
Hough Transform-Based Angular Features for Learning-Free Handwritten Keyword Spotting

 ,
,  and
and
Abstract
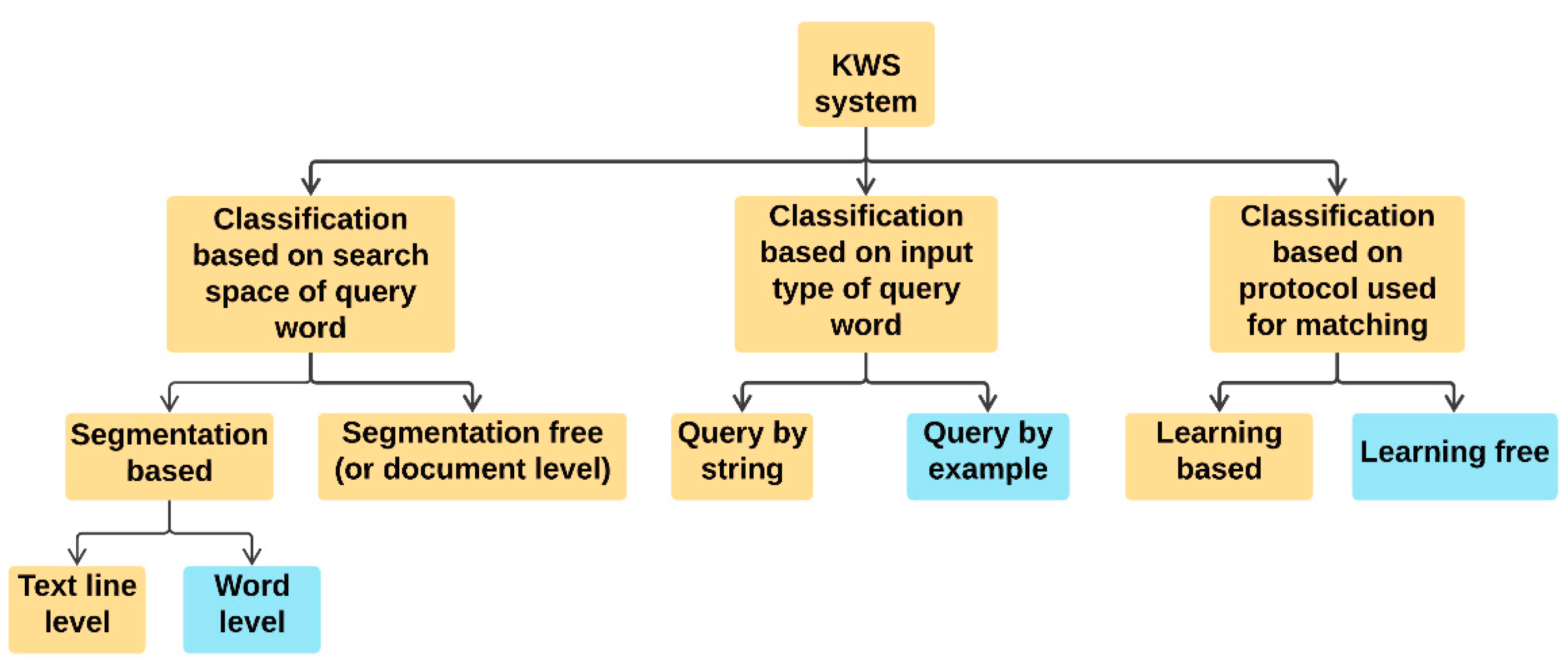
:1. Introduction
- Generation of low-cost angular feature descriptors using HT. The number of features is equal to the number of characters in a query word, obtained from the machine-encoded text of the query word, multiplied by the number of angular bins considered in HT. To the best of our knowledge, this feature has been used here for the first time to deal with the KWS problem, and the dimension of this feature is much lower than that of state-of-the-art features.
- Formation of fuzzy membership function-based image contrast enhancement technique. The contrast enhancement technique helps in skipping the use of the edge detection method before applying HT.
- Application of word image normalization (i.e., slant and skew correction) at a grey level while the general tendency is to apply the same on the binarized image.
- Use of a variable number of vertical fragments (controlled by the number of letters in query word), as opposed to a fixed number of such fragments used by state-of-the-art methods.
