
Using Embedded Feature Selection and CNN for Classification on CCD-INID-V1—A New IoT Dataset


Abstract
:1. Introduction
- To demonstrate a real-world attack scenario and evaluate the effectiveness of our proposed IDS, we create an IoT network-based dataset, namely, Center for Cyber Defense (CCD) IoT Network Intrusion Dataset V1 (CCD-INID-V1). The data is collected in the smart lab and smart home environments using Rainbow HAT sensor boards installed on Raspberry Pis.
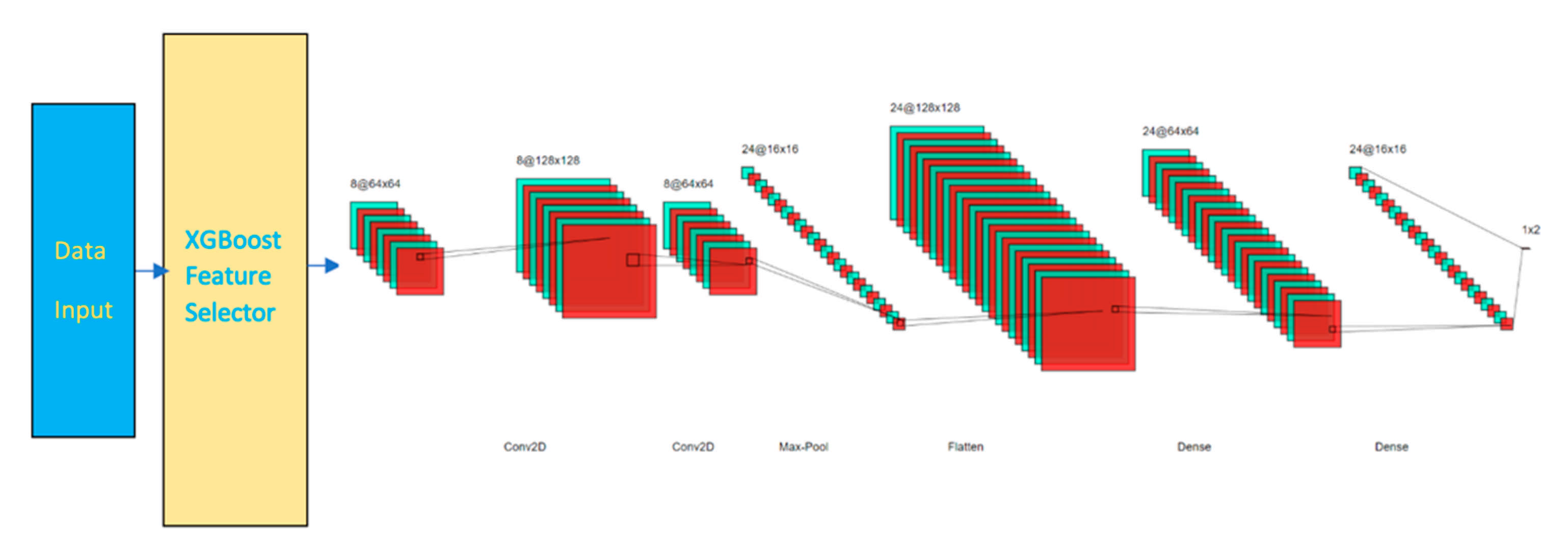
- To provide a solution to devise resource constraints and utilize IDS placement, we propose a lightweight and hybrid technique for IoT intrusion detections. The placement of IDS for IoT networks are primarily in: cloud [43,44], fog [45], and edge [46]. In this work, we adopt a hybrid format [47], which is a combination of fog computing and cloud computing. We monitor and generate features at the fog layer and compute detection training and testing at the cloud layer. Our proposed hybrid method combines an embedded model (EM) for feature selection and a CNN for attack classification. The proposed intrusion detection method has two models: (a) RCNN, where RF is combined with CNN, and (b) XCNN, where XGBoost is combined with CNN. The EM selects the most influential features without compromising the detection rates.
- To compare the effectiveness of our proposed technique to traditional ML algorithms, such as k-nearest neighbors (KNN), naïve bayes (NB), logistic regression (LR), and support vector machine (SVM), we use two publicly available datasets, the detection_of_IoT_botnet_attacks_N_BaIoT dataset (Balot) [48], and the CIRA-CIC-DoHBrw-2020 dataset (DoH20) [49], as benchmarks and provide the comparative results of anomaly and multiclass classifications.
2. Related Work
3. Methods and Datasets
3.1. Architectures for RCNN and XCNN
- An embedding layer of batch size 512
- A convolutional 2D layer of size 64 × 64 using RELU activation function
- A dropout layer with rate of 0.3
- A convolutional 2D layer of size 128 × 128 using RELU activation function
- A maxpooling layer
- A flatten layer
- A dense layer of size 128
- A dense layer of size 64
- A dropout layer with rate of 0.3
- A dense layer of size 16
- An output layer of 2 or n classes using Adam optimizer
3.2. Datasets Used
3.2.1. CCD IoT Network Intrusion Dataset V1
3.2.2. List of Attacks
- ARP Poisoning—ARP Poisoning generates minimum web traffic. It is extremely challenging for IDS to pick up the signature of this type of attack. We wanted to see how well our IDS can handle this attack signature with limited trace.
- ARP DoS—This attack leaves plenty of “breadcrumbs” for IDS to pick up. We sent 600,000 messages at our only available socket at a one-second interval continuously for 12 h.
- UDP Flood—Similar to the previous attack, however this attack uses a different protocol. We wanted to test how our IDS handle network traffic with different protocols.
- Hydra Bruteforce with Asterisk protocol—This type of attack attempts to gain authentication using commonly used password combinations. Hydra is a well-known attack toolkit. The Asterisk protocol is an interesting choice for our attack selection because it is a protocol that is standard for voice-over-IP, which relates to many users that rely on communication tools such as Zoom, Skype, WeChat, WhatsApp during the COVID-19 pandemic.
- SlowLoris—SlowLoris is a new representation for low-bandwidth Distributed Denial-of-Service attacks [115]. First developed by a hacker named Robert “RSnake” Hansen, this attack can bring down high-bandwidth servers with a single botnet computer, as evidenced in the 2009 Iranian presidential election [116].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name of Attack | Type of Attack | Description |
|---|---|---|
| ARP Poisoning | Man-in-the-Middle | ARP poisoning occurs when an attacker sends falsified ARP messages over a local area network (LAN) to link an attacker’s MAC address with the IP address of a legitimate computer or server on the network. Once the attacker’s MAC address is linked to an authentic IP address, the attacker can receive any messages directed to the legitimate MAC address. As a result, the attacker can intercept, modify or block communication to the legitimate MAC address [117]. |
| ARP DoS | DoS | In ARP flooding, the affected system sends ARP replies to all systems connected in a network, causing incorrect entries in the ARP cache. The result is that the affected system is unable to resolve IP and MAC addresses because of the wrong entries in the ARP cache. The affected system is unable to connect to any other system in the network [118]. |
| UDP Flood | DoS | A UDP flood is a type of DoS attack in which a large number of User Datagram Protocol (UDP) packets are sent to a targeted server with the aim of overwhelming the device’s ability to process and respond. The firewall protecting the targeted server can also become exhausted due to UDP flooding, resulting in a DoS to legitimate traffic [119]. |
| Hydra Bruteforce with Asterisk | Bruteforce | Hydra is a parallelized network logon cracker built in various operating systems such as Kali Linux, Parrot, and other penetration testing environments. Hydra works by using different approaches to perform brute-force attacks to guess the right username and password combination [120]. Asterisk supports several standard voice-over-IP protocols, including the Session Initiation Protocol (SIP), the Media Gateway Control Protocol (MGCP), and H. 323. Asterisk supports most SIP telephones, acting both as registrar and back-to-back user agent [121]. |
| SlowLoris | Distributed DoS | SlowLoris is a type of DoS attack tool which allows a single machine to take down another machine’s web server with minimal bandwidth and side effects on unrelated services and ports. SlowLoris tries to keep many connections to the target web server open and hold them open as long as possible. It accomplishes this by opening connections to the target web server and sending a partial request. Periodically, it will send subsequent HTTP headers, adding to, but never completing, the request. Affected servers will keep these connections open, filling their maximum concurrent connection pool, eventually denying additional connection attempts from clients [115]. |
3.2.3. Feature Engineering Using NFStream
- Statistical features extraction: NFStream provides the post-mortem statistical features (e.g., min, mean, stddev and max of packet size and inter arrival time) and early flow features (e.g., sequence of first n packets sizes, inter arrival times and directions).
- Flexibility: NFStream is easily extensible. The project is open-sourced and NFPlugins can be used for feature engineering.
- NFStreamer is a driver process. The driver’s main responsibility involves setting the overall workflow, which is mostly an orchestration of parallel metering processes.
- Meters make up the integral parts to the NFStream framework. Meters transform information gathered through flow-aggregation into statistical features until flow is terminated by expiration (active timeout, inactive timeout). After processing (e.g., timestamped, decoded, truncated), raw packets are dispatched across meters.
3.3. Detection_of_IoT_botnet_attacks_N_BaIoT Dataset
Dataset Summary
- (1)
- BL_Scan: Scanning the network for vulnerable devices
- (2)
- BL_Junk: Sending spam data
- (3)
- BL_UDP: UDP flooding
- (4)
- BL_TCP: TCP flooding
- (5)
- BL_COMBO: Sending spam data and opening a connection to a specified IP address and port
- (1)
- Mirai_Scan: Automatic scanning for vulnerable devices
- (2)
- Mirai_Ack: Ack flooding
- (3)
- Mirai_Syn: Syn flooding
- (4)
- Mirai_UDP: UDP flooding
- (5)
- Mirai_UDPplain: UDP flooding with fewer options, optimized for higher packet-per-second (PPS).
