1. Introduction
In recent decades, technological advancements have led to the implementation and diffusion of Wearable Health Devices (WHDs). These devices can measure and acquire, in real time and without using bulky equipment, clinical information about a human user, such as: (i) ElectroCardioGram (ECG), (ii) blood pressure, (iii) respiration wave, (iv) heart rate and many other parameters. Moreover, the implementation of these devices using the Internet-of-Things (IoT) paradigm with smart sensor networks and wireless communication protocols have led to the uprising of Internet-of-Medical-Things (IoMT). There are several technological challenges to face when dealing with IoMT systems, mainly because typically these devices (i.e., WHD nodes) are battery powered and have to meet strict energy consumption and size requirements. Furthermore, the presence of a large number of WHD nodes in a network results in a significant quantity of data to be acquired, transmitted and stored. In order to deal with these challenges, the state of the art proposes data compression techniques, so as to reduce the amount of acquired data that have to be transmitted to the sink node. In fact, data transmission represents the most expensive activity in terms of energy consumption for an IoMT node [
1]. In particular, the transmission of the ECG signals is one of the most power demanding activities. Typically, the compression of ECG signals is based on Domain Transform Methods (DTMs) [
2,
3,
4], which ensure almost no information loss of the clinical information of the patient, but these methods require a high computational loads at the WHD nodes, which translates to a higher power consumption. In order to overcome this bottleneck, lossy compression methods based on Compressed Sensing (CS) have been developed and proposed in the literature to be used on WHDs. In particular, digital CS methods require low computational loads in the compression step of ECG signals, and a higher one in the reconstruction step. For these reasons, the compression step can be performed directly on WHD by means of CS, while the latter can be achieved by the receiving node that has enough computation power, without energy consumption constraints (e.g., PC, server). In [
5], the authors compare a CS-based method for energy-efficient real-time ECG compression with several state of the art Discrete Wavelet Transform (DWT)-based compression methods. The authors present results which demonstrate that, even if the reconstruction quality of CS-based compression is lower than the classical DWT methods, it ensures a much higher energy efficiency and a lower computational load at the sink node, making it suitable for real-time ECG compression and decompression for remote healthcare services. In [
6], the authors compared two lossy compression methods: CS compression vs. the Set Partitioning In Hierarchical Trees (SPIHT) algorithm. The performance of CS is lower when compared to SPIHT, but the CS-based method proposed in [
6] exhibits lower distortion on the reconstructed ECG signal and lower power consumption, making it very appealing for applications with tight constraints such as those required for WHDs.
An important aspect is that the reconstruction quality of CS methods depends on how the sensing matrix and the dictionary matrix are chosen. Typically, random matrices based on well-known probability functions, such as Gaussian, Bernoulli, or Rademacher, are used as sensing matrices [
6,
7,
8,
9].
Alternatively to random matrices, which require the generation of random numbers in the WHD, recently deterministic matrices have been also proposed with performances in some cases better than random matrices. Regarding dictionary matrices, they are used for the reconstruction of the signal by the receiver node. The most utilized ones are based on domain transformation such as: Discrete Cosine Transform (DCT), Discrete Wavelet Transform (DWT) and Discrete Fourier Transform (DFT) [
10,
11].
