1. Introduction
Point clouds have become a standard data input tool for many fields, including scientific visualization, photogrammetry, and medical applications. For data acquisition of 3D shapes, modern 3D scanning devices can produce a vast amount of data, reaching millions of points [
1]. This amount of data creates challenges on several fronts, like large storage requirements and increased data transmission and rendering times. To reduce the complexity of such point clouds and make the subsequent geometric processing algorithms more efficient, it is common to simplify the point cloud.
The main requirement for point cloud simplification algorithms is that they should maintain the global shape, the sharp features, and the curvatures of the original cloud. For the last of these, transitions between planar and curved areas should be preserved [
2]. It is important to preserve the representative points and the sampling density in order to approximate faithfully the original point cloud both geometrically and topologically. The simplified point cloud must be dense around the sharp features (corners, edges, and curvatures) to preserve the global topology and sparse in flattened regions (low or zero curvature).
Some of the limitations of current simplification algorithms are nonuniformity in the simplified point clouds [
3,
4], problems in keeping the balance between preserved and lost features [
5], reduced accuracy, and high computational cost [
6]. Some of the proposed algorithms solve those shortcomings using parameters for tuning the final metric by means of weights of scales, but the burden is on the user to obtain satisfactory results [
7]. Other methods present high computational cost because they use clustering algorithms in their initial stages [
5,
8] and some use only one feature (e.g., normal or curvature) for the simplification [
9,
10].
In this paper, we propose a reliable, robust, and simple solution for the above problems. Our method uses the normal vector, the surface variation (curvature), and the point coordinates, integrated into a unique feature vector, as input to train a dictionary. There are two advantages of using this approach: on one hand, it is possible to unify different descriptors in a unique feature vector, and on the other hand, it is possible to capture the local and the global structure of the point cloud using dictionary learning and sparse coding representation.
Since sharp features are often sparse, the use of sparsity-based modeling to describe and preserve sharp features is an attractive tool for point cloud simplification.
The main contribution of our work is to use the sparse matrix to analyze the structure of point sets, gathering evidence from local geometry to infer global properties about the objects. When the point cloud sparse matrix representation is very sparse, it means that it has found the intrinsic structure of the input point cloud. In the context of point cloud simplification, this means that the model can properly represent the sampling points, preserving the sharp features and at the same time maintaining the uniformity of the point cloud.
The original point cloud data only contains the coordinates of the points with no topological information. To extract the implicit geometric information (normal vectors, surface variation, curvatures), the point-based simplification algorithms use the local information around each point in the cloud.
Usually, the k-nearest neighbor algorithm is used to estimate such geometric information. For each point in the cloud, the proposed method uses the coordinates of the normal vector, the coordinates of the point, and the curvature as a feature vector to identify potential saliency points. The feature vectors of each data point are the training signals for a dictionary learning process. With the dictionary trained, a sparse coding process is carried out to identify the most salient regions in the point cloud. Finally, the proposed method simplifies the point cloud by using the sparse vectors as a clusterization radius.
Formally, the problem of point cloud simplification is defined as follows: Given a surface
defined by a point cloud
and a target sampling rate
, the goal is to find a point cloud
with |
| =
such that the distance
ε of the surface
to the original surface
is minimal [
6]. Symbolically we write the above as follows:
where
and
, where
is the point cloud cardinality and
is the Euclidean distance. The error limit
ε is used to enforce that that no point in the simplified cloud
is further than
ε with respect to the original model.
As far as we know, we have not found in the state of the art any method that uses dictionary learning and sparse coding as a basis for point cloud simplification. The proposed method does not introduce a new technique or modification to the classic dictionary learning and sparse coding algorithms.
The contributions of this paper are as follows:
- 1.
The proposed point cloud simplification method based on dictionary learning and sparse coding maintains a balance between sharp features and the density of point distribution.
- 2.
The proposed method reduces the cardinality of the point cloud very efficiently due to its inherent perceptual nature, which selects important points based on their saliency.
- 3.
The saliency-based simplification provides an importance criterion to preserve the most important geometric features.
- 4.
The analysis of the dispersion matrix together with the fit or approximation error (Equation (3)) can be used to determine when a point is salient or not.
2. Related Work
In recent decades, a considerable amount of research has been conducted on point cloud simplification. Point cloud simplification algorithms can be roughly divided into four categories: particle simulation-based methods, iteration-based methods, formulation-based methods, and clustering-based methods.
2.1. Particle Simulation-Based Methods
Pauly et al. [
9] presented a particle simulation method. The proposed algorithm distributes a set of points called particles evenly onto a surface, producing point clouds with low approximation error to the original point cloud. Collections of particle simulation-based methods are called local optimal projection (LOP)-based methods [
3]. These methods project a set of points over an underlying surface using a localized version of the L1 median filter regularized by a repulsion potential. Huang et al. [
5] proposed a correction over the original LOP algorithm, distributing the points evenly over the underlying surface. Huang et al. [
6] and Liao et al. [
11] aimed to integrate the vector normal to each projected point in order to preserve sharp features in the point cloud. These methods produce good results for surface simplification but are computationally expensive. Furthermore, the original points are replaced by the particles, changing their location in the process.
