Abstract
Nearest neighbor (NN) and range (RN) queries are basic query types in spatial databases. In this study, we refer to collections of NN and RN queries as spatial proximity (SP) queries. At peak times, location-based services (LBS) need to quickly process SP queries that arrive simultaneously. Timely processing can be achieved by increasing the number of LBS servers; however, this also increases service costs. Existing solutions evaluate SP queries sequentially; thus, such solutions involve unnecessary distance calculations. This study proposes a unified batch algorithm (UBA) that can effectively process SP queries in dynamic spatial networks. With the proposed UBA, the distance between two points is indicated by the travel time on the shortest path connecting them. The shortest travel time changes frequently depending on traffic conditions. The goal of the proposed UBA is to avoid unnecessary distance calculations for nearby SP queries. Thus, the UBA clusters nearby SP queries and exploits shared distance calculations for query clusters. Extensive evaluations using real-world roadmaps demonstrated the superiority and scalability of UBA compared with state-of-the-art sequential solutions.
1. Introduction
This study investigates a unified batch approach to spatial proximity (SP) queries in dynamic spatial networks. In the investigated approach, the distance between two points is the travel time of the shortest path connecting them, and the shortest travel time frequently changes depending on traffic conditions, such as traffic volume and accidents. In this study, SP queries refer to a collection of nearest neighbor (NN) and range (RN) queries, which are basic query types in spatial databases. NN queries retrieve points of interest (POI), such as taxis and restaurants, closest to a query user [1,2], and RN queries retrieve POIs within a query distance [3,4,5]. Typically, location-based services (LBS), such as taxi-booking and ride-sharing services, use real-time spatial data to locate POIs close to the query user [6,7,8,9,10]. When multiple SP queries reach an LBS server simultaneously at peak times, if the SP queries are processed sequentially, it may not be possible to provide prompt responses to the query users. This difficulty can be addressed by increasing the number of LBS servers or by developing state-of-the-art algorithms based on “one-query-at-a-time processing” [3,11,12,13,14,15] to process the SP queries quickly.
SP queries have many potential applications in dynamic spatial networks, such as ride-hailing and car parking facilities. For example, in 2020, the ride-hailing company Uber accomplished an average of 18.7 million trips per day [16], demonstrating the significance of scalable and efficient solutions to promptly match Uber cabs with passengers. Another example is real-time parking management, which helps drivers find a parking space close to their destination.
Figure 1 shows two snapshots of SP queries in a dynamic spatial network, where a set Q of SP query points and a set P of data points are expressed as and , respectively. This study assumes that both the query points and data points run freely within the spatial network and that spatial segments often change their weights. In this example, and find the data points closest to and , respectively, and finds data points within a query distance (e.g., 4 km) to . As shown in Figure 1a, at timestamp , data point is the closest to both and , and data point is within 4 km of . However, as shown in Figure 1b, at timestamp , data points and are closest to and , respectively, and no data point is within 4 km of . A simple solution sequentially retrieves data points that satisfy the condition of each SP query in Q. However, this simple solution involves unnecessary network traversal, which can result in prohibitively high computational costs when a large number of SP queries reach the LBS server during peak hours [3,12,13,14,15]. Thus, we propose a unified batch algorithm (UBA) that can process SP queries in dynamic spatial networks effectively and efficiently.

Figure 1.
Snapshots of a set of SP queries, Q in a dynamic spatial network, where : (a) at time . (b) At time .
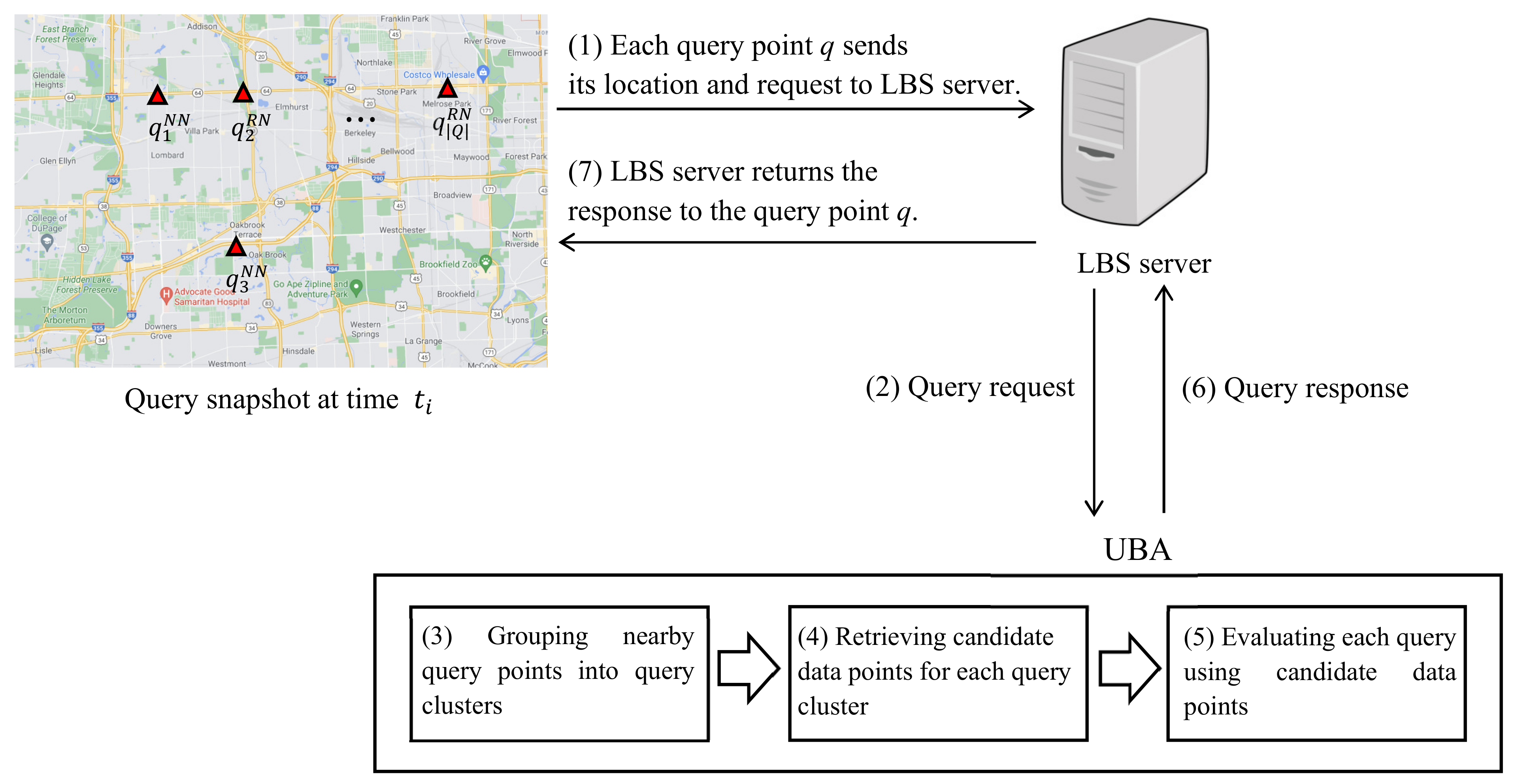
Figure 2 is a system diagram of the proposed UBA between query points and LBS server. Query points send their locations and query requests to the LBS server (step 1). The LBS server collects the requests from query points and forwards them to the UBA (step 2). The UBA first groups nearby query points into query clusters for shared computation (step 3). Then, UBA retrieves candidate data points for each query cluster to avoid unnecessary network traversals (step 4). UBA evaluates each query using the candidate data points for the query cluster (step 5) and returns query results to the LBS server (step 6). Finally, the LBS server provides the result to each query point (step 7).
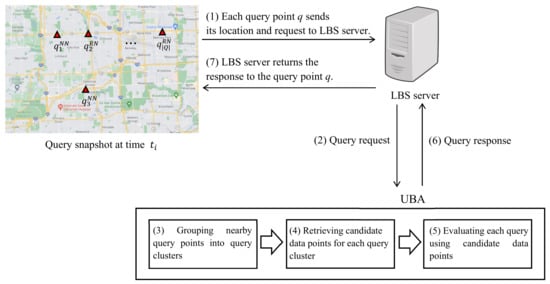
Figure 2.
System diagram of UBA between query points and LBS server.
All nearest neighbor (ANN) queries [17,18] are similar to SP queries. However, ANN queries assume that each query point q in Q only finds a single data point closest to q and, therefore does not consider RN queries. This study considers a highly dynamic situation in which both query and data points run freely within a dynamic spatial network [19,20,21]. The proposed UBA can effectively process SP queries in dynamic spatial networks. For simplicity, this study considers NN queries rather than kNN queries, which retrieve k data points closest to the query user for a positive integer k. However, UBA can easily be extended to process kNN queries.
The primary contributions of this study are summarized as follows.
- A unified batch processing algorithm, i.e., UBA, is proposed for the batch processing of SP queries in dynamic spatial networks. The performance of UBA highly depends on the distribution of query points. Thus, UBA clearly outperforms sequential algorithms when query points display a skewed distribution. Conversely, UBA shows similar performance to sequential algorithms when query points display a uniform distribution.
- Clustering of SP queries and their shared computation are presented to avoid unnecessary distance computations. The correctness of UBA is proved using a lemma. Furthermore, a theoretical analysis is presented to establish the advantage of UBA over sequential algorithms, particularly when query points display a skewed distribution.
- An empirical study is conducted under various conditions to demonstrate the superiority and scalability of UBA compared with a sequential algorithm.
