
OctoPath: An OcTree-Based Self-Supervised Learning Approach to Local Trajectory Planning for Mobile Robots

 , and
, and 
Abstract
:1. Introduction
- based on the octree environment model, we provide a solution for estimating local driving trajectories by reformulating the estimation task as a classification problem with a configurable resolution;
- we define an encoder-decoder deep neural network topology for predicting desired future trajectories, which are obtained in a self-supervised fashion;
- we leverage the innate property of the state vector between the encoder and the decoder to represent a learned sequence of trajectory points constrained by road topology.
2. Related Work
3. Method
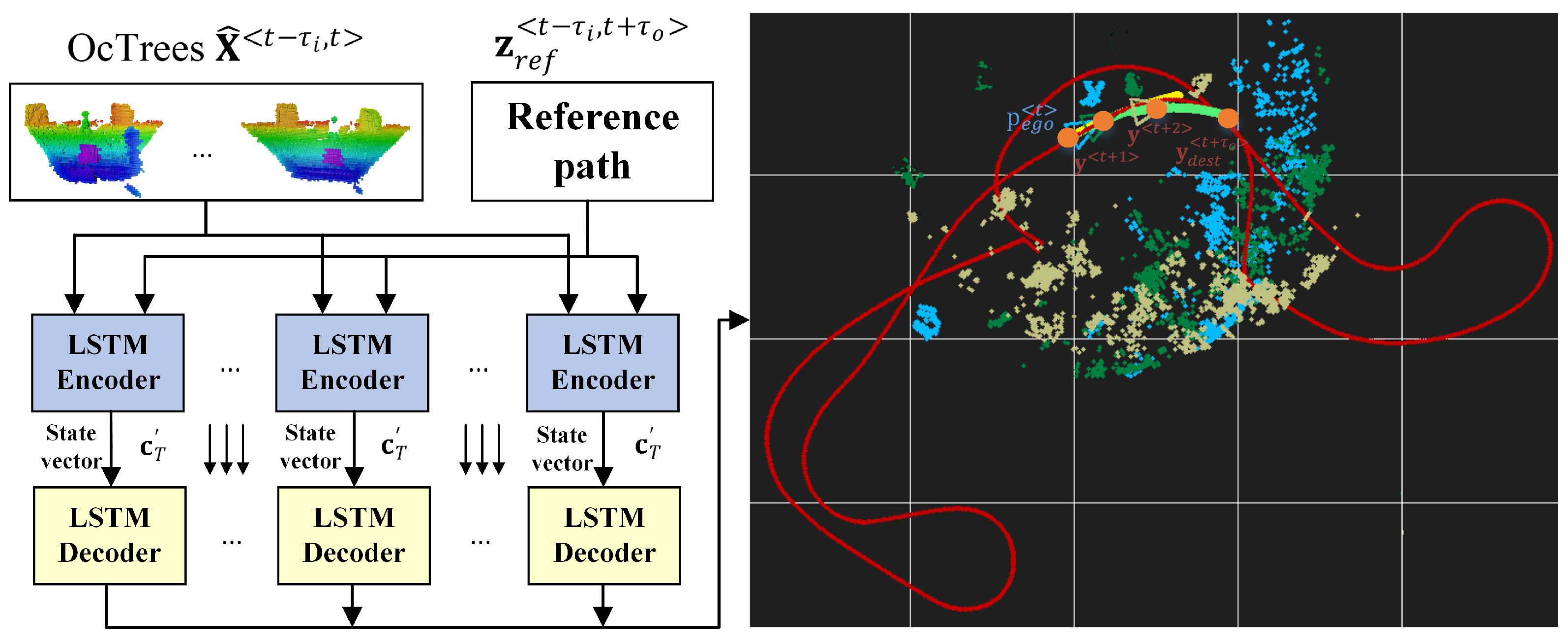
3.1. Problem Definition: Local Trajectory Prediction
- the longitudinal velocity is maximal and is contained within the bounds ;
- the total distance between consecutive trajectory points is minimal: ;
- the lateral velocity is minimal. It is is determined by the rate of change of the steering angle .
