
Design and Characterization of an Asynchronous Fixed Priority Tree Arbiter for SPAD Array Readout

 , , , ,
, , , , {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
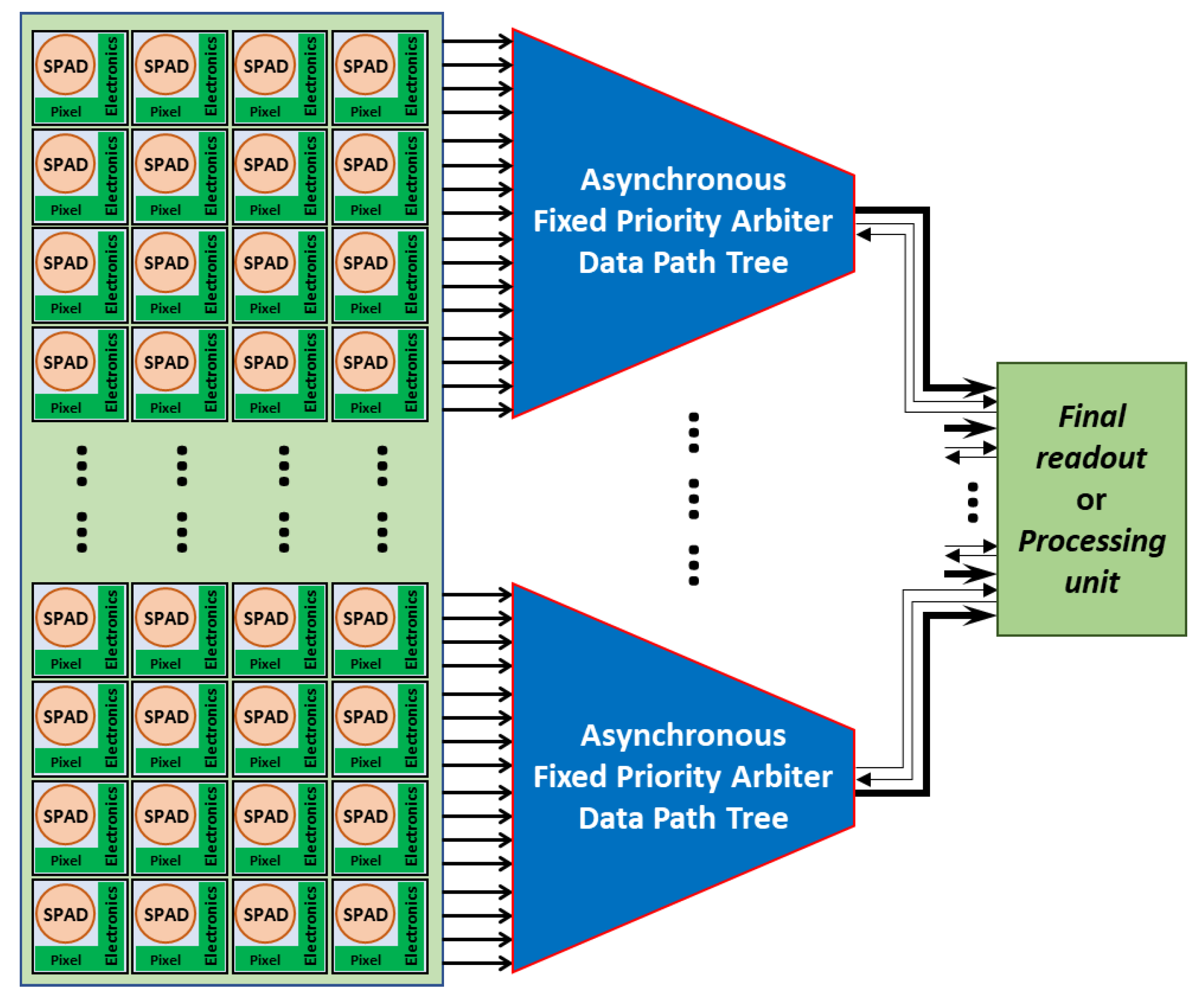
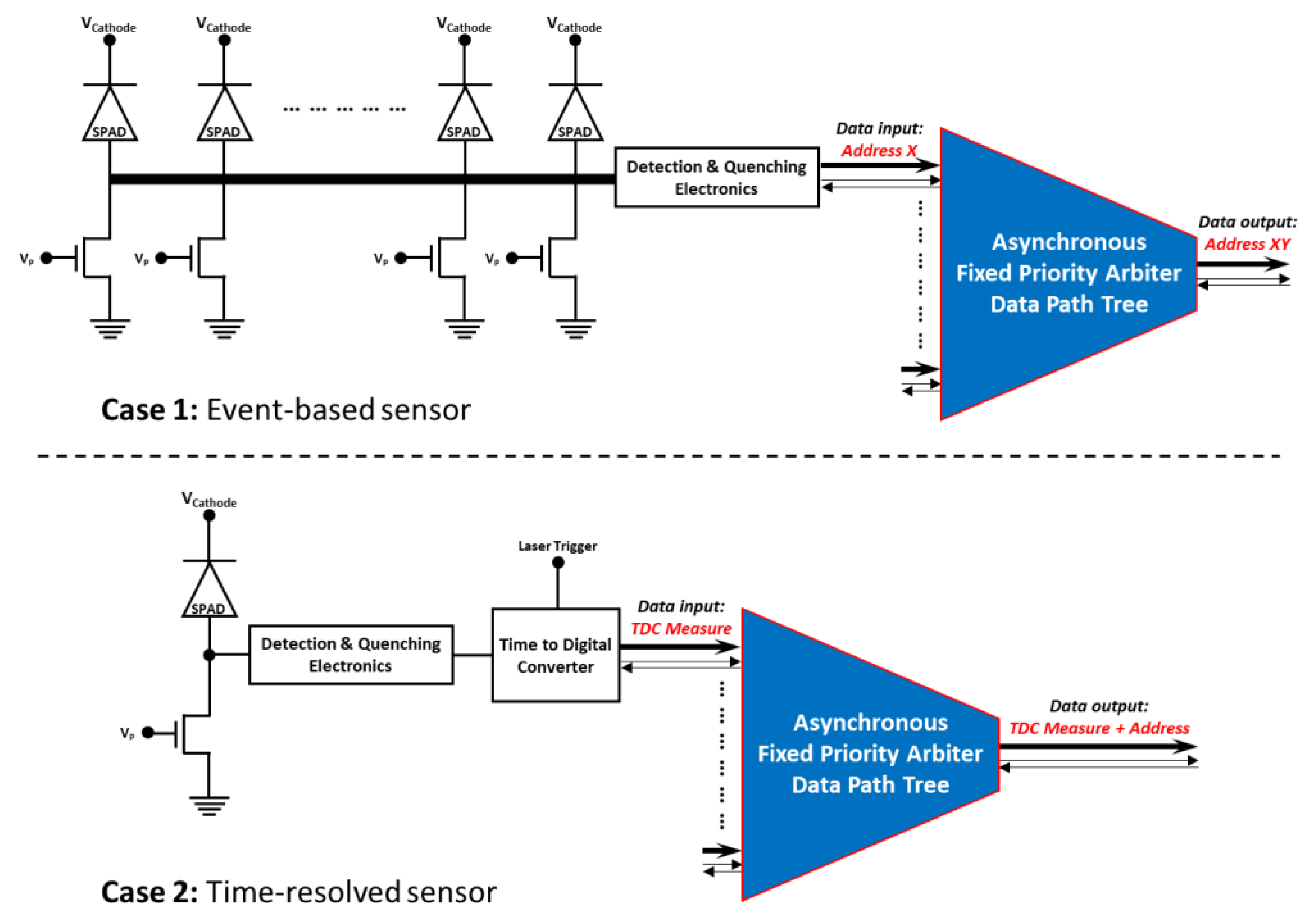
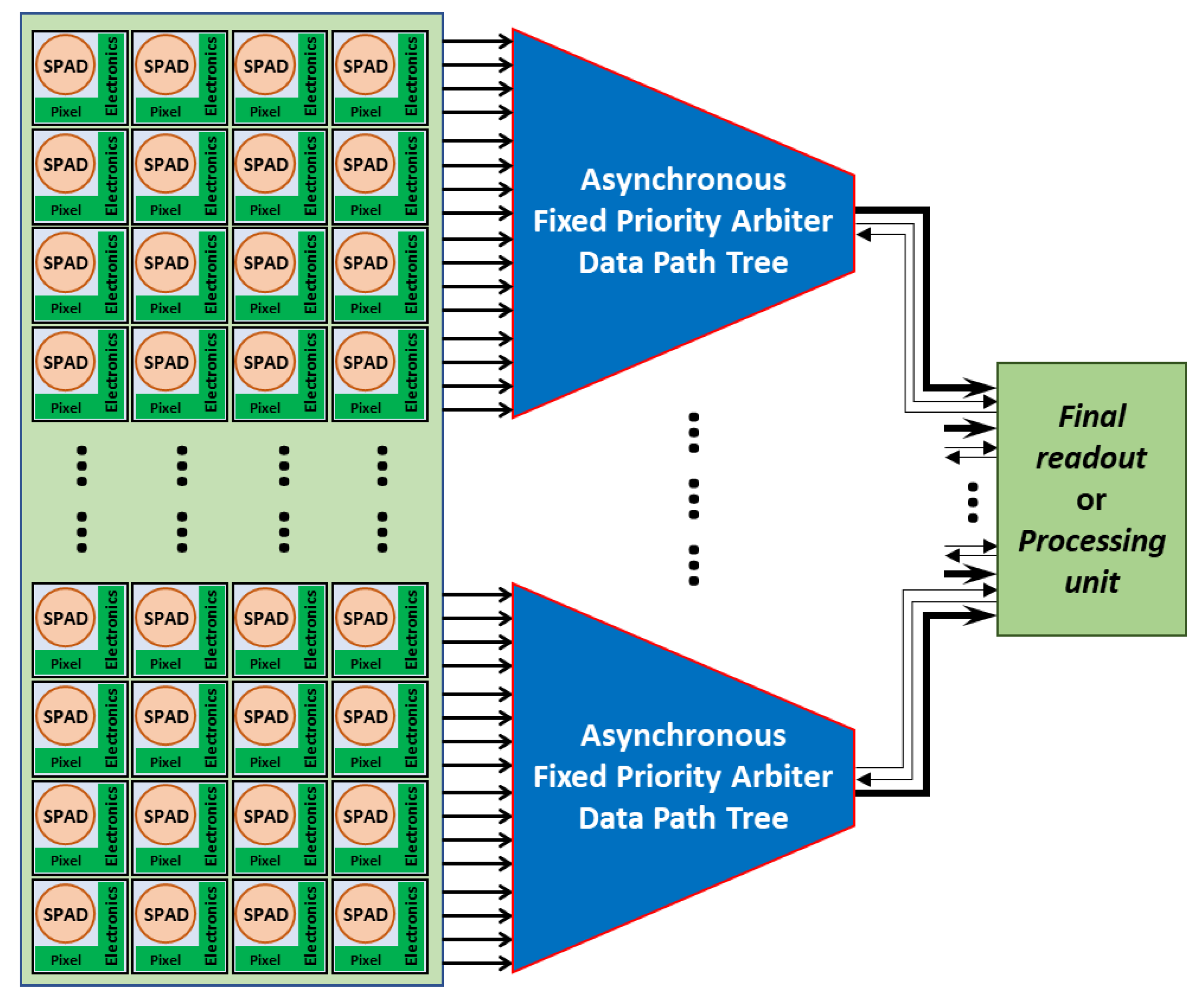
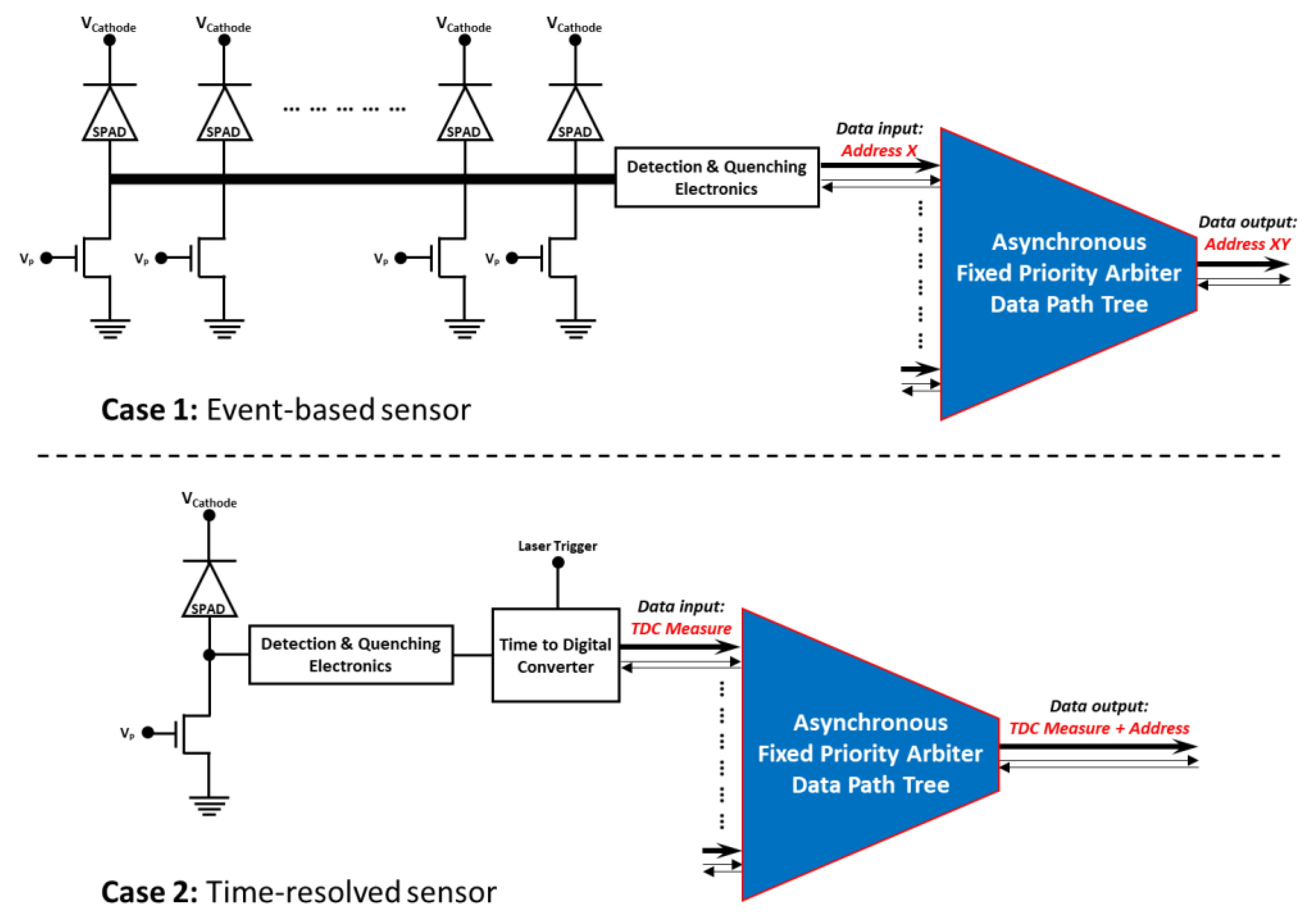
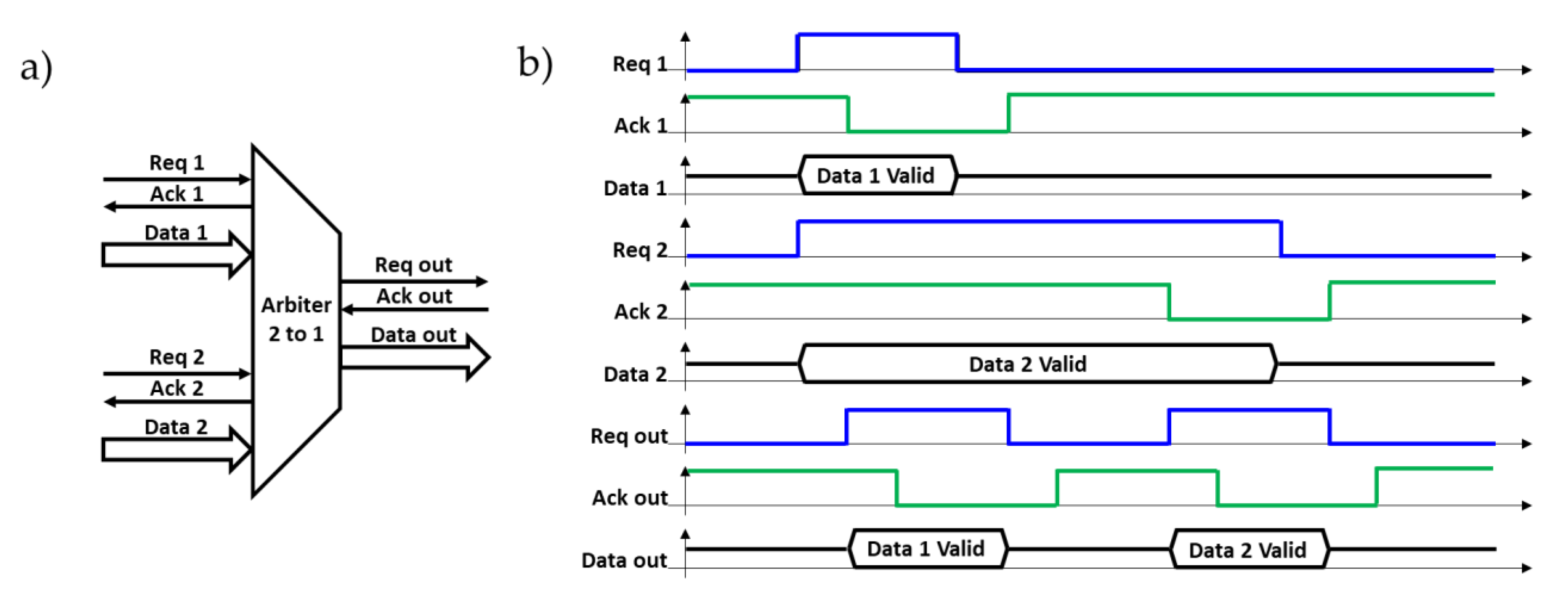
2. Asynchronous Priority-Based Arbiter Readout System
3. Asynchronous Logic Principle
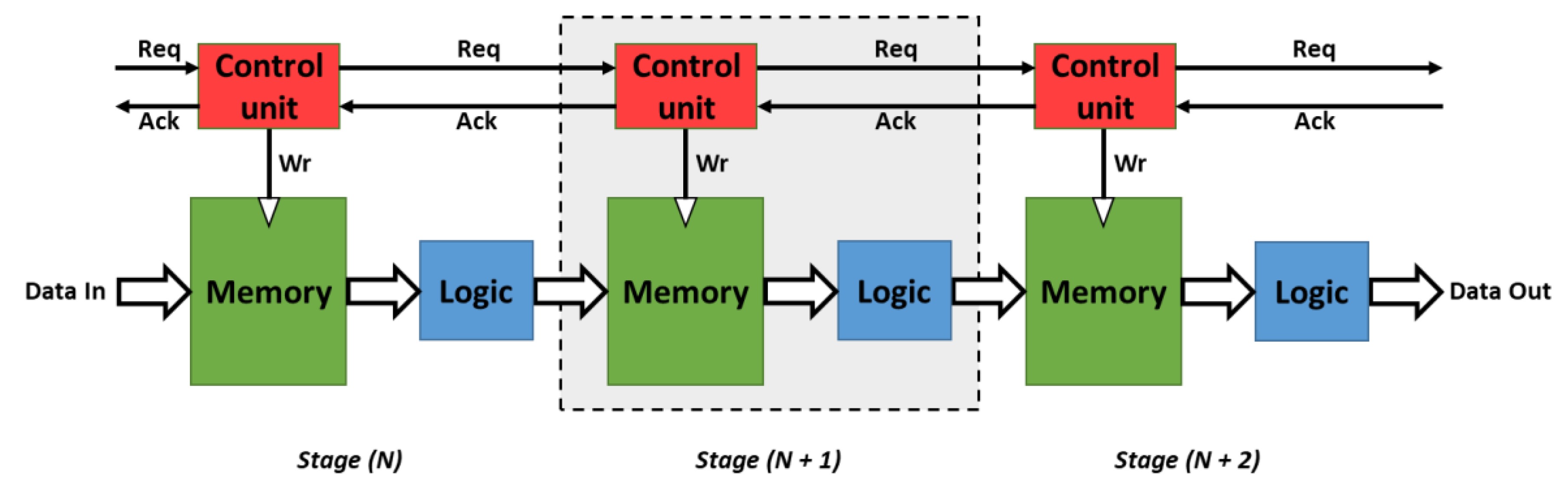
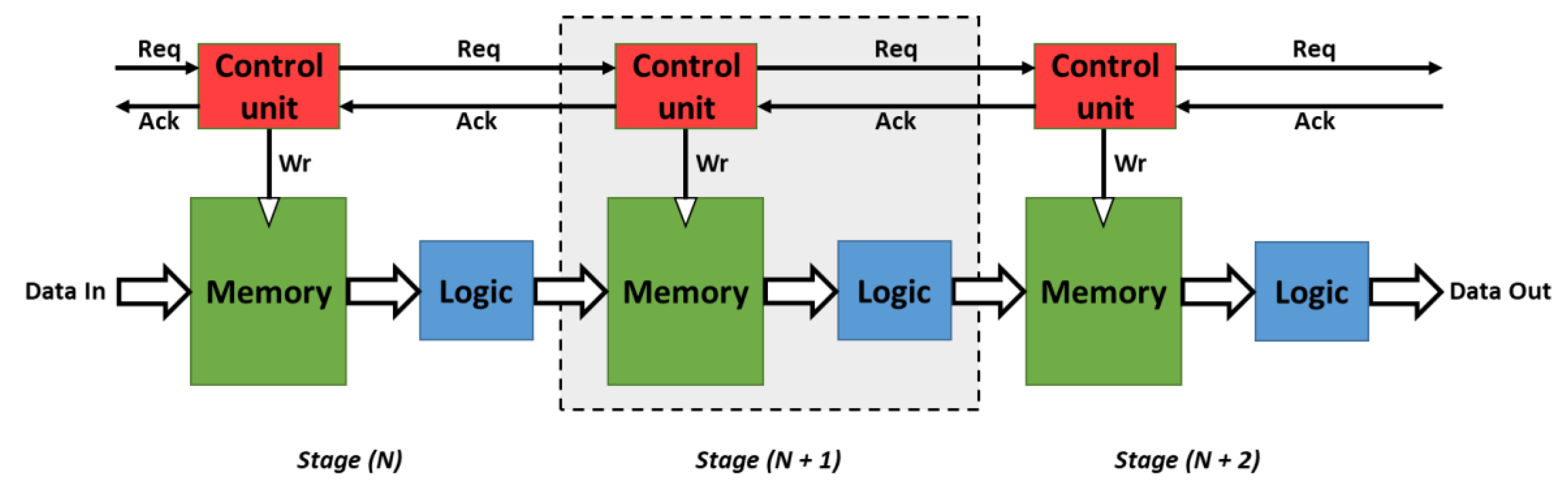
3.1. Micropipeline Circuit
3.2. Handshake Protocols and Data Encoding
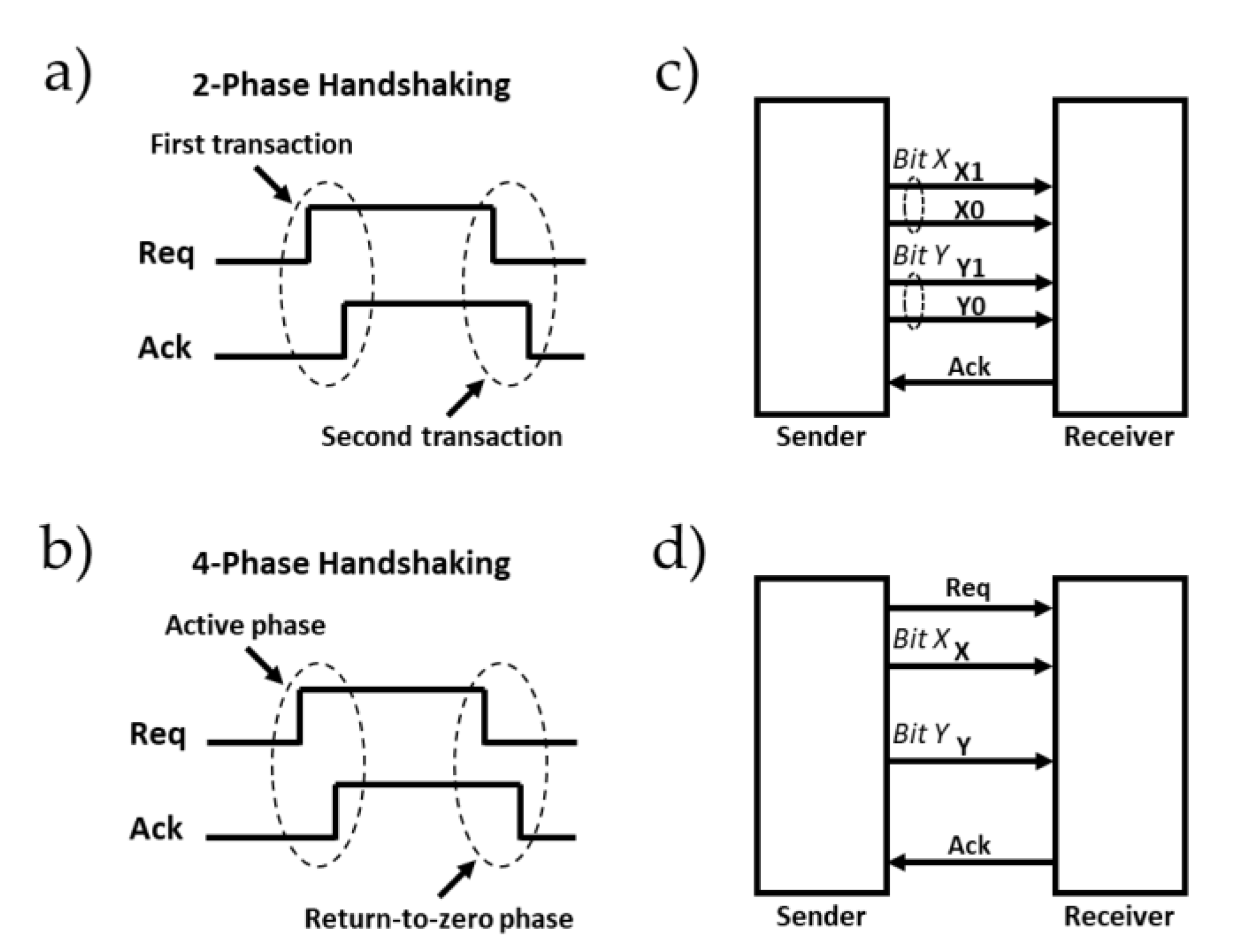
3.2.1. Handshaking Protocols
3.2.2. Data Encoding Schemes
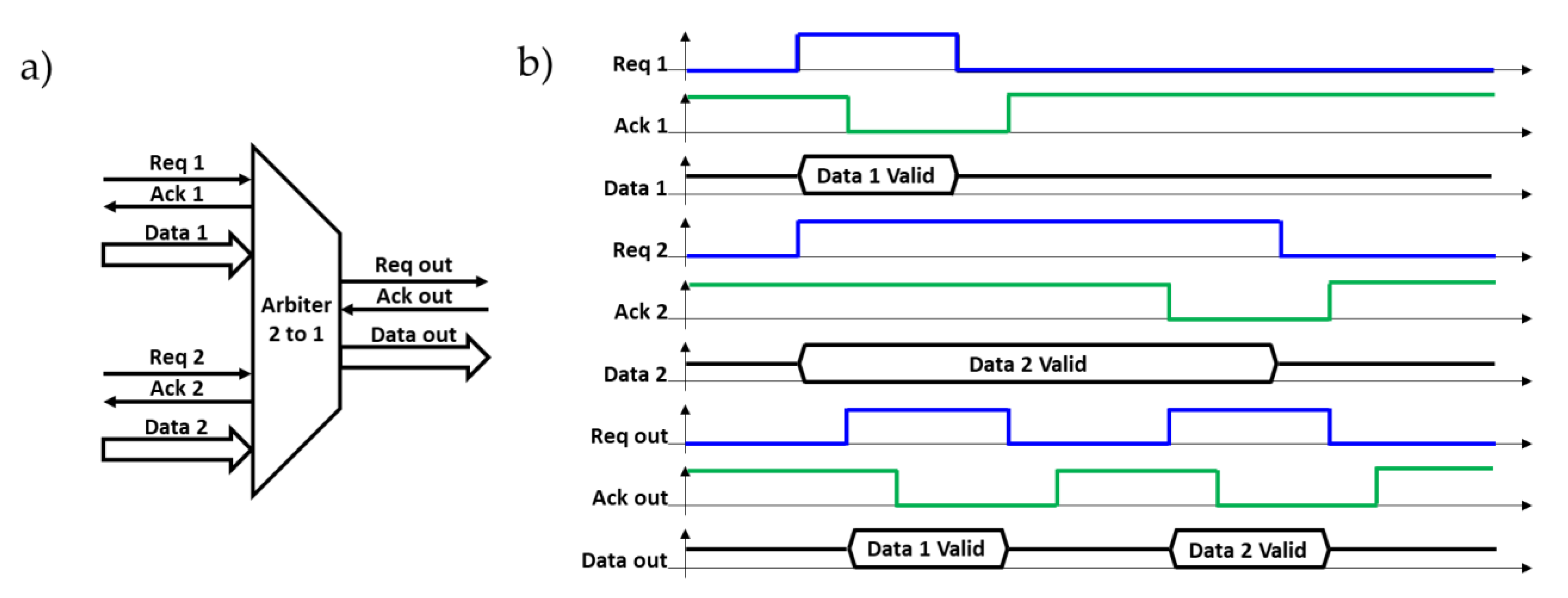
3.3. Fixed Priority Arbiter
4. Design of the Studied System
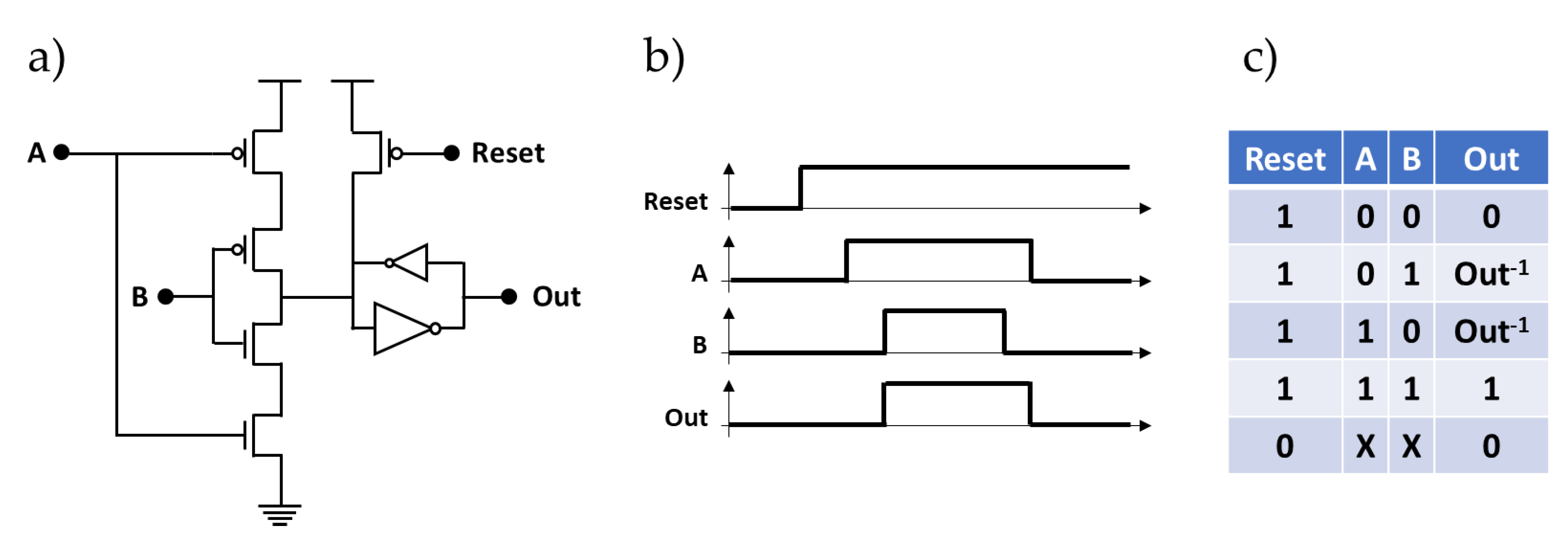
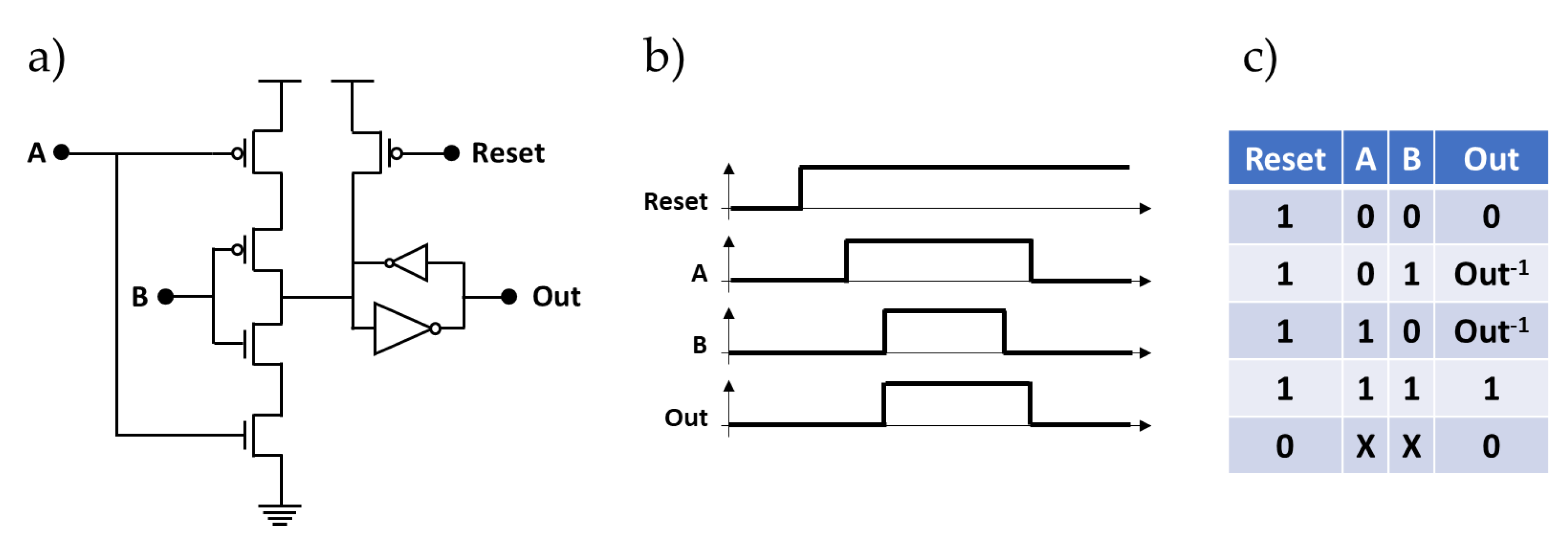
4.1. Muller C-Element (C-Muller)
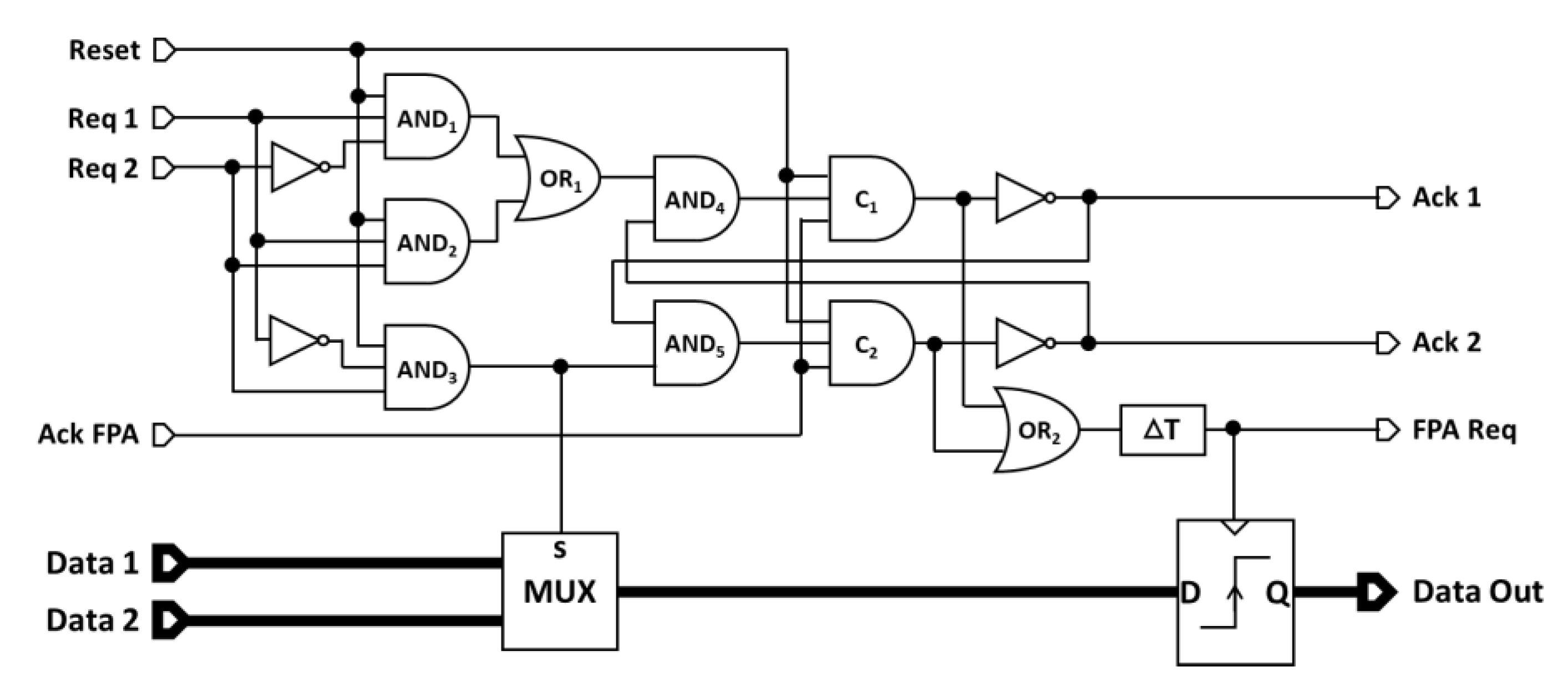
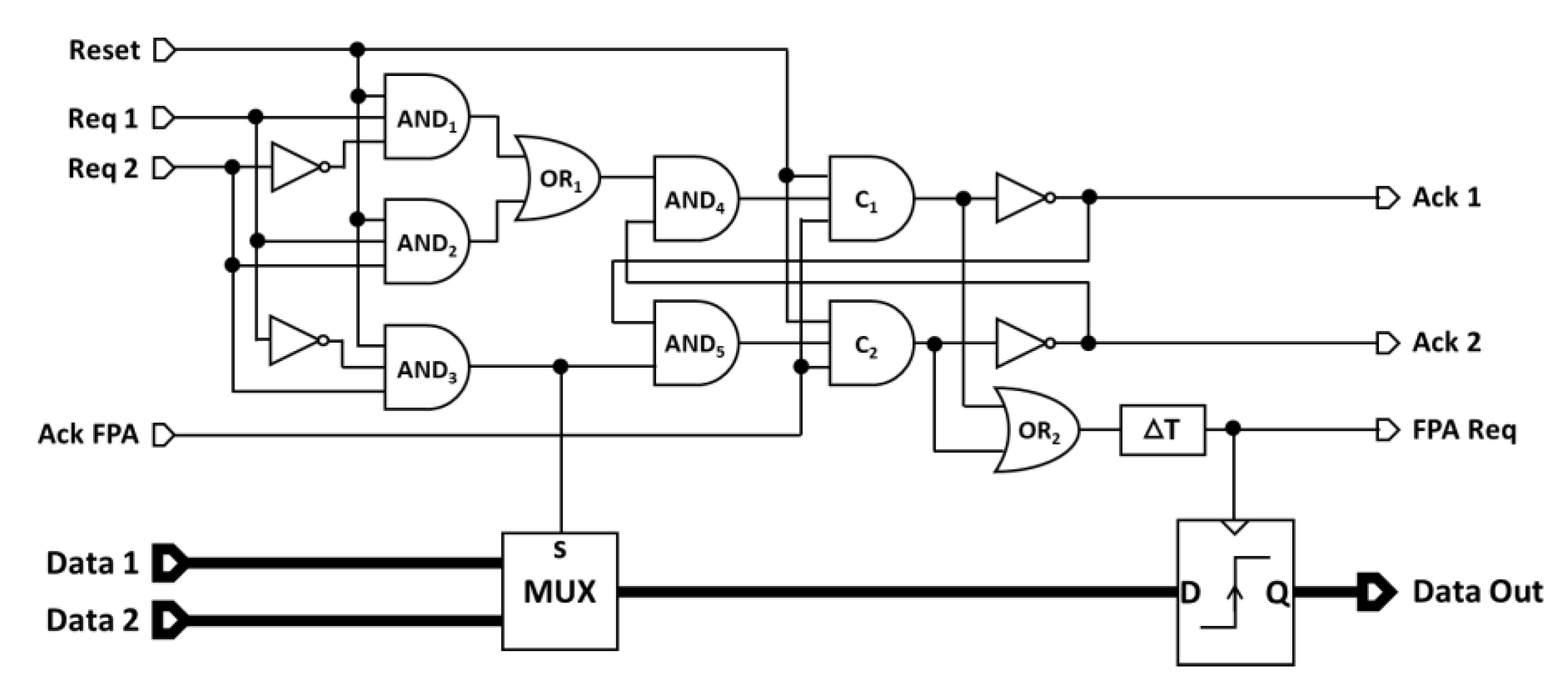
4.2. Fixed Priority Arbiter Unit
5. VLSI Implementation of the Proposed 16 to 1 Fixed Priority Arbiter
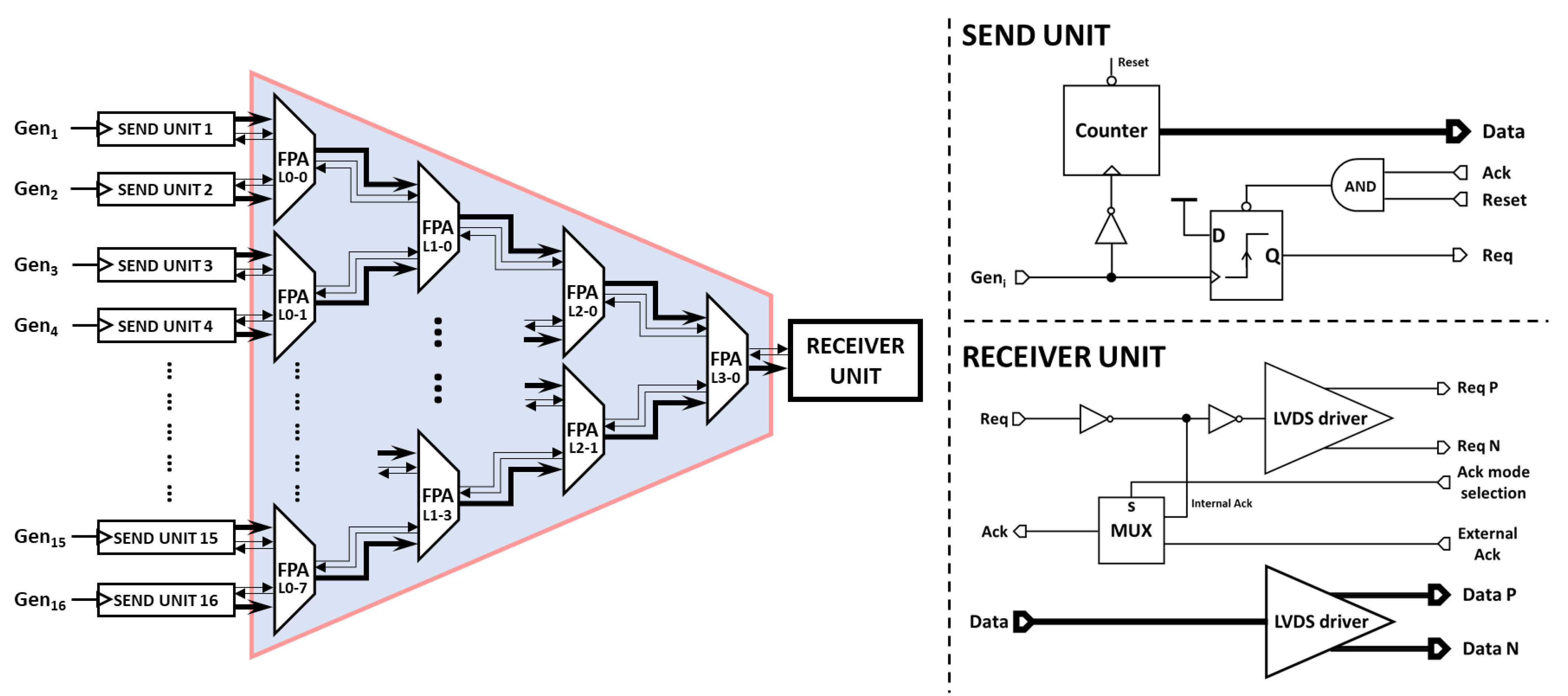
5.1. Tree-Structure of the Proposed 16 to 1 FPA
5.2. Send Units
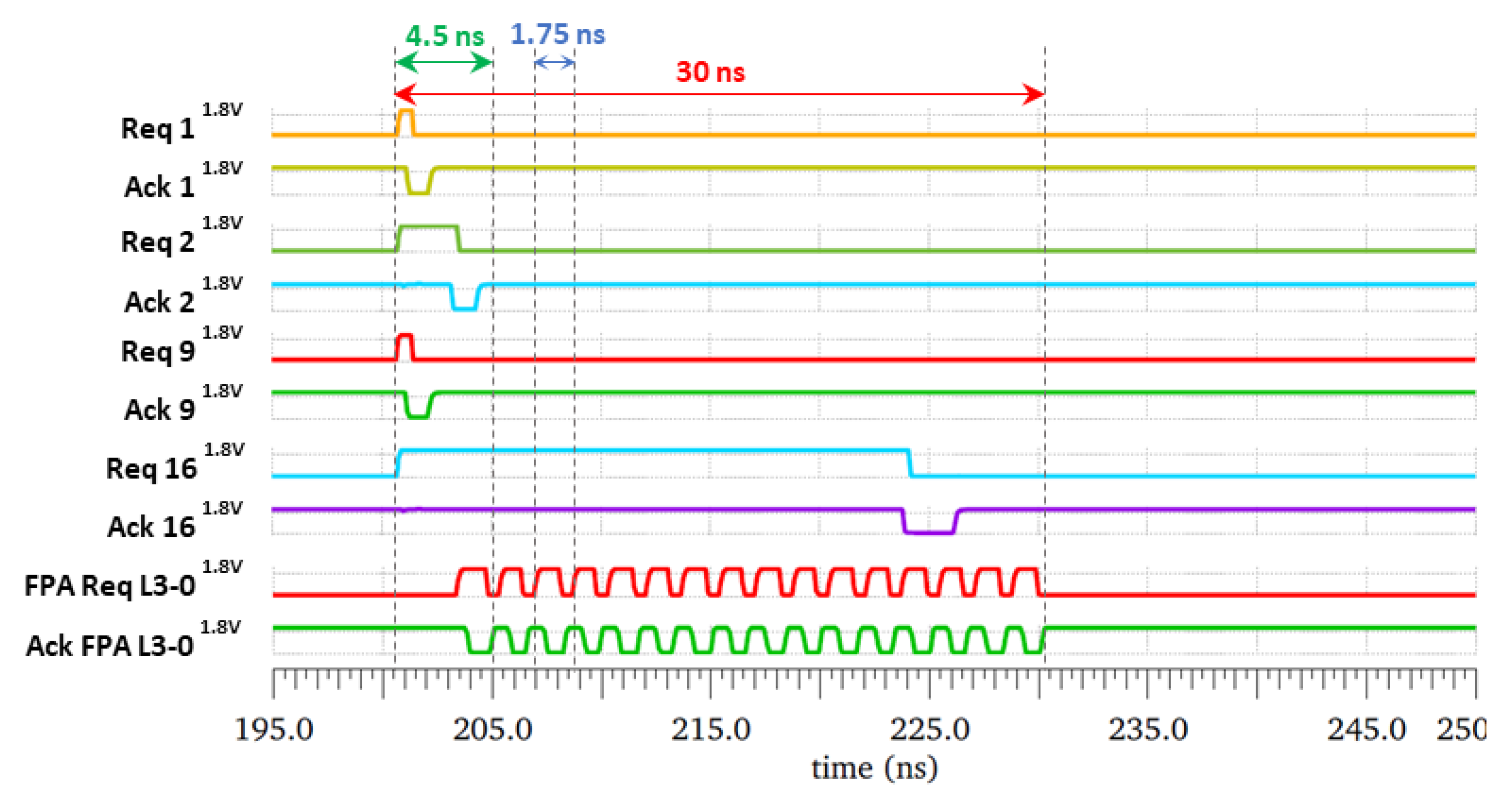
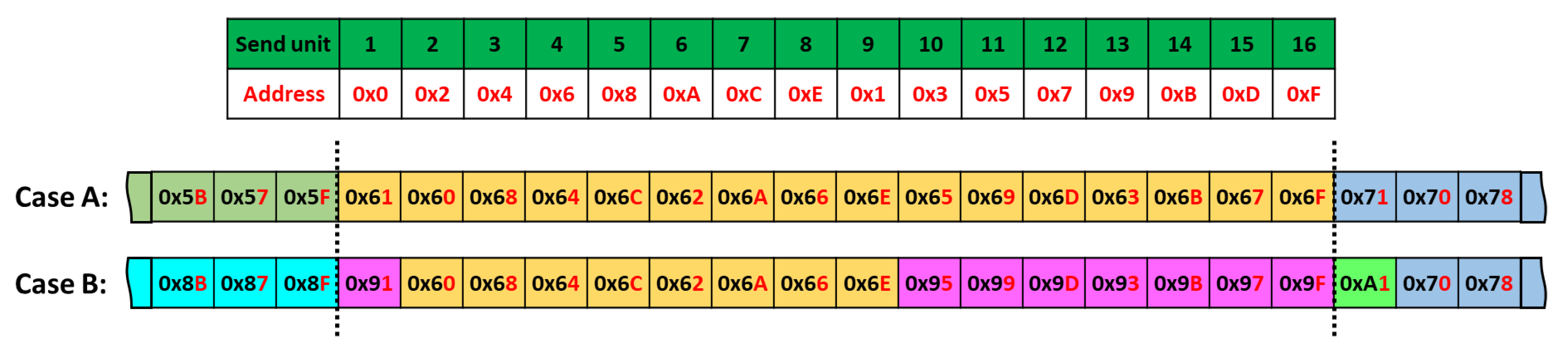
5.3. Simulation Results