The remainder of this paper is organized as follows. Section 2 reviews related studies. Section 3 introduces the necessary preliminaries, including a definition of the notations and symbols used in this study. Section 4 explains how to cluster nearby SP queries into query clusters and presents the proposed UBA for SP queries in dynamic spatial networks. Section 5 presents an empirical study of UBA compared to a conventional algorithm under various conditions. Conclusions and suggestions for future work are presented in Section 6.
2. Related Work
Researchers developed algorithms and index structures to evaluate spatial queries, including NN and RN queries for LBSs [6,22,23,24,25]. When calculating the length of the shortest path between two points, spatial queries for dynamic spatial networks suffer from high computational cost because graph traversal is required at runtime. Therefore, numerous studies attempt to reduce the computational cost of the shortest path distance, to avoid unnecessary shortest-path computations [6,22,23,24,25]. Incremental Euclidean restriction (IER) and incremental network expansion (INE) were developed for NN queries [3]. IER assumes that the shortest path between two points is larger than or equal to the Euclidean distance. INE explores the spatial network incrementally from the query point, as in Dijkstra’s algorithm, and investigates the data points in the encountered sequence. Range network expansion (RNE), which is similar to INE, was also developed for RN queries [3]. The route overlay and association directory method, ROAD [12], hierarchically divides the spatial network and pre-calculates the length of the shortest path between the border vertices within each partition. The distance-browsing method, DisBrw [13], exploits the spatially induced linkage cognizance index, and retains the length of the shortest path between each pair of vertices. G-tree [15] hierarchically divides the spatial network and uses an assembly based approach to compute the length of the shortest path between two vertices. V-tree [14] iteratively divides the spatial network into sub-networks and identifies the border vertices of each subnetwork. Then, the V-tree maintains a list of data points closest to each border vertex to quickly evaluate the kNN queries. A scalable and in-memory kNN query processing method called SIMkNN [26] was developed to quickly evaluate snapshot kNN queries over moving objects in a spatial network. The existing methods described in [6,22,23,24,25] are considered to be one-query-at-a-time processing algorithms because they aim to quickly evaluate a spatial query rather than a batch of spatial queries. This study is motivated by the observation that, with simple modifications, NN query processing algorithms can be applied to evaluate RN queries for spatial networks.
Multi-query optimization techniques were originally studied for relational database systems [27]. Their goal is to reduce the computational costs for a collection of queries that concurrently reach the database server by performing shared expressions once, materializing them temporarily, and then recycling them to evaluate other queries. Therefore, the subexpressions are typically evaluated once. These multi-query optimization techniques later expanded to involve query rewriting, query result caches, materialized views, and intermediate query results for relational database systems [28,29,30,31,32,33,34,35,36] and streaming processing systems [37,38,39]. Many applications involving high-load conditions have proven that batch processing algorithms can significantly reduce the query processing time for multiple simultaneous queries [19,30,31,32,33,34,35,36,37,38,39,40,41,42,43]. Furthermore, multi-query optimization techniques have received significant attention in spatial databases. Several batch shortest path algorithms also exist [19,40,41,42,43,44]. Furthermore, multi-query optimization techniques have received significant attention in spatial databases. Several batch shortest path algorithms [19,40,41,42,43,44] have been developed to efficiently evaluate multiple shortest path queries in spatial networks. However, these batch shortest path algorithms cannot be directly used to evaluate SP queries because of their diverse problem definitions. Several cache strategies for query results have been developed to efficiently process batches of kNN queries in spatial networks [6]. These strategies exploit the cached results of adjacent recently computed queries to efficiently process a batch of kNN queries. However, cache strategies have clear limitations in dynamic spatial networks, as their results may be invalidated by frequent updates to the weight of the spatial segments and by the movement of query points or data points. Finally, Li et al. [45,46,47,48,49] developed a series of algorithms for processing large complex networks, such as social networks. Specifically, they considered the trust management system based on game theory [47], dynamic clustering for electronic commerce systems [45], identifiability for the community detection [49], an optimal estimation of low-rank factors [48], and the identification of overlapping communities [46].
This work differs from existing studies in several respects. First, UBA considers SP queries in dynamic spatial networks. Second, UBA avoids dispensable network traversal by clustering SP queries and performing batch processing. Third, UBA can easily be incorporated into one-query-at-a-time processing algorithms for spatial networks [3,12,13,15].
3. Preliminaries
This section defines the terms and notations that are used in this paper.
Definition 1
(NN query [1,11,18,22,25]). Given a query point and a set of data points P, an NN query retrieves data point closest to such that dist holds for and .
Definition 2
(RN query [3,4,5]). Given a positive integer r, a query point , and a set of data points P, an RN query retrieves data points within query distance r to such that dist holds for .
Definition 3
(Spatial network [3,9,11,25,26,41,50,51]). A dynamic spatial network can be described as a dynamic weighted graph , where V, E, and W indicate the vertex set, edge set, and edge distance matrix, respectively. An edge has a nonnegative weight, e.g., travel time, and changes its weight frequently.
Definition 4
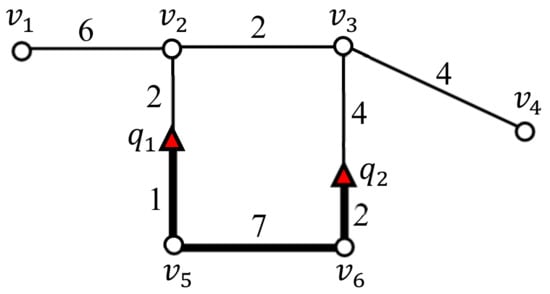
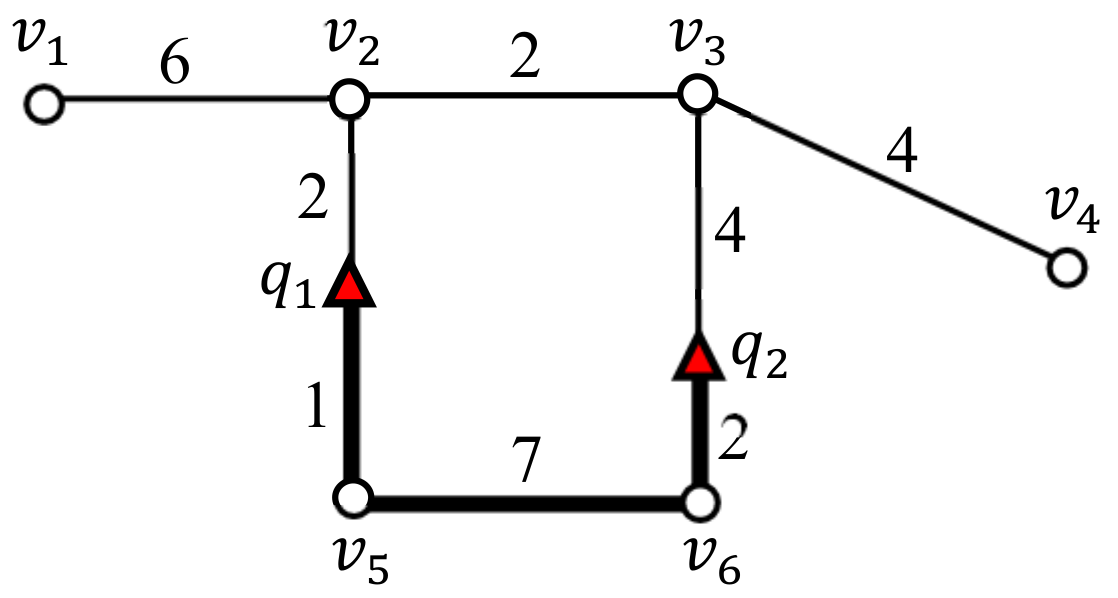
(Intersection, intermediate, and terminal vertices). In this study, vertices are categorized via their degree. In this study, vertices are categorized via their degree as follows: (1) if the degree of a vertex is greater than or equal to three, the vertex is an intersection vertex; (2) if the degree is two, the vertex is an intermediate vertex; (3) if the degree is one, the vertex is a terminal vertex. For example, and in Figure 3 are intersection vertices, and are intermediate vertices, and and are terminal vertices.
Figure 3.
Difference between and .
Definition 5
(Vertex sequence and segment). A vertex sequence denotes a segment connecting two vertices and such that and are either an intersection vertex or a terminal vertex, and the other vertices in the segment, i.e., , are intermediate vertices. The length of a vertex sequence is the total weight of the edges in the vertex sequence. Parts of a vertex sequence are referred to as segments. By definition, a vertex sequence is also a segment. For example, Figure 3 has four vertex sequences , , , and . Examples of query segments in Figure 3 include , and .
Table 1 summarizes the symbols and notations used in this study. Note that the query points are often used interchangeably to refer to SP queries. Figure 3 illustrates the difference between the distance and segment length between and in a spatial network. Here, the shortest path from to is , whose distance is equal to eight. The segment connecting and (marked with a bold line) is , and its length is equal to 10.

Table 1.
Definitions of symbols.
