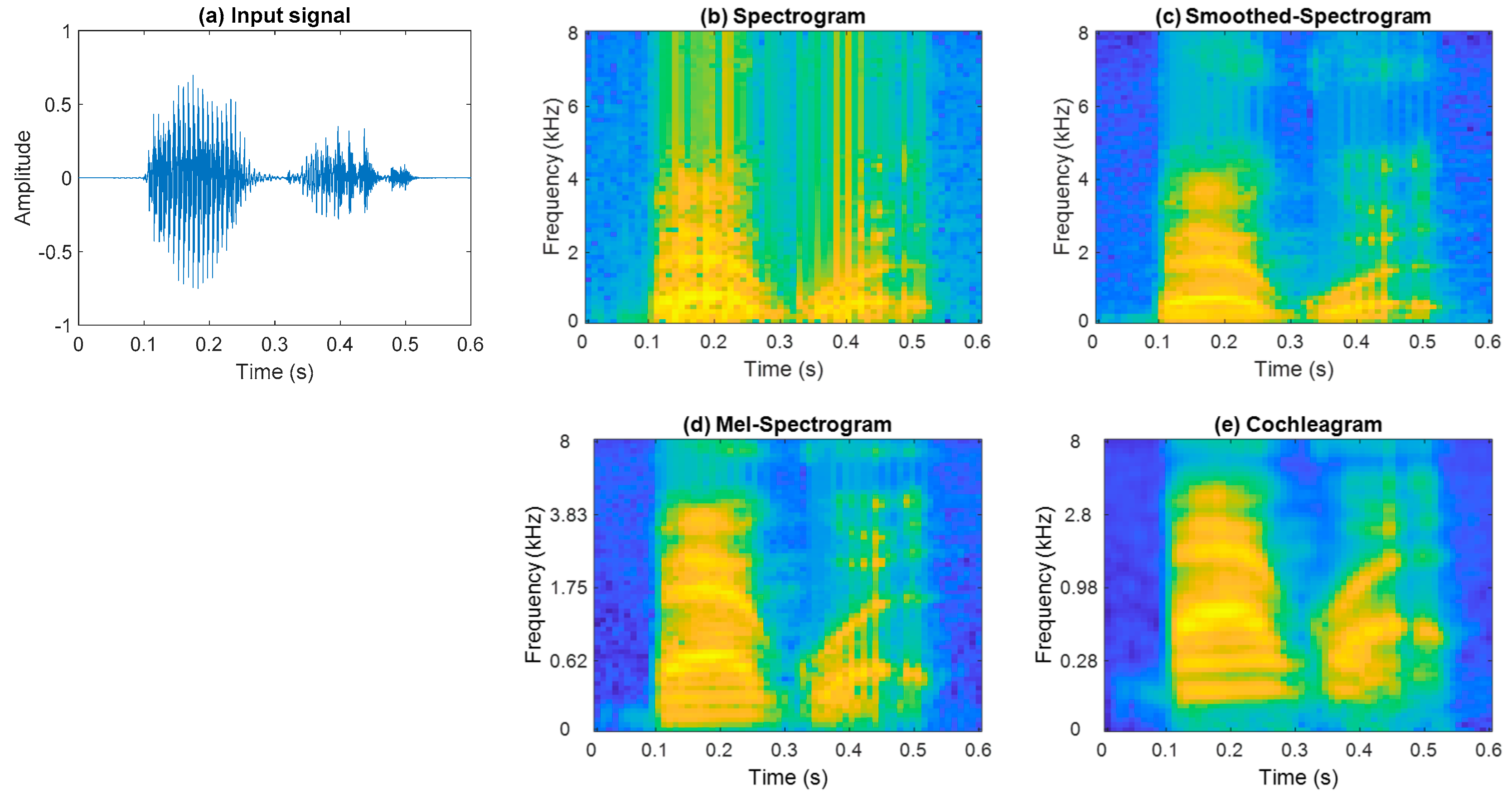
3.1. Time-Frequency Image Representations
3.2. Time-Frequency Image Resizing Techniques
3.3. Combination of Signal Representations
4. Benchmarking
4.1. Experimental Setup
4.1.1. Datasets
4.1.2. CNN
4.2. Classification Results
4.2.1. Time-Frequency Representations
4.2.2. Resized Representations
4.2.3. Fusion Techniques
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Salekin, A.; Eberle, J.W.; Glenn, J.J.; Teachman, B.A.; Stankovic, J.A. A weakly supervised learning framework for detecting social anxiety and depression. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018, 2, 81. [Google Scholar] [CrossRef]
- Mazo, M.; Rodríguez, F.J.; Lázaro, J.L.; Ureña, J.; García, J.C.; Santiso, E.; Revenga, P.A. Electronic control of a wheelchair guided by voice commands. Control. Eng. Pract. 1995, 3, 665–674. [Google Scholar] [CrossRef]
- Bonet-Solà, D.; Alsina-Pagès, R.M. A comparative survey of feature extraction and machine learning methods in diverse acoustic environments. Sensors 2021, 21, 1274. [Google Scholar] [CrossRef]
- Sharan, R.V.; Abeyratne, U.R.; Swarnkar, V.R.; Porter, P. Automatic croup diagnosis using cough sound recognition. IEEE Trans. Biomed. Eng. 2019, 66, 485–495. [Google Scholar] [CrossRef] [PubMed]
- Ciregan, D.; Meier, U.; Schmidhuber, J. Multi-column deep neural networks for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3642–3649. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Salamon, J.; Bello, J.P. Deep convolutional neural networks and data augmentation for environmental sound classification. IEEE Signal Process. Lett. 2017, 24, 279–283. [Google Scholar] [CrossRef]
- Lisa, T.; Jude, S. Transfer learning. In Handbook of Research on Machine Learning Applications and Trends: Algorithms, Methods, and Techniques; Soria, O.E., Martín, G.J.D., Marcelino, M.-S., Rafael, M.-B.J., Serrano, L.A.J., Eds.; IGI Global: Hershey, PA, USA, 2010; pp. 242–264. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Feng, S.; Zhou, H.; Dong, H. Using deep neural network with small dataset to predict material defects. Mater. Des. 2019, 162, 300–310. [Google Scholar] [CrossRef]
- Liu, S.; Deng, W. Very deep convolutional neural network based image classification using small training sample size. In Proceedings of the 3rd IAPR Asian Conference on Pattern Recognition (ACPR), Kuala Lumpur, Malaysia, 3–6 November 2015; pp. 730–734. [Google Scholar]
- Ng, H.-W.; Nguyen, V.D.; Vonikakis, V.; Winkler, S. Deep learning for emotion recognition on small datasets using transfer learning. In Proceedings of the 2015 ACM on International Conference on Multimodal Interaction, Seattle, WA, USA, 9–13 November 2015; pp. 443–449. [Google Scholar]
- Frid-Adar, M.; Diamant, I.; Klang, E.; Amitai, M.; Goldberger, J.; Greenspan, H. GAN-based synthetic medical image augmentation for increased CNN performance in liver lesion classification. Neurocomputing 2018, 321, 321–331. [Google Scholar] [CrossRef] [Green Version]
- Sharan, R.V.; Moir, T.J. An overview of applications and advancements in automatic sound recognition. Neurocomputing 2016, 200, 22–34. [Google Scholar] [CrossRef] [Green Version]
- Gerhard, D. Audio Signal Classification: History and Current Techniques; TR-CS 2003-07; University of Regina: Regina, SK, Canada, 2003. [Google Scholar]