3.2. Octree Environment Model
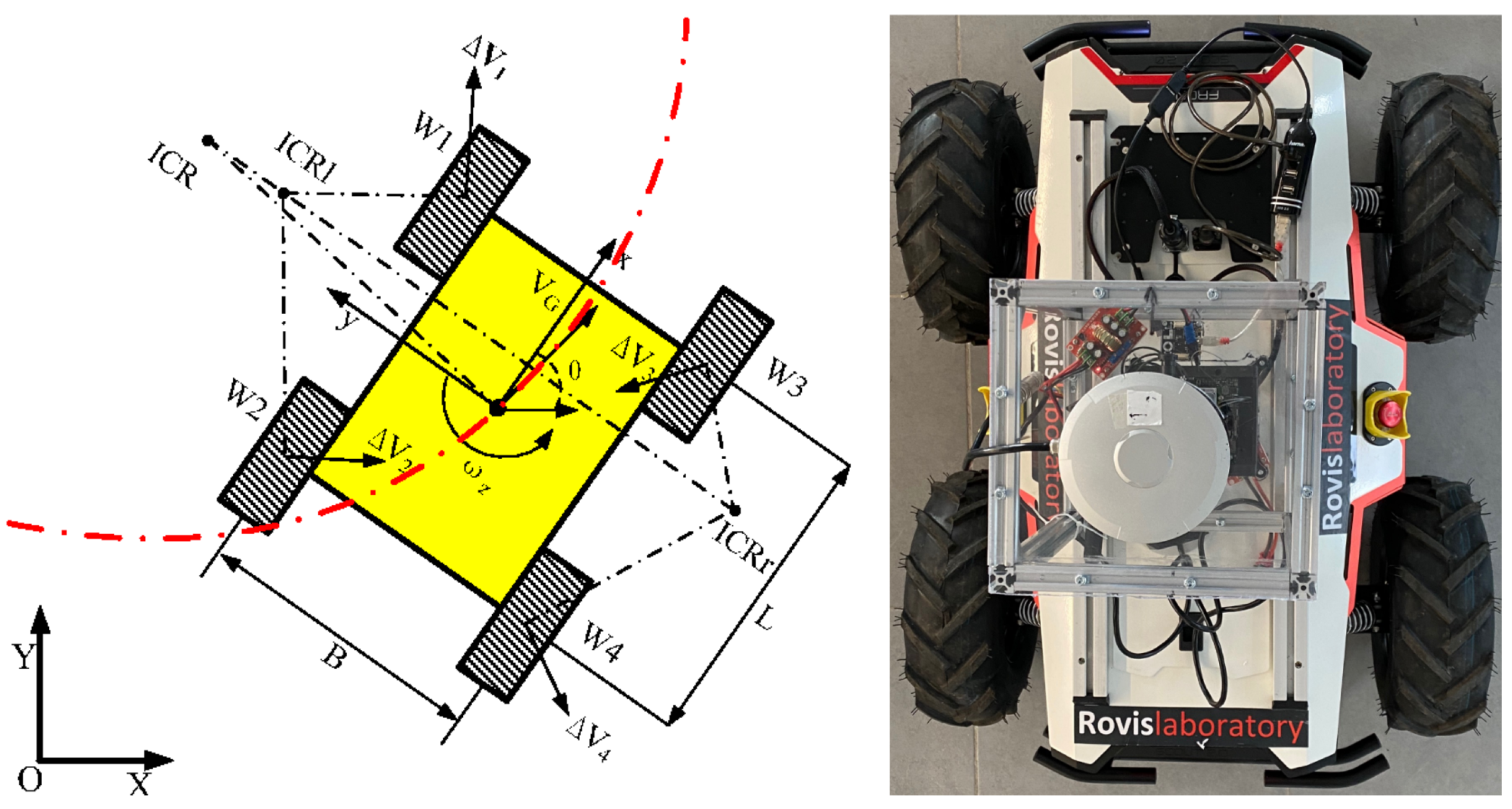
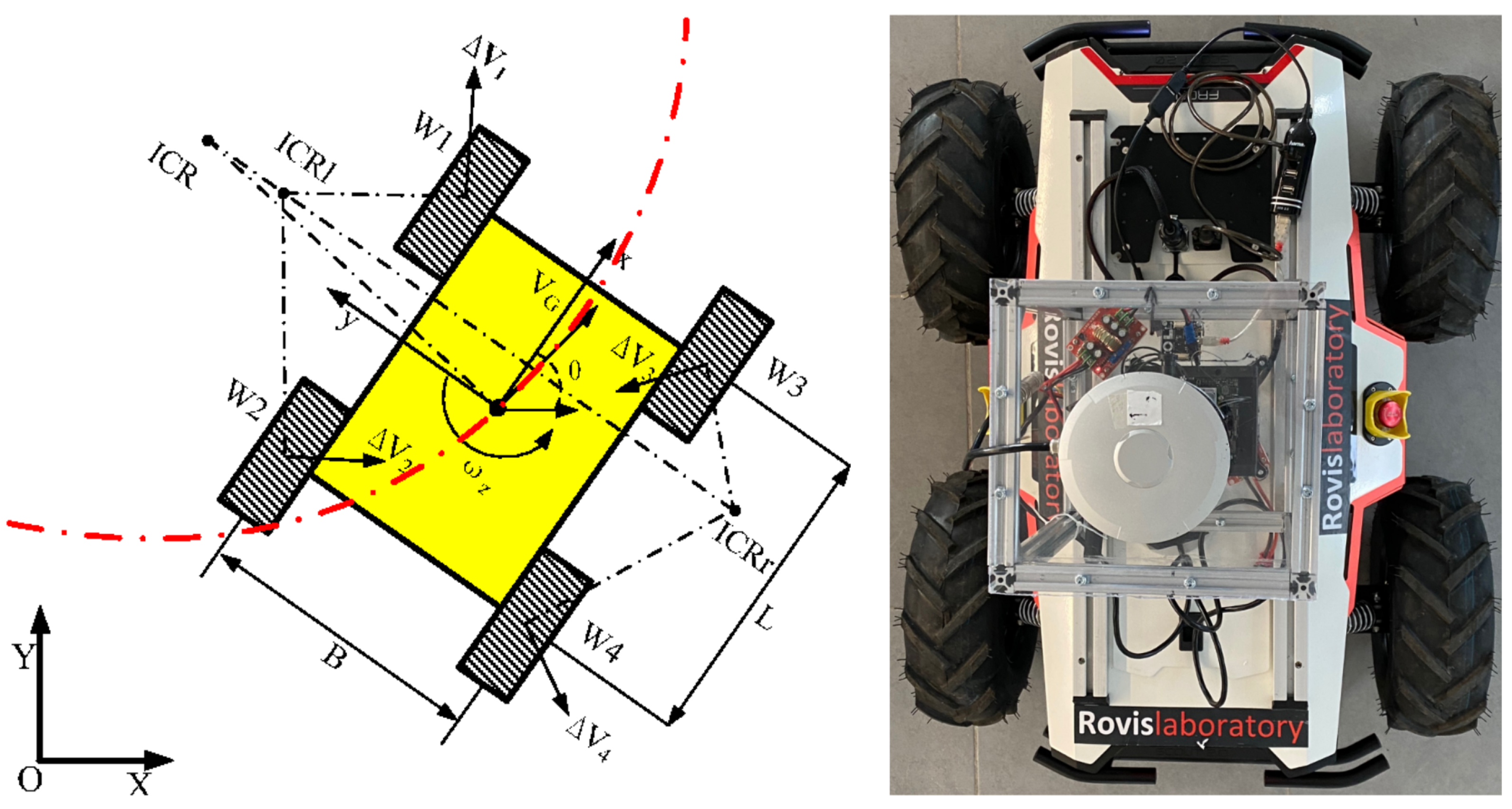
3.3. Kinematics of RovisLab’s AMTU as a SSWMR (Skid-Steer Wheeled Mobile Robot)
- The robot’s mass center is at the geometric center of the body frame;
- Each side’s two wheels rotate at the same speed;
- The robot is operating on a firm ground floor with all four wheels in contact with it at all times.
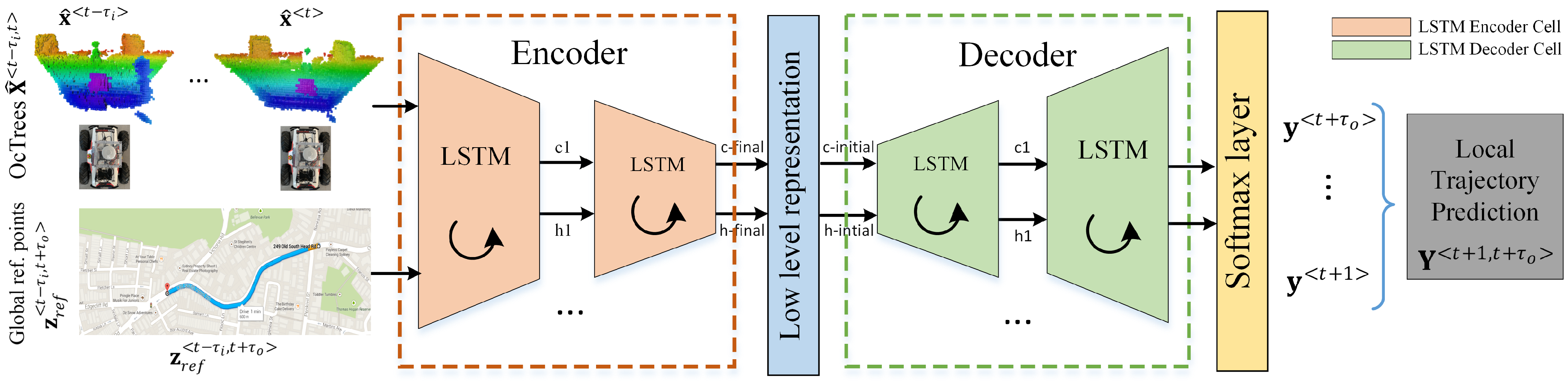
4. OctoPath: Architecture, Training and Deployment
4.1. RNN Encoder-Decoder Architecture
4.2. Training Setup
5. Results
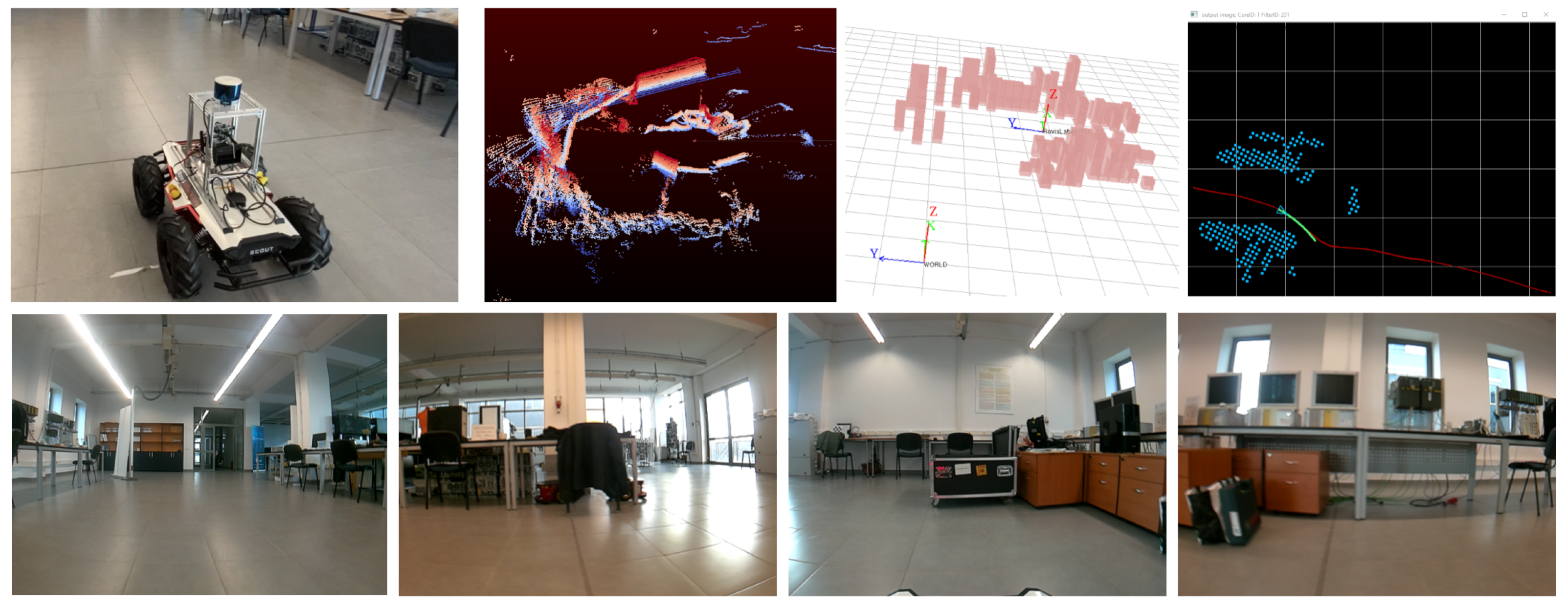
5.1. Experimental Setup Overview
- collect training data from driving recordings;
- generate octrees and format training data as sequences;
- train the OctoPath deep network from Figure 1;
- evaluate on simulated and real-world driving scenarios.
5.2. Experiment I: GridSim Simulation Environment
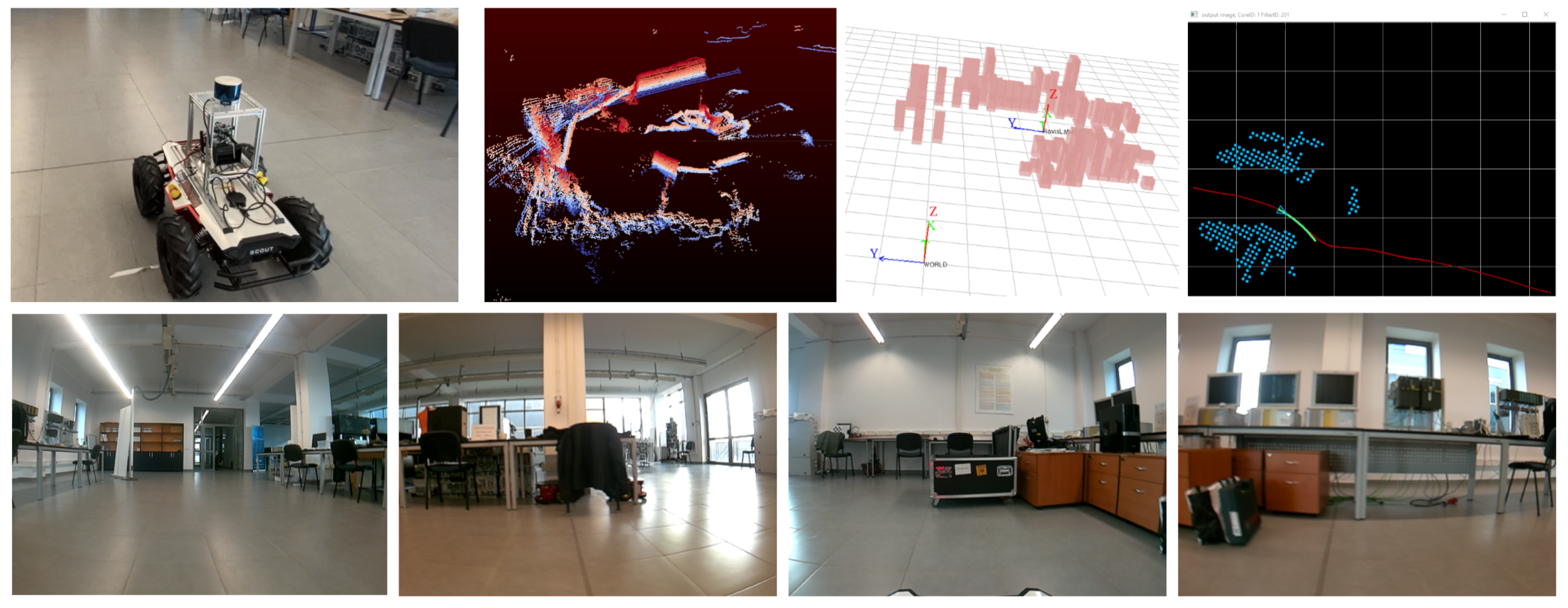
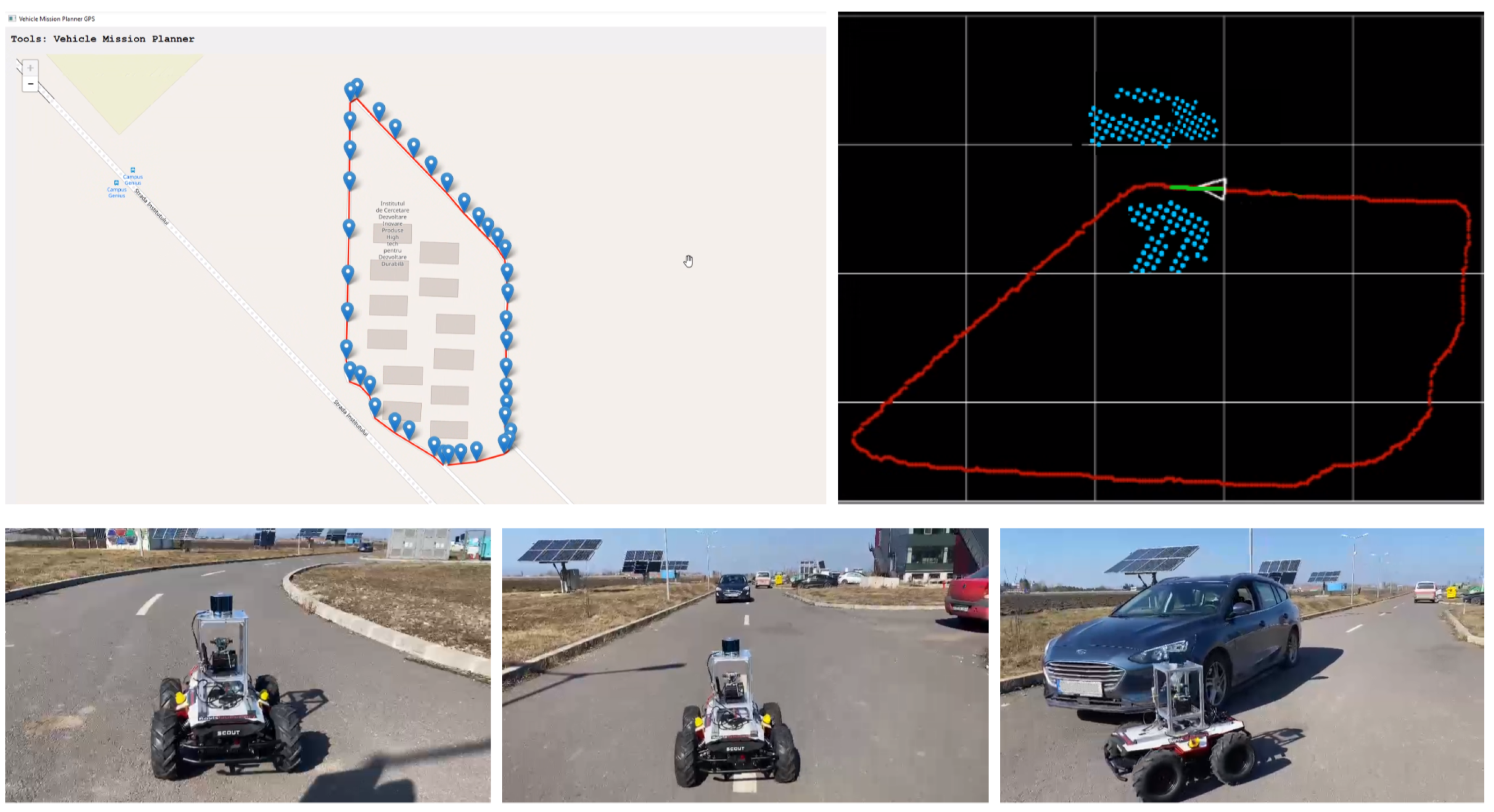
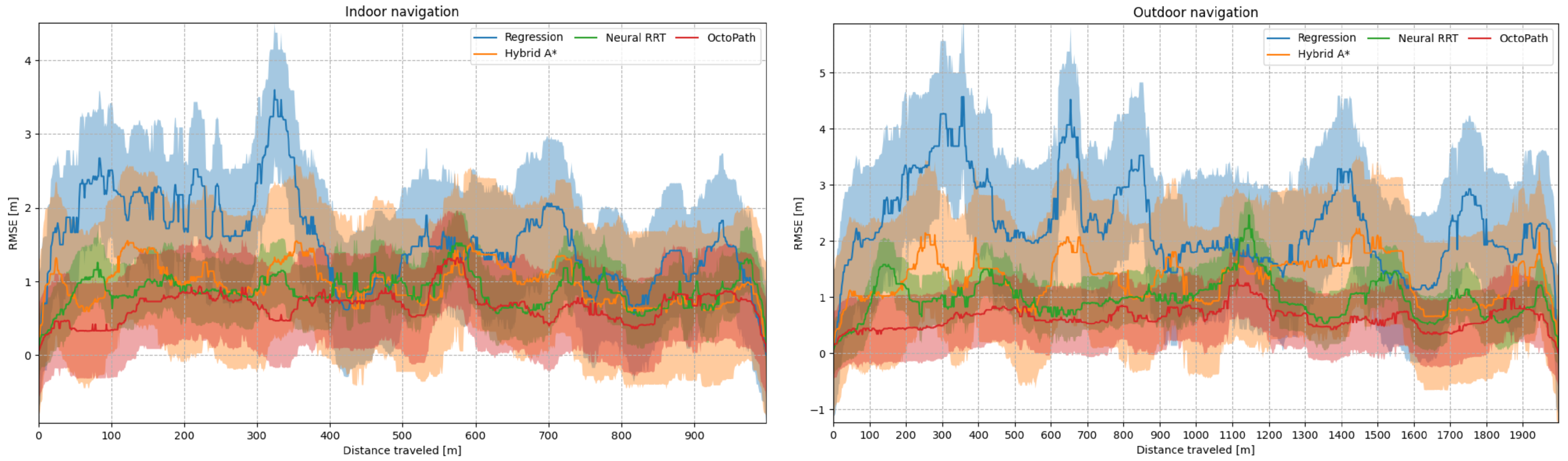
5.3. Experiment II: Indoor and Outdoor Navigation
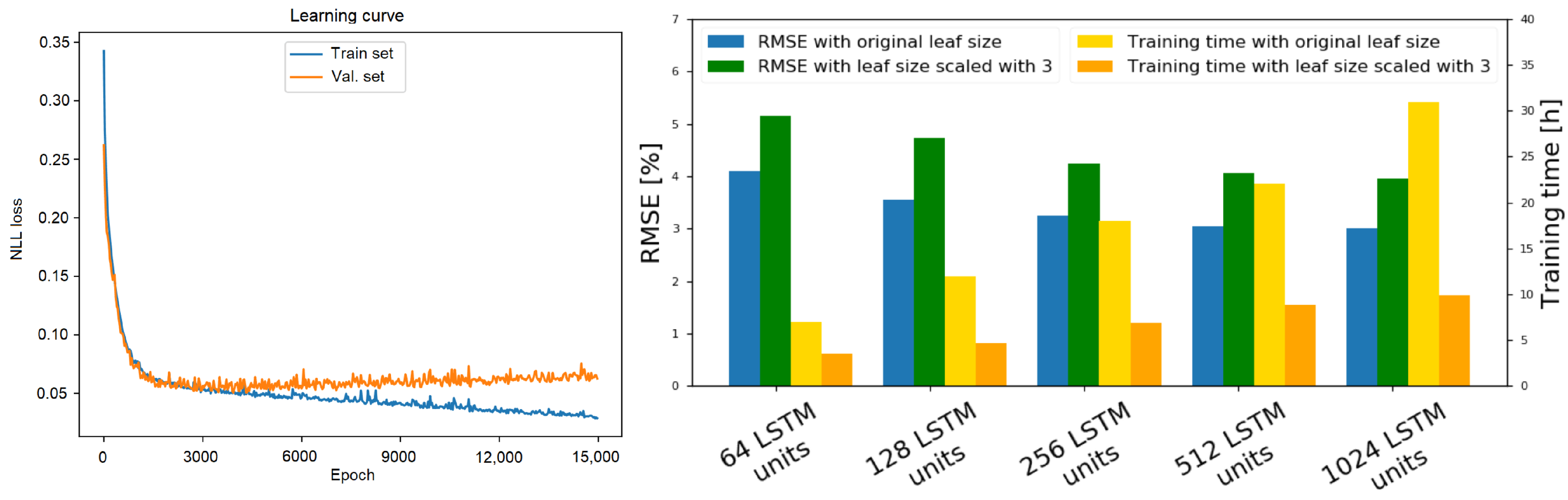
5.4. Ablation Study
5.5. Deployment of OctoPath on the Nvidia AGX Xavier
5.6. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xu, H.; Gao, Y.; Yu, F.; Darrell, T. End-to-end learning of driving models from large-scale video datasets. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2174–2182. [Google Scholar]
