1. Introduction
With the rise of machine learning, especially deep learning, more and more data-driven algorithms have been proposed and applied successfully in different fields in the last few years [
1,
2,
3]. Similarly, data-driven methods are increasingly suggested to deal with problems in the field of machine health monitoring [
4], which has great importance in modern industry.
For example, Atoui et al. [
5] presented Bayesian network for fault detection and diagnosis, Rajakarunakaran S et al. [
6] proposed artificial neural networks (ANN) for the fault detection of the centrifugal pumping system, and Ivan et al. [
7] suggested a novel weighted adaptive recursive fault diagnosis method based on principal component analysis (PCA) to reduce the false alarm rate in processing monitoring schemes. Recently, as deep learning is rapidly developing, artificial intelligence methods are considered to handle the fault detection and classification in rolling bearing elements, e.g., autoencoders [
8] and convolutional neural networks (CNN). Li et al. [
9] proposed a bearing defect diagnosis technique based on a fully connected winner-take-all autoencoder. Jafar Zarei [
10] proposed a pattern recognition technique for fault diagnosis of induction motor bearings via utilizing the artificial multilayer perceptron neural networks. Olivier Janssens et al. [
11] introduced feature learning means for condition monitoring based on convolutional neural networks to obtain signal features for bearing fault detection. Although many studies have been conducted, most of them are only effective under a large amount of labeled data.
Through a brief review, it is obvious that most methods are only confirmed in theory, and few are able to be applied in industry [
12,
13]. In a real industry situation, as machines usually work in a healthy state, it is quite a difficult task to determine whether a fault has occurred during the data collection. Moreover, even when the equipment breaking down is known, it is difficult to point out the definite fault types disassembling and inspecting the components such as bearings and ball screws in a machine, being time and labor-consuming tasks. Additionally, the real machine always works under various working conditions. Thus, the collected signals are combined with different data distributions. Those scenarios in the industrial applications will seriously impact the performance of data- based fault diagnosis.
To overcome problems of different working conditions, some researchers proposed increasing the generalization ability of the algorithms, which are named domain adaption techniques. For instance, Zhang et al. [
14] proposed a deep neural network with high diagnostic accuracy in diagnosing signals with high noise and signals from different loads. In their work, the authors suggested that the high-level features of data from the different working conditions have a more similar distribution and are less affected by noise. Moreover, Zhu et al. [
15] used capsule net to extract more general features from the time-frequency spectrum and achieved higher diagnosis accuracy when dealing with data from different loads. With such improvement strategies, artificial neural networks have been proven to be a potential tool to deal with industry data. However, the above methods only focus on the variation between working conditions (e.g., speed, loads) on one machine, and they cannot handle the huge variations of mechanism between different types of equipment.
Transfer learning theory has been introduced to machine fault diagnosis in order to improve domain adaption ability among different machines. Transfer learning aims to reduce the distribution discrepancy of diverse domains, as data from the target domain have similar knowledge but different distribution compared to the source domain. For example, Lu et al. [
16] presented a deep model-based domain adaptation method for the machine fault diagnosis. A gearbox dataset collected under different operation conditions was used to test the performance of the proposed method. Wen et al. [
17] set up a new deep transfer learning method for fault diagnosis. The validation dataset was acquired from a bearing testbed operating under different working conditions. Xie et al. [
18] proposed a transfer analysis-based gearbox fault diagnosis method. The performance of the presented method was verified by a gearbox dataset obtained under various operation conditions. Guo et al. [
19] proposed deep transfer learning-based methods using maximum mean discrepancy and adversarial training techniques together to regularize the discrepancy between different domains. Sandeep et al. [
20] presented a ConvNet-based transfer learning method for bearing fault diagnosis with varying speeds. Hasan et al. [
21] proposed a transfer learning fault diagnosis framework using 2D acoustic spectral imaging-based pattern formation method. Zhang et al. [
22] introduced hybrid-weighted adversarial learning to address the domain adaptation problem. Meanwhile, Zhang et al. [
23] also utilized federated learning to facilitate the mechanical fault diagnosis. However, the above transfer learning methods took advantage of enough labeled data. Unfortunately, labeled signals from the practical industrial machine are rare and hard to collect.
As the most critical issue during the process of transfer learning, modeling and optimizing the discrepancy between different domains are the core of the proposed method. As a stable and continuous measurement, Wasserstein distance has displayed its superiority in different applications, e.g., image generation [
24,
25]. Thus, in this paper, we propose a new method with excellent domain adaptive ability based on Wasserstein distance (WDA) in order to deal with machine fault data from different machines. Cosine similarity and the Kuhn–Munkres algorithm are introduced to improve transfer effects. The contributions of this paper mainly lie in the following two parts:
(1) To achieve classification on unlabeled signals, we propose a transfer learning fault diagnosis method named WDA, which makes use of labeled signals from different machines to help the classification of signals. In WDA, Wasserstein distance is applied to manage the gaps between two distributions, during which we utilize cosine similarity to measure the discrepancy between feature embeddings. Moreover, Kuhn-Munkres algorithm is introduced to directly optimize the Wasserstein distance.
(2) We carried out extensive experiments to validate the effectiveness of the proposed method on various transfer scenarios. Meanwhile, to better illustrate the training process of high-dimensional feature embeddings, we also visualized the whole training process.
The structure of this paper is organized as follows. In
Section 2, we introduce the basic conception of transfer learning, Wasserstein distance, and the corresponding Kuhn-Munkres algorithm. Following that, the proposed method and optimization algorithm are discussed in
Section 3. Then, the experiments are carried out in
Section 4 to verify the proposed method. Finally, the conclusion is drawn from the above experiments.
2. Related Works
In the field of machine learning, transfer learning is proposed to deal with the differences between the signals from the source domain and target domain, while Wasserstein distance is a powerful criterion of the discrepancy. However, the calculation of Wasserstein distance belongs to the general assignment problem. Yet, in most of the research work [
26,
27,
28], there has hardly been one direct calculation of it. Thus, a brief introduction of transfer learning, Wasserstein distance, and the solution of the general assignment problem (GAP) are helpful to know about the development and the limitation of recent works.
2.1. Transfer Learning
Transfer learning is different from many other traditional machine learning methods, which are established under the assumption that training data and test data are drawn from the same distributions. To better illustrate transfer learning, we introduce two important conceptions: domain and task, as follows [
29].
To begin with, domain D includes two key components: feature space and marginal distribution , where means that is a set containing samples from feature space , e.g., the signals collected from the machine in different health conditions. Then, a task consists of two components: a label space and an objective function , corresponding to the health conditions of signals and classification algorithm. Generally speaking, the objective function could not be directly observed. However, it could be learned from training data, which consist of pairs . with the notion of source domain data and target domain data . The transfer learning could be defined as the following:
Given source domain and learning task , a target domain and learning task transfer learning aims to help improve the performance of the predictive function in through using the knowledge in and , where or .
