
A Deep Learning-Based Electromagnetic Signal for Earthquake Magnitude Prediction


Abstract
:1. Introduction
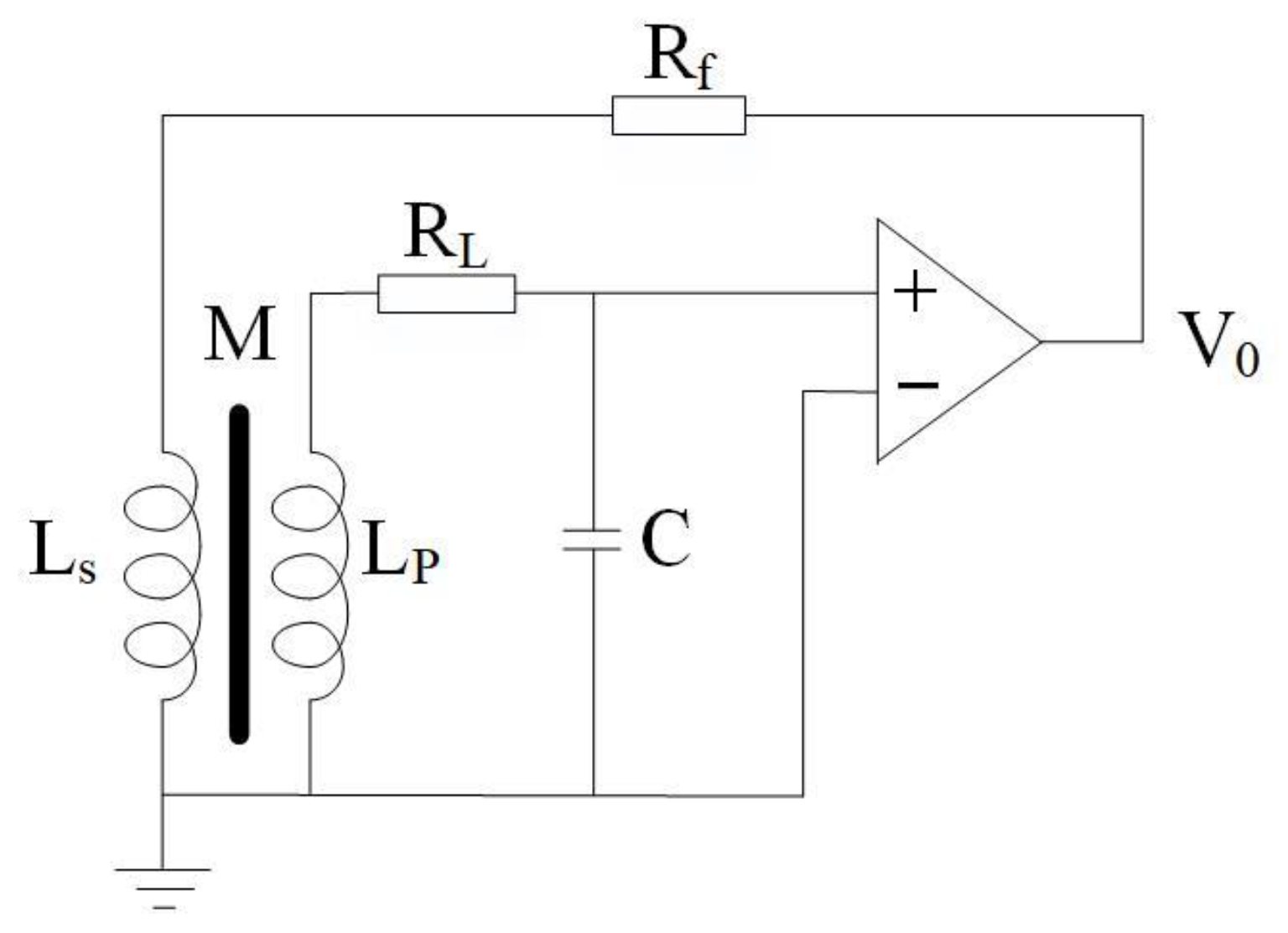
2. Electromagnetic Sensor
2.1. Effective Permeability Analysis with Magnetic Flux Collector
2.2. Research on the Effective Area of Laminated Cores
2.3. Research on Magnetic Negative Feedback Technology
3. CNN Networks
3.1. Shallow Features Extract
3.2. The Model Structure
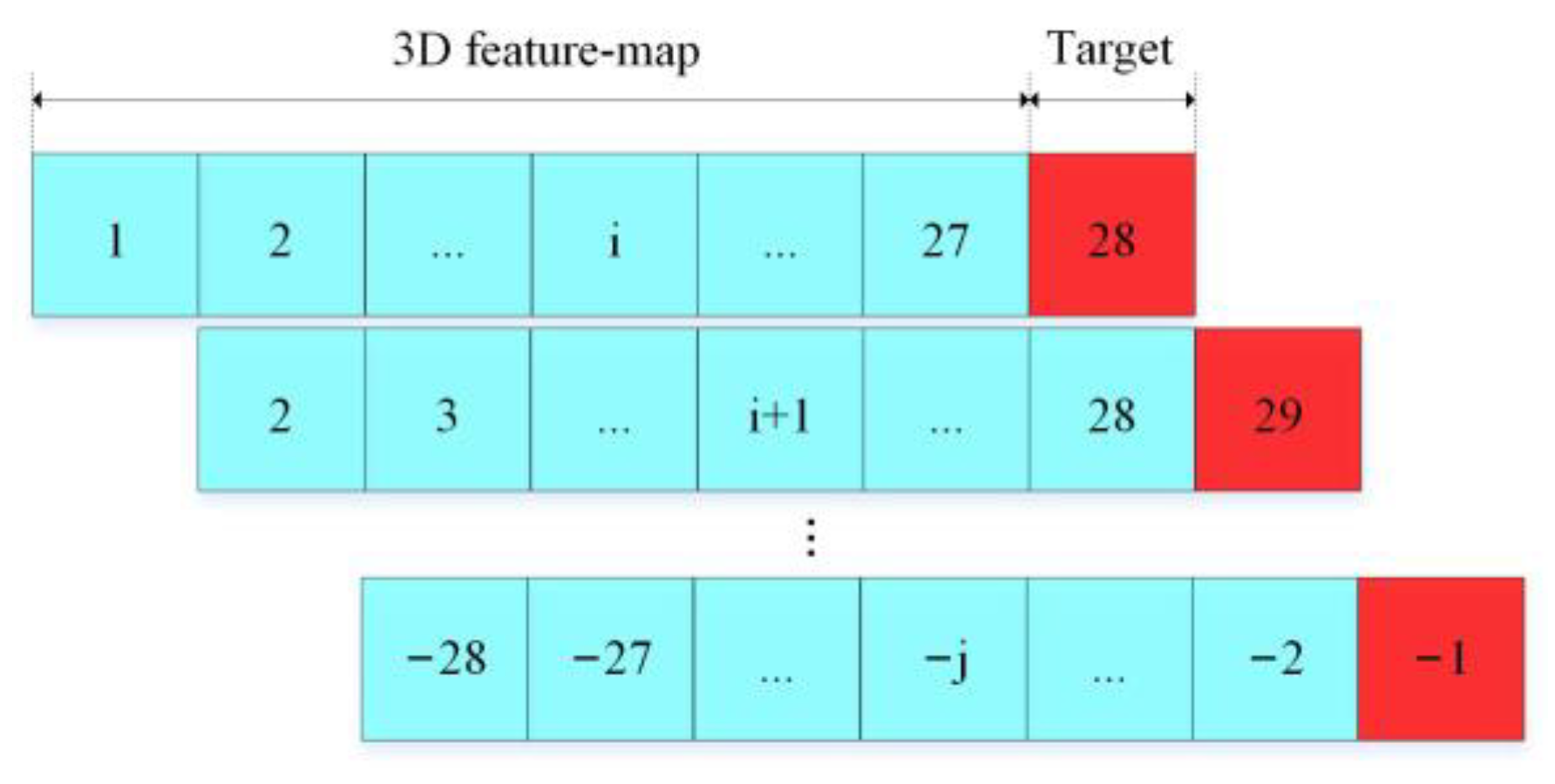
3.3. Data Set
3.4. Over-Sampling Data
4. Experiments
4.1. Model Setup and Hyper-Parameters
4.2. Loss and Accuracy
4.3. Algorithm Comparison and Discussions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Panakkat, A.; Adeli, H. Recent efforts in earthquake prediction (1990–2007). Nat. Hazards Rev. 2008, 9, 70–80. [Google Scholar] [CrossRef]
- Varotsos, P.; Alexopoulos, K. Physical properties of the variations of the electric field of the earth preceding earthquakes, I. Tectonophysics 1984, 110, 73–98. [Google Scholar] [CrossRef]
- Lakkos, S.; Hadjiprocopis, A.; Comley, R.; Smith, P. A neural network scheme for earthquake prediction based on the seismic electric signals. In Proceedings of the IEEE Workshop on Neural Networks for Signal Processing, Ermioni, Greece, 6–8 September 1994; IEEE: New York, NY, USA, 1994. [Google Scholar]
- Yue, L.; Yuan, W.; Yuan, L.; Zhang, B.; Wu, G. Earthquake prediction by RBF neural network ensemble. In Proceedings of the International Symposium on Neural Networks, Dalian, China, 19–21 August 2004; Springer: Berlin/Heidelberg, Germany, 2004. [Google Scholar]
- Ishimoto, M. Observations of earthquakes registered with the microseismograph constructed recently. Bull. Earthq. Res. Inst. Univ. Tokyo 1936, 17, 443–478. [Google Scholar]
- Sharma, M.L.; Arora, M.K. Prediction of seismicity cycles in the himalayas using artificial neural networks. Acta Geophys. Pol. 2005, 53, 299–309. [Google Scholar]
- Allen, R.M.; Gasparini, P.; Kamigaichi, O.; Bose, M. The status of earthquake early warning around the world: An introductory overview. Seismol. Res. Lett. 2008, 80, 682–693. [Google Scholar] [CrossRef]
- Lomax, A.; Michelini, A. Tsunami early warning within five minutes. Pure Appl. Geophys. 2013, 170, 1385–1395. [Google Scholar] [CrossRef]
- Melgar, D.; Allen, R.M.; Riquelme, S.; Geng, J.; Bravo, F.; Baez, J.C.; Parra, H.; Barrientos, S.; Fang, P.; Bock, Y.; et al. Local tsunami warnings: Perspectives from recent large events. Geophys. Res. Lett. 2016, 43, 1109–1117. [Google Scholar] [CrossRef] [Green Version]
