
An Efficient and Accurate Iris Recognition Algorithm Based on a Novel Condensed 2-ch Deep Convolutional Neural Network


Abstract
:1. Introduction
2. Related Work
- To allow the 2-ch CNN to apply in the large-scale iris identification scenario, we investigate the encoding ability of the 2-ch CNN in different layers and put forward a hybrid framework which takes advantage of the accurateness of 2-ch CNN and the efficiency of the encoding and matching.
- A radial attention layer that can guide our model to focus on relevant iris regions along the radial direction is proposed, and branch level model pruning is realized by norm computing.
- Three types of online augmentation schemes are designed to enhance the robustness of the model. The successful modeling of brightness jitter, iris image rotation, and radial extension occurring in real-time iris recognition can prevent the model from overfitting and allow the model to train on the small-scale training dataset.
- A condensed 2-ch CNN with optimal architecture is obtained by pruning the model at the channel level as well as the branch level.
3. Methods
3.1. Preprocessing
3.2. Online Augmentation Method
3.3. Modified 2-ch Deep Convolutional Neural Network
3.4. Structural Model Pruning
3.5. Efficient Encoding for Large Scale Iris Recognition
4. Experiments and Results
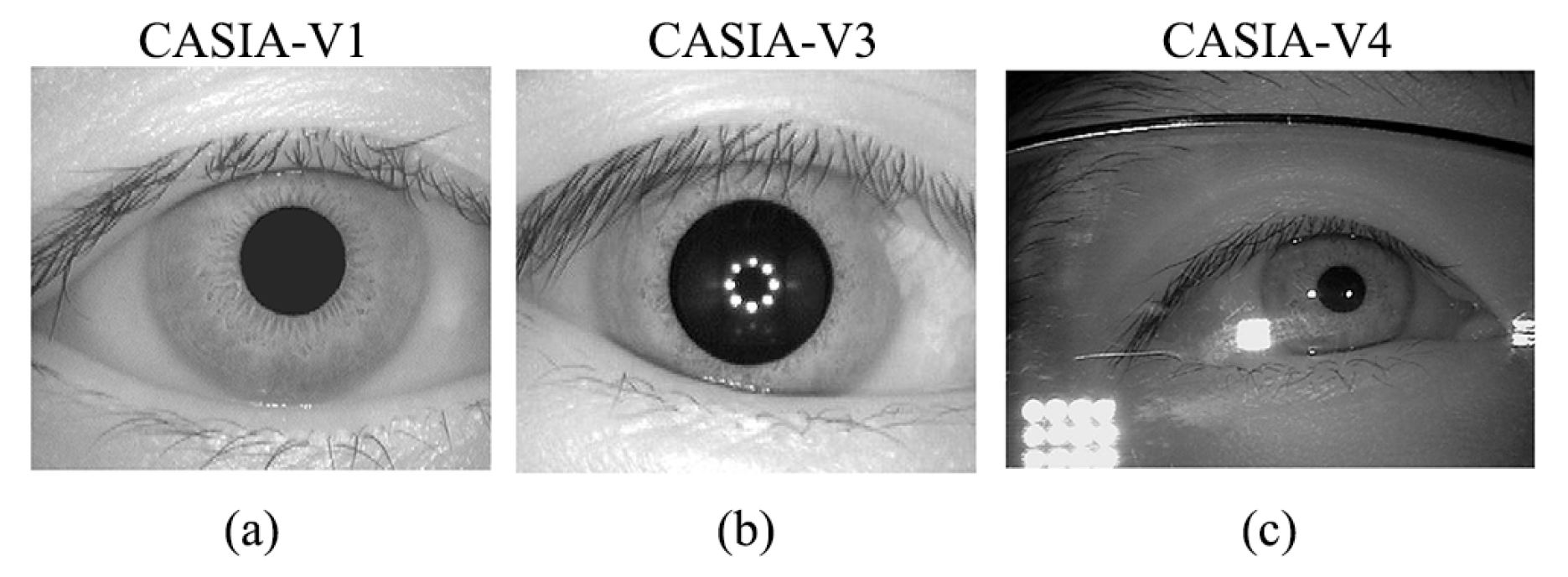
4.1. Experimental Iris Databases
4.2. Experimental Results for Iris Identification and Verification
4.3. Ablation Study
4.4. Encoding Ability Research
5. Discussion
5.1. Weight Visualization
5.2. Time Consumption Experiments
5.3. Interpretability Analysis
5.4. Comparison of Iris Recognition Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bowyer, K.W.; Hollingsworth, K.; Flynn, P.J. Image understanding for iris biometrics: A survey. Comput. Vis. Image Underst. 2008, 110, 281–307. [Google Scholar] [CrossRef]
- Nguyen, K.; Fookes, C.; Jillela, R.; Sridharan, S.; Ross, A. Long range iris recognition: A survey. Pattern Recognit. 2017, 72, 123–143. [Google Scholar] [CrossRef]
- Sheela, S.; Vijaya, P. Iris recognition methods-survey. Int. J. Comput. Appl. Technol. 2010, 3, 19–25. [Google Scholar] [CrossRef]
- Winston, J.J.; Hemanth, D.J. A comprehensive review on iris image-based biometric system. Soft Comput. 2019, 23, 9361–9384. [Google Scholar] [CrossRef]
- Bonnen, K.; Klare, B.F.; Jain, A.K. Component-based representation in automated face recognition. IEEE Trans. Inf. Forensics Secur. 2012, 8, 239–253. [Google Scholar] [CrossRef] [Green Version]
- Meraoumia, A.; Chitroub, S.; Bouridane, A. Palmprint and Finger-Knuckle-Print for efficient person recognition based on Log-Gabor filter response. Analog Integr. Circuits Signal Process. 2011, 69, 17–27. [Google Scholar] [CrossRef]
- Jain, A.K.; Arora, S.S.; Cao, K.; Best-Rowden, L.; Bhatnagar, A. Fingerprint recognition of young children. IEEE Trans. Inf. Forensics Secur. 2016, 12, 1501–1514. [Google Scholar] [CrossRef]