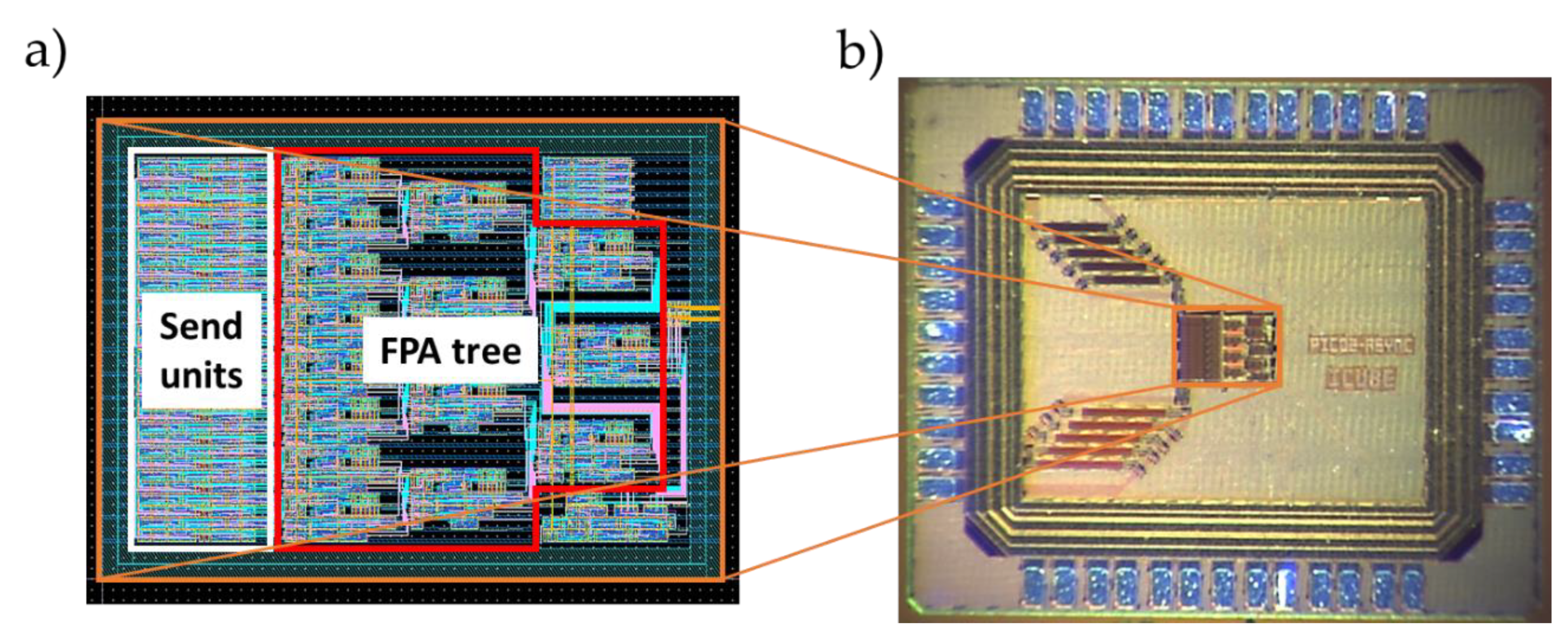
5.4. Physical Implementation
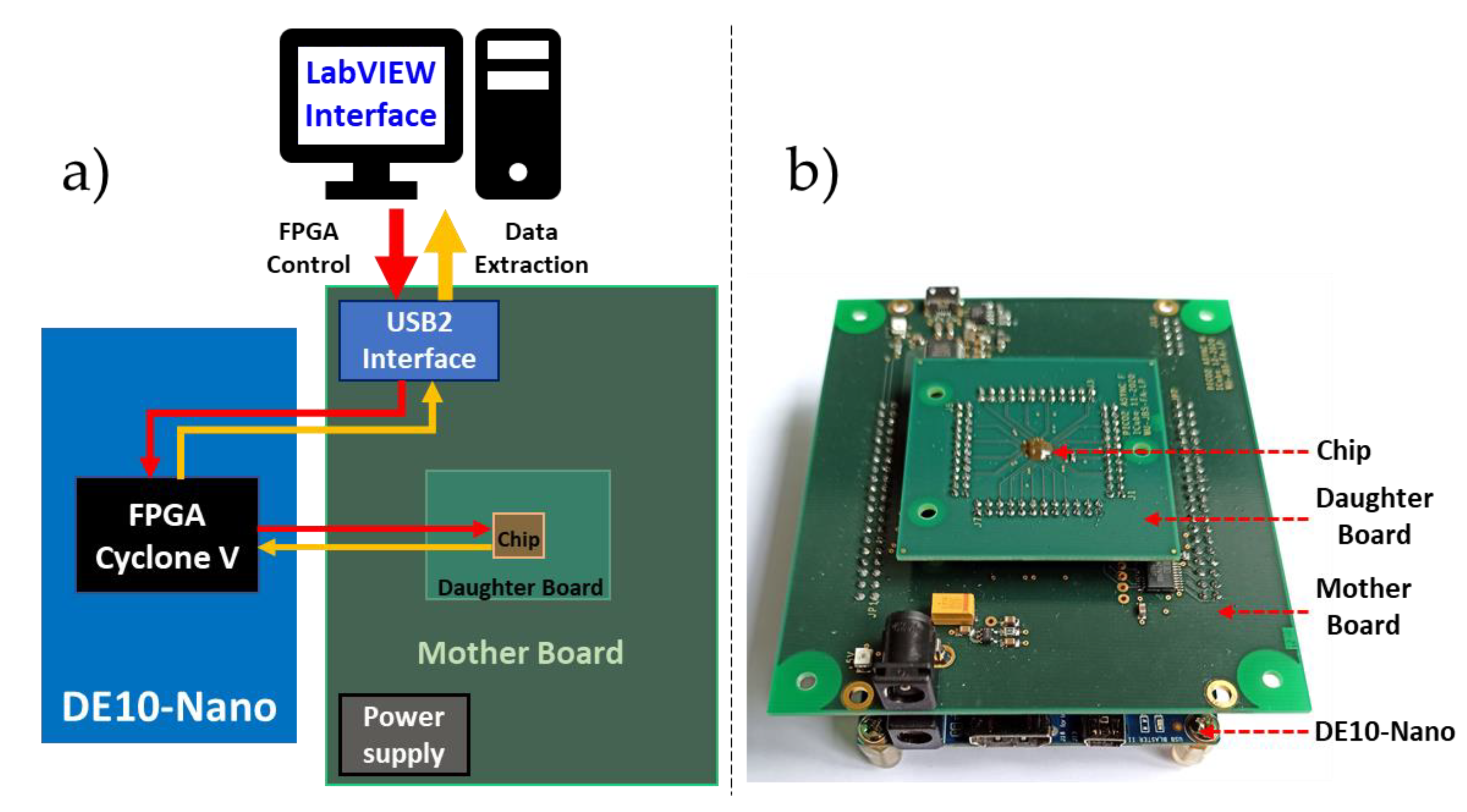
6. Experimental Environment, Results and Discussion
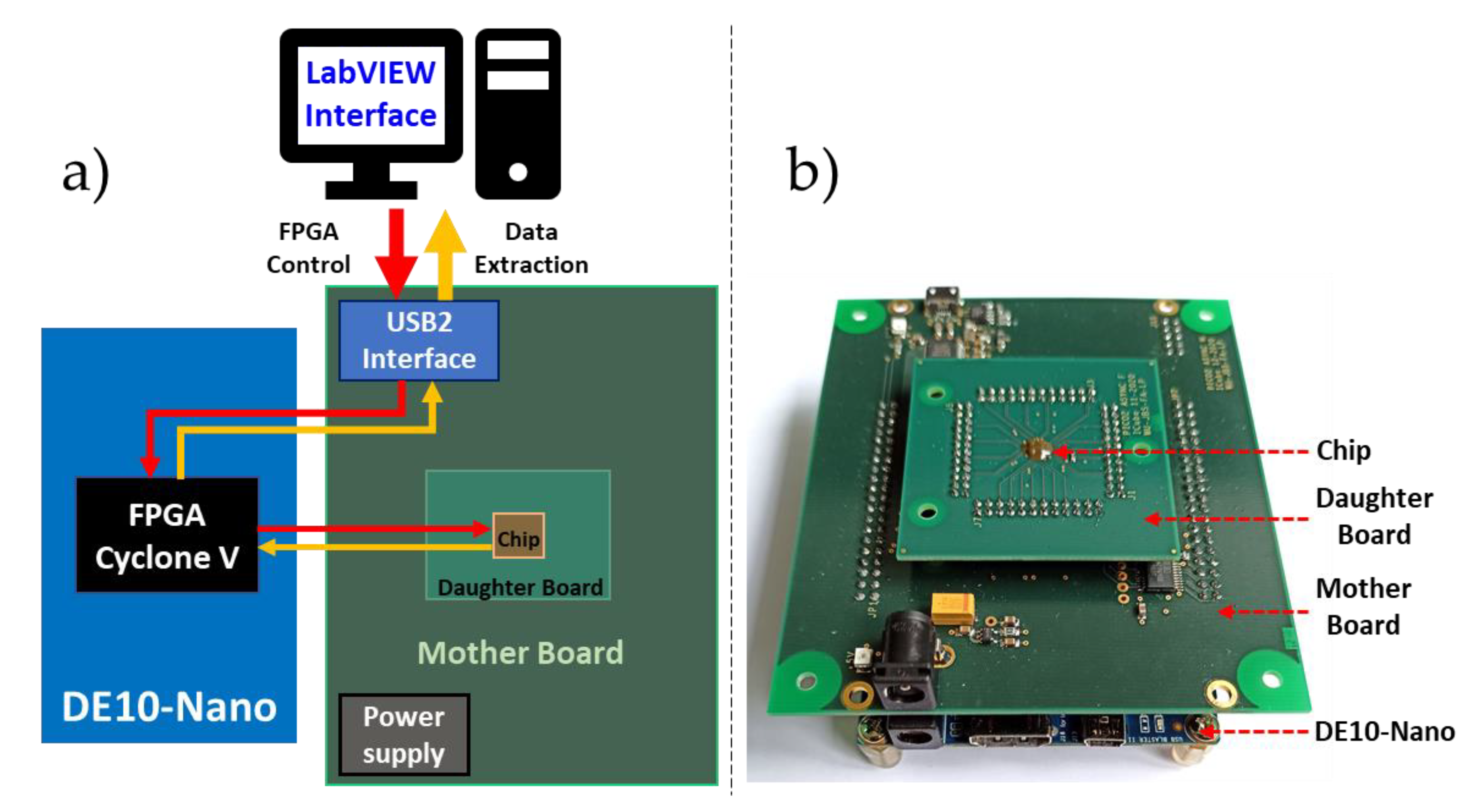
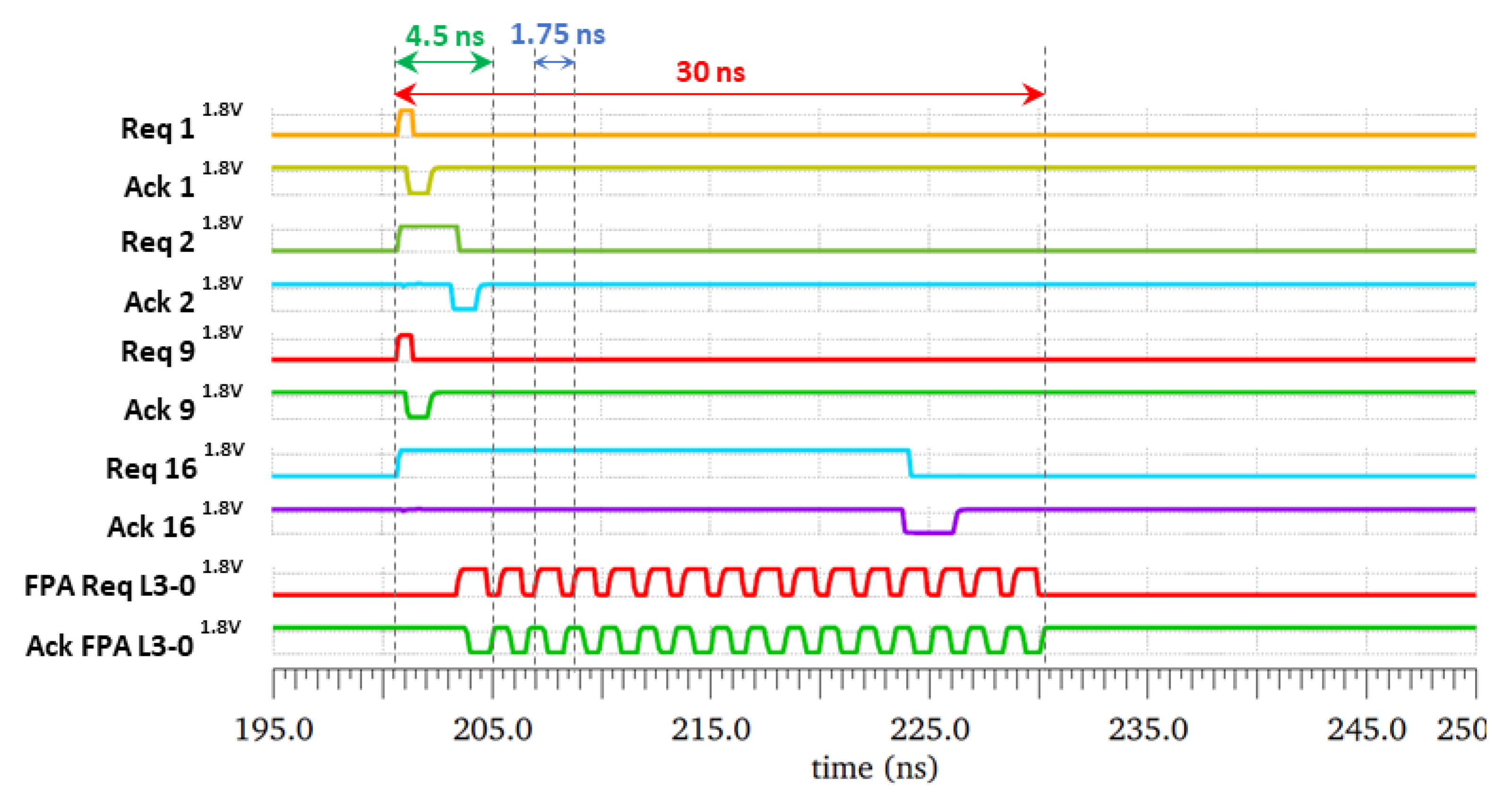
6.1. Experimental Setup
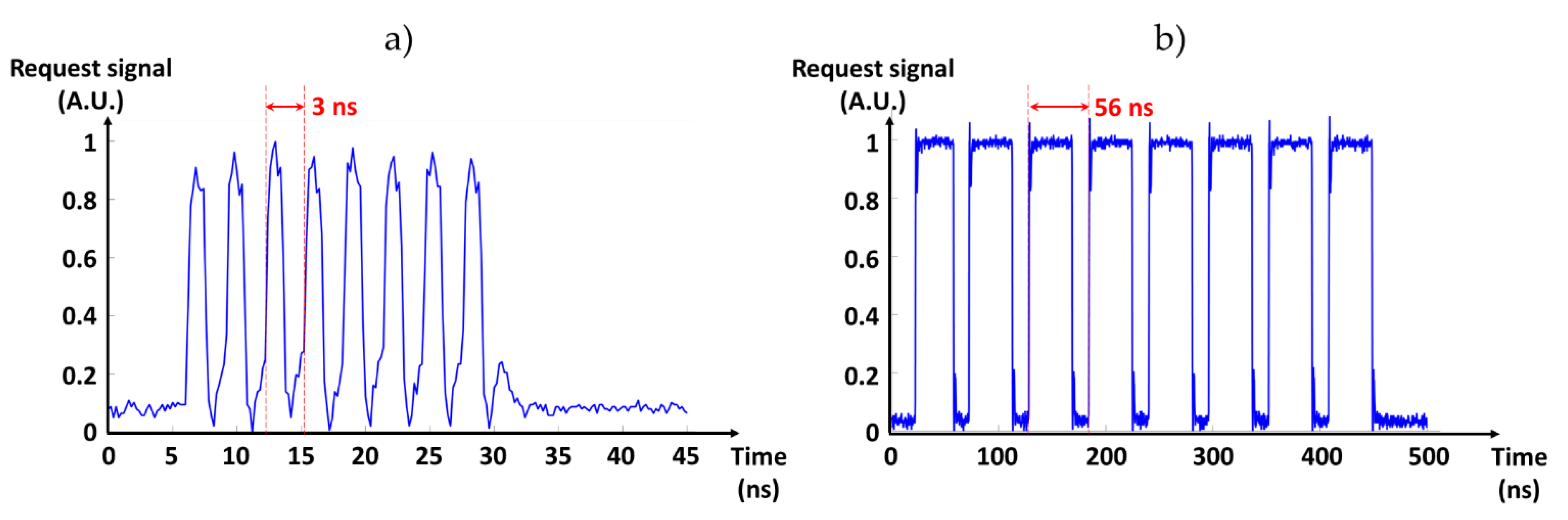
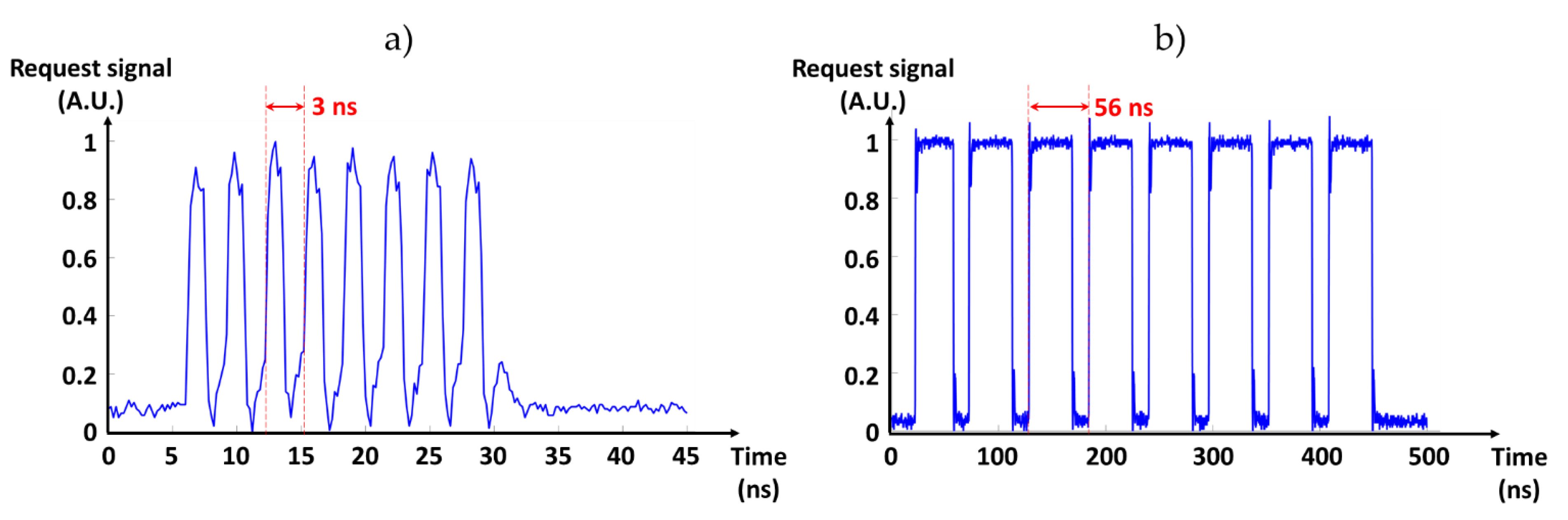
6.2. Results and Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bronzi, D.; Villa, F.; Tisa, S.; Tosi, A.; Zappa, F. SPAD Figures of Merit for Photon-Counting, Photon-Timing, and Imaging Applications: A Review. IEEE Sens. J. 2016, 16, 3–12. [Google Scholar] [CrossRef] [Green Version]
- Charbon, E. Single-photon imaging in complementary metal oxide semiconductor processes. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2014, 372, 20130100. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bruschini, C.; Homulle, H.; Antolovic, I.M.; Burri, S.; Charbon, E. Single-photon avalanche diode imagers in biophotonics: Review and outlook. Light Sci. Appl. 2019, 8, 1–28. [Google Scholar] [CrossRef]
- Palubiak, D.P.; Deen, M.J. CMOS SPADs: Design Issues and Research Challenges for Detectors, Circuits, and Arrays. IEEE J. Sel. Top. Quantum Electron. 2014, 20, 409–426. [Google Scholar] [CrossRef]
- Zappa, F.; Tisa, S.; Tosi, A.; Cova, S. Principles and features of single-photon avalanche diode arrays. Sens. Actuators A Phys. 2007, 140, 103–112. [Google Scholar] [CrossRef]
