Abstract
The original Hyperspectral image (HSI) has different degrees of Hughes phenomenon and mixed noise, leading to the decline of classification accuracy. To make full use of the spatial-spectral joint information of HSI and improve the classification accuracy, a novel dual feature extraction framework joint transform domain-spatial domain filtering based on multi-scale-superpixel-dimensionality reduction (LRS-HRFMSuperPCA) is proposed. Our framework uses the low-rank structure and sparse representation of HSI to repair the unobserved part of the original HSI caused by noise and then denoises it through a block-matching 3D algorithm. Next, the dimension of the reconstructed HSI is reduced by principal component analysis (PCA), and the dimensions of the reduced images are segmented by multi-scale entropy rate superpixels. All the principal component images with superpixels are projected into the reconstructed HSI in parallel. Secondly, PCA is once again used to reduce the dimension of all HSIs with superpixels in scale with hyperpixels. Moreover, hierarchical domain transform recursive filtering is utilized to obtain the feature images; ultimately, the decision fusion strategy based on a support vector machine (SVM) is used for classification. According to the Overall Accuracy (OA), Average Accuracy (AA) and Kappa coefficient on the three datasets (Indian Pines, University of Pavia and Salinas), the experimental results have shown that our proposed method outperforms other state-of-the-art methods. The conclusion is that LRS-HRFMSuperPCA can denoise and reconstruct the original HSI and then extract the space-spectrum joint information fully.
1. Introduction
HSI uses numerous continuous narrow-band electromagnetic wave bands to image the surface species and obtain rich joint information of the space-spectrum. With the rapid development of HSI processing and analysis in recent years, HSI classification technology is extensively utilized in agriculture [1], environmental detection [2], marine monitoring [3], and other fields; however, considering the effects of imaging sensor breakdown [4], environmental pollution [5], and other factors, the obtained HSI has mixed noise [6,7,8,9] that reduces the classification accuracy. For example, Tu et al. [7] proposed a kernel entropy component analysis (KECA)-based method for noisy label detection that can remove noisy labels for the PaviaU with 50 true samples and 10 noisy labels per class, KECA obtains 81.11% OA, with 50 true samples and 30 noisy labels per class, the OA is 71%. Xu et al. [8] proposed a spectral-spatial classification of HSI based on low-rank decomposition, by removing the sparse part, the LRD-NWFE-GC [8] obtains 92.3% on Indian Pines even if the training sample is small. On the contrary, the NWFE-GC [8] does not remove the sparse noise, and the classification accuracy is reduced to 74.53%. So, the HSI denoising needs to be solved.
The common noises in HSI are gaussian, impulse, and stripe noises [10]. The methods of noise removal are divided into transform domain filtering and spatial domain filtering [11]. Original spatial domain filtering is easy to perform; however, it will cause a blur of the image and losing some edge and texture details. At present, the edge-preserving filtering method can eliminate the image noise and keep the boundary between various species clear. Typical edge-preserving filtering methods based on spatial domain include a guided filter presented by He et al. [12] and a domain transform recursive filter proposed by Gastal et al. [13]. The non-local mean method is also a type of spatial domain filtering. The related non-local mean algorithms are the shape adaptive non-local mean algorithm [14] and the block matching 3D (BM3D) algorithm [15]. BM3D can preserve the image edge and texture information and obtain a high signal-to-noise ratio [15]. The transform domain filtering denoising transforms the image from the spatial domain to the transform domain through a set of orthogonal transforms. It separates the signal and noise via the different features of noise and signal in the transform domain. In recent years, the denoising algorithm based on sparse representation is extensively used in the field of HSI processing. Low-rank sparse representation is a technique to decompose the observation matrix into the low-rank matrix and sparse matrix, using the low-rank attribute of HSI. This technology can restore the low-rank component robustly when the image is destroyed by mixed noise. In this regard, Zhang et al. [16] proposed an HSI restoration method based on low-rank matrix restoration. A fast denoising algorithm based on low-rank sparse representation was proposed by Lina et al. [17], taking full advantage of the HSIs’ low-rank structure and self-similarity to further improve the denoising effect.
HSI can present rich spectral information by increasing the dimension of HSI data. The classification accuracy will first increase and then decrease, leading to the dimension disaster [18]. The dimension reduction algorithms of HSI are divided into band selection [19,20] and feature extraction. A feature extraction algorithm is divided into supervised and unsupervised. Among the traditional unsupervised algorithms is PCA [21]. PCA does not need label information, it can be reduced to any dimension and is easy to implement. Later, some efficient unsupervised algorithms were proposed, such as subspace feature learning [22] and potential subclass learning [23]. A supervised dimensionality reduction algorithm utilizes supervised information known as labels, to learn the feature space after dimensionality reduction. The representative work includes linear discriminant analysis (LDA) [24] and local Fisher discriminant analysis (LFDA) [25]. LDA cannot only reduce the dimension, but also distinguish different kinds of samples. On the other hand, many HSIs contain complex types of surface features. LDA needs a lot of manpower and costs much time to acquire prior knowledge, and when the ratio between the number of training samples and the number of features is very small, the LDA will achieve lower classification accuracy [24]. In recent years, the spectral features of each pixel are used in most feature extraction algorithms ignoring the spatial features, in order to make full use of spatial features. Kang et al. [26] proposed a spatial-spectral joint classification algorithm based on image fusion (IFRF). An HSI classification algorithm was proposed by Tu et al. [27] combining the correlation coefficient and the joint sparse representation (CCJSR). It can make full use of spectral similarity information and spatial context information at the same time. With the development of deep learning technology, a convolutional neural network (CNN) is extensively utilized in image processing [28]. The relevant CNN classification algorithms based on the spatial-spectral combination include 2D-CNN [29], SSRN [30], CDL-MLR [31] and SSFC [32] to obtain a robust result. Although deep learning methods have great advantages in classification, the architecture of CNNs often has feature redundancy. Therefore, Arijitet et al. [33] proposed a CNN structure based on the GhoMR module to reduce the number of parameters and form a lightweight feature extraction module. Compared with the original 2D-CNN algorithm, the OA of the GhoMR algorithm is improved by 18%, on Indian Pines with 10% training set. Besides, different species often exist in various regions of HSI, resulting in different spectral features. However, most of the extraction algorithms often construct a unified projection space for the feature image after dimensionality reduction [21,26,33], making it impossible to make full use of the different spectral features of various species. To solve this problem, segmentation technology divides the observed image into several specific regions. Jakub et al. [34]. proposed an end-to-end approach to segment hyperspectral images in a fully unsupervised way. Jiang et al. [35]. proposed a feature extraction algorithm based on multi-scale superpixel PCA(MSuperPCA). A superpixel representation based on K-Nearest Neighbor was proposed by Tu et al. [36] for HSI classification (KNNRS). The authors of [34,35,36] fully extracted the spatial-spectral features of HSI.
Compared with the basic feature extraction algorithm PCA, in recent years, there are many advanced feature extraction algorithms, for example, LFDA [25] and 2D-CNN [29] improve the OA only by at least 3%, IFRF [26], CCJSR [27], SSRN [30], CDL-MLR [31], GhoMR [33], MSuperPCA [35], and KNNRS [36] improve the OA by at least 15% on the Indian Pines with 10% training sets; however, only the spatial domain denoising algorithm is selected for feature extraction [26,36]. The noise in HSI is often mixed noise. Different noise has various imaging reasons and denoising strategies. To reduce the mixed noise of HSI and further enhance the subsequent classification accuracy, transformation domain filtering algorithms based on low-rank sparse representations can robustly recover the low-rank component when the images are destroyed by mixed noise. Nevertheless, HSI classification algorithms only selecting low-rank sparse representations cannot acquire sufficiently spatial structural information, leading to decreased classification accuracy on datasets that are large and complex in texture and structure [27]. The original HSI is not denoised by the HSI feature extraction algorithm based on multi-scale superpixel PCA. Hence, the classification accuracy improvement is not obvious when the training set is large [35]. The problem of feature redundancy of traditional convolutional neural networks is solved by convolutional neural network structure based on the GhoMR module achieving high classification accuracy. However, GhoMR performs PCA on the original HSI and constructs a single projection space, making it impossible to make full use of the spectral features of different species [33]. We propose a multi-scale superpixel unsupervised dimension reduction HSI classification algorithm based on hierarchical recursive filtering and low-rank sparse representation (LRS-HRFMSuperPCA), the schematic diagram is shown in Figure 1. Firstly, the low-rank sparse representation algorithm is used to predict the subspace of HSI. The fully observed HSI is obtained according to the subspace. Next, BM3D is utilized to denoise HSI, and PCA is used to reduce the dimension of HSI after restoration and denoising. The principal component images are segmented by multi-scale entropy rate superpixels. To construct multiple projection spaces, the segmented principal component images with superpixels are projected parallel to the denoised HSIs. The dimension of HSI with superpixels is reduced by PCA again, and each feature image in the multi-scale, after dimension reduction, is transformed by hierarchical recursive filtering. Ultimately, the decision fusion algorithm based on an SVM is used to classify the multi-scale feature images after hierarchical recursive filtering and obtain the final classification result.
