1. Introduction
The advances in hardware and software technologies have led to the adoption of smart-environments in many contexts of our daily lives. Smart homes and smart buildings are already equipped with a multitude of embedded devices, along with connected sensors and actuators [
1]. Several real cases already exemplify smart cities, which use the opportunities provided by innovative technologies to improve the lives of their inhabitants [
2]. In such settings, smart environments are expected to play a crucial role for coping with the needs of sustainability, energy distribution, mobility, health and public safety/security [
3]. A particular focus is the realization of ambient assisted living (AAL) solutions to enable elderly people to live independently for as long as possible, without intrusiveness from others. These solutions benefit from Internet of Things (IoT)-enabling technologies to improve elderly life thanks to the introduction of intelligent, connected devices [
4].
Several AAL applications have been developed that have user positioning as their core capability. Elderly care [
5], guidance systems [
6], energy consumption [
7] and security [
8] are only some of the possible applications of indoor positioning information. Based on indoor positioning, it is possible to identify where a user is located and to predict his/her future locations based on the recent location history. In this paper, the indoor positioning issue is addressed by considering the performance obtained while using two different kinds of device to estimate the indoor position: a smartphone and a smartwatch. With both devices, the Bluetooth Low Energy (BLE) technology was exploited to obtain indoor positioning information. A generic home has been equipped with BLE beacon infrastructure, and several tests have been carried out with different configurations in terms of the number and models of beacons in each room. For each test campaign, the performance in terms of mean percentage error in the detection of the indoor position was calculated using a smartphone and a smartwatch, and the results have been discussed. For the location prediction, we present an algorithm based on using neural embeddings to represent the locations of a house and an attention-based mechanism that instead of being applied to the hidden states of the neural network architecture is used to modify those embeddings.
The rest of the paper is structured as follows.
Section 2 contains an analysis of the state of the art. In
Section 3 we describe the overall architecture of the system and in
Section 4 the location prediction algorithm.
Section 5 contains an explanation of the testing environment and we discuss the results of the experiments in
Section 6. Finally, in
Section 7 we draw the conclusions and propose future areas of research.
3. System Architecture
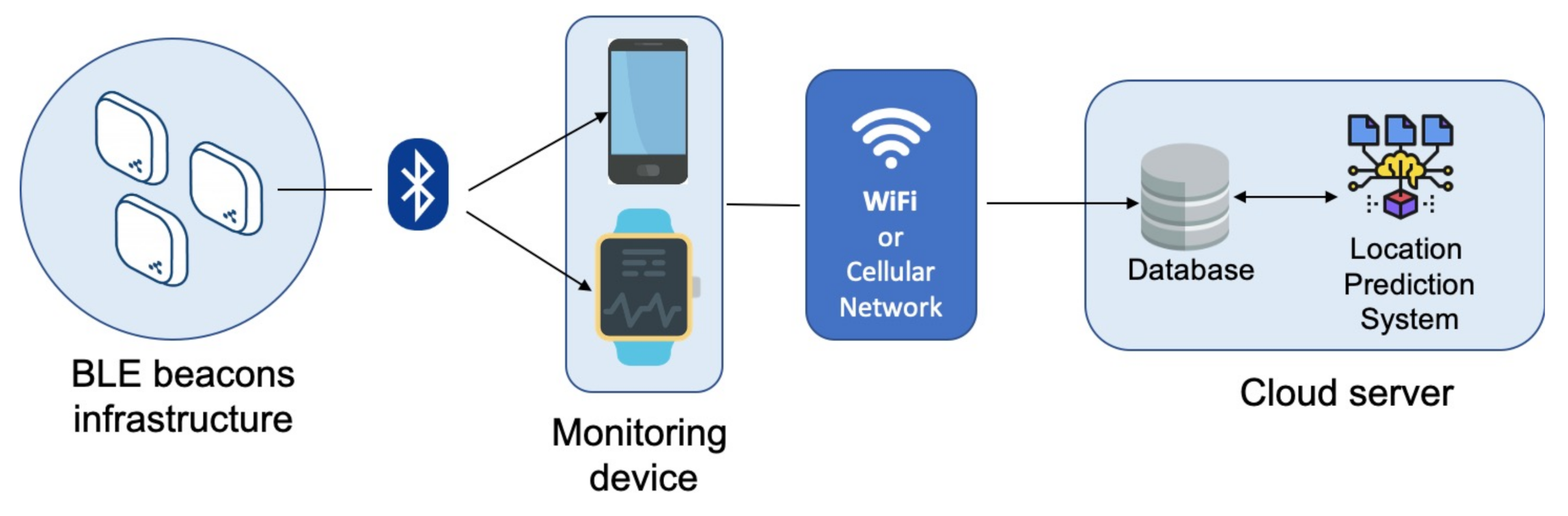
In
Figure 1, the system’s overall architecture is depicted. It mainly consists of the following components:
BLE beacon infrastructure.