2.2. Clustering-Based Methods
These methods divide the point cloud into clusters, applying some criteria and then replacing the cluster points with a centroid. Pauly et al. [
9] presented two algorithms: uniform incremental clustering and hierarchical clustering. These methods are memory- and time-efficient but produce high average approximation errors with respect to the original surface. Shi et al. [
10] presented an adaptive method for simplifying point clouds. They applied a recursive subdivision scheme in which the algorithm selects representative points and removes redundant ones. They used k-means clustering to group similar spatial points and applied the maximum normal vector deviation measure to subdivide the clusters. The algorithm can handle boundaries and produce uniform density in flat regions and high density in curved regions. Mahdaoui et al. [
12] presented a comparison between two simplification algorithms using k-means and fuzzy c-means algorithms. The method proposes using a metric based on entropy estimation for clustering the point cloud. Liu et al. [
13] presented an edge-sensitive feature detail preserving algorithm; they used two clustering schemas to split the point cloud into the geometric and spatial domains. These methods can preserve global structures of the point clouds, and some of them preserve sharp features; however, because of the clustering process, they are computational time-consuming.
2.3. Formulation-Based Methods
These methods are based on mathematically modeled optimality. Leal et al. [
8] proposed a three-step method. In the first step, they apply a clusterization algorithm. The second step involves the identification of points with high curvature to be preserved. The last step uses a linear programming model to simplify the point cloud, maintaining a density equivalent to the original point cloud. Chen et al. [
14] employed a resampling strategy based on a graph that selects representative points while preserving features. The minimization of the point cloud is carried out by a proposed reconstruction error based on a feature extraction operator. Qi et al. [
15] proposed an optimization strategy for maintaining the balance between finding the sharp features and preserving the density in the point cloud. The optimization is represented using a graph filter. The results of this method are superior to some other state-of-the-art methods, but it is computationally expensive.
2.4. Iteration-Based Methods
Pauly et al. [
9] proposed an iterative simplification method using quadric error metrics. The algorithm produces point clouds with low approximation errors, but they are expensive to compute. Alexa et al. [
4] proposed a decimation process based on the moving least square (MLS) method. The proposed method removes redundant information using a surface error metric. The global result of the algorithm is good, but it can produce uneven sampling because the subsampling unnecessarily restricts the potential sampling position. Zang et al. [
16] presented a method based on a multilevel strategy for point cloud simplification, which adaptively determines the optimal level of each point. For each level, the method extracts the points based on a measure of importance given by a 3D Gaussian method. Zhu et al. [
17] proposed a multiview method for point cloud simplification, projecting the points onto the three orthographic planes, in order to identify the model edges. The edges are merged to produce the 3D edges of the model, and the points with less importance are separated from the point cloud. Shoaib et al. [
18] proposed a method called fractal bubble to simplify point clouds, selecting important data points through the expansion of a recursive generation of self-similar 2D bubbles until contact is made with a point. Ji et al. [
7] presented a detailed feature points simplified algorithm (DFPSA). They proposed estimating the importance of each point using a four characteristic operator, which involves estimating normal curvature distance between the points and the projection distance to each point in the point cloud. Finally, a threshold is used to decide whether each point may be classified as a feature point or not. The nonfeature points are simplified using an octree structure to avoid creating regions with holes. Zhang et al. [
19] presented a feature-preserved point cloud simplification (FPPS) method. For the simplification, an entropy measure is defined, which quantifies the geometric features hidden in the point cloud. Then, the key points are selected based on the entropy.
3. Dictionary Learning and Sparse Coding
Dictionary learning is a technique whose goal is to learn a set of overcomplete basis (dictionary) in order to model data vectors as a sparse linear combination of basis elements (atoms of the dictionary) [
20].
Formally, the dictionary learning problem can be formulated as follows:
Given a set of training data vectors
, the aim is to find a basis vector
, which can sparsely represent the training data vectors in the set
, with
being its sparsest representation. The goal is to minimize Equation (1).
controls the sparsity of
in
. Equation (1) is minimized using the K-SVD algorithm proposed by Aharon et al. [
21].
The purpose of sparse coding [
22,
23] is to approximate a feature input vector as a linear combination of basis vectors, which are selected from a dictionary that has been learned from the data directly.
Formally, let
be a signal of dimension
; the sparse coding aims to find a dictionary
, such that
may be approximated by a linear combination of atoms
. This is
, where most of the coefficients
are zero or close to zero [
20]. Thus, the sparse coding problem can typically be formulated as an optimization problem:
In this formulation, the dictionary
is given and
once again controls the sparsity of
x in
. The term
measures the dispersion of the decomposition and can be understood as the number of nonzero coefficients in
, or sparse coefficients, in order to approximate the signal
as sparsely as possible. Or, alternatively,
Equation (3) is an optimization problem where the norm is changed by the norm ( and is the regularization parameter. The solution to Equation (2) with norm is an NP-hard problem; fortunately, under certain conditions, it is possible to relax the problem using norm and find an approximated solution using Equation (3) with norm.
4. Proposed Method
Our proposed method is based on dictionary learning and sparse coding. The input point set is analyzed using the covariance matrix to extract the local features; then, using the dictionary and the sparse representation matrix, the point set is analyzed globally to identify saliency features. Finally, we use the saliencies to sample the point cloud, keeping the most representative points.
Figure 1 shows the pipeline of the proposed method.
4.1. Selecting the Features
To characterize the point set, we define a descriptor for each point . The point descriptor is composed of the normal vector, the total variation of surface (curvature), and the point coordinate. With these features, we build a feature vector for each point to measure its importance with respect to the entire set.
The normal vector is used for two reasons. The first is because it can help to identify feature points. A large difference between the normals around a point means that the surface at the point is not planar; that is, it is likely to be a feature point. The second reason is related to the problem of obtaining a simplified point cloud that, when rendered, looks like or mimics the original point cloud from which it was derived. The normals are used in the rendering process to estimate shading and lighting. Therefore, when a point is in a sharp feature, it is considered an important point, and its normal vector must be retained in the simplified point cloud. We use the normal coordinates as components of the feature vector.
