
How Imitation Learning and Human Factors Can Be Combined in a Model Predictive Control Algorithm for Adaptive Motion Planning and Control


Abstract
:1. Introduction
- MPC jointly performs (local) trajectory planning and control. As mentioned above, the optimization process provides a suitable vehicle trajectory together with the control command, making the vehicle track the trajectory.
- The planned trajectories are:
- –
- Optimal (over a finite time interval). In fact, they are obtained as solutions of a suitable optimization problem.
- –
- Consistent with the vehicle dynamics. A constraint is directly imposed in the optimization problem, forcing the trajectories to satisfy the vehicle dynamics/ kinematics equations.
- Trajectory planning is performed on-line. This allows the ego vehicle to adapt in real time to the road scenario and to promptly react when unexpected events occur.
- MPC can systematically deal with constraints. Besides the dynamics/kinematics constraint, other constraints can be inserted in the optimization problem, which can account for command saturations, obstacles which may affect the trajectory, boundaries in the trajectory domain, and so forth.
- MPC can efficiently manage the trade-off between performance and energy consumption. Indeed, trajectory planning is attained by minimization of an objective function consisting of two terms describing the maneuver precision, and one term quantifying the command effort (that is related to energy consumption). These terms are characterized by suitable weight matrices, which can be designed to systematically manage the aforementioned trade-off.
2. Vehicle Prototype Description and Model
2.1. Use-Cases Definition and Description
2.2. Prototype Vehicle
- External camera, with a Field of View (FoV) of 52, to detect obstacles and lanes on the road.
- External rear-corner radars, with a FoV of 15 (±75) and maximum distance of 90 m, to detect objects coming from the rear, in the adjacent lane.
- The dSpace MicroAutoBox II is used to manage the CAN board, in particular to control the data synchronization and acquisition; the control panel is used to activate the logging system and the start-up of sensors (cameras, above all).
2.3. Experimental Phase
- Approaching the (slower) vehicle ahead (car following/approaching);
- Left lane change (LC);
- Passing the vehicle aside, travelling on the right lane (this can also be multiple passing, if more than one vehicle is present);
- Right LC;
- Lane-keeping (LK) or free-riding—means the end of the overtaking maneuver.
- Vehicle dynamics:
- –
- Speed;
- –
- Steering wheel;
- –
- Yaw rate;
- –
- Acceleration;
- –
- Brake and accelerator pedal positions.
- Road information:
- –
- Number and type of lanes;
- –
- Road curvature;
- –
- Variation of road curvature (when present);
- –
- Position of the ego-vehicle in the lane;
- –
- Heading angle.
- Environmental information (of obstacles):
- –
- (Relative) speed;
- –
- Distance;
- –
- Angular position.
2.4. Single-Track Model
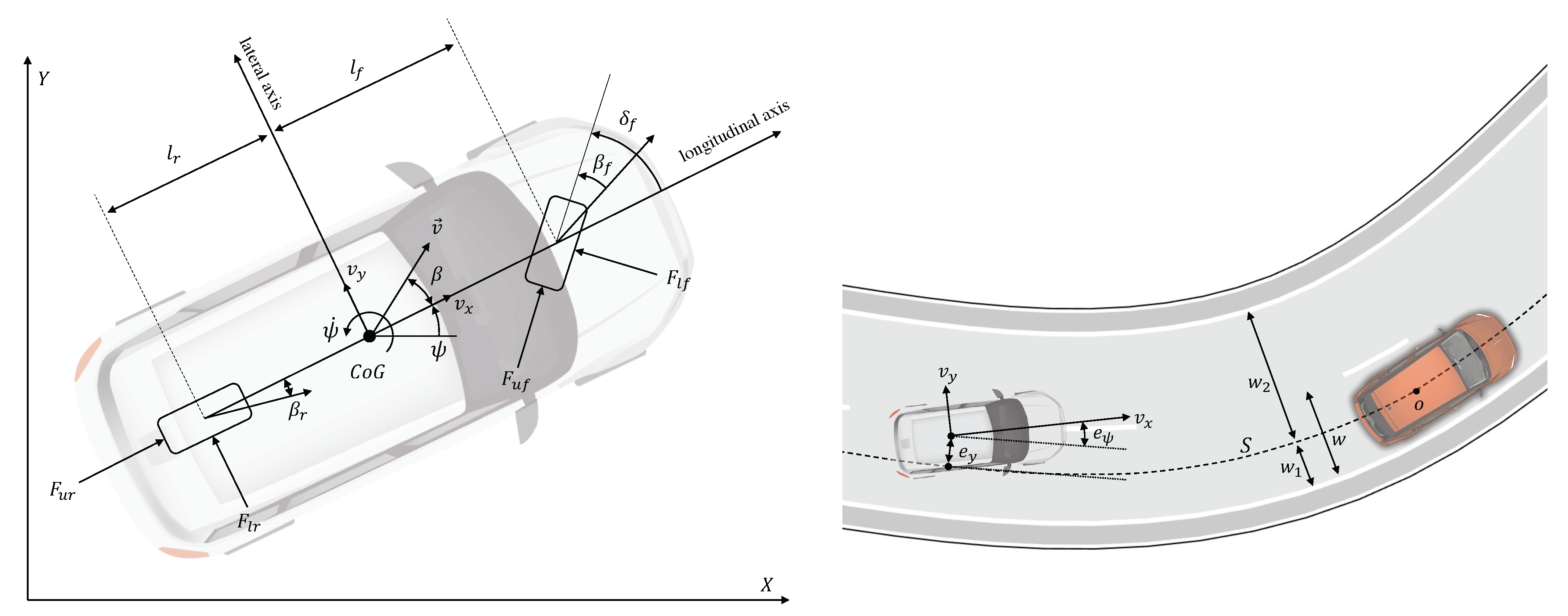
- Vehicle variables:: coordinates of the vehicle’s center of gravity (CoG) in an inertial reference frame;: yaw angle;: yaw rate;: velocity vector in the inertial frame;: longitudinal speed = component along the longitudinal axis;: lateral speed = component along the transverse axis;: longitudinal acceleration;: front wheel steering angle;: vehicle slip angle = angle between the vehicle longitudinal axis and velocity;: tire slip angles = angles between the tires’ longitudinal axis and velocity.