2. Previous Work
2.1. Methods That Use Single Feature Types
2.2. Methods That Combine Several Feature Types
3. Present Work
3.1. Pre-Processing
3.1.1. Contrast Normalization
3.1.2. Word Normalization
- (i)
- The length is replaced by , which accounts for about 95% of the total length of the horizontal projection [8]. If and , instead of and respectively represent the new boundaries that define , we have the following relationship given by Equation (5).
- (ii)
- The regularization parameter is adaptive, in the sense that it can adjust its value depending upon the distribution of horizontal projection, thereby ensuring a narrower middle zone for words with elongated ascenders or descenders. The regularization parameter is formulated in Equation (6):
3.2. Vertical Zoning
- An overlapping window of adequate size between two consecutive zones is included, to account for the variation in character size and handwriting style.
- The number of columns in the search and target word images should be such that after zoning (considering the overlapping window), the number of columns in each zone is an integer. Therefore, a re-sizing of the images is required and based on , the number of columns is updated.
3.3. Feature Extraction
3.4. Matching of Feature Descriptor Sequences
- Every value from the first input sequence is to be matched with at least one value from the second sequence, and vice versa.
- The value at the first index from the first sequence is to be matched with the value at the first index from the second sequence, although it need not be the only match.
- The value at the last index from the first sequence is to be matched with the value at the last index from the second sequence, although it need not be the only match.
- The mapping of indices corresponding to value from the first sequence to those of the second sequence must be monotonically increasing and vice versa.
4. Results and Discussion
4.1. Database Description
4.2. Performance Measure
4.3. Parameters Tuning
4.4. Results
4.5. Performance Comparison on the Evaluation Set of ICDAR2015 Competition on KWS for Handwritten Documents (Track IA)
4.6. Error Case Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Wigington, C.; Stewart, S.; Davis, B.; Barrett, B.; Price, B.; Cohen, S. Data Augmentation for Recognition of Handwritten Words and Lines Using a CNN-LSTM Network. In Proceedings of the 14th International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1. [Google Scholar]
- Sueiras, J.; Ruiz, V.; Sanchez, A.; Velez, J.F. Offline Continuous Handwriting Recognition using Sequence to Sequence Neural Networks. Neurocomputing 2018, 289, 119–128. [Google Scholar] [CrossRef]
- Malakar, S.; Ghosh, M.; Bhowmik, S.; Sarkar, R.; Nasipuri, M. A GA based Hierarchical Feature Selection Approach for Handwritten Word Recognition. Neural Comput. Appl. 2019, 1–17. [Google Scholar] [CrossRef]
- Malakar, S.; Ghosh, M.; Sarkar, R.; Nasipuri, M. Development of a Two-Stage Segmentation-Based Word Searching Method for Handwritten Document Images. J. Intell. Syst. 2020, 29. [Google Scholar] [CrossRef]
- Giotis, A.P.; Sfikas, G.; Gatos, B.; Nikou, C. A Survey of Document Image Word Spotting Techniques. Pattern Recognit. 2017, 68, 310–332. [Google Scholar] [CrossRef]
- Malakar, S.; Ghosh, P.; Sarkar, R.; Das, N.; Basu, S.; Nasipuri, M. An Improved Offline Handwritten Character Segmentation Algorithm for Bangla Script. In Proceedings of the 5th Indian International Conference on Artificial Intelligence (IICAI 2011), Tumkur, India, 14–16 December 2011. [Google Scholar]
- Malakar, S.; Sarkar, R.; Basu, S.; Kundu, M.; Nasipuri, M. An Image Database of Handwritten Bangla Words with Automatic Benchmarking Facilities for Character Segmentation Algorithms. Neural Comput. Appl. 2020, 1–20. [Google Scholar] [CrossRef]
