
Data-Driven Dispatching Rules Mining and Real-Time Decision-Making Methodology in Intelligent Manufacturing Shop Floor with Uncertainty



Abstract
:1. Introduction
- (1)
- This paper proposes an improved IGEP approach to extract the appropriate scheduling knowledge.
- (2)
- An efficient real-time decision-making approach is proposed to respond the disturbance timely.
- (3)
- The appropriate dispatching rules is discovered from the historical production data.
2. Literature Review
3. Motivations
4. Intelligent Job Shop Scheduling Problem Statement
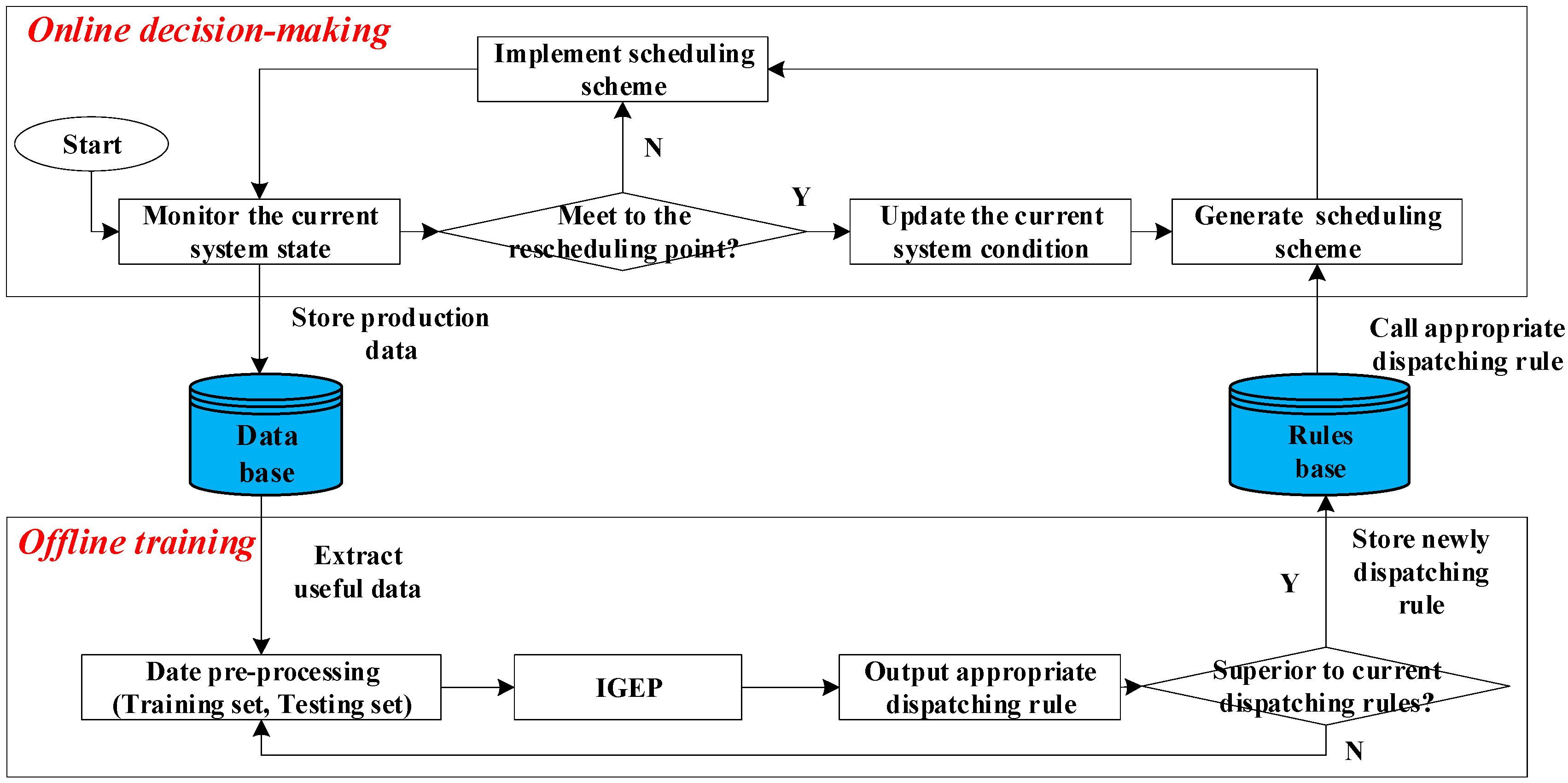
5. Data-Driven Dispatching Rule Mining and Decision-Making Framework
6. Offline Training Method
6.1. Data Pre-Processing
6.2. The Improved Gene Expression Programming
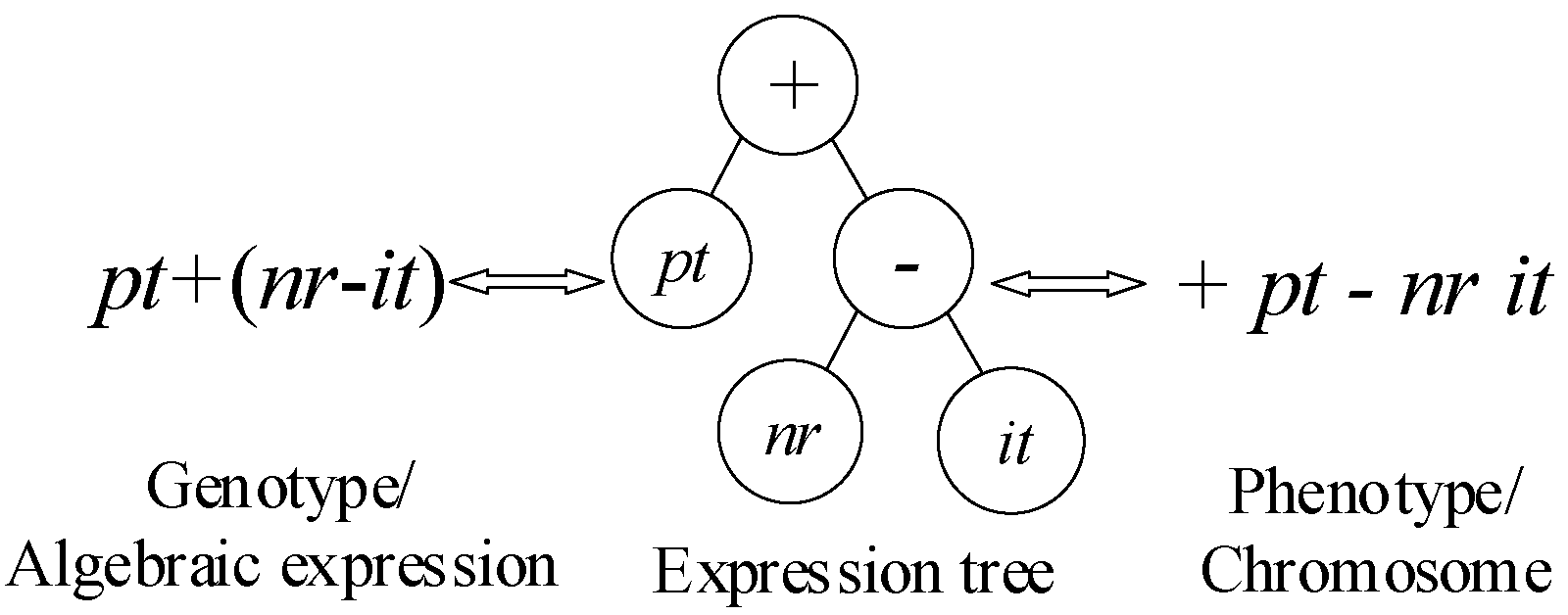
6.2.1. Chromosome Representation and Decoding
6.2.2. Feasible Scheduling Scheme from Algebraic Expression
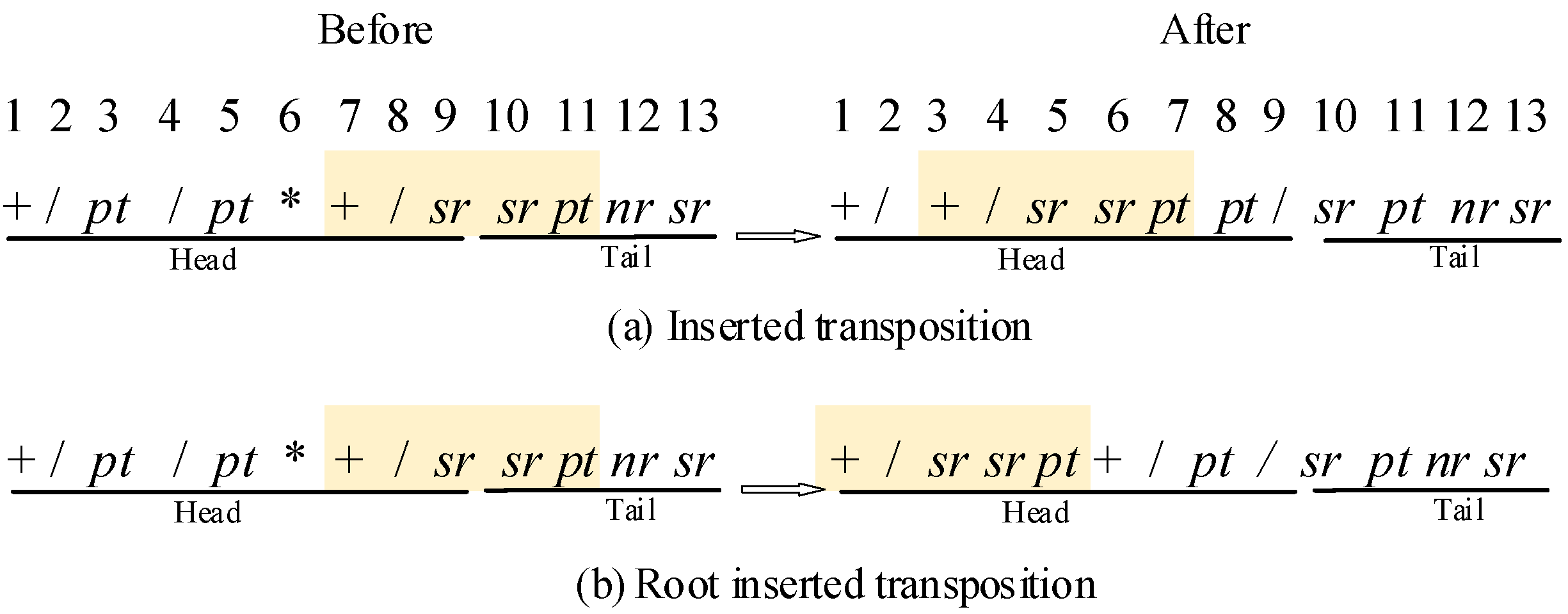
6.2.3. Four Operators of IGEP
6.2.4. Evaluation for Each Individual
| Algorithm1. Evaluation for each individual. |
| 1: for j = 1: popsize do 2: , 3: for i = 1: n do 4: calculate fij 5: if then 6: 7: end if 8: if then 9: 10: end if 11: end for 12: if then 13: 14: else 15: 16: end if 17: end for |
6.2.5. Overall Framework of the Offline Training Method
| Algorithm2. Overall framework of the IGEP-based offline training method. |