The surface curvature captures the surface variation at a point. The curvature is used in several algorithms of point cloud simplification because it is an intrinsic property that intuitively reflects the sharpness of a point in a surface. High curvatures reflect large variations of the surface at the point and hence pinpoint a sharp feature. Therefore, we use the surface variation at the point as a curvature measure, and we include it as a component of the feature vector.
In addition to the normal vector and the surface variation or curvature, the position of each point is also considered in order to guarantee a minimum sample density in every region of the cloud. Without this information, low-saliency areas could be heavily decimated, appearing holes in the point cloud and thus compromising the continuity of the surface when the cloud is rendered. Hence, the coordinate of each point is also used as a component in its feature vector.
4.2. Low-Level Feature Estimation
A common way to estimate low-level features in a point set is to apply the principal component analysis (PCA) method locally to each neighborhood around each point
[
9]. Specifically, we use a weighted version of PCA [
24,
25] with a covariance matrix
, as defined in Equation (4).
where
is the cardinality of the neighborhood around
,
;
is a weight estimated by
is the Euclidean distance. Next, we analyze the eigenvalues
and eigenvectors
of the covariance matrix
.
The eigenvector
corresponding to the smallest eigenvalue
is the normal vector
at point
. Pauly et al. [
9,
26] proved that the surface variation is equivalent to the surface curvature, as defined in Equation (6).
Once the low-level features are defined, we build a seven-dimensional feature vector
for each point
, where
4.3. Dictionary Construction and Sparse Model
Using the feature vectors defined in the above section as data vectors
, with
(number of low-level features), we construct the data matrix
, where
is the number of feature vectors. A sparse coding matrix
and a dictionary
are defined using sparse coding theory.
is the number of atoms of the dictionary. Un our experiment, we set
; for all the models, the fixed value of the dictionary with
was selected using the mean square error variation. We found that for values greater than
atoms, the MSE tends to converge, as is verified in
Section 5. The dictionary learning problem is solved using the K-SVD algorithm, as per Aharon et al. [
21], obtaining the estimation of
and
. Now
can be reconstructed as
, obtaining the sparse representation of the data matrix
in the dictionary
. The saliency points can be found by analyzing the sparse matrix
.
4.4. Detecting Saliency Points
Once the sparse coding matrix has been obtained, we analyze what vectors correspond to saliencies. Let and be column vectors of the matrices and , respectively. A feature vector is considered salient if its sparse representation has many nonzero elements—implying that a linear combination of many atoms is required to represent the point correctly—and if its sparse reconstruction error produces a high residual. On the other hand, a feature vector is not considered salient if its sparse representation has few nonzero elements, i.e., if it can be represented by the linear combination of only a few atoms and its sparse reconstruction error produces a low residual.
On this basis, we sum the nonzero elements of each column of the matrix
. A score vector with these sums is built as follows:
The sparse reconstruction error is computed by summing the residuals resulting from the difference between each signal
and its respective reconstruction
; i.e.,
. The score vector is defined as follows:
Now we normalize the score vectors
and
, dividing each vector by its highest component.
Next, both score vectors are integrated into a unique score vector as follows:
We use the vector score
as a metric for the simplification process.
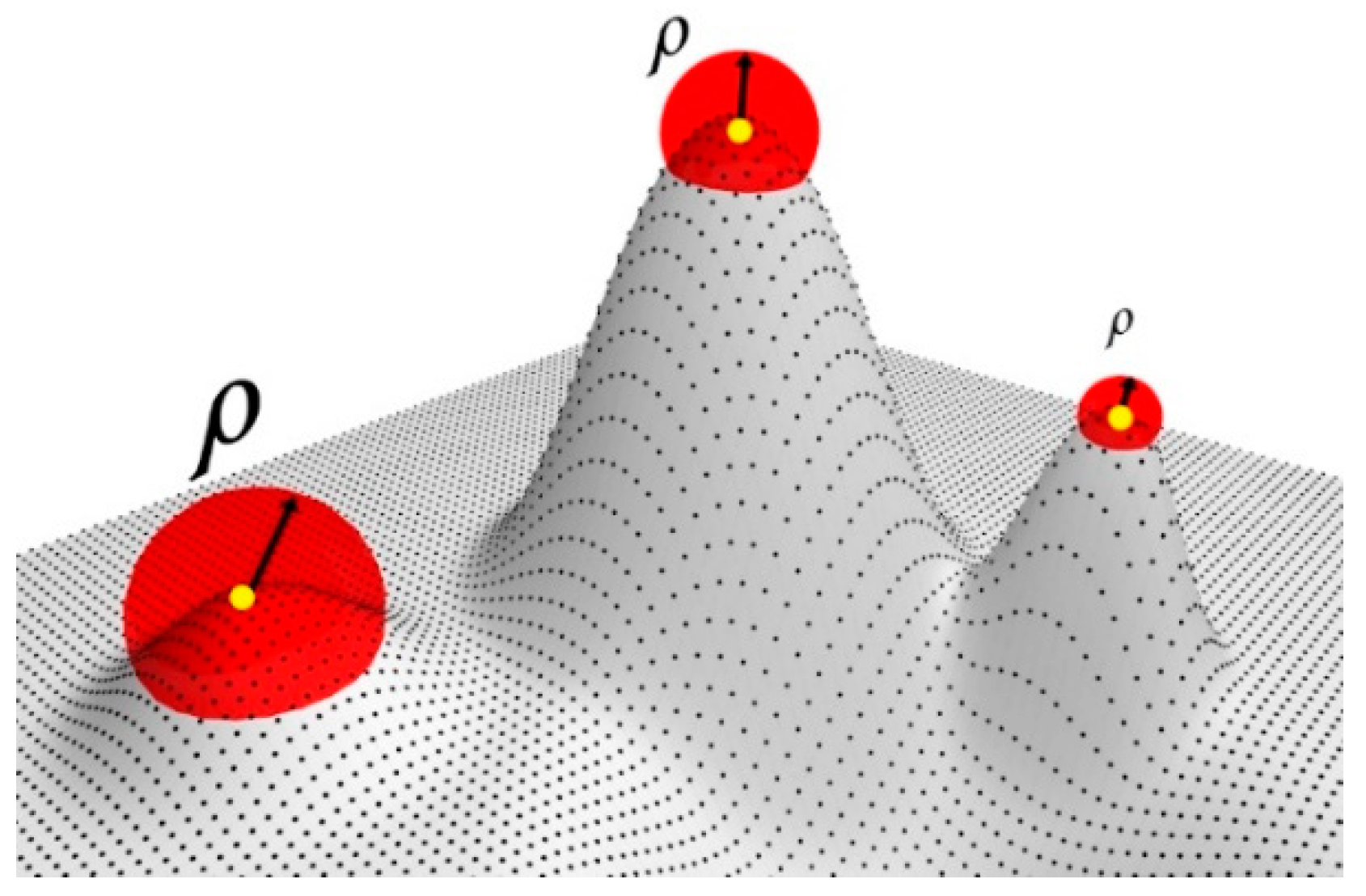
Figure 2 shows the saliency levels found in the vector
; to visualize it, we use a threshold
with different values. Equation (14), was proposed by [
27] in a local context, and the present work is a generalization to use it globally.
