1. Introduction
Age estimation is performed to identify a human’s age from face images, which has broad application scenarios in public areas. For example, when police search for criminals through video surveillance, they can quickly narrow the search range by using age estimation. So far, there have been a variety of methods proposed for age estimation [
1,
2]. Most existing facial age estimation systems usually consist of two key stages: age-feature learning and age-feature estimator. Age-feature learning aims to learn more age features from face images to make age information separable. Traditional age-feature-learning methods are based on hand-crafted features, such as the Local Binary Pattern (LBP) [
3], the Histogram of Oriented Gradients (HOG) [
4], and Biologically Inspired Features (BIF) [
5]. However, these hand-crafted-based features require strong prior knowledge to engineer them by hand [
6]. To address this limitation, deep-learning-based techniques have been proposed and have shown great success in age-feature learning in recent years [
7,
8]. For example, Yi et al. [
7] proposed a multiscale framework to learn deep age features for age estimation. Wang et al. [
8] developed an end-to-end learning approach to learn robust age features and achieved very competitive performance compared with hand-crafted-based methods. Due to this, the recent age-feature-learning studies mainly focus on deep-learning networks such as VGG-16 [
9], AlexNet [
10], and MobileNet [
11].
On the one hand, although very competitive performance has been achieved, most state-of-the-art deep-learning networks are often bulky with more than 300 MB and not suitable to be adapted to platforms with limited memory such as mobile and embedded devices [
12,
13]. Thus, some studies are focused on designing compact deep-learning networks for age estimation, so that these deep-learning models can be embedded in small memory devices. For example, Yang et al. [
12] adopted a two-stream CNN model to estimate age, and the model consumed around 1 MB. Niu et al. [
14] proposed ORCNN with only 1.7 MB of consumption. These compact models sacrifice some performance for a smaller memory space.
On the other hand, it is widely observed that the information of race and gender is highly correlated with age features, which also exist in the form of pixels in facial images. For example, females usually look younger than males of similar ages when they are young and look older than males when they are old. Men have less of a beard or none when they are young, but they have more of a beard when they are old. On the contrary, no matter whether young or old, women never have a beard, as shown in
Figure 1. However, most age-feature-learning approaches focus on learning a single kind of age feature and ignore other appearance features such as gender and race, which have a great influence on the age pattern [
15]. Inspired by this, we utilized three compact subnetworks to learn multiple features from the same input image and fused these features to form more discriminative and robust features for age estimation.
For the age-feature estimator, it mainly converts the extracted age features into exact age numbers. In general, the age estimator can be considered as a classifier or a regressor. Representative classifier-based methods include Support Vector Machines (SVMs) [
16], Random Forests (RFs) [
17], and k Nearest Neighbors (k-NNs) [
18]. Classifier-based methods equally treat different ages as independent classes, which ignores the inherent relationship of age labels. Therefore, the costs of classifying a young subject as a middle-aged subject and an old subject are the same. Due to this, many regression-based methods [
1,
9] were proposed to make use of the continuity of age labels. For example, Agustsson et al. [
19] proposed a nonlinear regression network for age estimation. Geng et al. [
20] proposed a CPNN algorithm to learn age-regression distributions. The regressor-based method oversimplifies the aging pattern to a linear model. However, the facial-aging pattern is generally a nonlinear problem and an extremely complex process, affected by many factors [
21]. To avoid the problem of over linearization, some ranking-based methods have been proposed for age estimation [
22,
23], and these approaches treat the age label as an ordinal sequence. For example, Zhang et al. [
24] proposed a paradigm for mapping multiple age comparisons into an age-distribution posterior for age estimation. Chen et al. [
23] proposed a ranking-CNN model with a series of basic networks, and their binary outputs were aggregated for the final age prediction. For ranking-based methods, features are learned independently in each age group to depict different aging patterns, which avoids the overlinearization problem of the regression-based model. However, most ranking-based methods are built on complex networks or ensembles of networks. These models are often bulky and not suitable to be adapted to platforms with limited memory and computation resources such as mobile and embedded devices.