In the field of fault diagnosis, source and target domains usually are different. However, the tasks are equivalent, i.e.,
. This kind of problem is also called domain adaptation, belonging to transductive transfer learning [
29,
30]. For the transfer learning problems, there are four different approaches to solve them: instance transfer, feature representation transfer, parameter transfer, and relational knowledge transfer. Among them, the feature representation transfer is a widely used transfer learning method in transfer fault diagnosis [
18,
19,
31,
32,
33]. Moreover, there are currently two methods to bridge the gap between two distributions: feature extractor regularization, applying regularization terms on feature extractor to obtain features extracted from different domains in similar distributions, or using adversarial training methods to close two distributions.
Firstly, maximum mean discrepancy [
34,
35] and Wasserstein distance are widely used to measure discrepancies in domain adaptation transfer learning. They are used to regularize the output feature of the feature extractor to obtain equivalent marginal distribution. Secondly, some adversarial training methods such as DANN [
36] are also proposed to narrow the gap between source and target domain. Most of them use adversarial training techniques in artificial neural networks to manage the gap of two different distributions. However, these training methods suffer problems, e.g., those methods are hard to train [
37,
38] and converge to a high-performance result. Thus, a high accuracy method is badly needed.
2.2. Wasserstein Distance
Wasserstein distance, also called earth mover’s distance, is a metric to measure the discrepancy between two distributions, and it is widely used in domain adaptation, e.g., WGAN [
24] and BEGAN [
39]. Wasserstein distance is generally based on a way that transforms one distribution to the other with minimal cost.
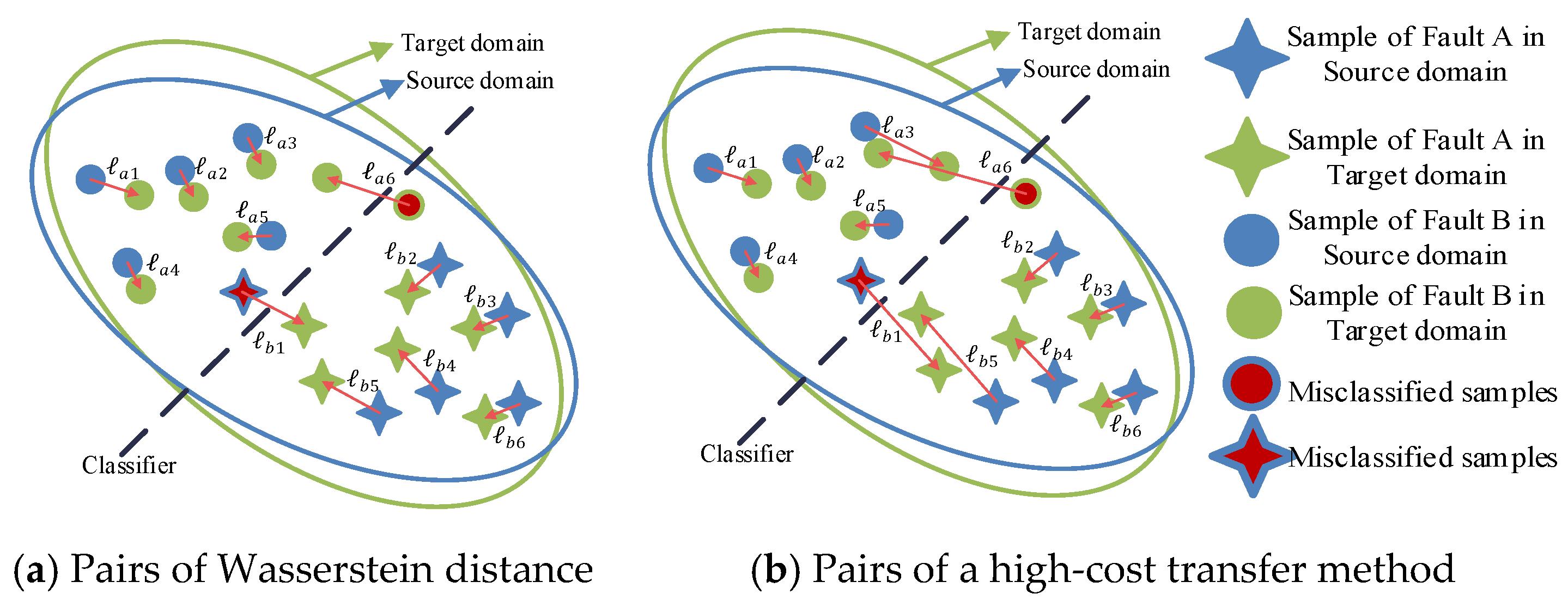
As shown in
Figure 1a, different discrepancies of two domains are represented, which could also be considered as the cost of transporting distribution from one domain to the other. We define the transporting cost as:
where
,
denote the numbers of samples of different fault types, and
represents a function measuring the difference between two samples, which usually is L2-norm or L1-norm. As shown in
Figure 1b, Wasserstein distance (noted as
) is used to transport the feature from the source domain to the target domain with minimal cost. The other transport method, e.g.,
, shown in
Figure 1b, is higher than
.
The formula of Wasserstein distance (
) is shown as:
From the above equation, we can see that the Wasserstein distance is a low bound of the cost to transform a distance between two distributions. Berthelot et al. also proposed BEGAN to optimize the lower bound of Wasserstein distance to achieve better performance on image generation [
39]. Note that all the above methods are unsupervised methods. Different from supervised or semi-supervised methods, unsupervised methods do not care about the similarity of distributions of the input and output domains. However, it would remain a huge problem, especially in the beginning training stage, if the discriminator is extremely unstable. Moreover, it is difficult to use it to regularize the feature extractor. Moreover, the discriminator could only be said to safely match the 1-Lipschitz function in the features that already are trained with the discriminator. That is, with the training process going on, the distribution of the high-level features may change, and that discriminator may not correctly calculate the distance between features from two domains. Thus, the methods based on adversarial training struggle to achieve high performance.
