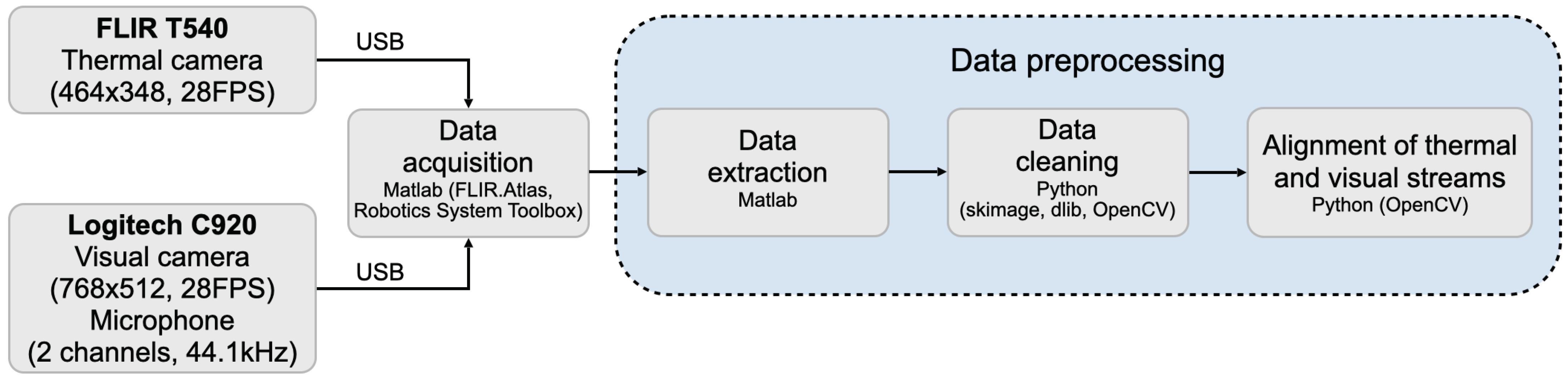
We developed two baseline tasks to demonstrate the utility and reliability of the SpeakingFaces multimodal dataset. The first task utilizes the three data streams (visual, thermal, and audio) to classify the gender of subjects under clean and noisy environments. The second task aims to learn a thermal-to-visual image translation model in order to demonstrate a transfer of domain knowledge between the two data streams.
3.1. Gender Classification
The goal of this task is to predict the gender of a subject using the information from a single utterance, consisting of visual, thermal, and audio data streams. To achieve this goal, we constructed a multimodal gender classification system using our SpeakingFaces dataset. A successful gender classification system can improve the performance of many applications, including HCI, surveillance and security systems, image/video retrieval, and so on [
37].
The gender classification model is based on LipNet [
38] architecture consisting of two main modules: an encoder and a classifier. The encoder module is constructed by combining deep convolutional neural networks (CNN) with the stack of bidirectional recurrent neural network (BRNN) layers:
The encoder module is used to transform an
N-length input feature sequence
into a hidden feature vector
h as follows:
where
is an three-dimensional tensor for images or a two-dimensional tensor for the spectrograms generated from the audio records. A separate encoder module is trained for each data stream, producing three hidden vector representations:
,
, and
. These generated hidden features are then concatenated and fed to the classifier module.
The classifier module consists of two fully-connected layers with the rectified linear unit (
ReLU) activation and single linear layer followed by the sigmoid activation:
where the linear layer is used to convert a vector to a scalar. The classifier takes the generated hidden features and outputs probability distribution over the two classes
as follows:
where
is a
i-th encoder dedicated to the specific data stream, and
T denotes the transpose operation.
The input sequence
X is constructed as follows. For visual and thermal streams, we used the same number of equidistantly spaced frames. For audio streams, we used mel-spectogram features computed over a 0.4-second snippet extracted from the middle of uttered commands. To evaluate the robustness of multimodal gender classification model, we constructed noisy versions of input features for the validation and test sets. The noisy input features
were generated by including additive white Gaussian noise (AWGN):
where Z∼
. To estimate the noise variance
, we steadily increased it up to the point when the input data were sufficiently corrupted, that is, the gender classifier makes random predictions. As a result, the noise variance
for image and audio streams was set to 100 and 5, respectively.