In this paper, we proposed a new age-feature descriptor by exploring multiple types of appearance features and engineered a regression-ranking estimator for robust age estimation. Specifically, we first used three compact subnetworks to learn gender, race, and age information from the same input image. Then, we fused these complementary features to further form more discriminative and robust features. Finally, we used a regression-ranking-age estimator to predict the final age number based on the fusion features. Compared to the approaches based on ranking technology or regression technology, our proposed method could better utilize the order and continuity of age labels. Moreover, our model was more compact with only 20 MB of memory overhead. The experimental results showed the effectiveness and efficiency of the proposed method on facial-age estimation in comparison with previous state-of-the-art methods.
The main contributions of this paper can be summarized as follows:
We proposed a compact multifeature-learning network for age estimation by learning and fusing the gender, race, and age information. By integrating these complementary features, more discriminative and robust age features could be obtained in the final feature descriptor;
We engineered a regression-ranking estimator to convert the fusion features into exact age numbers, which could simultaneously make use of the continuity and the order of the age labels;
We conducted extensive experiments on three widely used databases. The experimental results clearly showed that our proposed method could achieve a higher accuracy for age estimation than most state-of-the-art age-estimation methods.
The remainder of this paper is organized as follows.
Section 2 reviews the related work.
Section 3 shows the details of our proposed method. The experiments and results are illustrated in
Section 4. Finally, we draw conclusions in
Section 5.
3. Proposed Method
In this section, we first present the overall framework of the proposed method. Then, we illustrate the multifeature learning and the regression-ranking estimator of the proposed method.
3.1. The Framework of the Proposed Method
On the one hand, the human age pattern is complicated and is easily affected by many factors, such as identity, gender, race, and extrinsic factors. However, most models focus on single-age-feature learning and ignore gender, race, and other age-related features. Due to this, we aimed to learn more robust age features by exploring the potential gender and race information from the same original images. On the other hand, most deep-learning-based age-estimation methods are built on complex networks or ensembles of networks, which require a large sample and memory to train the network. Thus, they are not suitable to be adapted to platforms with limited memory and computation resources such as mobile and embedded devices. To reduce the model size without sacrificing much accuracy, we first broke down the complex age problem into three simple feature-learning tasks. Then, we fused these age-related features in the fully connected layer and fed them into the age-feature estimator to predict the final age.
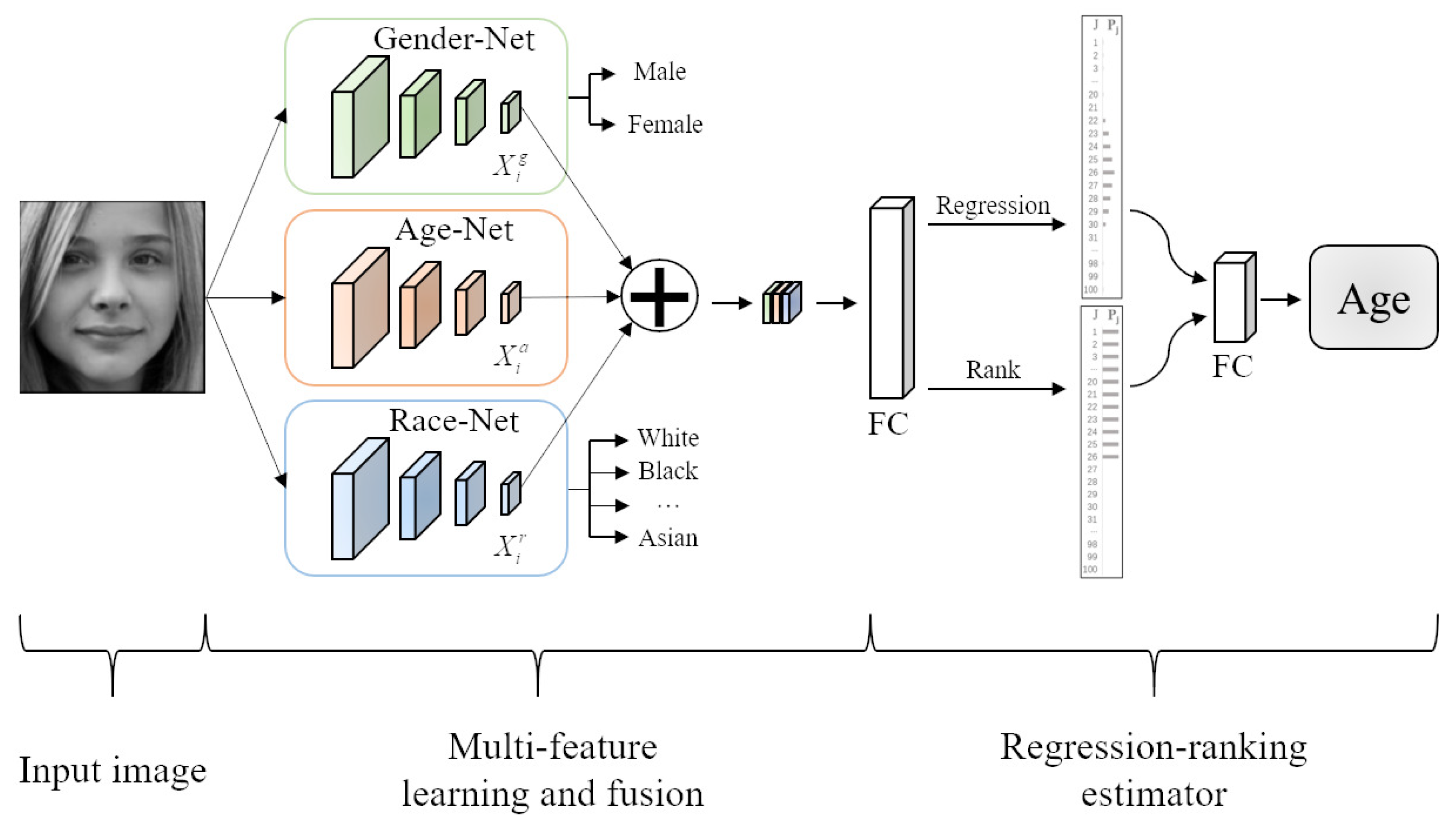