Lately, in order to improve the reconstruction performance of the CS-based ECG signal acquisition, several authors explored the possibility of using a dictionary matrix trained and adapted to a specific patient. This approach is defined in the literature as Dictionary Learning (DL) and it aims to find a proper representation of datasets by means of reduced dimension dictionaries, adapted to the patient-specific ECG signal morphology [
12]. In [
13], the performance improvement due to the application of dictionary learning techniques to ECG signals is described. The authors compare the performance of an agnostic learned dictionary and a patient-specific learned dictionary, with two untrained dictionaries. The results show that DL, in particular when tuned on a single patient, helps to improve, considerably, the reconstruction quality of the ECG signal. Similarly, the advantages of DL are also demonstrated in [
14], where the authors propose an ECG compression method where the dictionary contains segments of the ECG signal of the patient. Typically, DL techniques are applied to overcomplete dictionaries; this is due to the fact that the subspaces used for data description are usually greater than the signal dimension. This means that the observed processes are sparse in the set of all possible cases. So, the goal of DL is to find these subspaces in order to efficiently represent the compressed signals. The state of the art of DL methods can be divided into three major groups [
12]: (i) the probabilistic learning methods, (ii) the learning methods based on clustering or vector quantization, and (iii) the learning methods for dictionaries with particular construction, typically driven by a priori knowledge of the signal structure. The work presented in [
15] falls into the first group. Here, the authors use the Method of Optimal Direction (MOD) in order to train the dictionary matrix. The most representative learning algorithm belonging to the second group is instead the K-SVD. In [
16], the authors present a method for enhancing the spatial resolution of the ECG signal by using a joint learning approach, based on the K-SVD algorithm of two patient’s dictionaries, one for the High Resolution (HR) ECG and one for the Low Resolution (LR) ECG. In [
17], again the K-SVD algorithm is used. Moreover, in the reconstruction stage, a coarse signal is obtained using a generic dictionary. This coarse signal is used to detect the position of the QRS complex. By considering, again, the QRS position, it is possible to chose a new dictionary, in order to properly reconstruct the ECG signal. This new dictionary has been trained with signals having the same QRS complex position of the signal to reconstruct. In this way, the authors demonstrate that it is possible to increase the performance of standard dictionary learning-based CS methods.
The main difference between the methods in the first two groups and those in the last group is that probabilistic and clustering learning methods follow a fully data driven approach, by constructing the dictionary by a portion of the ECG signals acquired from the sensors. The alternative approach of the methods in the third group instead relies on parametric dictionaries, where dictionaries are built from a generating function and a set of atom parameters.
In practical applications, this approach is quite beneficial in terms of memory requirements, communication costs and implementation complexity [
12]. This paper proposes a new method belonging to the third group among those mentioned above, which relies on a parametric dictionary. In particular, the method starts from a large wavelet parametric dictionary which is then reduced by means of a learning phase. Thanks to the learning phase, the dictionary adapts to the patient-specific features. The reduced dictionary is used for the signal reconstruction.
The paper presents the following innovations:
It makes use of a dynamic sensing matrix, proposed in [
18], which already proved to have superior performance compared with random and deterministic matrices;
It performs the reconstruction on signals frames where the R peaks are aligned. Thanks to this alignment, the dictionary optimization can exploit the different scaling features of the ECG waves, and thus provide a waveform better matched to the ECG wave lying in a specific position. The optimization of the dictionary considering the waveform position was already exploited in [
17]. In said paper, however, different dictionaries are created according to different positions of the QRS complex. In this paper, instead, the R-peak alignment of the frames during the acquisition phase is proposed.
It is worth noting that modern state of the art ECG front-end chips for wearable devices, such as [
19], are able to provide the position of the R peak together with the acquired samples. This means that the R-peak detection does not require computational load at the micro-controller side.
It proposes a procedure for the dictionary optimization by modeling the optimization as a multiple measurement vector problem;
It evaluates three different large wavelet dictionaries to be optimized and three different algorithms to solve the matrix optimization. In order to achieve a better performance, a parametric evaluation for the algorithms is carried out, since these parameters directly affect the estimation of the optimized matrix.
The proposed method and an initial evaluation of its performance are presented in [
20]. In this paper, a more complete evaluation on ECG signals from the MIT-BIH Arrhythmia Database [
21] is presented, and a comparison with other methods using dictionary learning is reported.
The proposed method has been designed as a solution for ECG monitoring, to be deployed on low power devices, such as the smart WHD of the Ambient-intelligent Tele-monitoring and Telemetry for Incepting & Catering over hUman Sustainability (ATTICUS) project [
22], aiming at developing a telemedicine system.
The rest of the paper is organized as follows. In
Section 2, an overview on CS is given. In
Section 3, the proposed method and the algorithms evaluated for the dictionary optimization are presented, followed by the experimental evaluation in
Section 4. Lastly, in
Section 5, conclusions and future work are reported.