3.4. CIRA-CIC-DoHBrw-2020 Dataset
Dataset Summary
4. Experimental Setup
4.1. Data Preparation and Pre-Processing
4.2. Metrics Used for Evaluations
5. Results
5.1. Feature Importance
5.2. Training, Testing Loss and Accuracy over Epochs
5.3. Confusion Matrix Comparisons
5.4. Comparison of Precision, Recall, F1-Score
5.5. Comparison of ROC and AUC
5.6. Efficiency Comparisons
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Khurpade, J.M.; Rao, D.; Sanghavi, P.D. A Survey on IOT and 5G Network. In Proceedings of the 2018 International Conference on Smart City and Emerging Technology (ICSCET), Mumbai, India, 5 January 2018; IEEE: New York, NY, USA, 2018; pp. 1–3. [Google Scholar]
- Nespoli, P.; Mármol, F.G.; Vidal, J.M. Battling against cyberattacks: Towards pre-standardization of countermeasures. Clust. Comput. 2021, 24, 57–81. [Google Scholar] [CrossRef]
- Othmana, Z.; Rahimb, N.; Sadiqc, M. The Human Dimension as the Core Factor in Dealing with Cyberattacks in Higher Education. Int. J. Innov. Creat. Chang. 2020, 11, 1–19. [Google Scholar]
- Gadirova, N. The Impacts of Cyberattacks on Private Firms’ Cash Holdings. Doctoral Dissertation, University of Ottawa, Ottawa, ON, Canada, 2021. [Google Scholar]
- Putchala, M.K. Deep Learning Approach for Intrusion Detection System (ids) in the Internet of Things (iot) Network Using Gated Recurrent Neural Networks (gru). Master’s Thesis, Wright State University, Dayton, OH, USA, 2017. [Google Scholar]
- Li, J.; Zhao, Z.; Li, R. Machine learning-based IDS for software-defined 5G network. IET Netw. 2017, 7, 53–60. [Google Scholar] [CrossRef] [Green Version]
- Pushpam, C.A.; Jayanthi, J.G. Systematic Literature Survey on IDS Based on Data Mining. In Proceedings of the International Conference on Computer Networks and Inventive Communication Technologies, Coimbatore, India, 23–24 May 2019; Springer: Cham, Switzerland, 2020; pp. 850–860. [Google Scholar]
- Mishra, P.; Pilli, E.S.; Varadharajan, V.; Tupakula, U. Intrusion detection techniques in cloud environment: A survey. J. Netw. Comput. Appl. 2017, 77, 18–47. [Google Scholar] [CrossRef]
- Lee, S.K.; Bae, M.; Kim, H. Future of IoT networks: A survey. Appl. Sci. 2017, 7, 1072. [Google Scholar] [CrossRef]
- Balaji, S.; Nathani, K.; Santhakumar, R. IoT technology, applications and challenges: A contemporary survey. Wirel. Pers. Commun. 2019, 108, 363–388. [Google Scholar] [CrossRef]
- Hassija, V.; Chamola, V.; Saxena, V.; Jain, D.; Goyal, P.; Sikdar, B. A survey on IoT security: Application areas, security threats, and solution architectures. IEEE Access 2019, 7, 82721–82743. [Google Scholar] [CrossRef]
- Galeano-Brajones, J.; Carmona-Murillo, J.; Valenzuela-Valdés, J.F.; Luna-Valero, F. Detection and mitigation of dos and ddos attacks in iot-based stateful sdn: An experimental approach. Sensors 2020, 20, 816. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, Z.; Yu, H. Ransomware’s origin, explosions, and its evolution. Int. J. Adv. Electron. Comput. Sci. 2018, 5, 2394–2835. [Google Scholar]
- Tahaei, H.; Afifi, F.; Asemi, A.; Zaki, F.; Anuar, N.B. The rise of traffic classification in IoT networks: A survey. J. Netw. Comput. Appl. 2020, 154, 102538. [Google Scholar] [CrossRef]
- Mohammadi, M.; Al-Fuqaha, A.; Sorour, S.; Guizani, M. Deep learning for IoT big data and streaming analytics: A survey. IEEE Commun. Surv. Tutor. 2018, 20, 2923–2960. [Google Scholar] [CrossRef] [Green Version]
- Bay, S.D.; Kibler, D.; Pazzani, M.J.; Smyth, P. The UCI KDD Archive of Large Data Sets for Data Mining Research and Experimentation. ACM SIGKDD Explor. Newsl. 2000, 2, 81–85. [Google Scholar] [CrossRef] [Green Version]
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A. A Detailed Analysis of the KDD CUP 99 Data Set. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence for Security and Defense Applications, Ottawa, ON, Canada, 8–10 July 2009. [Google Scholar]
- Venkatraman, S.; Alazab, M. Research Article Use of Data Visualisation for Zero-Day Malware Detection. Secur. Commun. Netw. 2018, 2018, 1728303. [Google Scholar] [CrossRef]
- Al-Hadhrami, Y.; Hussain, F.K. Real time dataset generation framework for intrusion detection systems in IoT. Future Gener. Comput. Syst. 2020, 108, 414–423. [Google Scholar] [CrossRef]
- Anagnostopoulos, M.; Spathoulas, G.; Viaño, B.; Augusto-Gonzalez, J. Tracing Your Smart-Home Devices Conversations: A Real World IoT Traffic Data-Set. Sensors 2020, 20, 6600. [Google Scholar] [CrossRef] [PubMed]
- Parmisano, A.; Garcia, S.; Erquiaga, M.J. A Labeled Dataset with Malicious and Benign IoT Network Traffic; Stratosphere Laboratory: Praha, Czech Republic, 2020. [Google Scholar]
- Kunang, Y.N.; Nurmaini, S.; Stiawan, D.; Suprapto, B.Y. Attack classification of an intrusion detection system using deep learning and hyperparameter optimization. J. Inf. Secur. Appl. 2021, 58, 102804. [Google Scholar]
- Zarpelão, B.B.; Miani, R.S.; Kawakani, C.T.; de Alvarenga, S.C. A survey of intrusion detection in Internet of Things. J. Netw. Comput. Appl. 2017, 84, 25–37. [Google Scholar] [CrossRef]
- Liu, Z.; Thapa, N.; Shaver, A.; Roy, K.; Yuan, X.; Khorsandroo, S. Anomaly Detection on IoT Network Intrusion Using Machine Learning. In Proceedings of the 2020 International Conference on Artificial Intelligence, Big Data, Computing and Data Communication Systems (icABCD), Durban, South Africa, 6–7 August 2020; IEEE: Red Hook, NY, USA, 2020; pp. 1–5. [Google Scholar]
- Ghugar, U.; Pradhan, J. ML-IDS: MAC Layer Trust-Based Intrusion Detection System for Wireless Sensor Networks. In Computational Intelligence in Data Mining; Springer: Singapore, 2020; pp. 427–434. [Google Scholar]
- Alhowaide, A.; Alsmadi, I.; Tang, J. PCA, Random-Forest and Pearson Correlation for Dimensionality Reduction in IoT IDS. In Proceedings of the 2020 IEEE International IOT, Electronics and Mechatronics Conference (IEMTRONICS), Vancouver, BC, Canada, 9–12 September 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Mishra, P.; Varadharajan, V.; Tupakula, U.; Pilli, E.S. A detailed investigation and analysis of using machine learning techniques for intrusion detection. IEEE Commun. Surv. Tutor. 2018, 21, 686–728. [Google Scholar] [CrossRef]
- Xie, J.; Song, Z.; Li, Y.; Zhang, Y.; Yu, H.; Zhan, J.; Ma, Z.; Qiao, Y.; Zhang, J.; Guo, J. A survey on machine learning-based mobile big data analysis: Challenges and applications. Wirel. Commun. Mob. Comput. 2018, 2018, 8738613. [Google Scholar] [CrossRef]
- Amanullah, M.A.; Habeeb, R.A.; Nasaruddin, F.H.; Gani, A.; Ahmed, E.; Nainar, A.S.; Akim, N.M.; Imran, M. Deep learning and big data technologies for IoT security. Comput. Commun. 2020, 151, 495–517. [Google Scholar] [CrossRef]
- Sendak, M.; Elish, M.C.; Gao, M.; Futoma, J.; Ratliff, W.; Nichols, M.; Bedoya, A.; Balu, S.; O’Brien, C. “The human body is a black box” supporting clinical decision-making with deep learning. In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, Barcelona, Spain, 27–30 January 2020; pp. 99–109. [Google Scholar]
- Sun, J.; Tian, Z.; Fu, Y.; Geng, J.; Liu, C. Digital twins in human understanding: A deep learning-based method to recognize personality traits. Int. J. Comput. Integr. Manuf. 2020, 1–14. [Google Scholar] [CrossRef]
- Zaman, S.; Karray, F. Lightweight IDS based on features selection and IDS classification scheme. In Proceedings of the 2009 international conference on computational science and engineering, Vancouver, BC, Canada, 29–31 August 2009; IEEE: Los Alamitos, CA, USA, 2009; Volume 3, pp. 365–370. [Google Scholar]
- Rai, A. Explainable AI: From black box to glass box. J. Acad. Mark. Sci. 2020, 48, 137–141. [Google Scholar] [CrossRef] [Green Version]
- Lu, Y.Y.; Fan, Y.; Lv, J.; Noble, W.S. DeepPINK: Reproducible feature selection in deep neural networks. arXiv 2018, arXiv:1809.01185. [Google Scholar]
- Aman1608. Available online: https://www.analyticsvidhya.com/blog/2020/10/feature-selection-techniques-in-machine-learning/ (accessed on 21 April 2021).