- Takai, I.; Matsubara, H.; Soga, M.; Ohta, M.; Ogawa, M.; Yamashita, T. Single-Photon Avalanche Diode with Enhanced NIR-Sensitivity for Automotive LIDAR Systems. Sensors 2016, 16, 459. [Google Scholar] [CrossRef] [PubMed]
- Chen, G.; Wiede, C.; Kokozinski, R. Data Processing Approaches on SPAD-Based d-TOF LiDAR Systems: A Review. IEEE Sens. J. 2021, 21, 5656–5667. [Google Scholar] [CrossRef]
- Caccia, M.; Nardo, L.; Santoro, R.; Schaffhauser, D. Silicon Photomultipliers and SPAD imagers in biophotonics: Advances and perspectives. Nucl. Instrum. Methods Phys. Res. Sect. A Accel. Spectrometers Detect. Assoc. Equip. 2019, 926, 101–117. [Google Scholar] [CrossRef]
- Hiskett, P.A.; Bonfrate, G.; Buller, G.S.; Townsend, P.D. Eighty kilometre transmission experiment using an InGaAs/InP SPAD-based quantum cryptography receiver operating at 1.55 μm. J. Mod. Opt. 2001, 48, 1957–1966. [Google Scholar] [CrossRef]
- Li, Y.; Safari, M.; Henderson, R.; Haas, H. Nonlinear Distortion in SPAD-Based Optical OFDM Systems. In Proceedings of the 2015 IEEE Globecom Workshops (GC Wkshps), San Diego, CA, USA, 6–10 December 2015; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2015; pp. 1–6. [Google Scholar]