- Vehicle parameters:: mass and yaw polar inertia;: distance CoG - front wheel center;: distance CoG - rear wheel center;: vehicle width;: front/rear cornering stiffnesses;: front/rear vertical load factors.
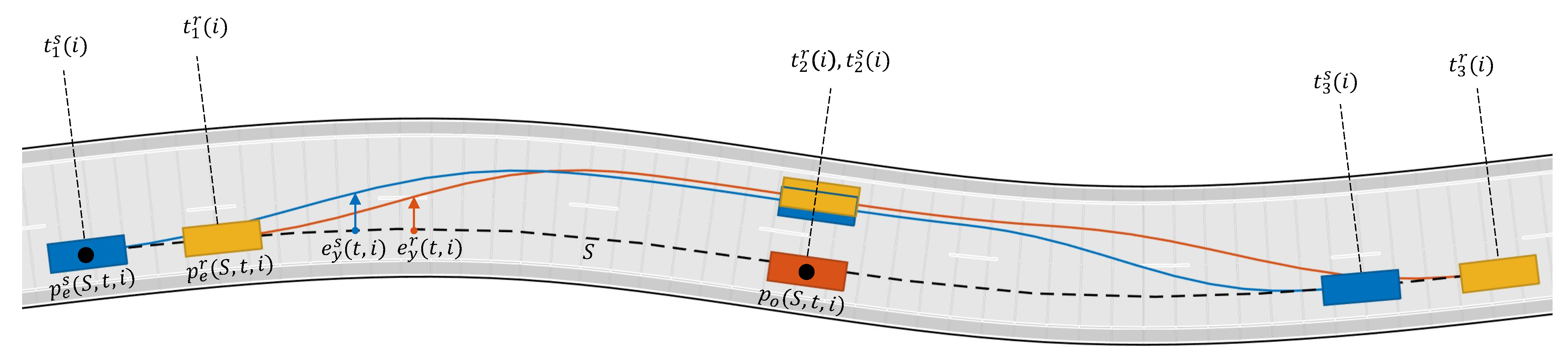
- (lateral error): lateral deviation of the vehicle CoG from the reference path S.
- (orientation error): angular deviation between the vehicle orientation and the direction of the reference path S.
3. Methods