All models were trained on a single V100 GPU running on the NVIDIA DGX-2 server using the clean training set. All hyper-parameters were tuned using the clean validation set. In particular, we optimized model parameters using Adadelta [
39] with the initial learning rate of 0.1 for 200 epochs. As a regularization, we applied dropout, which was tuned for each model independently. We set the batch size to 256 and applied gradient clipping with a threshold of 10 to prevent the gradients from exploding. The best-performing model was evaluated using the clean and noisy versions of the validation and test sets. The system implementation including the model specifications and other hyper-parameter values are provided in our GitHub repository (
https://github.com/IS2AI/SpeakingFaces/tree/master/baseline_gender, accessed on 24 February 2021).
The model inference results are given in
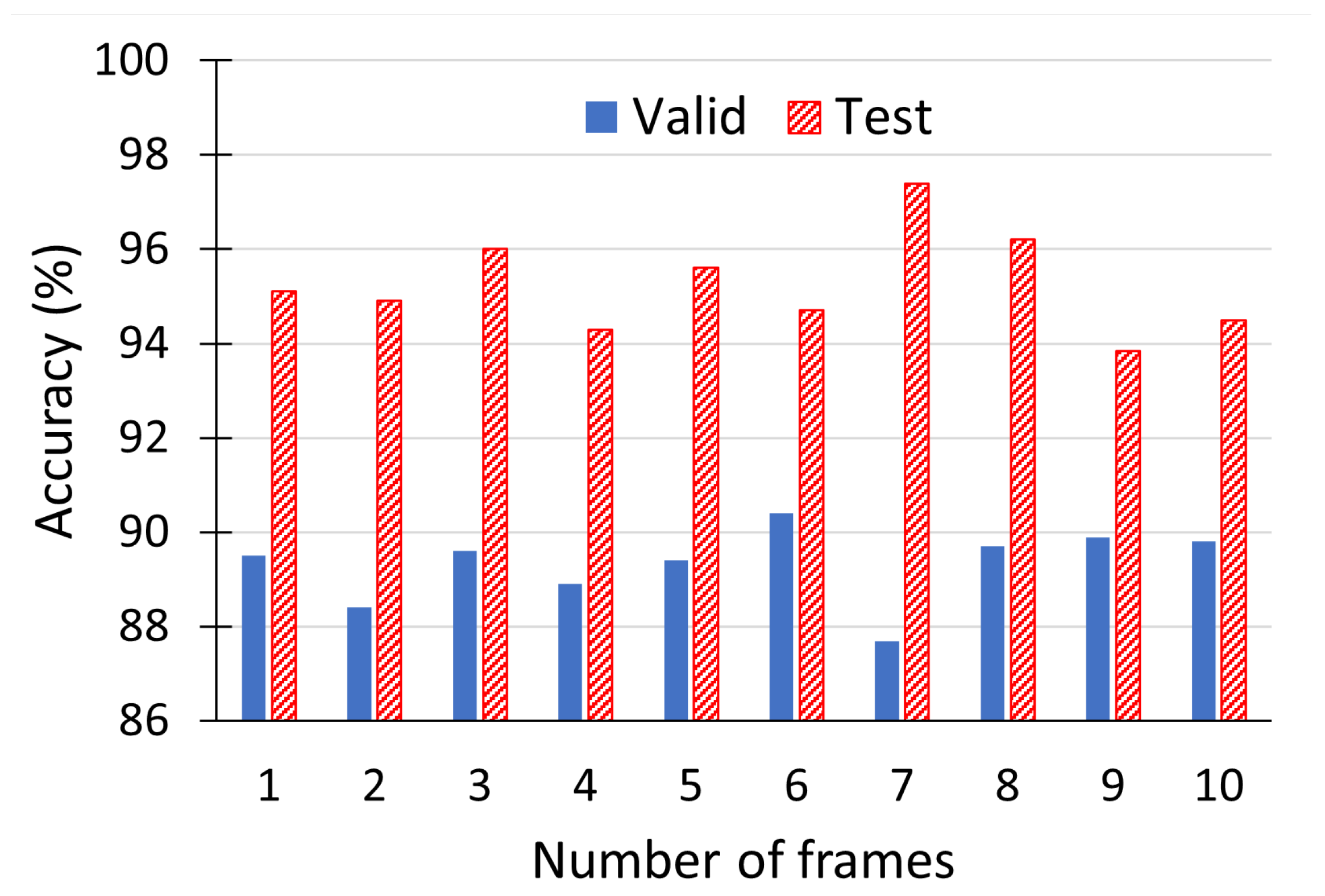
Table 4. In these experiments, we set the number of visual and thermal frames to three, extracted from the beginning, middle and end of an utterance. We examined different number of frames and observed that three equidistantly spaced frames were sufficient to achieve a good predictive performance, i.e., increasing the number of frames commensurately lengthened both training and inference time, but did not produce any noticeable performance improvement (see
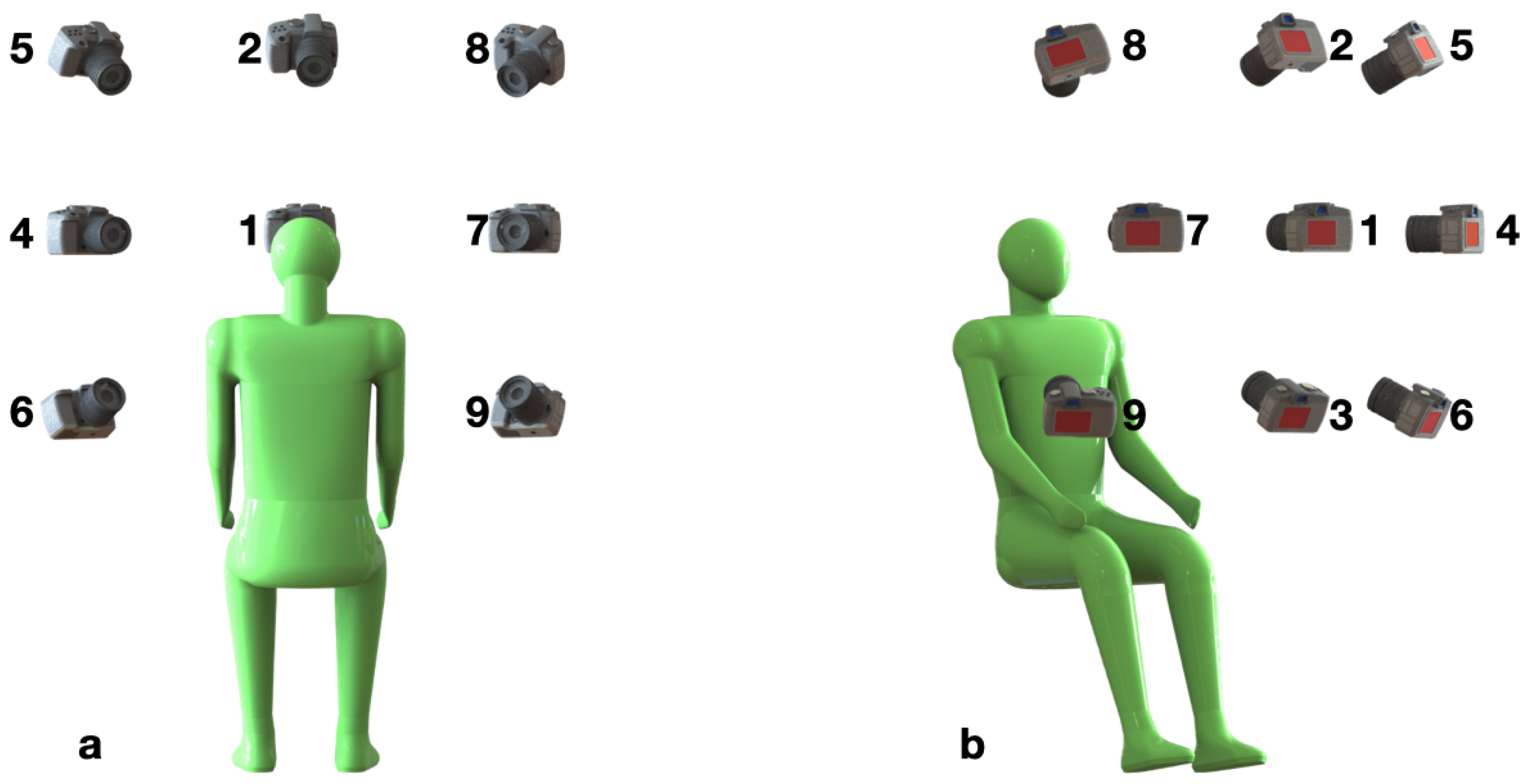
Figure 8). In the best-case scenario, when all of the three data streams are clean (ID 1), the gender classifier achieves the highest accuracy rate of 96% on the test set. When all the three data streams are noisy (ID 8), the model performance is random, equivalent to a coin toss. In other scenarios, when only one or two data streams are corrupted (IDs 2–7), the model achieves an accuracy of 65.8–95.6% on the test set; these results serve to demonstrate the robustness of using multimodal systems.