| 1: Inputs: Training instances I, 2: Set parameters, population size (popsize), maximum iteration (maxIter), probability of mutation (pm), probability of recombination (pr), probability of transposition (ptr), and the pre-set value for selection (k_s). 3: Initialize population randomly P, 4: Calculate each individuals Fj, store the best individual into Jbest 5: for iteration = 1: maxIter do 6: Apply selection to generate the new population 7: if p < pm 8: Apply recombination to generate the new population 9: end if 10: if p < pm 11: Apply mutation to generate the new population 12: end if 13: if p < pm 14: Apply transposition to generate the new population 15: end if 16: Calculate each individuals Fj, store the best individual into Jbest 17: 18: end for 19: Compare Jbest with the dispatching rule JR_base in the rules base by testing instances. 20: if Jbest is better than JR_base then 21: JR_base =Jbest 22: end if |
7. Experimental Results
7.1. Data Setting and Parameter Tuning
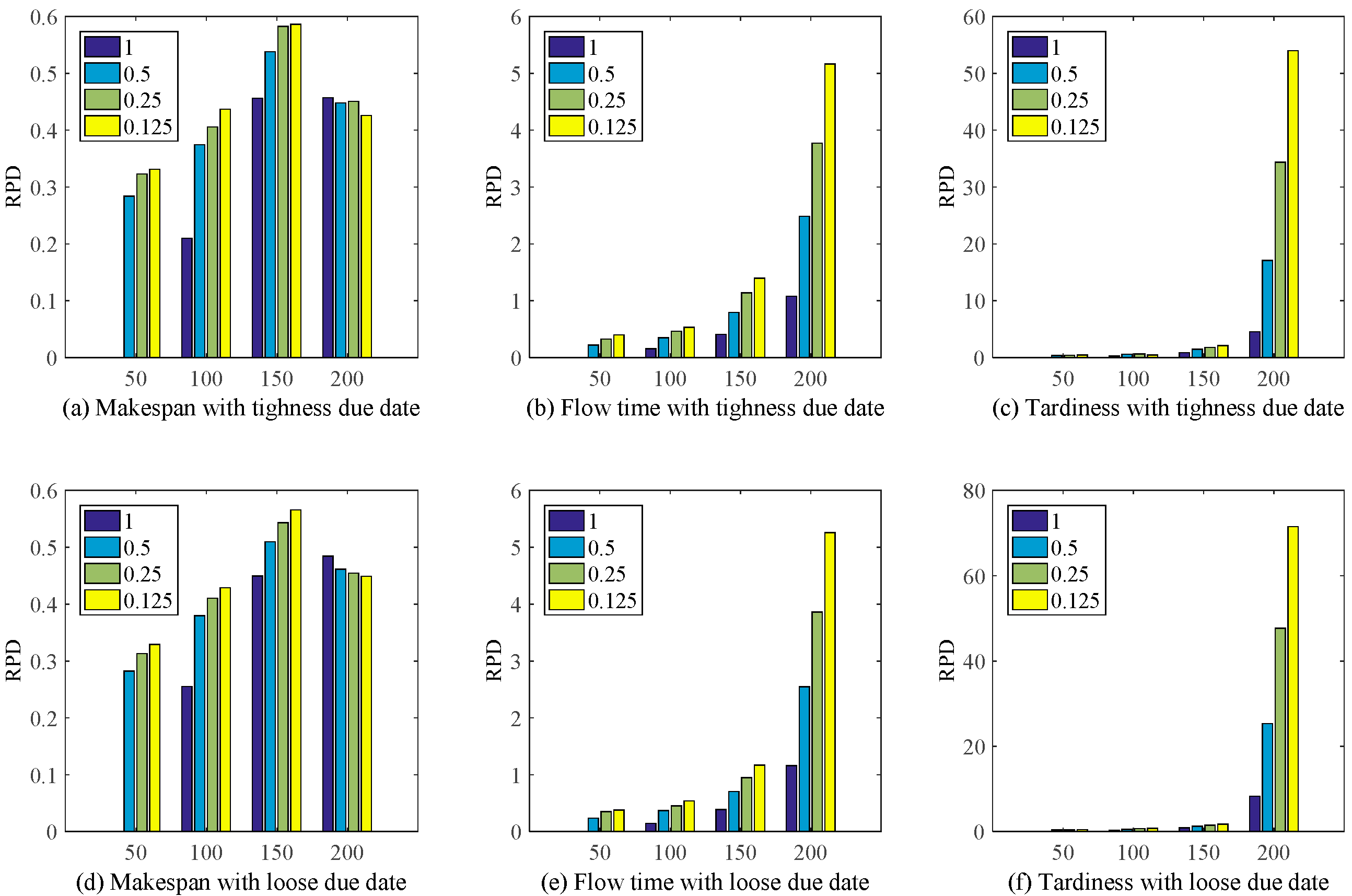
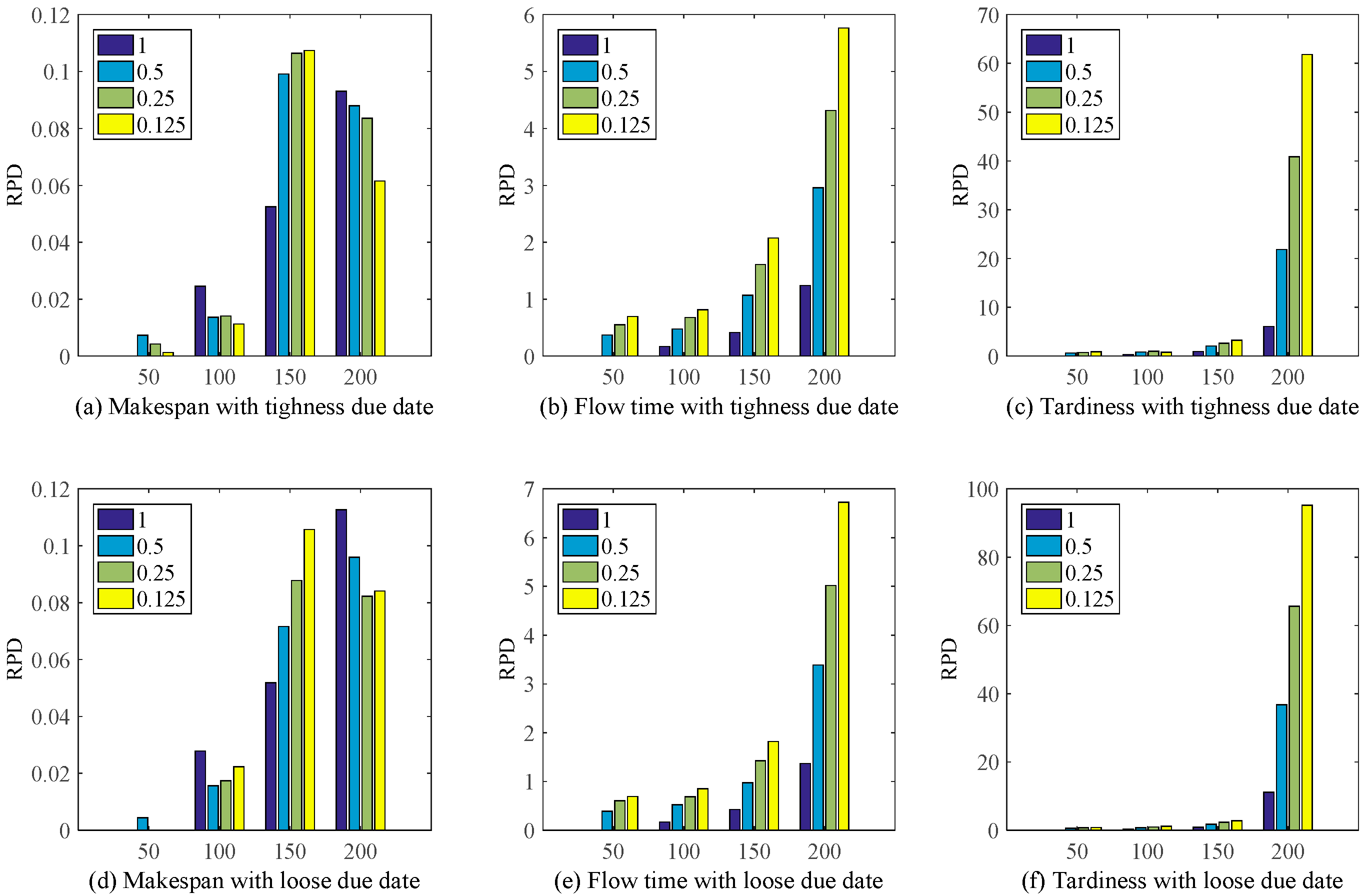
7.2. Compared with the Discovered/Combination Rules via Metaheuristic Algorithm
7.3. Compared with Other Well-Known Dispatching Rules
7.4. Sensitivity Study on the Experimental Parameters
8. Conclusions
- (1)
- The real-time decision-making ban be achieved by calling the dispatching rules at each rescheduling point. It can be quite satisfying to reach up to the requirements of the real application.