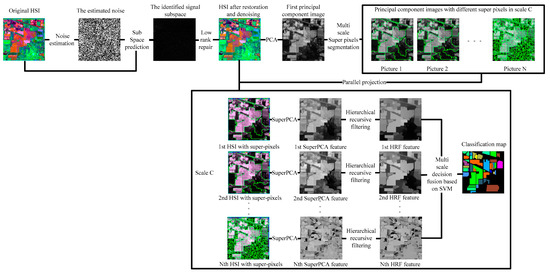
Figure 1.
The schematic of the proposed LRS-HRFMSuperPCA method.
The main contributions of LRS-HRFMSuperPCA can be summarized as follows:
- Compared to other HSI classification algorithms, we propose to integrate the new joint feature extraction framework of spatial domain filtering and transform domain filtering(LRS-HRF) into the MSuperPCA. Firstly, the sparse feature and low-rank structure of HSI are utilized to realize transform domain filtering to separate the mixed noise in the image and improve the PSNR of HSI. Then, the separated feature images are transformed and filtered recursively in a multi-level domain based on the spatial domain. To enhance the spatial-spectral features of the feature image, the strong edges of different objects in the image are preserved and the fine texture structure is removed.
- The HSI with restoration and denoising is obtained by filtering in the transform domain segmented by multi-scale superpixels, and the low-dimension characteristics of different species in different regions are fully obtained. Then, PCA is performed for each HSI with superpixels in multi-scale, and the spatial information of each HSI is fully utilized.
- Compared to the state-of-the-art HSI classification algorithms, the LRS-HRFMSuperPCA algorithm achieves the highest OA, AA, and Kappa coefficient on the three real datasets.
2. Methodology
2.1. Estimation of Noise in Hyperspectral Image
Suppose an original HSI , is the number of pixels in each band, is the number of bands. The high correlation between neighboring spectral bands and the spatial correlation within that band are the reasons underlying the good performance of the linear regression theory in hyperspectral applications [37,38].
Calculate the autocorrelation matrix and the inverse matrix . Traversing all bands, we assume that is explained by a linear combination of the remaining bands, contains the data read by the hyperspectral sensor at the th band for all image pixels, , so we have [39]:
where denotes data from other band image pixels after removing the -th band, is the regression vector of size , and is the noise vector of size , the least squares estimator of the regression vector is given by [39]:
In order to reduce the computational complexity, define the pseudoinverse , of size . Let be the size of symmetric and positive definite matrices and that are partitioned into block matrices as follows:
where and are matrices, and are vectors, and and are scalars. Because they are symmetric and positive, we find:
So, let is the inverse of the autocorrelation matrix obtained by deleting row and column , and we have , the following is the assignment operation, , , thus:
is calculated for the regression vector of each band, the end traversal output yields the estimated noise in the HSI.
2.2. Subspace Prediction of the Signal from the Hyperspectral Image
This section performs a subspace prediction of the signal from the HSI. First, calculate the autocorrelation matrix and the autocorrelation matrix of the noise according to the noise vector . Then, the autocorrelation matrix is computed for the predicted signals. The eigenvectors for are computed. Given a permutation of indices , let us decompose the space into two orthogonal subspaces. The two orthogonal subspaces are: the -D subspace and , is the orthogonal complement of the subspace . Let Uk be the projection matrix onto and be the projection of the observed spectral vector onto the subspace , we introduce the concept of minimum mean square error between and as a criterion of subspace [40].
where is an irrelevant constant, with respect to all the permutations of size and to . So, we can construct the setting item as follows:
Let be the number of negative values of , where . Ultimately, the proper subset of feature vector corresponding to negative is found from as the prediction. The value of the HSI subspace is retrieved from the signal subspace from and .
2.3. Domain Transform Recursive Filtering (DTRF)
The principle of DTRF is to find a transform for the input signal , in the new domain . It is stated that the Euclidean distance between neighboring samples in the new domain must equal the distance between them in the original domain [13].
where represents the sample set on the signal. Set up is the sampling interval, and convert Equation (8) to:
In general, to avoid calculating the absolute value, is defined as a simple increasing function set up . We have:
In the actual filtering process, two adjustable parameters are introduced to adjust the filter, the spatial standard deviation and the spectral standard deviation , as:
where is the transform domain signal, represents the derivative of input one-dimensional signal . Then, the input signal is processed by recursive filtering as:
where refers to the feedback coefficient, is the distance between two adjacent samples in the transform domain, represents the filtered result. By increasing , tends to be zero, which stops the propagation chain to preserve sharp edges in the signal.
3. Proposed LRS-HRFMSuperPCA Method
The HSIs are inevitably contaminated with various noises due to equipment limitation and atmospheric environment impact. On the other hand, the computational complexity will grow exponentially as the dimension increases, which will cause the “curse of dimensionality”; two problems that limit the subsequent classification. We proposed a novel transformation domain-space domain feature extraction framework, called LRS-HRFMSuperPCA, which can effectively improve the classification accuracy and is effective for HSI denoising.
The framework of this joint feature extraction algorithm includes four parts: low-rank sparse representation denoising, multi-scale superpixel dimensionality reduction, and hierarchical domain transform recursive filtering, SVM classification. We detail all parts and provide a pseudo code in the following.
3.1. Low-Rank Sparse Representation Denoising Based on MSuperPCA
Transform domain filtering denoising algorithm is used to remove the mixed noise in the original HSI. Following Jiang et al. [35] and Lina et al. [17], we propose the low-rank sparse representation denoising algorithm to remove noise from the original HSI, as the input of the MSuperPCA algorithm. According to Section 2.2, we can obtain the subspace of the original HSI
where represents Kronecker product and , is the clean image without noise and is the identity matrix, represents the correlation coefficient matrix. The denoising and inpainting problem is formulated as
where is the regularization function, is the regularization coefficient, . Let the mask acting on the unobserved pixel and HSI affected by noise, because , we have
In addition, is the noise part, according to the literature [40], we can obtain . By calculating , we can obtain the fully observed HSI . After recovering the unobserved component, we should solve the denoising problem
For the optimization problem of Equation (17), we choose BM3D for denoising [15], because the image obtained by the BM3D algorithm keeps a high PSNR. Then, the correlation coefficient matrix is obtained. The HSI is solved by .
The dimension of HSI is reduced by PCA, the first principal component images are segmented into principal component images with various superpixel blocks utilizing the entropy rate superpixel algorithm [41], where , is a user-defined number of scales. The number of superpixels per image in the scale is , where , denotes the rank of each picture with superpixels, the segmented superpixel blocks of each scale are parallel projected onto the repaired and denoised HSI . SuperPCA was performed on [35], therefore, we have
where is the dimension after PCA, represents the principal component image after superpixel segmentation.
3.2. Hierarchical Domain Transform Recursive Filtering (HDTRF)
Inspired by the idea of deep learning [42,43], we set up a hierarchical structure based on DTRF [13], as shown in Figure 2, the output feature set of the upper level DTRF unit is used as the input of the next level DTRF unit. The spatial information and spectral information of hyperspectral data are fully mined. The obtained spatial-spectral features preserve the global similarity structure, local geometry structure and rich spatial information of the hyperspectral dataset.
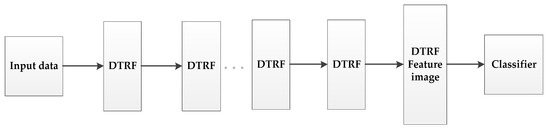
Figure 2.
The schematic of the proposed HDTRF method.
3.3. Decision Fusion Strategy Based on Support Vector Machine
We use multi-scale entropy rate superpixel segmentation to obtain multiple principal component images. We classify the feature image sets after hierarchical recursive filtering by using SVM. SVM is a supervised learning model, and it is mainly oriented to the linear separable case.
In the case of linear inseparability, the linear inseparable samples in the low-dimensional input space are transformed into a high-dimensional feature space by using a nonlinear transformation algorithm. The nonlinear transformation is to map the sample information in the input space into a high-dimensional space through a properly defined inner product function, and then find the optimal linear classification surface in the new space. The optimal classification surface is obtained when the maximum interval classification line is expanded to the -dimensional space. The optimal classification line cannot only correctly separate some individuals of different categories, but also maximize the overall classification interval. The general principle of SVM is shown in Figure 3.