- Alqahtani, A. Evaluation of the reliability of iris recognition biometric authentication systems. In Proceedings of the 2016 International Conference on Computational Science and Computational Intelligence (CSCI’16), Las Vegas, NV, USA, 15–17 December 2016; pp. 781–785. [Google Scholar]
- Benalcazar, D.P.; Zambrano, J.E.; Bastias, D.; Perez, C.A.; Bowyer, K.W. A 3D Iris Scanner from a Single Image Using Convolutional Neural Networks. IEEE Access 2020, 8, 98584–98599. [Google Scholar] [CrossRef]
- Boyd, A.; Yadav, S.; Swearingen, T.; Kuehlkamp, A.; Trokielewicz, M.; Benjamin, E.; Maciejewicz, P.; Chute, D.; Ross, A.; Flynn, P. Post-Mortem Iris Recognition—A Survey and Assessment of the State of the Art. IEEE Access 2020, 8, 136570–136593. [Google Scholar] [CrossRef]
- Vyas, R.; Kanumuri, T.; Sheoran, G.; Dubey, P. Smartphone based iris recognition through optimized textural representation. Multimed. Tools Appl. 2020, 79, 14127–14146. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Z.-Q.; Zheng, P.; Xu, S.-T.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [Green Version]
- Guo, G.; Zhang, N. A survey on deep learning based face recognition. Comput. Vis. Image Underst. 2019, 189, 102805. [Google Scholar] [CrossRef]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep learning for computer vision: A brief review. Comput. Intell. Neurosci. 2018, 2018, 13. [Google Scholar] [CrossRef] [PubMed]
- Guo, Y.; Liu, Y.; Oerlemans, A.; Lao, S.; Wu, S.; Lew, M.S. Deep learning for visual understanding: A review. Neurocomputing 2016, 187, 27–48. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Twenty-sixth Annual Conference on Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–8 December 2012. [Google Scholar]
- Bazrafkan, S.; Thavalengal, S.; Corcoran, P. An end to end deep neural network for iris segmentation in unconstrained scenarios. Neural Netw. 2018, 106, 79–95. [Google Scholar] [CrossRef] [Green Version]
- Arsalan, M.; Naqvi, R.A.; Kim, D.S.; Nguyen, P.H.; Owais, M.; Park, K.R. IrisDenseNet: Robust iris segmentation using densely connected fully convolutional networks in the images by visible light and near-infrared light camera sensors. Sensors 2018, 18, 1501. [Google Scholar] [CrossRef] [Green Version]
- Jayanthi, J.; Lydia, E.L.; Krishnaraj, N.; Jayasankar, T.; Babu, R.L.; Suji, R.A. An effective deep learning features based integrated framework for iris detection and recognition. J. Ambient Intell. Humaniz. Comput. 2020, 12, 3271–3281. [Google Scholar] [CrossRef]
- Hamd, M.H.; Ahmed, S.K. Biometric system design for iris recognition using intelligent algorithms. Inter. J. Educ. Mod. Comp. Sci. 2018, 10, 9. [Google Scholar] [CrossRef]
- Park, K.; Song, M.; Kim, S.Y. The design of a single-bit CMOS image sensor for iris recognition applications. Sensors 2018, 18, 669. [Google Scholar] [CrossRef] [Green Version]
- Agarwal, R.; Jalal, A.S. Presentation attack detection system for fake Iris: A review. Multimed. Tools. Appl. 2021, 80, 15193–15214. [Google Scholar] [CrossRef]