2. Compressed Sensing Overview
Compressed Sensing represents a novel framework for compressed acquisition and reconstruction of natural (or man-made) signals which present sparsity in a specific domain in which they can be represented. The aim of CS is to acquire a compressed version of the signal of interest and reconstruct it from this compressed acquisition. Let
be the vector of
N samples acquired at Nyquist rate and
be its compressed acquisition; then, the CS compression process can be described as:
where
, and
is the
sensing matrix. In order to reconstruct the signal from its compressed acquisition,
must have a sparse representation in a specific domain (i.e., the signal can be represented by few coefficients in the chosen domain) [
23,
24]. If this condition is satisfied, it is in fact possible to reconstruct the signal from a relatively small number of samples. The ECG signal can be represented with a sparse signal model [
8], and so it is suitable to be compressed using a CS approach. The sparse representation of the ECG signal can be modeled as:
where
is the dictionary matrix and
is the coefficient vector of the signal
x in the transform domain, with
P being the number of waveforms in the dictionary. Substituting (
2) into (
1), the following expression holds:
The reconstruction problem must take the
M measurements in the vector
, the sensing matrix
and the dictionary matrix
, and reconstruct the signal
. Since
, there are infinite solutions to (
3). Under the assumption that the vector of the signal coefficients
is
K-sparse, it has been demonstrated that an estimation of the coefficient
can be obtained by solving:
where
represents the
norm operator. The minimum value of
M, allowing a successful signal reconstruction, depends on the sparsity
K and on the coherence between the sensing and the dictionary matrices [
23]. Equation (
4) represents a constrained optimization problem, where the aim is to find the vector
as the
maximally sparse solution, subject to (