Figure 2 shows the basic idea of the proposed method, which mainly consisted of two parts: multifeature learning and fusion and regression-ranking estimator. In the first part, we firstly utilized Gender-Net, Age-Net, and Race-Net to learn multiple types of features from the same input image. Then, we fused the features in the full connection layer such that more discriminative and robust features could be obtained. In the second part, to simultaneously utilize the continuity and the order of age labels, we engineered the regression-ranking estimator to predict the final age based on the fusion features. In the following, we present the detailed procedures of the two parts of the proposed method.
3.2. Multiple Types of Features’ Learning and Fusion
To learn more discriminative and robust features, we first employed three subnetworks to learn the gender, age, and race information from the same input image, as shown in
Figure 2. Each network was composed of 4 convolution blocks, and each convolution block included a convolutional layer, a nonlinear activation, a batch normalization, and a pooling layer. For the convolutional layer, it mainly learned the target feature from the previous feature map and output a new feature map. Specifically, we respectively used 32 and 64 kernels with a size of 5 × 5, a stride of 1 pixel, and 0 padding for the first and second layers to learn the coarse features. Then, we used the following two layers to learn the subtle features, which respectively used 64 and 128 kernels with a size of 3 × 3, a stride of 1, and 1padding. The outputs of the convolutions added an element-wise nonlinear activation function to normalize the front results. Without loss of generality, we used the ELU function as the nonlinear activation function to deactivate the output of the convolutional layer. For the batch normalization, it not only aimed to improve the learning of the local features, but also to improve the learning of the overall features [
37]. To achieve the target, we used the subtractive and divisive normalization operations [
35,
38] to normalize each feature map. For the pooling layer, it mainly converted the feature map into a more representative feature-representation map with a smaller size scale. For example, after the pooling layer, the feature map [64, 64] was transformed into a feature-representation map [32, 32]. Although the size of the feature-representation map was smaller, it contained the main feature information, which was helpful to save computing resources and improve the accuracy of the feature recognition. In our experiments, we used the maximum pooling operation to generate the feature-representation map.
These three subnetworks took the same image with the gender, age, and race labels as the input. For example,
represents a 25-year-old white man. For the gender and race attributes, we used one-hot coding [
39] to encode these attributes, in which only one feature map was filled with one and others were filled with zero. For example, the output of the Gender-Net [1, 0] represents a male and [0, 1] a female. Through the learning procedure of the three subnetworks, the high-level-feature maps of gender, age, and race could be learning and recorded in the convolution layer. Then, we fused these feature maps and fed them into the full connection layer, so that more discriminative and robust age features could be obtained in the final feature descriptor. When the input features had more information, the age estimator would be more flexibility at predicting the age of people with different genders and races. Thus, the age-feature estimator could achieve a better generalization performance.