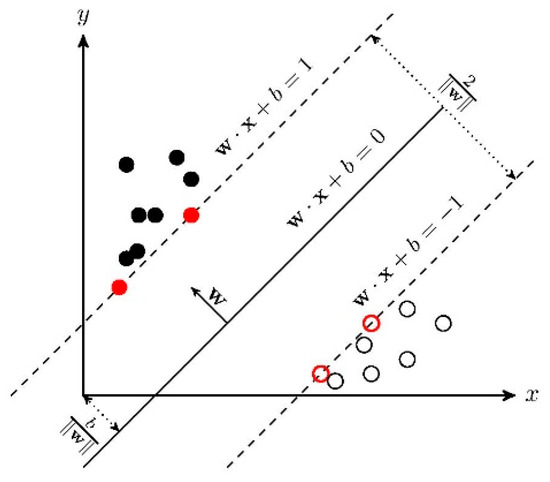
Figure 3.
Linear SVM.
In the face of the feature classification in HSIs, the problem is always nonlinear. Therefore, we should use some nonlinear feature transformation to map the sample information in the original input space to a high-dimensional feature space, and then find the optimal classification surface in the new space. The objective function is:
where represents the spatial variation function, represents the relaxation factor, represents the regularization parameter. Facing different classification tasks, we need to construct different kernel functions. The RBF kernel function has the characteristic of unique best approximation. As a kernel function, RBF can map input samples to high-dimensional feature space in SVM. We use the RBF kernel function in the LIBSVM toolbox.
As a feature image can obtain one classification accuracy, we can get classification accuracies from different feature images. The decision fusion algorithm is used to improve classification accuracy. We leverage the majority voting-based decision fusion strategy due to its insensitivity to inaccurate estimates of posterior probabilities, the majority vote is given by [44]:
where is the indicator function, is the class label from one of the possible classes for the test pixel, is the classifier index, is the number of classifiers, is the number of times class was detected in the bank of classifiers, and denotes the voting strength of the -th classifier. In our method, we use the equal voting strength, .
The detailed procedure for the LRS-HRFMSuperPCA classification is described in Algorithm 1.
| Algorithm 1 LRS-HRFMSuperPCA |
| Inputs: Insert original HSI , is the minimum spectral value of all bands traversed; |
| Step 1 Noise prediction of HSI |
| (1) , ; |
| (2) ,; |
| (3) for :=1 to do |
| (4) ; |
| (5) |
| (6) end for |
| (7) Output ; |
| Step 2 Subspace prediction of HSI |
| (1) , , ; |
| (2) Calculate the eigenvector of , ; |
| (3) Construction setting item ,, ; |
| (4) Set , ; by ascending order, save the permutation ; |
| (5) number of terms , find subspace prediction |
| Step 3 HSI restoration and denoising |
| (1) Let the mask acting on the unobserved pixel and HSI affected by noise; |
| (2) The correlation coefficient of the subspace is calculated by ; |
| (3) Determine the fully observed HSI ; |
| (4) Solve the optimal value problem of based on the BM3D algorithm; the denoised HSI is obtained by ; |
| Step 4 Dimension reduction algorithm based on multi-scale superpixels segmentation |
| (1) Insert scale number , ; Input initial number of pixels ; |
| (2) Let , ;; |
| (3) for to do |
| (4) ; |
| (5) end for |
| (6) for to do |
| (7) |
| (8) end for |
| (9) Output |
| Step 5 Decision fusion classification algorithm based on hierarchical recursive filtering |
| (1) for =1 to do |
| (2) |
| (3) end for |
| (4) |
| (5) |
4. Experiment and Analysis
4.1. Experimental Datasets
Indian Pines is a pixel HSI collected by the AVIRIS hyperspectral spectrometer sensor at the Indiana agricultural test site. It contains 220 bands of 16 types of ground objects, and 20 bands with noise removed. The remaining 200 bands are utilized as the experimental dataset, and the total number of labeled pixels is 10,249, Figure 4 shows Indian Pines’ ground true value map, specific species and false color map.

Figure 4.
(a) Indian Pines ground truth; (b) Indian Pines land-cover category; (c) Indian Pines false-color image.
PaviaU is a pixel HSI collected by the ROSIS hyperspectral spectrometer sensor over Pavia University. A total of 115 bands of 9 types of ground objects are included, and 12 bands with noise are eliminated. The remaining 103 bands are utilized as the experimental dataset, and the total number of labeled pixels is 42,776, Figure 5 shows PaviaU’s ground value map, specific species and false color map.
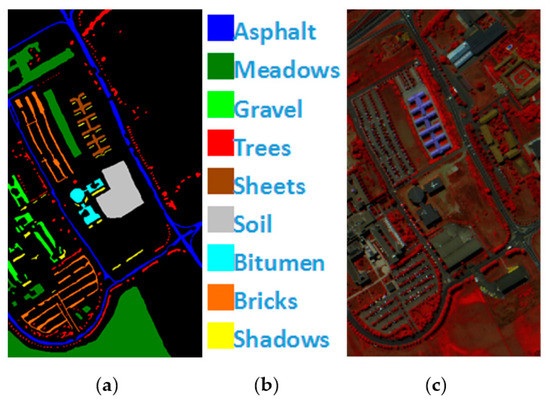
Figure 5.
(a) PaviaU ground truth; (b) PaviaU land-cover category; (c) PaviaU false-color image.
Salinas Scene is a pixel HSI collected by the AVIRIS hyperspectral spectrometer sensor over the Salinas Valley, California. A total of 224 bands of 16 types of ground objects are included, and 20 bands with noise are eliminated. The remaining 204 bands are employed as the experimental dataset, Figure 6 shows Salinas’ ground value map, specific species and false color map. The total number of labeled pixels is 54,129, Table 1 shows Number of samples in the Indian Pines, PaviaU, and Salinas.
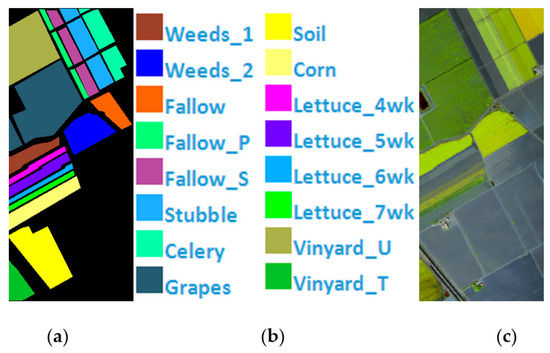
Figure 6.
(a) Salinas ground truth; (b) Salinas land-cover category; (c) Salinas false-color image.

Table 1.
Number of samples in the Indian Pines, PaviaU, and Salinas.
4.2. Parameter Analysis
The commonly used HSI classification performance indicators are as follows: OA, AA and Kappa coefficient. Taking the hyperspectral dataset with kinds of surface features as an example, by comparing the classification results with the real surface feature distribution data, the confusion matrix is obtained, in the matrix, represents the number of samples that belong to class and are divided into class . Therefore, the diagonal element in the confusion matrix represents the number of correctly classified samples in each feature category. Next, each evaluation index can be calculated separately.
OA: It refers to the proportion of all correctly classified samples in the total number of samples in the hyperspectral dataset. The calculation formula is:
AA: According to the OA, the AA is:
Kappa coefficient: In order to make full use of the information of the confusion matrix to measure the consistency between the classification results and the real surface features distribution map, researchers put forward the concept of Kappa, which is defined as follows:
where, . It represents the total number of samples in the hyperspectral dataset. There are three types of parameters in our paper.
4.2.1. Scale Number and Initial Superpixel Number
As seen in Figure 7, when is 0, the model degenerates to a single-scale superpixel dimension reduction. As a result, it is unable to make full use of the spatial information of multiple images, leading to the decline of classification accuracy. When the value is too large, an over-segmentation will occur. Hence, a single-pixel block is obtained not being visible and the correct label cannot be identified. As shown in Figure 7a, when is 7, OA will be maximized on the Indian Pines. Figure 7b reveals that, when is 10, the maximum value is obtained on PaviaU, since the datasets with complex structures and textures and large sizes need to be segmented into more hyper pixels (for instance, PaviaU). Fewer hyper pixels are segmented when the dataset size is smaller (for example, the Indian Pines).