- (2)
- Due to historical production data-driven, the discovered dispatching rules at each rescheduling point have significant superiority in the current specific production scenario. These rules with low computational requirement and easy implementation in real intelligent job shop scheduling problem.
- (3)
- The IGEP algorithm owns the merits of artificial intelligence via high self-study and self- adaptability, and also has the advantage of exploring the potential and appropriate scheduling knowledge from the historical production data.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhong, R.Y.; Xu, C.; Chen, C.; Huang, G.Q. Big Data Analytics for Physical Internet-based intelligent manufacturing shop floors. Int. J. Prod. Res. 2017, 55, 2610–2621. [Google Scholar] [CrossRef]
- Ouelhadj, D.; Petrovic, S. A survey of dynamic scheduling in manufacturing systems. J. Sched. 2009, 12, 417–431. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Tang, Q.; Wu, Z.; Wang, F. Mathematical modeling and evolutionary generation of rule sets for energy-efficient flexible job shops. Energy 2017, 138, 210–227. [Google Scholar] [CrossRef]
- Zhang, R.; Song, S.; Wu, C. Robust Scheduling of Hot Rolling Production by Local Search Enhanced Ant Colony Optimization Algorithm. IEEE Trans. Ind. Inform. 2020, 16, 2809–2819. [Google Scholar] [CrossRef]
- Zhang, L.; Li, X.; Gao, L.; Zhang, G. Dynamic rescheduling in FMS that is simultaneously considering energy consumption and schedule efficiency. Int. J. Adv. Manuf. Technol. 2016, 87, 1387–1399. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, J.; Yang, S. An improved particle swarm optimization algorithm for dynamic job shop scheduling problems with random job arrivals. Swarm Evol. Comput. 2019, 51, 100594. [Google Scholar] [CrossRef]
- Cao, Z.; Lin, C.; Zhou, M. A Knowledge-Based Cuckoo Search Algorithm to Schedule a Flexible Job Shop with Sequencing Flexibility. IEEE Trans. Autom. Sci. Eng. 2021, 18, 56–69. [Google Scholar] [CrossRef]
- Ahmadian, M.M.; Salehipour, A.; Cheng, T.C.E. A meta-heuristic to solve the just-in-time job-shop scheduling problem. Eur. J. Oper. Res. 2021, 288, 14–29. [Google Scholar] [CrossRef]
- Precup, R.-E.; David, R.-C. Nature-Inspired Optimization Algorithms for Fuzzy Controlled Servo Systems; Butterworth-Heinemann: Oxford, UK; Elsevier: Oxford, UK, 2019. [Google Scholar]
- Haber, R.E.; Beruvides, G.; Quiza, R.; Hernandez, A. A Simple Multi-Objective Optimization Based on the Cross-Entropy Method. IEEE Access 2017, 5, 22272–22281. [Google Scholar] [CrossRef]
- Zhang, G.; Hu, Y.; Sun, J.; Zhang, W. An improved genetic algorithm for the flexible job shop scheduling problem with multiple time constraints. Swarm Evol. Comput. 2020, 54, 100664. [Google Scholar] [CrossRef]
- Zhang, G.; Sun, J.; Lu, X.; Zhang, H. An improved memetic algorithm for the flexible job shop scheduling problem with transportation times. Meas. Control. 2020, 53, 1518–1528. [Google Scholar] [CrossRef]
- Amina, G.R.; El-Bouri, A. A minimax linear programming model for dispatching rule selection. Comput. Ind. Eng. 2018, 121, 27–35. [Google Scholar] [CrossRef]
- Potts, C.N.; Strusevich, V.A. Fifty years of scheduling: A survey of milestones. J. Oper. Res. Soc. 2009, 60, S41–S68. [Google Scholar] [CrossRef] [Green Version]
- Ragazzini, L.; Negri, E.; Fumagalli, L.; Macchi, M.; Kozłowski, J. Tolerance Scheduling for CPS. In Proceedings of the 2020 IEEE Conference on Industrial Cyber Physical Systems, Tampere, Finland, 10–12 June 2020. [Google Scholar]
- Villalonga, A.; Negri, E.; Biscardo, G.; Castano, F.; Haber, R.E.; Fumagalli, L.; Macchi, M. A decision-making framework for dynamic scheduling of cyber-physical production systems based on digital twins. Annu. Rev. Control. 2021, 51, 357–373. [Google Scholar] [CrossRef]
- Zhang, J.; Ding, G.; Zou, Y.; Qin, S.; Fu, J. Review of job shop scheduling research and its new perspectives under industry 4.0. J. Intell. Manuf. 2019, 30, 1809–1830. [Google Scholar] [CrossRef]
- Panwalkar, S.S.; Iskander, W. A survey of scheduling rules. Oper. Res. 1977, 25, 45–61. [Google Scholar] [CrossRef]
- Ho, N.B.; Tay, J.C. Evolving dispatching rules for solving the flexible job-shop problem. IEEE Congr. Evol. Comput. 2005, 2, 2848–2855. [Google Scholar]
- Holthaus, O.; Rajendran, C. Efficient dispatching rules for scheduling in a job shop. Int. J. Prod. Econ. 1997, 48, 87–105. [Google Scholar] [CrossRef]
- Rajendran, C.; Holthaus, O. A comparative study of dispatching rules in dynamic flow shops and job shops. Eur. J. Oper. Res. 1999, 116, 156–170. [Google Scholar] [CrossRef]
- Durasevic, M.; Jakobovic, D. A survey of dispatching rules for the dynamic unrelated machines environment. Expert Syst. Appl. 2018, 113, 555–569. [Google Scholar] [CrossRef]
- Blackstone, J.H.; Philips, D.T.; Hogg, G.L. A state-of-the survey of dispatching rules for manufacturing job shop operations. Int. J. Prod. Res. 1982, 20, 27–45. [Google Scholar] [CrossRef]
- Dominic, P.D.D.; Kaliyamoorthy, S.; Kumar, M.S. Efficient dispatching rules for dynamic job shop scheduling. Int. J. Adv. Manuf. Technol. 2004, 24, 70–75. [Google Scholar] [CrossRef]
- Haupt, R. A survey of priority rule-based scheduling. Oper. Res. Spektrum 1989, 11, 3–16. [Google Scholar] [CrossRef]
- Korytkowski, P.; Wisniewski, T.; Rymaszewski, S. An evolutionary simulation-based optimization approach for dispatching scheduling. Simul. Model. Pract. Ther. 2013, 35, 69–85. [Google Scholar] [CrossRef]
- Bergmann, S.; Feldkamp, N.; Strassburger, S. Emulation of control strategies through machine learning in manufacturing simulations. J. Simul. 2017, 11, 38–50. [Google Scholar] [CrossRef]
- Tharwat, A.; Hassanien, A.E. Quantum-Behaved Particle Swarm Optimization for Parameter Optimization of Support Vector Machine. J. Classif. 2019, 36, 576–598. [Google Scholar] [CrossRef]