For the feature map fusion, we aimed to obtain an enhanced feature that was beneficial to the age-feature estimator. Specifically, let be the gender, age, and race feature maps, respectively, and ⊕ denote the channel-connection operation; is formed and input into the regression-ranking-age estimator to predict the final age. In other words, we first broke down the complex task of age estimation into three simple subtasks. Then we separately learned the gender-specific, race-specific, and age-specific features. After that, we fused these complementary features to form the more discriminative and robust age features. Finally, we fed the fusion features into the age-feature estimator to predict the final age.
3.3. Regression and Ranking Estimator
Given the age-feature representation, the age estimator aimed to predict the age of the face in the image. Generally, the age estimator could be modeled as a regression model or a ranking model. Different from single-regression-based methods or single-ranking-based methods, we first engineered a regression-age estimator and a ranking-age estimator to simultaneously make use of the continuity and the order of the age labels. Then, we balanced the effects of continuity and the order of the age label and made a good tradeoff between them. Specifically, we used two fully connected layers to engineer the regression-age estimator and ranking-age estimator, respectively. The output of the regression-age estimator was the age probability
, and the output of the age-ranking estimator was the age ranking
. For the regression age, we computed the expected value as the age number, as follows:
where
is the age label and
denotes the probability that the input image belongs to the age of
. For the ranking age, we first denoted the face image as
, where
is the
i-th input image and
is the corresponding ranking-age label, which means that the age of the
i-th input image is
y. The age number can be computed as:
where
is the threshold value and
represents the true and false check operator, which outputs 1 when the internal condition is true, and 0 otherwise. It can be seen that age estimation was turned into a ranking problem by minimizing the binary ranking errors.
Age regression and age ranking respectively estimate the age from the age-continuity and age-order properties, such that they are complementary for the final age number estimation. After age regression and age ranking, we further forwarded them to a fully connected layer to estimate the final age as follows:
where
and
are two parameters of the final fully connected layer to balance the effects of the continuity and order of the age label and make a good tradeoff between them.
4. Experimental Setup and Results
In this section, we conducted age-estimation experiments on the widely used MORPH2 [
40], FG-NET [
41], and LAP [
42] datasets. Our method was implemented within the PyTorch framework. The parameters of the proposed networks were all initialized with the Xavier initialization, and Adam was used as the optimizer. The learning rate and batch size were empirically set to 0.001 and 16, respectively, and the RLRP algorithm was used to automatically adjust the learning rate. The experiments were performed on the same machine with a GTX 2060s graphics card (including 2176 CUDA cores), a i5-9600KF CPU, and a 32 GB RAM.
4.1. Datasets and Preprocessing
MORPH2 is the most popular dataset for age estimation, which contains 55,134 face images of 13,617 subjects with the age ranging from 16 to 77. Among them, there are 77% face images from Africa, 19% from America, and the rest from Asia. FG-NET is a very recent database used for age estimation, which contains one-thousand two face images of eight-two individuals with the age ranging from zero to sixty-nine. All of them are from Europe and America. LAP contains 4691 face images, of which approximately 81% of the face images are from America, 11% are from Africa, and the rest are from Asia.
Table 1 tabulates the information of three databases, as well as their experimental settings. The age distributions of the MORPH2, FG-NET, and LAP datasets are shown in
Table 2. In addition, we employed the IMDB-WIKI database of 523,051 images to pretrain our proposed network.
As shown in
Table 1, the training images of the FG-NET, MORPH II, and LAP databases are extremely insufficient. For example, FG-NET contains no more than eight-hundred training images, which is far from enough to train a deep-learning network. Although MORPH2 has 44,000 training samples, it is not enough for a deep model to reach convergence [
10,
43]. Therefore, increasing the training samples was necessary to improve the performance. To enlarge the sample sets, we first flipped each image to obtain two mirror-symmetric samples and then rotated them by ±5° and ±10°. Moreover, we added Gaussian white noise with variances of 0.001, 0.005, 0.01, 0.015, and 0.02 on the original and the synthetic samples, so that each image was finally extended to 40 samples.