4. Batch Processing of SP Queries in Spatial Networks
4.1. Clustering Nearby SP Queries
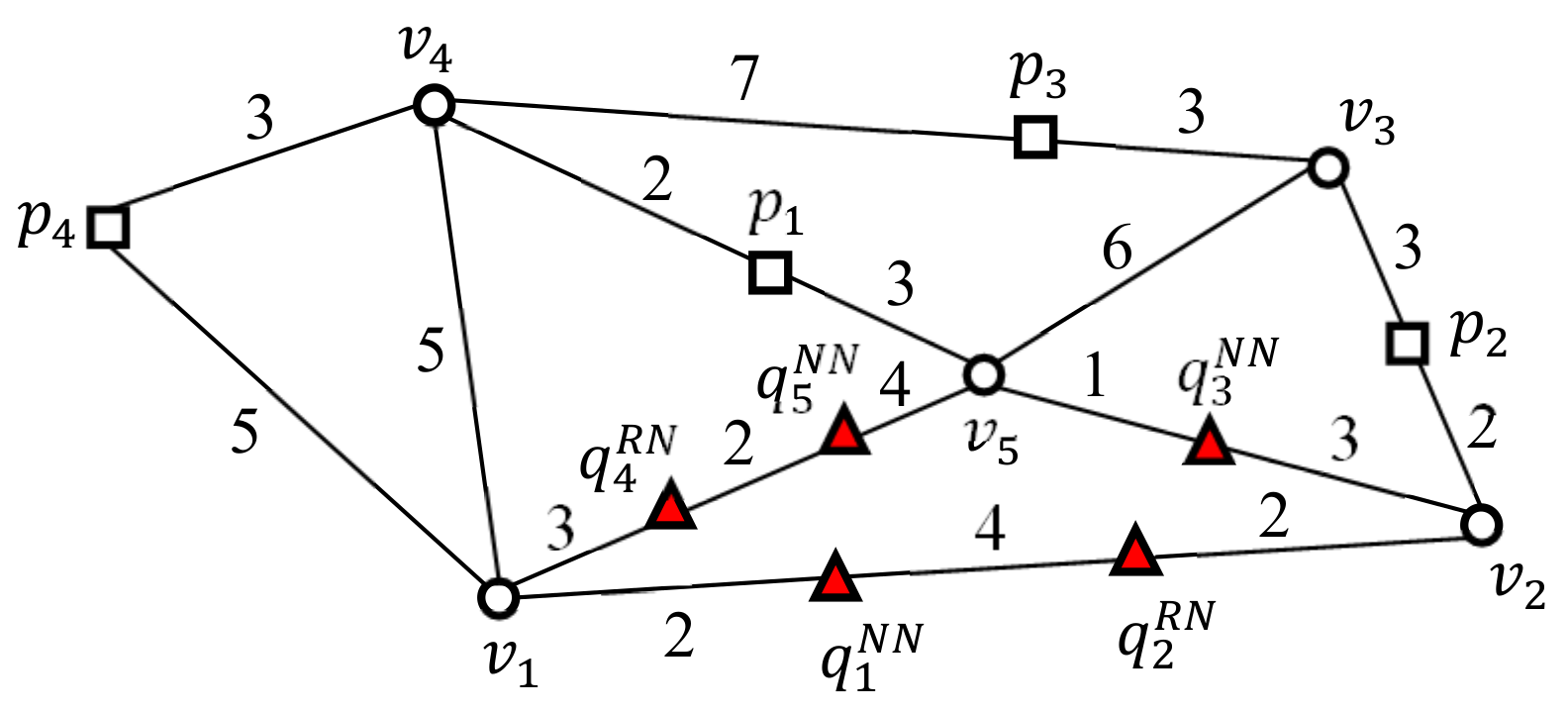
Here, we consider five SP queries , and in a spatial network (Figure 4). Assume that the NN queries , , and find a data point closest to themselves and that the RN queries and find data points within query distance ) to themselves.
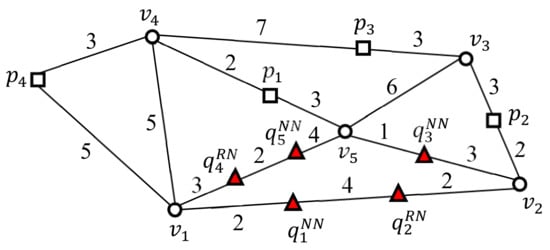
Figure 4.
Population comprising five SP queries and .
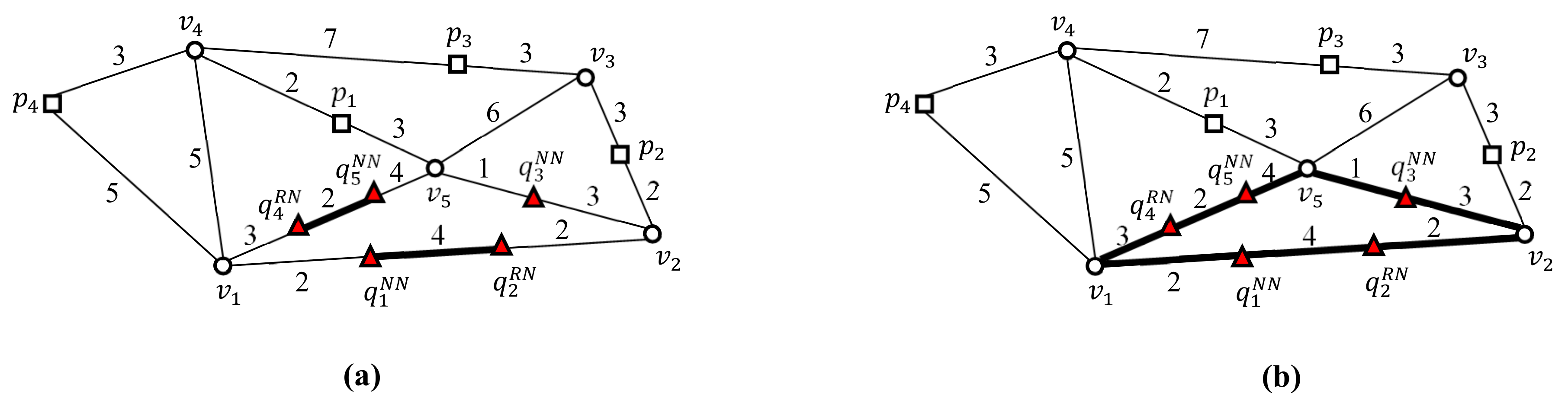
Figure 5 shows an example of the two-step clustering method, which converts nearby query points into a query cluster. In the first step, query points in a vertex sequence are connected to a query segment (Figure 5a). As a result, three query segments , , and are generated, where and connect two separate sets of query points, i.e., and and and , respectively, in vertex sequences and , respectively. In the second step, adjacent query segments are grouped into a query cluster using joint vertices (Figure 5b). The intersection vertex is referred to as a joint vertex when it is adjacent to greater than two query segments. As shown in Figure 5b, query segments and are adjacent to an intersection vertex , which becomes a joint vertex for and . Similarly, query segments, and are adjacent to intersection vertex , which becomes a joint vertex for and . Finally, query segments and are adjacent to intersection vertex , which becomes a joint vertex for and . Therefore, the three query segments, , , and are connected to a query cluster . In other words, the five query points and are clustered into query cluster . Note that is represented by a set of query segments. Consequently, a set of query points is converted into a set of query clusters .
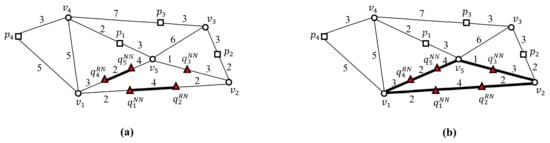
Figure 5.
Clustering nearby query points into a query cluster: (a) connecting query points in a vertex sequence into a query segment. (b) Clustering adjacent query segments into a query cluster using joint vertices.
Next, we define the border point of query cluster . Any point at which and its non-query cluster meet is referred to as the border point of . In this example, has three border points, i.e., , , and , where and its non-query cluster meet. Note that sequential solutions should evaluate the five SP queries shown in Figure 4. The two-step clustering method enables UBA to evaluate the three SP queries at border points , , and rather than at query points and .
Figure 6 illustrates the computation of the distance between query point q in query segment and data point p for the following cases: and . As shown in Figure 6a, when data point p is outside query segment , i.e., , the distance from q to p is given as because the shortest path between q and p is either or . As shown in Figure 6b, when p is inside , i.e., , the distance is given as because the shortest path between q and p is governed by one of the following three cases: , , or .

Figure 6.
Computation of the distance between query point q in query segment and data point p: (a) . (b) .
4.2. Unified Batch Processing Algorithm for SP Queries
Algorithm 1 provides the key concept of UBA for the unified batch processing of SP queries in a spatial network. Here, the result set is initially set to an empty set (line 1). Then, the nearby query points are first grouped into query clusters (lines 2 and 3), as discussed in Section 4.1. A Cluster search then is executed for each query cluster to perform batch processing of the SP queries in , and its query result is saved to (line 6). Then, the query cluster result is appended to , where and (line 7). When cluster_search (Algorithm 2) is performed for each query cluster in , UBA terminates by returning the query result (line 8).
| Algorithm 1 |
|
Algorithm 2 describes the cluster search algorithm employed to answer SP queries in query cluster . Here, cluster search performs batch execution for a query cluster to avoid dispensable network traversal. This algorithm runs in two steps. In the first step, the SP queries are evaluated at the border points of rather than at the query points in (lines 3–6). Note that an SP query is either an NN or RN query; thus, the type of spatial query must be determined, which is evaluated at a border point b. If a query cluster includes only NN queries, an NN query is evaluated at the border point b, i.e., . Similarly, if includes only RN queries, the function evaluates an RN query at border point b, i.e., . Finally, if includes both NN and RN queries, the function evaluates the SP query that finds all the data points satisfying the NN or RN conditions at border point b, i.e., . In the second step, a shared computation is performed for each query segment in using the candidate data points obtained at the border points of (lines 7–10). Here, each SP query in chooses qualified data points from the candidate data points in , where it is assumed that query segment belongs to segment in . When the segment_search (Algorithm 3) is performed for each query segment in , the cluster_search algorithm (Algorithm 2) terminates by returning the query result (line 11).
| Algorithm 2cluster_search |
|
| Algorithm 3segment_search |
|
Algorithm 3 describes the segment search algorithm employed to answer the SP queries in a query segment using the candidate data points in . Here, the batch query result for , i.e., , is initially set to an empty set (line 1). The distance between a query point q in and a candidate data point p, i.e., dist is then calculated (lines 5–9), as shown in Figure 6. When p is outside , i.e., , the distance from q to p is given as dist. When p is inside , i.e., , the distance from q to p is given as . If query point q is an NN query and candidate data point p is closer to q than the current NN , then p is appended to and is removed from , i.e., (lines 11–12). Similarly, if query point q is an RN query and is not greater than the query distance , then p is simply appended to , i.e., , where is the query distance of q (lines 13–14). The Segment_search algorithm (Algorithm 3) ends by returning the batch result for (line 16).