- Stowell, D.; Giannoulis, D.; Benetos, E.; Lagrange, M.; Plumbley, M.D. Detection and classification of acoustic scenes and events. IEEE Trans. Multimed. 2015, 17, 1733–1746. [Google Scholar] [CrossRef]
- Sainath, T.N.; Mohamed, A.; Kingsbury, B.; Ramabhadran, B. Deep convolutional neural networks for LVCSR. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 8614–8618. [Google Scholar]
- Abdel-Hamid, O.; Mohamed, A.-R.; Jiang, H.; Deng, L.; Penn, G.; Yu, D. Convolutional neural networks for speech recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 1533–1545. [Google Scholar] [CrossRef] [Green Version]
- Swietojanski, P.; Ghoshal, A.; Renals, S. Convolutional neural networks for distant speech recognition. IEEE Signal Process. Lett. 2014, 21, 1120–1124. [Google Scholar] [CrossRef] [Green Version]
- Hertel, L.; Phan, H.; Mertins, A. Classifying variable-length audio files with all-convolutional networks and masked global pooling. arXiv 2016, arXiv:1607.02857. [Google Scholar]
- Kumar, A.; Raj, B. Deep CNN framework for audio event recognition using weakly labeled web data. arXiv 2017, arXiv:1707.02530. [Google Scholar]
- Hertel, L.; Phan, H.; Mertins, A. Comparing time and frequency domain for audio event recognition using deep learning. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Vancouver, CO, Canada, 24–29 July 2016; pp. 3407–3411. [Google Scholar]
- Golik, P.; Tüske, Z.; Schlüter, R.; Ney, H. Convolutional neural networks for acoustic modeling of raw time signal in LVCSR. In Proceedings of the 16th Annual Conference of the International Speech Communication Association (INTERSPEECH), Dresden, Germany, 6–10 September 2015; pp. 26–30. [Google Scholar]
- Sharan, R.V.; Berkovsky, S.; Liu, S. Voice command recognition using biologically inspired time-frequency representation and convolutional neural networks. In Proceedings of the 42nd Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Montreal, QC, Canada, 20–24 July 2020; pp. 998–1001. [Google Scholar]
- Becker, S.; Ackermann, M.; Lapuschkin, S.; Müller, K.-R.; Samek, W. Interpreting and explaining deep neural networks for classification of audio signals. arXiv 2018, arXiv:1807.03418. [Google Scholar]
- Ismail Fawaz, H.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P.-A. Deep learning for time series classification: A review. Data Min. Knowl. Discov. 2019, 33, 917–963. [Google Scholar] [CrossRef] [Green Version]
- Gama, F.; Marques, A.G.; Leus, G.; Ribeiro, A. Convolutional neural network architectures for signals supported on graphs. IEEE Trans. Signal Process. 2019, 67, 1034–1049. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Wang, C.; Tai, T.; Wang, J.; Santoso, A.; Mathulaprangsan, S.; Chiang, C.; Wu, C. Sound events recognition and retrieval using multi-convolutional-channel sparse coding convolutional neural networks. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 1875–1887. [Google Scholar] [CrossRef]
- Hershey, S.; Chaudhuri, S.; Ellis, D.P.W.; Gemmeke, J.F.; Jansen, A.; Moore, R.C.; Plakal, M.; Platt, D.; Saurous, R.A.; Seybold, B.; et al. CNN architectures for large-scale audio classification. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 131–135. [Google Scholar]