- Retsinas, G.; Louloudis, G.; Stamatopoulos, N.; Gatos, B. Efficient Learning-Free Keyword Spotting. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1587–1600. [Google Scholar] [CrossRef]
- Singh, P.K.; Mahanta, S.; Malakar, S.; Sarkar, R.; Nasipuri, M. Development of a Page Segmentation Technique for Bangla Documents Printed in Italic Style. In Proceedings of the 2nd International Conference on Business and Information Management (ICBIM 2014), Durgapur, India, 9–11 January 2014. [Google Scholar]
- Frinken, V.; Fischer, A.; Baumgartner, M.; Bunke, H. Keyword Spotting for Self-Training of BLSTM NN Based Handwriting Recognition Systems. Pattern Recognit. 2014, 47, 1073–1082. [Google Scholar] [CrossRef]
- Venkateswararao, P.; Murugavalli, S. CTC Token Parsing Algorithm Using Keyword Spotting for BLSTM Based Unconstrained Handwritten Recognition. J. Ambient Intell. Humaniz. Comput. 2019, 1–8. [Google Scholar] [CrossRef]
- Retsinas, G.; Louloudis, G.; Stamatopoulos, N.; Gatos, B. Keyword Spotting in Handwritten Documents Using Projections of Oriented Gradients. In Proceedings of the 2016 12th IAPR Workshop on Document Analysis Systems (DAS), Santorini, Greece, 11–14 April 2016; pp. 411–416. [Google Scholar]
- Almazán, J.; Gordo, A.; Fornés, A.; Valveny, E. Word Spotting and Recognition with Embedded Attributes. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 2552–2566. [Google Scholar] [CrossRef]
- Sudholt, S.; Fink, G.A. PHOCNet: A Deep Convolutional Neural Network for Word Spotting in Handwritten Documents. In Proceedings of the International Conference on Frontiers in Handwriting Recognition (ICFHR), Shenzhen, China, 23–26 October 2016; pp. 277–282. [Google Scholar]
- Ghosh, S.; Bhattacharya, R.; Majhi, S.; Bhowmik, S.; Malakar, S.; Sarkar, R. In Textual Content Retrieval from Filled-in Form Images. In Proceedings of the the Workshop on Document Analysis and Recognition, Hyderabad, India, 18 December 2018; Springer: Cham, Switzerland, 2018; pp. 27–37. [Google Scholar]
- Bhattacharya, R.; Malakar, S.; Ghosh, S.; Bhowmik, S.; Sarkar, R. Understanding Contents of Filled-In Bangla form Images. Multimed. Tools Appl. 2020, 80, 3529–3570. [Google Scholar] [CrossRef]
- Mondal, T.; Ragot, N.; Ramel, J.Y.; Pal, U. Comparative Study of Conventional Time Series Matching Techniques for Word Spotting. Pattern Recognit. 2018, 73, 47–64. [Google Scholar] [CrossRef]
- Stamatopoulos, N.; Gatos, B.; Louloudis, G.; Pal, U.; Alaei, A. ICDAR 2013 Handwriting Segmentation Contest. In Proceedings of the 2013 12th International Conference on Document Analysis and Recognition, Washington, WA, USA, 25–28 August 2013; pp. 1402–1406. [Google Scholar]
- Yadav, V.; Ragot, N. Text Extraction in Document Images: Highlight on Using Corner Points. In Proceedings of the 2016 12th IAPR Workshop on Document Analysis Systems (DAS), Santorini, Greece, 11–14 April 2016; pp. 281–286. [Google Scholar]
- Rajesh, B.; Javed, M.; Nagabhushan, P. Automatic Tracing and Extraction of Text-Line and Word Segments Directly in JPEG Compressed Document Images. IET Image Process. 2020, 14, 1909–1919. [Google Scholar] [CrossRef]
- Khurshid, K.; Faure, C.; Vincent, N. A Novel Approach for Word Spotting Using Merge-Split Edit Distance. In Proceedings of the Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2009; Volume 5702, pp. 213–220. [Google Scholar]
- Rath, T.M.; Manmatha, R. Word Spotting for Historical Documents. Int. J. Doc. Anal. Recognit. 2007, 9, 139–152. [Google Scholar] [CrossRef] [Green Version]
- Sfikas, G.; Retsinas, G.; Gatos, B. Zoning Aggregated Hypercolumns for Keyword Spotting. In Proceedings of the 2016 15th International Conference on Frontiers in Handwriting Recognition (ICFHR), Shenzhen, China, 23–26 October 2016; pp. 283–288. [Google Scholar]