4.5. Simplification-Based Saliency
The saliency points characterize the most relevant features in the point cloud. These points must be retained in the simplification process. On the other hand, points with low saliency are redundant and have less importance for representing the original surface. Using the vector score defined by (14), we establish a dynamic ratio of influence that depends on the importance of the saliency of each point in the entire cloud. If point
is salient, the ratio of influence will be small, and few points will be removed. If, however, it is not salient, the ratio of influence will be large, and more points will be removed (see
Figure 3).
To proceed with the simplification, as a first step, the vector score
is sorted by the absolute value of its components. In the second step, we calculate the ratio of influence as follows:
According to (15), the dynamic ratio
is determined by
. Therefore, in points with high saliency, the ratio is small, while in points with low saliency, the ratio is large, as shown in
Figure 3, where
is a user-defined scale parameter that controls the number of points to be simplified.
5. Results and Discussion
We evaluated the proposed method using a set of models, namely the Max Planck data set (50,112 points, few detail features), the Fandisk data set (6475 points; high, sharp features), the Asian dragon data set (3,609,600 points, many detail features), the Bunny data set (35,947 points, few detail features), the Elephant data set (24,955 points, many detail features), the Horse data set (48,485 points, few detail features), the Gargoyle data set (25,038 points, many detail features), and the Nicolo data set (50,419 points, few detail features).
We also compared the results of our method to other approaches. For quantitative comparison, our method, which we named saliency dictionary-based simplification (SDBS), is compared to three point-based methods, namely the curvature-based method (CV), implemented using Geomagic Studio; simplification on graph (FPUC) [
15]; and fast resampling via graphs (FRGR) [
14], and one mesh-based method, namely poisson sampled disk (PSD), implemented using MeshLab. For visual comparison, we replicated the same experiment carried out in [
7], and we used the results to compare the proposed algorithm with our method and six state-of-the-art simplification methods: grid simplification (GRID) from CGAL library, hierarchical clustering simplification (HCS) [
9], weighted LOP (WLOP) [
5], simplification on graph (FPUC) [
15], fast resampling via graphs (FRGR) [
14] and detailed feature points simplified algorithm (DFPSA) [
7].
All the experiments were run on a PC with Intel Core i7-2670QM CPU 2.20 GHz and 8 GB RAM. For implementing the proposed method, we used the MATLAB R2016b programming environment.
Figure 4,
Figure 5,
Figure 6 and
Figure 7 are examples of the effectiveness of the proposed simplification method in different types of point clouds (free-form surfaces and surfaces with sharp edges and corners). It is clear that the proposed method is capable of preserving the global structure of the clouds as the simplification rate increases in all cloud types, since the needed information is integrated into the dictionary training.
Figure 4 shows the Fandisk model. The edges and corners are preserved as the simplification rate increases, and in flat regions, the method tries to distribute the points evenly.
Figure 5 shows how the Asian dragon model is simplified from millions of points (3,609,600) to thousands (1502). The proposed method preserves the global structure and the most relevant details of the original point cloud.
In
Figure 6, it can be appreciated how the Max Plank model is simplified from 50,112 to 1502 points. The proposed method preserves the global structure and some of the details of the original point set. The Max Plank model is a free-form surface, showing that our method operates efficiently over these types of models.