- Chang, W.; Ji, X.; Xiao, Y.; Zhang, Y.; Chen, B.; Liu, H.; Zhou, S. Prediction of Hypertension Outcomes Based on Gain Sequence Forward Tabu Search Feature Selection and XGBoost. Diagnostics 2021, 11, 792. [Google Scholar] [CrossRef] [PubMed]
- Zhang, W.; Wu, C.; Zhong, H.; Li, Y.; Wang, L. Prediction of undrained shear strength using extreme gradient boosting and random forest based on Bayesian optimization. Geosci. Front. 2021, 12, 469–477. [Google Scholar] [CrossRef]
- Zhu, M. Construction of Quantization Strategy Based on Random Forest and XGBoost. In Proceedings of the 2020 Conference on Artificial Intelligence and Healthcare, Taiyuan, China, 23–25 October 2020; pp. 5–9. [Google Scholar]
- Misir, R.; Mitra, M.; Samanta, R.K. A reduced set of features for chronic kidney disease prediction. J. Pathol. Inf. 2017, 8, 24. [Google Scholar]
- Kondo, M.; Bezemer, C.P.; Kamei, Y.; Hassan, A.E.; Mizuno, O. The impact of feature reduction techniques on defect prediction models. Empir. Softw. Eng. 2019, 24, 1925–1963. [Google Scholar] [CrossRef]
- Sheikh, N.U.; Rahman, H.; Vikram, S.; AlQahtani, H. A Lightweight Signature-Based IDS for IoT Environment. arXiv 2018, arXiv:1811.04582. [Google Scholar]
- Khraisat, A.; Alazab, A. A critical review of intrusion detection systems in the internet of things: Techniques, deployment strategy, validation strategy, attacks, public datasets and challenges. Cybersecurity 2021, 4, 1–27. [Google Scholar] [CrossRef]
- Dizdarević, J.; Carpio, F.; Jukan, A.; Masip-Bruin, X. A survey of communication protocols for internet of things and related challenges of fog and cloud computing integration. ACM Comput. Surv. (CSUR) 2019, 51, 1–29. [Google Scholar] [CrossRef]
- Chen, Y.C.; Chang, Y.C.; Chen, C.H.; Lin, Y.S.; Chen, J.L.; Chang, Y.Y. Cloud-fog computing for information-centric Internet-of-Things applications. In Proceedings of the 2017 International Conference on Applied System Innovation (ICASI), Sapporo, Japan, 13–17 May 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 637–640. [Google Scholar]
- Dinh, T.; Kim, Y.; Lee, H. A location-based interactive model of internet of things and cloud (IoT-Cloud) for mobile cloud computing applications. Sensors 2017, 17, 489. [Google Scholar] [CrossRef] [Green Version]
- Wang, T.; Zhang, G.; Liu, A.; Bhuiyan, M.Z.A.; Jin, Q. A secure IoT service architecture with an efficient balance dynamics based on cloud and edge computing. IEEE Internet Things J. 2018, 6, 4831–4843. [Google Scholar] [CrossRef]
- Tawalbeh, L.A.; Muheidat, F.; Tawalbeh, M.; Quwaider, M. IoT Privacy and security: Challenges and solutions. Appl. Sci. 2020, 10, 4102. [Google Scholar] [CrossRef]
- Meidan, Y.; Bohadana, M.; Mathov, Y.; Mirsky, Y.; Breitenbacher, D.; Shabtai, A.; Elovici, Y. N-BaIoT: Network-based Detection of IoT Botnet Attacks Using Deep Autoencoders. IEEE Pervasive Comput. 2018, 17, 12–22. [Google Scholar] [CrossRef] [Green Version]
- MontazeriShatoori, M.; Davidson, L.; Kaur, G.; Lashkari, A.H. Detection of DoH Tunnels using Time-series Classification of Encrypted Traffic. In Proceedings of the 5th IEEE Cyber Science and Technology Congress, Calgary, AB, Canada, 17–22 August 2020. [Google Scholar]
- Di Mauro, M.; Galatro, G.; Liotta, A. Experimental Review of Neural-based approaches for Network Intrusion Management. IEEE Trans. Netw. Serv. Manag. 2020, 17, 2480–2495. [Google Scholar] [CrossRef]
- Kim, A.; Park, M.; Lee, D.H. AI-IDS: Application of deep learning to real-time Web intrusion detection. IEEE Access 2020, 8, 70245–70261. [Google Scholar] [CrossRef]
- Ravikumar, G.; Singh, A.; Babu, J.R.; Govindarasu, M. D-IDS for Cyber-Physical DER Modbus System-Architecture, Modeling, Testbed-based Evaluation. In Proceedings of the 2020 Resilience Week (RWS), Salt Lake City, UT, USA, 19–23 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 153–159. [Google Scholar]
- Yang, H.; Chen, Y. Research on IDS Data Fusion Model Based on DS Evidence Theory. In Proceedings of the 2012 International Conference on Convergence Computer Technology, Daejeon, Korea, 23–25 August 2012; pp. 286–289. [Google Scholar]
- Li, W.; Dai, Y.X.; Lian, Y.F.; Feng, P.H. Context sensitive host-based IDS using hybrid automaton. J. Softw. 2009, 20, 138–151. [Google Scholar] [CrossRef]
- Bakhsh, S.T.; Alghamdi, S.; Alsemmeari, R.A.; Hassan, S.R. An adaptive intrusion detection and prevention system for Internet of Things. Int. J. Distrib. Sens. Netw. 2019, 15. [Google Scholar] [CrossRef]
- Maldonado, S.; López, J. Dealing with high-dimensional class-imbalanced datasets: Embedded feature selection for SVM classification. Appl. Soft Comput. 2018, 67, 94–105. [Google Scholar] [CrossRef]
- Lu, M. Embedded feature selection accounting for unknown data heterogeneity. Expert Syst. Appl. 2019, 119, 350–361. [Google Scholar] [CrossRef]
- Liu, H.; Zhou, M.; Liu, Q. An embedded feature selection method for imbalanced data classification. IEEE/CAA J. Autom. Sin. 2019, 6, 703–715. [Google Scholar] [CrossRef]
- Chen, Z.; He, N.; Huang, Y.; Qin, W.T.; Liu, X.; Li, L. Integration of a deep learning classifier with a random forest approach for predicting malonylation sites. Genom. Proteom. Bioinform. 2018, 16, 451–459. [Google Scholar] [CrossRef]
- Thapa, N.; Liu, Z.; Kc, D.B.; Gokaraju, B.; Roy, K. Comparison of Machine Learning and Deep Learning Models for Network Intrusion Detection Systems. Future Internet 2020, 12, 167. [Google Scholar] [CrossRef]
- Maleki, N.; Zeinali, Y.; Niaki, S.T.A. A k-NN method for lung cancer prognosis with the use of a genetic algorithm for feature selection. Expert Syst. Appl. 2021, 164, 113981. [Google Scholar] [CrossRef]
- Rahman, M.A.; Muniyandi, R.C. An enhancement in cancer classification accuracy using a two-step feature selection method based on artificial neural networks with 15 neurons. Symmetry 2020, 12, 271. [Google Scholar] [CrossRef] [Green Version]
- Mourad, M.; Moubayed, S.; Dezube, A.; Mourad, Y.; Park, K.; Torreblanca-Zanca, A.; Torrecilla, J.S.; Cancilla, J.C.; Wang, J. Machine learning and feature selection applied to SEER data to reliably assess thyroid cancer prognosis. Sci. Rep. 2020, 10, 1–11. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Haq, A.U.; Li, J.P.; Saboor, A.; Khan, J.; Wali, S.; Ahmad, S.; Ali, A.; Khan, G.A.; Zhou, W. Detection of Breast Cancer Through Clinical Data Using Supervised and Unsupervised Feature Selection Techniques. IEEE Access 2021, 9, 22090–22105. [Google Scholar] [CrossRef]
- Malhi, A.; Gao, R.X. PCA-based feature selection scheme for machine defect classification. IEEE Trans. Instrum. Meas. 2004, 53, 1517–1525. [Google Scholar] [CrossRef]
- Song, F.; Guo, Z.; Mei, D. Feature selection using principal component analysis. In Proceedings of the 2010 International Conference on System Science, Engineering Design and Manufacturing Informatization, Nanjing, China, 20–23 October 2019; IEEE: Los Alamitos, CA, USA, 2020; Volume 1, pp. 27–30. [Google Scholar]
- Li, S.; Harner, E.J.; Adjeroh, D.A. Random KNN feature selection-a fast and stable alternative to Random Forests. BMC Bioinform. 2011, 12, 450. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tahir, M.A.; Bouridane, A.; Kurugollu, F. Simultaneous feature selection and feature weighting using Hybrid Tabu Search/K-nearest neighbor classifier. Pattern Recognit. Lett. 2007, 28, 438–446. [Google Scholar] [CrossRef]
- Chen, J.; Huang, H.; Tian, S.; Qu, Y. Feature selection for text classification with Naïve Bayes. Expert Syst. Appl. 2009, 36, 5432–5435. [Google Scholar] [CrossRef]
- Zhang, M.L.; Peña, J.M.; Robles, V. Feature selection for multi-label naive Bayes classification. Inf. Sci. 2009, 179, 3218–3229. [Google Scholar] [CrossRef]
- Cheng, Q.; Varshney, P.K.; Arora, M.K. Logistic regression for feature selection and soft classification of remote sensing data. IEEE Geosci. Remote Sens. Lett. 2006, 3, 491–494. [Google Scholar] [CrossRef]
- Bursac, Z.; Gauss, C.H.; Williams, D.K.; Hosmer, D.W. Purposeful selection of variables in logistic regression. Source Code Biol. Med. 2008, 3, 1–8. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kursa, M.B. Robustness of Random Forest-based gene selection methods. BMC Bioinform. 2014, 15, 8. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cai, Z.; Xu, D.; Zhang, Q.; Zhang, J.; Ngai, S.M.; Shao, J. Classification of lung cancer using ensemble-based feature selection and machine learning methods. Mol. BioSyst. 2015, 11, 791–800. [Google Scholar] [CrossRef]
- Lin, R.H.; Pei, Z.X.; Ye, Z.Z.; Guo, C.C.; Wu, B.D. Hydrogen fuel cell diagnostics using random forest and enhanced feature selection. Int. J. Hydrogen Energy 2020, 45, 10523–10535. [Google Scholar] [CrossRef]
- Niu, D.; Wang, K.; Sun, L.; Wu, J.; Xu, X. Short-term photovoltaic power generation forecasting based on random forest feature selection and CEEMD: A case study. Appl. Soft Comput. 2020, 93, 106389. [Google Scholar] [CrossRef]