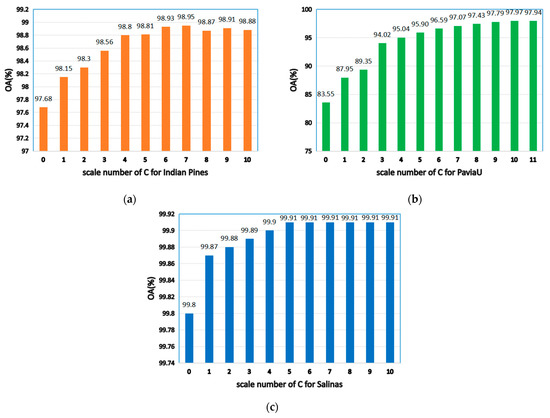
Figure 7.
The effects of different scales on classification accuracy of HSIs; (a) Indian Pines; (b) PaviaU; (c) Salinas.
For the number of initial superpixels , according to Figure 8, the trend of classification accuracy for the three datasets increases first and then decreases with increasing number of initial hyperpixels. Too few or too many initial superpixels will lead to poor classification accuracy. The reason is that when the initial number of superpixel blocks is too small, the number of superpixel blocks calculated for each image in the scale is also small, and the pixel blocks contain various ground objects, which cannot make full use of the spectral characteristics of different species. When the number of superpixels is too large, a single-pixel block will be smaller, and a single-pixel block will contain fewer pixels and will not be able to utilize all samples belonging to a uniform area. As seen in Figure 8, when is 40, the maximum OA can be obtained for the three datasets. This indicates that hyperpixel segmentation of the reduced-dimension image can capture the spatial structure of the HSI and improve the OA of the subsequent process.
Figure 8.
The effects of superpixels on classification accuracy of HSIs; (a) Indian Pines; (b) PaviaU; (c) Salinas.
4.2.2. The Spatial and Range Standard Deviations of the Filter
As seen in Figure 9, on the Indian Pines, when is 30 and is 0.8, the method can obtain the optimal classification accuracy. This will not be repeated for the Salinas and PaviaU. For the recursive layer number , when the recursion level is 0, the LRS-HRFMSuperPCA method degenerates to the LRS-MSuperPCA method leading to the failure to guarantee similar eigenvalues for the adjacent pixels on the same side of the edge and the classification accuracy is minimum, when the recursion level is 1, the fine texture structure cannot be completely eliminated by single-layer recursive filtering. Hence, it eliminates the fine texture structure and preserves the edges. This can be inferred from the SuperPCA part in schematic Figure 1. According to Figure 9, Figure 10 and Figure 11, it is indicated that the proposed HDTRF can enhance the classification accuracy of HSI.
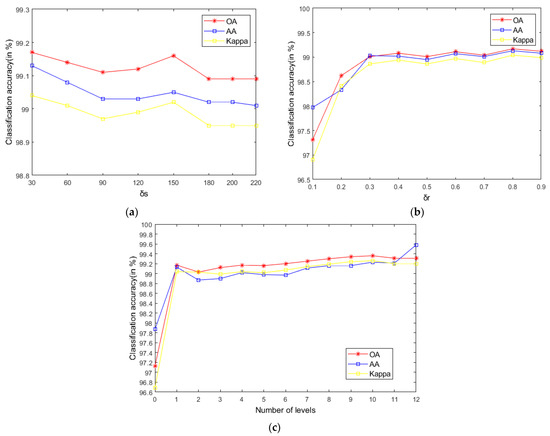
Figure 9.
The influence of , and on the OA of Indian Pines. (a); (b); (c).
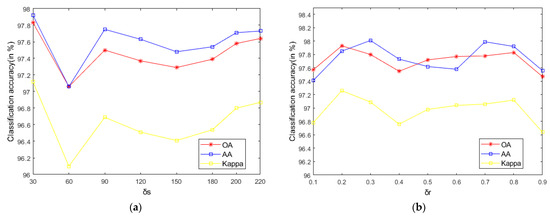
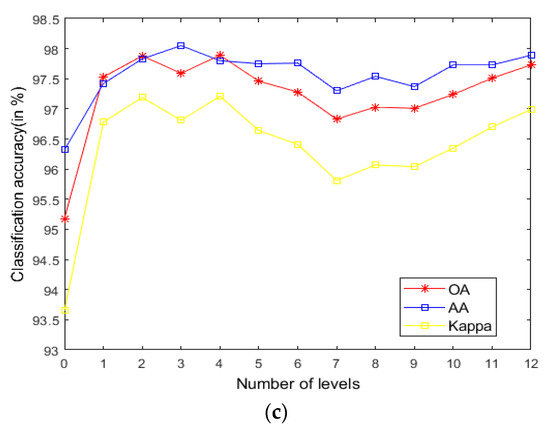
Figure 10.
The influence of , and on the OA of PaviaU. (a); (b); (c).
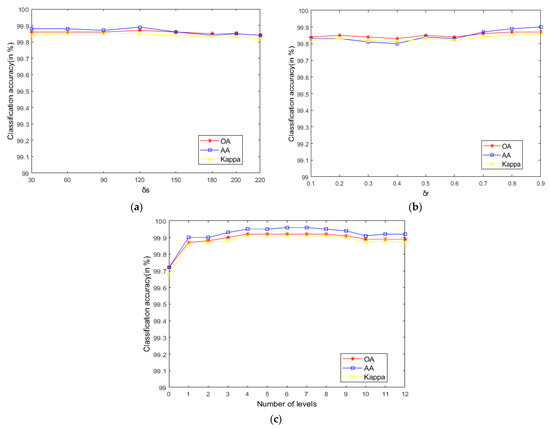
Figure 11.
The influence of and on the OA of Salinas. (a); (b); (c).
4.2.3. Kernel Function Parameter and Regularization Parameter in SVM
The SVM classifier used in the LRS-HRFMSuperPCA technique utilizes the LIBSVM toolbox in MATLAB. Moreover, the comparison algorithm of the SVM classifier also uses the LIBSVM toolbox in MATLAB containing the kernel parameter gamma and regularization parameter . Figure 12 and Figure 13 represent the effect of different kernel parameters and regularization parameter on classification accuracy in three datasets, respectively. It is observed that for the three datasets, the maximum classification accuracy can be achieved when the kernel parameter is 300, 40 and 400, respectively, and the different regularization parameter is set to 106, 106 and 108. In our classifier, a higher gamma value leads to a higher dimension of the mapping, and the training result is better. We choose the higher , as the higher aims to classify all training samples correctly by giving the model the freedom to choose more samples as support vectors. Since the Salinas training sample is larger than the Indian Pines and PaviaU, we can see that the value of will increase with the increase of training set samples.
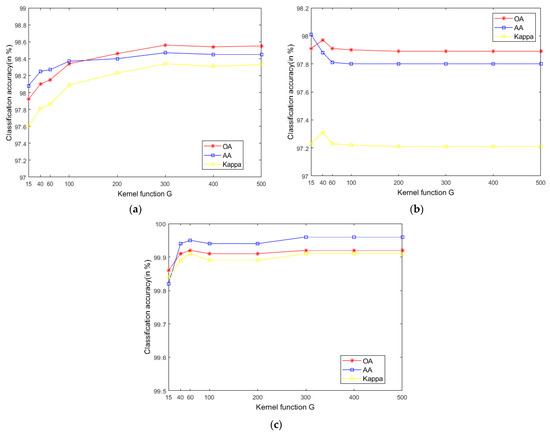
Figure 12.
The effect of the different kernel function in SVM on classification accuracy; (a) Indian Pines; (b) PaviaU; (c) Salinas.
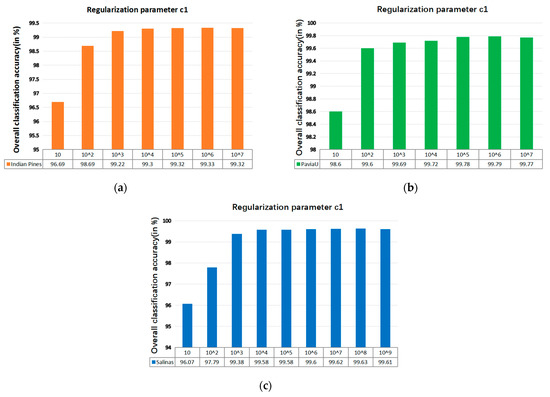
Figure 13.
The effect of the different regularization parameter in SVM on OA; (a) Indian Pines; (b) PaviaU; (c) Salinas.
The experimental parameter settings of the LRS-HRFMSuperPCA method in subsequent experiments are shown in Table 2.
Table 2.
The experimental parameters settings in LRS-HRFMSuperPCA.