- Jakobovic, D.; Marasovic, K. Evolving priority scheduling heuristics with genetic programming. Appl. Soft Comput. 2012, 12, 2781–2789. [Google Scholar] [CrossRef]
- Nguyen, S.; Zhang, M.; Johnston, M.; Tan, K.C. A computational study of representations in genetic programming to evolve dispatching rules for the job shop scheduling problem. IEEE Trans. Evol. Comput. 2013, 17, 621–639. [Google Scholar] [CrossRef]
- Zhang, L.; Li, Z.; Krolczyk, G.; Tang, Q. Mathematical modeling and multi-attribute rule mining for energy efficient job-shop scheduling. J. Clean. Prod. 2019, 241, 118289. [Google Scholar] [CrossRef]
- Jun, S.; Lee, S. Learning dispatching rules for single machine scheduling with dynamic arrivals based on decision trees and feature construction. Int. J. Prod. Res. 2020, 11, 1–19. [Google Scholar] [CrossRef]
- Mouelhi-Chibani, W.; Pierreval, H. Training a neural network to select dispatching rules in real time. Comput. Ind. Eng. 2010, 58, 249–256. [Google Scholar] [CrossRef]
- Jens, H.; Hildebrandt, T.; Scholz-Reiter, B. Dispatching rule selection with Gaussian processes. Cent. Eur. J. Oper. Res. 2015, 23, 235–249. [Google Scholar]
- Zhang, H.; Roy, U. A semantics-based dispatching rule selection approach for job shop scheduling. J. Intell. Manuf. 2019, 30, 2759–2779. [Google Scholar] [CrossRef]
- Luo, S. Dynamic scheduling for flexible job shop with new job insertions by deep reinforcement learning. Appl. Soft Comput. 2020, 91, 1–17. [Google Scholar] [CrossRef]
- Fang, W.; Guo, Y.; Liao, W.; Ramani, K.; Huang, S. Big data driven jobs remaining time prediction in discrete manufacturing system: A deep learning based approach. Int. J. Prod. Res. 2019, 58, 2751–2766. [Google Scholar] [CrossRef]
- Raheja, A.S.; Subramaniam, V. Reactive recovery of job shop schedules—A review. Int. J. Adv. Manuf. Technol. 2002, 19, 756–763. [Google Scholar] [CrossRef]
- Georgiadis, P.; Michaloudis, C. Real-Time production planning and control system for job-shop manufacturing: A system dynamics analysis. Eur. J. Oper. Res. 2012, 216, 94–104. [Google Scholar] [CrossRef]
- Xiong, J.; Xing, L.; Chen, Y. Robust scheduling for multi-objective flexible job-shop problems with random machine breakdowns. Int. J. Prod. Res. 2013, 141, 112–126. [Google Scholar] [CrossRef]
- Zhang, L.; Gao, L.; Li, X. A hybrid genetic algorithm and tabu search for a multi-objective dynamic job shop scheduling problem. Int. J. Prod. Res. 2013, 51, 3516–3531. [Google Scholar] [CrossRef]
- Kutanoglu, E.; Sabuncuoglu, I. Routing-based reactive scheduling policies for machine failures in dynamic job shops. Int. J. Prod. Res. 2001, 39, 3141–3158. [Google Scholar] [CrossRef]
- Rangsaritratsamee, R.; Ferrell, W.G.; Kurz, J.B.M. Dynamic rescheduling that simultaneously considers efficiency and stability. Comput. Ind. Eng. 2004, 46, 1–15. [Google Scholar] [CrossRef]
- Vinod, V.; Sridharan, R. Simulation-Based metamodels for scheduling a dynamic job shop with sequence-dependent setup times. Int. J. Prod. Res. 2009, 47, 1425–1447. [Google Scholar] [CrossRef]
- Nowicki, E.; Smutnicki, C. A Fast Taboo Search Algorithm for the Job Shop Problem. Manag. Sci. 1996, 42, 797–813. [Google Scholar] [CrossRef]
- Bughin, J.; Chui, M.; Manyika, J. Clouds, big data, and smart assets: Ten tech-enabled business trends to watch. McKinsey Q. 2010, 56, 75–86. [Google Scholar]
- Tao, F.; Zhang, H.; Liu, A.; Nee, A.Y.C. Digital Twin in Industry: State-of-the-Art. IEEE Trans. Ind. Inform. 2019, 15, 2405–2415. [Google Scholar] [CrossRef]
- Tang, D.; Zheng, K.; Zhang, H.; Zhang, Z.; Sang, Z.; Zhang, T.; Espinosa-Oviedo, J.; Vargas-Solar, G. Using autonomous intelligence to build a smart shop floor. Int. J. Adv. Manuf. Technol. 2018, 94, 1597–1606. [Google Scholar] [CrossRef]
- Tao, F.; Qi, Q.; Liu, A.; Kusiak, A. Data-Driven smart manufacturing. J. Manuf. Syst. 2018, 48, 157–169. [Google Scholar] [CrossRef]
- Yang, Y.; Li, X.; Gao, L.; Shao, X. Modeling and impact factors analyzing of energy consumption in CNC face milling using GRASP gene expression programming. Int. J. Adv. Manuf. Technol. 2016, 87, 1247–1263. [Google Scholar] [CrossRef]
- Ferreira, C. Gene expression programming in problem solving. In Soft Computing and Industry; Springer: London, UK, 2002; pp. 635–653. [Google Scholar]
- Nie, L.; Gao, L.; Li, P.; Li, X. A GEP-Based reactive scheduling policies constructing approach for dynamic flexible job shop scheduling problem with job release dates. J. Intell. Manuf. 2013, 24, 763–774. [Google Scholar] [CrossRef]
- Zhong, J.; Ong, Y.S.; Cai, W. Self-Learning gene expression programming. IEEE Trans. Evol. Comput. 2016, 20, 65–80. [Google Scholar] [CrossRef]
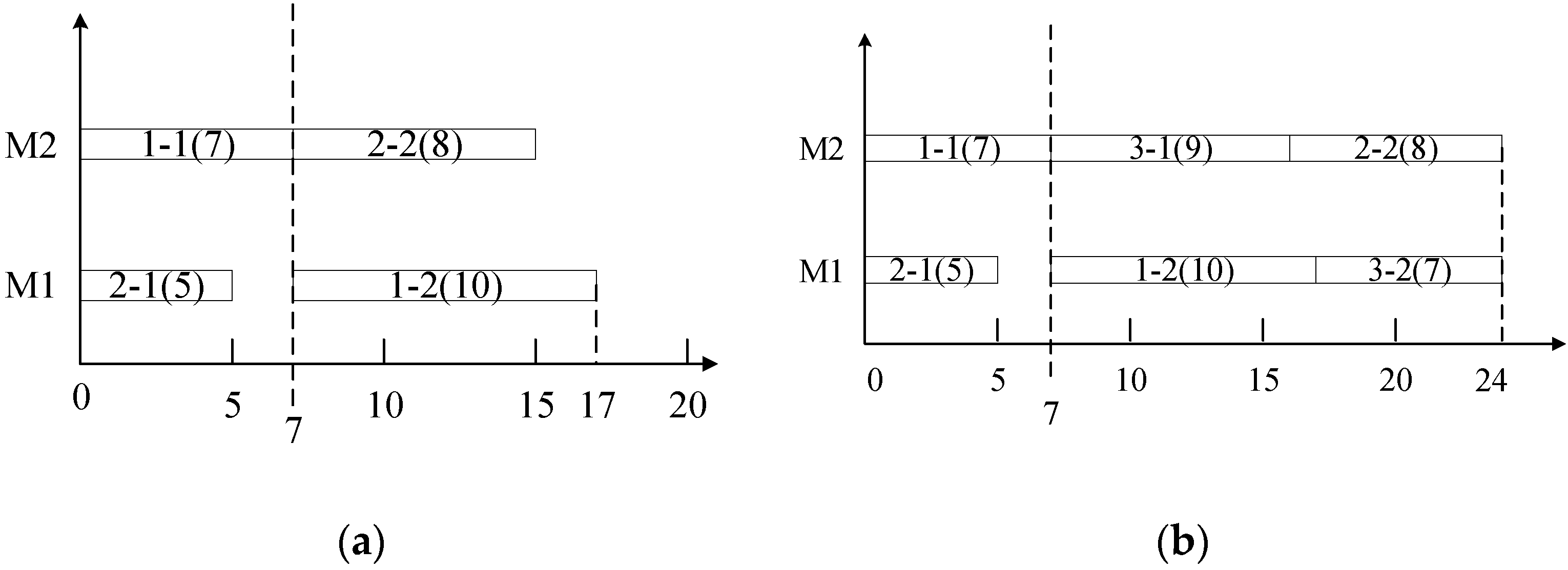





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PTWINQ | RH1 | RH2 | RH3 | GP1 | GP2 | GP3 | GEP1 | GEP2 | IGEP | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 50 | 1 | T | 1074.6 | 1074.6 | 1074.6 | 1074.6 | 1074.6 | 1074.6 | 1074.6 | 1074.6 | 1074.6 | 1074.6 |
| L | 1039.4 | 1039.4 | 1039.4 | 1039.4 | 1039.4 | 1039.4 | 1039.4 | 1039.4 | 1039.4 | 1039.4 | ||
| 0.5 | T | 991.8 | 1003.8 | 1189.5 | 612.9 | 1091.9 | 1098.5 | 1057.3 | 528.7 | 504.5 | 506.4 | |
| L | 1015 | 997 | 1261.7 | 558.4 | 1098.6 | 1125.7 | 1070.9 | 471.3 | 447.2 | 444.9 | ||
| 0.25 | T | 1029.5 | 1062 | 1314.4 | 591.2 | 1164.5 | 1207.5 | 1057.9 | 446.5 | 401.7 | 406.1 | |
| L | 1020.5 | 1047.7 | 1286.2 | 583.6 | 1174.3 | 1177.8 | 1045.4 | 436.1 | 401.4 | 402.6 | ||
| 0.125 | T | 1038.1 | 1030 | 1249.5 | 727.6 | 1190.4 | 1191.9 | 920.6 | 530.4 | 501.7 | 499.4 | |
| L | 1041.8 | 1035.5 | 1248.3 | 708.4 | 1151.4 | 1193.6 | 943.4 | 503.5 | 475 | 477.3 | ||
| 100 | 1 | T | 1888.5 | 1995.6 | 2578 | 869.5 | 2166.3 | 2230.4 | 2051.6 | 722.9 | 677.6 | 677 |