Lemma 1 proves the correctness of UBA, which means that each query point q in a query cluster can retrieve its qualified data points from the candidate data points for .
Lemma 1.
Each query point q in a query cluster can retrieve its qualified data points from the candidate data points for .
Proof.
We prove Lemma 1 by contradiction under the assumption that there exists a qualified data point p for query point q in such that p is not a candidate data point for . Clearly, set of candidate data points for is the union of set of data points inside and the SP query result at each border point of as follows: where it is assumed that . Clearly, this data point p must be outside . This is because as illustrated in Figure 6b, qualified data point p inside becomes a candidate data point for according to the definition of . When qualified data point p is outside as illustrated in Figure 6a, the following two cases should be considered: and . In the first case, i.e., ∧ , qualified data point p satisfies the range query ; however, it is not a candidate data point for . In the second case, i.e., , qualified data point p satisfies the NN query ; however, it is not a candidate data point for . The shortest path from to p should pass through a border point of . For convenience, assume that the shortest path from to p is where is a border point of . Note that the distance from to p is less than or equal to query distance r, i.e., . Thus, the distance from the border point to p is also less than or equal to r, i.e., . This leads to a contradiction to the assumption that the qualified data point p for is not a candidate data point for . Next, consider the second case that the qualified data point p for is not a candidate data point for . For convenience, assume that the shortest path from to p is and that a data point is the NN of rather than p. This means that is closer to than p, i.e., . Note that the shortest path from to p () is (). Thus, should be the NN of rather than p. This leads to a contradiction to the assumption that p is the NN of . Therefore, each query point q in a query cluster can retrieve its qualified data points from the candidate data points for . □
Table 2 compares the time complexities of UBA and sequential algorithms, such as INE [3] and RNE [3], for dynamic spatial networks. Note that UBA is independent of the one-query-at-a-time processing algorithms [3,11,12,13,14,15] and can be easily incorporated into these algorithms. For simplicity, INE and RNE are considered to evaluate a single SP query in dynamic spatial networks, and their time complexity is . UBA evaluates as many as SP queries, where is the number of query clusters in and M is the maximum number of border points in , i.e., . Conversely, sequential algorithms evaluate as many as SP queries because each query point should be handled individually. Thus, the time complexities of UBA and the sequential algorithms are and , respectively. The results of the time complexity analysis indicate that UBA is superior to sequential algorithms, particularly when , i.e., the query points exhibit a highly skewed distribution. In addition, the results demonstrate that UBA shows similar performance to sequential algorithms when , i.e., the query points exhibit a uniform distribution.
Table 2.
Comparison of time complexities of UBA and sequential algorithms.
4.3. Evaluation of Example SP Queries Using UBA
This section describes the process used to evaluate five example SP queries using UBA. As shown in Figure 5, the five SP queries , , , , and are grouped into a query cluster , whose border points are , , and . Clearly, a set of query points is transformed into a set of query clusters . Note that UBA evaluates only three SP queries at the border points of rather than the five query points , , , , and . Note that includes both the NN queries (, , and ) and RN queries ( and ); thus the results of the SP queries at the border points , , and should be , , and , respectively. Table 3 shows the results of the SP queries at the three border points , , and .
Table 3.
Computation of the SP queries at the border points.
The Segment_search algorithm (Algorithm 3) is called for each query segment in . For convenience, the three query segments , , and are processed sequentially. First, the Segment_search function evaluates the SP queries in with the candidate data points in . This function computes the distance between each pair of query points and in , and the candidate data points and . Table 4 summarizes the distances between each pair of query points q in query segment and their candidate data points p. Here, the SP query finds the data point closest to from the candidate data points and . Consequently, is the chosen NN of because is closer to than (Table 4). Similarly, the SP query locates data points within a query distance to . Accordingly, is included in the result of because and (Table 4). The query result for is .
Table 4.
Computation of the distances between the queries and the candidate data points.
Next, the segment_search function evaluates the SP queries in with the candidate data points in . First, the distance between each pair of query points and then candidate data points and is computed. Then, the SP query locates the data point that is closest to in and . Consequently, is the chosen NN of because is closer to than (Table 4). The query result for is .
Finally, the segment_search function evaluates the SP queries in using the candidate data points in . First, the distances between each pair of query points in and then the candidate data points and are calculated. The SP query locates the data points within a query distance to . No data points belong to the result set of because and (Table 4). The SP query identifies the data point that is closest to in and . Consequently, is the chosen NN of because is closer to than (Table 4). The query result for is . Clearly, the results of the SP queries in Q are the union of the results for the query segments in : .
5. Performance Study
In this section, the results from an empirical analysis of UBA are presented and compared with those of the conventional method [3]. The experimental settings are described in Section 5.1 and the experimental results are presented in Section 5.2.
5.1. Experimental Settings
Three real-world spatial networks [52] (Table 5) were used for the empirical study. These real-world spatial networks have different sizes and are part of the United States road network. For convenience, the extents of the spatial networks were normalized to a unit square , and the query distance r was set to . The query points followed a centroid distribution, and the data points followed either a centroid or uniform distribution. Here, centroid-based points were generated to mimic highly skewed distributions of POIs in the real world. First, the centroids were selected randomly based on the extent of the spatial networks, where is to the number of centroids. The points around each centroid followed a normal distribution, with the mean indicating the centroid, and the standard deviation was set to . A total of 1–10 centroids were selected as the query points, and five centroids were selected as the data points. The number of NN queries was the same as that of the RN queries for the SP queries. The experimental parameters are listed in Table 6. In each experiment, a single parameter was varied within the range, and the other parameters were maintained at their default values (shown in bold).
Table 5.
Real-world roadmaps.
Table 6.
Experimental parameter settings.
Next, the proposed UBA was compared in terms of query processing time and the number of evaluated SP queries to a sequential algorithm called SEQ, which computes SP queries sequentially. Here, it was assumed that the query and data points moved freely within the dynamic spatial networks. Note that it is impractical to exploit the precomputation techniques presented in the literature [12,13,15] because the precomputed distances might be invalidated frequently when the query and data points run freely within a dynamic spatial network. UBA and SEQ use common subroutines for similar tasks, e.g., the evaluation of SP queries at a single query point; thus, both algorithms were implemented in C++ using the Microsoft Visual Studio 2019 development environment. The experiments were executed on a desktop computer running the Windows 10 operating system with 32 GB RAM and a 3.1 GHz processor (i9-9900). As in many recent studies [11,26,53], the indexing structures for UBA and SEQ remained in main memory to provide prompt responses, which are crucial in online map services. The experiments were repeated 10 times, and the average processing time was measured to determine the SP queries in Q. As stated previously, the proposed UBA is orthogonal to one-query-at-a-time processing algorithms [3,11,12,13,14,15] and can be easily incorporated into these algorithms. In this study, INE [3] and RNE [3] were used to evaluate the NN and RN queries, respectively, for the dynamic spatial networks because INE and RNE are based on network expansion similar to Dijkstra’s algorithm, which is well-suited to dynamic spatial networks.