- Allen, J. Short term spectral analysis, synthesis, and modification by discrete Fourier transform. IEEE Trans. Acoust. Speech Signal Process. 1977, 25, 235–238. [Google Scholar] [CrossRef]
- Allen, J. Applications of the short time Fourier transform to speech processing and spectral analysis. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Paris, France, 3–5 May 1982; pp. 1012–1015. [Google Scholar]
- Badshah, A.M.; Ahmad, J.; Rahim, N.; Baik, S.W. Speech emotion recognition from spectrograms with deep convolutional neural network. In Proceedings of the International Conference on Platform Technology and Service (PlatCon), Busan, Korea, 13–15 February 2017; pp. 1–5. [Google Scholar]
- Brown, R.G. Smoothing, Forecasting and Prediction of Discrete Time Series; Dover Publications: Mineola, NY, USA, 2004. [Google Scholar]
- Kovács, G.; Tóth, L.; Van Compernolle, D.; Ganapathy, S. Increasing the robustness of CNN acoustic models using autoregressive moving average spectrogram features and channel dropout. Pattern Recognit. Lett. 2017, 100, 44–50. [Google Scholar] [CrossRef]
- Sharan, R.V.; Moir, T.J. Acoustic event recognition using cochleagram image and convolutional neural networks. Appl. Acoust. 2019, 148, 62–66. [Google Scholar] [CrossRef]
- Davis, S.; Mermelstein, P. Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences. IEEE Trans. Acoust. Speech Signal Process. 1980, 28, 357–366. [Google Scholar] [CrossRef] [Green Version]
- Stevens, S.S.; Volkmann, J.; Newman, E.B. A scale for the measurement of the psychological magnitude pitch. J. Acoust. Soc. Am. 1937, 8, 185–190. [Google Scholar] [CrossRef]
- Mesaros, A.; Heittola, T.; Benetos, E.; Foster, P.; Lagrange, M.; Virtanen, T.; Plumbley, M.D. Detection and classification of acoustic scenes and events: Outcome of the DCASE 2016 challenge. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 379–393. [Google Scholar] [CrossRef] [Green Version]
- Young, S.; Evermann, G.; Gales, M.; Hain, T.; Kershaw, D.; Liu, X.; Moore, G.; Odell, J.; Ollason, D.; Povey, D.; et al. The HTK Book (for HTK Version 3.4); Cambridge University Engineering Department: Cambridge, UK, 2009. [Google Scholar]
- Sharan, R.V.; Moir, T.J. Time-frequency image resizing using interpolation for acoustic event recognition with convolutional neural networks. In Proceedings of the IEEE International Conference on Signals and Systems (ICSigSys), Bandung, Indonesia, 16–18 July 2019; pp. 8–11. [Google Scholar]
- Tjandra, A.; Sakti, S.; Neubig, G.; Toda, T.; Adriani, M.; Nakamura, S. Combination of two-dimensional cochleogram and spectrogram features for deep learning-based ASR. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, Australia, 19–24 April 2015; pp. 4525–4529. [Google Scholar]
- Brown, J.C. Calculation of a constant Q spectral transform. J. Acoust. Soc. Am. 1991, 89, 425–434. [Google Scholar] [CrossRef] [Green Version]
- Rakotomamonjy, A.; Gasso, G. Histogram of gradients of time-frequency representations for audio scene classification. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 142–153. [Google Scholar] [CrossRef] [Green Version]
- McLoughlin, I.; Xie, Z.; Song, Y.; Phan, H.; Palaniappan, R. Time-frequency feature fusion for noise robust audio event classification. Circuits Syst. Signal Process. 2020, 39, 1672–1687. [Google Scholar] [CrossRef] [Green Version]