3.1. NMPC General Formulation
- At time :
- –
- Compute by solving (6);
- –
- Apply to the system only the first input value: and keep it constant for ;
- Repeat the two steps above for
3.2. TPC Design and Implementation
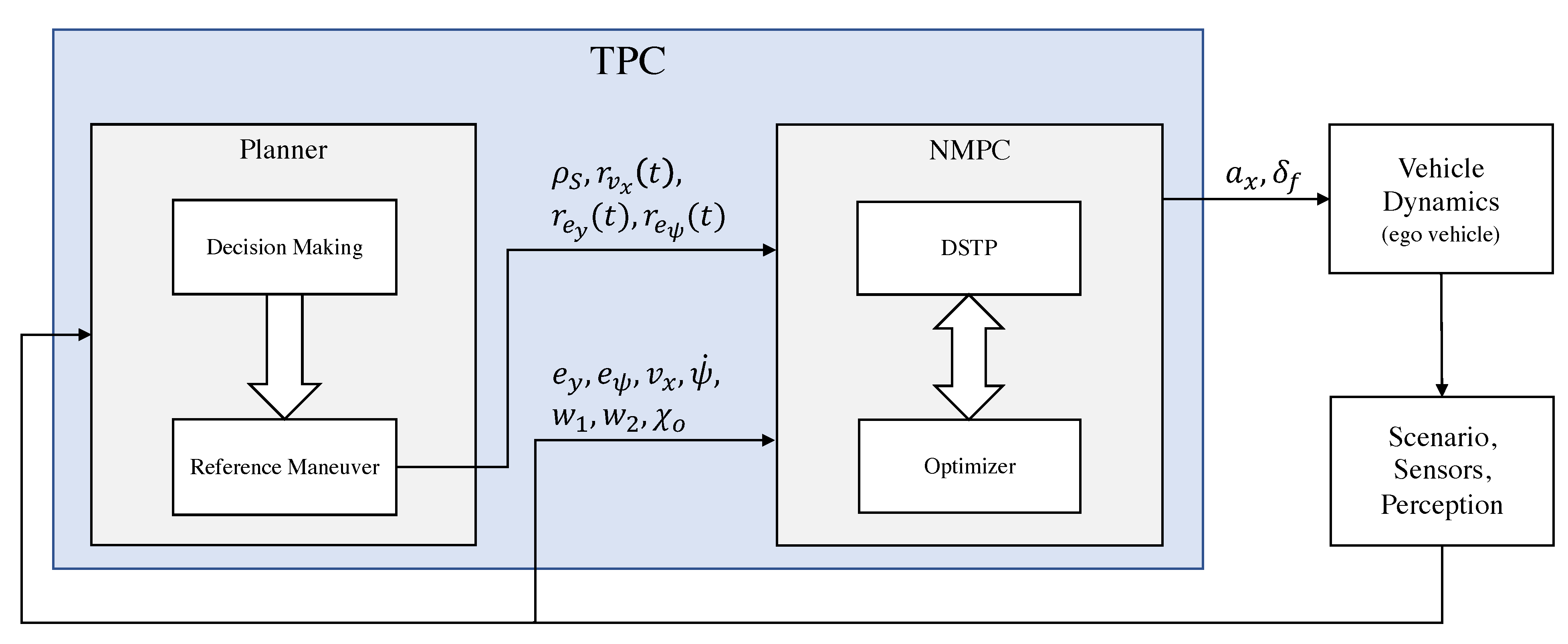
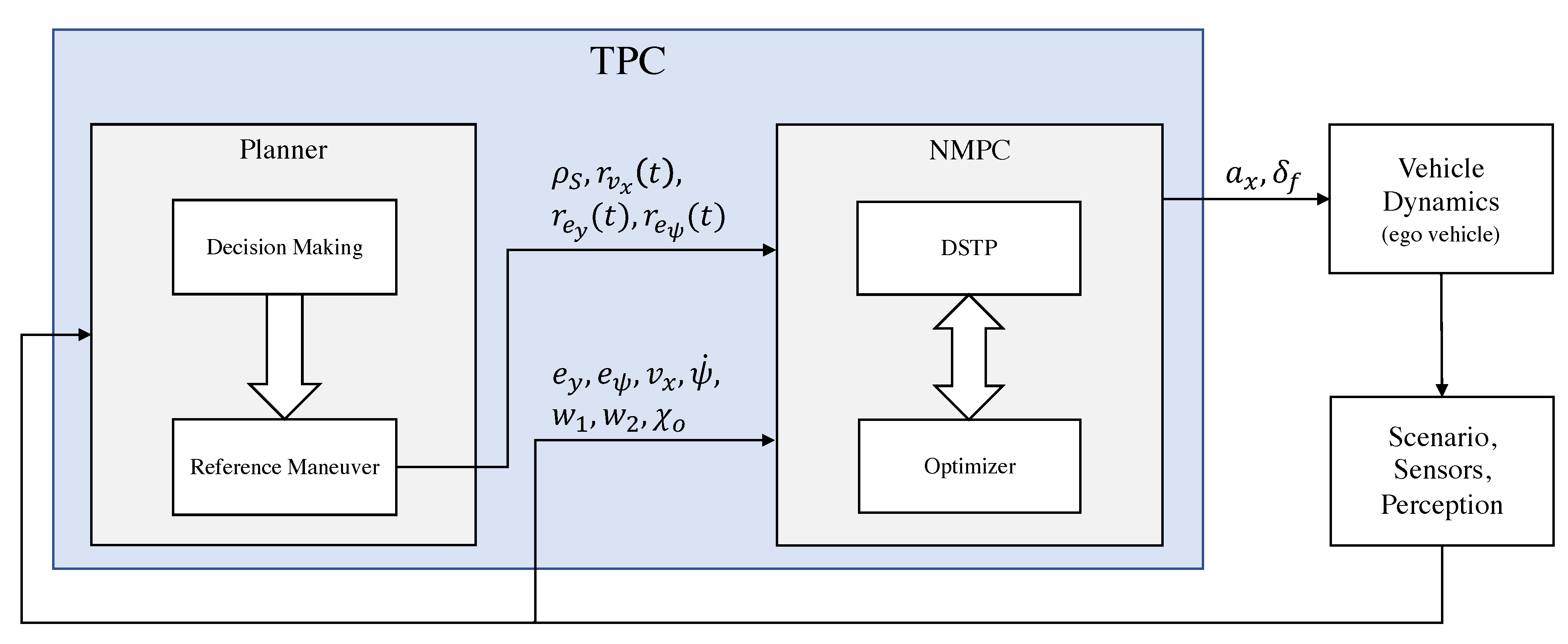
3.2.1. TPC Design
- Ego vehicle. Autonomous vehicle whose trajectory must be planned and controlled.
- Scenario, Perception. Provides road and obstacle information.