- Kang, J.M.; Kim, I.M.; Lee, S.; Ryu, D.W.; Kwon, J. A Deep CNN-based ground vibration monitoring scheme for MEMS sensed data. IEEE Geosci. Remote Sens. Lett. 2020, 17, 347–351. [Google Scholar] [CrossRef]
- Mousavi, S.M.; Beroza, G.C. Bayesian-deep-learning estimation of earthquake location from single-station observations. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8211–8224. [Google Scholar] [CrossRef]
- Jozinovic, D.; Lomax, A.; Stajduhar, I. Rapid prediction of earthquake ground shaking intensity using raw waveform data and a convolutional neural network. Geophys. J. Int. 2020, 222, 1379–1389. [Google Scholar] [CrossRef]
- Perol, T.; Gharbi, M.; Denolle, M. Convolutional neural network for earthquake detection and location. Sci. Adv. 2018, 4. [Google Scholar] [CrossRef] [Green Version]
- Lomax, A.; Michelini, A.; Jozinović, D. An investigation of rapid earthquake characterization using single-station waveforms and a convolutional neural network. Seismol. Res. Lett. 2019, 90, 517–529. [Google Scholar] [CrossRef]
- Mousavi, S.M.; Zhu, W.; Sheng, Y.; Beroza, G.C. CRED: A deep residual network of convolutional and recurrent units for earthquake signal detection. Sci. Rep. 2019, 9, 10267. [Google Scholar] [CrossRef]
- Jena, R.; Pradhan, B.; Beydoun, G. Earthquake hazard and risk assessment using machine learning approaches at Palu, Indonesia. Sci. Total Environ. 2020, 749, 141582. [Google Scholar] [CrossRef]
- Jena, R.; Pradhan, B.; Al-Amri, A.; Lee, C.W.; Park, H.J. Earthquake probability assessment for the Indian subcontinent using deep learning. Sensors 2020, 20, 4369. [Google Scholar] [CrossRef]
- Bayona, J.A.; Savran, W.; Strader, A.; Hainzl, S.; Cotton, F.; Schorlemmer, D. Two global ensemble seismicity models obtained from the combination of interseismic strain measurements and earthquake-catalogue information. Geophys. J. Int. 2021, 224, 1945–1955. [Google Scholar] [CrossRef]
- Li, R.; Lu, X.; Yang, H.; Qiu, J.; Zhang, L. DLEP: A deep learning model for earthquake prediction. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; IEEE: New York, NY, USA, 2020. [Google Scholar]
- Reid, H.F. The Mechanics of the Earthquake, the California Earthquake of April 18, 1906; Report of the State Investigation Commission; Carnegie Institution of Washington: Washington, DC, USA, 1910; pp. 1–192. [Google Scholar]