5.2. Experimental Results
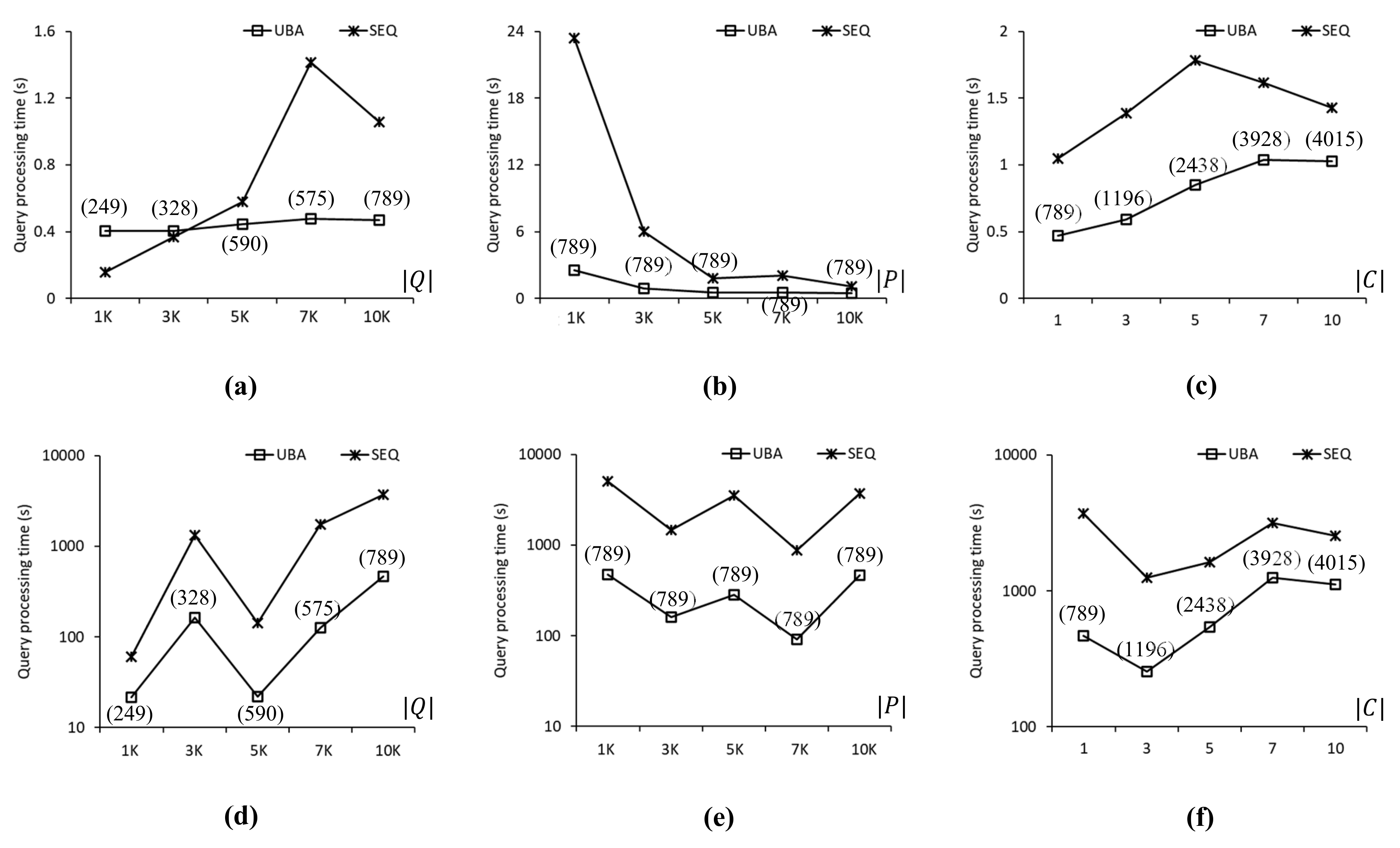
Figure 7 compares the query processing times of UBA and SEQ to evaluate the SP queries in the CAL roadmap. In Figure 7, Figure 8 and Figure 9, the three upper-row and three bottom-row charts show the experimental results when the data points followed a uniform distribution and a centroid distribution, respectively. Each chart shows the query processing time and number of evaluated SP queries by varying one parameter at a time (Table 6). The values in parentheses in Figure 7, Figure 8, Figure 9 and Figure 10 indicate the number of SP queries evaluated by the proposed UBA. Note that the numbers of SP queries evaluated by SEQ were omitted because these numbers were exactly equal to of the SP queries in Q. Figure 7a shows the query processing times of UBA and SEQ when of the query points was between 1 K and 10 K, i.e., . As can be seen, the proposed UBA clearly outperformed SEQ as the number of SP queries in Q increased. In terms of query processing times, UBA was up to 2.9 times faster than SEQ for . However, UBA was up to 2.59 times slower than SEQ for . Note that the proposed UBA was not sensitive to , unlike SEQ, which means that the effectiveness of batch processing in UBA increased as increased. When , , , , and , UBA evaluated fewer SP queries than SEQ by 75%, 89%, 88%, 91%, and 92%, respectively. Figure 7b shows the query processing times when of data points was varied between 1 K and 10 K, i.e., . Thus, UBA clearly outperformed SEQ in all cases. The query processing times of UBA were up to 8.9 times lower than those of SEQ when . As the value decreased, the search space for the NN query processing increased. Regardless of the change in , UBA and SEQ evaluated 789 and 10,000 SP queries, respectively. Figure 7c shows the query processing times when of the centroids for the query points was varied between 1 and 10, i.e., . The proposed UBA was up to 2.3 times faster than SEQ for all cases. As increased, the difference in query processing times between UBA and SEQ decreased because increasing led to a reduced density of the query points, which resulted in an increased value. Specifically, when 1, 3, 5, 7, and 10, UBA evaluated 789, 1196, 2438, 3928, and 4015 SP queries, respectively, whereas SEQ evaluated 10 K SP queries for all these cases.
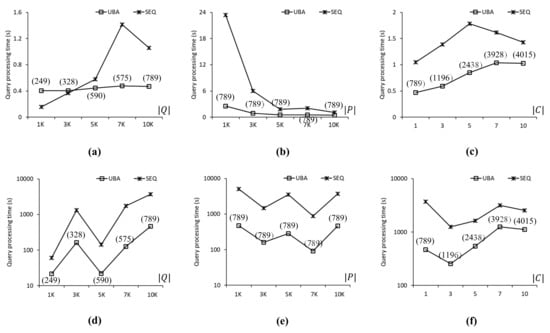
Figure 7.
Comparison of query processing times for the CAL roadmap: (a) . (b) . (c) . (d) . (e) . (f) .
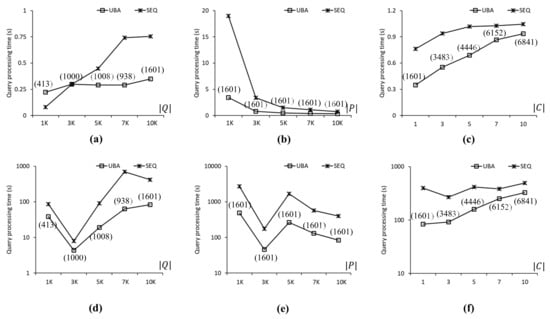
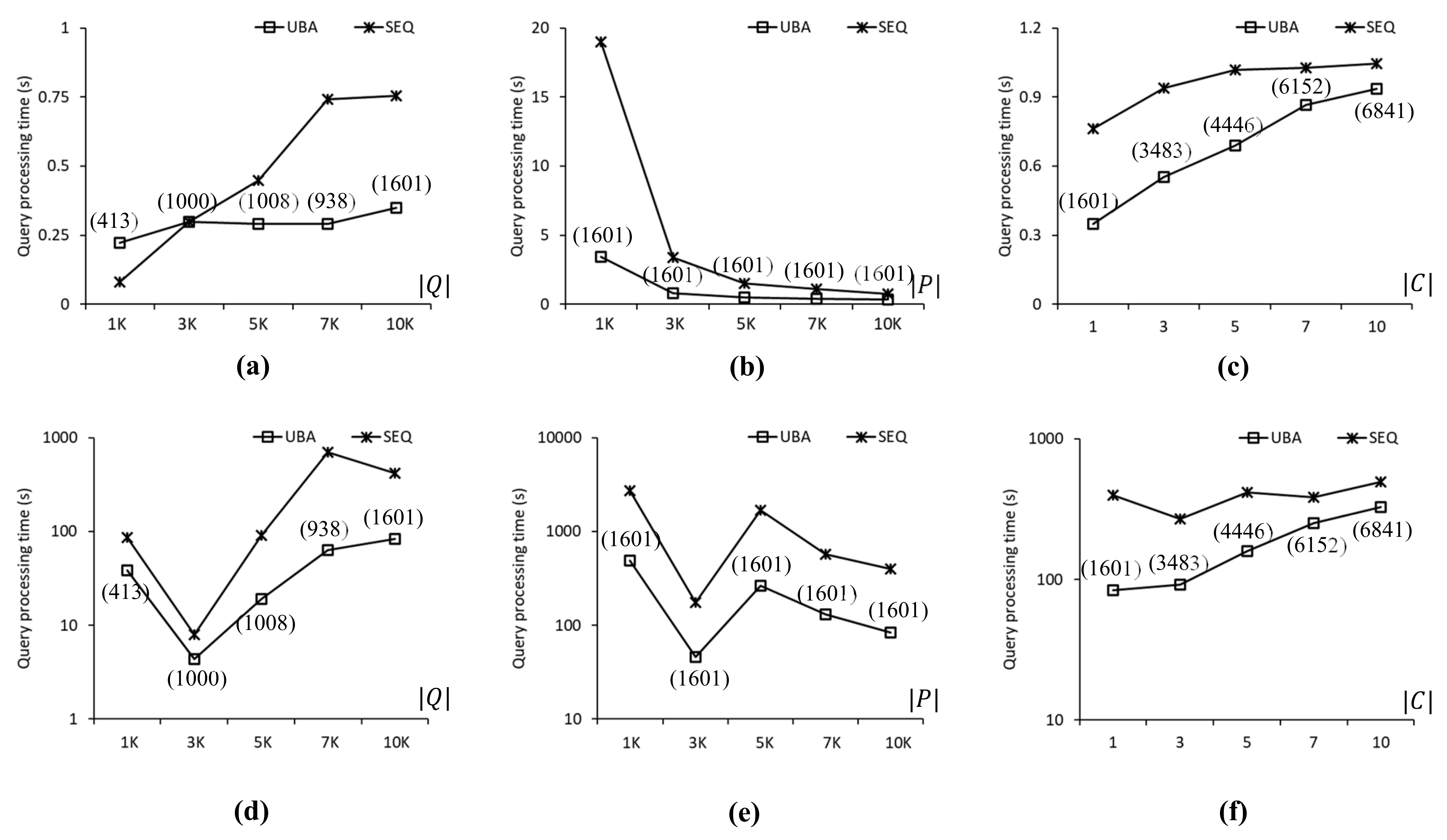
Figure 8.