- TPC. Trajectory planning and control algorithm which includes the NMPC controller and a planner.
- S: reference path
- : curvature of the reference path
- : reference speed
- : reference lateral deviation
- : reference heading angle deviation
- : ego vehicle command input
- state: ,
- output: ,
- command input: .
- Input constraints:
- ,
- State/output constraints:
- road constraint:
- obstacle collision constraints:
- where is the set of ego vehicle body geometry positions and is the set of all obstacle/vehicle body geometry position predictions.
- Sampling time:
- Prediction horizon:
- Input nodes:
- Weight matrices: , , .
3.2.2. TPC Implementation
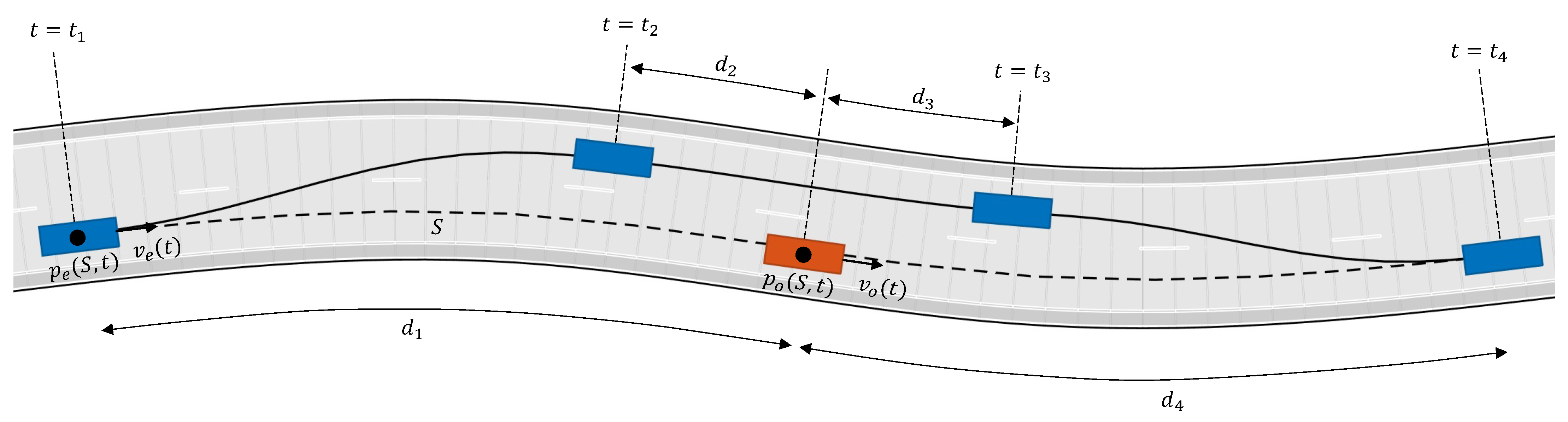
3.3. Overtaking Maneuver
- Phase 1 starts if
- Phase 2 starts if
- Phase 3 starts if
- Phase 3 ends if
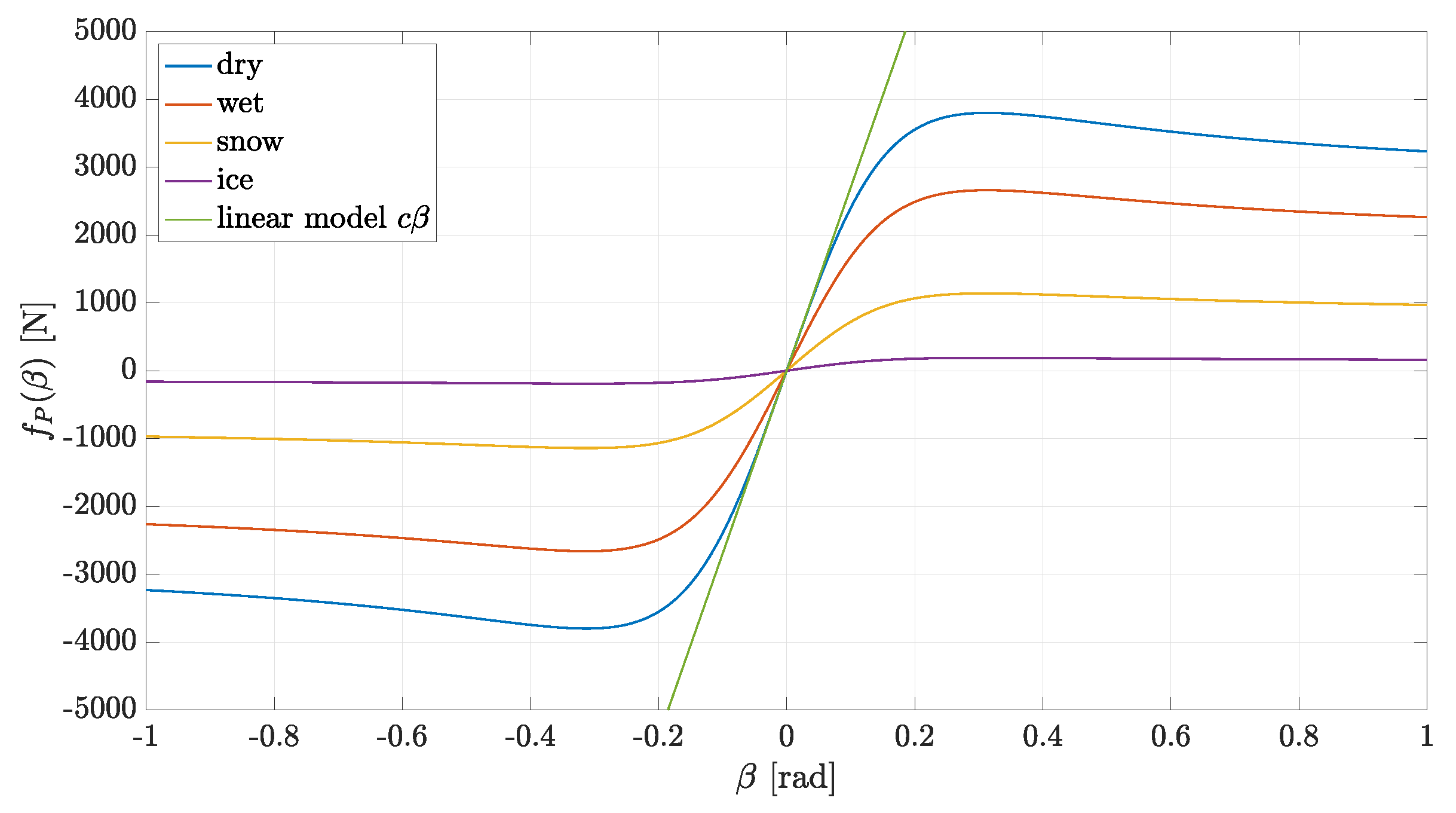
3.4. Parameter Learning
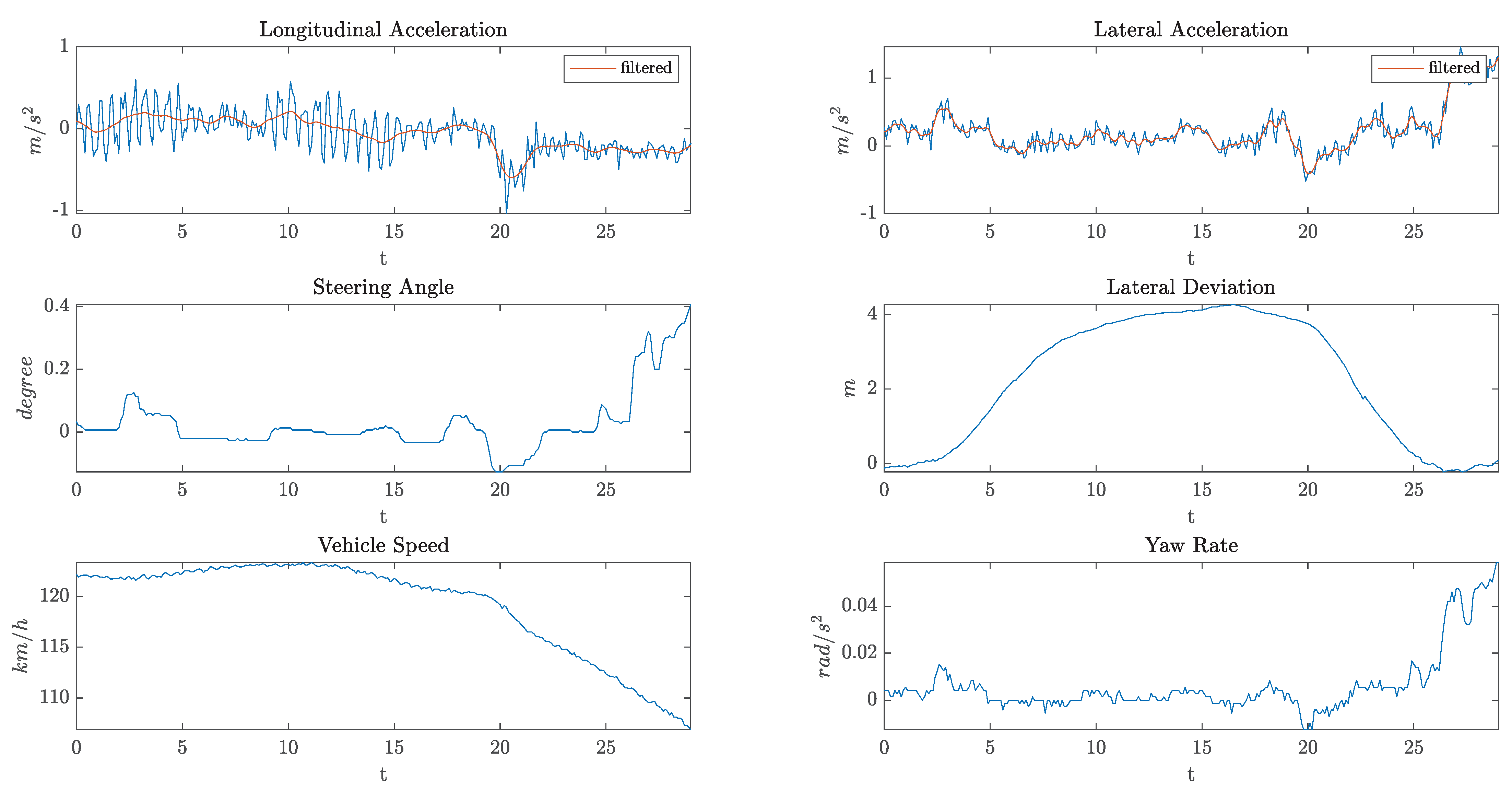
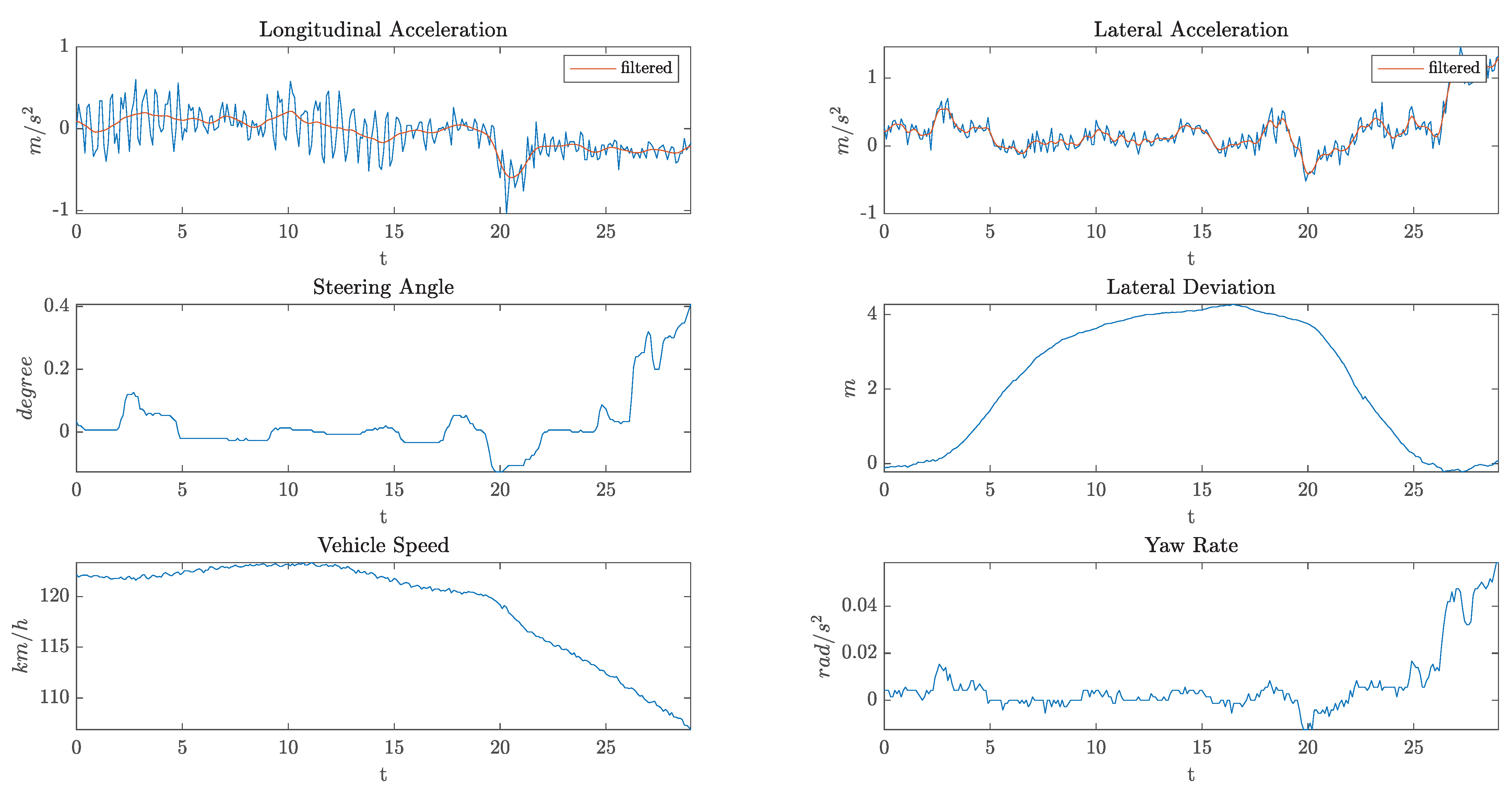
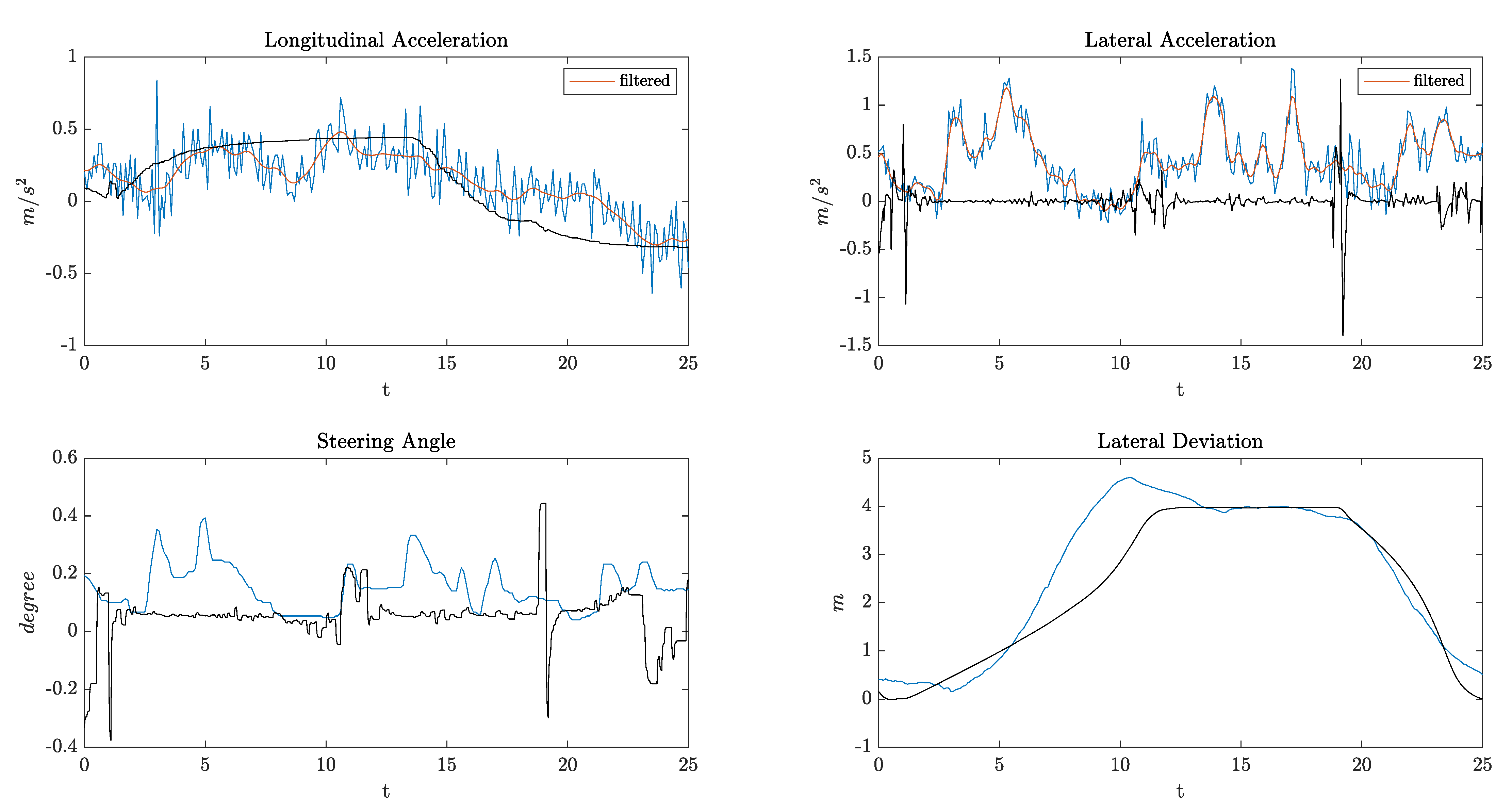
4. Results and Discussion
- KPI1: Root Mean Square (RMS) value of the lateral acceleration
- KPI2: RMS value of the longitudinal jerk
- KPI3: RMS value of the steering velocity (rad/s)
- KPI4: RMS value of lateral deviation from lane center during Phase 2 of the overtake