- Fischer, A.; Keller, A.; Frinken, V.; Bunke, H. Lexicon Free Handwritten Word Spotting using Character HMMs. Pattern Recognit. Lett. 2012, 33, 934–942. [Google Scholar] [CrossRef]
- Frinken, V.; Fischer, A.; Manmatha, R.; Bunke, H. A Novel Word Spotting Method Based on Recurrent Neural Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 211–224. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Al Aghbari, Z.; Brook, S. HAH manuscripts: A Holistic Paradigm for Classifying and Retrieving Historical Arabic Handwritten Documents. Expert Syst. Appl. 2009, 36, 10942–10951. [Google Scholar] [CrossRef]
- Tavoli, R.; Keyvanpour, M. A Method for Handwritten Word Spotting Based on Particle Swarm Optimisation and Multi-Layer Perceptron. IET Softw. 2017, 12, 152–159. [Google Scholar] [CrossRef]
- Mondal, T.; Ragot, N.; Ramel, J.Y.; Pal, U. Flexible Sequence Matching technique: An Effective Learning-Free Approach for Word Spotting. Pattern Recognit. 2016, 60, 596–612. [Google Scholar] [CrossRef]
- Majumder, S.; Ghosh, S.; Malakar, S.; Sarkar, R.; Nasipuri, M. A Voting-Based Technique for Word Spotting in Handwritten Document Images. Multimed. Tools Appl. 2021, 1–24. [Google Scholar] [CrossRef]
- Sarkar, R.; Malakar, S.; Das, N.; Basu, S.; Kundu, M.; Nasipuri, M. Word Extraction and Character Segmentation from Text Lines of Unconstrained Handwritten Bangla Document Images. J. Intell. Syst. 2011, 20, 227–260. [Google Scholar] [CrossRef]
- Almazán, J.; Gordo, A.; Fornés, A.; Valveny, E. Efficient Exemplar Word Spotting. In Proceedings of the Bmvc, Ciudad en Inglaterra, UK, 3–7 September 2012; Volume 1, p. 3. [Google Scholar]
- Zheng, L.; Yang, Y.; Tian, Q. SIFT meets CNN: A Decade Survey of Instance Retrieval. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1224–1244. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Aldavert, D.; Rusiñol, M.; Toledo, R.; Lladós, J. A Study of Bag-Of-Visual-Words Representations for Handwritten Keyword Spotting. Int. J. Doc. Anal. Recognit. 2015, 18, 223–234. [Google Scholar] [CrossRef]
- Puigcerver, J.; Toselli, A.H.; Vidal, E. Icdar2015 Competition on Keyword Spotting for Handwritten Documents. In Proceedings of the 2015 13th International Conference on Document Analysis and Recognition (ICDAR), Tunis, Tunisia, 23–26 August 2015; pp. 1176–1180. [Google Scholar]
- Zagoris, K.; Pratikakis, I.; Gatos, B. Unsupervised Word Spotting in Historical Handwritten Document Images Using Document-Oriented Local Features. IEEE Trans. Image Process. 2017, 26, 4032–4041. [Google Scholar] [CrossRef]
- Yalniz, I.Z.; Manmatha, R. Dependence Models for Searching Text in Document Images. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 49–63. [Google Scholar] [CrossRef] [PubMed]
- Yalniz, I.Z.; Manmatha, R. An Efficient Framework for Searching Text in Noisy Document Images. In Proceedings of the 2012 10th IAPR International Workshop on Document Analysis Systems, Gold Coast, QLD, Australia, 27–29 March 2012; pp. 48–52. [Google Scholar]
- Barakat, B.K.; Alasam, R.; El-Sana, J. Word Spotting Using Convolutional Siamese Network. In Proceedings of the 2018 13th IAPR International Workshop on Document Analysis Systems (DAS), Vienna, Austria, 24–27 April 2018; pp. 229–234. [Google Scholar]
- Khayyat, M.; Lam, L.; Suen, C.Y. Learning-Based Word Spotting System for Arabic Handwritten Documents. Pattern Recognit. 2014, 47, 1021–1030. [Google Scholar] [CrossRef]
- Saabni, R.; Bronstein, A. Fast Keyword Searching Using “Boostmap” Based Embedding. In Proceedings of the 2012 International Conference on Frontiers in Handwriting Recognition (ICFHR), Bari, Italia, 18–20 September 2012; pp. 734–739. [Google Scholar]