Comparison of query processing times for the FLA roadmap: (a) . (b) . (c) . (d) . (e) . (f) .
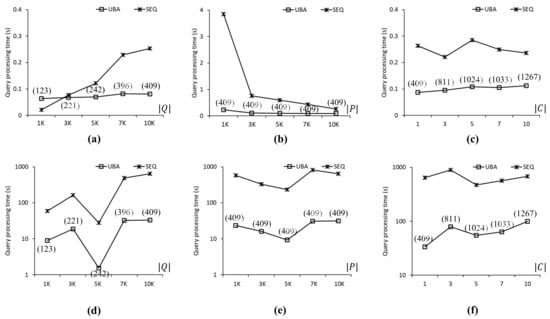
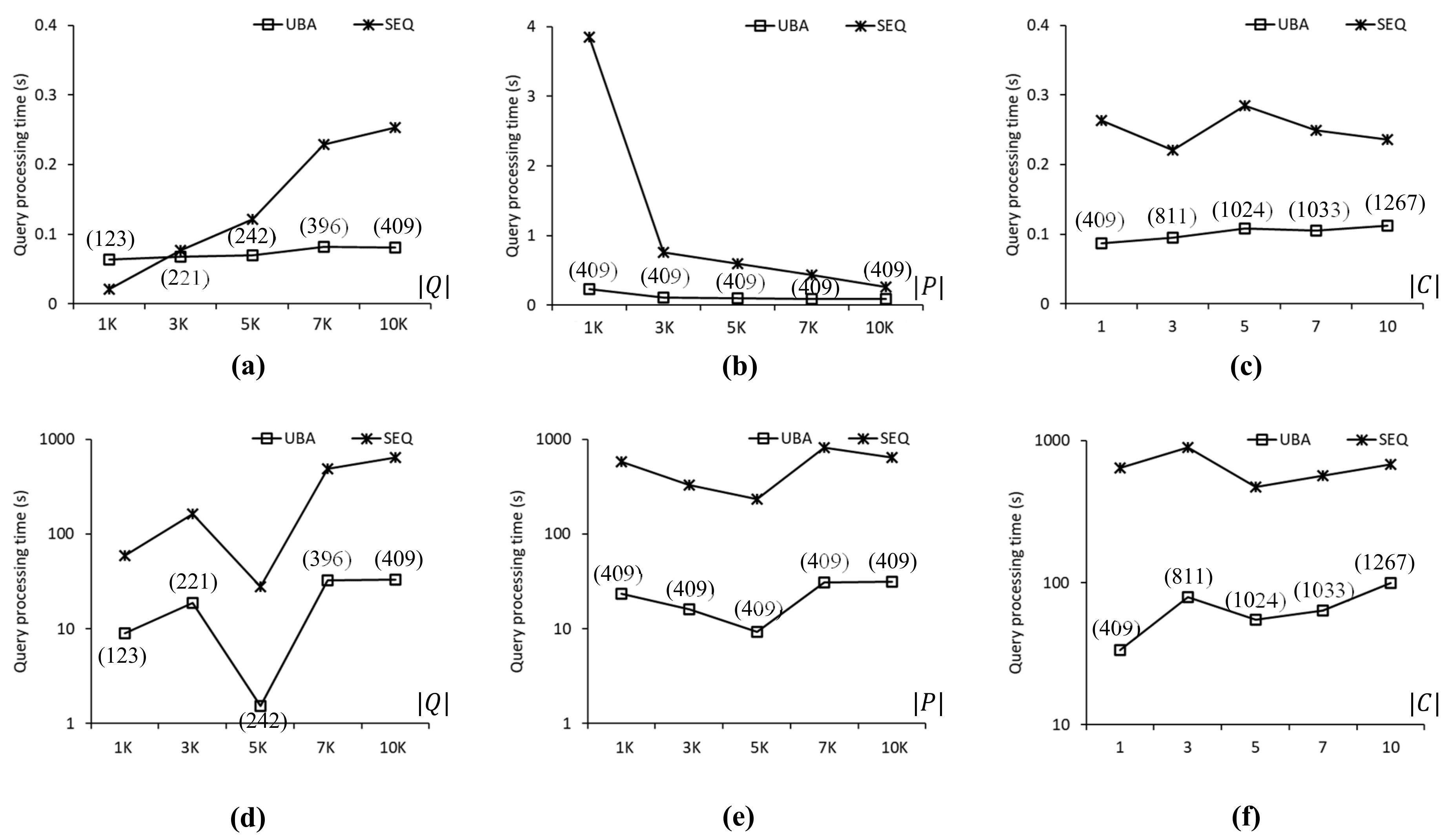
Figure 9.
Comparison of query processing times for the COL roadmap: (a) . (b) . (c) . (d) . (e) . (f) .
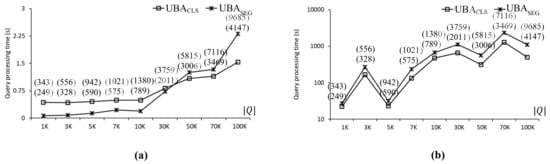
Figure 10.
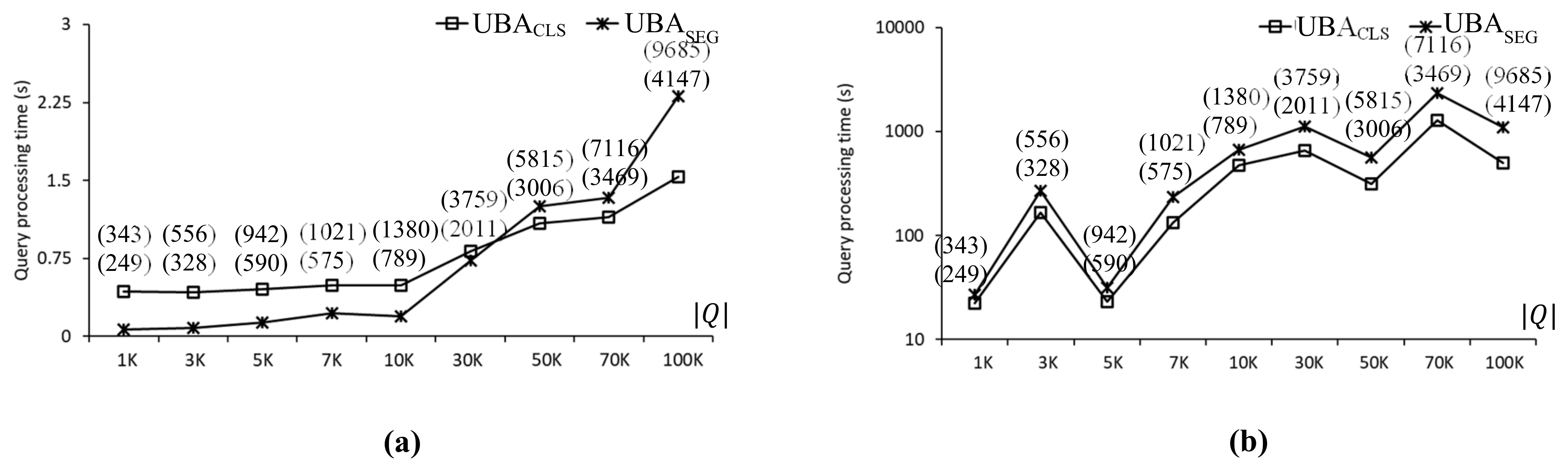
Effect of two-step clustering on the CAL roadmap: (a) uniform data points. (b) Skewed data points.
Figure 7d–f show the query processing times of UBA and SEQ when the data points followed a centroid distribution. The query processing times of the proposed UBA were up to 18.95 times lower than those of SEQ for all cases. Unlike the case shown in Figure 7a, the query processing times of UBA and SEQ did not increase with , as shown in Figure 7d, which means that the query processing time was more sensitive to the distribution of data points than when the data points followed a highly skewed distribution. When , , , , and , the query processing times of UBA were 21.7, 162.8, 21.9, 126.8, and 468.7 s, respectively. As shown in Figure 7d–f, UBA was faster than SEQ in all cases. The difference in query processing times between UBA and SEQ for a centroid distribution of data points was up to several orders of magnitude greater than that for a uniform distribution of data points.
Figure 8 compares the query processing times obtained when using UBA and SEQ to evaluate the SP queries in the FLA roadmap. Figure 8a shows the query processing time as a function of . We found that the proposed UBA was up to 2.2 times faster than SEQ for . However, SEQ was 2.7 times faster than UBA for because the batch processing of UBA was for a large number rather than a small number of SP queries. Figure 8b shows the query processing time as a function of . UBA was 5.5 and 2.2 times faster than SEQ for and , respectively, even though UBA and SEQ evaluated 1601 and 10,000 SP queries, respectively, for these two cases. This is because the search space for the NN queries when was greater than that when . Figure 8c shows the query processing time as a function of , which, for UBA was up to 2.1 times shorter than that of SEQ in all cases. Clearly, the number of query clusters increased with , which adversely affected the performance of the proposed UBA. As shown in Figure 8d–f, UBA was up to 11 times faster than SEQ in all cases. The query processing times of both UBA and SEQ fluctuated, which means that the distribution of highly skewed data points affected the NN query processing time significantly. Specifically, as shown in Figure 8d, the query processing time of UBA for was 8.9 times longer than that for despite the difference in the number of SP queries in Q.