A monitoring device to capture positioning data.
A cloud server to store and process captured data.
Beacons are small radio transmitters that send Bluetooth signals. They are available in different sizes and shapes, making them suitable for a wide range of applications and allowing them to be easily integrated into any environment unobtrusively. A beacon is cost-effective and can be installed easily, and its position can be determined with to within a few meters. The BLE standard is also very energy efficient. Beacons can be used in server-based (asset tracking) and client-based (indoor navigation) applications. The last option was used in our study. Specifically, in the proposed solution, the indoor environment is equipped with a BLE beacon infrastructure. In particular, a BLE beacon is placed in each room, but in large rooms or long corridors, more beacons can be placed.
On the server side, every association between a beacon (i.e., the MAC address of the beacon) and its location (i.e., the room in which it is located) is stored in the database. When the application starts, this beacon/room map is transmitted from the server to the local database on the monitoring device. In this way, the application performs preliminary filtering during the scanning phase and only considers signals from beacons that are part of the implemented infrastructure for subsequent operations. The monitoring device consists of a smartphone or smartwatch running a specially designed and implemented application. In particular, the mobile application performs repeated Bluetooth scanning in configurable time intervals. With our settings, Bluetooth scanning lasts 10 seconds, and the next scan starts 15 s after the end of the previous one. During the scanning phase (i.e., within a 10-s interval), each beacon will be detected multiple times, triggering an event. Specifically, the average value of the detected RSSI and the average value of the transmission power (TxPower) (the power at which the beacon broadcasts its signal) are calculated. At the conclusion of the scanning process, a list of beacons identified by MAC address is obtained, along with relative average RSSI and TxPower values. Using these values, the calculateRating function in Listing 1 is applied for each beacon.
| Listing 1. Function used to calculate the RSSI accuracy. |
| 1 | /* |
| 2 | * Calculates the accuracy of RSSI value considering txPower |
| 3 | * https://developer.radiusnetworks.com/2014/12/04/fundamentals- |
| 4 | * beacon-ranging.html |
| 5 | */ |
| 6 | protected static double calculateRating(int txPower, double rssi) { |
| 7 | if (rssi == 0) { |
| 8 | return -1.0; // if we cannot determine accuracy, return -1. |
| 9 | } |
| 10 | |
| 11 | double ratio = rssi*1.0/txPower; |
| 12 | if (ratio < 1.0) { |
| 13 | return Math.pow(ratio,10); |
| 14 | } |
| 15 | else |
| 16 | return (0.89976)*Math.pow(ratio,7.7095) + 0.111; |
| 17 | } |
This allows an “accuracy” value, called a rating, to be assigned to each beacon, which is used to correct the detected average RSSI value.
The formula used in the previous code to calculate the rating was [
44]:
The three constants in the formula (0.89976, 7.7095 and 0.111) are based on a best fit curve based on a number of measured signal strengths at various known distances from a Nexus 4. However, because the accuracy of this measurement is affected by errors, our algorithm uses the formula generically as a “rating” rather than as a true distance.
Additionally, each beacon is linked to an indoor location (room) via the function in Listing 2.