- Yao, R.; Li, J.; Hui, M.; Bai, L.; Wu, Q. Feature Selection Based on Random Forest for Partial Discharges Characteristic Set. IEEE Access 2020, 8, 159151–159161. [Google Scholar] [CrossRef]
- Hsieh, C.P.; Chen, Y.T.; Beh, W.K.; Wu, A.Y.A. Feature Selection Framework for XGBoost Based on Electrodermal Activity in Stress Detection. In Proceedings of the 2019 IEEE International Workshop on Signal Processing Systems (SiPS), Nanjing, China, 20–23 October 2019; IEEE: Red Hook, NY, USA, 2020; pp. 330–335. [Google Scholar]
- Zhanshan, L.; Zhaogeng, L.I.U. Feature selection algorithm based on XGBoost. J. Commun. 2019, 40, 101. [Google Scholar]
- Shi, X.; Wong, Y.D.; Li, M.Z.F.; Chai, C. Accident risk prediction based on driving behavior feature learning using CART and XGBoost (No. 18-06270). In Proceedings of the Transportation Research Board 97th Annual Meeting, Washington, DC, USA, 7–11 August 2018. [Google Scholar]
- Zheng, H.; Yuan, J.; Chen, L. Short-term load forecasting using EMD-LSTM neural networks with a Xgboost algorithm for feature importance evaluation. Energies 2017, 10, 1168. [Google Scholar] [CrossRef] [Green Version]
- Kasongo, S.M.; Sun, Y. Performance Analysis of Intrusion Detection Systems Using a Feature Selection Method on the UNSW-NB15 Dataset. J. Big Data 2020, 7, 1–20. [Google Scholar] [CrossRef]
- Hasan, M.A.M.; Nasser, M.; Ahmad, S.; Molla, K.I. Feature selection for intrusion detection using random forest. J. Inf. Secur. 2016, 7, 129–140. [Google Scholar] [CrossRef] [Green Version]
- Gharaee, H.; Hosseinvand, H. A new feature selection IDS based on genetic algorithm and SVM. In Proceedings of the 2016 8th International Symposium on Telecommunications (IST), Tehran, Iran, 27–28 September 2016; pp. 139–144. [Google Scholar]
- Sharafaldin, I.; Lashkari, A.H.; Ghorbani, A.A. Toward Generating a New Intrusion Detection Dataset and Intrusion Traffic Characterization. In Proceedings of the 4th International Conference on Information Systems Security and Privacy (ICISSP), Madeira, Portugal, 22–24 January 2018. [Google Scholar]
- Han, K.; Wang, Y.; Zhang, C.; Li, C.; Xu, C. Autoencoder inspired unsupervised feature selection. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 2941–2945. [Google Scholar]
- Wang, S.; Ding, Z.; Fu, Y. Feature selection guided auto-encoder. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–10 February 2017; Volume 31. [Google Scholar]
- Sakurada, M.; Yairi, T. Anomaly detection using autoencoders with nonlinear dimensionality reduction. In Proceedings of the MLSDA 2014 2nd Workshop on Machine Learning for Sensory Data Analysis, Gold Coast, QLD, Australia, 2 December 2014; pp. 4–11. [Google Scholar]
- Roopak, M.; Tian, G.Y.; Chambers, J. An intrusion detection system against ddos attacks in iot networks. In Proceedings of the 2020 10th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 6–8 January 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 0562–0567. [Google Scholar]
- Zhong, M.; Zhou, Y.; Chen, G. Sequential model based intrusion detection system for IoT servers using deep learning methods. Sensors 2021, 21, 1113. [Google Scholar] [CrossRef]
- Xie, M.; Hu, J. Evaluating host-based anomaly detection systems: A preliminary analysis of adfa-ld. In Proceedings of the 2013 6th International Congress on Image and Signal Processing (CISP), Hangzhou, China, 16–18 December 2013; Volume 3, pp. 1711–1716. [Google Scholar]
- Shurman, M.; Khrais, R.; Yateem, A. DoS and DDoS Attack Detection Using Deep Learning and IDS. Int. Arab J. Inf. Technol. 2020, 17, 655–661. [Google Scholar]
- Sharafaldin, I.; Lashkari, A.H.; Hakak, S.; Ghorbani, A.A. Developing Realistic Distributed Denial of Service (DDoS) Attack Dataset and Taxonomy. In Proceedings of the IEEE 53rd International Carnahan Conference on Security Technology, Chennai, India, 1–3 October 2019. [Google Scholar]
- Chundi, J.; Rao, V.G. Role of feature reduction in intrusion detection systems for wireless attacks. Int. J. Eng. Trends Technol. 2013, 1, 241–246. [Google Scholar]
- Kolias, C.; Kambourakis, G.; Stavrou, A.; Gritzalis, S. Intrusion Detection in 802.11 Networks: Empirical Evaluation of Threats and a Public Dataset. IEEE Commun. Surv. Tutor. 2016, 18, 184–208. [Google Scholar] [CrossRef]
- Pal, M. Random forest classifier for remote sensing classification. Int. J. Remote Sens. 2005, 26, 217–222. [Google Scholar] [CrossRef]
- Chen, T.; He, T.; Benesty, M.; Khotilovich, V.; Tang, Y.; Cho, H. Xgboost: Extreme gradient boosting. R Package Version 0.4-2. 2015. Available online: https://cran.r-project.org/web/packages/xgboost/index.html (accessed on 11 May 2021).
- Wang, B.; Fan, S.D.; Jiang, P.; Zhu, H.H.; Xiong, T.; Wei, W.; Fang, Z.L. A Novel Method with Stacking Learning of Data-Driven Soft Sensors for Mud Concentration in a Cutter Suction Dredger. Sensors 2020, 20, 6075. [Google Scholar] [CrossRef]
- Samat, A.; Li, E.; Wang, W.; Liu, S.; Lin, C.; Abuduwaili, J. Meta-XGBoost for hyperspectral image classification using extended MSER-guided morphological profiles. Remote Sens. 2020, 12, 1973. [Google Scholar] [CrossRef]
- Ullah, I.; Mahmoud, Q.H. A Deep Learning Based Framework for Cyberattack Detection in IoT Networks. IEEE Access 2021. [Google Scholar] [CrossRef]
- Mehmood, F.; Ullah, I.; Ahmad, S.; Kim, D.H. A Novel Approach towards the Design and Implementation of Virtual Network Based on Controller in Future IoT Applications. Electronics 2020, 9, 604. [Google Scholar] [CrossRef] [Green Version]
- Google. Available online: https://developer.android.com/studio (accessed on 11 May 2021).
- Nate Ebel. Available online: https://medium.com/goobar/androidthings-hello-rainbow-hat-ab218e9bbd6a (accessed on 11 May 2021).
- Raspberry Pi. Available online: https://www.raspberrypi.org/ (accessed on 11 May 2021).
- Google. Available online: https://developer.android.com/things (accessed on 11 May 2021).
- NFStream. Available online: https://www.nfstream.org/ (accessed on 11 May 2021).
- Al-Sarawi, S.; Anbar, M.; Alieyan, K.; Alzubaidi, M. Internet of Things (IoT) communication protocols. In Proceedings of the 2017 8th International conference on information technology (ICIT), Amman, Jordan, 17–18 May 2017; pp. 685–690. [Google Scholar]
- Naik, N. Choice of effective messaging protocols for IoT systems: MQTT, CoAP, AMQP and HTTP. In Proceedings of the 2017 IEEE international systems engineering symposium (ISSE), Vienna, Austria, 11–13 October 2017; pp. 1–7. [Google Scholar]
- Alavi, S.A.; Rahimian, A.; Mehran, K.; Ardestani, J.M. An IoT-based data collection platform for situational awareness-centric microgrids. In Proceedings of the 2018 IEEE Canadian Conference on Electrical & Computer Engineering (CCECE), Quebec, QC, Canada, 13–16 May 2018; pp. 1–4. [Google Scholar]
- Zhong, C.L.; Zhu, Z.; Huang, R.G. Study on the IOT architecture and gateway technology. In Proceedings of the 2015 14th International Symposium on Distributed Computing and Applications for Business Engineering and Science (DCABES), Guiyang, China, 18–24 August 2015; pp. 196–199. [Google Scholar]
- Blanco-Novoa, Ó.; Fraga-Lamas, P.; A Vilar-Montesinos, M.; Fernández-Caramés, T.M. Creating the internet of augmented things: An open-source framework to make iot devices and augmented and mixed reality systems talk to each other. Sensors 2020, 20, 3328. [Google Scholar] [CrossRef]
- Cruz-Piris, L.; Rivera, D.; Marsa-Maestre, I.; De La Hoz, E.; Velasco, J.R. Access control mechanism for IoT environments based on modelling communication procedures as resources. Sensors 2018, 18, 917. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dipsis, N.; Stathis, K. A RESTful middleware for AI controlled sensors, actuators and smart devices. J. Ambient Intell. Hum. Comput. 2019, 11, 2963–2986. [Google Scholar] [CrossRef] [Green Version]
- Noura, M.; Atiquzzaman, M.; Gaedke, M. Interoperability in internet of things: Taxonomies and open challenges. Mob. Netw. Appl. 2019, 24, 796–809. [Google Scholar] [CrossRef] [Green Version]
- Imperva. Available online: https://www.imperva.com/learn/ddos/slowloris/ (accessed on 11 May 2021).
- Stone, B.; Cohen, N. Social networks spread defiance online. New York Times, 15 June 2009; 15. [Google Scholar]
- Double Octopus. Available online: https://doubleoctopus.com/security-wiki/threats-and-tools/address-resolution-protocol-poisoning/ (accessed on 24 May 2021).
- ISEA. Available online: https://infosecawareness.in/concept/arp-spoofing/system-admin (accessed on 24 May 2021).
- Cloudflare. Available online: https://www.cloudflare.com/learning/ddos/udp-flood-ddos-attack/ (accessed on 24 May 2021).
- Bat_09. Available online: https://bat0san.medium.com/tryhackme-hydra-walkthrough-2202a6806b74 (accessed on 24 May 2021).
- Network Security. Available online: https://www.networxsecurity.org/members-area/glossary/a/asterisk.html (accessed on 24 May 2021).