- Kesar, A.S. Underground anomaly detection by electromagnetic shock waves. IEEE Trasactions Antennas Propag. 2011, 59, 149–153. [Google Scholar] [CrossRef]
- Fraser-Smith, A.C.; Bernardi, A.; McGill, P.R.; Ladd, M.E.; Helliwell, R.A.; Villard, O.G. Low-frequency magnetic field measurements near the epicenter of the Ms 7.1 Loma Prieta Earthquake. Geophys. Res. Lett. 1990, 17, 1465–1468. [Google Scholar] [CrossRef]
- Hirano, T.; Hattori, K. ULF geomagnetic changes possibly associated with the 2008 Iwate-Miyagi Nairiku earthquake. J. Asian Earth Sci. 2011, 41, 442–449. [Google Scholar] [CrossRef]
- Gokhberg, M.B.; Morgounov, V.A.; Yoshino, T.; Tomizawa, I. Experimental measurement of electromagnetic emissions possibly related to earthquakes in Japan. J. Geophys. Res. Solid Earth 1982, 87, 7824–7828. [Google Scholar] [CrossRef]
- Paperno, E.; Grosz, A. A miniature and ultralow power search coil optimized for a 20 mHz to 2 kHz frequency range. In Proceedings of the 53rd Annual Conference on Magnetism and Magnetic Materials, Austin, TX, USA, 10–14 November 2008; IEEE: New York, NY, USA, 2008. [Google Scholar]
- Tumanski, S. Induction coil sensors—A review. Meas. Sci. Technol. 2007, 18, R31–R46. [Google Scholar] [CrossRef]
- Nourmohammadi, A.; Asteraki, M.H.; Feiz, S.M.H.; Habibi, M. A generalized study of coil-core-aspect ratio optimization for noise reduction and snr enhancement in search coil magnetometers at low frequencies. IEEE Sens. J. 2015, 15, 6454–6459. [Google Scholar] [CrossRef]
- Ding, S.; An, Y.; Zhang, X.; Wu, F.; Xue, Y. Wavelet twin support vector machines based on glowworm swarm optimization. Neurcomputing 2017, 225, 157–163. [Google Scholar] [CrossRef]
- Wang, X.; Yong, S.; Xu, B.; Liang, Y.; Bai, Z.; An, H.; Zhang, X.; Huang, J.; Xie, Z.; Lin, K.; et al. Research and Imple-mentation of multi-component seismic monitoring system AETA. Acta Sci. Nat. Univ. Pekin. 2018, 54, 487–494. [Google Scholar]
- Yong, S.; Wang, X.; Pang, R.; Jin, X.; Zeng, J.; Han, C.; Xu, B. Development of inductive magnetic sensor for mul-ti-component seismic monitoring system AETA. Acta Sci. Nat. Univ. Pekin. 2018, 54, 495–501. [Google Scholar]
- Kamigaichi, O.; Saito, M.; Doi, K.; Matsumori, T.; Tsukada, S.; Takeda, K.; Shimoyama, T.; Nakamura, K.; Kiyomoto, M.; Watanabe, Y. Earthquake early warning in Japan: Warning the general public and future prospects. Seismol. Res. Lett. 2009, 80, 717–726. [Google Scholar] [CrossRef]