- Jaritz, M.; Charette, R.; Toromanoff, M.; Perot, E.; Nashashibi, F. End-to-End Race Driving with Deep Reinforcement Learning. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018. [Google Scholar]
- Pendleton, S.D.; Andersen, H.; Du, X.; Shen, X.; Meghjani, M.; Eng, Y.H.; Rus, D.; Ang, M.H. Perception, planning, control, and coordination for autonomous vehicles. Machines 2017, 5, 6. [Google Scholar] [CrossRef]
- Grigorescu, S.M.; Trasnea, B.; Marina, L.; Vasilcoi, A.; Cocias, T. NeuroTrajectory: A Neuroevolutionary Approach to Local State Trajectory Learning for Autonomous Vehicles. IEEE Robot. Autom. Lett. 2019, 4, 3441–3448. [Google Scholar] [CrossRef] [Green Version]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef]
- Hessel, M.; Modayil, J.; Van Hasselt, H.; Schaul, T.; Ostrovski, G.; Dabney, W.; Horgan, D.; Piot, B.; Azar, M.; Silver, D. Rainbow: Combining improvements in deep reinforcement learning. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- González, D.; Pérez, J.; Milanés, V.; Nashashibi, F. A review of motion planning techniques for automated vehicles. IEEE Trans. Intell. Transp. Syst. 2015, 17, 1135–1145. [Google Scholar] [CrossRef]
- Grigorescu, S.; Trasnea, B.; Cocias, T.; Macesanu, G. A survey of deep learning techniques for autonomous driving. J. Field Robot. 2020, 37, 362–386. [Google Scholar] [CrossRef]
- Amini, A.; Gilitschenski, I.; Phillips, J.; Moseyko, J.; Banerjee, R.; Karaman, S.; Rus, D. Learning robust control policies for end-to-end autonomous driving from data-driven simulation. IEEE Robot. Autom. Lett. 2020, 5, 1143–1150. [Google Scholar] [CrossRef]