- Malass, I.; Uhring, W.; Le Normand, J.-P.; Dumas, N.; Dadouche, F. 10-ps Resolution hybrid time to digital converter in a 0.18 μm CMOS technology. In Proceedings of the 2014 IEEE 12th International New Circuits and Systems Conference (NEWCAS), Trois-Rivieres, QC, Canada, 22–25 June 2014; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2014; pp. 105–108. [Google Scholar]
- Malass, I.; Uhring, W.; Le Normand, J.-P.; Dumas, N.; Dadouche, F. Parallelized Integrated Time-Correlated Photon Counting System for High Photon Counting Rate Applications. Photon Count. Fundam. Appl. 2018. [Google Scholar] [CrossRef] [Green Version]
- Della Rocca, F.M.; Mai, H.; Hutchings, S.W.; Al Abbas, T.; Buckbee, K.; Tsiamis, A.; Lomax, P.; Gyongy, I.; Dutton, N.A.W.; Henderson, R.K. A 128 × 128 SPAD Motion-Triggered Time-of- Flight Image Sensor with In-Pixel Histogram and Column-Parallel Vision Processor. IEEE J. Solid-State Circuits 2020, 55, 1. [Google Scholar] [CrossRef]
- Shawkat, M.S.A.; Mcfarlane, N. A Digital CMOS Silicon Photomultiplier Using Perimeter Gated Single Photon Avalanche Diodes with Asynchronous AER Readout. IEEE Trans. Circuits Syst. I Regul. Pap. 2020, 67, 4818–4828. [Google Scholar] [CrossRef]
- Lin, J.; Andreou, A.G. A 32 × 32 single photon avalanche diode imager with delay-insensitive address-event readout. 2011 IEEE Int. Symp. Circuits Syst. 2011, 1824–1827. [Google Scholar] [CrossRef]