- Ozer, I.; Ozer, Z.; Findik, O. Noise robust sound event classification with convolutional neural network. Neurocomputing 2018, 272, 505–512. [Google Scholar] [CrossRef]
- Hashemi, M. Enlarging smaller images before inputting into convolutional neural network: Zero-padding vs. interpolation. J. Big Data 2019, 6, 98. [Google Scholar] [CrossRef]
- Reddy, D.M.; Reddy, N.V.S. Effects of padding on LSTMs and CNNs. arXiv 2019, arXiv:1903.07288. [Google Scholar]
- Tang, H.; Ortis, A.; Battiato, S. The impact of padding on image classification by using pre-trained convolutional neural networks. In Proceedings of the 20th International Conference on Image Analysis and Processing (ICIAP), Trento, Italy, 9–13 September 2019; pp. 337–344. [Google Scholar]
- Mallat, S.G.; Zhang, Z. Matching pursuits with time-frequency dictionaries. IEEE Trans. Signal Process. 1993, 41, 3397–3415. [Google Scholar] [CrossRef] [Green Version]
- Guo, G.; Li, S.Z. Content-based audio classification and retrieval by support vector machines. IEEE Trans. Neural Netw. 2003, 14, 209–215. [Google Scholar] [CrossRef]
- Rabaoui, A.; Davy, M.; Rossignol, S.; Ellouze, N. Using one-class SVMs and wavelets for audio surveillance. IEEE Trans. Inf. Forensics Secur. 2008, 3, 763–775. [Google Scholar] [CrossRef]
- Chu, S.; Narayanan, S.; Kuo, C.C.J. Environmental sound recognition with time-frequency audio features. IEEE Trans. Audio Speech Lang. Process. 2009, 17, 1142–1158. [Google Scholar] [CrossRef]
- Sharan, R.V.; Moir, T.J. Subband time-frequency image texture features for robust audio surveillance. IEEE Trans. Inf. Forensics Secur. 2015, 10, 2605–2615. [Google Scholar] [CrossRef]
- Li, S.; Yao, Y.; Hu, J.; Liu, G.; Yao, X.; Hu, J. An ensemble stacked convolutional neural network model for environmental event sound recognition. Appl. Sci. 2018, 8, 1152. [Google Scholar] [CrossRef] [Green Version]
- Su, Y.; Zhang, K.; Wang, J.; Madani, K. Environment sound classification using a two-stream CNN based on decision-level fusion. Sensors 2019, 19, 1733. [Google Scholar] [CrossRef] [Green Version]
- Mesaros, A.; Heittola, T.; Virtanen, T. Acoustic scene classification: An overview of DCASE 2017 Challenge entries. In Proceedings of the 16th International Workshop on Acoustic Signal Enhancement (IWAENC), Tokyo, Japan, 17–20 September 2018; pp. 411–415. [Google Scholar]
- Pandeya, Y.R.; Lee, J. Deep learning-based late fusion of multimodal information for emotion classification of music video. Multimed. Tools Appl. 2021, 80, 2887–2905. [Google Scholar] [CrossRef]
- Wang, H.; Zou, Y.; Chong, D. Acoustic scene classification with spectrogram processing strategies. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2020 Workshop (DCASE2020), Tokyo, Japan, 2–4 November 2020; pp. 210–214. [Google Scholar]
- Sharan, R.V. Spoken digit recognition using wavelet scalogram and convolutional neural networks. In Proceedings of the IEEE Recent Advances in Intelligent Computational Systems (RAICS), Thiruvananthapuram, India, 3–5 December 2020; pp. 101–105. [Google Scholar]
- Patterson, R.D.; Robinson, K.; Holdsworth, J.; McKeown, D.; Zhang, C.; Allerhand, M. Complex sounds and auditory images. In Auditory Physiology and Perception; Cazals, Y., Horner, K., Demany, L., Eds.; Pergamon: Oxford, UK, 1992; pp. 429–446. [Google Scholar]