- Pan, Y.; Cheng, C.A.; Saigol, K.; Lee, K.; Yan, X.; Theodorou, E.A.; Boots, B. Imitation learning for agile autonomous driving. Int. J. Robot. Res. 2020, 39, 286–302. [Google Scholar] [CrossRef]
- Bojarski, M.; Del Testa, D.; Dworakowski, D.; Firner, B.; Flepp, B.; Goyal, P.; Jackel, L.D.; Monfort, M.; Muller, U.; Zhang, J.; et al. End to End Learning for Self-Driving Cars. arXiv 2016, arXiv:1604.07316. [Google Scholar]
- Kahn, G.; Abbeel, P.; Levine, S. BADGR: An autonomous self-supervised learning-based navigation system. arXiv 2020, arXiv:2002.05700. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529. [Google Scholar] [CrossRef]
- Panov, A.I.; Yakovlev, K.S.; Suvorov, R. Grid path planning with deep reinforcement learning: Preliminary results. Procedia Comput. Sci. 2018, 123, 347–353. [Google Scholar] [CrossRef]
- Wang, B.; Liu, Z.; Li, Q.; Prorok, A. Mobile Robot Path Planning in Dynamic Environments through Globally Guided Reinforcement Learning. arXiv 2020, arXiv:2005.05420. [Google Scholar] [CrossRef]
- Salay, R.; Queiroz, R.; Czarnecki, K. An Analysis of ISO 26262: Machine Learning and Safety in Automotive Software; Technical Report, SAE Technical Paper; SAE: Pittsburgh, PA, USA, 2018. [Google Scholar]
- Steffi, D.D.; Mehta, S.; Venkatesh, K.; Dasari, S.K. Robot Path Planning—Prediction: A Multidisciplinary Platform: A Survey. In Data Science and Security; Springer: Singapore, 2021; pp. 211–219. [Google Scholar]