The experiment results show that the most informative data stream is the audio, followed by the visual and then thermal stream. When considering the case where only a single stream is noisy, the corruption of the audio stream drops the accuracy rate by 11.6% (ID 1 vs. ID 3), whereas for the visual and thermal streams, the accuracy drops by 2.4% (ID 1 vs. ID 5) and 0.4% (ID 1 vs. ID 2), respectively. Now, considering the case where two streams are noisy: when the audio (ID 6) stream is clean (and the others corrupted), the accuracy is 88.2%, while, when only the visual (ID 4) and thermal (ID 7) images are clean, the performances are 82.0% and 65.7%, respectively. We presume that during the training phase, the multimodal model decides to emphasize the audio features such that the relative contributions of the visual and thermal streams are de-emphasized. Presumably, this issue can be addressed by using attention-based models [
40]. Although the thermal stream seems to be relatively less consequential, it is still extremely useful in the case where the visual stream is corrupted (e.g., at night), where 5.4% of improvement on the test set is gained (ID 5 vs. ID 6). The experimental results successfully demonstrate the advantages of examining multiple data streams, and the utility of the SpeakingFaces dataset. We believe that the gender classification model can achieve even better results, with further development of the architectural structure and tuning of the hyper-parameter values, though this optimization work lies beyond the scope of this baseline example.
To further verify the reliability of the SpeakingFaces dataset, we evaluated the performance of each data stream independently. Specifically, we trained a gender classification model using only a single data stream. The model architecture was same as in the previous experiment setup, except that the number of encoders was reduced from three to one. This experiment was conducted using only the clean version of the data. The obtained results (IDs 9–11) show that all the data streams achieve an accuracy score of above 90% on both validation and test sets. The best accuracy on the test set is achieved by the model trained on the audio (ID 10) stream, followed by the thermal (ID 11) and visual (ID 9) streams. These experimental results demonstrate the reliability of each data stream present in the SpeakingFaces dataset.
As was previously mentioned, the gender classification experiments were conducted to demonstrate the utility and trustworthiness of the available modalities in the SpeakingFaces. In particular, the multimodal experiments were conducted to demonstrate the robustness of the recognition system trained on the three streams under different conditions. On the other hand, the unimodal experiments were conducted to show the reliability of each individual stream present in the dataset. These experiments are not intended to compare unimodal versus multimodal systems, they were generated as a proof-of-concept. Further investigation on hyper-parameter tuning and architectural search to improve and compare the performance of unimodal and multimodal models is underway as a separate contribution.