4.3. Experimental Results and Analysis
The HSI restored by the transform domain filtering algorithm based on low-rank sparse representation is better than the original image. In our paper, the peak-signal-to-noise ratio (PSNR) was utilized to compare the quality of the denoised HSI and the original HSI, as follows:
where is the maximum value of the color of the image point, represents the mean square error between two monochromatic images and of m∗n size. In our method, the original HSI with additive Gaussian noise with a noise variance of 0.01 is used as the reference image to determine the PSNR. In the experiment, the original HSI and the denoised HSI obtained by low-rank sparse representation are considered as the processed images. Figure 14 represents the PSNR values of all bands of the original HSI and the HSI denoised by low-rank sparse representation on the Indian Pines. Table 3 denotes the average PSNR values of all bands of the two HSIs after summation.
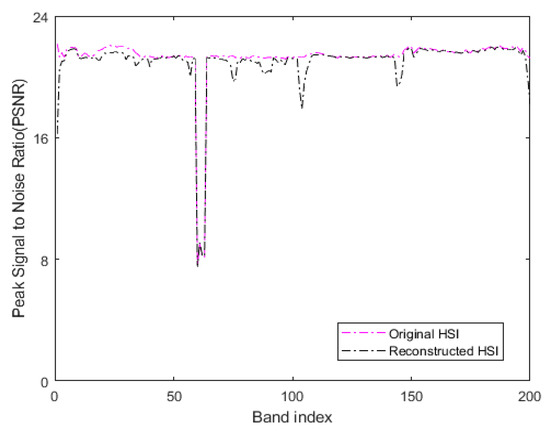
Figure 14.
The PSNR values of all bands of original HSI and denoised reconstructed HSI on the Indian Pines.
Table 3.
The average PSNR of the original Indian Pines and the reconstructed Indian Pines in all bands and the OA of the LRS-HRFMSuperPCA method and HRFMSuperPCA method are compared.
When comparing the PSNR values, the reference image used in our method is a noisy HSI with additive Gaussian noise. Thus, the greater the MSE between the processed image and the reference image, the greater the difference between the processed image and the reference image. Moreover, the smaller the corresponding PSNR value, in our method, the smaller the difference between the processed image and the reference image damaged by additive noise. The larger corresponding PSNR value indicates that the quality of the processed image is poor. As seen in Figure 14, the PSNR values of the reconstructed HSI obtained by our method are lower compared to the original HSI in all bands. The third row of Table 3 reveals that the OA of the LRS-HRFMSuperPCA is better than that of the HRFMSuperPCA without low-rank sparse representation denoising on the 10% training set. Therefore, the transform domain filtering denoising algorithm based on low-rank sparse representation of HSI can enhance the quality of the original HSI and improve the OA.
The LRS-HRFMSuperPCA is compared with several HSI classification models, including original classification algorithm, SVM, PCA and the recently proposed IFRF [26], CCJSR [27], MSuperPCA [35], SSRN [30], KNNRS [36] and GhoMR [33]. To avoid the chance of the experimental results, the average value of five runs is considered as the final result, including our algorithm and all other comparison algorithms. At the same time, for a fair comparison, the parameters of the comparison algorithm are set as the default optimal parameters based on the relevant literature. Table 4 represents the specific experimental parameters of the comparison algorithm. The experimental environment of the LRS-HRFMSuperPCA method and other comparative algorithms is a notebook with 12 GB memory, Intel Core i5 2.2 GHz CPU and the development environment in MATLAB R2018a is used. GhoMR and SSRN are performed utilizing PyTorch 1.6.0 with CUDA 10.1 in the open-source GPU environment of Google Colaboratory. The code for the LRS-HRFMSuperPCA is available at https://gitee.com/lxxds123/my-dem (accessed on 25 April 2021).
Table 4.
The application of experimental parameters in the comparison algorithm.
In order to fully compare with the training set in the references corresponding to the comparison algorithm, the contrast experiments are carried out on the training set which accounts for = 77 (10% Training set) and = 173 (20% Training set) for per class on Indian Pines and = 475 (10% Training set) and = 1139 (20% Training set) for PaviaU, = 102 (3% Training set) and = 170 (5% Training set) on Salinas, leaving the rest samples to form the testing samples. For 10% training data on Indian Pines and PaviaU, 3% training data on Salinas, from Table 5, our method obtains 99.32%, 99.87% and 99.73% OA values on the three datasets. For 20% training data on Indian Pines and PaviaU, 5% training data on Salinas, from Table 6, our method obtains 99.63%, 99.91% and 99.90% OA values on the three datasets.
Table 5.
The data distribution along with class-wise accuracies, OA, AA, Kappa on Indian Pines, PaviaU, and Salinas datasets, respectively, for randomly chosen 10% training data on Indian Pines and PaviaU, 3% training data on Salinas, leaving the rest samples to form the test set.
Table 6.
The data distribution along with class-wise accuracies, OA, AA, Kappa on Indian Pines, PaviaU, and Salinas datasets, respectively, for randomly chosen 20% training data on Indian Pines and PaviaU, 5% training data on Salinas, leaving the rest samples to form the test set.
To compare 10%, 20%, 3% and 5% of the total randomly selected training samples, the eight advanced comparison algorithms in Table 4 and the LRS-HRFMSuperPCA method are used. In this section, only the comparison results on the Indian Pines are discussed. Table 7 shows that, when the training set is 10%, the OA of our method is improved by 17.65% and 20.27%, respectively, compared with the original SVM and PCA on the Indian Pines. Compared to the IFRF, according to Table 3, the low-rank sparse representation denoising algorithm can enhance the quality of the original HSI, thus improving the OA of 0.9% on 10% of the Indian Pines. Compared to the CCJSR, the OA of our method is enhanced by 3.32% and 2.78% over the two training sets on Indian Pines. In comparison to the MSuperPCA, when the training set is 20%, the OA of our method on the Indian Pines dataset is improved by 1.78%. The reason is that our method combines the spatial domain filtering algorithm and the transform domain filtering algorithm. The mixed noise can be removed by the transform domain filtering denoising algorithm based on low-rank sparse representation within the original HSI. At the same time, the small-scale structure of the HSI can be eliminated by the multi-level spatial domain recursive filtering algorithm fully obtaining the spatial-spectral joint information of the HSI and improving the OA. Compared to KNNRS, the OA of our method is always higher than that of the LRS-HRFMSuperPCA on the three datasets (from Table 7 and Table 8). Compared to GhoMR, the single projection space constructed by the GhoMR makes it impossible to make full use of the spectral features of different species. Our method can randomly control the scale of multi-scale superpixel segmentation, and each obtained superpixel block is a set of pixels with similar characteristics. Subsequently, a hierarchical recursive filtering algorithm is used to extract the spatial-spectral joint information in each pixel block region to improve the consistency and similarity within the region. At the same time, our method runs in a non-GPU environment. Compared to the GhoMR running on GPU, we use CPU to reduce the experimental equipment cost.
Table 7.
OA, AA, and Kappa using the LRS-HRFMSuperPCA and other state-of-the-art methods on 10% and 20% randomly chosen training samples.
Table 8.
OA, AA, and Kappa using the LRS-HRFMSuperPCA and other state-of-the-art methods on 3% and 5% randomly chosen training samples on Salinas.
Figure 15, Figure 16 and Figure 17 represent the random feature classification map obtained by our method and different comparison algorithms and the OA of the corresponding feature classification map. As seen in Figure 15, the OA of the SVM and PCA is not ideal since they do not combine the joint information of spatial-spectrum, and the “salt and pepper” noise phenomenon appears in the classification result graph. In contrast, IFRF and KNNRS combined with the spatial-spectrum can effectively eliminate the noise pixels, and the “salt and pepper” noise phenomenon is greatly reduced. Compared to PCA and SVM, the OA of IFRF is improved by 18.33% and 15.92%, respectively, and that of KNNRS is improved by 17.3% and 19.6%, respectively. According to the surface features classification map of Indian Pines, the OA of our method is 1.43%, 2.47%, and 0.16% higher than that of IFRF, CCJSR, and KNNRS. Compared to the advanced MSuperPCA, SSRN and GhoMR algorithms, the OA of our algorithm on the Indian Pines is improved by 1.58%, 0.61% and 0.68%, respectively. Improvements or comparable results are obtained on PaviaU and Salinas as well that are not repeated here.
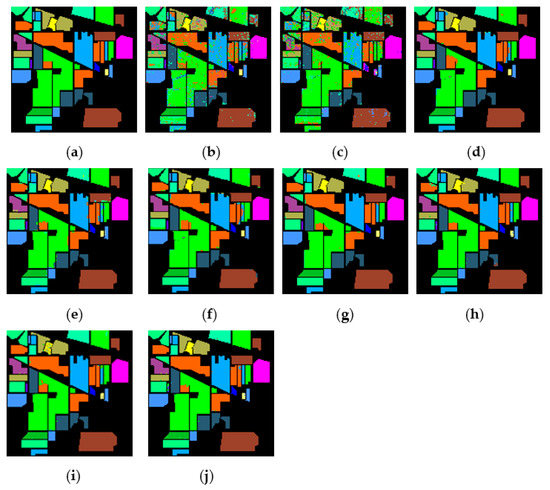
Figure 15.