- Ochoa, L.H.; Nio, L.F.; Vargas, C.A. Fast magnitude determination using a single seismological station record implementing machine learning techniques—ScienceDirect. Geod. Geodyn. 2018, 9, 34–41. [Google Scholar] [CrossRef]
- Rouet-Leduc, B.; Hulbert, C.; Lubbers, N.; Barros, K.; Humphreys, C.J.; Johnson, P.A. Machine learning predicts laboratory earthquakes. Geophys. Res. Lett. 2017, 44, 9276–9282. [Google Scholar] [CrossRef]
- Adler, A.; Araya-Polo, M.; Poggio, T. Deep learning for seismic inverse problems: Toward the acceleration of geophysical analysis workflows. IEEE Signal Process. Mag. 2021, 38, 89–119. [Google Scholar] [CrossRef]
- DeVries, P.M.R.; Viegas, F.; Wattenberg, M.; Meade, B.J. Deep learning of aftershock patterns following large earthquakes. Nature 2018, 560, 632–634. [Google Scholar] [CrossRef]
- Huang, J.P.; Wang, X.A.; Zhao, Y.; Xin, C.; Xiang, H. Large earthquake magnitude prediction in Taiwan based on deep learning neural network. Neural Netw. World 2018, 28, 149–160. [Google Scholar] [CrossRef]
- Lara, C.; Saldias, G.S.; Cazelles, B.; Rivadeneira, M.M.; Haye, P.A.; Broitman, B.R. Coastal biophysical processes and the biogeography of rocky intertidal species along the south-eastern Pacific. J. Biogeogr. 2019, 46, 420–431. [Google Scholar] [CrossRef]
- Hu, W.; Zhang, Y.; Li, L. Study of the application of deep convolutional neural networks (CNNs) in processing sensor data and biomedical images. Sensors 2019, 19, 3584. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; IEEE: New York, NY, USA, 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, X.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 27–30 June 2016; IEEE: New York, NY, USA, 2016. [Google Scholar]
- Peng, S.L.; Jiang, H.Y.; Wang, H.X.; Alwageed, H.; Zhou, Y.; Sebdani, M.M.; Yao, Y. Modulation classification based on signal constellation diagrams and deep learning. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 718–727. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Zhang, X.; Zhang, B.; Lei, M.; Cui, W.; Guo, Y. A channel-projection mixed-scale convolutional neural network for motor imagery EEG decoding. IEEE Trans. Neural Syst. Rehabil. Eng. 2019, 27, 1170–1180. [Google Scholar] [CrossRef]
- Qiu, G.; Gu, Y.; Cai, Q. A deep convolutional neural networks model for intelligent fault diagnosis of a gearbox under different operational conditions. Measurement 2019, 145, 94–107. [Google Scholar] [CrossRef]