- Cai, K.; Wang, C.; Cheng, J.; De Silva, C.W.; Meng, M.Q.H. Mobile Robot Path Planning in Dynamic Environments: A Survey. arXiv 2020, arXiv:2006.14195. [Google Scholar]
- Li, J.; Yang, S.X.; Xu, Z. A Survey on Robot Path Planning using Bio-inspired Algorithms. In Proceedings of the 2019 IEEE International Conference on Robotics and Biomimetics (ROBIO), Dali, China, 6–8 December 2019; pp. 2111–2116. [Google Scholar]
- Wang, J.; Chi, W.; Li, C.; Wang, C.; Meng, M.Q.H. Neural RRT*: Learning-based optimal path planning. IEEE Trans. Autom. Sci. Eng. 2020, 17, 1748–1758. [Google Scholar] [CrossRef]
- Wu, H.; Chen, Z.; Sun, W.; Zheng, B.; Wang, W. Modeling trajectories with recurrent neural networks. In Proceedings of the 26th International Joint Conference on Artificial Intelligence IJCAI-17, Melbourne, Australia, 19–25 August 2017. [Google Scholar]
- Park, S.H.; Kim, B.; Kang, C.M.; Chung, C.C.; Choi, J.W. Sequence-to-sequence prediction of vehicle trajectory via LSTM encoder-decoder architecture. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1672–1678. [Google Scholar]
- Ma, Y.; Zhu, X.; Zhang, S.; Yang, R.; Wang, W.; Manocha, D. Trafficpredict: Trajectory prediction for heterogeneous traffic-agents. In Proceedings of the AAAI Conference on Artificial Intelligence 2019, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 6120–6127. [Google Scholar]