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Severino, A.; Curto, S.; Barberi, S.; Arena, F.; Pau, G. Autonomous Vehicles: An Analysis Both on Their Distinctiveness and the Potential Impact on Urban Transport Systems. Appl. Sci. 2021, 11, 3604. [Google Scholar] [CrossRef]
- Hart, P.E.; Nilsson, N.J.; Raphael, B. A Formal Basis for the Heuristic Determination of Minimum Cost Paths. IEEE Trans. Syst. Sci. Cybern. 1968, 4. [Google Scholar] [CrossRef]
- Stentz, A. Optimal and efficient path planning for partially-known environments. In Intelligent Unmanned Ground Vehicles; Springer: Boston, MA, USA, 1994; pp. 203–220. [Google Scholar]
- Uras, T.; Koenig, S. An Empirical Comparison of Any-Angle Path-Planning Algorithms. In Eighth Annual Symposium on Combinatorial Search; AAAI Publications: Palo Alto, CA, USA, 2015. [Google Scholar]
- Warren, C.W. Global path planning using artificial potential fields. IEEE Int. Conf. Robot. Autom. 1989, 316–317. [Google Scholar] [CrossRef]
- Kavraki, L.E.; Švestka, P.; Latombe, J.C.; Overmars, M.H. Probabilistic roadmaps for path planning in high-dimensional configuration spaces. IEEE Trans. Robot. Autom. 1996, 12. [Google Scholar] [CrossRef] [Green Version]
- LaValle, S.M. Rapidly-Exploring Random Trees: A New Tool for Path Planning. Annu. Res. Rep. 1998, 129. [Google Scholar]
- Roque, W.L.; Doering, D. Trajectory planning for lab robots based on global vision and Voronoi roadmaps. Robotica 2005, 23. [Google Scholar] [CrossRef]
