1. Introduction
Forecasting is one of the pillars for decision support systems in different domains such as weather, web traffic, demand and sales, and energy. It can be defined simply as the rational prediction of future events based on past and current events, where all events are represented as time series observations [
1]. Time series forecasting (TSF) with reasonable accuracy is a necessary but quite tricky problem because it correlates many factors with an enormous amount of observations [
2].
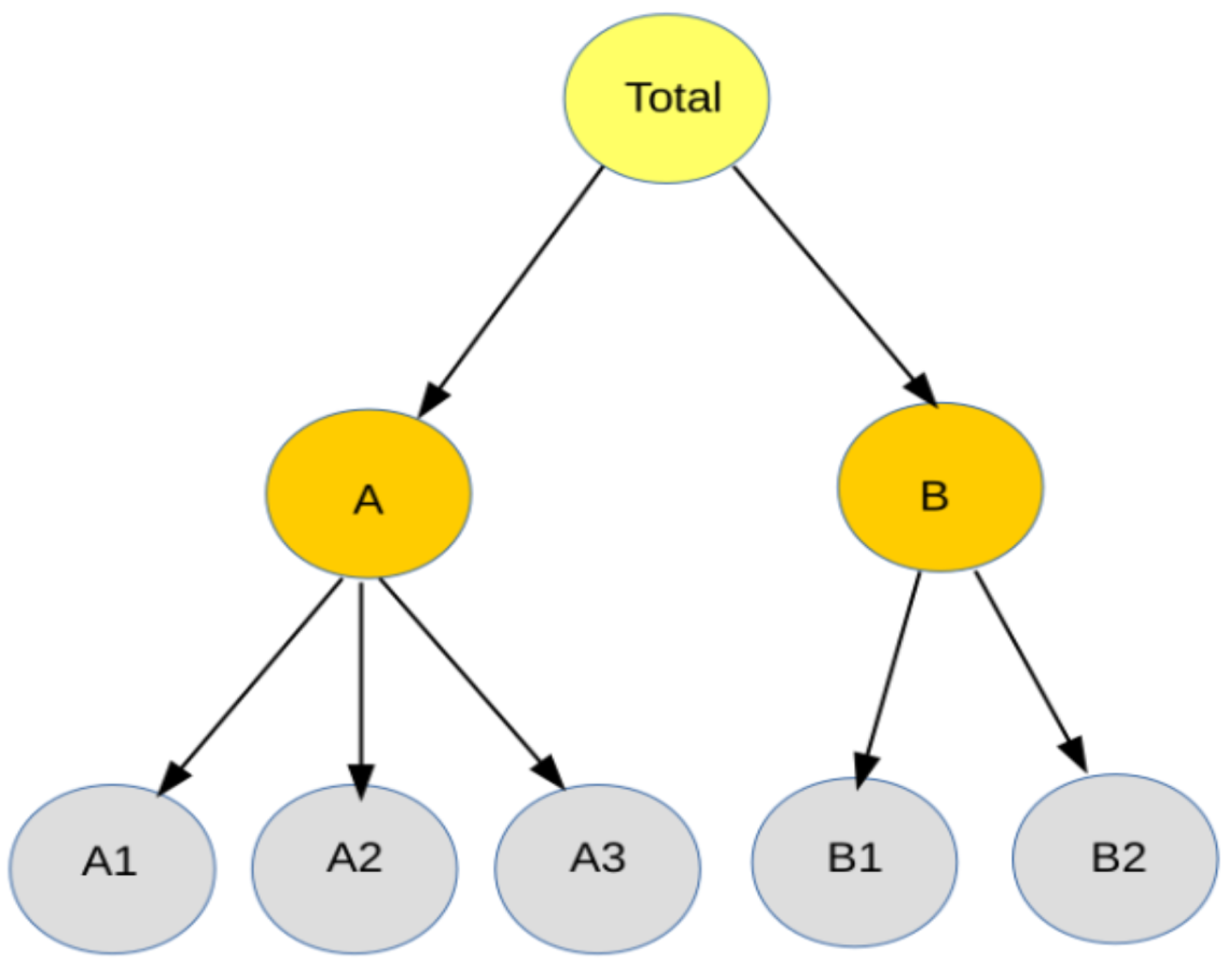
Many real-world applications exhibit naturally hierarchical data organization, with multiple time series on several levels based on dimensional attributes such as geography, products, or some other attributes. Forecasting through such a hierarchical time series (HTS) structure adds difficulty to the original TSF problem owing to ensuring the forecasting consistency among the hierarchy levels, a phenomenon called coherency [
3]. Coherent forecasts mean that the forecast of a time series in a higher level should equal to the sum of forecasts of the corresponding time series in the lower level. In other words, to ensure forecast coherency, we require the forecasts to add up in a manner that is consistent with the aggregation structure of the collection of time series [
4]. Therefore, it is often necessary to carry out a reconciliation step to adjust the lower level forecasts and to make them coherent or consistent in the upper levels [
5].