3). However, since the positions of the nonzero elements in the vector are not known, the problem has a combinatorial complexity. For this reason, the (
4) is often relaxed to a
optimization problem [
25], which instead can be solved by linear programming, as:
Once the optimization in (
4) or (
5) has been solved, and the vector
has been found, it is possible to reconstruct the ECG signal from the compressed samples using (
2).
3. Proposed Method
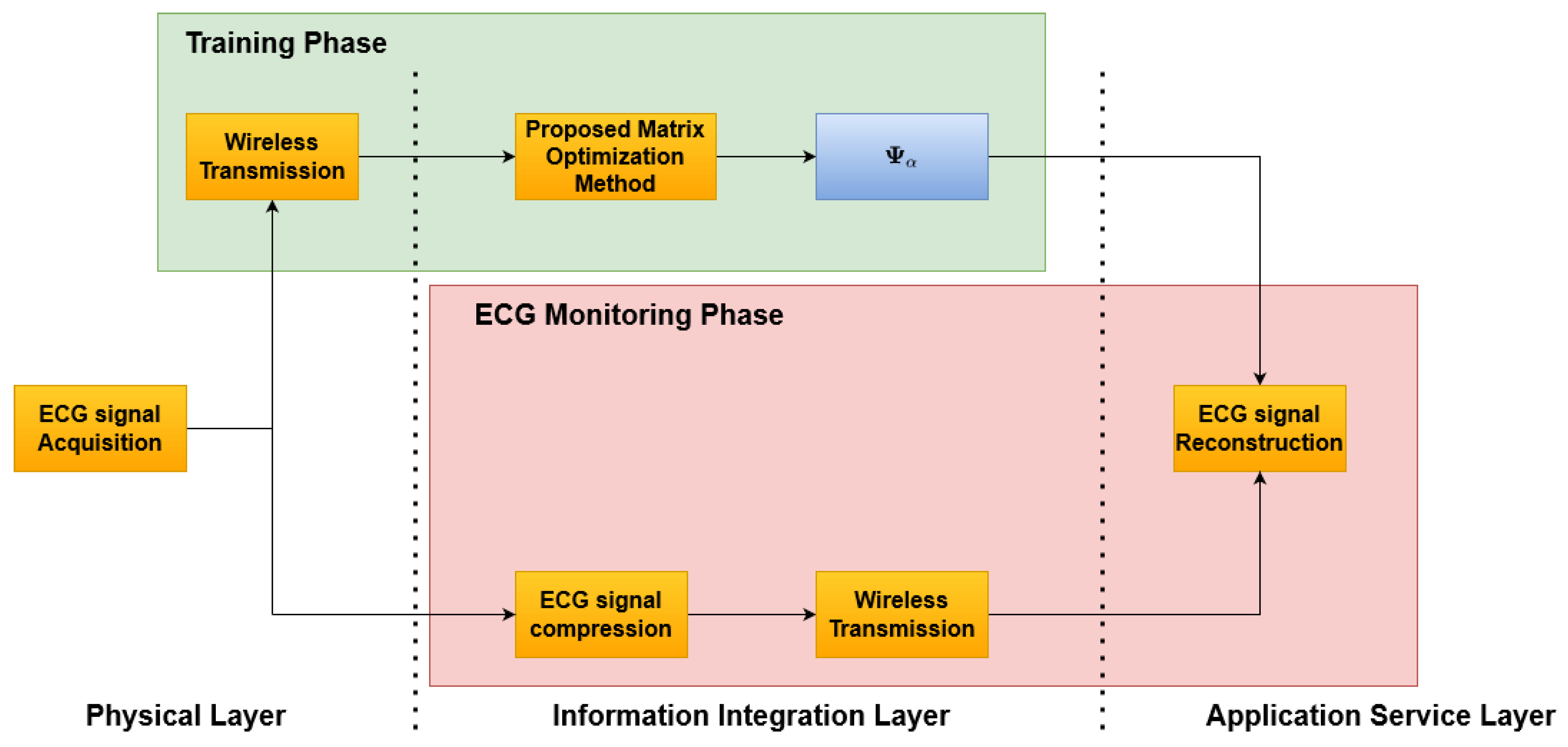
The proposed method is reported in
Figure 1 and consists of two phases: an initial
Training Phase (
Figure 2), which allows one to build the optimized dictionary, and an
ECG monitoring phase (
Figure 3), where the acquired ECG is compressed and the reconstruction can rely on the optimized dictionary. Considering a reference IoMT architecture, as described in [
22], a brief explanation is presented.
The architecture consists of three main elements: (i) the smart wearable device, (ii) the server, and (iii) the end user. These three elements are located on the three layers depicted in
Figure 1, respectively, as: (i) physical layer, (ii) information integration layer, and (iii) application service layer. The smart wearable device consists of a piece of clothing with several sensors embedded in order to acquire the ECG signal of the subject. Its tasks are: (i) to acquire the ECG signal, (ii) to split the acquired signal into frame, aligned to the R Peak, and (iii) to transmit the compressed (or uncompressed in the case of the training phase) ECG samples via a wireless communication interface to the server. The server receives the ECG signal and the unoptimized dictionary matrix during the training phase in order to realize the matrix optimization and store the optimized dictionary matrix that will be used in the
ECG monitoring phase. During the
ECG monitoring phase, the server will transmit both the signal received by the smart wearable device and the optimized dictionary matrix to the end user. The end user will then reconstruct the original signal.