The classification maps obtained by different methods on the Indian Pines when training samples account for 10% of the reference. (a) GroundT. (b) SVM (OA = 81.99%). (c) PCA (OA = 79.58%). (d) IFRF (OA = 97.91%). (e) CCJSR (OA = 96.87%). (f) MSuperPCA (OA = 97.76%). (g) SSRN (OA = 98.73%). (h) KNNRS (OA = 99.18%). (i) GhoMR (OA = 98.66%). (j) LRS-HRFMSuperPCA (OA = 99.34%).

Figure 16.
The classification maps obtained by different methods on the PaviaU when training samples account for 10% of the reference. (a) GroundT. (b) SVM (OA = 94.17%). (c) PCA (OA = 90.50%). (d) IFRF (OA = 99.21%). (e) CCJSR (OA = 93.73%). (f) MSuperPCA (OA = 99.40%). (g) SSRN (OA = 99.47%). (h) KNNRS (OA = 99.45%). (i) GhoMR (OA = 99.54%). (j) LRS-HRFMSuperPCA (OA = 99.88%).

Figure 17.
The classification maps obtained by different methods on the Salinas dataset when training samples account for 3% of the reference. (a) GroundT. (b) SVM (OA = 93.05%). (c) PCA (OA = 92.94%). (d) IFRF (OA = 99.42%). (e) CCJSR (OA = 95.37%). (f) MSuperPCA (OA = 99.53%). (g) SSRN (OA = 99.34%). (h) KNNRS (OA = 99.68%). (i) GhoMR (OA = 99.30%). (j) LRS-HRFMSuperPCA (OA = 99.78%).
This section analyzes the effects of various training and test sets on the OA of our method and the other methods. Figure 18 represents the classification results of the LRS-HRFMSuperPCA method. The number of training samples of three datasets increased from 1% to 6%. According to Figure 18, with different training sample numbers, the OA can be improved significantly by our method by increasing the number of training samples. Hence, we can conclude that our method can achieve the best OA for the three datasets compared to other state-of-the-art comparison algorithms.
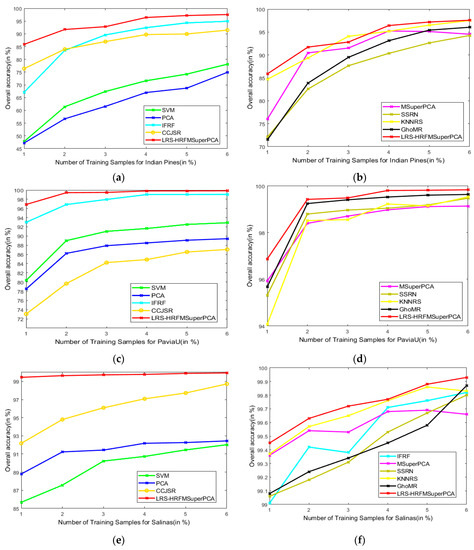
Figure 18.
OA of the proposed LRS-HRFMSuperPCA method with different numbers of training samples on different images. (a,b) Indian Pines; (c,d) PaviaU; (e,f) Salinas.
The computational time of the LRS-HRFMSuperPCA algorithm and other comparison algorithms are represented in Table 9. The running environment of the LRS-HRFMSuperPCA and all the comparison algorithms is a notebook computer with 12 GB memory and a 2.2 GHz CPU processor. Except for GhoMR and SSRN, the running environment of GhoMR and SSRN are pytorch 1.6.0 and CUDA10.1 in the open-source GPU environment of Google lab, the running environment of other algorithms is MATLAB2018a. Table 8 shows the number of training samples as a percentage of the total sample number in the measurement run time to experiment on the three datasets. According to the analysis of Table 9, the LRS-HRFMSuperPCA algorithm takes a long time on the Indian Pines. The main reason is that this technique utilizes multi-level domain transform recursive filtering and multi-scale superpixel segmentation. As seen in Figure 18a,b, under different training sets of Indian Pines, the OA of our method is enhanced compared to other comparison algorithms. On the PaviaU and Salinas, the CCJSR took the most time since the computation of the correlation coefficient of the training set increased by increasing the training set, followed by the KNNRS. The main computation of the KNNRS is caused by the operation of KNNs. The operation time of the MSuperPCA is mainly caused by multiscale hyperpixel segmentation of HSIs. The run time of our method on the PaviaU is lower compared to the KNNRS, MSuperPCA, and CCJSR. The OA index of this method is also improved compared to other algorithms on PaviaU, for the GhoMR. Although the time cost of our algorithm on Indian Pines and PaviaU is higher than that of the GhoMR, the classification accuracy of our algorithm is better than that of the GhoMR in various training sets. Moreover, the time cost on Salinas is lower than that of GhoMR. Thus, the experimental results show that the run time of LRS-HRFMSuperPCA is acceptable.
Table 9.
The computational time (in seconds) of different methods (10% training set).
5. Discussion
We reveal some interesting points about the LRS-HRFMSuperPCA methods by conducting several comparison experiments and parameter discussion on three HSIs.
- In general, we notice that the mixed noise in HSI will reduce the classification accuracy [9]. Considering the effects of imaging sensors breakdown, environmental pollution, and other factors, these degradation factors account for a small proportion in HSI. We usually build them as sparse noise models here. A clear natural image (specific to our article, it is a HSI) is often a low-rank structure; therefore, when dealing with the mixed noise problem of natural image, we usually use the low-rank sparse representation algorithm to solve it. In order to remove the small-scale textures in HSI, domain transform recursive filtering is used to solve this problem. Another knowledge base is that after the stable low-rank feature natural image (specific to our article, it is a HSI) is extracted (specific to our article, it is LRS-MSuperPCA in Section 3.1), the joint information of the spatial-spectrum of the feature image can be obtained by hierarchical filtering (specific to our article, it is HDTRF in Section 3.2). In order to facilitate understanding, we apply hierarchical recursive filtering to IFRF (Figure 19) for experimental verification.
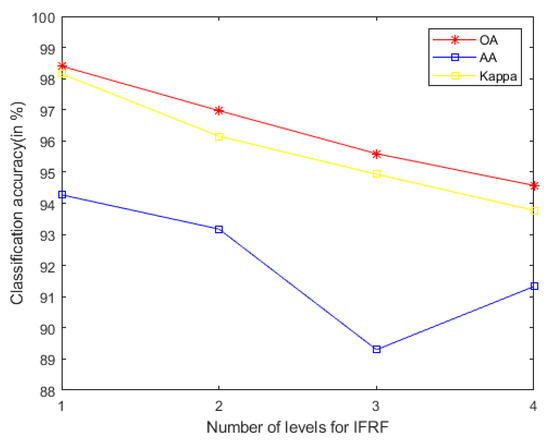 Figure 19. The accuracy of image fusion and recursive filtering algorithm (IF gets non-low-rank feature image) under adding the influence of hierarchical filtering on Indian Pines.
Figure 19. The accuracy of image fusion and recursive filtering algorithm (IF gets non-low-rank feature image) under adding the influence of hierarchical filtering on Indian Pines. - Based on the two knowledge bases proposed in the previous point, denoising based on low-rank sparse representation (let it set to function ) belongs to the transform domain filtering algorithm, while denoising based on hierarchical recursive filtering (let it set to function ) belongs to the spatial domain filtering algorithm. Let us set the penalty factor that controls the proportion between function and function , , the optimal filtering of the finding can be expressed as a function, which can be used for future research to find an optimal framework:
- According to the data in Table 7 and Table 8, LRS-HRFMSuperPCA is superior to the feature extraction algorithm using a single filter. Compared with IFRF and KNNRS, our method uses low-rank sparse representation algorithm to denoise the original HSI. It can be seen from Table 3 that the OA of LRS-HRFMSuperPCA is 0.23% higher than that of HRFMSuperPCA, and PSNR has also improved. This supports the correctness of LRS [17] that can remove mixed noise in the original HSI. Compared with LRS-MSuperPCA, the small-scale textures of the HSI can be eliminated by the multi-level spatial domain recursive filtering algorithm, fully obtaining the spatial-spectral joint information of the HSI and improving the OA. It can be seen from Figure 9c, Figure 10c and Figure 11c that the OA of LRS-HRFMSuperPCA is always higher than that of LRS-MSuperPCA on the three datasets. The comparative experiments verify that the DTRF [13] and IFRF [26] can remove texture structure and improve classification accuracy. These results support earlier studies.