- Nguyen, D.T.; Pham, T.D.; Lee, Y.W.; Park, K.R. Deep learning-based enhanced presentation attack detection for iris recognition by combining features from local and global regions based on NIR camera sensor. Sensors 2018, 18, 2601. [Google Scholar] [CrossRef] [Green Version]
- Wang, K.; Kumar, A. Toward more accurate iris recognition using dilated residual features. IEEE Trans. Inf. Forensics Secur. 2019, 14, 3233–3245. [Google Scholar] [CrossRef]
- Daugman, J.G. High confidence visual recognition of persons by a test of statistical independence. IEEE Trans. Pattern Anal. Mach. Intell. 1993, 15, 1148–1161. [Google Scholar] [CrossRef] [Green Version]
- Flom, L.; Safir, A. Iris Recognition System. Google Patents US4641349A, 3 February 1987. [Google Scholar]
- Daugman, J. New methods in iris recognition. IEEE Trans. Syst. Man Cybern. Syst. Cybern Part B (Cybern) 2007, 37, 1167–1175. [Google Scholar] [CrossRef] [Green Version]
- Daugman, J. How iris recognition works. In The Essential Guide to Image Processing; Elsevier: Amsterdam, The Netherlands, 2009; pp. 715–739. [Google Scholar]
- Barpanda, S.S.; Majhi, B.; Sa, P.K.; Sangaiah, A.K.; Bakshi, S. Iris feature extraction through wavelet mel-frequency cepstrum coefficients. Opt. Laser Technol. 2019, 110, 13–23. [Google Scholar] [CrossRef]
- Nalla, P.R.; Kumar, A. Toward more accurate iris recognition using cross-spectral matching. IEEE Trans. Image Process. 2016, 26, 208–221. [Google Scholar] [CrossRef] [PubMed]
- Yao, P.; Li, J.; Ye, X.Y.; Zhuang, Z.Q.; Li, B. Iris recognition algorithm using modified Log-Gabor filters. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; pp. 461–464. [Google Scholar]
- Alonso-Fernandez, F.; Tome-Gonzalez, P.; Ruiz-Albacete, V.; Ortega-Garcia, J. Iris recognition based on SIFT features. In Proceedings of the First IEEE International Conference on Biometrics, Identity and Security (BIdS 2009), Tampa, FL, USA, 22–23 September 2009; p. 8. [Google Scholar]
- Bakshi, S.; Das, S.; Mehrotra, H.; Sa, P.K. Score level fusion of SIFT and SURF for iris. In Proceedings of the 2012 International Conference on Devices, Circuits and Systems (ICDCS), Coimbatore, India, 15–16 March 2012; pp. 527–531. [Google Scholar]
- Zhu, R.; Yang, J.; Wu, R. Iris recognition based on local feature point matching. In Proceedings of the 2006 International Symposium on Communications and Information Technologies, Bangkok, Thailand, 18–20 October 2006; pp. 451–454. [Google Scholar]
- Juneja, K.; Rana, C. Compression-Robust and Fuzzy-Based Feature-Fusion Model for Optimizing the Iris Recognition. Wirel. Pers. Commun. 2021, 116, 267–300. [Google Scholar] [CrossRef]
- Santos, G.; Hoyle, E. A fusion approach to unconstrained iris recognition. Pattern Recognit. Lett. 2012, 33, 984–990. [Google Scholar] [CrossRef]
- Tajbakhsh, N.; Araabi, B.N.; Soltanianzadeh, H. Feature fusion as a practical solution toward noncooperative iris recognition. In Proceedings of the 11th International Conference on Information Fusion, Cologne, Germany, 30 June–3 July 2008; pp. 1–7. [Google Scholar]