| Listing 2. Function used to link each beacon to the corresponding room. |
| 1 | /* |
| 2 | * IndoorLocation |
| 3 | * @param beacon_address the BLE beacon mac address |
| 4 | * @param location_type the location (room) string label |
| 5 | * @param location_id the location (room) specific beacon identifier |
| 6 | * @param location_calibrated_rssi the integer value of RSSI measured at 1 meter |
| 7 | */ |
| 8 | indoorLocations.add(new IndoorLocation("E0:2E:61:8A:19:E7", "Livingroom", "53", -70)); |
| 9 | indoorLocations.add(new IndoorLocation("D3:5E:63:38:3B:45", "Bedroom", "56", -65)); |
| 10 | indoorLocations.add(new IndoorLocation(DC:64:4C:44:61:8C", "Livingroom", "32", -50)); |
| 11 | indoorLocations.add(new IndoorLocation("D4:64:95:34:4F:46", "Bathroom", "LVR", -70)); |
| 12 | indoorLocations.add(new IndoorLocation("FD:19:B1:2A:45:6B", "Bathroom", "46", -80)); |
| 13 | indoorLocations.add(new IndoorLocation("F0:A9:05:0A:6F:DB", "Bathroom", "54", -60)) |
| 14 | indoorLocations.add(new IndoorLocation("C8:7E:EC:5F:E4:00", "Bedroom", "47", -60)); |
| 15 | indoorLocations.add(new IndoorLocation("D4:3E:77:B1:F8:9D", "Kitchen", "45", -50)); |
| 16 | indoorLocations.add(new IndoorLocation("E9:68:B7:2C:F9:68", "Kitchen", "23-black", 0)); |
As a result, each beacon is identified by its MAC address, associated with the corresponding room (e.g., living room, bathroom, bedroom or kitchen), and labeled with a location ID label (53, 56, 32, LVR, etc.) In addition, each beacon has a calibration RSSI value that corresponds to the average RSSI value measured at a 1 meter distance.
Finally, the distance from each beacon is calculated using this calibration value and the “log-distance path loss” [
45] as reported in Listing 3.
| Listing 3. Distance calculation. |
| 1 | /** |
| 2 | * Calculates distances using the log-distance path loss model |
| 3 | * |
| 4 | * @param rssi the currently measured RSSI |
| 5 | * @param calibratedRssi the RSSI measured at 1m distance |
| 6 | * @param pathLossParameter the path-loss adjustment parameter |
| 7 | */ |
| 8 | public static double calculateDistance(double rssi, float calibratedRssi) { |
| 9 | float pathLossParameter = 3f; |
| 10 | return Math.pow(10, (calibratedRssi - rssi) / (10 * pathLossParameter)); |
| 11 | } |
Then, the beacon list is sorted according to the rating value. Since the calculated rating is proportional to the distance, as specified in the formula (
1), the first beacon in the list is the beacon with the lowest rating and closest to the smartphone.
The information about the nearest beacon is sent to the cloud server by the application. All detected locations are saved on the server and provided to the location prediction system to be processed, as described in
Section 4.
4. Location Prediction System
The location prediction system is based in our previous work [
38,
39] focused on predicting users’ behavior. The algorithm we present in this paper models the user’s movements through indoor locations; it uses the semantic location to model them. One of the characteristics of our algorithm is that it works in the semantic-location space instead of the sensor space, which allows us to abstract from the underlying indoor location technologies. The location prediction is divided into four modules that process the data sequentially (see
Figure 2):
Input module: It takes the semantic locations as inputs and transforms them into embeddings to be processed. It has both an input and an embedding layer.
Attention mechanism: It evaluates the location embedding sequence to identify those that are more relevant for the prediction process. To do so, it uses a GRU layer, followed by a dense layer with a tanh activation and finally a dense layer with a softmax activation.
Sequence feature extractor: It receives the location embeddings processed by the attention mechanism and uses a 1D CNN or a LSTM to identify the most relevelant location n-grams of sequences of locations for the prediction. In case of the CNNs, multiple 1D convolution operations are done in parallel to extract n-grams of different lengths in order to obtain a rich representation of the relevant features.
Location prediction module: It receives the features extracted by the sequence feature extractor (multi-scale CNNs or LSTMs) and uses those features to predict the next location. This module is composed of two dense layers with ReLU activations and an output dense layer with a softmax activation.
4.1. Input Module
The input module is in charge of receiving the location IDs and using the embedding matrix to get the vectors that represent them. As we demonstrated in [
38], using better representations, such as embeddings, instead of IDs, provides better predictions. The proposed system uses Word2Vec to obtain the embedding vectors [
46], a model widely used in the NLP community.
Given a sequence of locations
where
n is the length of the sequence and
indicates the location vector of the
ith location in the sequence, and
represents the context of
, the window size being
.
is the probability of
being in that position of the location instance sequence. To calculate the embeddings, we try to optimize the log maximum likelihood estimation:
Our system uses Gensim to calculate the embedding vectors for each location in the dataset. The location embedding vectors have a size of 50. To translate the one-hot encoded location IDs to embeddings, we use an embedding matrix, instead of providing the embedding values directly. This allows us to train this matrix and adapt the calculated embeddings to the task at hand, thereby improving the results.