- Our finding is a novel feature extraction framework with joint low-rank sparse representation-hierarchical domain transform recursive filtering. The framework agrees with the existence of mixed noise in the original HSI [9] and the spectral vectors live in a low-dimensional subspace [45]. The proposed framework is applied to HSI feature extraction (MSuperPCA), so the algorithm LRS-HRFMSuperPCA is obtained. As can be seen from Figure 1, we use hierarchical recursive filtering to extract features images from HSI. According to the experimental results in Table 7 and Table 8, it improves the OA, AA and Kappa. In the field of remote sensing science, there are two expectations for remote sensing image classification [46]: the first is feature mining, and the second is to design a classifier with high classification accuracy. Our LRS-HRFMSuperPCA algorithm achieves the two expectations.
- Compared with the HSI classification algorithm based on non-deep learning [26,27,35,36] and deep learning [30,33], the advantage of the LRS-HRFMSuperPCA algorithm is the use of the dual filtering framework. Specifically, compared with IFRF [26] and KNNRS [36] which only use spatial domain filtering, LRS-HRFMSuperPCA uses spatial-transform dual domain filtering, LRS-HRFMSuperPCA reconstructs the original HSI by recovering the pixels not observed in some known bands. We conduct an experiment to prove the anti- noise performance of the algorithm, in which 0-means additive Gaussian noise is added to the original HSI. According to Figure 20, with the increase of Gaussian noise intensity, our algorithm still maintains an OA of more than 98%, accounting for 10% of the Indian Pines samples on the training sets. Compared with CCJSR [27], which only uses a sparse representation, LRS-HRFMSuperPCA uses hierarchical domain transformation recursive filtering to make full use of spatial context information. Compared with SSRN [30] and GhoMR [33], the two space-spectrum joint classification algorithms based on deep learning use a single projection space. They cannot make full use of the low-dimensional characteristics of each species. Multi-scale superpixel segmentation can learn the low-dimensional features of different regions in HSIs by inputting the number of scales. At the same time, the architectures of SSRN [30] and GhoMR [33] need expensive GPU hardware to train and store. LRS-HRFMSuperPCA uses CPU to reduce the consumption of the experimental equipment. However, we find that most feature extraction algorithms (such as PCA in LRS-HRFMSuperPCA) can compress the information transformation of the original data into the low-dimensional feature space and this may lose the physical meaning of the original feature. In future research, we will suggest to focus on the method of unsupervised band selection algorithm instead of SuperPCA. Band selection selects a desired band subset from the original bands and preserves well the spectral meaning of spectral channels. In practice, prior knowledge about the surface features are difficult to obtain, so it is necessary to develop an unsupervised feature extraction algorithm. Specifically, for the reconstructed HSI with superpixels , hybrid scheme-based methods implement multiple schemes to select appropriate bands from . We can try to integrate both clustering and ranking based techniques to search for the best combination of bands with higher classification accuracy. Another major drawback of our method is that its performance is still affected by the number of superpixel segmentation and the shape of superpixel in our method is irregular. Specifically, once pixels of different classes exist in the same superpixel region, the pixels in these superpixels cannot be effectively classified. In future research, for different categories of pixels in the same superpixel, we will segment all kinds of pixels again, according to the weight of each pixel in the superpixel. The weight can be measured by relative entropy or Euclidean distance, etc. On the other hand, a gradient-based superpixel method has the advantage of regular shape and controllable number of generated superpixels, which is the direction to solve the problem of irregular shape of superpixels in the future.
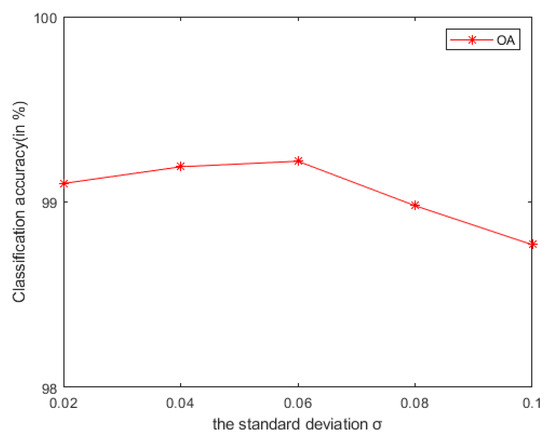 Figure 20. Under different additive Gaussian noise environments, the OA of LRS-HRFMSuperPCA algorithm.
Figure 20. Under different additive Gaussian noise environments, the OA of LRS-HRFMSuperPCA algorithm.
6. Conclusions
In this paper, a simple and effective HSI classification algorithm is proposed combining transform domain filtering and spatial domain filtering. The objective of our method is to combine the PCA based on multi-scale entropy rate superpixel dimension reduction within two types of joint filtering denoising framework. To remove the mixed noise in the original HSI, the denoising algorithm based on a low-rank sparse representation is used to denoise and restore the original HSI, improve the peak-signal-to-noise ratio of the original HSI, and the subsequent classification accuracy. A multi-scale entropy ratio-based superpixel segmentation algorithm is utilized to segment the repaired image. By dividing the whole HSI into several regions, the same superpixel block has similar reflection characteristics, which is convenient for subsequent dimension reduction processing and finding the low-dimensional features of the HSI. Secondly, hierarchical recursive filtering is applied to the feature images after SuperPCA is making full use of the spatial information contained in HSI. Experiments on three real HSIs reveal that the proposed LRS-HRFMSuperPCA algorithm enhances the classification accuracy compared with the original MSuperPCA algorithm and the recently proposed HSI classification algorithm. However, the disadvantage of the LRS-HRFMSuperPCA algorithm is that the parameters of the algorithm are manually selected, thereby reducing the operability of the algorithm. Therefore, in future research, we will focus on how to automatically determine the optimal parameters of our algorithm.
Author Contributions
All authors made significant contributions to the manuscript. X.L. and S.Q. put forward the idea; S.Q. and X.L. conceived and designed the experiments; S.Q. and X.L. presented tools and carried out the data analysis; X.L. and S.Q. wrote the paper. S.Q. and S.L. guided and revised the paper; S.Q. provided the funding; All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Henan science and technology development plan project (No. 212102210538), Postgraduate education innovation and quality improvement project of Henan University (No. SYL20040121).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Acknowledgments
The authors would like to sincere thank all the editors and anonymous reviewers gave valuable comments on our research.
Conflicts of Interest
The authors declare that there are no conflict of interest.