- Chen, J.; Shen, F.; Chen, D.Z.; Flynn, P.J. Iris recognition based on human-interpretable features. IEEE Trans. Inf. Forensics Secur. 2016, 11, 1476–1485. [Google Scholar] [CrossRef]
- Shen, F. A Visually Interpretable Iris Recognition System with Crypt Features. Ph.D. Thesis, University of Notre Dame, Notre Dame, IN, USA, 2014. [Google Scholar]
- Gangwar, A.; Joshi, A. DeepIrisNet: Deep iris representation with applications in iris recognition and cross-sensor iris recognition. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 2301–2305. [Google Scholar]
- Nguyen, K.; Fookes, C.; Ross, A.; Sridharan, S. Iris recognition with off-the-shelf CNN features: A deep learning perspective. IEEE Access 2017, 6, 18848–18855. [Google Scholar] [CrossRef]
- Raja, K.B.; Raghavendra, R.; Venkatesh, S.; Busch, C. Multi-patch deep sparse histograms for iris recognition in visible spectrum using collaborative subspace for robust verification. Pattern Recognit. Lett. 2017, 91, 27–36. [Google Scholar] [CrossRef]
- Liu, M.; Zhou, Z.; Shang, P.; Xu, D. Fuzzified image enhancement for deep learning in iris recognition. IEEE Trans. Fuzzy Syst. 2019, 28, 92–99. [Google Scholar] [CrossRef]
- Zagoruyko, S.; Komodakis, N. Learning to compare image patches via convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4353–4361. [Google Scholar]
- Liu, N.; Zhang, M.; Li, H.; Sun, Z.; Tan, T. DeepIris: Learning pairwise filter bank for heterogeneous iris verification. Pattern Recognit. Lett. 2016, 82, 154–161. [Google Scholar] [CrossRef]
- Špetlík, R.; Razumenić, I. Iris verification with convolutional neural network and unit-circle layer. In Proceedings of the 41th German Conference on Pattern Recognition, Dortmund, Germany, 10–13 September 2019. [Google Scholar]
- Proença, H.; Neves, J.C. Segmentation-less and non-holistic deep-learning frameworks for iris recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Othman, N.; Dorizzi, B.; Garcia-Salicetti, S. OSIRIS: An open source iris recognition software. Pattern Recognit. Lett. 2016, 82, 124–131. [Google Scholar] [CrossRef]
- Sutra, G.; Garcia-Salicetti, S.; Dorizzi, B. The Viterbi algorithm at different resolutions for enhanced iris segmentation. In Proceedings of the 2012 5th IAPR International Conference on Biometrics (ICB), New Delhi, India, 29 March–1April 2012. [Google Scholar]
- Gonzalez, R.C.; Woods, R.E.; Eddins, S.L. Digital Image Processing Using MATLAB; Pearson Education India: Bengaluru, India, 2004. [Google Scholar]
- Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; Yang, Y. Random erasing data augmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- DeVries, T.; Taylor, G.W. Improved regularization of convolutional neural networks with cutout. arXiv 2017, arXiv:1708.04552. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Chia Laguna Resort, Sardinia, Italy, 13–15 May 2010. [Google Scholar]
- CASIA-IrisV1. Available online: http://biometrics.idealtest.org/ (accessed on 21 October 2019).
- Database, C.I.I. Available online: http://biometrics.idealtest.org/ (accessed on 21 October 2019).