Figure 3 shows some samples from MORPH2, FG-NET and LAP. We can see that there was much noise in the facial images such as illumination variations and different postures. As pointed out by [
44], illumination compensation and normalization have an important impact on facial attribute analysis. Therefore, we used DT-CWT [
45] to normalize the illumination in the experiments. After that, all face images were first processed by a face detector [
46], and a few nonface images were removed. Then, we used AAM [
47] to align all faces, according to the eyes’ center and the upper lip. Finally, all face images were cropped into a size of 224 × 224 and then fed into the network. Some of the processed images are shown in
Figure 4. From
Figure 4, we can see that these images were well normalized in terms of illumination and posture. For example, the illumination of the images in the middle row of
Figure 3 was relatively dark. After the illumination normalization, the illumination of these images increased. The face of the third row of
Figure 3 was detected, and the pose was normalized according to the eyes’ center and the upper lip.
4.2. Evaluation Metrics
For the evaluation of the age estimation models, the Mean Absolute Error (
MAE) is the most commonly used evaluation indicator, which represents the absolute average error between the predicted age and the true age.
MAE is calculated as follows:
where
and
represent the predicted age and the true age, respectively, and
n is the total number of test samples. Obviously, a lower
MAE value indicates a better performance of the model. On the contrary, a higher
MAE value means a worse performance of the model.
The Cumulative Score (
CS) is another important evaluation metric of the age-estimation model. We set the cumulative prediction accuracy as the error
, and
can be calculated as follow:
where
denotes the total number of test samples on which the error of age prediction was less than
. For example, we only counted the number of samples whose predicted age error was less than five if
was set as five. Obviously, a higher
value means a better performance of the model. On the contrary, a lower
value means a worse performance of the model.
4.3. Comparisons with the State-of-the-Art
To validate the performance of our proposed multifeature-learning-and-fusion method, we compared our proposed method with different feature-based methods. The competing methods can be roughly categorized into two groups, single-feature-based methods and multifeature-based methods. The single-feature-based methods included DEX [
1] and MSFCL [
6]. These single-feature-based methods only consider the age feature and ignore other age-related features such as race and gender. The multifeature-based methods included DCP [
35] and CNN2ELM [
10]. DCP focuses on exploring the influence of race factors on age estimation. CNN2ELM extracts the age, race, and gender features from multimodel images and fuses them for age estimation. Different from CNN2ELM, we simultaneously learned and fused multiple types if features from the single-model face images for age estimation. For each dataset, eighty percent of the samples were used for training and the rest for testing. All models were pretrained with the IMDB-WIKI dataset.
Table 3 tabulates the
MAEs of different feature-based methods on the three databases.
We can see that multifeature-based methods had better performance on age estimation than single-feature-based methods. This is because human age estimation is a complicated process that is easily affected by race and gender. The multifeature-based method learned different age-related features and fused them to form the more discriminative and robust age features. In addition, our proposed method consistently outperformed the two multifeature-based methods by achieving lower MAEs. This was because our proposed method simultaneously learned and fused multiple types of features from the same input image, which could provide more relevant age-related features. Moreover, we engineered a regression-ranking age-feature estimator, which could make better use of the continuity and order of the age label.
To validate the performance of our proposed regression-and-ranking-estimator method on age estimation, we compared it with four representative age-estimation methods including GA-DFL [
9], DOEL [
22], C3AE [
36], and CNN2ELM [
15]. To make a fair comparison with the state-of-the-art methods, we adopted the same experimental setting as the work in [
1]. We first used the training samples to train our method. Then, we used the testing samples to validate the performance of our method and calculated the Mean Absolute Error (
MAE) [
1].
Table 4 tabulates the
MAEs of the different methods on the three databases.
It can be seen that our proposed method consistently outperformed the four compared methods by achieving obviously lower MAEs. This was because the proposed method adaptively fused the regression-and-ranking-age estimator, which can fully utilize the continuity and the ordinal relationship of the age labels. Another possible reason was that our proposed method first used three subnetworks to learn the gender, race, and age information and then fused these complementary features, such that more discriminative and robust age features could be obtained in the final feature descriptor, which improved the performance of our proposed method on age estimation.