- Linn, A.M.T.; Tuan, D.A.; Shoushun, C.; Seng, Y.K. Adaptive priority toggle asynchronous tree arbiter for AER-based image sensor. In Proceedings of the 2011 IEEE/IFIP 19th International Conference on VLSI and System-on-Chip, Hong Kong, China, 3–5 October 2011; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2011; pp. 66–71. [Google Scholar]
- Shoushun, C.; Bermak, A.; Martinez, D. A CMOS vision sensor with on-the-fly histogram equalization using TFS encoding and AER read-out. In Proceedings of the 2005 IEEE Asian Solid-State Circuits Conference, Hsinchu, Taiwan, 1–3 November 2005; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2005; pp. 433–436. [Google Scholar]
- Ghiribaldi, A.; Bertozzi, D.; Nowick, S.M.; Alberto, G. A Transition-Signaling Bundled Data NoC Switch Architecture for Cost-effective GALS Multicore Systems. Des. Autom. Test Eur. Conf. Exhib. 2013, 332–337. [Google Scholar] [CrossRef]
- Rigaud, J.-B.; Quartana, J.; Fesquet, L.; Renaudin, M. Modeling and Design of Asynchronous Priority Arbiters for On-Chip Com-munication Systems. In Proceedings of the IFIP TC10/WG10.5 Eleventh International Conference on Very Large Scale Integration of Systems-on/Chip: SOC Design Methodologies, Montpellier, France, 3–5 December 2001; pp. 313–324. [Google Scholar]