- Glasberg, B.R.; Moore, B.C. Derivation of auditory filter shapes from notched-noise data. Heart Res. 1990, 47, 103–138. [Google Scholar] [CrossRef]
- Slaney, M. Lyon’s Cochlear Model; Apple Computer: Cupertino, CA, USA, 1988; Volume 13. [Google Scholar]
- Greenwood, D.D. A cochlear frequency-position function for several species-29 years later. J. Acoust. Soc. Am. 1990, 87, 2592–2605. [Google Scholar] [CrossRef]
- Slaney, M. An Efficient Implementation of the Patterson-Holdsworth Auditory Filter Bank; Apple Computer, Inc.: Cupertino, CA, USA, 1993; Volume 35. [Google Scholar]
- Slaney, M. Auditory Toolbox for Matlab; Interval Research Corporation: Palo Alto, CA, USA, 1998; Volume 10. [Google Scholar]
- Zhang, W.; Han, J.; Deng, S. Heart sound classification based on scaled spectrogram and partial least squares regression. Biomed. Signal Process.Control 2017, 32, 20–28. [Google Scholar] [CrossRef]
- Verstraete, D.; Ferrada, A.; Droguett, E.L.; Meruane, V.; Modarres, M. Deep learning enabled fault diagnosis using time-frequency image analysis of rolling element bearings. Shock Vib. 2017, 2017, 5067651. [Google Scholar] [CrossRef]
- Stallmann, C.F.; Engelbrecht, A.P. Signal modelling for the digital reconstruction of gramophone noise. In Proceedings of the International Conference on E-Business and Telecommunications (ICETE) 2015, Colmar, France, 20–22 July 2016; pp. 411–432. [Google Scholar]
- Keys, R. Cubic convolution interpolation for digital image processing. IEEE Trans. Acoust. Speech Signal Process. 1981, 29, 1153–1160. [Google Scholar] [CrossRef] [Green Version]
- Gearhart, W.B.; Shultz, H.S. The function sin x/x. Coll. Math. J. 1990, 21, 90–99. [Google Scholar] [CrossRef]
- Turkowski, K. Filters for common resampling tasks. In Graphics Gems; Glassner, A.S., Ed.; Morgan Kaufmann: San Diego, CA, USA, 1990; pp. 147–165. [Google Scholar]
- Nakamura, S.; Hiyane, K.; Asano, F.; Nishiura, T.; Yamada, T. Acoustical sound database in real environments for sound scene understanding and hands-free speech recognition. In Proceedings of the 2nd International Conference on Language Resources and Evaluation (LREC 2000), Athens, Greece, 31 May–2 June 2000; pp. 965–968. [Google Scholar]
- Warden, P. Speech commands: A dataset for limited-vocabulary speech recognition. arXiv 2018, arXiv:1804.03209. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Jarrett, K.; Kavukcuoglu, K.; Ranzato, M.A.; LeCun, Y. What is the best multi-stage architecture for object recognition? In Proceedings of the IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 2146–2153. [Google Scholar]
- Getreuer, P. Linear methods for image interpolation. Image Process. Line 2011, 1, 238–259. [Google Scholar] [CrossRef] [Green Version]
- Kim, T.; Lee, J.; Nam, J. Comparison and analysis of SampleCNN architectures for audio classification. IEEE J. Sel. Top. Signal Process. 2019, 13, 285–297. [Google Scholar] [CrossRef]
- Sainath, T.N.; Weiss, R.J.; Senior, A.; Wilson, K.W.; Vinyals, O. Learning the speech front-end with raw waveform CLDNNs. In Proceedings of the 16th Annual Conference of the International Speech Communication Association (INTERSPEECH), Dresden, Germany, 6–10 September 2015; pp. 1–5. [Google Scholar]