To better validate the effectiveness and efficiency of the proposed method, we compared it with a set of state-of-the-art deep-learning-based age-estimation methods. The competing methods can be roughly categorized into two groups, bulky models and compact models, based on their model sizes. The bulky models included DEX [
1] and RankingCNN [
23]. These bulky models pay more attention to performance, but at the expense of bulky network models. Compact models included SSR-Net [
12] and DenseNet [
48], which emphasize a reduced memory footprint, but sacrifice the accuracy of the models.
Table 5 reports the
MAE values on MORPH2, FG-NET, and LAP for the set of state-of-the-art network models for age estimation, including both bulky and compact ones.
Compared with the bulky models, our model not only had a relatively small size, but also achieved lower
MAEs. This was because we first broke down the complex task of age estimation into three simple subtasks. Then we learned and fused the gender-specific, race-specific, and age-specific features, which provided more instructive age-related information than only learning the age features. Another possible reason was that bulky models often require a large number of samples to train the network; however, the sample of the age-related databases was still insufficient. For example, MORPH, the most popular age dataset, contains only 55,000 face images, which is not enough for the training of the bulky models. Therefore, the lack of samples limited the performance of large-scale models, but these samples were enough to train the compact models to achieve a good performance. Although IMDB-WIKI, the largest age-related face dataset, contains 523,051 face images, it contains too many wrong label samples such as no face or multiface images [
10]. Therefore, it was not suitable for training the model directly. Compared with the compact models, our proposed method could make a good tradeoff when both accuracy and efficiency were concerned.
4.4. Ablation Analysis
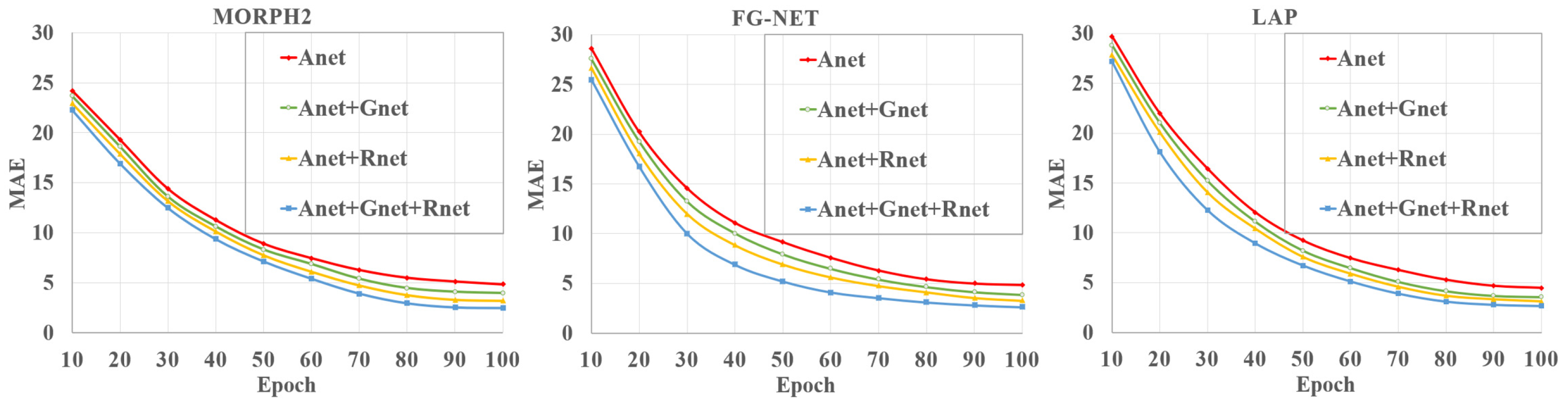
As mentioned above, human aging is a complex process and is easily affected by race and gender. To better learn the complex age features, we first utilized Gender-Net, Race-Net, and Age-Net to learn the gender, race, and age features. Then, we fused these features to form more robust and discriminative features for age estimation. To evaluate the effectiveness of the multifeature learning on age estimation, we conducted the following comparative experiments by removing Gender-Net, or Race-Net, or both of them from our proposed method. Specifically, we took Age-Net (Anet) as the baseline, and we compared Gender-Net (Gnet) and Race-Net (Rnet) as Anet + Gnet, Anet + Rnet, and Anet + Gnet + Rnet (i.e., the proposed method), respectively.