- Kovalchuk, A.; Wolf, L.; Dershowitz, N. A Simple and Fast Word Spotting Method. In Proceedings of the 2014 14th International Conference on Frontiers in Handwriting Recognition, Crete, Greece, 1–4 September 2014; pp. 3–8. [Google Scholar]
- Sauvola, J.; Pietikäinen, M. Adaptive Document Image Binarization. Pattern Recognit. 2000, 33, 225–236. [Google Scholar] [CrossRef] [Green Version]
- Otsu, N. A Threshold Selection Method from Gray-Level Histograms. IEEE Trans. Syst. Man. Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef] [Green Version]
- Dong, J.; Dominique, P.; Krzyyzak, A.; Suen, C.Y. Cursive Word Skew/Slant Corrections Based on Radon Transform. In Proceedings of the Eighth International Conference on Document Analysis and Recognition, Seoul, Korea, 31 August–1 September 2005; pp. 478–483. [Google Scholar]
- Dasgupta, J.; Bhattacharya, K.; Chanda, B. A Holistic Approach for Off-Line Handwritten Cursive Word Recognition Using Directional Feature Based on Arnold Transform. Pattern Recognit. Lett. 2016, 79, 73–79. [Google Scholar] [CrossRef]
- Largest Sum Contiguous Subarray. Available online: https://www.geeksforgeeks.org/largest-sum-contiguous-subarray/ (accessed on 1 July 2021).
- Bera, S.K.; Kar, R.; Saha, S.; Chakrabarty, A.; Lahiri, S.; Malakar, S.; Sarkar, R. A One-Pass Approach for Slope and Slant Estimation of Tri-Script Handwritten Words. J. Intell. Syst. 2018, 29, 688–702. [Google Scholar] [CrossRef]
- Fitton, N.C.; Cox, S.J.D. Optimising the Application of the Hough Transform for Automatic Feature Extraction from Geoscientific Images. Comput. Geosci. 1998, 24, 933–951. [Google Scholar] [CrossRef]
- Vijayarajeswari, R.; Parthasarathy, P.; Vivekanandan, S.; Basha, A.A. Classification of Mammogram for Early Detection of Breast Cancer Using SVM Classifier and Hough Transform. Measurement 2019, 146, 800–805. [Google Scholar] [CrossRef]
- Varun, R.; Kini, Y.V.; Manikantan, K.; Ramachandran, S. Face Recognition Using Hough Transform Based Feature Extraction. Procedia Comput. Sci. 2015, 46, 1491–1500. [Google Scholar] [CrossRef] [Green Version]
- Zhao, K.; Han, Q.; Zhang, C.-B.; Xu, J.; Cheng, M.-M. Deep Hough Transform for Semantic Line Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2021. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Zhang, Z. Improving Neural Network Detection Accuracy of Electric Power Bushings in Infrared Images by Hough Transform. Sensors 2020, 20, 2931. [Google Scholar] [CrossRef] [PubMed]
- Al Maadeed, S.; Ayouby, W.; Hassaïne, A.; Aljaam, J.M. Quwi: An Arabic and English Handwriting Dataset for Offline Writer Identification. In Proceedings of the 2012 International Conference on Frontiers in Handwriting Recognition, Bari, Italia, 18–20 September 2012; pp. 746–751. [Google Scholar]
- Zimmermann, M.; Bunke, H. Automatic Segmentation of the IAM Off-Line Database for Handwritten English Text. In Proceedings of the Object Recognition Supported by User Interaction for Service Robots, Quebec City, QC, Canada, 11–15 August 2002; Volume 4, pp. 35–39. [Google Scholar]
- ICDAR. Competition. 2015. Available online: http://icdar2015.imageplusplus.com/ (accessed on 1 July 2021).
- Krishnan, P.; Dutta, K.; Jawahar, C.V. Word Spotting and Recognition Using Deep Embedding. In Proceedings of the 2018 13th IAPR International Workshop on Document Analysis Systems (DAS), Vienna, Austria, 24–27 April 2018; pp. 1–6. [Google Scholar]
- Canny, J. A Computational Approach to Edge Detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, 6, 679–698. [Google Scholar] [CrossRef]
- Retsinas, G. Learning-Free-KWS. Available online: https://github.com/georgeretsi/Learning-Free-KWS (accessed on 1 July 2021).