2.3. General Assignment Problem and Kuhn–Munkres Algorithm
The calculation of Wasserstein distance belongs to a general assignment problem (GAP) while the samples of two distributions are equal. Considering that there are
samples from source domain
and
samples
from target domain, without loss of generality, we assume that
. Any target samples
could be assigned to the source
. Each pair
has a cost
to transfer from
to
. The task is to assign
target samples to
source samples with the minimal cost, which is also the Wasserstein distance between two distributions. Moreover, the assignment problem could be formulated as the following optimization problem:
The K-M algorithm [
40] could be implanted through different versions: graph [
41,
42] or matrix [
43]. Unlike the adversarial learning-based methods, which utilize discriminator to approximate Wasserstein distance of two distributions [
26,
28], in this section, we introduce the K-M algorithm through graph perspective, which has been applied to the applications such as multi-objective optimization [
44] and role transfer [
45]. Considering a bipartite graph
, where
means the edges of pairs
and
, we introduce the following three definitions:
Definition 1: Neighborhood: the neighborhood of a verticesis the setwith all vertices sharing edges with; similarly, the neighborhood of a setis, whose all vertices are sharing edges with any vertices in.
Definition 2: Feasible label: it is a function, which satisfies the following condition:
Definition 3: Matched/exposed: considering a match, the vertexis called matched if it is a vertex in. Otherwise, it is exposed.
Meanwhile,
denotes the subgraph of
, which contains those edges that perfectly satisfy the feasible label, such as the following:
Moreover, contains all the vertices of . The K-M Algorithm 1 for solving the assignment problem is shown below.
| Algorithm 1. Kuhn–Munkres Algorithm |
| Input: A bipartite graph , corresponding edge weights |
| Output: the perfect matching M. |
| Step 1: Generate initial labeling and match in |
| Step 2: If perfect, stop. Otherwise, pick a free vertex . Set ,. |
| Step 3: If , update labels (forcing ) with following Equations (6) and (7)
|
|
|
| Step 4: If , choose :
|
| If free, is augmenting path. Augment M and go to 2
|
| If matched, say to , extend alternating tree: , . Go to |
The K-M algorithm can efficiently address assignment problems, especially small-scale ones, e.g., transfer between two mini-batch samples. Meanwhile, Wasserstein distance as a useful divergence to measure the distance between two distributions has been widely used in the field of transfer learning. However, the performances of these methods leave much to be desired. Most of them used the approximation form of Wasserstein distance instead of calculating it directly. Actually, the calculation of Wasserstein distance is an assignment problem that could compute through the K-M algorithm. Thus, we proposed a novel method using the K-M algorithm to address the discrepancy measurement of transferring between two domains.
3. Proposed Method
In this section, the proposed Wasserstein distance-based domain adaptive neural network (WDA) is discussed. The architecture of the neural network and the objective of WDA are introduced.
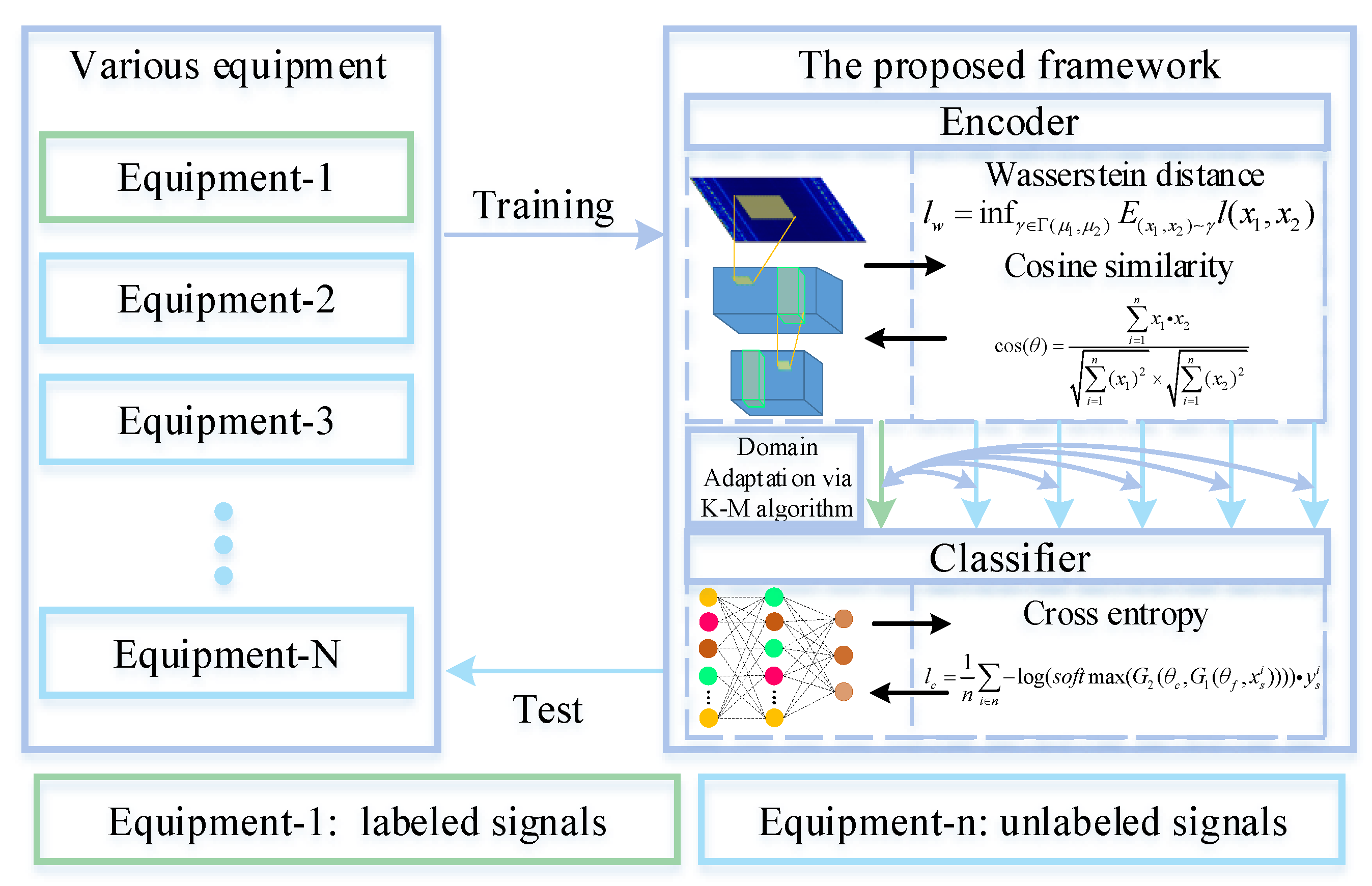
The framework of the proposed method is shown in
Figure 2. Meanwhile, the detailed architecture is shown in
Figure 3. WDA is composed of two parts: CNN (feature extractor) and a fully connected layer to extract features (noted as
), and a full-connected layer (classifier) noted as
. The aim of CNN is to extract high-level features from input data. Before high-level features are fed into the classifier, Wasserstein distance is used to regularize the features from two different domains. Thus, the CNN could extract features from different domains with similar distributions. Finally, the classifier is used to predict the health conditions of different signals.