In the past two decades, several reconciliation procedures are presented to ensure coherent forecasts, including top-down, bottom-up, and a combination of both procedures called middle-out [
6]. These procedures generate what we can call “base” forecasts in different ways by separately predicting individual time series. Then, the “base” forecasts are reconciled according to the inherent hierarchical structure of the selected procedure. The bottom-up procedure starts by estimating the “base” forecasts for the time series at the bottom level in the hierarchy. Then, it implements a simple aggregation way to obtain the “target” forecasts at the higher levels of the hierarchy. On the contrary, the top-down procedure involves estimating the “base” forecasts only for the top layer of the hierarchy and then disaggregates it based on historical proportions of time series at the lower levels. The middle-out procedure estimates the “base” forecasts for the time series at the intermediate level and then implements both bottom-up and top-down procedures to perform the prediction through the hierarchy [
6].
Overall, it is not ultimately confirmed which procedure is more efficient than the other because every procedure focuses on a different aggregation level to yield forecasts [
7]. Researchers have attributed such instability to the tendency of these procedures to minimize the forecast errors without questioning the coherence of consecutive predictions. As a result, some important information that exists in other levels will be ignored [
8]. If we disregard the aggregation constraints, we could forecast all the time series in a group independently. Nevertheless, it is still doubtful that the produced set of forecasts is coherent [
5]. Another drawback in the existing approaches is that none of them takes account of the relationships and inherent correlation among series. Therefore, it is not easy to identify prediction intervals for the forecasts from any of these approaches [
6].
Toward optimal reconciliation, Hyndman et al. introduced an optimal combination approach that outperformed the approaches mentioned above [
6]. This approach assumes that the forecasting error distribution is typical as the aggregated hierarchical structure [
9]. It runs by estimating forecasts on all levels of the hierarchy independently. Then, it uses a regression model to optimally combine these forecasts to yield a set of coherent forecasts [
6,
9]. The generated forecasts add up appropriately across the hierarchy, are unbiased and have minimum variance amongst all combination forecasts [
3]. However, this approach is computationally expensive, particularly for large hierarchies, because it should estimate forecasts for all levels in the hierarchy [
10,
11]. In addition, the authors did not provide any justification whether the reconciled forecasts work well compared to the most commonly implemented approaches [
5].
As a common practice in all the approaches that mentioned above, the “base” forecasts are generated using either a statistical or empirical forecasting method depending on the aggregation level of focus [
12]. Standard statistical methods include autoregression integrated moving average (ARIMA), Box and Jenkins method, and exponential smoothing (ES) method [
13]. These statistical methods are static and often ignore the dynamics of the individual time series and the structure of grouped time series during computations. Consequently, they may fail to perform well if the corresponding groups of time series are subject to a time variation or any sudden change, as the case in energy load or supply chain applications [
14]. In addition, it was demonstrated that these methods failed to exploit the complete available information in the hierarchy, which influences the efficiency of the overall forecasting. Moreover, they lack a straightforward mean to determine an optimal reconciliation approach, which is crucial for hierarchical aggregation [
9].