- Narendran, V.; Hedrick, J. Autonomous Lateral Control of Vehicles in an Automated Highway System. Veh. Syst. Dyn. 1994, 23, 307–324. [Google Scholar] [CrossRef]
- Ji, J.; Khajepour, A.; Melek, W.W.; Huang, Y. Path planning and tracking for vehicle collision avoidance based on model predictive control with multiconstraints. IEEE Trans. Veh. Technol. 2006, 66, 952–964. [Google Scholar] [CrossRef]
- Rajamani, R. Vehicle Dynamics and Control; Springer: Boston, MA, USA, 2006. [Google Scholar]
- Thrun, S.; Montemerlo, M.; Dahlkamp, H.; Stavens, D.; Aron, A.; Diebel, J.; Fong, P.; Gale, J.; Halpenny, M.; Hoffmann, G.; et al. Stanley: The robot that won the DARPA Grand Challenge. J. Field Robot. 2006, 23, 661–692. [Google Scholar] [CrossRef]
- Soudbakhsh, D.; Eskandarian, A. Vehicle Lateral and Steering Control. In Handbook of Intelligent Vehicles; Eskandarian, A., Ed.; Springer: London, UK, 2012; pp. 209–232. [Google Scholar] [CrossRef]
- Huang, J. Vehicle Longitudinal Control. In Handbook of Intelligent Vehicles; Eskandarian, A., Ed.; Springer: London, UK, 2012; pp. 167–190. [Google Scholar]
- Tseng, H.E. Vehicle Dynamics Control. In Encyclopedia of Systems and Control; Baillieul, J., Samad, T., Eds.; Springer: London, UK, 2020; pp. 1–9. [Google Scholar]