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Chao, P.; Kao, C.-Y.; Ruan, Y.-S.; Huang, C.-H.; Lin, Y.-L. Hardnet: A Low Memory Traffic Network. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 3552–3561. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 248–255. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Test Case ID | MAP | Test Case ID | MAP | Test Case ID | MAP | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.05 | 0.1 | 6 | 69.93 | 26 | 0.15 | 0.1 | 6 | 67.63 | 51 | 0.25 | 0.1 | 6 | 57.49 |
| 2 | 0.05 | 0.1 | 8 | 71.76 | 27 | 0.15 | 0.1 | 8 | 69.22 | 52 | 0.25 | 0.1 | 8 | 63.06 |
| 3 | 0.05 | 0.1 | 10 | 70.14 | 28 | 0.15 | 0.1 | 10 | 64.35 | 53 | 0.25 | 0.1 | 10 | 57.59 |
| 4 | 0.05 | 0.1 | 12 | 70.23 | 29 | 0.15 | 0.1 | 12 | 65.17 | 54 | 0.25 | 0.1 | 12 | 60.25 |
| 5 | 0.05 | 0.1 | 14 | 68.87 | 30 | 0.15 | 0.1 | 14 | 63.07 | 55 | 0.25 | 0.1 | 14 | 56.57 |
| 6 | 0.05 | 0.3 | 6 | 78.33 | 31 | 0.15 | 0.3 | 6 | 66.1 | 56 | 0.25 | 0.3 | 6 | 61.64 |
| 7 | 0.05 | 0.3 | 8 | 82.38 | 32 | 0.15 | 0.3 | 8 | 70.75 | 57 | 0.25 | 0.3 | 8 | 64.22 |
| 8 | 0.05 | 0.3 | 10 | 79.03 | 33 | 0.15 | 0.3 | 10 | 69.33 | 58 | 0.25 | 0.3 | 10 | 63.18 |
| 9 | 0.05 | 0.3 | 12 | 81.89 | 34 | 0.15 | 0.3 | 12 | 67.29 | 59 | 0.25 | 0.3 | 12 | 62.35 |
| 10 | 0.05 | 0.3 | 14 | 78.8 | 35 | 0.15 | 0.3 | 14 | 66.96 | 60 | 0.25 | 0.3 | 14 | 60.9 |
| 11 | 0.05 | 0.5 | 6 | 67.19 | 36 | 0.15 | 0.5 | 6 | 63.39 | 61 | 0.25 | 0.5 | 6 | 59.42 |
| 12 | 0.05 | 0.5 | 8 | 70.26 | 37 | 0.15 | 0.5 | 8 | 64.72 | 62 | 0.25 | 0.5 | 8 | 63.92 |
| 13 | 0.05 | 0.5 | 10 | 67.14 | 38 | 0.15 | 0.5 | 10 | 63.35 | 63 | 0.25 | 0.5 | 10 | 60.24 |
| 14 | 0.05 | 0.5 | 12 | 69.23 | 39 | 0.15 | 0.5 | 12 | 62.7 | 64 | 0.25 | 0.5 | 12 | 61.55 |
| 15 | 0.05 | 0.5 | 14 | 67.27 | 40 | 0.15 | 0.5 | 14 | 63.07 | 65 | 0.25 | 0.5 | 14 | 58.19 |
| 16 | 0.05 | 0.7 | 6 | 65.93 | 41 | 0.15 | 0.7 | 6 | 62.21 | 66 | 0.25 | 0.7 | 6 | 58.21 |
| 17 | 0.05 | 0.7 | 8 | 68.76 | 42 | 0.15 | 0.7 | 8 | 65.71 | 67 | 0.25 | 0.7 | 8 | 61.22 |
| 18 | 0.05 | 0.7 | 10 | 64.94 | 43 | 0.15 | 0.7 | 10 | 64.32 | 68 | 0.25 | 0.7 | 10 | 58.54 |
| 19 | 0.05 | 0.7 | 12 | 67.72 | 44 | 0.15 | 0.7 | 12 | 63.29 | 69 | 0.25 | 0.7 | 12 | 58.57 |
| 20 | 0.05 | 0.7 | 14 | 65.17 | 45 | 0.15 | 0.7 | 14 | 63.76 | 70 | 0.25 | 0.7 | 14 | 57.59 |
| 21 | 0.05 | 0.9 | 6 | 72.69 | 46 | 0.15 | 0.9 | 6 | 64.57 | 71 | 0.25 | 0.9 | 6 | 61.09 |
| 22 | 0.05 | 0.9 | 8 | 74.63 | 47 | 0.15 | 0.9 | 8 | 67.87 | 72 | 0.25 | 0.9 | 8 | 62.39 |