- Hui, H.; Wang, W.; Mao, B. Borderline-SMOTE: A new over-sampling method in imbalanced data sets learning. Adv. Intell. Comput. 2005, 3644, 878–887. [Google Scholar]
- Ji, M.; Liu, L.; Buchroithner, M. Identifying collapsed buildings using post-earthquake satellite imagery and convolutional neural networks: A case study of the 2010 haiti earthquake. Remote Sens. 2018, 10, 1689. [Google Scholar] [CrossRef] [Green Version]
- Zhang, W.; Tang, X.; Yoshida, T. Text classification toward a scientific forum. J. Syst. Sci. Syst. Eng. 2007, 16, 356–369. [Google Scholar] [CrossRef]
- Xu, X.; Chen, W.; Sun, Y. Over-sampling algorithm for imbalanced data classification. J. Syst. Eng. Electron. 2019, 30, 1182–1191. [Google Scholar] [CrossRef]
- Banerjee, A.; Bhattacharjee, M.; Ghosh, K.; Chatterjee, S. Synthetic minority oversampling in addressing imbalanced sarcasm detection in social media. Multimed. Tools Appl. 2020, 79, 35995–36031. [Google Scholar] [CrossRef]
- Incorvaia, G.; Dorn, O. Stochastic optimization methods for parametric level set reconstructions in 2D through-the-wall radar imaging. Electronics 2020, 9, 2055. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Feature Description |
|---|---|
| 1 | Variance |
| 2 | Power |
| 3 | Skewness |
| 4 | Kurtosis |
| 5 | Maximum absolute value |
| 6 | Mean absolute value |
| 7 | Absolute maximum 5% position |
| 8 | Absolute maximum 10% position |
| 9 | Short-term energy standard deviation |
| 10 | Maximum short-term energy |
| 11 | 0~5 Hz power |
| 12 | 5~10 Hz power |
| 13 | 10~15 Hz power |
| 14 | 15~20 Hz power |
| 15 | 20~25 Hz power |
| 16 | 25~30 Hz power |
| 17 | 30~35 Hz power |
| 18 | 35~40 Hz power |
| 19 | 40~60 Hz power |
| 20 | 140~160 Hz power |
| 21 | Power ratio of other frequency bands |
| 22 | Center of gravity frequency |
| 23 | Mean square frequency |
| 24 | Frequency variance |
| 25 | Frequency entropy |
| 26 | Mean value of absolute value of level 4 detail |
| 27 | Level 4 detail energy |
| 28 | Maximum energy value of level 4 detail |
| 29 | Level 4 detail energy value variance |
| 30 | Mean value of absolute value of level 5 detail |
| 31 | Level 5 detail energy |
| 32 | Maximum energy value of level 5 detail |
| 33 | Variance of Level 5 detail energy value |
| 34 | Mean value of absolute value of level 6 detail |
| 35 | Level 6 detail energy |
| 36 | Maximum energy value of level 6 detail |
| 37 | Level 6 detail energy value variance |
| 38 | Approximate mean value of absolute value at level 6 |
| 39 | Level 6 approximate energy |