- Rakvic, R.N.; Ulis, B.J.; Broussard, R.P.; Ives, R.W.; Steiner, N. Parallelizing iris recognition. IEEE Trans. Inf. Forensics Secur. 2009, 4, 812–823. [Google Scholar] [CrossRef]
- Subramanian, V. Deep Learning with PyTorch: A Practical Approach to Building Neural Network Models Using PyTorch; Packt Publishing Ltd.: Birmingham, UK, 2018. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Wang, Z.; Li, C.; Shao, H.; Sun, J. Eye recognition with mixed convolutional and residual network (MiCoRe-Net). IEEE Access 2018, 6, 17905–17912. [Google Scholar] [CrossRef]
- Tobji, R.; Di, W.; Ayoub, N. FMnet: Iris segmentation and recognition by using fully and multi-scale CNN for biometric security. Appl. Sci. 2019, 9, 2042. [Google Scholar] [CrossRef] [Green Version]
- Lee, Y.W.; Kim, K.W.; Hoang, T.M.; Arsalan, M.; Park, K.R. Deep residual CNN-based ocular recognition based on rough pupil detection in the images by NIR camera sensor. Sensors 2019, 19, 842. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Wu, C.; Wang, Y. T-Center: A Novel Feature Extraction Approach towards Large-Scale Iris Recognition. IEEE Access 2020, 8, 32365–32375. [Google Scholar] [CrossRef]
- Alaslani, M.G.; Elrefaei, L.A. Convolutional neural network based feature extraction for iris recognition. J. Comput. Sci. Inf. Technol. 2018, 10, 65–78. [Google Scholar] [CrossRef] [Green Version]
- Boyd, A.; Czajka, A.; Bowyer, K. Deep learning-based feature extraction in iris recognition: Use existing models, fine-tune or train from scratch? In Proceedings of the 2019 IEEE 10th International Conference on Biometrics Theory, Applications and Systems (BTAS), Tampa, FL, USA, 23–26 September 2019. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Database (Method) | Training Classes | Testing Classes | Identification | Verification | |||
|---|---|---|---|---|---|---|---|---|
| Register 1 Picture | Register 6 Pictures | EER | FRR@ FAR = 0.1% | FRR@ FAR = 0.01% | ||||
| 1 | CASIA-V3 | 33 | 200 | 98.95% | 100% | 0.76% | 1.24% | 1.45% |
| 2 | CASIA-V1 | 0 | 108 | 99.51% | 100% | 0.35% | 0.57% | 1.32% |
| 3 | CASIA-V1 | 20 | 88 | 99.76% | 100% | 0.33% | 0.43% | 1.46% |
| 4 | CASIA-V4 | 0 | 648 | 89.53% | 98.21% | 3.54% | 16.92% | 31.13% |
| 5 | CASIA-V4 | 5 | 615 | 94.89% | 99.47% | 2.20% | 5.84% | 12.40% |
| 6 | CASIA-V4 | 10 | 615 | 96.10% | 99.58% | 1.80% | 4.28% | 8.87% |
| 7 | CASIA-V4 | 15 | 615 | 97.12% | 99.72% | 1.30% | 2.89% | 5.40% |
| 8 | CASIA-V4 | 20 | 615 | 97.65% | 99.79% | 1.23% | 2.39% | 3.96% |
| 9 | CASIA-V4 | 25 | 615 | 97.86% | 99.81% | 1.18% | 2.25% | 3.50% |
| 10 | CASIA-V4 | 30 | 615 | 97.92% | 99.77% | 1.19% | 2.16% | 3.31% |
| No. | Structure | Loss | Reg. | Aug. | Att. | Pru. | Fin. | EER |
|---|---|---|---|---|---|---|---|---|
| 1 | Resnet | MSE | √ | √ | × | × | × | 1.55% |
| 2 | A | MSE | √ | √ | × | × | × | 1.26% |
| 3 | A | MSE | × | √ | × | × | × | 1.86% |