- Mirsky, Y.; Doitshman, T.; Elovici, Y.; Shabtai, A. Kitsune: An ensemble of autoencoders for online network intrusion detection. arXiv 2018, arXiv:1802.09089. [Google Scholar]
- Lemaître, G.; Nogueira, F.; Aridas, C.K. Imbalanced-learn: A python toolbox to tackle the curse of imbalanced datasets in machine learning. J. Mach. Learn. Res. 2017, 18, 559–563. [Google Scholar]













| Approach | Dataset | Dimension Reduction | Anomaly/Multiclass | Lightweight | IDS | IoT IDS |
|---|---|---|---|---|---|---|
| LASSO [94] | AWID [95] | Yes | N/A | Yes | Yes | No |
| Auto-encoder [86] | Image-based datasets | Yes | Multiclass | No | No | No |
| Auto-encoder [87] | Image-based datasets | Yes | Multiclass | No | No | No |
| Auto-encoder [88] | N/A | Yes | Anomaly | No | No | No |
| JG NSGA-II, CNN+LSTM [89] | CISIDS2017 [85] | Yes | Anomaly | No | Yes | Yes |
| GRU, Text-CNN [90] | KDD99 [17] and the ADFA-LD [91] | No | Both | Yes | Yes | Yes |
| Hybrid, LSTM [92] | CICDDoS2019 [93] | No | Anomaly | No | Yes | No |
| Our proposed work | CCD-INID-V1, Balot [48], DoH20 [49] | Yes | Both | Yes | Yes | Yes |
| Features | Data Type | Description |
|---|---|---|
| id | data | Flow identifier |
| expiration_id | data | Identifier of flow expiration trigger. Can be 0 for idle_timeout, 1 for active_timeout or −1 for custom expiration. |
| Src_ip | str | Source IP address string representation. |
| Src_mac | str | Source MAC address string representation. |
| Src_oui | str | Source Organizationally Unique Identifier string representation. |
| Src_port | int | Transport layer source port. |
| Dst_ip | str | Destination IP address string representation. |
| Dst_mac | str | Destination MAC address string representation. |
| Dst_oui | str | Destination Organizationally Unique Identifier string representation. |
| Dst_port | int | Transport layer destination port. |
| Protocol | int | Transport layer protocol. |
| Ip_version | int | IP version. |
| Vlan_id | int | Virtual LAN identifier. |
| Bidirectional_first_seen_ms | int | Timestamp in milliseconds on first flow bidirectional packet. |
| Bidirectional_last_seen_ms | int | Timestamp in milliseconds on last flow bidirectional packet. |
| Bidirectional_duration_ms | int | Flow bidirectional duration in milliseconds. |
| Bidirectional_packets | int | Flow bidirectional packets accumulator. |
| Bidirectional_bytes | int | Flow bidirectional bytes accumulator (depends on accounting_mode). |
| Src2dst_first_seen_ms | int | Timestamp in milliseconds on first flow src2dst packet. |
| Src2dst_last_seen_ms | int | Timestamp in milliseconds on last flow src2dst packet. |
| Src2dst_duration_ms | int | Flow src2dst duration in milliseconds. |
| Src2dst_packets | int | Flow src2dst packets accumulator. |
| Src2dst_bytes | int | Flow src2dst bytes accumulator (depends on accounting_mode). |
| Dst2src_first_seen_ms | int | Timestamp in milliseconds on first flow dst2src packet. |
| Dst2src_last_seen_ms | int | Timestamp in milliseconds on last flow dst2src packet. |
| Dst2src_duration_ms | int | Flow dst2src duration in milliseconds. |
| Dst2src_packets | int | Flow dst2src packets accumulator. |
| Dst2src_bytes | int | Flow dst2src bytes accumulator (depends on accounting_mode). |
| Application_name | str | nDPI detected application name. |
| application_category_name | str | nDPI detected application category name. |
| application_is_guessed | int | Indicates if detection result is based on pure dissection or on a port-based guess. |
| Requested_server_name | str | Requested server name (SSL/TLS, DNS, HTTP) |
| client_fingerprint | str | Client fingerprint (DHCP fingerprint for DHCP, JA3 for SSL/TLS and HASSH for SSH). |
| Server_fingerprint | str | Extracted user agent for HTTP or User Agent Identifier for QUIC |
| content_type | str | Extracted HTTP content type |
| bidirectional_min_ps | int | Flow bidirectional minimum packet size (depends on accounting_mode). |
| Bidirectional_mean_ps | float | Flow bidirectional mean packet size (depends on accounting_mode). |
| Bidirectional_stdev_ps | float | Flow bidirectional packet size sample standard deviation (depends on accounting_mode). |
| Bidirectional_max_ps | int | Flow bidirectional maximum packet size (depends on accounting_mode). |
| Src2dst_min_ps | int | Flow src2dst minimum packet size (depends on accounting_mode). |
| Src2dst_mean_ps | float | Flow src2dst mean packet size (depends on accounting_mode). |
| Src2dst_stdev_ps | float | Flow src2dst packet size sample standard deviation (depends on accounting_mode). |
| Src2dst_max_ps | int | Flow src2dst maximum packet size (depends on accounting_mode). |
| Dst2src_min_ps | int | Flow dst2src minimum packet size (depends on accounting_mode). |
| Dst2src_mean_ps | float | Flow dst2src mean packet size (depends on accounting_mode). |
| Dst2src_stdev_ps | float | Flow dst2src packet size sample standard deviation (depends on accounting_mode). |
| Dst2src_max_ps | int | Flow dst2src maximum packet size (depends on accounting_mode). |
| Bidirectional_min_piat_ms | int | Flow bidirectional minimum packet inter arrival time. |
| Bidirectional_mean_piat_ms | float | Flow bidirectional mean packet inter arrival time. |
| Bidirectional_stdev_piat_ms | float | Flow bidirectional packet inter arrival time sample standard deviation. |
| Bidirectional_max_piat_ms | int | Flow bidirectional maximum packet inter arrival time. |
| Src2dst_min_piat_ms | int | Flow src2dst minimum packet inter arrival time. |
| Src2dst_mean_piat_ms | float | Flow src2dst mean packet inter arrival time. |
| Src2dst_stdev_piat_ms | float | Flow src2dst packet inter arrival time sample standard deviation. |
| Src2dst_max_piat_ms | int | Flow src2dst maximum packet inter arrival time. |
| Dst2src_min_piat_ms | int | Flow dst2src minimum packet inter arrival time. |
| Dst2src_mean_piat_ms | float | Flow dst2src mean packet inter arrival time. |
| Dst2src_stdev_piat_ms | float | Flow dst2src packet inter arrival time sample standard deviation. |
| Dst2src_max_piat_ms | int | Flow dst2src maximum packet inter arrival time. |
| Bidirectional_syn_packets | int | Flow bidirectional syn packet accumulators. |
| Bidirectional_cwr_packets | int | Flow bidirectional cwr packet accumulators. |
| Bidirectional_ece_packets | int | Flow bidirectional ece packet accumulators. |
| Bidirectional_urg_packets | int | Flow bidirectional urg packet accumulators. |
| Bidirectional_ack_packets | int | Flow bidirectional ack packet accumulators. |
| Bidirectional_psh_packets | int | Flow bidirectional psh packet accumulators. |
| Bidirectional_rst_packets | int | Flow bidirectional rst packet accumulators. |
| Bidirectional_fin_packets | int | Flow bidirectional fin packet accumulators. |
| Src2dst_syn_packets | int | Flow src2dst syn packet accumulators. |
| Src2dst_cwr_packets | int | Flow src2dst cwr packet accumulators. |
| Src2dst_ece_packets | int | Flow src2dst ece packet accumulators. |
| Src2dst_urg_packets | int | Flow src2dst urg packet accumulators. |
| Src2dst_ack_packets | int | Flow src2dst ack packet accumulators. |
| Src2dst_psh_packets | int | Flow src2dst psh packet accumulators. |
| Src2dst_rst_packets | int | Flow src2dst rst packet accumulators. |
| Src2dst_fin_packets | int | Flow src2dst fin packet accumulators. |