- Altché, F.; de La Fortelle, A. An LSTM network for highway trajectory prediction. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 353–359. [Google Scholar]
- Deo, N.; Trivedi, M.M. Multi-modal trajectory prediction of surrounding vehicles with maneuver based lstms. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1179–1184. [Google Scholar]
- Kim, B.; Kang, C.M.; Kim, J.; Lee, S.H.; Chung, C.C.; Choi, J.W. Probabilistic vehicle trajectory prediction over occupancy grid map via recurrent neural network. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 399–404. [Google Scholar]
- Hornung, A.; Wurm, K.M.; Bennewitz, M.; Stachniss, C.; Burgard, W. OctoMap: An efficient probabilistic 3D mapping framework based on octrees. Auton. Robot. 2013, 34, 189–206. [Google Scholar] [CrossRef] [Green Version]
- Han, S. Towards efficient implementation of an octree for a large 3D point cloud. Sensors 2018, 18, 4398. [Google Scholar] [CrossRef] [Green Version]
- Vanneste, S.; Bellekens, B.; Weyn, M. 3DVFH+: Real-time three-dimensional obstacle avoidance using an Octomap. In Proceedings of the MORSE 2014—Model-Driven Robot Software Engineering, York, UK, 21 July 2014; Volume 1319, pp. 91–102. [Google Scholar]
- Zhang, G.; Wu, B.; Xu, Y.L.; Ye, Y.D. Multi-granularity environment perception based on octree occupancy grid. Multimed. Tools Appl. 2020, 79, 26765–26785. [Google Scholar] [CrossRef]
- Wang, T.; Wu, Y.; Liang, J.; Han, C.; Chen, J.; Zhao, Q. Analysis and experimental kinematics of a skid-steering wheeled robot based on a laser scanner sensor. Sensors 2015, 15, 9681–9702. [Google Scholar] [CrossRef] [Green Version]