| L | 1873.9 | 1973.2 | 2516 | 848.6 | 2164.6 | 2239.6 | 2035.5 | 704.9 | 662.2 | 661.9 | ||
| 0.5 | T | 1915.5 | 1946.7 | 2450.5 | 948.1 | 2142.8 | 2231.5 | 2002.3 | 734.3 | 689.8 | 689.8 | |
| L | 2026.8 | 2070.8 | 2613.6 | 952.6 | 2272 | 2296.4 | 2018.9 | 739.5 | 690.5 | 690.5 | ||
| 0.25 | T | 1974.3 | 1980.1 | 2502.6 | 1073.7 | 2213.6 | 2280.5 | 1881.6 | 749.8 | 691.2 | 698.1 | |
| L | 1918.1 | 1993.1 | 2508.3 | 1032.4 | 2190.5 | 2269.1 | 1872 | 733.2 | 677.8 | 683.9 | ||
| 0.125 | T | 1984.3 | 1981.9 | 2368.4 | 1336.4 | 2231.7 | 2242.5 | 1673.3 | 947.9 | 924.2 | 923.2 | |
| L | 2007.7 | 1962.8 | 2388.5 | 1309.2 | 2198.7 | 2304.7 | 1662.7 | 923.5 | 903 | 895.8 | ||
| 150 | 1 | T | 2821.4 | 3024.4 | 3833.5 | 1264.4 | 3198 | 3332.1 | 3009.3 | 1015 | 956.4 | 955.5 |
| L | 2863.3 | 2991.1 | 3830.9 | 1239.5 | 3268.5 | 3387.4 | 2990.6 | 1014.8 | 944.7 | 944.2 | ||
| 0.5 | T | 2825.6 | 2937.2 | 3727.9 | 1382.6 | 3224.7 | 3347.4 | 2897.7 | 1037.7 | 981.5 | 983.4 | |
| L | 2991 | 3034.2 | 3894.1 | 1382.5 | 3357.4 | 3431.5 | 2951 | 1042 | 978.3 | 980.2 | ||
| 0.25 | T | 2856.7 | 2964.5 | 3727.4 | 1555.2 | 3273 | 3383.7 | 2674.8 | 1049.4 | 972 | 982.8 | |
| L | 2861.2 | 2977.6 | 3717.5 | 1518 | 3299.5 | 3385.2 | 2750.8 | 1046.5 | 971.8 | 983.8 | ||
| 0.125 | T | 2914.7 | 2975.3 | 3528.2 | 1923.4 | 3282.1 | 3327.3 | 2393.8 | 1350.8 | 1327.5 | 1326 | |
| L | 2941.7 | 2920.5 | 3571.9 | 1904.3 | 3281.1 | 3396.5 | 2390.1 | 1328 | 1310.1 | 1309.4 | ||
| 200 | 1 | T | 3819.6 | 4108.3 | 5183.7 | 1669.9 | 4376.8 | 4520.4 | 4003.2 | 1337.1 | 1254.1 | 1254 |
| L | 3906.6 | 4063.7 | 5253.1 | 1666.3 | 4393.6 | 4567.6 | 3981.3 | 1337.4 | 1253.3 | 1253.6 | ||
| 0.5 | T | 3827.8 | 4020.1 | 5076.6 | 1827.6 | 4350.6 | 4514.1 | 3837.1 | 1347.4 | 1267.9 | 1271.9 | |
| L | 3944.2 | 4110.4 | 5244.9 | 1820 | 4464.3 | 4578.1 | 3870.7 | 1357.9 | 1271.2 | 1273.8 | ||
| 0.25 | T | 3815.4 | 4039.7 | 4992.2 | 2039.3 | 4382.8 | 4501.7 | 3545.4 | 1362.3 | 1264.8 | 1285.6 | |
| L | 3854 | 3904.2 | 4994.3 | 2011.4 | 4364.4 | 4503.2 | 3567 | 1356.3 | 1269.3 | 1284.6 | ||
| 0.125 | T | 3874.9 | 3912.7 | 4669.2 | 2558 | 4352 | 4436.4 | 3090.7 | 1815.4 | 1797 | 1794.1 | |
| L | 3880.2 | 3869.2 | 4707.4 | 2517.7 | 4364.1 | 4466.2 | 3081 | 1757.8 | 1738.9 | 1737.8 |
| PTWINQ | RH1 | RH2 | RH3 | GP1 | GP2 | GP3 | GEP1 | GEP2 | IGEP | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 50 | 1 | T | 27,224.5 | 27,224.5 | 27,224.5 | 27,224.5 | 27,224.5 | 27,224.5 | 27,224.5 | 27,224.5 | 27,224.5 | 27,224.5 |
| L | 25,233.7 | 25,233.7 | 25,233.7 | 25,233.7 | 25,233.7 | 25,233.7 | 25,233.7 | 25,233.7 | 25,233.7 | 25,233.7 | ||
| 0.5 | T | 24,441.7 | 33,230.5 | 31,892.6 | 16,077.3 | 24,437.7 | 24,408.1 | 24,237.2 | 14,160.9 | 15,255 | 13,894.6 | |
| L | 24,038.9 | 33,058 | 33,393.1 | 14,920.6 | 24,106.5 | 24,511.4 | 24,012.4 | 12,955.3 | 14,406.6 | 13,082 | ||
| 0.25 | T | 24,248.2 | 35,934.2 | 34,661.6 | 13,897.5 | 25,648.2 | 26,515.6 | 21,726.3 | 10,606.5 | 12,529.8 | 9864 | |
| L | 23,934.2 | 34,910.8 | 34,082.3 | 13,455 | 25,639.6 | 25,617.2 | 20,995.4 | 10,123.4 | 12,236.7 | 9703.6 | ||
| 0.125 | T | 19,073.2 | 26,788 | 25,558.8 | 11,149.4 | 21,777.6 | 22,120.7 | 13,042.7 | 5917.2 | 6449.3 | 5350.7 | |
| L | 18,908.1 | 26,969.3 | 25,735.8 | 11,316.5 | 20,643.1 | 21,845.6 | 13,399.1 | 5845.1 | 6531.1 | 5244.2 | ||
| 100 | 1 | T | 92,786.7 | 142,077.1 | 139,488.9 | 45,350 | 93,993 | 95,471.1 | 93,012.4 | 38,099 | 48,963.9 | 37,113.7 |
| L | 90,151.3 | 138,283.1 | 135,782.5 | 44,171.3 | 93,240.4 | 94,048.5 | 90,654.8 | 36,340.8 | 47,756.7 | 35,788.6 | ||
| 0.5 | T | 89,267 | 135,859.2 | 130,829.4 | 44,163.6 | 91,083.1 | 94,804.6 | 83,381.6 | 34,250.1 | 44,867.9 | 32,665.5 | |
| L | 95,275 | 143,177.3 | 138,559 | 44,168.1 | 97,096.8 | 96,712 | 84,967.9 | 34,963.8 | 46,462.9 | 32,290 | ||
| 0.25 | T | 84,085.8 | 126,218.5 | 122,818.6 | 40,073.7 | 89,828.2 | 94,065.8 | 66,485.3 | 24,934 | 37,684.1 | 22,313.7 | |
| L | 81,439 | 125,729.7 | 122,325.1 | 38,315.6 | 87,727.3 | 91,408.1 | 65,143.5 | 24,726.3 | 36,684.1 | 22,505.1 | ||
| 0.125 | T | 63,625.4 | 93,736.6 | 87,527.4 | 30,413.3 | 73,309.2 | 77,736.4 | 35,468.9 | 10,280.3 | 10,698.3 | 8715.8 | |
| L | 64,998.5 | 95,745.8 | 90,721.2 | 31,192.7 | 72,116.6 | 79,313.4 | 36,350.3 | 10,321.3 | 10,883 | 8793 | ||
| 150 | 1 | T | 204,569.7 | 322,195.8 | 315,526.2 | 92,377.6 | 206,362.6 | 213,759.7 | 200,236 | 75,800.3 | 103,499.4 | 69,631.3 |
| L | 204,407.2 | 322,299.4 | 309,511.3 | 90,167.5 | 209,066.1 | 213,110.9 | 198,102.8 | 73,973.8 | 103,419.6 | 66,854.4 | ||
| 0.5 | T | 195,613.8 | 309,206.2 | 294,512.3 | 88,714.8 | 204,084.1 | 211,248 | 175,535.8 | 66,589.7 | 94,761.6 | 60,597.9 | |
| L | 207,092.5 | 317,950.4 | 310,949.7 | 88,995.7 | 213,978.2 | 216,953.7 | 179,185.2 | 66,905.6 | 97,213.2 | 61,358.7 | ||
| 0.25 | T | 175,988.4 | 282,124.5 | 269,352.2 | 78,917.2 | 193,117.1 | 202,920.4 | 130,847.7 | 44,178.2 | 75,130.1 | 36,838.1 | |
| L | 178,088.6 | 284,430.9 | 271,702.6 | 77,193.9 | 194,400 | 202,939.9 | 136,853.4 | 44,875.3 | 76,400.4 | 39,648.5 | ||
| 0.125 | T | 132,407.8 | 209,223.4 | 190,462.7 | 58,954.6 | 155,456.9 | 167,921.8 | 66,599.8 | 14,655.2 | 15,065.9 | 12,359.3 | |
| L | 136,123.5 | 208,675.1 | 194,796.2 | 59,607.5 | 157,480.9 | 169,850.3 | 68,239.5 | 14,560.2 | 15,481.2 | 12,261.6 | ||
| 200 | 1 | T | 373,429.3 | 596,443.1 | 577,584.4 | 159,719 | 385,104.6 | 393,346.8 | 356,041.8 | 126,889.4 | 185,066.9 | 114,124 |
| L | 377,988.8 | 593,816.6 | 577,838 | 157,174.4 | 381,946.4 | 394,165.1 | 352,694.6 | 125,705.9 | 185,770 | 114,017.6 | ||
| 0.5 | T | 353,438.3 | 574,122.2 | 540,786 | 151,360.7 | 372,818.8 | 383,075.1 | 306,174.1 | 108,902.3 | 165,472 | 98,491.1 | |
| L | 360,244 | 579,227.6 | 557,606.8 | 150,348.6 | 376,191.6 | 382,466.2 | 307,384.6 | 109,085.1 | 167,952 | 97,736 | ||