Figure 9 compares the query processing times obtained using UBA and SEQ with the COL roadmap. As shown in Figure 9a, the proposed UBA was up to 3.1 times faster than SEQ when . Here, as increased, UBA was superior to SEQ. As shown in Figure 9b, UBA was up to 16.3 times faster than SEQ regardless of the value because UBA and SEQ evaluated 409 and 10,000 SP queries, respectively. Clearly, this difference in the number of evaluated SP queries (i.e., 9591) occurred the proposed UBA can exploit the batch processing of the clustered SP queries; thus, unnecessary distance computations can be avoided. As shown in Figure 9c, UBA clearly outperformed SEQ in all cases of . As increased, the density of the query points decreased, which was ineffective for the batch processing of UBA. As shown in Figure 9d–f, UBA was up to 26.6 times faster than SEQ in all cases. As shown in Figure 9d, the query processing times of UBA and SEQ fluctuated significantly because the highly skewed distributions of data points affected the search space of the NN queries significantly.
Two versions of UBA, i.e., and , were implemented and evaluated to investigate the effect of the two-step clustering method on the batch processing of UBA and its scalability in terms of . transforms nearby query points into query segments, and transforms nearby query points into query clusters. and are illustrated in Figure 5a,b, respectively. Figure 10 compares the query processing times using and with the CAL roadmap, where the two values in the parentheses indicate the number of SP queries evaluated by and , respectively. As can be seen, the number of SP queries evaluated by was greater than that of . As shown in Figure 10a, when the data points exhibited a uniform distribution, was up to 6.1 times faster than for . However, as increased, was faster than , which means that scaled better than with . Specifically, was 1.5 times faster than for . As shown in Figure 10b, when the data points exhibited a centroid distribution, was up to 2.2 times faster than in all cases. Therefore, scaled with better than . It is clear that the distribution of data points affected query processing time significantly. Specifically, when the data points exhibited uniform and centroid distributions, the query processing times of were 1.5 and 497.7 s, respectively, for .
6. Conclusions
This paper has proposed the UBA to efficiently process SP queries comprising NN and RN queries in dynamic spatial networks. The goal of the proposed UBA is to avoid dispensable distance computations during batch processing. Accordingly, UBA performs two-step clustering of SP queries and their batch processing to reduce the number of SP queries evaluated for query clusters. The experimental results have confirmed that the proposed UBA outperformed a conventional algorithm based on one-query-at-a-time processing and scaled well with the number of queries. We found that the proposed UBA was up to 26.6 times faster than the compared conventional algorithm. The proposed UBA has several advantages. First, UBA avoids dispensable network traversal by clustering SP queries and performing batch processing. Second, UBA can easily be incorporated into one-query-at-a-time processing algorithms for spatial networks [3,12,13,15]. However, the proposed UBA also exhibits a disadvantage, i.e., its performance is very sensitive to the distribution of query points. Thus, UBA demonstrates similar performance to that of sequential algorithms, particularly when the query points exhibit a uniform distribution. The proposed UBA clearly outperforms sequential algorithms when the query points exhibit a highly skewed distribution. In future, we plan to apply this unified batch solution to extremely large spatial networks for distributed batch processing of sophisticated spatial queries, e.g., spatial join queries [54] and spatial keyword queries [2,50].
Funding
This research was supported by Basic Science Research Program through the National Research Foundation of Korea(NRF) funded by the Ministry of Education (NRF-2020R1I1A3052713).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Mouratidis, K.; Yiu, M.L.; Papadias, D.; Mamoulis, N. Continuous nearest neighbor monitoring in road networks. In Proceedings of the International Conference on Very Large Data Bases, Seoul, Korea, 12–15 September 2006; pp. 43–54. [Google Scholar]
- Zheng, B.; Zheng, K.; Xiao, X.; Su, H.; Yin, H.; Zhou, X.; Li, G. Keyword-aware continuous knn query on road networks. In Proceedings of the International Conference on Data Engineering, Helsinki, Finland, 16–20 May 2016; pp. 871–882. [Google Scholar]
- Papadias, D.; Zhang, J.; Mamoulis, N.; Tao, Y. Query processing in spatial network databases. In Proceedings of the International Conference on Very Large Data Bases, Berlin, Germany, 9–12 September 2003; pp. 802–813. [Google Scholar]
- Taniar, D.; Rahayu, W. A taxonomy for region queries in spatial databases. J. Comput. Syst. Sci. 2015, 81, 1508–1531. [Google Scholar] [CrossRef]
- Zacharatou, E.T.; Sidlauskas, D.; Tauheed, F.; Heinis, T.; Ailamaki, A. Efficient bundled spatial range queries. In Proceedings of the International Conference on Advances in Geographic Information Systems, Chicago, IL, USA, 5–8 November 2019; pp. 139–148. [Google Scholar]
- Huang, X.; Jensen, C.S.; Saltenis, S. Multiple k nearest neighbor query processing in spatial network databases. In Proceedings of the European Conference on Advances in Databases and Information Systems, Thessaloniki, Greece, 3–7 September 2006; pp. 266–281. [Google Scholar]
- Liu, Y.; Peng, M.; Shou, G. Mobile edge computing-enhanced proximity detection in time-aware road networks. IEEE Access 2019, 7, 167958–167972. [Google Scholar] [CrossRef]
- Miao, X.; Gao, Y.; Mai, G.; Chen, G.; Li, Q. On efficiently monitoring continuous aggregate k nearest neighbors in road networks. IEEE Trans. Mob. Comput. 2020, 19, 1664–1676. [Google Scholar] [CrossRef]
- Ouyang, D.; Wen, D.; Qin, L.; Chang, L.; Zhang, Y.; Lin, X. Progressive top-k nearest neighbors search in large road networks. In Proceedings of the International Conference on Management of Data, Portland, OR, USA, 14–19 June 2020; pp. 1781–1795. [Google Scholar]
- Tang, X.; Chai, M.; Chen, X.; Chen, W. Spatio-temporal reachable area calculation based on urban traffic data. IEEE Syst. J. 2021, 15, 641–652. [Google Scholar] [CrossRef]
- Abeywickrama, T.; Cheema, M.A.; Taniar, D. k-Nearest neighbors on road networks: A journey in experimentation and in-memory implementation. Proc. VLDB Endow. 2016, 9, 492–503. [Google Scholar] [CrossRef]
- Lee, K.C.K.; Lee, W.-C.; Zheng, B.; Tian, Y. ROAD: A new spatial object search framework for road networks. IEEE Trans. Knowl. Data Eng. 2012, 24, 547–560. [Google Scholar] [CrossRef]
- Samet, H.; Sankaranarayanan, J.; Alborzi, H. Scalable network distance browsing in spatial databases. In Proceedings of the International Conference on Mobile Data Management, Beijing, China, 27–30 April 2008; pp. 43–54. [Google Scholar]
- Shen, B.; Zhao, Y.; Li, G.; Zheng, W.; Qin, Y.; Yuan, B.; Rao, Y. V-tree: Efficient knn search on moving objects with road-network constraints. In Proceedings of the International Conference on Data Engineering, San Diego, CA, USA, 19–22 April 2017; pp. 609–620. [Google Scholar]
- Zhong, R.; Li, G.; Tan, K.-L.; Zhou, L.; Gong, Z. G-tree: An efficient and scalable index for spatial search on road networks. IEEE Trans. Knowl. Data Eng. 2015, 27, 2175–2189. [Google Scholar] [CrossRef]
- Uber Revenue and Usage Statistics. Available online: https://www.businessofapps.com/data/uber-statistics/ (accessed on 22 July 2021).