- Wong, J.; Chiang, C. A general theory for skid steering of tracked vehicles on firm ground. Proc. Inst. Mech. Eng. Part D J. Automob. Eng. 2001, 215, 343–355. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Dolgov, D.; Thrun, S.; Montemerlo, M.; Diebel, J. Practical search techniques in path planning for autonomous driving. Ann Arbor 2008, 1001, 18–80. [Google Scholar]
- Trasnea, B.; Marina, L.; Vasilcoi, A.; Pozna, C.; Grigorescu, S. GridSim: A Simulated Vehicle Kinematics Engine for Deep Neuroevolutionary Control in Autonomous Driving. In Proceedings of the 2019 Third IEEE International Conference on Robotic Computing (IRC), Naples, Italy, 25–27 February 2019. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scenario | Method | |||||
|---|---|---|---|---|---|---|
| GridSim | Hybrid A* | 1.43 | 3.21 | 2.71 | 4.01 | 2.71 |
| simulation | Regression | 3.51 | 7.20 | 4.71 | 8.53 | 5.10 |
| Neural RRT | 1.27 | 3.01 | 2.35 | 2.98 | 2.48 | |
| Octopath | 1.16 | 2.31 | 1.72 | 2.75 | 2.07 | |
| Indoor | Hybrid A* | 1.21 | 4.33 | 1.33 | 3.88 | 1.74 |
| navigation | Regression | 1.90 | 5.73 | 2.31 | 4.98 | 2.75 |
| Neural RRT | 1.01 | 3.29 | 0.98 | 2.16 | 1.44 | |
| Octopath | 0.55 | 1.08 | 0.44 | 0.87 | 0.69 | |
| Outdoor | Hybrid A* | 1.35 | 4.67 | 1.44 | 4.44 | 1.98 |
| navigation | Regression | 2.41 | 8.42 | 2.77 | 8.98 | 3.01 |
| Neural RRT | 1.05 | 2.52 | 1.06 | 3.24 | 1.17 | |