3.2. Thermal-to-Visual Facial Image Translation
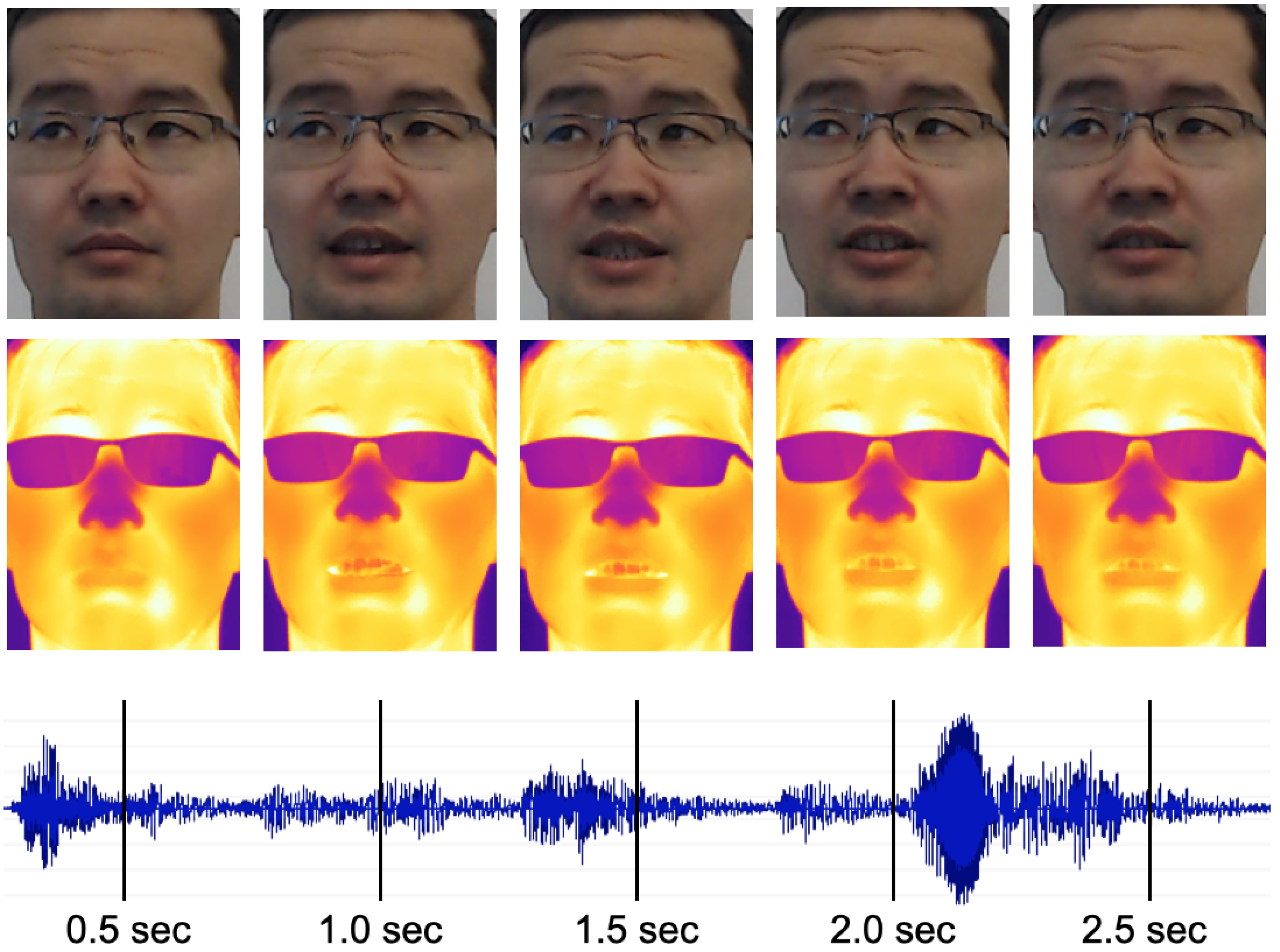
Facial features which are distinctly discernible in the visible images are not clearly observable in the corresponding thermal versions (see
Figure 4). As a result, models developed for visual images (e.g., facial landmark detection, face recognition) cannot be utilized directly on thermal images. Therefore, in this task, we aim to address the problem of generating a realistic visual-spectrum version of a given thermal facial image.