- Bystrov, A.; Kinniment, D.; Yakovlev, A. Priority arbiters. In Proceedings of the 6th International Symposium on Advanced Research in Asynchronous Circuits and Systems (ASYNC 2000), Eilat, Israel, 2–6 April 2000; pp. 128–137. [Google Scholar] [CrossRef]
- Beerel, P.A.; Roncken, M.E. Low Power and Energy Efficient Asynchronous Design. J. Low Power Electron. 2007, 3, 234–253. [Google Scholar] [CrossRef]
- Turko, T.; Uhring, W.; Dadouche, F.; Fesquet, L. An Asynchronous Fixed Priority Arbiter for High througput Time Correlated Single Photon Counting Systems. In Proceedings of the 2018 25th IEEE International Conference on Electronics, Circuits and Systems (ICECS), Bordeaux, France, 9–12 December 2018; pp. 765–768. [Google Scholar]
- Lichtsteiner, P.; Posch, C.; Delbruck, T. A 128 128 120 dB 15 µs Latency Asynchronous Temporal Contrast Vision Sensor. IEEE J. Solid-State Circuits 2008, 43, 566–576. [Google Scholar] [CrossRef] [Green Version]
- Niclass, C.; Favi, C.; Kluter, T.; Gersbach, M.; Charbon, E. A 128 × 128 Single-Photon Image Sensor With Column-Level 10-Bit Time-to-Digital Converter Array. IEEE J. Solid-State Circuits 2008, 43, 2977–2989. [Google Scholar] [CrossRef]
- Sutherland, I.E. Micropipelines. Commun. ACM 1989, 32, 720–738. [Google Scholar] [CrossRef]
- Nowick, S.M.; Singh, M. High-Performance Asynchronous Pipelines: An Overview. IEEE Des. Test Comput. 2011, 28, 8–22. [Google Scholar] [CrossRef]