Different machine learning algorithms were recently utilized to estimate the “base” and “target” forecasts and to derive the combination weights for the forecasts in the optimal combination approach. For example, Mahdi et al. [
14] used artificial neural networks (ANN), extreme gradient boosting (XGboost), and support vector regression (SVR) algorithms to estimate the proportions of time series through a middle-out approach. Spiliotis et al. [
12] suggested a machine learning-based method that allows for a nonlinear combination of the “base” forecasts more general than other linear methods. It estimates the “base” forecasts directly without conditioning that the complete information is utilized to generate reconciled forecasts for each time series. Shiratori et al. [
15] introduced an approach based on a forecasting model for each time series at the bottom level and then used a structured regularization step to combine the forecasts at the upper levels into the forecast of the bottom level. Mancuso et al. [
16] represented the disaggregation method as a nonlinear regression procedure instead of relying on forecast or historical proportions. Namely, they proposed a deep neural network (DNN) model that learns how to share the top level forecasts to the time series at the bottom level of the hierarchy, taking into consideration the characteristics of the information of the individual series and the aggregated series.
To the best of our knowledge, some machine learning-based reconciliation approaches adopted the top-down approach and exploited information only from the parent node. They ignore the rest of the nodes that could be beneficial for obtaining more accurate results, such as the system shown in [
14]. Some other machine learning-based approaches try to optimize the forecast accuracy in a linear coherence fashion, such as the system shown in [
5], which adopted an in-sample error method for the baseline forecasting. This approach may not be representative of out-sample accuracy [
12]. Overall, most machine learning-based reconciliation approaches are built to achieve coherency under particular assumptions to improve the overall prediction accuracy. An exception is the approach presented in [
12], which solved the problem of forecasts reconciliation in a general nonlinear fashion to enhance the overall performance across all levels of the hierarchy. However, this approach has a reservation of bias since it selects the forecasts to be combined and neglect other forecasts that may be useful. Nevertheless, all of these approaches still use traditional methods, such as ARIMA and ES, to generate the “base” forecast.
In the last two years, the first author of this paper developed a Deep Long Short-Term Memory (DLSTM) approach that can solve various forecasting problems using either univariate or multivariate time series data [
17,
18]. The excellent empirical performance of DLSTM motivated us to extend it to treat the hierarchical time series forecasting (HTSF) problem. In this paper, we develop the DLSTM in an auto-encoder (AE) fashion; from here, on we call it DSLTM-AE, taking full advantage of the hierarchical architecture for better time series forecasting. DLSTM-AE can work as an alternative approach to traditional and machine learning approaches that have been used to manipulate the HTSF problem. However, as demonstrated in [
18], training a DLSTM in hierarchical architectures requires updating the weight vectors for every LSTM cell, which is time-consuming and requires a large amount of data through several dimensions. Transfer learning strategy can mitigate the effect of this problem, particularly if we adopt it in a bottom-up procedure. The proposed approach runs as follows: First, we train the time series at the bottom level of the hierarchy using DLSTM-AE and generate the “base” forecasts. Then, we use (or transfer) the learned features of the “base” forecast to perform synchronous training to all time series at the upper levels of the hierarchy to estimate the “target” forecasts.
To demonstrate the efficiency of the proposed approach, we empirically compared its performance with several existing approaches using two different case studies using two different datasets. Namely, the Brazilian electrical power generation dataset [
19] and the Australian visitor nights of domestic tourism dataset [
20]. Using three different performance metrics, we compared our results with those reported by the authors of [
19,
20], respectively. The comparison among all approaches was based on two criteria: forecasting accuracy and the ability to produce coherent forecasts. Overall, the proposed approach attained the highest accuracy results among all reference approaches. Moreover, it produced more coherent forecasts through a straightforward scenario compared to reference approaches.