3.1. Network Architecture
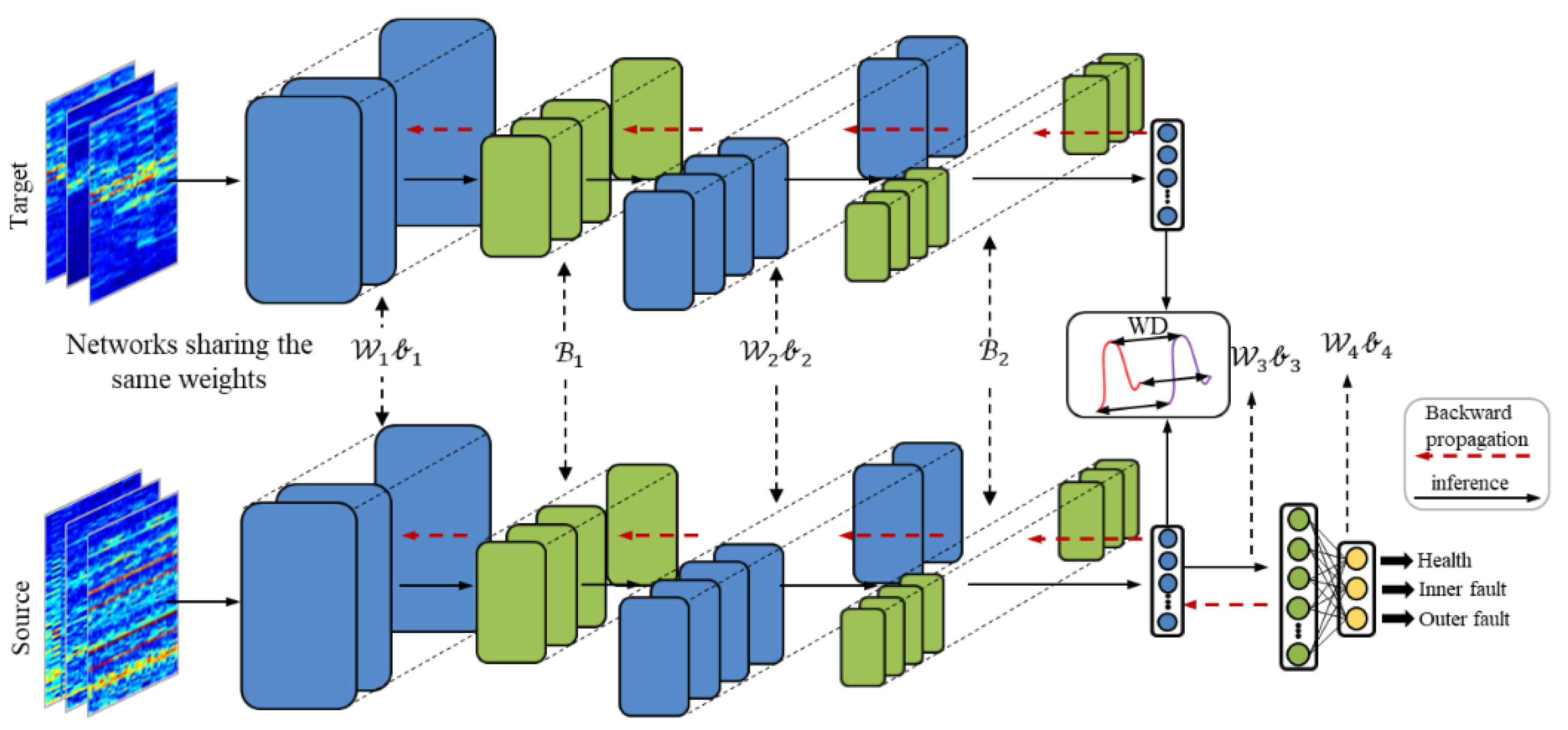
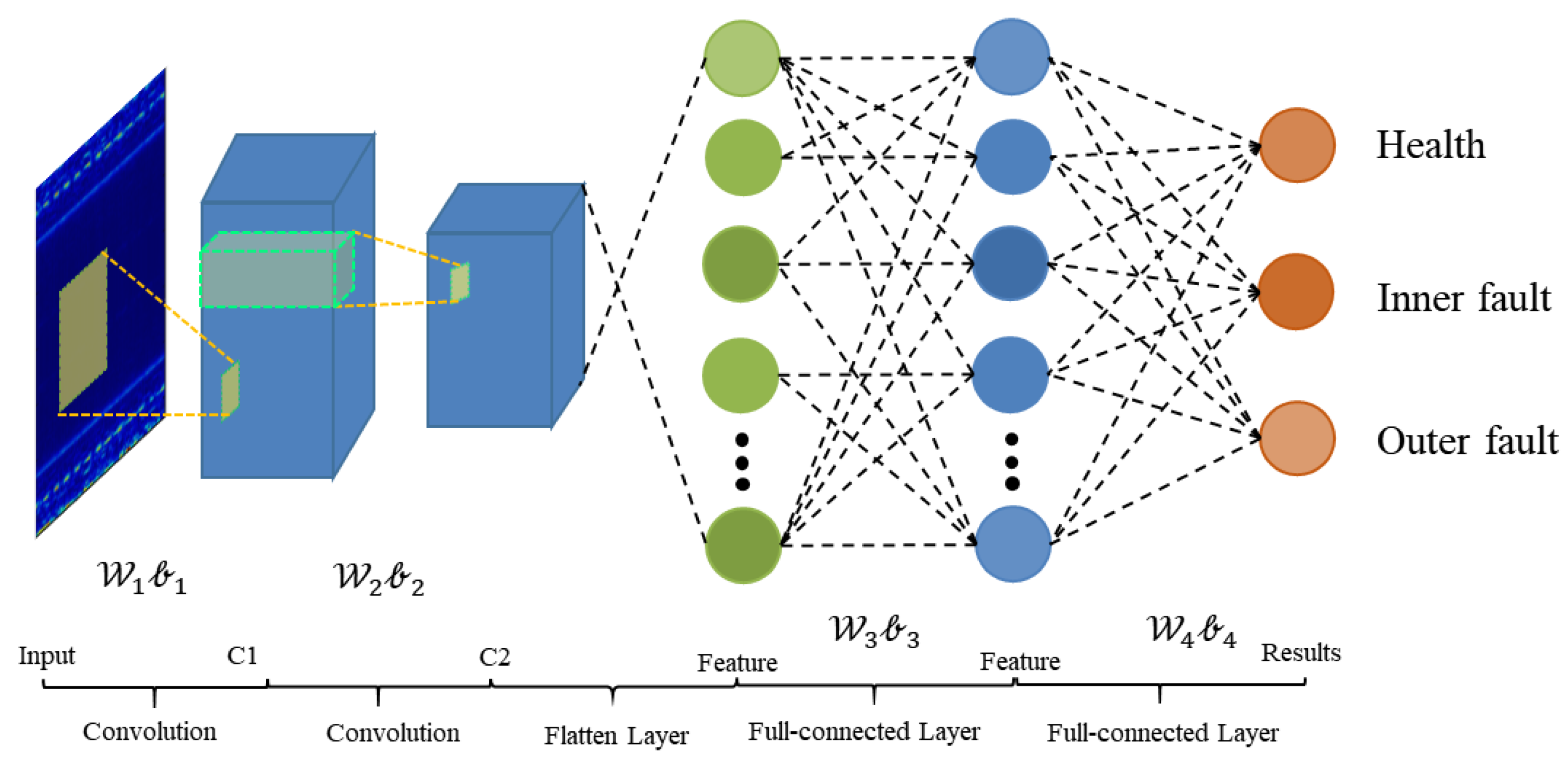
The architecture of WDA is shown in
Figure 4. It contains two parts: feature extractor and fully connected classifier.