References
- Park, B.; Lu, R. Hyperspectral Imaging Technology in Food and Agriculture; Springer: Berlin, Germany, 2015. [Google Scholar]
- Pontius, J.; Martin, M.; Plourde, L.; Hallett, R. Ash decline assessment in emerald ash borer-infested regions: A test of tree-level, hyperspectral technologies. Remote Sens. Environ. 2008, 112, 2665–2676. [Google Scholar] [CrossRef]
- Ruitenbeek, F.; Debba, P.; Meer, F.; Cudahy, T.; Meijde, M.; Hale, M. Mapping white micas and their absorption wavelengths using hyperspectral band ratios. Remote Sens. Environ. 2006, 102, 211–222. [Google Scholar] [CrossRef]
- Majumdar, A.; Ansari, N.; Aggarwal, H.; Biyani, P. Impulse denoising for hyper-spectral images: A blind compressed sensing approach. Signal Process. 2016, 119, 136–141. [Google Scholar] [CrossRef][Green Version]
- Hu, X.; Gu, X.; Yu, T.; Zhang, Z.; Li, J.; Luan, H. Effects of aerosol optical thickness on the optical remote sensing imaging quality. Spectrosc. Spect. Anal. 2014, 34, 735–740. [Google Scholar]
- Acito, N.; Diani, M.; Corsini, G. Subspace-based striping noise reduction in hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2011, 49, 1325–1342. [Google Scholar] [CrossRef]
- Tu, B.; Zhou, C.; Peng, J.; He, W.; Ou, X.; Xu, Z. Kernel Entropy Component Analysis-Based Robust Hyperspectral Image Supervised Classification. Remote Sens. 2019, 11, 2823. [Google Scholar] [CrossRef]
- Xu, Y.; Wu, Z.; Wei, Z. Spectral–spatial classification of hyperspectral image based on low-rank decomposition. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2370–2380. [Google Scholar] [CrossRef]
- Rasti, B.; Ghamisi, P.; Chanussot, J. Mixed Noise Reduction in Hyperspectral Imagery. In Proceedings of the 2019 10th Workshop on Hyperspectral Imaging and Signal Processing: Evolution in Remote Sensing, Amsterdam, The Netherlands, 24–26 September 2019; pp. 1–4. [Google Scholar]
- Chen, Y.; Guo, Y.; Wang, Y.; Dong, W.; Chong, P.; He, G. Denoising of Hyperspectral Images Using Nonconvex Low Rank Matrix Approximation. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5366–5380. [Google Scholar] [CrossRef]
- Aggarwal, H.K.; Majumdar, A. Hyperspectral Unmixing in the Presence of Mixed Noise Using Joint-Sparsity and Total Variation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 4257–4266. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Guided Image Filtering. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1397–1409. [Google Scholar] [CrossRef]
- Palumbo, N.F.; Harrison, G.A.; Blauwkamp, R.A.; Marquart, J.K. Guidance filter fundamentals. Johns Hopkins APL Tech. Digest 2010, 29, 60–70. [Google Scholar]
- Deledalle, C.A.; Duval, V.; Salmon, J. Non-local methods with shape-adaptive patches (nlm-sap). J. Math. Imaging Vision 2012, 43, 103–120. [Google Scholar] [CrossRef]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image Denoising by Sparse 3-D Transform-Domain Collaborative Filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [CrossRef]
- Zhang, H.; He, W.; Zhang, L.; Shen, H.; Yuan, Q. Hyperspectral image restoration using low-rank matrix recovery. IEEE Trans. Geosci. Remote Sens. 2014, 52, 4729–4743. [Google Scholar] [CrossRef]
- Zhuang, L.; Bioucas-Dias, J.M. Fast Hyperspectral image Denoising based on low rank and sparse representations. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium, Beijing, China, 10–15 July 2016; pp. 1847–1850. [Google Scholar]
- Hughes, G. On the mean accuracy of statistical pattern recognizers. IEEE Trans. Inf. Theory 1968, 14, 55–63. [Google Scholar] [CrossRef]
- Sun, W.; Du, Q. Hyperspectral Band Selection: A Review. IEEE Geosci. Remote Sens. Mag. 2019, 7, 118–139. [Google Scholar] [CrossRef]
- Ribalta, L.P.; Tulczyjew, L.; Marcinkiewicz, M.; Nalepa, J. Hyperspectral band selection using attention-based convolutional neural networks. IEEE Access 2020, 8, 42384–42403. [Google Scholar] [CrossRef]
- Prasad, S.; Bruce, L.M. Limitations of Principal Components Analysis for Hyperspectral Target Recognition. IEEE Geosci. Remote Sens. Lett. 2008, 5, 625–629. [Google Scholar] [CrossRef]
- Slavkovikj, V.; Verstockt, S.; De, N.W.; Van, H.S. Unsupervised spectral sub-feature learning for hyperspectral image classification. Int. J. Remote Sens. 2016, 37, 309–326. [Google Scholar] [CrossRef]
- Wei, W.; Zhang, Y.; Tian, C. Latent subclass learning-based unsupervised ensemble feature extraction method for hyperspectral image classification. Remote Sens. Lett. 2015, 6, 257–266. [Google Scholar] [CrossRef]
- Bandos, T.V.; Bruzzone, L.; Camps, V.G. Classification of Hyperspectral Images with Regularized Linear Discriminant Analysis. IEEE Trans. Geosci. Remote Sens. 2009, 47, 862–873. [Google Scholar] [CrossRef]
- Li, W. Locality-Preserving Dimensionality Reduction and Classification for Hyperspectral Image Analysis. IEEE Trans. Geosci. Remote Sens. 2012, 50, 1185–1198. [Google Scholar] [CrossRef]
- Kang, X.; Li, S.; Benediktsson, J.A. Feature extraction of hyperspectral images with image fusion and recursive filtering. IEEE Trans. Geosci. Remote Sens. 2014, 52, 3742–3752. [Google Scholar] [CrossRef]
- Tu, B.; Zhang, X.; Kang, X.; Zhang, G.; Wang, J.; Wu, J. Hyperspectral Image Classification via Fusing Correlation Coefficient and Joint Sparse Representation. IEEE Geosci. Remote Sens. Lett. 2018, 15, 340–344. [Google Scholar] [CrossRef]
- Zheng, Q.; Yang, M.; Yang, J.; Zhang, Q.; Zhang, X. Improvement of Generalization Ability of Deep CNN via Implicit Regularization in Two-Stage Training Process. IEEE Access 2018, 6, 15844–15869. [Google Scholar] [CrossRef]
- Makantasis, K.; Karantzalos, K.; Doulamis, A.; Doulamis, N. Deep supervised learning for hyperspectral data classification through convolutional neural networks. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, IGARSS 2015, Milan, Italy, 26–31 July 2015; pp. 4959–4962. [Google Scholar]
- Zhong, Z.; Li, J.; Luo, Z.; Michael, C. Spectral–Spatial Residual Network for Hyperspectral Image Classification: A 3-D Deep Learning Framework. IEEE Trans. Geosci. Remote Sens. 2018, 56, 847–858. [Google Scholar] [CrossRef]
- Ma, X.; Geng, J.; Wang, H. Hyperspectral image classification via contextual deep learning. EURASIP J. Image Video Process. 2015, 20, 1–12. [Google Scholar] [CrossRef]
- Zhao, W.; Du, S. Spectral-Spatial Feature Extraction for Hyperspectral Image Classification: A Dimension Reduction and Deep Learning Approach. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4544–4554. [Google Scholar] [CrossRef]
- Das, A.; Saha, I.; Scherer, R. GhoMR: Multi-Receptive Lightweight Residual Modules for Hyperspectral Classification. Sensors 2020, 20, 6823. [Google Scholar] [CrossRef]
- Nalepa, J.; Myller, M.; Imai, Y.; Honda, K.I.; Takeda, T.; Antoniak, M. Unsupervised Segmentation of Hyperspectral Images Using 3-D Convolutional Autoencoders. IEEE Geosci. Remote Sens. Lett. 2019, 17, 1948–1952. [Google Scholar] [CrossRef]
- Jiang, J.; Ma, J.; Chen, C.; Wang, Z.; Cai, Z.; Wang, L. SuperPCA: A Superpixelwise PCA Approach for Unsupervised Feature Extraction of Hyperspectral Imagery. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4581–4593. [Google Scholar] [CrossRef]
- Tu, B.; Wang, J.; Kang, X.; Zhang, G.; Ou, X. KNN-Based representation of superpixels for hyperspectral image classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 4032–4047. [Google Scholar] [CrossRef]
- Roger, R.E.; Arnold, J.F. Reliably estimating the noise in AVIRIS hyperspectral images. Int. J. Remote Sens. 1996, 17, 1951–1962. [Google Scholar] [CrossRef]
- Chang, C.I.; Du, Q. Estimation of number of spectrally distinct signal sources in hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2004, 42, 608–619. [Google Scholar] [CrossRef]
- Kim, S.-J.; Koh, K.; Lustig, M.; Boyd, S.; Gorinevsky, D. An Interior-Point Method for Large-Scale -Regularized Least Squares. IEEE J. Sel. Top. Signal. Process. 2007, 1, 606–617. [Google Scholar] [CrossRef]
- Bioucas-Dias, J.M.; Nascimento, J.M.P. Hyperspectral subspace identification. IEEE Trans. Geosci. Remote Sens. 2008, 46, 2435–2445. [Google Scholar] [CrossRef]
- Liu, M.Y.; Tuzel, O.; Ramalingam, S.; Chellappa, R. Entropy rate superpixel segmentation. In Proceedings of the 24th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 2097–2104. [Google Scholar]
- Chen, Y.; Lin, Z.; Zhao, X.; Wang, G.; Gu, Y. Deep Learning-Based Classification of Hyperspectral Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 7, 2094–2107. [Google Scholar] [CrossRef]
- Zhou, Y.; Wei, Y. Learning Hierarchical Spectral-Spatial Features for Hyperspectral Image Classification. IEEE Trans. Cybern. 2017, 46, 1667–1678. [Google Scholar] [CrossRef]
- Prasad, S.; Bruce, L.M. Decision Fusion With Confidence-Based Weight Assignment for Hyperspectral Target Recognition. IEEE Trans. Geosci. Remote Sens. 2008, 46, 1448–1456. [Google Scholar] [CrossRef]
- Bioucas-Dias, J.M.; Plaza, A.; Dobigeon, N.; Parente, M.; Du, Q.; Gader, P.; Chanussot, J. Hyperspectral Unmixing Overview: Geometrical, Statistical, and Sparse Regression-Based Approaches. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 354–379. [Google Scholar] [CrossRef]
- Zhang, B. Advancement of hyperspectral image processing and information extraction. J. Remote Sens. 2016, 20, 1062–1090. [Google Scholar] [CrossRef]






















Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).