4.2. Attention Mechanism
Once we have the semantic embeddings for each location, they are processed by the attention mechanism to identify those locations in the sequence that are more relevant for the prediction process. To do so we use a soft attention mechanism. This is a similar approach to the ones used in NLP to identify the most relevant words in a phrase. However, we do something different in this approach: applying the attention mechanism to the embeddings instead of the hidden steps of the sequence encoder. As proven in [
38], this approach has achieved better results when predicting locations.
Location sequences
are temporally ordered sets of locations
, given
. The location sequence
goes through the input module, which uses the matrix
, calculated previously with Word2Vec, to obtain the location embedding vectors. Those embedding vectors are then processed by the gated recurrent unit layer, creating a representation of the sequence. This gated recurrent unit layer reads the location sequence from
to
. The used gated recurrent unit layer has a total of 128 units.
The attention module gets the gated recurrent unit’s layer states
and creates a vector of weights
with the relevance of each location
. This is done using a dense layer with a unit size of 128 to get the hidden representation
of
:
Then we use a softmax function to calculate the normalized relevance of the weights (
) for the location instances:
The obtained vector is used to calculate the relevance of the location embeddings
for the prediction,
:
Those embeddings are the used to process the sequence.
4.3. Sequence Feature Extractor
After obtaining the attention modified location embeddings
in Equation (
7), we tested two different approaches to perform the feature extraction: CNNs and LSTMs.
On the one hand, the CNN architecture was used to extract the features of the sequence. This architecture was composed of multiple 1D CNNs that processed the sequence in parallel with different kernel sizes. This was done to identify differently sized n-grams in the location sequences. The location sequences had a set length:
. The size of the location embedding was represented by
, and the elements of the embedding were real numbers,
. After getting the attention modified location embeddings, each location sequence was represented like
. The convolution operation was:
The result of the operation was , and , and b were the trained parameters. The activation function was a rectified linear unit, and represents the element-wise multiplication. Using filter maps, the output of the operation was . Two hundred filters were used in this case for each convolution operation. After each convolution layer we used 1 max pooling layer. Finally, the results of all the parallel convolution layers were concatenated and flattened.
On the other hand, the LSTM with 512 units received the location embeddings and analysed the existing temporal relations among the different locations that formed each of the sequences. Then, dropout normalization was applied to the extracted features.
4.4. Location Prediction Module
The input for the location prediction module is the output of the previously described feature extractor module. To predict the most probable location, this module uses three dense layers. The first two ones (
) use rectified linear units as their activation:
To predict the location, the final dense layer uses a softmax activation. The output of this module is a vector with the probabilities of each possible location.
7. Conclusions
In this paper we present an indoor locating system based on BLE and its evaluation utilizing a smartphone and a smartwatch as monitoring devices. Over that system, we built a behavior prediction system based on locations and validated two different approaches. Our system provides a holistic approach to an indoor location system, providing both the necessary infrastructure and the intelligent framework over it.
The system’s performance in terms of mean percentage error was assessed and analyzed. A distinct BLE beacon infrastructure was considered for each test by altering the quantity and models of BLE beacons in each room of the considered indoor environment. The best results were achieved using the smartwatch instead of the smartphone.
Furthermore, a position prediction system based on neural embeddings to represent the locations of a house was introduced, along with an attention-based mechanism that modifies those embeddings rather than having them applied to the hidden states of the neural network design. The location prediction system’s accuracy has also been assessed, compared with other approaches and discussed. From these experiments, two main conclusions can be drawn: first, the proposed attention mechanism applied to the embeddings improves the architecture’s performance; and second, despite the limited size of training samples, the presented deep neural network architectures performed better than shallow machine learning algorithms such as hidden Markov models.
The system will be expanded in the future by including RFID components, such as wearable RFID devices and RFID tags, to capture data that will be processed by an activity recognition module. From location data and RFID data, this module will be able to deduce user activities. Additionally, as a future extension of the presented work, it would be interesting to use algorithms such as the Kalman filter to improve the results of our indoor location system. Regarding the location prediction system, using the transformers introduced by Vaswani et al. [
51] could improve its performance.


 ,
, 





{kind=link}
{kind=link}
{kind=link}