| 0.25 | T | 311,517.4 | 514,774 | 477,247.8 | 131,825.9 | 341,554.7 | 355,814.2 | 225,592.7 | 67,327.8 | 127,236.1 | 54,964.3 | |
| L | 314,377.7 | 499,506.9 | 484,014.9 | 130,140.9 | 342,117.3 | 357,962.9 | 229,184.5 | 69,333.7 | 129,773.9 | 60,080.3 | ||
| 0.125 | T | 230,656.1 | 363,731.4 | 332,335.7 | 96,621.6 | 268,951.2 | 295,484.4 | 104,743.6 | 18,691.1 | 18,861.6 | 15,679.6 | |
| L | 232,664.9 | 366,069.3 | 338,412.4 | 98,136.1 | 274,425.3 | 295,171.2 | 107,654.4 | 18,880.4 | 19,505.2 | 15,685.8 |
| PTWINQ | RH1 | RH2 | RH3 | GP1 | GP2 | GP3 | GEP1 | GEP2 | IGEP | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 50 | 1 | T | 20,533.6 | 20,533.6 | 20,533.6 | 20,533.6 | 20,533.6 | 20,533.6 | 20,533.6 | 20,533.6 | 20,533.6 | 20,533.6 |
| L | 18,710.5 | 18,710.5 | 18,710.5 | 18,710.5 | 18,710.5 | 18,710.5 | 18,710.5 | 18,710.5 | 18,710.5 | 18,710.5 | ||
| 0.5 | T | 17,882.5 | 26,644.3 | 25,310.1 | 9533.2 | 17,911.9 | 17,874.4 | 17,754.5 | 7689.9 | 8679.2 | 7434.4 | |
| L | 17,482.9 | 26,452.7 | 26,801.5 | 8352.3 | 17,609.2 | 18,017.9 | 17,534.8 | 6436.1 | 7808.2 | 6377.4 | ||
| 0.25 | T | 17,337.2 | 28,858.6 | 27,590.4 | 6917.2 | 18,812.7 | 19,679.1 | 14,975.5 | 3753.2 | 5603.6 | 3635.5 | |
| L | 17,187.2 | 27,987.2 | 27,167 | 6644 | 18,949.1 | 18,904.8 | 14,346.3 | 3504.2 | 5440.5 | 3608.9 | ||
| 0.125 | T | 12,833.6 | 19,961.7 | 18,762.6 | 4503.1 | 15,704.9 | 15,974.6 | 6970.9 | 835.6 | 1626.6 | 811.2 | |
| L | 12,362.1 | 19,809.1 | 18,636.3 | 4377 | 14,201.8 | 15,296.7 | 7050 | 530.7 | 1321.8 | 470.6 | ||
| 100 | 1 | T | 79,547.7 | 128,803.7 | 126,221.3 | 32,120 | 80,810.3 | 82,291 | 79,858.4 | 24,940.7 | 35,690.5 | 23,044.5 |
| L | 76,822.6 | 124,931.2 | 122,433.6 | 30,842 | 79,979.1 | 80,785.9 | 77,443.6 | 23,095.5 | 34,404.8 | 22,604.2 | ||
| 0.5 | T | 76,163 | 122,594.6 | 117,571.3 | 30,955.5 | 78,106.8 | 81,810.2 | 70,392.1 | 21,133.9 | 31,603.3 | 19,362.3 | |
| L | 81,948.3 | 129,720.2 | 125,115.5 | 30,751.9 | 83,928.6 | 83,547.5 | 71,758 | 21,623.9 | 33,005.8 | 20,694.6 | ||
| 0.25 | T | 70,932.2 | 112,555.4 | 109,159.5 | 26,505.9 | 76,852.3 | 81,090.7 | 53,439.8 | 11,500.8 | 24,141.3 | 10,601.7 | |
| L | 68,517.3 | 112,369.9 | 108,973.6 | 25,068.4 | 74,979.5 | 78,640.6 | 52,317.6 | 11,676.5 | 23,424.9 | 11228.8 | ||
| 0.125 | T | 51,564 | 80,325.1 | 74,146 | 17,188 | 61,491.2 | 65,734.2 | 23,418.3 | 1066.1 | 2090.7 | 948.9 | |
| L | 52,603.6 | 81,934.9 | 76,971 | 17,602.5 | 59,855.8 | 66,903.7 | 23,948.2 | 776.8 | 1756.6 | 668.9 | ||
| 150 | 1 | T | 184,836.2 | 302,350.3 | 295,686.5 | 72,575.5 | 186,770.6 | 194,170.9 | 180,621.2 | 56,077 | 83,653.9 | 50,811.9 |
| L | 184,455.3 | 302,260.6 | 289,475.5 | 70,151.3 | 189,269.1 | 193,326.6 | 178,355 | 54,041.5 | 83,380.8 | 50,196.5 | ||
| 0.5 | T | 175,773.6 | 289,108.4 | 274,421 | 68,673.5 | 184,443.1 | 191,609.7 | 155,848.8 | 46,641.3 | 74,663.8 | 41,503 | |
| L | 187,060.7 | 297,681.1 | 290,694 | 68,767.3 | 194,213 | 197,227 | 159,304.7 | 46,753.9 | 76,943.9 | 41,585.8 | ||
| 0.25 | T | 156,630 | 261,858.2 | 249,089.9 | 58,746.2 | 174,043.8 | 183,810.7 | 111,482.6 | 24,141.7 | 54,934.2 | 20,945.8 | |
| L | 158,703.8 | 264,323 | 251,603 | 57,198.6 | 175,279.7 | 183,816.2 | 117,488.8 | 25,081.6 | 56,334.3 | 22,907.7 | ||
| 0.125 | T | 114,495.3 | 189,187 | 170,456.4 | 39,104.4 | 137,869.4 | 150,100.2 | 48,405 | 1242.4 | 2516.3 | 1104.6 | |
| L | 117,653.7 | 188,004.1 | 174,185.9 | 39,157.2 | 139,051.3 | 151,330.4 | 49,561.2 | 936.1 | 2440.5 | 804.1 | ||
| 200 | 1 | T | 346,471.9 | 569,314.9 | 550,462 | 132,634.2 | 358,325.6 | 366,639.1 | 329,214.1 | 99,885.7 | 157,938.7 | 89,508.2 |
| L | 350,901.6 | 566,553.7 | 550,578.1 | 129,934.1 | 355,080.9 | 367,313.8 | 325,800.2 | 98,549.9 | 158,507.1 | 90,372.7 | ||
| 0.5 | T | 326,877.3 | 547,187.9 | 513,858.2 | 124,482.9 | 346,529.3 | 356,769.8 | 279,805.5 | 82,117.4 | 138,537.7 | 84,899.1 | |
| L | 333,496.8 | 552,099.9 | 530,492.7 | 123,261.8 | 349,800.2 | 356,104.5 | 280,771.5 | 82,075 | 140,824.3 | 70,765.6 | ||
| 0.25 | T | 285,586.4 | 487,559.1 | 450,036.9 | 104,706.3 | 316,013.3 | 330,203.7 | 199,487.8 | 40,342.8 | 100,107.7 | 33,508.7 | |
| L | 288,698.1 | 472,782.5 | 457,298.8 | 103,529.1 | 316,806 | 332,611.2 | 203,469.5 | 42,923.5 | 103,114.8 | 37,722.4 | ||
| 0.125 | T | 206,839.1 | 336,861.7 | 305,496.1 | 69,938.1 | 245,456.5 | 271,701 | 80,231.7 | 1395.9 | 2704.8 | 1272.3 | |
| L | 208,445.2 | 338,842.7 | 311,246.5 | 71,130.2 | 250,289.6 | 270,860.5 | 82,989.5 | 1138.1 | 2717.4 | 981.1 |
| SPT | LPT | SRM | LRM | LOPR | MOPR | SWKR | MWKR | WINQ | IGEP | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 50 | 1 | T | 1074.6 | 1074.6 | 1074.6 | 1074.6 | 1074.6 | 1074.6 | 1074.6 | 1074.6 | 1074.6 | 1074.6 |
| L | 1039.4 | 1039.4 | 1039.4 | 1039.4 | 1039.4 | 1039.4 | 1039.4 | 1039.4 | 1039.4 | 1039.4 | ||
| 0.5 | T | 969.6 | 1001.4 | 1199.1 | 553.9 | 1219.1 | 518.8 | 1174.9 | 551.7 | 1015.4 | 506.4 | |
| L | 991.8 | 985.7 | 1215.4 | 506.9 | 1222.5 | 457.3 | 1211.7 | 496.4 | 1047.7 | 444.9 | ||
| 0.25 | T | 1011.6 | 1050.6 | 1331.9 | 480.7 | 1303.3 | 427.4 | 1303.7 | 469.9 | 1091 | 406.1 | |
| L | 978 | 1019 | 1295.1 | 466.7 | 1333.2 | 423.5 | 1282.2 | 472.8 | 1054 | 402.6 | ||
| 0.125 | T | 1002.5 | 1049.4 | 1320.3 | 584.1 | 1328 | 545.9 | 1283.2 | 575.7 | 1081.8 | 499.4 | |
| L | 999.8 | 1054.1 | 1297 | 563.1 | 1332 | 531.1 | 1303.6 | 555.9 | 1063.9 | 477.3 | ||
| 100 | 1 | T | 1863.7 | 1932.8 | 2473.5 | 755.1 | 2496.8 | 681.9 | 2448.5 | 745.7 | 1951.2 | 677 |
| L | 1857.9 | 1894.8 | 2474.9 | 742.6 | 2475.8 | 664.8 | 2459.8 | 746.8 | 1985.3 | 661.9 | ||
| 0.5 | T | 1847.4 | 1915.7 | 2462.8 | 773.7 | 2498.2 | 699.2 | 2464.6 | 781 | 1971.7 | 689.8 | |
| L | 1953.1 | 1976.7 | 2555.9 | 795.9 | 2546.3 | 701.3 | 2513.5 | 787.4 | 2089.2 | 690.5 | ||