Figure 5 shows the
MAEs of the proposed methods with different combinations of subnetworks.
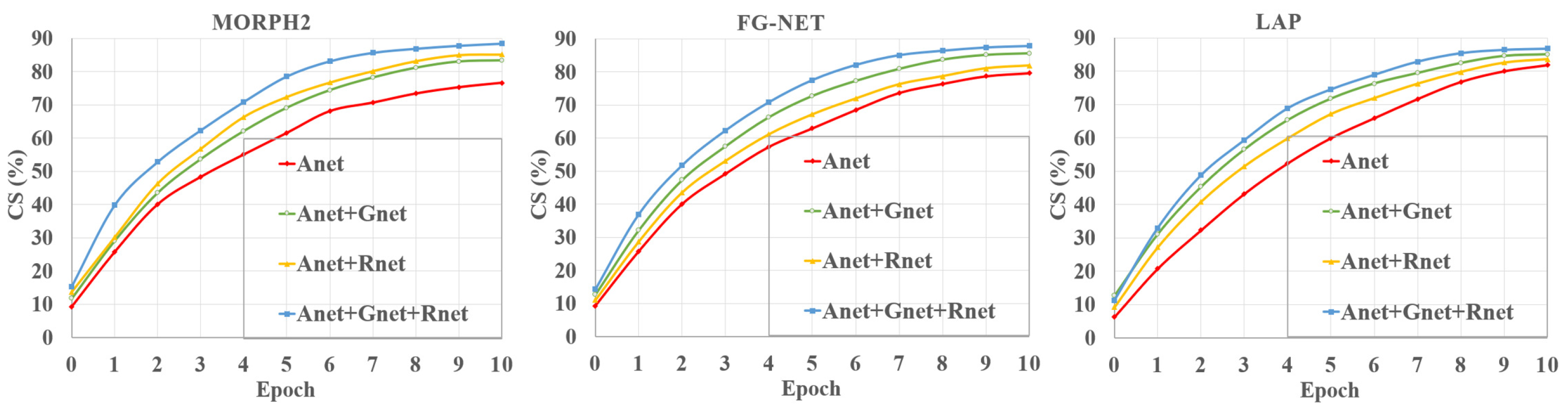
CS is presented to show the performance of different combinations of subnetworks in
Figure 6. It clearly shows that Anet+Gnet and Anet+Rnet consistently outperformed the baseline Anet, demonstrating the effectiveness of both the gender- and race-feature-learning procedures. Moreover, Anet+Gnet+Rnet (i.e., the proposed method) yielded the best result. This was because age estimation was significantly affected by race and gender according to the above analysis. For different targets (race, gender, and age), we used different subnetworks to extract different kinds of features and form more robust and discriminative features. This process improved the performance of age estimation and made our proposed method have lower
MAEs and higher
CS than the single-feature-based learning module. Therefore, the multifeature learning network could exploit more discriminative and robust age features than a single learning module for age estimation.
To further explore the role of Gnet and Rnet, we conducted experiments on different age groups.
Figure 7 presents the prediction results of some samples of different age groups. We can see that the performance of Anet and Anet+Rnet+Gnet was similar when predicting the age of minors. The performance of Anet+Rnet+Gnet was better than single Anet at predicting the age of adults. This was because people of different genders or races have some differences in their aging patterns, and our proposed model could better utilize gender features, which could make the model more flexibility at predicting the age of people of different genders or races. For example, women do not have beards when they are minors or adults, and most men grow a beard in adulthood. Therefore, beards could be used to predict the age of men, but not women.