- McGee, P.B.; Agyekum, M.Y.; Mohamed, M.A.; Nowick, S.M. A Level-Encoded Transition Signaling Protocol for High-Throughput Asynchronous Global Communication. In Proceedings of the 2008 14th IEEE International Symposium on Asynchronous Circuits and Systems, Newcastle Upon Tyne, UK, 7–10 April 2008; pp. 116–127. [Google Scholar]
- Naqvi, S.R.; Steininger, A. A Tree Arbiter Cell for High Speed Resource Sharing in Asynchronous Environments. In Proceedings of the Conference on Design, Automation & Test in Europe; European Design and Automation Association, Leuven, Belgium, 24 March 2014; pp. 1–6. [Google Scholar]
- Miorandi, G.; Bertozzi, D.; Nowick, S.M. Increasing Impartiality and Robustness in High-Performance N-Way Asynchronous Arbiters. In Proceedings of the 2015 21st IEEE International Symposium on Asynchronous Circuits and Systems, Mountain View, CA, USA, 4–6 May 2015; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2015; pp. 108–115. [Google Scholar]
- Malass, I.; Uhring, W.; Le Normand, J.-P.; Dumas, N.; Dadouche, F. Efficiency improvement of high rate integrated time correlated single photon counting systems by incorporating an embedded FIFO. In Proceedings of the 2015 IEEE 13th International New Circuits and Systems Conference (NEWCAS), Grenoble, France, 7–10 June 2015; pp. 1–4. [Google Scholar]