| 40 | Maximum approximate energy value of level 6 |
| 41 | Level 6 approximate energy value variance |
| 42 | Mean absolute value of ultra-low frequency |
| 43 | Variance of ultra-low Frequency |
| 44 | Ultra-low frequency power |
| 45 | Ultra-low frequency skewness |
| 46 | Ultra-low frequency kurtosis |
| 47 | Maximum absolute value of ultra-low frequency |
| 48 | Maximum 5% position of absolute value of ultra-low frequency |
| 49 | Maximum 10% position of absolute value of ultra-low frequency |
| 50 | Ultra-low frequency short-term energy standard deviation |
| 51 | Maximum ultra-low frequency short-term energy |
| Magnitude Range (M.) | Label |
|---|---|
| 0 < M. < 3.5 | 0 |
| 3.5 < M. < 4 | 1 |
| 4 < M. < 4.5 | 2 |
| 4.5 < M. < 5 | 3 |
| 5 < M. < 6 | 4 |
| M. > 6 | 5 |
| M. | Pre | Recall | F1 |
|---|---|---|---|
| 0 < M. < 3.5 | 0.948571 | 0.927374 | 0.937853 |
| 3.5 < M. < 4 | 0.955056 | 0.988372 | 0.971429 |
| 4 < M. < 4.5 | 0.970588 | 0.988024 | 0.979228 |
| 4.5 < M. < 5 | 0. 975802 | 0.983425 | 0.981643 |
| 5 < M. < 6 | 0. 989385 | 0.988166 | 0.984048 |
| M. > 6 | 0. 993163 | 0.991362 | 0.993048 |
| Macro-average | 0.979036 | 0.979227 | 0.979034 |
| Model | Accuracy | Time Consuming(s) |
|---|---|---|
| SVM | 0.934 | 10,457 |
| Decision Tree | 0.8687 | 22,236 |
| KNN | 0.8691 | 23,330 |
| Random Forests | 0.7592 | 9657 |
| LSTM | 0.7493 | 6154 |
| CNN + LSTM | 0.8903 | 6800 |
| Resnet50 | 0.9324 | 1386 |
| Resnet101 | 0.9182 | 1001 |
| Vgg16 | 0.9086 | 2261 |
| Vgg19 | 0.9162 | 2464 |
| Nasnet | 0.9353 | 1841 |
| Current Method | 0.9788 | 1736 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bao, Z.; Zhao, J.; Huang, P.; Yong, S.; Wang, X. A Deep Learning-Based Electromagnetic Signal for Earthquake Magnitude Prediction. Sensors 2021, 21, 4434. https://doi.org/10.3390/s21134434
Bao Z, Zhao J, Huang P, Yong S, Wang X. A Deep Learning-Based Electromagnetic Signal for Earthquake Magnitude Prediction. Sensors. 2021; 21(13):4434. https://doi.org/10.3390/s21134434
Chicago/Turabian StyleBao, Zhenyu, Jingyu Zhao, Pu Huang, Shanshan Yong, and Xin’an Wang. 2021. "A Deep Learning-Based Electromagnetic Signal for Earthquake Magnitude Prediction" Sensors 21, no. 13: 4434. https://doi.org/10.3390/s21134434
APA StyleBao, Z., Zhao, J., Huang, P., Yong, S., & Wang, X. (2021). A Deep Learning-Based Electromagnetic Signal for Earthquake Magnitude Prediction. Sensors, 21(13), 4434. https://doi.org/10.3390/s21134434