| 0.25 | T | 1878.8 | 1981 | 2523.1 | 865.5 | 2542.6 | 767.3 | 2491.2 | 845.8 | 2051.7 | 698.1 | |
| L | 1858.8 | 1930.1 | 2455.2 | 823.5 | 2529.7 | 732.9 | 2450.1 | 818.7 | 1993.9 | 683.9 | ||
| 0.125 | T | 1886.9 | 1970.9 | 2541.4 | 1071.7 | 2554.2 | 1004.4 | 2523.2 | 1057.1 | 2049.6 | 923.2 | |
| L | 1871.3 | 1994.2 | 2495.4 | 1047.7 | 2580.3 | 981.8 | 2520.8 | 1035.8 | 2044.7 | 895.8 | ||
| 150 | 1 | T | 2731.2 | 2895.6 | 3684 | 1064 | 3695.1 | 959.5 | 3678.1 | 1053.2 | 2918.9 | 955.5 |
| L | 2797.4 | 2858.2 | 3746.5 | 1054.2 | 3728.3 | 943.7 | 3710.3 | 1048.8 | 2976.6 | 944.2 | ||
| 0.5 | T | 2743.3 | 2908.1 | 3713.4 | 1100.6 | 3771.5 | 997.2 | 3685.2 | 1100.2 | 2970.5 | 983.4 | |
| L | 2835.8 | 2921.5 | 3769.1 | 1120.2 | 3821.7 | 997.3 | 3758.4 | 1101.6 | 3029.6 | 980.2 | ||
| 0.25 | T | 2794.4 | 2928.5 | 3735.6 | 1229 | 3774.1 | 1087.4 | 3706.5 | 1217.3 | 3018.1 | 982.8 | |
| L | 2758.3 | 2889.6 | 3682.6 | 1190.3 | 3817.6 | 1070.2 | 3691 | 1178.9 | 3002 | 983.8 | ||
| 0.125 | T | 2795.3 | 2894.7 | 3752.2 | 1539.3 | 3797.2 | 1436.8 | 3720 | 1520.8 | 2993.1 | 1326 | |
| L | 2772.4 | 2931.1 | 3713.2 | 1517.1 | 3813.1 | 1417.1 | 3754.4 | 1503.6 | 3028.9 | 1309.4 | ||
| 200 | 1 | T | 3704.6 | 3900.8 | 4971.6 | 1391 | 5043.6 | 1255.5 | 4996.3 | 1400.7 | 3949.7 | 1254 |
| L | 3781.5 | 3876.7 | 5063.7 | 1385 | 5077.2 | 1252.2 | 5034.3 | 1381.1 | 4035.8 | 1253.6 | ||
| 0.5 | T | 3687.2 | 3918 | 4985.2 | 1430.3 | 5046.5 | 1286.2 | 4959.5 | 1433.2 | 4013.8 | 1271.9 | |
| L | 3788.5 | 3887.2 | 5011 | 1454.3 | 5092.7 | 1302.3 | 5038.9 | 1434.7 | 4033.7 | 1273.8 | ||
| 0.25 | T | 3728.4 | 3872 | 5017.6 | 1587.8 | 5052.7 | 1423.7 | 4950.7 | 1577.8 | 4015.8 | 1285.6 | |
| L | 3693.2 | 3841 | 4919.8 | 1573.3 | 5091 | 1420.5 | 4949.5 | 1532.6 | 3995.9 | 1284.6 | ||
| 0.125 | T | 3711.3 | 3862.8 | 4996.6 | 2033.7 | 5047.3 | 1904.5 | 4971 | 2015.5 | 3969.5 | 1794.1 | |
| L | 3671.6 | 3886.7 | 4946.4 | 2005.1 | 5060 | 1884 | 4993.7 | 1988.9 | 4002.2 | 1737.8 |
| SPT | LPT | SRM | LRM | LOPR | MOPR | SWKR | MWKR | WINQ | IGEP | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 50 | 1 | T | 27,224.5 | 27,224.5 | 27,224.5 | 27,224.5 | 27,224.5 | 27,224.5 | 27,224.5 | 27,224.5 | 27,224.5 | 27,224.5 |
| L | 25,233.7 | 25,233.7 | 25,233.7 | 25,233.7 | 25,233.7 | 25,233.7 | 25,233.7 | 25,233.7 | 25,233.7 | 25,233.7 | ||
| 0.5 | T | 25,367 | 28,762.7 | 26,538.3 | 18,086.4 | 29,179.1 | 16,208.7 | 26,031.2 | 17,914.4 | 25,199 | 13,894.6 | |
| L | 25,481 | 29,491.1 | 26,230.8 | 17,267.4 | 28,659.6 | 15,307.2 | 26,031.9 | 17,195.1 | 25,985.2 | 13,082 | ||
| 0.25 | T | 25,558.2 | 30,896.9 | 27,880.9 | 16,336.8 | 30,395.1 | 13,945.9 | 27,049.2 | 16,315.3 | 26,523.5 | 9864 | |
| L | 24,473.8 | 29,764.3 | 26,547.6 | 15,904.2 | 30,748.6 | 13,842.9 | 26,569.6 | 16,447.1 | 26,038.6 | 9703.6 | ||
| 0.125 | T | 20,097.5 | 25,653.3 | 22,624.7 | 15,439.8 | 26,027.5 | 11,986.6 | 21,504.5 | 15,058 | 20,987.2 | 5350.7 | |
| L | 19,035.8 | 24,948.3 | 21,851.3 | 15,444.4 | 26,106.1 | 12,425.4 | 21,948.3 | 14,973 | 20,456.2 | 5244.2 | ||
| 100 | 1 | T | 99,112.4 | 117,741.8 | 104,772.2 | 57,637 | 118,810.7 | 50,844.2 | 102,906.1 | 58,063.9 | 98,395.6 | 37,113.7 |
| L | 96,182.5 | 114,172.1 | 104,160.6 | 56,945.5 | 116,116.2 | 49,804.5 | 102,523.8 | 58,117.7 | 98,511 | 35,788.6 | ||
| 0.5 | T | 94,013.1 | 112,281 | 101,616.1 | 56,170.7 | 116,604.4 | 48,142.4 | 100,827.7 | 57,115.4 | 95,243.8 | 32,665.5 | |
| L | 99,156.3 | 118,706.1 | 106,127.5 | 58,120.2 | 117,269.8 | 49,244.2 | 104,129.4 | 58,531.7 | 103,462.2 | 32,290 | ||
| 0.25 | T | 86,467 | 110,893 | 97,038.2 | 55,704.4 | 109,885.7 | 46,081.8 | 95,112.1 | 55,241.5 | 92,568.6 | 22,313.7 | |
| L | 85,136.6 | 106,444.7 | 92,318.7 | 52,635.2 | 110,154.2 | 44,461.5 | 92,128 | 53,240.5 | 89,722.2 | 22,505.1 | ||
| 0.125 | T | 64,887.4 | 85,448.6 | 76,893.4 | 51,505.8 | 91,053.9 | 34,471.9 | 75,216.1 | 49,034.4 | 70,185.7 | 8715.8 | |
| L | 64,722.4 | 87,397.7 | 75,101.9 | 52,619 | 93,653.2 | 38,588.9 | 76,328.2 | 51,683.3 | 71,398.2 | 8793 | ||
| 150 | 1 | T | 216,121.4 | 263,288.9 | 232,508.7 | 122,514.2 | 265,876.6 | 107,791 | 230,420 | 123,236.2 | 219,096.4 | 69,631.3 |
| L | 216,246 | 259,781.8 | 235,140.5 | 121,898.5 | 264,146.6 | 107,478 | 231,549.8 | 123,811.6 | 220,239.6 | 66,854.4 | ||
| 0.5 | T | 206,342.8 | 253,886.7 | 226,852.7 | 118,218.2 | 259,345.4 | 101,493.6 | 223,336.1 | 120,346.6 | 213,556.8 | 60,597.9 | |
| L | 216,769.4 | 261,532.1 | 231,611.3 | 121,830.8 | 263,271.5 | 103,520.1 | 229,419.5 | 122,883 | 223,058.3 | 61,358.7 | ||
| 0.25 | T | 188,564.8 | 239,162.3 | 210,027.3 | 115,352 | 240,296.3 | 96,130.6 | 205,856.2 | 117,168.9 | 198,005.1 | 36,838.1 | |
| L | 187,739 | 239,132.6 | 204,412.4 | 114,100.3 | 245,338.8 | 96,287.6 | 205,583.8 | 114,638.5 | 199,583.3 | 39,648.5 | ||
| 0.125 | T | 137,160.3 | 185,599 | 164,794.7 | 108,463.6 | 196,893 | 65,683.1 | 161,226.8 | 103,360.1 | 146,186.3 | 12,359.3 | |
| L | 136,049.9 | 188,810.2 | 161,983.1 | 109,433.6 | 200,729.8 | 73,804.9 | 163,627.9 | 107,428.1 | 150,689.4 | 12,261.6 | ||
| 200 | 1 | T | 394,656.6 | 480,846.3 | 424,225.6 | 220,485.5 | 487,352.8 | 193,205 | 425,035.7 | 224,262.4 | 401,391 | 114,124 |
| L | 398,032.7 | 477,883 | 432,521.8 | 218,964.7 | 488,024.9 | 193,208.9 | 425,772.1 | 222,543.4 | 406,202.3 | 114,017.6 | ||
| 0.5 | T | 370,484.8 | 464,258.9 | 406,416.6 | 206,974.8 | 467,858.6 | 178,291 | 401,960.7 | 211,480.5 | 387,306.9 | 98,491.1 | |
| L | 381,712.6 | 465,508.5 | 406,692.7 | 213,512 | 470,242 | 180,820.4 | 404,886.6 | 213,256.7 | 388,877.7 | 97,736 | ||
| 0.25 | T | 334,137 | 420,566.6 | 371,511.7 | 199,130.3 | 426,609.7 | 169,031.3 | 362,286.6 | 202,354.8 | 349,292.9 | 54,964.3 | |
| L | 331,423.9 | 424,995.8 | 359,986.7 | 201,033.5 | 436,141.4 | 169,503.1 | 363,879.9 | 198,520.7 | 351,902.1 | 60,080.3 | ||