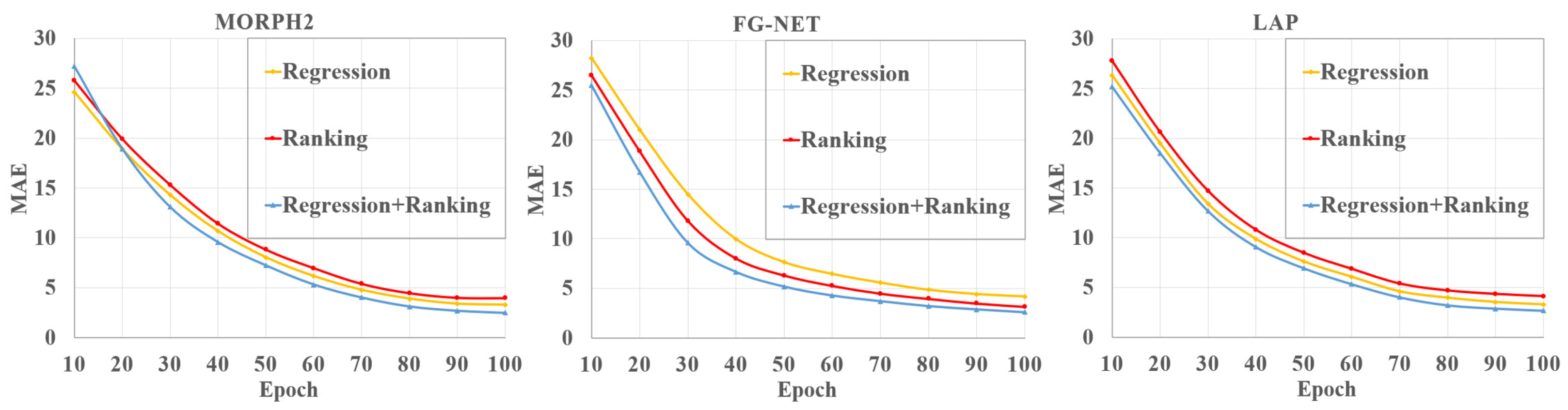
To validate the effectiveness of our regression-ranking-age estimator, we compared the regression estimator, ranking estimator, and regression-ranking estimator on the age estimation task, respectively. Specifically, for the regression estimator, we removed the ranking estimator and preserved only the regression-age estimator. In contrast, for the ranking estimator, we removed the regression estimator and preserved only the ranking-age estimator.
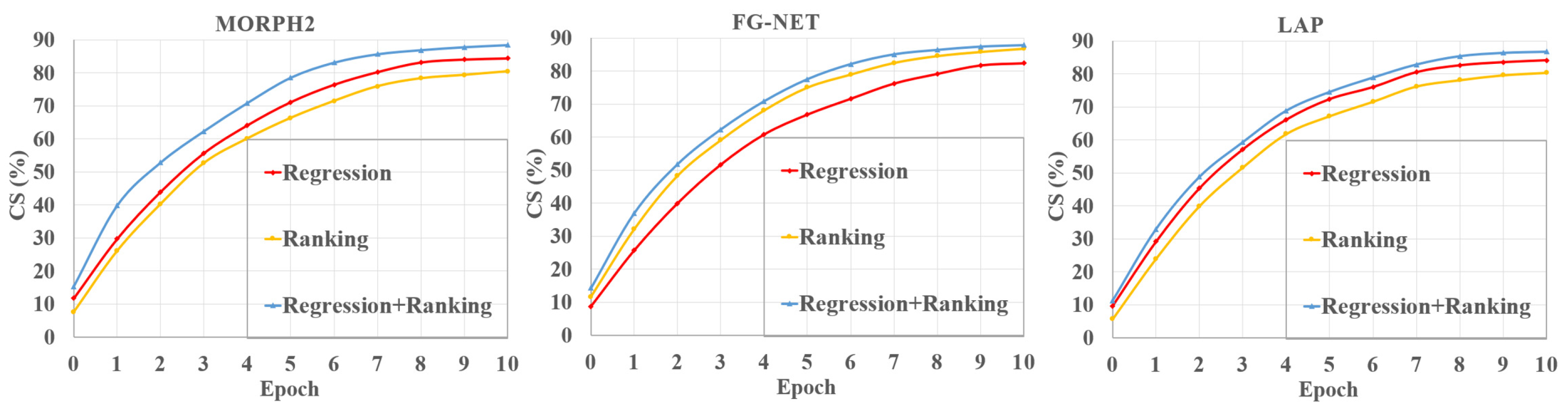
Figure 8 depicts the
MAEs of the three different estimators on the three databases.
CS is also presented to show the performance of different age estimators in
Figure 9. We can see that our fusion estimator outperformed both the regression-only or ranking-only estimators. This was because our method benefited from not only continuous attributes of age, but also the additional ranking constraints. In addition, our proposed regression-ranking-fusion estimator could make a good tradeoff between the continuity and ordinal relationship of age for the age-feature estimator.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}