- Xu, Y.; Qi, J.; Borovica-Gajic, R.; Kulik, L. Finding all nearest neighbors with a single graph traversal. In Proceedings of the International Conference on Database Systems for Advanced Applications, Gold Coast, Australia, 21–24 May 2018; pp. 221–238. [Google Scholar]
- Zhang, J.; Mamoulis, N.; Papadias, D.; Tao, Y. All-nearest-neighbors queries in spatial databases. In Proceedings of the International Conference on Scientific and Statistical Database Management, Santorini Island, Greece, 21–23 June 2004; pp. 297–306. [Google Scholar]
- Li, L.; Zhang, M.; Hua, W.; Zhou, X. Fast query decomposition for batch shortest path processing in road networks. In Proceedings of the International Conference on Data Engineering, Dallas, TX, USA, 20–24 April 2020; pp. 1189–1200. [Google Scholar]
- Wang, Y.; Li, G.; Tang, N. Querying shortest paths on time dependent road networks. Proc. VLDB Endow. 2019, 12, 1249–1261. [Google Scholar] [CrossRef] [Green Version]
- Wei, V.J.; Wong, R.C.-W.; Long, C. Architecture-intact oracle for fastest path and time queries on dynamic road networks. In Proceedings of the International Conference on Management of Data, Portland, OR, USA, 14–19 June 2020; pp. 1841–1856. [Google Scholar]
- Dong, T.; Lulu, Y.; Shang, Y.; Ye, Y.; Zhang, L. Direction-aware continuous moving k-nearest-neighbor query in road networks. ISPRS Int. J. Geo Inf. 2019, 8, 379. [Google Scholar] [CrossRef] [Green Version]
- Luo, S.; Kao, B.; Li, G.; Hu, J.; Cheng, R.; Zheng, Y. TOAIN: A throughput optimizing adaptive index for answering dynamic knn queries on road networks. Proc. VLDB Endow. 2018, 11, 594–606. [Google Scholar] [CrossRef]
- Yang, Y.; Li, H.; Wang, J.; Hu, Q.; Wang, X.; Leng, M. A novel index method for k nearest object query over time-dependent road networks. Complexity 2019, 2019, 4829164. [Google Scholar] [CrossRef]
- Abeywickrama, T.; Cheema, M.A. Efficient landmark-based candidate generation for knn queries on road networks. In Proceedings of the International Conference on Database Systems for Advanced Applications, Suzhou, China, 27–30 March 2017; pp. 425–440. [Google Scholar]
- Cao, B.; Hou, C.; Li, S.; Fan, J.; Yin, J.; Zheng, B.; Bao, J. SIMkNN: A scalable method for in-memory knn search over moving objects in road networks. IEEE Trans. Knowl. Data Eng. 2018, 30, 1957–1970. [Google Scholar] [CrossRef]
- Sellis, T.K. Multiple-query optimization. ACM Trans. Database Syst. 1988, 13, 23–52. [Google Scholar] [CrossRef]
- Eslami, M.; Tu, Y.; Charkhgard, H.; Xu, Z.; Liu, J. PsiDB: A framework for batched query processing and optimization. In Proceedings of the International Conference on Big Data, Los Angeles, CA, USA, 9–12 December 2019; pp. 6046–6048. [Google Scholar]
- Giannikis, G.; Alonso, G.; Kossmann, D. SharedDB: Killing one thousand queries with one stone. Proc. VLDB Endow. 2012, 5, 526–537. [Google Scholar] [CrossRef]
- Giannikis, G.; Makreshanski, D.; Alonso, G.; Kossmann, D. Shared workload optimization. Proc. VLDB Endow. 2014, 7, 429–440. [Google Scholar] [CrossRef] [Green Version]
- Makreshanski, D.; Giannikis, G.; Alonso, G.; Kossmann, D. MQJoin: Efficient shared execution of main-memory joins. Proc. VLDB Endow. 2016, 9, 480–491. [Google Scholar] [CrossRef]
- Makreshanski, D.; Giannikis, G.; Alonso, G.; Kossmann, D. Many-query join: Efficient shared execution of relational joins on modern hardware. VLDB J. 2018, 27, 669–692. [Google Scholar] [CrossRef]
- Marroquin, R.; Müller, I.; Makreshanski, D.; Alonso, G. Pay one, get hundreds for free: Reducing cloud costs through shared query execution. In Proceedings of the Symposium on Cloud Computing, Carlsbad, CA, USA, 11–13 October 2018; pp. 439–450. [Google Scholar]
- Michiardi, P.; Carra, D.; Migliorini, S. In-memory caching for multi-query optimization of data-intensive scalable computing workloads. In Proceedings of the Workshops of the EDBT/ICDT Joint Conference, Lisbon, Portugal, 26 March 2019. [Google Scholar]
- Psaroudakis, I.; Athanassoulis, M.; Ailamaki, A. Sharing data and work across concurrent analytical queries. Proc. VLDB Endow. 2013, 6, 637–648. [Google Scholar] [CrossRef] [Green Version]
- Rehrmann, R.; Binnig, C.; Böhm, A.; Kim, K.; Lehner, W.; Rizk, A. OLTPShare: The case for sharing in oltp workloads. Proc. VLDB Endow. 2018, 11, 1769–1780. [Google Scholar] [CrossRef] [Green Version]
- Jonathan, A.; Chandra, A.; Weissman, J.B. Multi-query optimization in wide-area streaming analytics. In Proceedings of the Symposium on Cloud Computing, Carlsbad, CA, USA, 11–13 October 2018; pp. 412–425. [Google Scholar]
- Karimov, J.; Rabl, T.; Markl, V. AStream: Ad-hoc shared stream processing. In Proceedings of the International Conference on Management of Data, Amsterdam, The Netherlands, 30 June–5 July 2019; pp. 607–622. [Google Scholar]
- Karimov, J.; Rabl, T.; Markl, V. AJoin: Ad-hoc stream joins at scale. Proc. VLDB Endow. 2019, 13, 435–448. [Google Scholar] [CrossRef]
- Mahmud, H.; Amin, A.M.; Ali, M.E.; Hashem, T.; Nutanong, S. A group based approach for path queries in road networks. In Proceedings of the International Symposium on Advances in Spatial and Temporal Databases, Munich, Germany, 21–23 August 2013; pp. 367–385. [Google Scholar]
- Reza, R.M.; Ali, M.E.; Hashem, T. Group processing of simultaneous shortest path queries in road networks. In Proceedings of the International Conference on Mobile Data Management, Pittsburgh, PA, USA, 15–18 June 2015; pp. 128–133. [Google Scholar]
- Zhang, M.; Li, L.; Hua, W.; Zhou, X. Efficient batch processing of shortest path queries in road networks. In Proceedings of the International Conference on Mobile Data Management, Hong Kong, China, 10–13 June 2019; pp. 100–105. [Google Scholar]
- Zhang, M.; Li, L.; Hua, W.; Zhou, X. Batch processing of shortest path queries in road networks. In Proceedings of the Australasian Database Conference on Databases Theory and Applications, Sydney, Australia, 29 January–1 February 2019; pp. 3–16. [Google Scholar]
- Thomsen, J.R.; Yiu, M.L.; Jensen, C.S. Effective caching of shortest paths for location-based services. In Proceedings of the International Conference on Management of Data, Scottsdale, AZ, USA, 20–24 May 2012; pp. 313–324. [Google Scholar]
- Li, H.-J.; Bu, Z.; Wang, Z.; Cao, J. Dynamical clustering in electronic commerce systems via optimization and leadership expansion. IEEE Trans. Ind. Inform. 2020, 16, 5327–5334. [Google Scholar] [CrossRef]
- Li, H.-J.; Zhang, J.; Liu, Z.-P.; Chen, L.; Zhang, X.-S. Identifying overlapping communities in social networks using multi-scale local information expansion. Eur. Phys. J. B 2012, 85, 190. [Google Scholar] [CrossRef]
- Li, H.-J.; Wang, Q.; Liu, S.; Hu, J. Exploring the trust management mechanism in self-organizing complex network based on game theory. Phys. A Stat. Mech. Appl. 2020, 542, 123514. [Google Scholar] [CrossRef]
- Li, H.-J.; Wang, Z.; Pei, J.; Cao, J.; Shi, Y. Optimal estimation of low-rank factors via feature level data fusion of multiplex signal systems. IEEE Trans. Knowl. Data Eng. 2020. [Google Scholar] [CrossRef]
- Li, H.-J.; Wang, L.; Zhang, Y.; Perc, M. Optimization of identifiability for efficient community detection. New J. Phys. 2020, 22, 063035. [Google Scholar] [CrossRef]
- Attique, M.; Afzal, M.; Ali, F.; Mehmood, I.; Ijaz, M.F.; Cho, H.-J. Geo-social top-k and skyline keyword queries on road networks. Sensors 2020, 20, 798. [Google Scholar] [CrossRef] [Green Version]
- Cho, H.-J.; Attique, M. Group processing of multiple k-farthest neighbor queries in road networks. IEEE Access 2020, 8, 110959–110973. [Google Scholar] [CrossRef]
- 9th DIMACS Implementation Challenge: Shortest Paths. Available online: http://www.dis.uniroma1.it/challenge9/download.shtml (accessed on 22 July 2021).
- Wu, L.; Xiao, X.; Deng, D.; Cong, G.; Zhu, A.D.; Zhou, S. Shortest path and distance queries on road networks: An experimental evaluation. Proc. VLDB Endow. 2012, 5, 406–417. [Google Scholar] [CrossRef]
- Corral, A.; Manolopoulos, Y.; Theodoridis, Y.; Vassilakopoulos, M. Multi-way distance join queries in spatial databases. GeoInformatica 2004, 8, 373–402. [Google Scholar] [CrossRef]

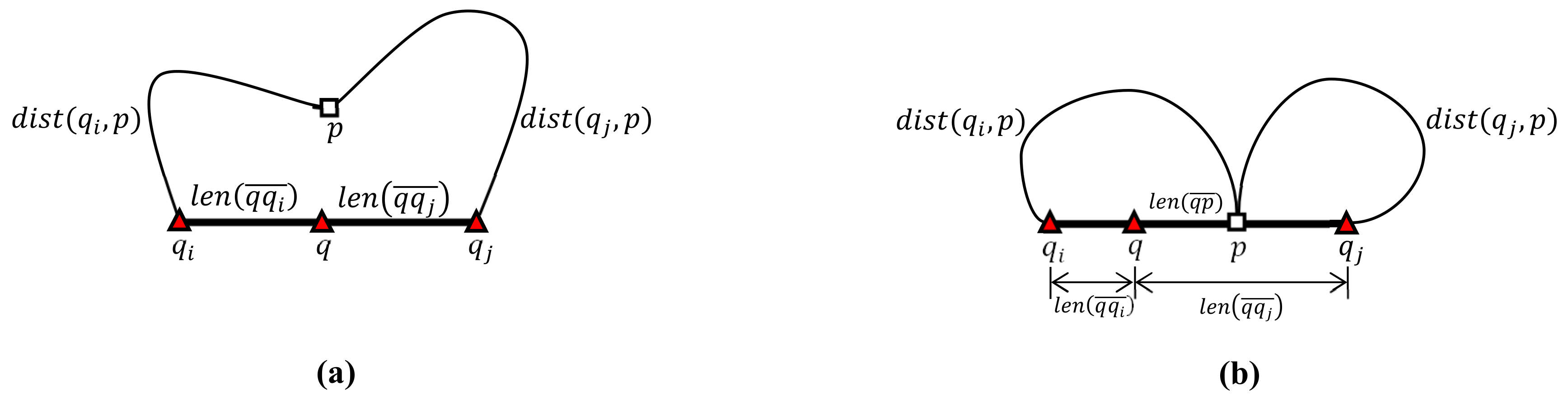
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).