| Dst2src_syn_packets | int | Flow dst2src syn packet accumulators. |
| Dst2src_cwr_packets | int | Flow dst2src cwr packet accumulators. |
| Dst2src_ece_packets | int | Flow dst2src ece packet accumulators. |
| Dst2src_urg_packets | int | Flow dst2src urg packet accumulators. |
| Dst2src_ack_packets | int | Flow dst2src ack packet accumulators. |
| Dst2src_psh_packets | int | Flow dst2src psh packet accumulators. |
| Dst2src_rst_packets | int | Flow dst2src rst packet accumulators. |
| Dst2src_fin_packets | int | Flow dst2src fin packet accumulators. |
| Features | Data Type | Description |
|---|---|---|
| H | Stream aggregation | Stats summarizing the recent traffic from this packet’s host (IP) |
| HH | Stream aggregation | Stats summarizing the recent traffic going from this packet’s host (IP) to the packet’s destination host. |
| HpHp | Stream aggregation | Stats summarizing the recent traffic going from this packet’s host+port (IP) to the packet’s destination host+port. Example 192.168.4.2:1242 → 192.168.4.12:80 |
| HH_jit | Stream aggregation | Stats summarizing the jitter of the traffic going from this packet’s host (IP) to the packet’s destination host. |
| L5, L3, L1, … | Time-frame | The decay factor Lambda used in the damped window |
| Weight | Statistics | The weight of the stream (can be viewed as the number of items observed in recent history) |
| Mean | Statistics | The weight of the stream (can be viewed as the number of items observed in recent history) |
| Std | Statistics | The weight of the stream (can be viewed as the number of items observed in recent history) |
| Radius | Statistics | The root squared sum of the two streams’ variances |
| Magnitude | Statistics | The root squared sum of the two streams’ means |
| Cov | Statistics | an approximated covariance between two streams |
| pcc | Statistics | an approximated covariance between two streams |
| Features | Data Type | Description |
|---|---|---|
| SourceIP | str | IP of source |
| DestinationIP | str | IP of destination |
| SourcePort | str | Source port number |
| DestinationPort | str | Port number of destination |
| TimeStamp | str | Systime |
| Duration | str | Duration of packet in transit |
| FlowBytesSent | str | Number of flow bytes sent |
| FlowSentRate | float64 | Rate of flow bytes sent |
| FlowBytesReceived | float64 | Number of flow bytes received |
| FlowReceivedRate | float64 | Rate of flow bytes received |
| PacketLengthVariance | float64 | Variance of packet length |
| PacketLengthStandardDeviation | float64 | Standard deviation of packet length |
| PacketLengthMean | float64 | Mean packet length |
| PacketLengthMedian | float64 | Median packet length |
| PacketLengthMode | float64 | Mode packet length |
| PacketLengthSkewFromMedian | float64 | Skew from median packet length |
| PacketLengthSkewFromMode | float64 | Skew from mode packet length |
| PacketLengthCoefficientofVariation | float64 | Coefficient of variation of packet length |
| PacketTimeVariance | float64 | Variance of packet time |
| PacketTimeStandardDeviation | float64 | Standard deviation of packet time |
| PacketTimeMean | float64 | Mean packet time |
| PacketTimeMedian | float64 | Median packet time |
| PacketTimeMode | float64 | Mode packet time |
| PacketTimeSkewFromMedian | float64 | Skew from median packet time |
| PacketTimeSkewFromMode | float64 | Skew from mode packet time |
| PacketTimeCoefficientofVariation | float64 | Coefficient of variation of packet time |
| ResponseTimeTimeVariance | float64 | Variance of request/response time difference |
| ResponseTimeTimeStandardDeviation | float64 | Standard deviation of request/response time difference |
| ResponseTimeTimeMean | float64 | Mean request/response time difference |
| ResponseTimeTimeMedian | float64 | Median request/response time difference |
| ResponseTimeTimeMode | float64 | Mode request/response time difference |
| ResponseTimeTimeSkewFromMedian | float64 | Skew from median request/response time difference |
| ResponseTimeTimeSkewFromMode | float64 | Skew from mode request/response time difference |
| ResponseTimeTimeCoefficientofVariation | float64 | Coefficient of variation of request/response time difference |
| Datasets | Epochs | Training Accuracy | Training Loss | Testing Accuracy | Testing Loss |
|---|---|---|---|---|---|
| CCD-INID-V1 | 1 | 0.8883 | 1.3042 | 0.9380 | 0.9850 |
| 2 | 0.9428 | 0.9088 | 0.9500 | 0.7976 | |
| 3 | 0.9389 | 0.9761 | 0.9505 | 0.7937 | |
| 4 | 0.9376 | 0.9980 | 0.9492 | 0.8128 | |
| 5 | 0.9378 | 0.9959 | 0.9563 | 0.7005 | |
| 6 | 0.9410 | 0.9443 | 0.9514 | 0.7790 | |
| 7 | 0.9452 | 0.8758 | 0.9484 | 0.8259 | |
| 8 | 0.9435 | 0.9046 | 0.9504 | 0.7951 | |
| 9 | 0.9446 | 0.8881 | 0.9515 | 0.7772 | |
| 10 | 0.9456 | 0.8713 | 0.9515 | 0.7773 | |
| Balot | 1 | 0.9748 | 0.0927 | 0.9981 | 0.0257 |
| 2 | 0.9980 | 0.0202 | 0.9986 | 0.0207 | |
| 3 | 0.9985 | 0.0182 | 0.9992 | 0.0114 | |
| 4 | 0.9980 | 0.0266 | 0.9986 | 0.0139 | |
| 5 | 0.9989 | 0.0153 | 0.9994 | 0.0104 | |
| 6 | 0.9989 | 0.0158 | 0.9996 | 0.0064 | |
| 7 | 0.9994 | 0.0088 | 0.9990 | 0.0149 | |
| 8 | 0.9992 | 0.0125 | 0.9990 | 0.0125 | |
| 9 | 0.9993 | 0.0102 | 0.9990 | 0.0165 | |
| 10 | 0.9994 | 0.0097 | 0.9989 | 0.0176 | |
| DoH20 | 1 | 0.8684 | 0.5958 | 0.5002 | 5.6470 |
| 2 | 0.5001 | 7.9952 | 0.5000 | 8.0151 | |
| 3 | 0.7117 | 4.5212 | 0.9818 | 0.1519 | |
| 4 | 0.9766 | 0.1375 | 0.9863 | 0.0601 | |
| 5 | 0.5709 | 6.8518 | 0.5000 | 8.0151 | |
| 6 | 0.4998 | 8.0176 | 0.5000 | 8.0151 | |
| 7 | 0.4999 | 8.0165 | 0.5000 | 8.0151 | |
| 8 | 0.5000 | 8.0158 | 0.5000 | 8.0151 | |
| 9 | 0.5002 | 8.0122 | 0.5000 | 8.0151 | |
| 10 | 0.4999 | 8.0159 | 0.5000 | 8.0151 |
| Datasets | Epochs | Training Accuracy | Training Loss | Testing Accuracy | Testing Loss |
|---|---|---|---|---|---|
| CCD-INID-V1 | 1 | 0.8883 | 1.3042 | 0.9380 | 0.9850 |
| 2 | 0.9428 | 0.9088 | 0.9500 | 0.7976 | |
| 3 | 0.9389 | 0.9761 | 0.9505 | 0.7937 | |
| 4 | 0.9376 | 0.9980 | 0.9492 | 0.8128 | |
| 5 | 0.9378 | 0.9959 | 0.9563 | 0.7005 | |
| 6 | 0.9410 | 0.9443 | 0.9514 | 0.7790 | |
| 7 | 0.9452 | 0.8758 | 0.9484 | 0.8259 | |
| 8 | 0.9435 | 0.9046 | 0.9504 | 0.7951 | |
| 9 | 0.9446 | 0.8881 | 0.9515 | 0.7772 | |
| 10 | 0.9456 | 0.8713 | 0.9515 | 0.7773 | |
| Balot | 1 | 0.9748 | 0.0927 | 0.9981 | 0.0257 |
| 2 | 0.9980 | 0.0202 | 0.9986 | 0.0207 | |
| 3 | 0.9985 | 0.0182 | 0.9992 | 0.0114 | |
| 4 | 0.9980 | 0.0266 | 0.9986 | 0.0139 | |
| 5 | 0.9989 | 0.0153 | 0.9994 | 0.0104 | |
| 6 | 0.9989 | 0.0158 | 0.9996 | 0.0064 | |
| 7 | 0.9994 | 0.0088 | 0.9990 | 0.0149 | |
| 8 | 0.9992 | 0.0125 | 0.9990 | 0.0125 | |
| 9 | 0.9993 | 0.0102 | 0.9990 | 0.0165 | |
| 10 | 0.9994 | 0.0097 | 0.9989 | 0.0176 | |
| DoH20 | 1 | 0.8684 | 0.5958 | 0.5002 | 5.6470 |
| 2 | 0.5001 | 7.9952 | 0.5000 | 8.0151 | |
| 3 | 0.7117 | 4.5212 | 0.9818 | 0.1519 | |
| 4 | 0.9766 | 0.1375 | 0.9863 | 0.0601 | |
| 5 | 0.5709 | 6.8518 | 0.5000 | 8.0151 | |
| 6 | 0.4998 | 8.0176 | 0.5000 | 8.0151 | |
| 7 | 0.4999 | 8.0165 | 0.5000 | 8.0151 | |
| 8 | 0.5000 | 8.0158 | 0.5000 | 8.0151 | |
| 9 | 0.5002 | 8.0122 | 0.5000 | 8.0151 | |
| 10 | 0.4999 | 8.0159 | 0.5000 | 8.0151 |
| Datasets | Predictions | Actual Results | Predictions | Actual Results | ||||
|---|---|---|---|---|---|---|---|---|
| CCD-INID-V1 | RCNN | Actual | XCNN | Actual | ||||
| 0 | 1 | 0 | 1 | |||||