As shown in
Table 1, there are essentially 12 layers in the proposed WDA. The feature extractor block contains two Conv-BN-Pooling-activation modules and a full-connected layer. In addition, the classifier contains only one full-connected layer to predict the health conditions of input data. The details of WDA are shown in
Table 2. Due to the different conditions of these methods, the ranges of labels vary from condition to condition, e.g., in some datasets, they are health, inner fault, and outer fault. However, in other datasets, there are four fault types: health, inner fault, outer fault, and rolling ball fault, where
means the number of classes of the models, and it should be 3 or 4.
3.2. Objective of WDA
In the proposed WDA, the loss function consists of two parts: classification loss () on the source domain and domain adaptive loss () between source and target domains . The classification loss aims at reducing the classification error on the source domain, and the domain adaptive loss aims to bridge the gap between the source domain and target domain. In the following section, they are introduced separately.
3.2.1. Classification Loss
Classification loss of WDA is a cross-entropy loss set as Equation (8), where softmax is described in Equation (9). As shown in Algorithm 1,
represents the feature extractor and
represents the classifier. Note that classification loss is only acted upon a source domain data whose labels are known.
3.2.2. Domain Adaptive Loss
Usually, for the semi-supervised problems, most methods want to regularize the feature extractor to obtain the features of source and target domains in exactly the same distribution. However, it is too strict for transfer learning categorical models. Actually, for the classifier, especially the linear classifier, the real concern is the pattern of the features (e.g., orientation of features). We demonstrate it through the following equation:
As shown in Equation (10), a linear classifier, which is designed to classify output features from a feature extractor, is present to explain the mechanism, where
indicates the weights of classifier,
means the bias of the classifier, and
indicates the input feature of the classifier. If the label of the feature
is
, Equation (11) would be established:
As we utilize the ReLu activation function, there is an interesting characteristic that
(for
,
). From Equation (12), we can see that if the label of the feature
is
, the prediction of feature
in the same orientation with
is also
, that is:
Equation (12) shows that the scale of features actually does not affect the classification result. Thus, the traditional ways are limited by using the L2-norm to measure the disparities between two variables. It is noted that cosine similarity calculates the orientation divergence of two vectors, which focuses more on the output pattern. Thus, for the feature extractor, we could use the cosine similarity to measure samples from different domains and change Wasserstein distance as:
where
is cosine similarity from feature
, shown as the following:
Once the objectives and architecture of WDA are established, the optimization of the proposed method is introduced in the following section.
3.3. Optimization of WDA
Following the establishment of the architecture and objective of WDA, the training algorithms are introduced in this chapter. The optimization algorithm is shown in Algorithm 2.
| Algorithm 2. Training WDA with ADAM optimization method= number of categories |
| Initialize: initial WDA feature extractor parameters and classifier parameters |
| For the number of training iterations, do: |
| • Sample minibatch of samples , from source domain signals distribution , from target domain . |
| • Extract feature from two different domains with two shared weights feature extractors through Equation (15).
|
| • Calculate the cost matrix between the high-level features from source and target domains (Equation (16)).
|
| • Use the K-M algorithm in Table 2 to address the assignment problem of cost matrix . |
| Input: bipartite graph,
|
| Output: permutations. |
| After obtaining optimal permutations , calculate Wasserstein distance :
|
| • Calculate cross-entropy classification loss on the source domain.
|
| • Calculate cross-entropy loss on the source domain. |
| • Calculate loss.
|
| • Backward propagation of , getting the gradients of parameters and updating the parameters ,.