- Dominguez-Quijada, S.; Ali, A.; Garcia, G.; Martinet, M. Comparison of Lateral Controllers for Autonomous Vehicle: Experimental Results. HAL Archives. 2020. Availabel online: https://hal.archives-ouvertes.fr/hal-02459398/document (accessed on 10 June 2021).
- Prystine. Programmable Systems for Intelligence in Automobiles, ECSEL Joint Undertaking. Availabel online: https://prystine.automotive.oth-aw.de (accessed on 10 June 2021).
- Findeisen, R.; Allgower, F. An Introduction to Nonlinear Model Predictive Control. In Proceedings of the 21st Benelux Meeting on Systems and Control, Veldhoven, The Netherlands, 19–21 March 2002; Volume 11, pp. 119–141. [Google Scholar]
- Magni, L.; Raimondo, D.; Allgower, F. Nonlinear Model Predictive Control—Towards New Challenging Applications. In Lecture Notes in Control and Information Sciences; Springer: Heidelberg, Germany, 2009. [Google Scholar]
- Grune, L.; Pannek, J. Nonlinear Model Predictive Control—Theory and Algorithms. In Communications and Control Engineering; Springer: London, UK, 2011. [Google Scholar]
- Németh, B.; Gáspár, P.; Hegedus, T. Optimal control of overtaking maneuver for intelligent vehicles. J. Adv. Transp. 2018, 2018, 2195760. [Google Scholar] [CrossRef]