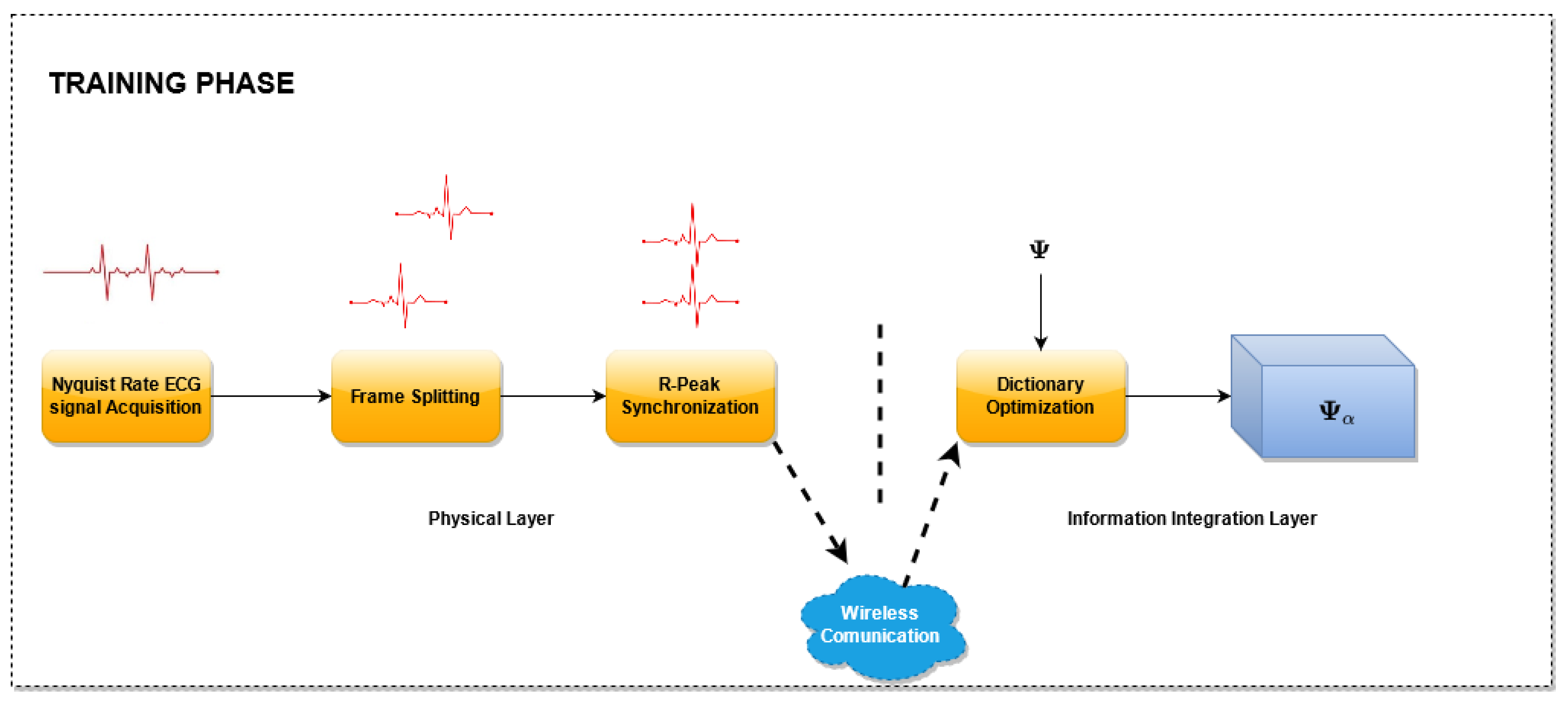
3.1. Training Phase
A block scheme of the
Training Phase is presented in
Figure 2. In this phase, the proposed dictionary matrix optimization method is performed. For this purpose, several ECG signals sampled at the Nyquist rate are utilized, split into frames, one for each heart beat, and aligned with reference to the R peak. In particular, for each frame, a new record larger than the longest heartbeat is created and the samples of the frame are copied in the new record such that the sample corresponding to the R peak lies at a fixed percentage of the record.
Then, the aligned records are used for the dictionary optimization. The optimization stage, receives as input an unoptimized dictionary matrix and selects the columns of this matrix. The selection is carried out by taking into account the coefficients that better represent the signals in the domain defined by the dictionary matrix. As a result of this block, an optimized matrix is generated composed by the selected columns. For this phase, three algorithms have been evaluated. The details of the algorithms used are described in
Section 3.3.1.
In the Training phase, the samples are acquired by the sensor nodes, disposed at the physical layer. During this phase, the sensor nodes send the uncompressed samples to the Information Integration Layer, which will realize the matrix optimization.
This Training Phase has a double advantage:
it allows to select the dictionary columns that best match the ECG signal of the patient, thus improving the reconstruction quality. If the training set is properly chosen including a sufficient number of anomalous beats, the dictionary optimization should also provide a better reconstruction quality of the anomalous beats,
it allows reducing the processing time of the ECG signal reconstruction, as the computational complexity of the algorithms increases with the number of columns of the dictionary matrix.