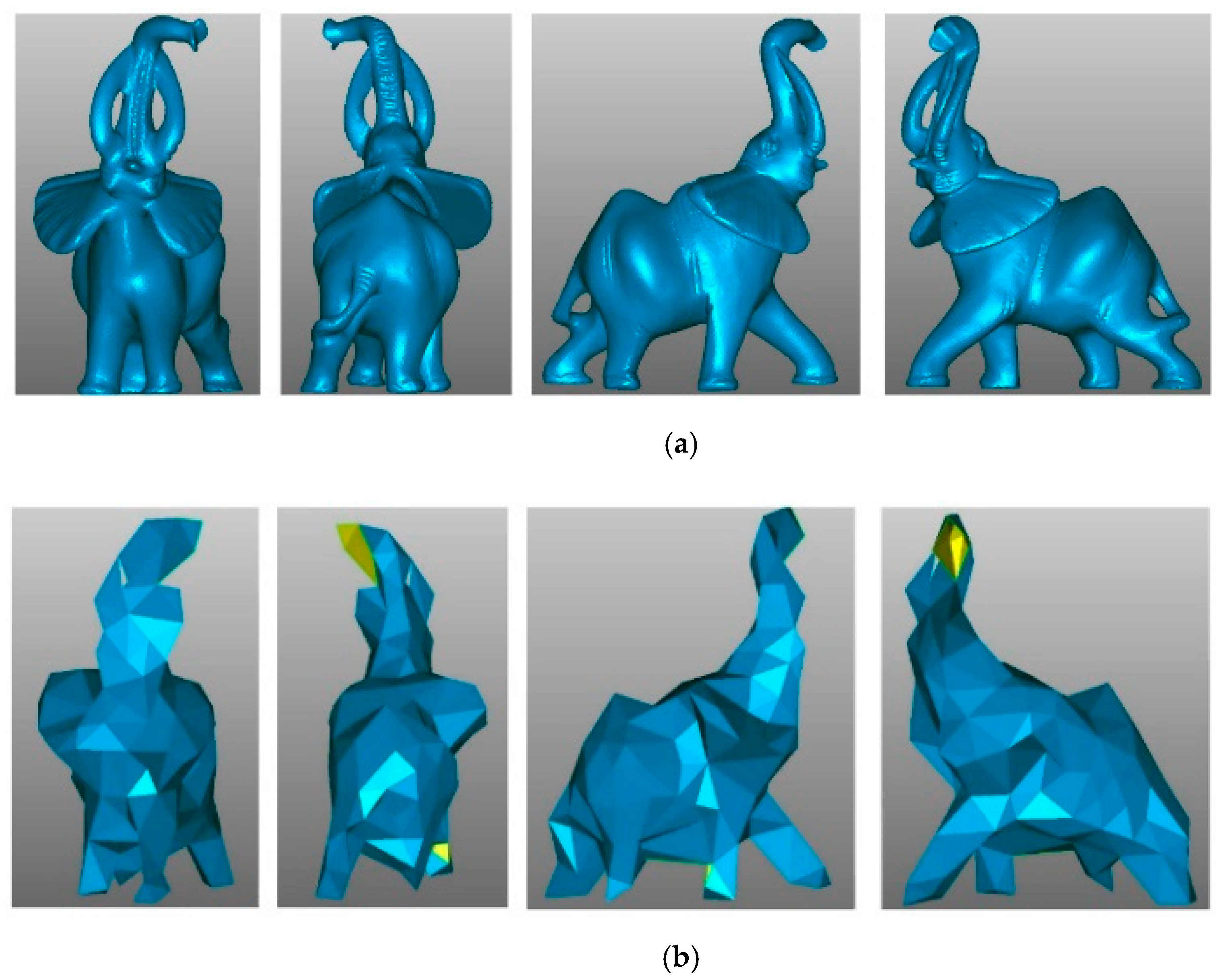
Figure 7 shows the Elephant model simplified from 24,955 to 167 points. The renderings of the simplified and original models are shown from different points of view, showing how the global structure is preserved even with a low sampling rate.
5.1. Parameter Selection
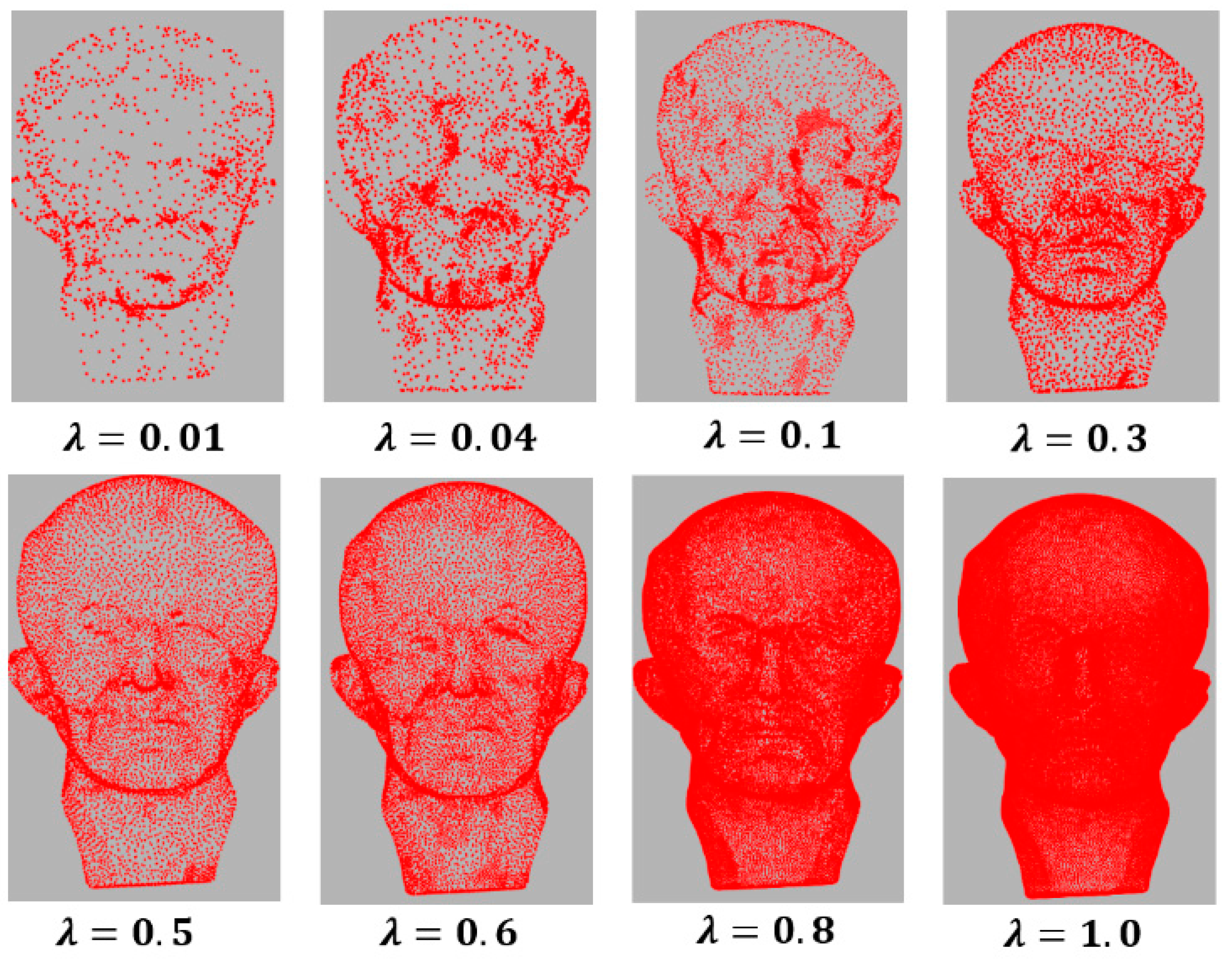
There are three parameters in our method: the regularization parameter
in Equation (3), the dictionary size S, and the fraction of points to be simplified
. The parameter
is the balance between the data fidelity and the regularization term. Small values can produce a simplification with few details, points, and features, while large values can result in more details, points, and features (see
Figure 8). In all our tests, we set
, which obtains the best results since this value maintains the balance between the number of points and the features.