| Predicted | 0 | 8558 | 424 | Predicted | 0 | 8977 | 5 | |
| 1 | 361 | 8621 | 1 | 29 | 8953 | |||
| Balot | RCNN | Actual | XCNN | Actual | ||||
| 0 | 1 | 0 | 1 | |||||
| Predicted | 0 | 306,212 | 0 | Predicted | 0 | 306,202 | 12 | |
| 1 | 0 | 440,287 | 1 | 10 | 440,275 | |||
| DoH20 | RCNN | Actual | XCNN | Actual | ||||
| 0 | 1 | 0 | 1 | |||||
| Predicted | 0 | 8912 | 70 | Predicted | 0 | 9985 | 16 | |
| 1 | 177 | 8805 | 1 | 8 | 9993 | |||
| Datasets | Predictions | Actual Results | Predictions | Actual Results | Predictions | Actual Results | Predictions | Actual Results | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CCD-INID-V1 | KNN | Actual | NB | Actual | LR | Actual | SVM | Actual | ||||||||
| 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | |||||||||
| Predicted | 0 | 11,088 | 0 | Predicted | 0 | 7897 | 3191 | Predicted | 0 | 7897 | 3191 | Predicted | 0 | 7897 | 3191 | |
| 1 | 0 | 11,829 | 1 | 5374 | 6455 | 1 | 5374 | 6455 | 1 | 5374 | 6455 | |||||
| Balot | KNN | Actual | NB | Actual | LR | Actual | SVM | Actual | ||||||||
| 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | |||||||||
| Predicted | 0 | 303,123 | 2313 | Predicted | 0 | 183,728 | 145,294 | Predicted | 0 | 228,758 | 76,678 | Predicted | 0 | 172,832 | 132,604 | |
| 1 | 3089 | 437,974 | 1 | 122,484 | 294,993 | 1 | 36,060 | 405,003 | 1 | 32,023 | 409,040 | |||||
| DoH20 | KNN | Actual | NB | Actual | LR | Actual | SVM | Actual | ||||||||
| 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | |||||||||
| Predicted | 0 | 4038 | 808 | Predicted | 0 | 4038 | 808 | Predicted | 0 | 3415 | 1431 | Predicted | 0 | 3225 | 1621 | |
| 1 | 319 | 62,246 | 1 | 319 | 62,246 | 1 | 523 | 62,042 | 1 | 3941 | 58,624 | |||||
| Approach | 0 | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|---|
| RCNN | 0 | 409 | 0 | 575 | 0 | 0 | 0 |
| 1 | 263 | 0 | 721 | 0 | 0 | 0 | |
| 2 | 134 | 0 | 850 | 0 | 0 | 0 | |
| 3 | 124 | 0 | 860 | 0 | 0 | 0 | |
| 4 | 171 | 0 | 813 | 0 | 0 | 0 | |
| 5 | 72 | 0 | 912 | 0 | 0 | 0 | |
| XCNN | 0 | 978 | 0 | 0 | 5 | 1 | 0 |
| 1 | 839 | 135 | 3 | 2 | 0 | 5 | |
| 2 | 956 | 0 | 19 | 2 | 6 | 1 | |
| 3 | 146 | 0 | 0 | 838 | 0 | 0 | |
| 4 | 963 | 0 | 1 | 1 | 16 | 3 | |
| 5 | 883 | 0 | 0 | 0 | 1 | 100 | |
| KNN | 0 | 2867 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 2674 | 0 | 0 | 0 | 0 | |
| 2 | 0 | 0 | 1958 | 0 | 0 | 0 | |
| 3 | 0 | 0 | 0 | 11,829 | 0 | 0 | |
| 4 | 0 | 0 | 0 | 0 | 2384 | 0 | |
| 5 | 0 | 0 | 0 | 0 | 0 | 1205 | |
| NB | 0 | 2867 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 2674 | 0 | 0 | 0 | 0 | |
| 2 | 0 | 0 | 1958 | 0 | 0 | 0 | |
| 3 | 0 | 0 | 0 | 11,829 | 0 | 0 | |
| 4 | 0 | 0 | 0 | 0 | 2384 | 0 | |
| 5 | 0 | 0 | 0 | 0 | 0 | 1205 | |
| LR | 0 | 2867 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 2674 | 0 | 0 | 0 | 0 | |
| 2 | 0 | 0 | 1958 | 0 | 0 | 0 | |
| 3 | 0 | 0 | 0 | 11,829 | 0 | 0 | |
| 4 | 0 | 0 | 0 | 0 | 2384 | 0 | |
| 5 | 0 | 0 | 0 | 0 | 0 | 1205 |
| Approach | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RCNN | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 9762 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 11,892 | 0 | 0 | 0 | 0 | |
| 2 | 0 | 0 | 0 | 0 | 0 | 0 | 5740 | 0 | 0 | 0 | 0 | |
| 3 | 0 | 0 | 0 | 0 | 0 | 0 | 5864 | 0 | 0 | 0 | 0 | |
| 4 | 0 | 0 | 0 | 0 | 0 | 0 | 18,436 | 0 | 0 | 0 | 0 | |
| 5 | 0 | 0 | 0 | 0 | 0 | 0 | 21,404 | 0 | 0 | 0 | 0 | |
| 6 | 0 | 0 | 0 | 0 | 0 | 0 | 20,460 | 0 | 0 | 0 | 0 | |
| 7 | 0 | 0 | 0 | 0 | 0 | 0 | 21,640 | 0 | 0 | 0 | 0 | |
| 8 | 0 | 0 | 0 | 0 | 0 | 0 | 24,461 | 0 | 0 | 0 | 0 | |
| 9 | 0 | 0 | 0 | 0 | 0 | 0 | 47,605 | 0 | 0 | 0 | 0 | |
| 10 | 0 | 0 | 0 | 0 | 0 | 0 | 20,439 | 0 | 0 | 0 | 0 | |
| XCNN | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 9762 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 11,892 | 0 | |
| 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 5740 | 0 | |
| 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 5864 | 0 | |
| 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 18,436 | 0 | |
| 5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 21,404 | 0 | |
| 6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 20,460 | 0 | |
| 7 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 21,640 | 0 | |
| 8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 24,461 | 0 | |
| 9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 47,605 | 0 | |
| 10 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 20,439 | 0 | |
| KNN | 0 | 15,071 | 40 | 13 | 2 | 0 | 0 | 0 | 0 | 1 | 1 | 6 |
| 1 | 34 | 7113 | 2 | 5 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | |
| 2 | 15 | 6 | 7419 | 0 | 0 | 0 | 2 | 1 | 0 | 1 | 64 | |
| 3 | 15 | 8 | 5 | 22,916 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | |
| 4 | 6 | 4 | 1 | 1 | 26,342 | 0 | 0 | 0 | 0 | 0 | 1 | |
| 5 | 1 | 0 | 0 | 0 | 0 | 4644 | 1 | 222 | 2350 | 11,663 | 10 | |
| 6 | 0 | 0 | 18 | 0 | 0 | 0 | 26,917 | 0 | 0 | 0 | 18 | |
| 7 | 1 | 2 | 5 | 0 | 0 | 918 | 1 | 23,125 | 4508 | 1760 | 27 | |
| 8 | 1 | 0 | 12 | 0 | 0 | 3402 | 1 | 4980 | 47,988 | 3291 | 62 | |
| 9 | 0 | 0 | 0 | 0 | 0 | 13,108 | 1 | 2693 | 3285 | 6428 | 15 | |
| 10 | 3 | 5 | 58 | 0 | 0 | 13 | 0 | 8 | 39 | 12 | 12,303 | |
| NB | 0 | 15,071 | 40 | 13 | 2 | 0 | 0 | 0 | 0 | 1 | 1 | 6 |
| 1 | 34 | 7113 | 2 | 5 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | |
| 2 | 15 | 6 | 7419 | 0 | 0 | 0 | 2 | 1 | 0 | 1 | 64 | |
| 3 | 15 | 8 | 5 | 22,916 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | |
| 4 | 6 | 4 | 1 | 1 | 26,342 | 0 | 0 | 0 | 0 | 0 | 1 | |
| 5 | 1 | 0 | 0 | 0 | 0 | 4644 | 1 | 222 | 2350 | 11,663 | 10 | |
| 6 | 0 | 0 | 18 | 0 | 0 | 0 | 26,917 | 0 | 0 | 0 | 18 | |
| 7 | 1 | 2 | 5 | 0 | 0 | 918 | 1 | 23,125 | 4508 | 1760 | 27 | |
| 8 | 1 | 0 | 12 | 0 | 0 | 3402 | 1 | 4980 | 47,988 | 3291 | 62 | |
| 9 | 0 | 0 | 0 | 0 | 0 | 13,108 | 1 | 2693 | 3285 | 6428 | 15 | |
| 10 | 3 | 5 | 58 | 0 | 0 | 13 | 0 | 8 | 39 | 12 | 12,303 | |
| LR | 0 | 15,071 | 40 | 13 | 2 | 0 | 0 | 0 | 0 | 1 | 1 | 6 |
| 1 | 34 | 7113 | 2 | 5 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | |
| 2 | 15 | 6 | 7419 | 0 | 0 | 0 | 2 | 1 | 0 | 1 | 64 | |
| 3 | 15 | 8 | 5 | 22,916 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | |
| 4 | 6 | 4 | 1 | 1 | 26,342 | 0 | 0 | 0 | 0 | 0 | 1 | |
| 5 | 1 | 0 | 0 | 0 | 0 | 4644 | 1 | 222 | 2350 | 11,663 | 10 | |
| 6 | 0 | 0 | 18 | 0 | 0 | 0 | 26,917 | 0 | 0 | 0 | 18 | |
| 7 | 1 | 2 | 5 | 0 | 0 | 918 | 1 | 23,125 | 4508 | 1760 | 27 | |
| 8 | 1 | 0 | 12 | 0 | 0 | 3402 | 1 | 4980 | 47,988 | 3291 | 62 | |
| 9 | 0 | 0 | 0 | 0 | 0 | 13,108 | 1 | 2693 | 3285 | 6428 | 15 | |
| 10 | 3 | 5 | 58 | 0 | 0 | 13 | 0 | 8 | 39 | 12 | 12,303 |
| Approach | 0 | 1 | 2 | 3 | |
|---|---|---|---|---|---|
| RCNN | 0 | 0 | 3942 | 0 | 0 |
| 1 | 0 | 33,542 | 0 | 0 | |
| 2 | 0 | 7229 | 0 | 0 | |
| 3 | 0 | 9243 | 0 | 0 | |
| XCNN | 0 | 801 | 2325 | 567 | 249 |
| 1 | 72 | 31,865 | 992 | 613 | |
| 2 | 70 | 3161 | 2317 | 1681 | |
| 3 | 70 | 3941 | 1373 | 3859 | |
| KNN | 0 | 4366 | 334 | 75 | 93 |
| 1 | 130 | 40,769 | 423 | 594 | |
| 2 | 32 | 182 | 8643 | 135 | |
| 3 | 14 | 249 | 253 | 11,152 | |
| NB | 0 | 4366 | 334 | 75 | 93 |
| 1 | 130 | 40,769 | 423 | 594 | |
| 2 | 32 | 182 | 8643 | 135 | |
| 3 | 14 | 249 | 253 | 11,152 | |
| LR | 0 | 4366 | 334 | 75 | 93 |
| 1 | 130 | 40,769 | 423 | 594 | |
| 2 | 32 | 182 | 8643 | 135 | |
| 3 | 14 | 249 | 253 | 11,152 |