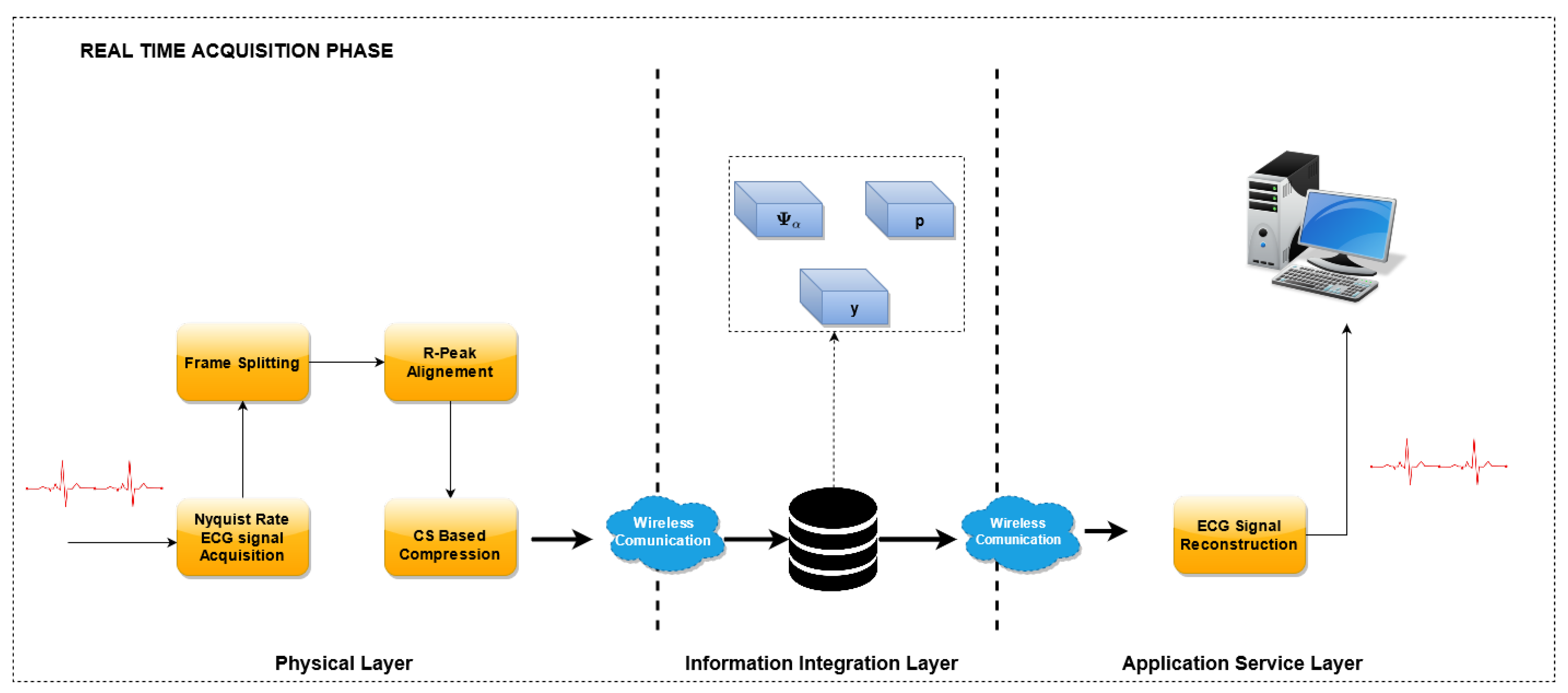
3.2. ECG Monitoring Phase
In the
ECG Monitoring Phase, the optimized dictionary is used to reconstruct the ECG waveform from the compressed samples. A block scheme of this phase is reported in
Figure 3.
Similarly to the previous phase, the Nyquist-sampled ECG signals are acquired, split into frames and aligned with reference to the R peak. Then, the CS encoding is performed by means of the sensing matrix
, and the compressed vector
is obtained. The sensing matrix is built dynamically, according to the algorithm described in [
18], and briefly reported in
Section 3.4.1.