We established the size of the dictionary,
, based on
Figure 8. It shows the mean square error (MSE) variation as the dictionary size increases. As the size of the dictionary increases, the MSE decreases, but processing time increases. On the other hand, when the dictionary size is reduced, the MSE increases, but the processing time decreases. Our goal was to find a balance between a suitable dictionary size and low processing time.
Figure 9 shows that in the range of values between 200 and 400, the MSEs are low, and the size of the dictionary is not significant. In all the experiments, we set the dictionary size
, producing good results.
The scale parameter is the only free user-defined parameter, and it is used for tuning the number of points to be removed.
5.2. Quantitative Analysis Parameter Selection
We chose the geometric error between the original and the simplified point cloud as a metric to evaluate the quality of the proposed simplification method, following Pauly et al. [
9]. Similarly, we measured the maximum error distance and the average error distance between the original point cloud,
, and the simplified point cloud,
. We denote the surface of
as
and the surface of
as
. The simplified error is estimated using the maximum error (16) and the average error (17) as follows:
For each point
, the geometric error
, is defined as the Euclidean distance between the sampled point
and its projection point
on the simplified surface approximation
. Since our method is mesh-free, we approximate the simplified surface
using a least squares plane (LSP). To estimate the LSP, we select a set of neighboring points
in
closest to
, using a Kd-tree data structure, and perform a PCA to obtain a regression plane (
), which represents the local approximation
, i.e.,
(
Figure 10).
Table 1 shows the test models with the original sizes and the sampled points with different sampling rates (the value shown is the arithmetic average of the number of points resulting from the different methods for each simplification rate).
Figure 11 shows the Gargoyle, Horse, and Nicolo models, as examples of
Table 1; the originals are shown in the left column, the models simplified at 5% are shown in the middle column, and the models simplified at 50% are shown in the right column.
Table 2 shows the different values of the parameter
for different simplification rates; we can appreciate how the variation of
does not clarify the relationship between the number of points to be simplified and its values in the table. This indicates that the algorithm is sensitive when its values change between different simplification rates, showing a weakness of the algorithm, which can be improved if the parameter
can be related to the density and distance between the points of the cloud to be simplified.
Table 3 shows the quantitative comparison between our method and the state-of-the-art methods.
Table 3 shows four simplification rates, i.e., 5%, 10%, 20%, and 50%. All five methods reduce the original number of points to a similar number of simplified points. Our method provides the most accurate simplification result of the five algorithms with respect to the average error metric
. However, considering the maximum error metric
, the Poisson disk mesh-based method is the best, closely followed by our method.
As shown in
Table 3, the CV and PSD methods produce similar results in terms of average surface error. The PSD method achieved relatively better results in terms of maximum surface error; however, a mesh structure must be used in the simplification. There are some practical applications where only the 3D coordinate information is available, which limits the applicability of the PSD sampling method. The SGR method and our SDBS method achieved the best results in terms of average surface error, but the SDBS outperforms all other methods.
We compared the SDBS method with the other methods in accuracy and running time.
Table 4 shows the running time and the number of preserved points of the proposed approach compared to six state-of-the-art methods. We simplified all the point clouds at a similar simplification rate with all the algorithms. We ran each method 10 times on each point cloud, and the average execution time is shown in
Table 4. The programming language is also shown. It is worth noting that the simplification rate of our method is the lowest in the study (the Bunny model was simplified from 35,945 points to 4517 points, and the Elephant model was simplified from 24,955 points to 2154). The SDBS keeps the balance between the sharp features and the point density in the data set.
5.3. Visual Comparison
To validate our method with respect to the visual quality of its results, we performed two experiments. The first experiment shows how the point cloud is affected in two scenarios: (1) when the normal coordinates are excluded from the feature vector and (2) when the coordinates of the point are excluded (
Figure 12). The second experiment compares our results with different state-of-the-art methods (
Figure 13 and
Figure 14). For rendering purposes, our point clouds were meshed using the Geomagic Studio software.