| 4 | A | MSE | √ | × | × | × | × | 3.40% |
| 5 | A | CE | √ | √ | × | × | × | 1.55% |
| 6 | A | MSE | √ | √ | √ | × | × | 1.09% |
| 7 | C | MSE | √ | √ | √ | √ | × | 1.22% |
| 8 | C | MSE | √ | √ | √ | √ | √ | 1.03% |
| 9 | C † | MSE | √ | √ | √ | √ | √ | 1.26% |
| 10 | C o | MSE | √ | √ | √ | √ | √ | 0.76% |
| No. | BJ. | HS. | LS. | EER | FRR@ FAR = 0.1% | FRR@ FAR = 0.01% |
|---|---|---|---|---|---|---|
| 1 | × | × | × | 2.80% | 9.46% | 17.05% |
| 2 | √ | × | × | 2.64% | 8.00% | 14.86% |
| 3 | × | √ | × | 2.50% | 8.89% | 16.83% |
| 4 | × | × | √ | 2.71% | 9.30% | 17.43% |
| 5 | × | √ | √ | 2.36% | 7.84% | 16.16% |
| 6 | √ | × | √ | 2.50% | 6.48% | 14.41% |
| 7 | √ | √ | × | 2.36% | 7.84% | 14.48% |
| 8 | √ | √ | √ | 2.27% | 6.06% | 13.97% |
| Layer | Type | Discarding Accuracy (%) | Feature Length | Time (ms) |
|---|---|---|---|---|
| 1 | Input | 85.61 ± 2.43 | 21,600 | 21.00 |
| 2 | Attention | 85.35 ± 2.61 | 21,600 | 20.76 |
| 3 | Convolution | 77.65 ± 2.86 | 118,800 | 104.56 |
| 4 | BN | 72.37 ± 3.24 | 118,800 | 104.09 |
| 5 | ReLu | 72.19 ± 3.18 | 118,800 | 104.09 |
| 6 | MP | 75.32 ± 2.92 | 29,700 | 27.57 |
| 7 | Attention | 73.36 ± 3.21 | 29,700 | 28.48 |
| 8 | Convolution | 71.37 ± 3.17 | 59,400 | 52.91 |
| 9 | BN | 70.82 ± 3.23 | 59,400 | 53.02 |
| 10 | ReLu | 76.00 ± 3.26 | 59,400 | 53.74 |
| 11 | MP | 83.58 ± 2.68 | 15,840 | 15.67 |
| 12 | Convolution | 90.79 ± 1.30 | 36,720 | 33.68 |
| 13 | BN | 91.70 ± 0.95 | 36,720 | 33.37 |
| 14 | ReLu | 89.48 ± 1.83 | 36,720 | 33.28 |
| 15 | MP | 95.88 ± 0.86 | 18,360 | 18.31 |
| 16 | Convolution | 96.52 ± 0.70 | 10,080 | 10.99 |
| 17 | BN | 96.55 ± 0.68 | 10,080 | 10.82 |
| 18 | ReLu | 96.27 ± 1.09 | 10,080 | 10.90 |
| 19 | MP | 95.42 ± 1.33 | 3360 | 5.00 |
| 20 | Convolution | 80.92 ± 2.66 | 960 | 2.25 |
| 21 | BN | 84.39 ± 3.07 | 960 | 2.25 |
| 22 | ReLu | 90.23 ± 1.92 | 960 | 2.41 |
| 23 | Convolution | 77.75 ± 2.57 | 8160 | 9.08 |
| 24 | BN | 77.48 ± 2.22 | 8160 | 9.10 |
| 25 | ReLu | 72.51 ± 2.50 | 8160 | 9.04 |
| 26 | GAP | 26.79 ± 1.75 | 68 | 1.33 |
| 27 | FC | 16.83 ± 1.23 | 1 | 1.05 |
| No | Studies | Year | Method | Parameters/FLOPs | Evaluation Protocol | Augmentation | Result |
|---|---|---|---|---|---|---|---|
| 1 | Othman et al. [50] | 2016 | IrisCode (2D-Gabor filter + Hamming Distance) | -/- | CASIA-V4: 602 classes (for testing) | None | CASIA-V4: 3.5% (Verification EER) |
| 2 | Nguyen et al. [43] | 2017 | Pre-trained CNN (Dense-Net) + SVM | -/- | CASIA-V4: 1000 classes (Train: 70%, Test: 30%) * | None | CASIA-V4: 98.8% (Identification Accuracy) |
| 3 | Alaslani et al. [67] | 2018 | Pre-trained CNN (Alex-Net) + SVM | 41 M/2.2 B | CASIA-V1: 60 classes CASIA-V3: 60 classes CASIA-V4: 60 classes (Train: 70%, Test: 30%) * | None | CASIA-V1: 98.3% CASIA-V3: 89% CASIA-V4: 98% (Identification Accuracy) |