- Zhang, M.; Zhang, T.; Yang, L.; Xu, H.; Zhang, Q. An autonomous overtaking maneuver based on relative position information. In Proceedings of the 2018 IEEE 88th Vehicular Technology Conference (VTC-Fall), Chicago, IL, USA, 27–30 August 2018. [Google Scholar]
- Shamir, T. How should an autonomous vehicle overtake a slower moving vehicle: Design and analysis of an optimal trajectory. IEEE Trans. Autom. Control 2004, 49, 607–610. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 2 | 0.5 | 0.5 | 1.6 | 6.5 (m/s) | 0.4 | −0.3 |
| Simulation | KPI1 | KPI2 | KPI3 | KPI4 |
|---|---|---|---|---|
| Human driver | ||||
| TPC Stanley | ||||
| TPC MPC |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Karimshoushtari, M.; Novara, C.; Tango, F. How Imitation Learning and Human Factors Can Be Combined in a Model Predictive Control Algorithm for Adaptive Motion Planning and Control. Sensors 2021, 21, 4012. https://doi.org/10.3390/s21124012
Karimshoushtari M, Novara C, Tango F. How Imitation Learning and Human Factors Can Be Combined in a Model Predictive Control Algorithm for Adaptive Motion Planning and Control. Sensors. 2021; 21(12):4012. https://doi.org/10.3390/s21124012
Chicago/Turabian StyleKarimshoushtari, Milad, Carlo Novara, and Fabio Tango. 2021. "How Imitation Learning and Human Factors Can Be Combined in a Model Predictive Control Algorithm for Adaptive Motion Planning and Control" Sensors 21, no. 12: 4012. https://doi.org/10.3390/s21124012