Generative Adversarial Networks (GANs) [
41] have been successfully deployed for generating realistic images; in particular, Pix2Pix [
42], CycleGAN [
43], and CUT [
44] have been shown to produce promising results in translating images from one domain to another. Zhang et al. introduced a Pix2Pix-based approach that focused on achieving a high face recognition accuracy of their generated visible images by incorporating an explicit closed-set face recognition loss [
45]. However, their image output lacked distinct facial features and high image quality, which was the priority of Wang et al. [
46]. They combined CycleGAN with a new detector network that located facial landmarks in generated visible images and aimed to guide the generator in producing realistic results. Both works were impaired by the relatively small number of image pairs and the use of low resolution thermal cameras. Zhang et al. filtered the IRIS dataset [
11] down to 695 image pairs, and Wang et al. collected 792 image pairs using FLIR AX5 thermal camera with a resolution of
. The latter dataset is not publicly available.
In our case, we experimented with CycleGAN and CUT to map thermal faces to visual-spectrum. The SpeakingFaces contains images of 142 subjects; 100 subjects were used for training and 42 were left for testing. We used the second session data, where participants uttered commands, and randomly selected three images for every position of each subject, which resulted in 2700 and 1134 thermal-visual image pairs for training and testing, respectively. To prepare the experimental data, we utilized the OpenCV’s deep learning face detector [
47] to identify faces in visible images. Noting that the thermal and visual images are aligned, we used the bounding boxes extracted from the visible images to delineate faces in both image streams. In cases where faces were not detected, we manually specified the coordinates of the bounding boxes. The instructions on how to access this version of SpeakingFaces can be found in our Github repository (
https://github.com/IS2AI/SpeakingFaces/tree/master/baseline_domain_transfer, accessed on 11 March 2021).
All models were trained on a single V100 GPU running on the NVIDIA DGX-2 server using the training set. For both CycleGAN and CUT, the generator architecture was comprised of ResNet-9 blocks, trained using identical hyperparameter values with a batch size of 1, an image load size of 130, and an image crop size of 128. The rest of the training and testing details can be accessed in our GitHub repository (
https://github.com/IS2AI/SpeakingFaces/tree/master/baseline_domain_transfer, accessed on 11 March 2021).
We used two methods to quantitatively assess our experimental results. The first one was the Fréchet inception distance (FID) metric that compares the distribution of generated images with the distribution of real images [
48]. The second method is based on the dlib’s face recognition model [
27,
49], which was trained on visual images, to show accuracy metrics on real visual, generated visual, and real thermal images from the test set.
The recognition model extracts a 128-dimension encoding for a given facial image and matches faces by comparing the Euclidean distance between the encodings. We started with the real visual images from the first trial to get the ground truth features. To do so, we built a feature matrix by extracting face encodings from the first trial data, where the columns represent features and the rows represent image samples. We also saved the corresponding labels (a numeric identifier of each subject) in the vector .
Next, we used the second trial images (real visual, real thermal, generated visual CycleGAN, and generated visual CUT) to evaluate the model performance. We computed encodings for each image in the second trial and calculated the Euclidean distance with every feature vector from
X. If the distance was below a predefined threshold, then we had a match. Note,
X contains 27 (three images from each of the nine positions) embedding vectors for each subject, so when we compared each face in the second trial with the encodings in
X, we chose the label with the highest number of matches. The implementation of the face recognition pipeline can be found in our GitHub repository (
https://github.com/IS2AI/SpeakingFaces/tree/master/baseline_domain_transfer, accessed on 11 March 2021).
The threshold value, or the tolerance, was tuned to meet the precision/recall trade-off on real visual images. The larger value increases a number of false positive predictions, while the lower value leads to a higher count of false negative predictions. The threshold value for our data was established at 0.45, to better balance the precision/recall trade-off.