|
| end |
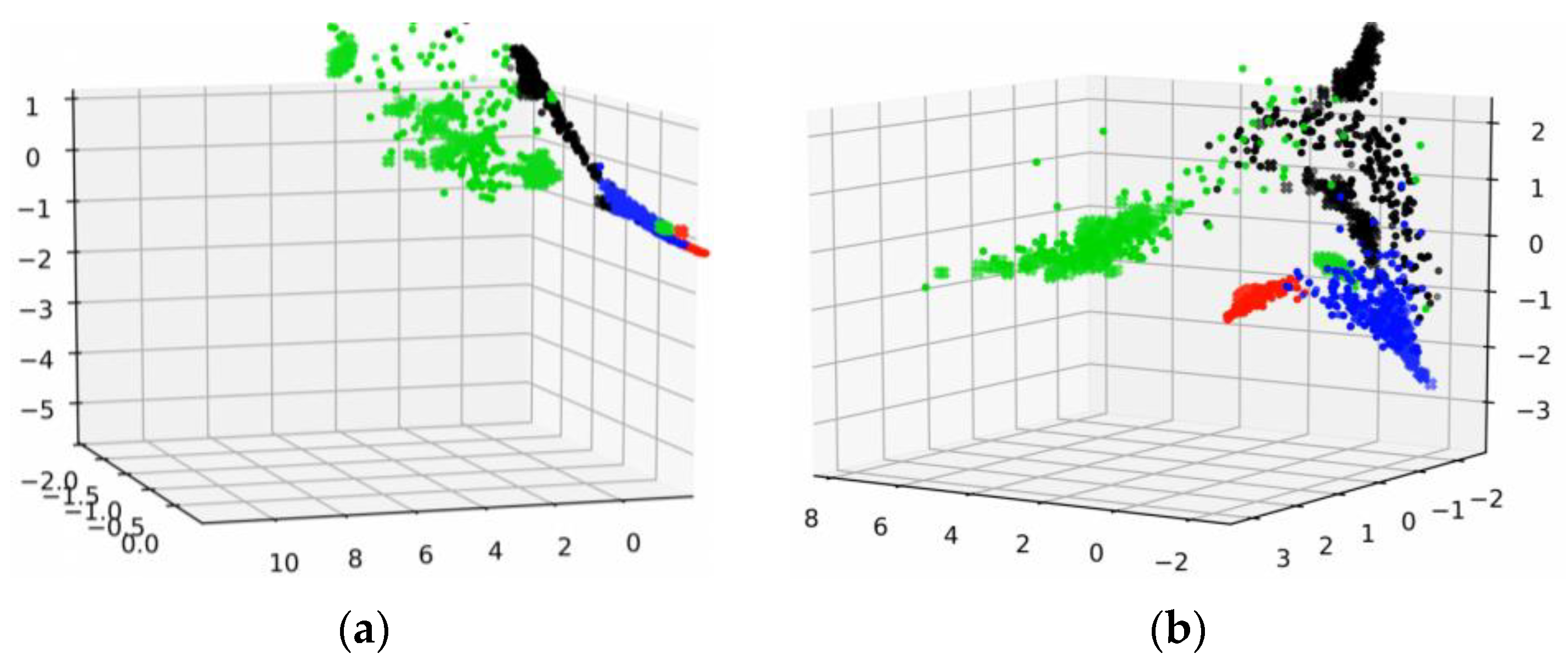
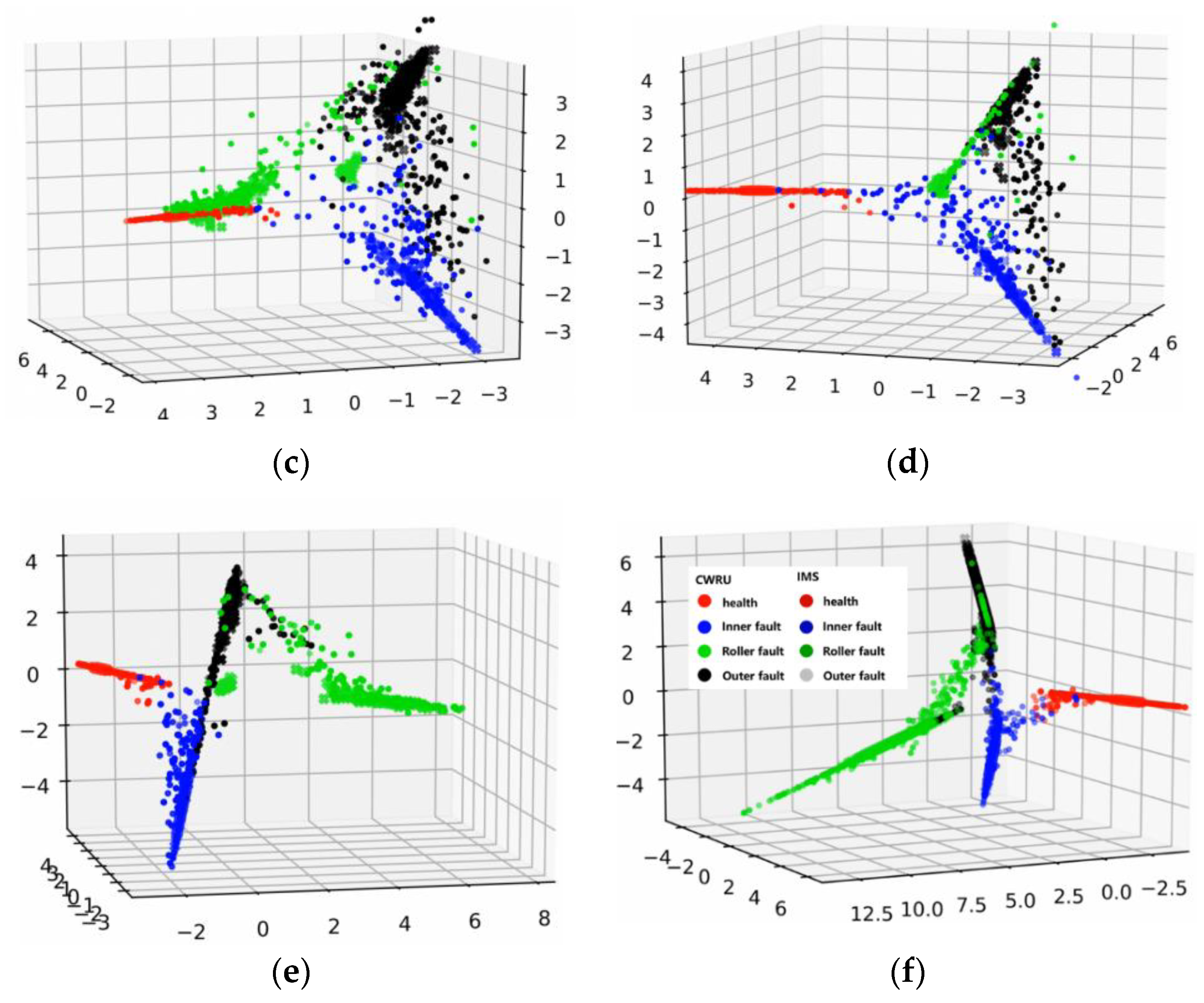
Moreover, in order to verify the choice of cosine similarity, we carried out experiments that contain feature visualization