| 4 | Wang et al. [63] | 2018 | MiCoRe-Net | >1.4 M/>50 M | CASIA-V3: 218 classes (Train: 1346 images, Test: 218 images) * CASIA-V4: 1000 classes (Train: 9000 images, Test: 1000 images) * | Rotation and Cropping | CASIA-V3: 99.08% CASIA-V4: 88.7% (Identification Accuracy) |
| 5 | Tobji et al. [64] | 2019 | FMnet | 15 K/10 M | CASIA-V4: 1000 classes (Train: 70%, Test: 30%) * | None | CASIA-V4: 95.63% (Identification Accuracy) |
| 7 | Boyd et al. [68] | 2019 | Pre-trained/Finetuned CNN (ResNet-50) + SVM | 25 M/5.1 B | CASIA-V4: 1000 classes (Train: 70%, Test: 30%) * | None | CASIA-V4: 99.03% (Identification Accuracy) |
| 6 | Liu et al. [45] | 2019 | Fuzzified image + Capsule network | >4 M/- | CASIA-V4: 1000 classes (Train: 80%, Test: 20%) | None | CASIA-V4: 83.1% (Identification Accuracy) |
| 8 | Lee et al. [65] | 2019 | Deep ResNet-152 +Matching distance | >53 M/>10 B | CASIA-V4: 1000 classes (Train: 50%, Test: 50%) | Translation and Cropping | CASIA-V4: 1.33% (Verification EER) |
| 9 | Proença et al. [49] | 2019 | VGG-19 based CNN | 138 M/- | CASIA-V4: 2000 classes (Train: 1000 classes, Test: 1000 classes) | Scale transform and Intensity transform | CASIA-V4: 3.0% (Verification EER) |
| 10 | Chen et al. [66] | 2020 | Tiny-VGG based CNN | >10 M/>1.3 B | CASIA-V4: 140 K pairs (Train: 50,632 images on another database) | Contrast, Brightness, and Distortion | CASIA-V4: 99.58% (Identification Accuracy) CASIA-V4: 2.36% (Verification EER) |
| 11 | Proposed Method | 2021 | Condensed 2-ch CNN | 33 K/49.1 M | CASIA-V1: 108 classes (Finetune: 20 classes, Test: 88 classes) CASIA-V3: 233 classes (Train: 33 classes, Test: 200 classes) CASIA-V4: 648 classes (Finetune: 30 classes, Test: 615 classes) | Brightness jitter, Horizontal shift, and Longitudinal scaling (Online) | CASIA-V1: 100% CASIA-V3: 100% CASIA-V4: 99.77% (Identification Accuracy) CASIA-V1: 0.33% CASIA-V3: 0.76% CASIA-V4: 1.19% (Verification EER) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, G.; Zhou, W.; Tian, L.; Liu, W.; Liu, Y.; Xu, H. An Efficient and Accurate Iris Recognition Algorithm Based on a Novel Condensed 2-ch Deep Convolutional Neural Network. Sensors 2021, 21, 3721. https://doi.org/10.3390/s21113721
Liu G, Zhou W, Tian L, Liu W, Liu Y, Xu H. An Efficient and Accurate Iris Recognition Algorithm Based on a Novel Condensed 2-ch Deep Convolutional Neural Network. Sensors. 2021; 21(11):3721. https://doi.org/10.3390/s21113721
Chicago/Turabian StyleLiu, Guoyang, Weidong Zhou, Lan Tian, Wei Liu, Yingjian Liu, and Hanwen Xu. 2021. "An Efficient and Accurate Iris Recognition Algorithm Based on a Novel Condensed 2-ch Deep Convolutional Neural Network" Sensors 21, no. 11: 3721. https://doi.org/10.3390/s21113721
APA StyleLiu, G., Zhou, W., Tian, L., Liu, W., Liu, Y., & Xu, H. (2021). An Efficient and Accurate Iris Recognition Algorithm Based on a Novel Condensed 2-ch Deep Convolutional Neural Network. Sensors, 21(11), 3721. https://doi.org/10.3390/s21113721