| 0.125 | T | 240,061.4 | 324,089.6 | 287,391.1 | 191,035.5 | 345,463 | 106,100.8 | 282,653.3 | 181,933.2 | 256,071.8 | 15,679.6 | |
| L | 235,147.8 | 326,479 | 282,299.4 | 191,882.2 | 352,169.1 | 121,131.5 | 284,588.7 | 185,692.6 | 258,831.2 | 15,685.8 |
| SPT | LPT | SRM | LRM | LOPR | MOPR | SWKR | MWKR | WINQ | IGEP | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 50 | 1 | T | 20,533.6 | 20,533.6 | 20,533.6 | 20,533.6 | 20,533.6 | 20,533.6 | 20,533.6 | 20,533.6 | 20,533.6 | 20,533.6 |
| L | 18,710.5 | 18,710.5 | 18,710.5 | 18,710.5 | 18,710.5 | 18,710.5 | 18,710.5 | 18,710.5 | 18,710.5 | 18,710.5 | ||
| 0.5 | T | 18,791.8 | 22,222.4 | 19,998.7 | 11,500.2 | 22,621.4 | 9623 | 19,488.4 | 11,328.2 | 18,625.3 | 7434.4 | |
| L | 18,897.7 | 22,911.8 | 19,700.5 | 10,662.1 | 22,102.2 | 8701.9 | 19,515.8 | 10,589.8 | 19,408.9 | 6377.4 | ||
| 0.25 | T | 18,612.2 | 23,929.8 | 21,046.7 | 9268.3 | 23,371.8 | 6908.5 | 20,164.6 | 9254.7 | 19,549.4 | 3635.5 | |
| L | 17,680.9 | 22,954.2 | 19,823.6 | 8983.8 | 23,892.3 | 6946.2 | 19,828.7 | 9539 | 19,237.9 | 3608.9 | ||
| 0.125 | T | 13,771.6 | 19,182.2 | 16,405.7 | 8797.6 | 19,257.4 | 5696.6 | 15,265.5 | 8598.1 | 14,656.7 | 811.2 | |
| L | 12,351.8 | 18,305.6 | 15,300.1 | 8435.7 | 19,025.4 | 5703.4 | 15,313.9 | 8119.9 | 13,732.3 | 470.6 | ||
| 100 | 1 | T | 85,844.4 | 104,481.2 | 91,578.4 | 44,363.6 | 105,601.1 | 37,570.8 | 89,706.9 | 44,790.5 | 85,134.6 | 23,044.5 |
| L | 82,833.5 | 100,841.9 | 90,895.4 | 43,593.6 | 102,801.2 | 36,452.6 | 89,243.1 | 44,765.8 | 85,162.8 | 22,604.2 | ||
| 0.5 | T | 80,800.5 | 99,100 | 88,597.8 | 42,906.1 | 103,385.5 | 34,877.8 | 87,842.8 | 43,850.8 | 82,054.3 | 19,362.3 | |
| L | 85,740.8 | 105,266.7 | 92,916.3 | 44,663.1 | 103,868.4 | 35,787.1 | 90,925.3 | 45,074.6 | 90,062.8 | 20,694.6 | ||
| 0.25 | T | 73,122.7 | 97,448.3 | 84,033.3 | 42,041.3 | 96,274.9 | 32,418.7 | 82,062.5 | 41,578.4 | 79,159.5 | 10,601.7 | |
| L | 72,100 | 93,278.9 | 79,504 | 39,275.4 | 96,861.7 | 31,101.7 | 79,266.6 | 39,880.7 | 76,718.4 | 11,228.8 | ||
| 0.125 | T | 52,506.7 | 72,728 | 64,783.9 | 38,190.3 | 77,698.6 | 21,644.9 | 63,114 | 36,023.6 | 57,827.4 | 948.9 | |
| L | 51,984.6 | 74,491.2 | 62,725.9 | 38,895.5 | 79,921.8 | 25,293.8 | 63,786.2 | 38,263.8 | 58,575.7 | 668.9 | ||
| 150 | 1 | T | 196,298.8 | 243,479.5 | 212,857.6 | 102,668.7 | 246,094.9 | 87,945.5 | 210,753.6 | 103,390.7 | 199,277.9 | 50,811.9 |
| L | 196,224.3 | 239,786.7 | 215,285.8 | 101,859.7 | 244,144.7 | 87,439.2 | 211,685.8 | 103,772.8 | 200,214.3 | 50,196.5 | ||
| 0.5 | T | 186,346.6 | 233,907.5 | 207,151 | 98,120.4 | 239,293.3 | 81,395.8 | 203,686.5 | 100,248.8 | 193,566.5 | 41,503 | |
| L | 196,632.7 | 241,344.8 | 211,832.1 | 101,561.5 | 243,057.9 | 83,250.8 | 209,628.8 | 102,613.7 | 202,913.6 | 41,585.8 | ||
| 0.25 | T | 168,897.3 | 219,248.3 | 190,863.5 | 95,085.7 | 220,082.3 | 75,864.3 | 186,642.5 | 96,902.6 | 178,296.3 | 20,945.8 | |
| L | 168,103 | 219,350.8 | 185,165.3 | 93,992.4 | 225,298.2 | 76,179.7 | 186,302.3 | 94,530.6 | 180,035.4 | 22,907.7 | ||
| 0.125 | T | 118,781.8 | 166,656.9 | 146,718.6 | 88,474.6 | 176,912.8 | 46,245.1 | 143,154.5 | 83,740.2 | 127,841 | 1104.6 | |
| L | 117,061.5 | 169,528.1 | 143,473.7 | 88,792.3 | 180,138.3 | 53,607.2 | 144,918.8 | 87,192.8 | 131,600.2 | 804.1 | ||
| 200 | 1 | T | 367,566.8 | 453,777.9 | 397,394.9 | 193,357.3 | 460,288.4 | 166,076.8 | 398,191.1 | 197,134.2 | 374,303.4 | 89,508.2 |
| L | 370,802.5 | 450,657.1 | 405,571.5 | 191,701.8 | 460,798.9 | 165,946 | 398,818.5 | 195,280.5 | 378,982 | 90,372.7 | ||
| 0.5 | T | 343,700.2 | 437,474.2 | 380,128.6 | 180,040.5 | 440,970 | 151,356.7 | 375,668.4 | 184,546.2 | 360,535.8 | 84,899.1 | |
| L | 354,788.9 | 438,528.3 | 380,249 | 186,384.3 | 443,170 | 153,692.7 | 378,442.5 | 186,129 | 361,946.7 | 70,765.6 | ||
| 0.25 | T | 307,700.7 | 393,793.3 | 345,820.5 | 171,915.4 | 399,447.1 | 141,816.4 | 336,503.8 | 175,139.9 | 322,808.9 | 33,508.7 | |
| L | 305,354.9 | 398,724 | 334,524.6 | 174,309.1 | 409,484.3 | 142,778.7 | 338,333.8 | 171,796.3 | 325,958.1 | 37,722.4 | ||
| 0.125 | T | 215,481.6 | 298,779.2 | 263,354.1 | 164,201.6 | 318,649.5 | 79,942.9 | 258,465.7 | 155,595.8 | 231,508.3 | 1272.3 | |
| L | 210,275.5 | 301,127.5 | 257,979.3 | 164,650.4 | 325,022 | 94,324.4 | 260,090.1 | 158,884.6 | 233,877.2 | 981.1 |
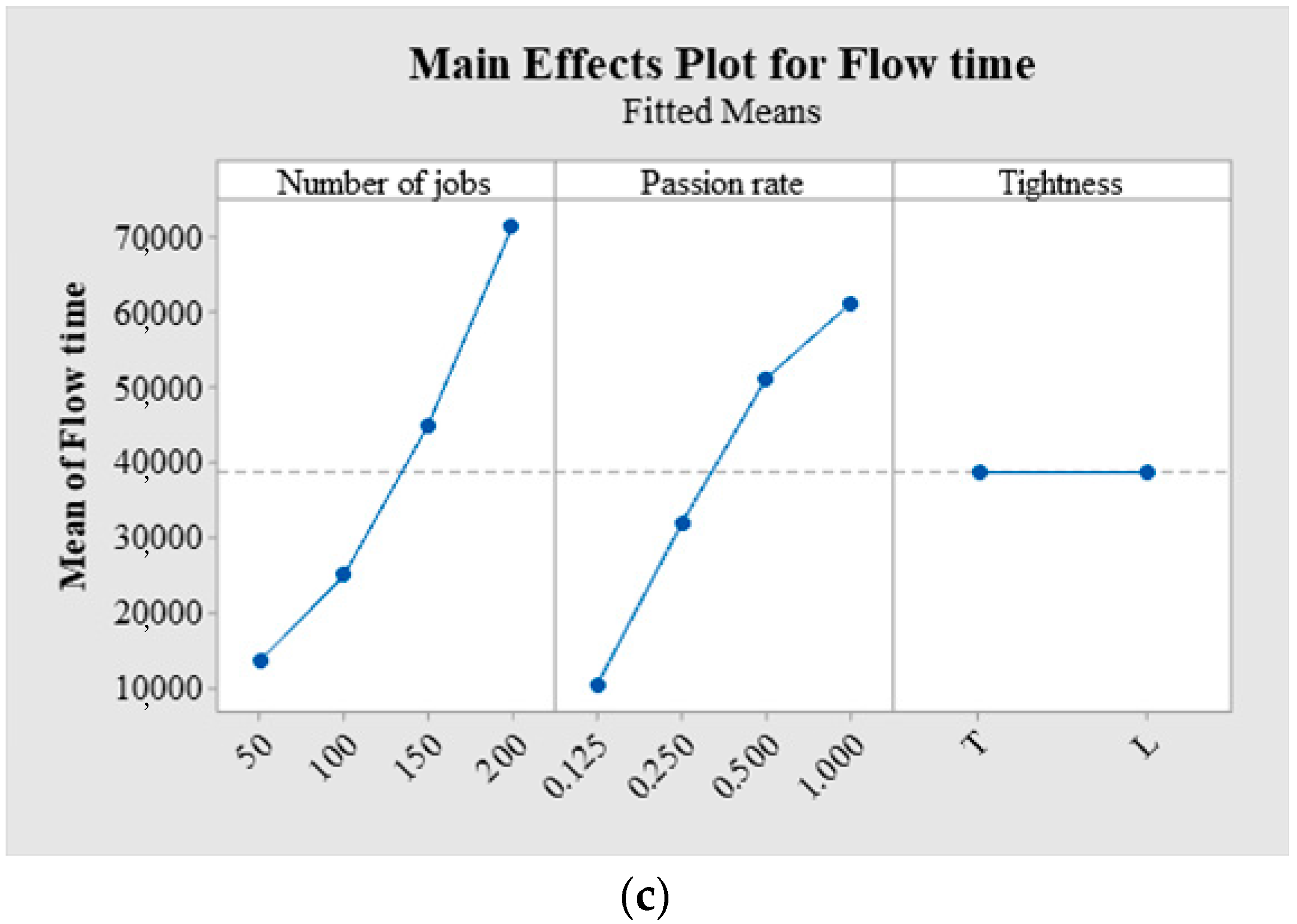
| Source of Variation | Makespan | Total Flow Time | Tardiness | ||||
|---|---|---|---|---|---|---|---|
| Main Effects | F | p | F | p | F | p | |
| A: Passion rate | 4.23 | 0.016 | 19.83 | 0.000 | 17.32 | 0.000 | |
| B: number of jobs | 30.78 | 0.000 | 25.24 | 0.000 | 16.32 | 0.000 | |
| C: Tightness | 0.07 | 0.797 | 0.00 | 0.996 | 0.02 | 0.895 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, L.; Hu, Y.; Tang, Q.; Li, J.; Li, Z. Data-Driven Dispatching Rules Mining and Real-Time Decision-Making Methodology in Intelligent Manufacturing Shop Floor with Uncertainty. Sensors 2021, 21, 4836. https://doi.org/10.3390/s21144836
Zhang L, Hu Y, Tang Q, Li J, Li Z. Data-Driven Dispatching Rules Mining and Real-Time Decision-Making Methodology in Intelligent Manufacturing Shop Floor with Uncertainty. Sensors. 2021; 21(14):4836. https://doi.org/10.3390/s21144836
Chicago/Turabian StyleZhang, Liping, Yifan Hu, Qiuhua Tang, Jie Li, and Zhixiong Li. 2021. "Data-Driven Dispatching Rules Mining and Real-Time Decision-Making Methodology in Intelligent Manufacturing Shop Floor with Uncertainty" Sensors 21, no. 14: 4836. https://doi.org/10.3390/s21144836
APA StyleZhang, L., Hu, Y., Tang, Q., Li, J., & Li, Z. (2021). Data-Driven Dispatching Rules Mining and Real-Time Decision-Making Methodology in Intelligent Manufacturing Shop Floor with Uncertainty. Sensors, 21(14), 4836. https://doi.org/10.3390/s21144836