and comparisons with state-of-the-art domain adaptive transfer learning methods.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
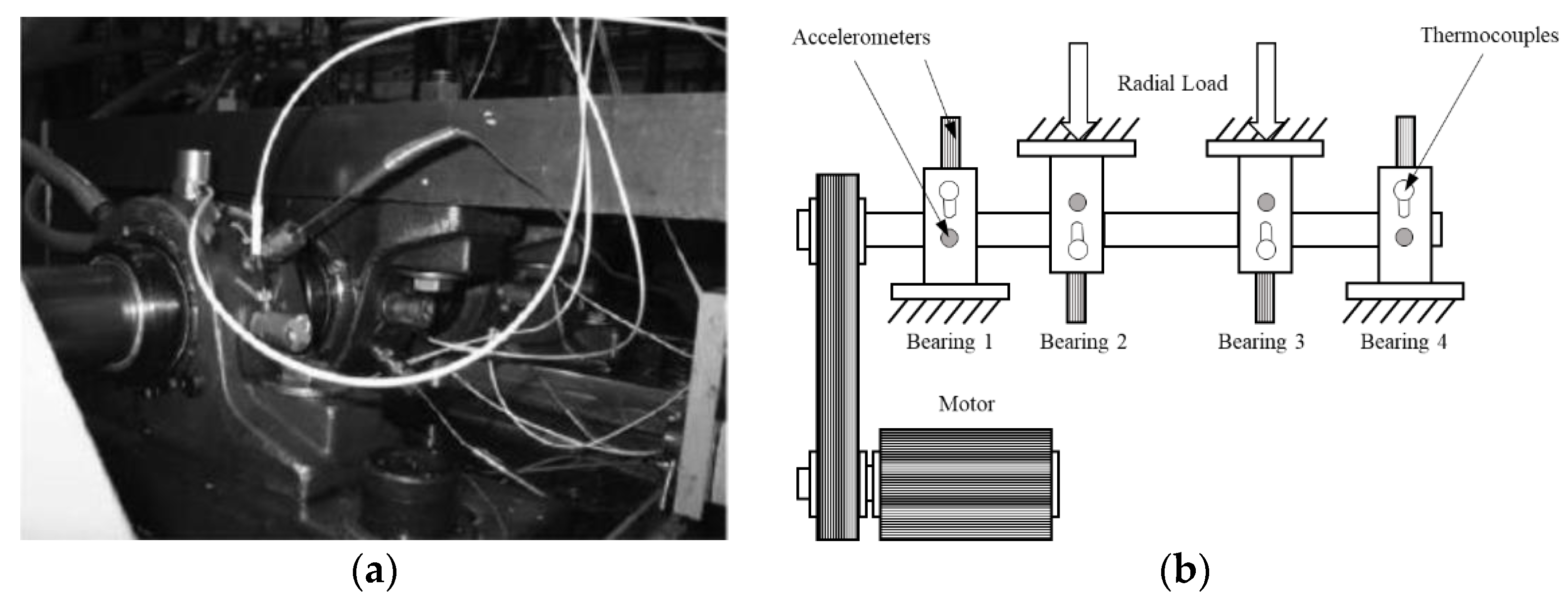{kind=link}
{kind=link}