Figure 12b shows the result of simplifying the elephant using only the normal and curvature, excluding the point coordinates from the feature vector of each point. Compared with the original model (
Figure 12a), the simplification has overdecimated some areas (ears, tusk, and tube), producing holes in the reconstructed model. On the other hand, the lighting in the simplified model mimics the original one (red arrows).
Figure 12c shows the simplification results for the Elephant model using the point coordinates and curvature, excluding the normal from the feature vector of each point. Compared with the original, the point density is maintained, producing a better reconstruction of the model surface, but the lighting of the simplification does not improve, as shown in
Figure 12b (see highlighted details). Finally,
Figure 12d shows the simplification results for the elephant using the normal, the point coordinates, and the surface variation (curvature). The combination of features improves the results, as shown in the details in the lighting and the preservation of details such as the elephant eye.
To compare visually the results of the studied algorithms, we simplified the models to approximately the same number of points with all methods.
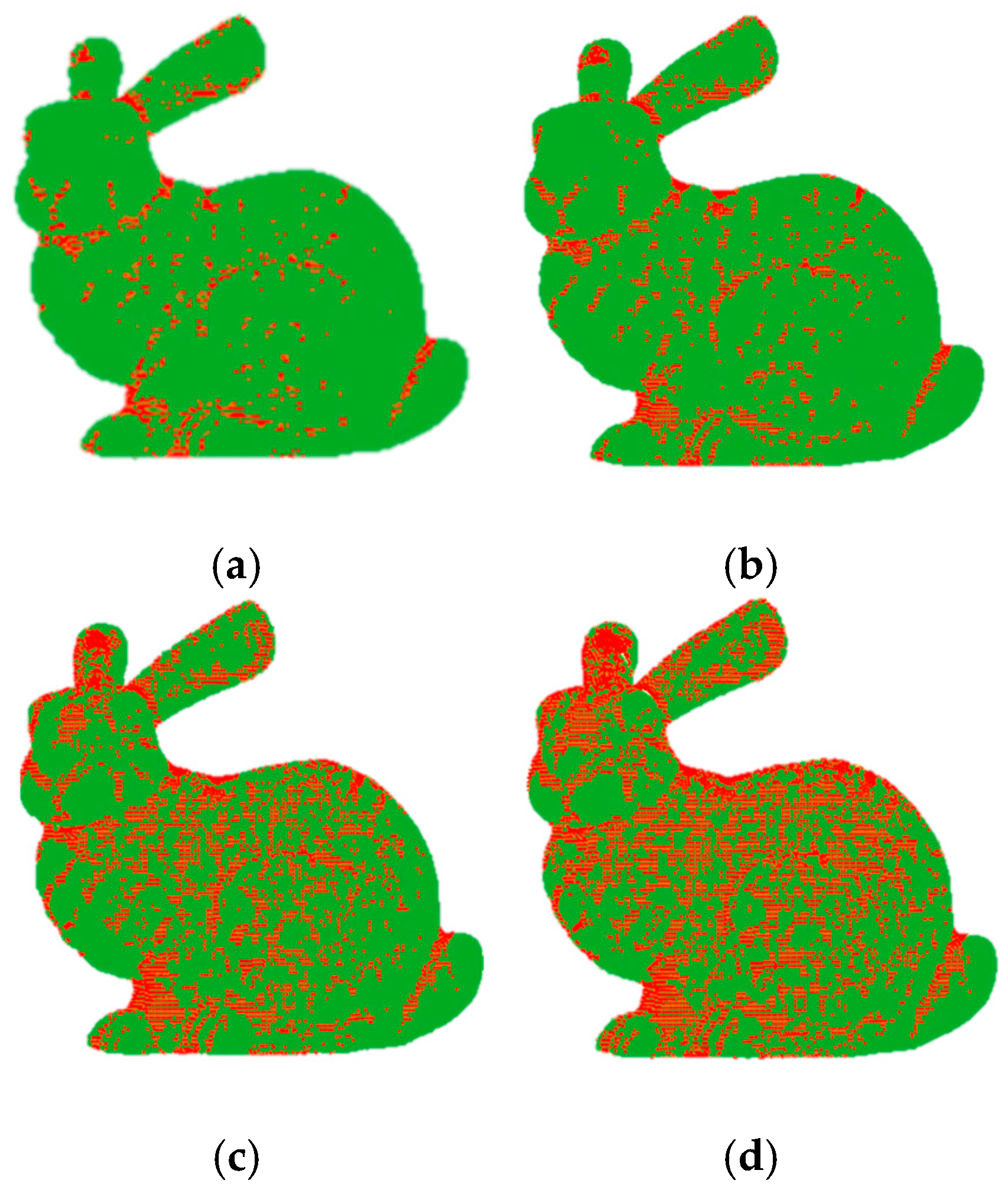
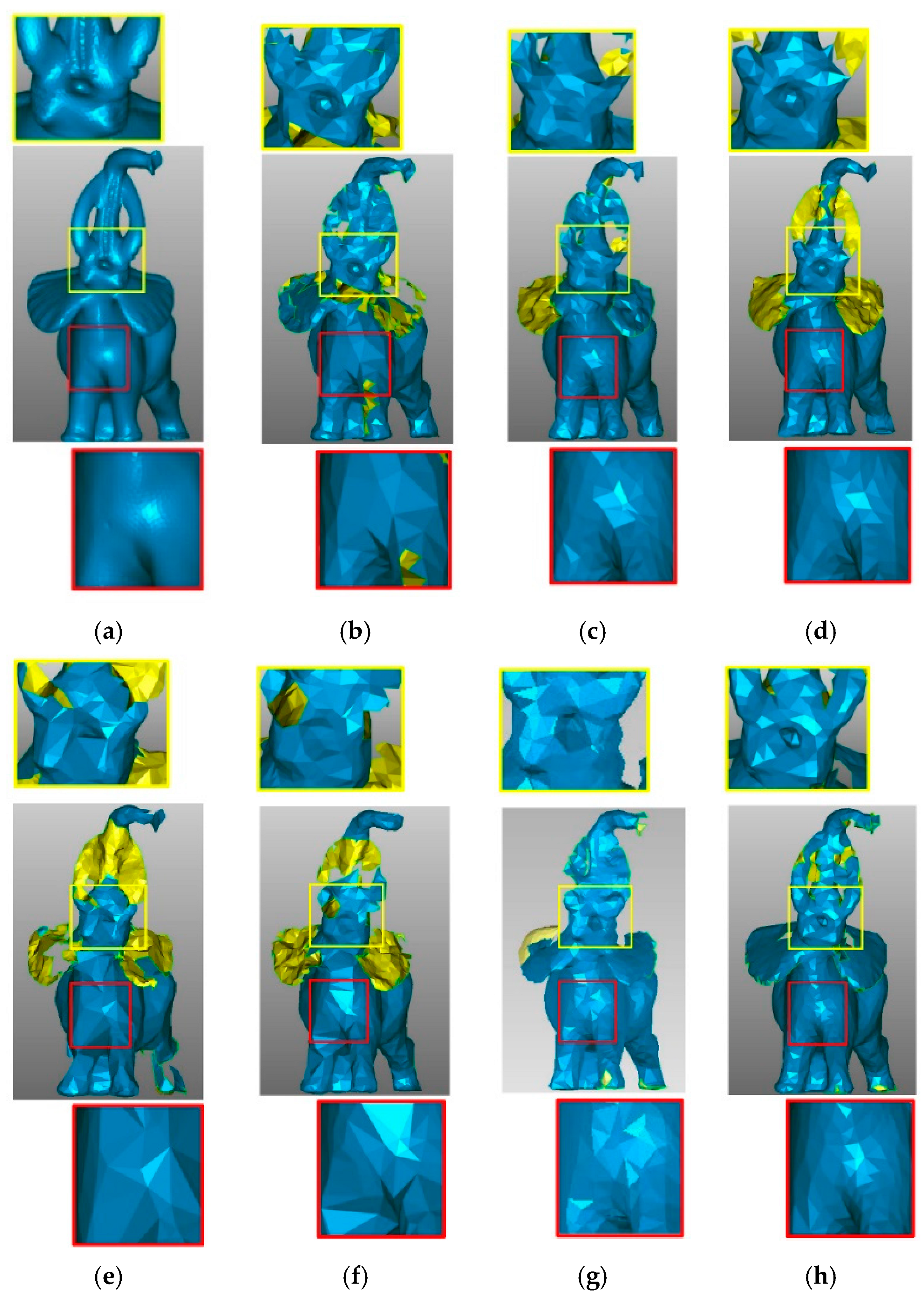
Figure 13 shows the simplified results of the application of different algorithms to the Bunny data set.
Figure 13b,c,e–g shows how more points are retained in curved parts, while fewer points are kept in smooth parts. The simplification result of
Figure 13d is uniform. All the methods present good reconstruction results but cannot reconstruct narrow features such as ears, except for the DFPSA method, which shows only a small hole. The proposed method (
Figure 13h) retains the most relevant features and details of the model, and the reconstruction does not present the problems observed with the other algorithms. The zoomed regions (nose commissure and paw) highlight how our approach better preserves geometric details of the original point cloud compared to previous methods, even when the simplification rate of our method is lower than the others.
Figure 14 shows the simplification result for the Elephant data set with a high simplification rate.
Figure 14c,d,g shows how the GRID, WLOP, and DFPSA simplification methods preserve few points in smooth regions and more points in feature regions such as legs, ears, trunk, and tusks. The HCS, FRGR, and FPUC simplification methods, as shown in