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aguénounon, E.; Razavinejad, S.; Schell, J.-B.; Dolatpoor Lakeh, M.; Khaddour, W.; Dadouche, F.; Kammerer, J.-B.; Fesquet, L.; Uhring, W. Design and Characterization of an Asynchronous Fixed Priority Tree Arbiter for SPAD Array Readout. Sensors 2021, 21, 3949. https://doi.org/10.3390/s21123949
Aguénounon E, Razavinejad S, Schell J-B, Dolatpoor Lakeh M, Khaddour W, Dadouche F, Kammerer J-B, Fesquet L, Uhring W. Design and Characterization of an Asynchronous Fixed Priority Tree Arbiter for SPAD Array Readout. Sensors. 2021; 21(12):3949. https://doi.org/10.3390/s21123949
Chicago/Turabian StyleAguénounon, Enagnon, Safa Razavinejad, Jean-Baptiste Schell, Mohammadreza Dolatpoor Lakeh, Wassim Khaddour, Foudil Dadouche, Jean-Baptiste Kammerer, Laurent Fesquet, and Wilfried Uhring. 2021. "Design and Characterization of an Asynchronous Fixed Priority Tree Arbiter for SPAD Array Readout" Sensors 21, no. 12: 3949. https://doi.org/10.3390/s21123949
APA StyleAguénounon, E., Razavinejad, S., Schell, J.-B., Dolatpoor Lakeh, M., Khaddour, W., Dadouche, F., Kammerer, J.-B., Fesquet, L., & Uhring, W. (2021). Design and Characterization of an Asynchronous Fixed Priority Tree Arbiter for SPAD Array Readout. Sensors, 21(12), 3949. https://doi.org/10.3390/s21123949