{kind=link}
{kind=link}
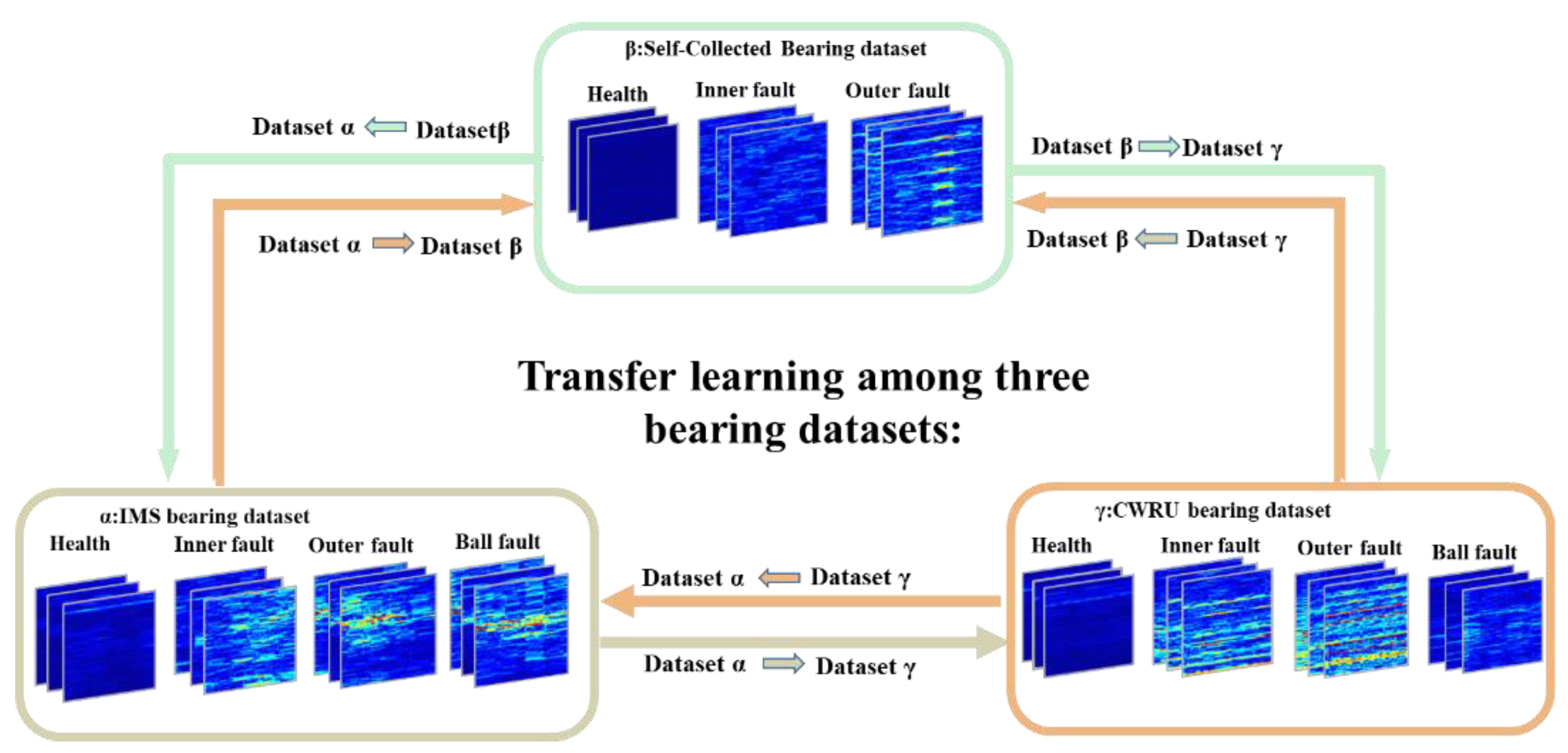{kind=link}
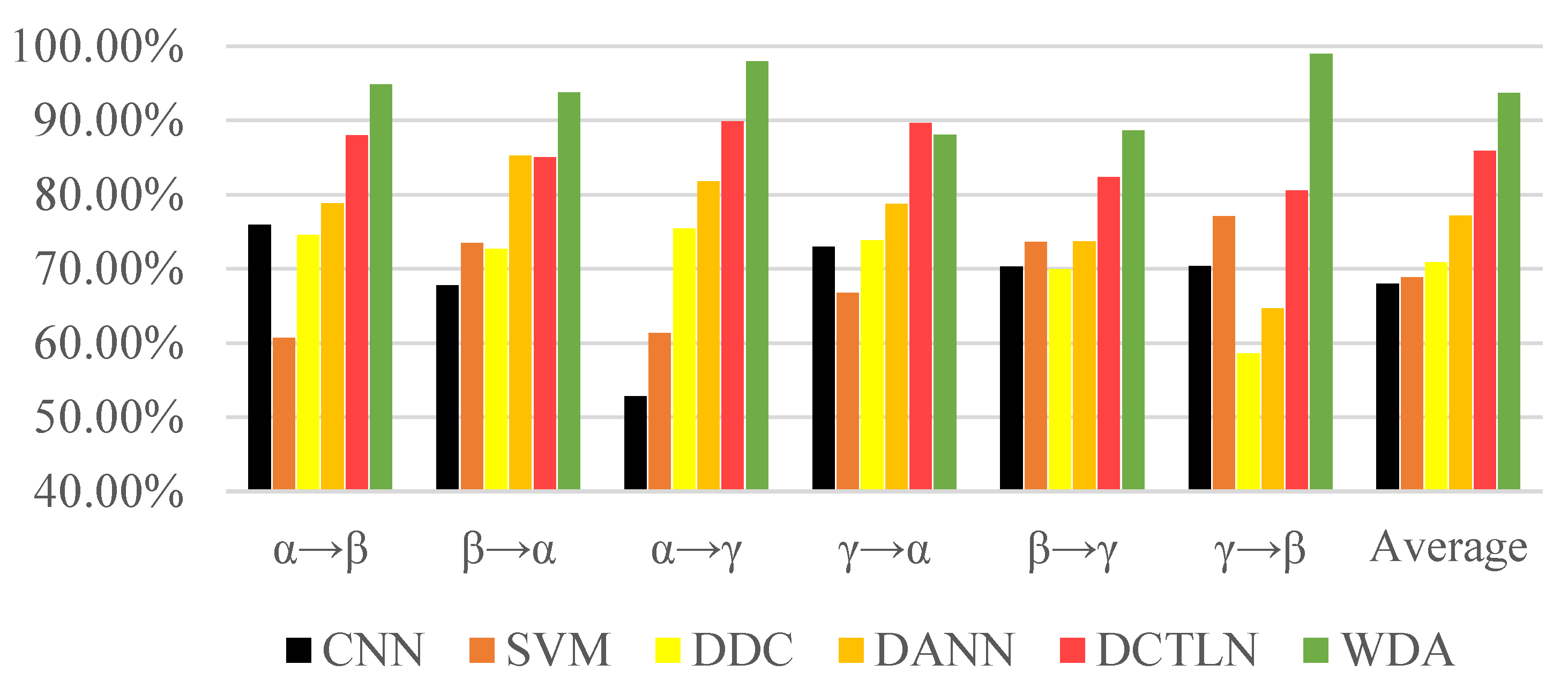{kind=link}
{kind=link}
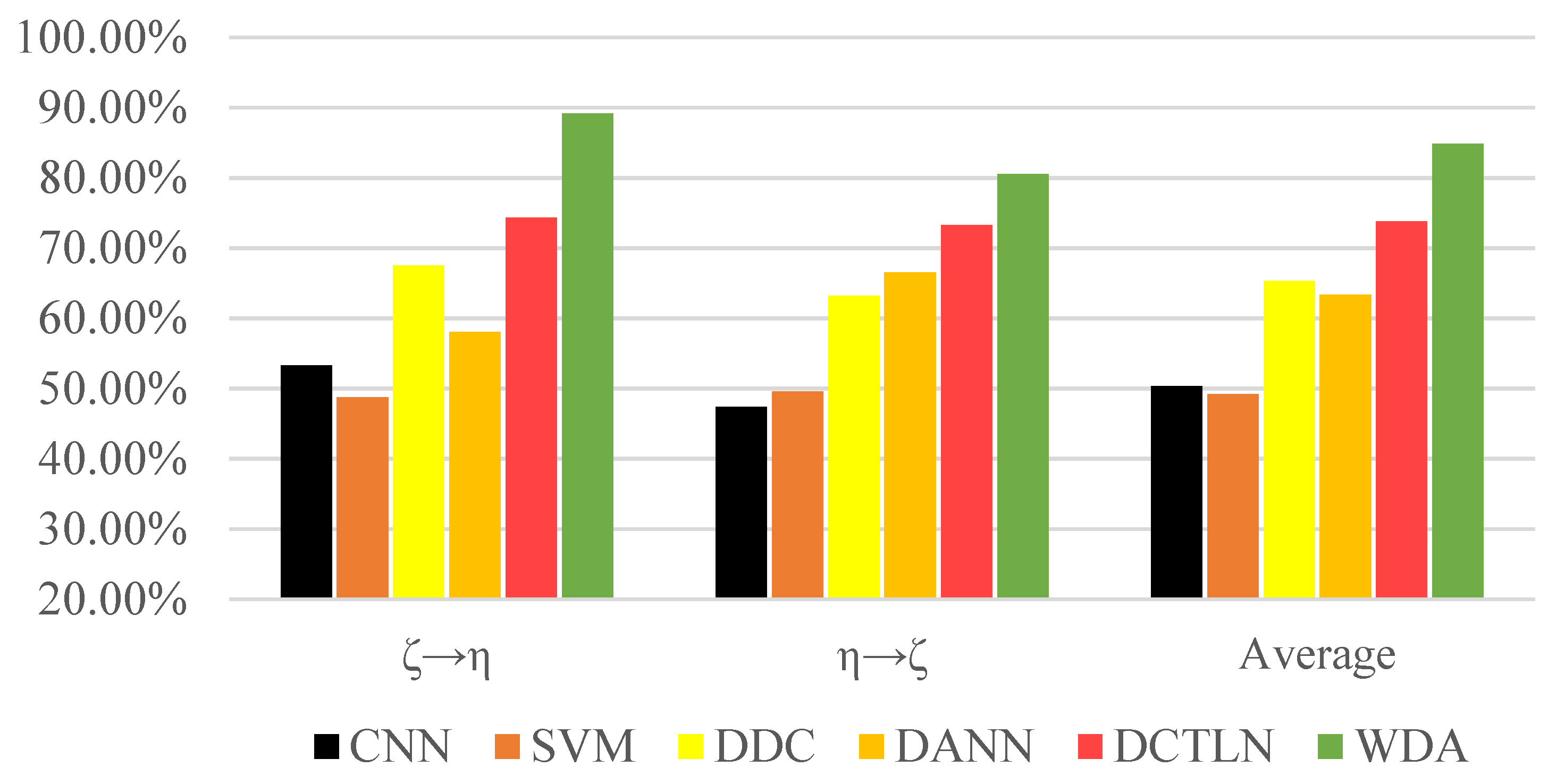{kind=link}
{kind=link}
{kind=link}