| Octopath | 0.71 | 1.46 | 0.57 | 1.17 | 0.88 |
| Nvidia AGX Xavier Power Mode | Number of Online Cores | CPU Maximal Frequency (MHz) | TensorRT (ms) | Native Tensorflow (ms) |
|---|---|---|---|---|
| MODE_10W | 2 | 1200 | 41.24 | 314.66 |
| MODE_15W | 4 | 1200 | 29.89 | 207.12 |
| MODE_30W_4CORE | 4 | 1780 | 21.37 | 153.86 |
| MODE_30W_6CORE | 6 | 2100 | 17.85 | 121.38 |
| MODE_MAXN | 8 | 2265 | 14.23 | 89.61 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Trăsnea, B.; Ginerică, C.; Zaha, M.; Măceşanu, G.; Pozna, C.; Grigorescu, S. OctoPath: An OcTree-Based Self-Supervised Learning Approach to Local Trajectory Planning for Mobile Robots. Sensors 2021, 21, 3606. https://doi.org/10.3390/s21113606
Trăsnea B, Ginerică C, Zaha M, Măceşanu G, Pozna C, Grigorescu S. OctoPath: An OcTree-Based Self-Supervised Learning Approach to Local Trajectory Planning for Mobile Robots. Sensors. 2021; 21(11):3606. https://doi.org/10.3390/s21113606
Chicago/Turabian StyleTrăsnea, Bogdan, Cosmin Ginerică, Mihai Zaha, Gigel Măceşanu, Claudiu Pozna, and Sorin Grigorescu. 2021. "OctoPath: An OcTree-Based Self-Supervised Learning Approach to Local Trajectory Planning for Mobile Robots" Sensors 21, no. 11: 3606. https://doi.org/10.3390/s21113606
APA StyleTrăsnea, B., Ginerică, C., Zaha, M., Măceşanu, G., Pozna, C., & Grigorescu, S. (2021). OctoPath: An OcTree-Based Self-Supervised Learning Approach to Local Trajectory Planning for Mobile Robots. Sensors, 21(11), 3606. https://doi.org/10.3390/s21113606