Figure 14b,e,f, present problems in retaining the global structure of the respective point clouds. Our method also preserves more points in feature areas, but it distributes the points evenly in smooth regions. Due to the high simplification rate, all algorithms present failures, but our method is the best in preserving the overall structure of the data set, as shown in the zoomed regions (mouth and chest), even when the simplification rate of our method is lower than the others.
6. Conclusions and Future Work
In this paper, we have presented a new method for point cloud simplification based on dictionary learning and sparse coding. The proposed method preserves the sharp features and produces evenly distributed points. Our method uses the normal vector, curvature, and the position of the points as a component of a feature vector. The feature vectors of all points of the cloud are the input for a dictionary learning and sparse coding process for saliency detection. We use the sparse representation of a signal to establish when a point is salient or not for the entire point cloud; i.e., points are considered salient if their feature vectors are reconstructed with many atoms from the dictionary, while points are not considered salient if the feature vectors are reconstructed with few atoms. The simplification is guided by global saliency using the sparse vectors resulting from the sparse coding process; we use its sparsity as an adaptive simplification ratio in different regions. The proposed method produces low simplification rates in salient regions (borders, corners, high curvatures, valleys) and high simplification rates in relatively planar regions while maintaining an appropriate density through an even distribution of points.
The robustness and efficiency of our approach are demonstrated by some experimental results that show that our method reduces the size of point clouds and retains the shape features without creating surface holes. Finally, the proposed method is compared with different state-of-the-art approaches, producing good simplification results and outperforming competing methods. As future work, we propose examining ways to automatically determine the choice of the regularization parameter and the size of the dictionary, S. Another future work is the mathematical demonstration of the interpretation when a point is considered salient or not salient and how to relate the δ directly with the number of points to be simplified.


 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}