| Dataset/Approach | Precision | Recall | F1-Score | Train Time | Predict Time | Total Runtime | |
|---|---|---|---|---|---|---|---|
| CCD-INID-V1/RCNN | 0 | 0.96 | 0.95 | 0.96 | 28.96 s | 3.32 s | 32.28 s |
| 1 | 0.95 | 0.96 | 0.96 | ||||
| CCD-INID-V1/XCNN | 0 | 0.99 | 0.99 | 0.99 | 42.32 s | 9.07 s | 51.39 s |
| 1 | 0.99 | 0.99 | 0.99 | ||||
| CCD-INID-V1/KNN | 0 | 1.00 | 1.00 | 1.00 | 26.1 ms | 7 min 53 s | 7 min 53 s |
| 1 | 1.00 | 1.00 | 1.00 | ||||
| CCD-INID-V1/LR | 0 | 0.60 | 0.71 | 0.65 | 8.57 s | 350 ms | 8.92 s |
| 1 | 0.67 | 0.55 | 0.60 | ||||
| CCD-INID-V1/NB | 0 | 0.60 | 0.71 | 0.65 | 19.9 ms | 18.2 ms | 38.1 ms |
| 1 | 0.67 | 0.55 | 0.60 | ||||
| CCD-INID-V1/SVM | 0 | 0.60 | 0.71 | 0.65 | 22.3 s | 34.9 ms | 22.33 s |
| 1 | 0.67 | 0.55 | 0.60 | ||||
| Balot/RCNN | 0 | 1.00 | 1.00 | 1.00 | 63.23 s | 8.24 s | 71.47 s |
| 1 | 1.00 | 1.00 | 1.00 | ||||
| Balot/XCNN | 0 | 0.99 | 0.99 | 0.99 | 60.03 s | 12.10 s | 72.13 s |
| 1 | 0.99 | 0.99 | 0.99 | ||||
| Balot/KNN | 0 | 0.99 | 0.99 | 0.99 | 5 min 21 s | 165 min 41 s | 171 min 2 s |
| 1 | 0.99 | 0.99 | 0.99 | ||||
| Balot/LR | 0 | 0.86 | 0.75 | 0.80 | 19 min 3 s | 2 min 14 s | 21 min 17 s |
| 1 | 0.84 | 0.92 | 0.88 | ||||
| Balot/NB | 0 | 0.60 | 0.71 | 0.65 | 4 min 32 s | 5 min 21 s | 9 min 53 s |
| 1 | 0.67 | 0.55 | 0.60 | ||||
| Balot/SVM | 0 | 0.84 | 0.57 | 0.68 | 25 min 6 s | 3 min 17 s | 28 min 23 s |
| 1 | 0.76 | 0.93 | 0.83 | ||||
| DoH20/RCNN | 0 | 0.98 | 0.99 | 0.99 | 24 s | 11.45 s | 35.45 s |
| 1 | 0.99 | 0.98 | 0.99 | ||||
| DoH20/XCNN | 0 | 1.00 | 1.00 | 1.00 | 67.45 s | 5.46 s | 72.91 s |
| 1 | 1.00 | 1.00 | 1.00 | ||||
| DoH20/KNN | 0 | 0.93 | 0.83 | 0.88 | 19 ms | 79 min 46 s | 79 min 46 s |
| 1 | 0.99 | 0.99 | 0.99 | ||||
| DoH20/LR | 0 | 0.87 | 0.70 | 0.78 | 16 min 44 s | 226 ms | 166 min 46 s |
| 1 | 0.98 | 0.99 | 0.98 | ||||
| DoH20/NB | 0 | 0.93 | 0.83 | 0.88 | 109 ms | 23.6 ms | 132.6 ms |
| 1 | 0.99 | 0.99 | 0.99 | ||||
| DoH20/SVM | 0 | 0.45 | 0.67 | 0.54 | 50.2 s | 36.3 ms | 50.24 s |
| 1 | 0.97 | 0.94 | 0.95 |
| Dataset/Approach | Precision | Recall | F1-Score | Train Time | Predict Time | Total Runtime | |
|---|---|---|---|---|---|---|---|
| CCD-INID-V1/RCNN | 0 | 0.35 | 0.42 | 0.38 | 18.24 s | 4.18 s | 22.42 s |
| 1 | 0 | 0 | 0 | ||||
| 2 | 0.18 | 0.86 | 0.30 | ||||
| 3 | 0 | 0 | 0 | ||||
| 4 | 0 | 0 | 0 | ||||
| 5 | 0 | 0 | 0 | ||||
| CCD-INID-V1/XCNN | 0 | 0.21 | 0.99 | 0.34 | 16.31 | 9.66 s | 25.97 s |
| 1 | 1.00 | 0.14 | 0.24 | ||||
| 2 | 0.83 | 0.02 | 0.04 | ||||
| 3 | 0.99 | 0.85 | 0.91 | ||||
| 4 | 0.67 | 0.02 | 0.03 | ||||
| 5 | 0.92 | 0.10 | 0.18 | ||||
| CCD-INID-V1/KNN | 0 | 1.00 | 1.00 | 1.00 | 5 min 41 s | 5 min 29 s | 10 min 70 s |
| 1 | 1.00 | 1.00 | 1.00 | ||||
| 2 | 1.00 | 1.00 | 1.00 | ||||
| 3 | 1.00 | 1.00 | 1.00 | ||||
| 4 | 1.00 | 1.00 | 1.00 | ||||
| 5 | 1.00 | 1.00 | 1.00 | ||||
| CCD-INID-V1/LR | 0 | 1.00 | 1.00 | 1.00 | 20 ms | 1 min 6 s | 1 min 6 s |
| 1 | 1.00 | 1.00 | 1.00 | ||||
| 2 | 1.00 | 1.00 | 1.00 | ||||
| 3 | 1.00 | 1.00 | 1.00 | ||||
| 4 | 1.00 | 1.00 | 1.00 | ||||
| 5 | 1.00 | 1.00 | 1.00 | ||||
| CCD-INID-V1/NB | 0 | 1.00 | 1.00 | 1.00 | 45.1 ms | 43 ms | 88.1 ms |
| 1 | 1.00 | 1.00 | 1.00 | ||||
| 2 | 1.00 | 1.00 | 1.00 | ||||
| 3 | 1.00 | 1.00 | 1.00 | ||||
| 4 | 1.00 | 1.00 | 1.00 | ||||
| 5 | 1.00 | 1.00 | 1.00 | ||||
| Balot/RCNN | 0 | 0.00 | 0.00 | 0.00 | 297.10 s | 70.11 s | 367.21 s |
| 1 | 0.00 | 0.00 | 0.00 | ||||
| 2 | 0.00 | 0.00 | 0.00 | ||||
| 3 | 0.00 | 0.00 | 0.00 | ||||
| 4 | 0.00 | 0.00 | 0.00 | ||||
| 5 | 0.10 | 1.00 | 0.19 | ||||
| 6 | 0.00 | 0.00 | 0.00 | ||||
| 7 | 0.00 | 0.00 | 0.00 | ||||
| 8 | 0.00 | 0.00 | 0.00 | ||||
| 9 | 0.00 | 0.00 | 0.00 | ||||
| 10 | 0.00 | 0.00 | 0.00 | ||||
| Balot/XCNN | 0 | 0.00 | 0.00 | 0.00 | 250.01 s | 113.86 s | 363.87 s |
| 1 | 0.00 | 0.00 | 0.00 | ||||
| 2 | 0.00 | 0.00 | 0.00 | ||||
| 3 | 0.00 | 0.00 | 0.00 | ||||
| 4 | 0.00 | 0.00 | 0.00 | ||||
| 5 | 0.00 | 0.00 | 0.00 | ||||
| 6 | 0.00 | 0.00 | 0.00 | ||||
| 7 | 0.00 | 0.00 | 0.00 | ||||
| 8 | 0.00 | 0.00 | 0.00 | ||||
| 9 | 0.23 | 1.00 | 0.37 | ||||
| 10 | 0.00 | 0.00 | 0.00 | ||||
| Balot/KNN | 0 | 0.99 | 1.00 | 1.00 | 531 min 31 s | 539 min 28 s | 1080 min 59 s |
| 1 | 0.99 | 0.99 | 0.99 | ||||
| 2 | 0.98 | 0.99 | 0.99 | ||||
| 3 | 1.00 | 1.00 | 1.00 | ||||
| 4 | 1.00 | 1.00 | 1.00 | ||||
| 5 | 0.21 | 0.25 | 0.23 | ||||
| 6 | 1.00 | 1.00 | 1.00 | ||||
| 7 | 0.75 | 0.76 | 0.75 | ||||
| 8 | 0.82 | 0.80 | 0.81 | ||||
| 9 | 0.28 | 0.25 | 0.26 | ||||
| 10 | 0.98 | 0.99 | 0.99 | ||||
| Balot/LR | 0 | 0.99 | 1.00 | 1.00 | 22 s | 2 min 10 s | 2 min 32 s |
| 1 | 0.99 | 0.99 | 0.99 | ||||
| 2 | 0.98 | 0.99 | 0.99 | ||||
| 3 | 1.00 | 1.00 | 1.00 | ||||
| 4 | 1.00 | 1.00 | 1.00 | ||||
| 5 | 0.21 | 0.25 | 0.23 | ||||
| 6 | 1.00 | 1.00 | 1.00 | ||||
| 7 | 0.75 | 0.76 | 0.75 | ||||
| 8 | 0.82 | 0.80 | 0.81 | ||||
| 9 | 0.28 | 0.25 | 0.26 | ||||
| 10 | 0.98 | 0.99 | 0.99 | ||||
| Balot/NB | 0 | 0.99 | 1.00 | 1.00 | 1.42 s | 1.43 s | 2.85 s |
| 1 | 0.99 | 0.99 | 0.99 | ||||
| 2 | 0.98 | 0.99 | 0.99 | ||||
| 3 | 1.00 | 1.00 | 1.00 | ||||
| 4 | 1.00 | 1.00 | 1.00 | ||||
| 5 | 0.21 | 0.25 | 0.23 | ||||
| 6 | 1.00 | 1.00 | 1.00 | ||||
| 7 | 0.75 | 0.76 | 0.75 | ||||
| 8 | 0.82 | 0.80 | 0.81 | ||||
| 9 | 0.28 | 0.25 | 0.26 | ||||
| 10 | 0.98 | 0.99 | 0.99 | ||||
| DoH20/RCNN | 0 | 0.00 | 0.00 | 0.00 | 42.37 s | 8.52 s | 50.89 s |
| 1 | 0.62 | 1.00 | 0.77 | ||||
| 2 | 0.00 | 0.00 | 0.00 | ||||
| 3 | 0.00 | 0.00 | 0.00 | ||||
| DoH20/XCNN | 0 | 0.79 | 0.20 | 0.32 | 42.21 s | 8.48 s | 50.69 s |
| 1 | 0.77 | 0.95 | 0.85 | ||||
| 2 | 0.44 | 0.32 | 0.37 | ||||
| 3 | 0.60 | 0.42 | 0.49 | ||||
| DoH20/KNN | 0 | 0.96 | 0.89 | 0.93 | 79 min 45 s | 80 min 30 s | 160 min 15 s |
| 1 | 0.98 | 0.97 | 0.98 | ||||
| 2 | 0.92 | 0.96 | 0.94 | ||||
| 3 | 0.93 | 0.96 | 0.94 | ||||
| DoH20/LR | 0 | 0.96 | 0.90 | 0.93 | 28 s | 72 min 25 s | 72 min 53 s |
| 1 | 0.98 | 0.97 | 0.98 | ||||
| 2 | 0.92 | 0.96 | 0.94 | ||||
| 3 | 0.93 | 0.96 | 0.94 | ||||
| DoH20/NB | 0 | 0.96 | 0.90 | 0.93 | 27 ms | 57.8 ms | 84.8 ms |
| 1 | 0.98 | 0.97 | 0.98 | ||||
| 2 | 0.92 | 0.96 | 0.94 | ||||
| 3 | 0.93 | 0.96 | 0.94 |
| Dataset | RCNN | XCNN | KNN | Epochs |
|---|---|---|---|---|
| CCD-INID-V1 | 32.28 s | 51.38 s | 7 min 53 s | 10 |
| Balot | 71.46 s | 72.12 s | 171 min 2 s | 10 |
| DoH20 | 35.45 s | 72.91 s | 79 min 46 s | 10 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Z.; Thapa, N.; Shaver, A.; Roy, K.; Siddula, M.; Yuan, X.; Yu, A. Using Embedded Feature Selection and CNN for Classification on CCD-INID-V1—A New IoT Dataset. Sensors 2021, 21, 4834. https://doi.org/10.3390/s21144834
Liu Z, Thapa N, Shaver A, Roy K, Siddula M, Yuan X, Yu A. Using Embedded Feature Selection and CNN for Classification on CCD-INID-V1—A New IoT Dataset. Sensors. 2021; 21(14):4834. https://doi.org/10.3390/s21144834
Chicago/Turabian StyleLiu, Zhipeng, Niraj Thapa, Addison Shaver, Kaushik Roy, Madhuri Siddula, Xiaohong Yuan, and Anna Yu. 2021. "Using Embedded Feature Selection and CNN for Classification on CCD-INID-V1—A New IoT Dataset" Sensors 21, no. 14: 4834. https://doi.org/10.3390/s21144834
APA StyleLiu, Z., Thapa, N., Shaver, A., Roy, K., Siddula, M., Yuan, X., & Yu, A. (2021). Using Embedded Feature Selection and CNN for Classification on CCD-INID-V1—A New IoT Dataset. Sensors, 21(14), 4834. https://doi.org/10.3390/s21144834