- Park, H.; Yoo, C.D. CNN-based learnable gammatone filterbank and equal-loudness normalization for environmental sound classification. IEEE Signal Process. Lett. 2020, 27, 411–415. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| Sound Event | Speech Command | |
|---|---|---|
| Image input layer | 32 × 15 | 64 × 64 |
| Middle layers | Conv. 1: 16@3 × 3, Stride 1 × 1, Pad 1 × 1 Batch Normalization, ReLU Max Pool: 2 × 2, Stride 1 × 1, Pad 1 × 1 Conv. 2: 16@3 × 3, Stride 1 × 1, Pad 1 × 1 Batch Normalization, ReLU Max Pool: 2 × 2, Stride 1 × 1, Pad 1 × 1 | Conv. 1: 48@3 × 3, Stride 1 × 1, Pad ‘same’ Batch Normalization, ReLU Max Pool: 3 × 3, Stride 2 × 2, Pad ‘same’ Conv. 2: 96@3 × 3, Stride 1 × 1, Pad ‘same’ Batch Normalization, ReLU Max Pool: 3 × 3, Stride 2 × 2, Pad ‘same’ Conv. 3: 192@3 × 3, Stride 1 × 1, Pad ‘same’ Batch Normalization, ReLU Max Pool: 3 × 3, Stride 2 × 2, Pad ‘same’ Conv. 4: 192@3 × 3, Stride 1 × 1, Pad ‘same’ Batch Normalization, ReLU Conv. 5: 192@3 × 3, Stride 1 × 1, Pad ‘same’ Batch Normalization, ReLU Max Pool: 3 × 3, Stride 2 × 2, Pad ‘same’ Dropout: 0.2 |
| Final layers | Fully connected layer: 50 Softmax layer Classification layer | Fully connected layer: 36 Softmax layer Classification layer |
| Sound Event | Speech Command | |
|---|---|---|
| Optimization algorithm | Adam | Adam |
| Initial learn rate | 0.001 | 0.0003 |
| Mini batch size | 50 | 128 |
| Max epochs | 30 | 25 |
| Learn rate drop factor | 0.5 | 0.1 |
| Learn rate drop period | 6 | 20 |
| L2 regularization | 0.05 | 0.05 |
| Signal Representation | Sound Event | Speech Command | ||
|---|---|---|---|---|
| Validation | Test | Validation | Test | |
| Spectrogram | 92.70 | 93.77 | 92.33 | 91.90 |
| Smoothed-Spectrogram | 96.48 | 97.32 | 93.79 | 93.41 |
| Mel-Spectrogram | 96.45 | 96.31 | 93.64 | 93.64 |
| Cochleagram | 98.35 | 98.61 | 94.33 | 94.13 |
| Signal Representation | Sound Event | Speech Command | ||
|---|---|---|---|---|
| Validation | Test | Validation | Test | |
| Resized spectrogram (nearest-neighbour) | 93.51 | 94.19 | 93.20 | 93.10 |
| Resized spectrogram (bilinear) | 95.71 | 96.31 | 94.10 | 93.81 |
| Resized spectrogram (bicubic) | 96.02 | 96.59 | 94.03 | 93.97 |
| Resized spectrogram (Lanczos-2) | 95.75 | 96.42 | 93.75 | 93.77 |
| Resized spectrogram (Lanczos-3) | 97.01 | 97.13 | 94.02 | 93.75 |
| Signal Representation Fusion Technique | Sound Event | Speech Command | ||
|---|---|---|---|---|
| Validation | Test | Validation | Test | |
| Early-fusion | 98.42 | 98.63 | 94.47 | 94.29 |
| Mid-fusion | 98.48 | 98.82 | 94.65 | 94.49 |
| Late-fusion | 98.64 | 98.83 | 94.86 | 94.80 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sharan, R.V.; Xiong, H.; Berkovsky, S. Benchmarking Audio Signal Representation Techniques for Classification with Convolutional Neural Networks. Sensors 2021, 21, 3434. https://doi.org/10.3390/s21103434
Sharan RV, Xiong H, Berkovsky S. Benchmarking Audio Signal Representation Techniques for Classification with Convolutional Neural Networks. Sensors. 2021; 21(10):3434. https://doi.org/10.3390/s21103434
Chicago/Turabian StyleSharan, Roneel V., Hao Xiong, and Shlomo Berkovsky. 2021. "Benchmarking Audio Signal Representation Techniques for Classification with Convolutional Neural Networks" Sensors 21, no. 10: 3434. https://doi.org/10.3390/s21103434