A subset of generated images is presented in
Figure 9; the rest can be found in our Github repository (
https://github.com/IS2AI/SpeakingFaces/tree/master/baseline_domain_transfer, accessed on 11 March 2021). Compared to the images generated by CUT, the output of CycleGAN is of much higher quality. The CycleGAN images are close to the target visible images not only in the structure of facial features, but also in the overall appearance for a variety of head postures. The model produced samples with smoother and more coherent skin texture and color. Overall, the hair is realistically drawn, though both models were biased towards brown-haired individuals, so they failed to provide the right hair color for subject ID 1. Interestingly, both learned to correctly predict the gender of each person; for example, the generators drew facial hair for the male subjects.
The qualitative assessment of the synthesized images is supported by the FID metric and face recognition results for both models. The FID scores were 22.12 for CUT and 18.95 for CycleGAN. This means that the CycleGAN-generated images were more similar to real visual images than the ones generated by CUT. The reason might be that, in the training procedure of the CUT model, each patch in the output image should reflect the content of the corresponding patch in the input image, whereas the CycleGAN enforces a cycle consistency between entire images.
The face recognition results are shown in
Table 5. As expected, the best outcomes were obtained from the real visual images, while the worst were from the real thermal images, because the deployed recognition model was trained on visual images. The results of the CycleGAN model are noticeably better than those of the CUT model; this is also supported by their FID scores and our qualitative examination. The quality of the generated images requires further improvement as compared to the outcomes achieved with the real visible images. We hypothesize that the realism of the output of these models was affected by the following factors:
The model may be biased towards young people, due to the observation that of participating subjects were 20–25 years old. As a result, the model in some cases generated a younger version of the subject.
The model may be biased towards Asian people, given that the majority of the participating subjects were Asians. As an example, in the case of some subjects wearing glasses, the depiction of eyes seems skewed towards an Asian presentation.
Even taking into account the noted slight biases, the recognition accuracy on the generated images is significantly higher than that on the real thermal images. These results showcase that SpeakingFaces can indeed be utilized for image translation tasks, and we encourage other researchers to experiment further and compare their results.
3.3. Limitations
The SpeakingFaces dataset was acquired in a semi-controlled laboratory setting, which may present certain limitations to the work when used in unconstrained real-world settings where there is less control over camera angles, distance, lighting, and temperature. The first limitation entails the orientation of the subject to the camera. We used nine camera positions, though in an open setting it is likely that a wider range of facial poses would be encountered. The second limitation involves the distance of the subject from the camera: the distance did not vary in the laboratory setting. In an open setting, the distance could vary considerably, which could result in reduced resolution of facial images, thus diminishing the accuracy of the results. The third limitation is that our dataset was acquired under consistent illumination and temperature conditions. In a real-world deployment there could be wide variation in the surrounding thermal conditions, ambient light intensity and illumination directions. To address these issues, as future work, it is proposed to enhance the dataset with the acquisition of in-the-wild subject data. The models trained on the original dataset could be further fine-tuned with the real-world dataset using transfer learning.
Another limitation arises from the proposed method of aligning visual images to their thermal pairs. Our method (as described in
Section 2.2) was based on planar homography and ArUco markers. Since the corners of the marker might not be detected very accurately in the thermal image due to heat dissipation, we estimated the averaged value of the homography matrix by collecting ArUco marker images from different positions and orientations. The averaged homography matrix allowed us to align well in terms of scale and position, but not in terms of orientation.
Despite the large size of the dataset, it might be insufficient to build robust multimodal models for the tasks, such as speech recognition and lip reading. These tasks require a substantial amount of annotated data, which is expensive and time-consuming to acquire. However, our dataset can be used to fine-tune unimodal models pre-trained on large single stream datasets, as was done in [
50].
Lastly, as noted above, the manual operation of the camera introduced variability in the acquisition of visual and thermal data. Nevertheless, we think that such an approach is suitable for the potential deployment of applications built with SpeakingFaces. As previously mentioned, smartphones will likely be the first devices to deploy applications utilizing all the three data streams. These devices are commonly handheld, thus it will be more suitable to train models on the data that were collected in a similar manner. Furthermore, manual operations introduce variability in framing and thereby improve the robustness of subsequent machine learning applications.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}