| 23 | 0.05 | 0.9 | 10 | 70.98 | 48 | 0.15 | 0.9 | 10 | 66.05 | 73 | 0.25 | 0.9 | 10 | 59.56 |
| 24 | 0.05 | 0.9 | 12 | 71.73 | 49 | 0.15 | 0.9 | 12 | 66.65 | 74 | 0.25 | 0.9 | 12 | 60.31 |
| 25 | 0.05 | 0.9 | 14 | 72.96 | 50 | 0.15 | 0.9 | 14 | 67.07 | 75 | 0.25 | 0.9 | 14 | 57.02 |
| Method | Feature Used | Length of Feature Dimension | MAP Score (in %) | ||
|---|---|---|---|---|---|
| IAM | QUWI | ICDAR KWS 2015 | |||
| Mondal et al. [17], 2018 | Column-based feature | 8× image width | 85.64 | 51.38 | 37.69 |
| Mondal et al. [28], 2016 | Column-based feature | 8× image width | 83.65 | 47.28 | 31.22 |
| Malakar et al. [4], 2019 | Modified HOG and Topological | 186 | 81.50 | 52.12 | 35.27 |
| Retsinas et al. [8], 2019 | mPOG | 2520 and 3024 for query and target word images respectively | 75.21 | 52.73 | 47.21 |
| Majumder et al. [29], 2021 | Profile-based features | 2× image width | 82.10 | 50.43 | 32.19 |
| Majumder et al. [29], 2021 | Pre-trained VGG16 [59] | 1024 | 80.35 | 42.18 | 17.12 |
| Majumder et al. [29], 2021 | Pre-trained HarDNet-85 [60] | 2048 | 78.22 | 41.53 | 15.79 |
| Szegedy et al. [62], 2015 | Pre-trained InceptionV3 | 2048 | 44.98 | 30.18 | 12.59 |
| Huang et al. [63], 2017 | Pre-trained DenseNet121 | 2048 | 77.98 | 45.40 | 15.25 |
| Simonyan and Zisserman [59], 2015 | Pre-trained VGG19 | 1024 | 81.15 | 43.91 | 18.64 |
| Proposed method | HT-based angular feature | 12× number of letters in the query word | 86.40 | 53.99 | 45.01 |
| Method | MAP Score (in %) |
|---|---|
| Pattern Recognition Group (PRG) [34], 2015 | 42.44 |
| Computer Vision Center (CVC) [34], 2015 | 30.00 |
| Baseline Method [34], 2015 | 19.35 |
| Retsinas et al. [8], 2019 | 58.40 |
| Proposed method | 56.12 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kundu, S.; Malakar, S.; Geem, Z.W.; Moon, Y.Y.; Singh, P.K.; Sarkar, R. Hough Transform-Based Angular Features for Learning-Free Handwritten Keyword Spotting. Sensors 2021, 21, 4648. https://doi.org/10.3390/s21144648
Kundu S, Malakar S, Geem ZW, Moon YY, Singh PK, Sarkar R. Hough Transform-Based Angular Features for Learning-Free Handwritten Keyword Spotting. Sensors. 2021; 21(14):4648. https://doi.org/10.3390/s21144648
Chicago/Turabian StyleKundu, Subhranil, Samir Malakar, Zong Woo Geem, Yoon Young Moon, Pawan Kumar Singh, and Ram Sarkar. 2021. "Hough Transform-Based Angular Features for Learning-Free Handwritten Keyword Spotting" Sensors 21, no. 14: 4648. https://doi.org/10.3390/s21144648