The DLSTM-AE procedure and its empirical results shown in the following sections highlight additional advantages of this approach. First, the DLSTM-AE utilizes all the information included in all time series in all levels of the hierarchy, contrary to reference approaches that may ignore useful information. Indeed, this is expected to enhance the overall forecasting performance of the approach. Second, the DLSTM-AE produces forecasts at each level of the hierarchy, which provides meaningful insights for decision-makers to make decisions at any moment during the operation, such as demand planning, production planning, energy crisis, etc. Third and in terms of the original LSTM properties, the DLSTM-AE inherently considers the relationship and temporal correlations among time series observations and automatically extracts many inherent useful features [
21]. Fourth, as the computations at the higher levels are performed in synchronous mode, this undoubtedly reduces the whole process’s computational cost.
Consequently, we can summarize our contribution in this paper as follows:
We developed a novel deep neural network model runs in a transfer learning scenario that significantly simplifies the forecasting through hierarchical architectures.
Our approach attained the highest forecasting accuracies among existing approaches.
Our approach produced more coherent forecasts within the hierarchy levels using a straightforward procedure.
The rest of the paper is organized as follows.
Section 2 briefly summarizes the standard time series forecasting problem and its related concepts. The elements and steps of the proposed approach are presented in
Section 3.
Section 4 shows the experimental settings and datasets used in this paper. The empirical results achieved using two case studies and related analysis are provided in
Section 5. Finally, an overall discussion and the paper conclusions are presented in
Section 6.
6. Overall Discussion and Conclusions
Forecasting through hierarchical time series has always been a challenging task for traditional approaches and various machine learning approaches. The challenge here is twofold; the first is to attain high prediction accuracy through the hierarchical architecture. The second is to ensure the forecasting consistency among hierarchy levels based on their dimensional features, a phenomenon called coherency. However, existing approaches exhibit good results addressing these two challenges, often showing instability in the overall prediction performance. This is because these approaches aim to minimize the prediction errors and to obtain good accuracy without questioning the coherence of consecutive predictions. As the granularity at which forecasts are needed increases, existing approaches may not scale well.
This paper addressed the hierarchical time series forecasting problem by extending our recent achievement, namely, the DLSTM model. Here, we reproduced the DLSTM model in auto-encoder (DLSTM-AE) fashion and implemented it in a transfer learning scenario. The proposed approach runs as follows: we first train the time series of the bottom level using DLSTM-AE to generate the “base” forecasts. Then, we freeze the weight vector of the “base” models and transferred the learned features to achieve synchronous training to the time series of the upper levels in the hierarchy.
Toward a fair evaluation, we compared the performance of the proposed approach with several existing approaches using two case studies belonging to different domains. The evaluation was based on two criteria: forecasting accuracy and the ability to produce coherent forecasts. The performance of all contenders was evaluated using three different performance metrics through multi-step ahead prediction mode. In both case studies, the proposed approach attained the highest accuracy results compared to other counterparts. We can attribute the goodness of the proposed approach to the use of DLSTM in generating the “base” forecasts at the bottom level compared to the existing approaches that use traditional statistical techniques, such as ARIMA and ES, to generate it. In this way, the individual forecasts at the bottom level are utilized on higher hierarchy levels to rapidly generate global forecasts without conducting a time-consuming parameter estimation as in existing approaches.
Moreover, the DLSTM-AE considered the relationship and temporal correlations among time series data and automatically extracted many inherent useful features that helped to generate the “target” forecasts. In contrast, most traditional techniques are static and ignore more helpful information. With the help of transfer learning, we significantly reduced the time for calculating the forecasts and substantially increase the forecasting efficiency for the higher level entities. The superiority of the proposed approach was not noticed only for the forecasting accuracy but also for the production of coherent forecasts. Using a standard performance metric, we empirically found that the difference between the forecast of a time series at a higher level and the sum of the corresponding time series forecasts at a lower level is tiny. This means that the proposed approach generated more coherent and consistent forecasts compared to reference models.
For future work, we plan to ensure forecast coherency at all levels of the hierarchy by running the proposed approach in a cross-temporal framework. Besides coherency, this framework will reduce the effect of the outliers and enhance the signal-to-noise ratio at aggregated lower frequencies of the time series while mitigating loss of information. In addition, despite describing our approach exemplarily through the tourism and energy domains, it can be easily adapted to other domains such as supply chain, sales promotion, and retail.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}