In the reconstruction stage, the optimized dictionary has been used to recover the original waveform. With reference to the implementation, the compressed vectors are acquired by the sensor nodes at the physical layer and sent to the Information integration layer. Here, when requested, the waveforms are reconstructed using the optimized dictionary and eventually sent to the end user of the Application Service Layer.
3.3. Adopted Unoptimized Dictionary Matrices
In this paper, the unoptimized dictionary
is chosen according to the analysis presented in [
24], where the authors compared several dictionaries for ECG compression and reconstruction. The authors found that the best reconstruction performance is achieved by a dictionary defined according to the Mexican Hat kernel expressed as follows:
where
,
a is the scaling factor of the Mexican Hat kernel and
b is the delay factor. Three dictionaries are utilized in this paper, built by choosing different values of the scaling and delay factors. A record of ECG signal is acquired for several minutes (at least two) by the sensors and split into
F frames, one for each heartbeat and are then aligned on the R-peak.
By considering all the frames of the training set, (
2) can be rewritten as:
where
is a matrix built by placing the training records divided into F frames placed side-by-side columns-wise and
is the matrix which contains the coefficients for the training records. It is worth noting that the higher the number of columns of
, the higher the number of coefficients representing a single record is.
The idea underlying the proposed method is that, since the dictionary is large, and also that the frames are aligned to the R peak, several elements of the dictionary
can be discarded, and instead only the most representative elements should be considered in reconstructing the signal. Based on this observation, the dictionary optimization problem can be written as the following problem, called Multiple Measurement Vector (MMV) sparse recovery:
where given a matrix
,
is the
support of
, which is the index set of the rows which contain nonzero entries [
26]. The solution of the above problem is a set of row indexes of the matrix
, corresponding to the most significant coefficients of the dictionary which are present in the training signals. Therefore, an optimization of the dictionary matrix
can be carried out by selecting the columns of
whose indexes are in the set
.
To solve the MMV sparse recovery problem in (
8), three algorithms have been evaluated: Multiple Orthogonal Matching Pursuit (M-OMP), Multiple FOCal Underdetermined System Solver (M-FOCUSS) and Spectral Projected Gradient for Least square 1 (SPGL1). All the considered algorithms present a convergence or regularization parameter to be set in order to achieve a proper dictionary optimization and it is difficult to determine a priori the best value of such parameter according to the noise characteristics of the signals.
Therefore, in the
Training phase, the matrix optimization is executed several times, for different values of the parameters, in a given range, and its performance is evaluated on the training signals, in terms of
. Among the obtained matrices (one for each value), the matrix
that achieves the lowest
is selected to be used in the
ECG Monitoring Phase. Details about the used algorithms and about their utilization for the matrix optimization will be provided in
Section 3.3.1 and
Section 4.1, respectively.
The proposed dictionary optimization method in this paper was evaluated on three different unoptimized matrices, all based on the Mexican Hat kernel:
is a dyadic matrix, defined according to [
18], and expressed by (
9). Here, the scaling factor
a follows the power of 2 (i.e.,
for the first
values,
for the following
, and so on), while the delay factor
b varies from 0 to
with a step of
a;
is a Mexican Hat matrix where
a also follows the power of 2, while
b varies linearly from 0 to
with a unitary step (see (
10));
is a matrix (see (
11)) where
a follows the geometric progression
,
with a step of
, and
b varies from 0 to
with a step of
a.
For all the considered matrices, an additional column has been added in order to take into account possible biases of the ECG signals (e.g., the baseline wander).
3.3.1. Dictionary Optimization Algorithms
In this subsection, the algorithms used for solving the MMV sparse recovery problem (
8) are briefly recalled.
This algorithm falls into the forward sequential selection methods, aiming to find a sparse solution by sequentially building up a smaller subset of column vectors from the dictionary matrix in order to represent the signal
[
27]. The algorithm performs the following steps [
27,
28]:
The residual , the set of column indices Λ = ∅ and the counter iteration t = 1 are initialized;
Find the index
that solves the equation
where
and
is the j-th column of
;
Λ and are updated, , ;
The least square approximation is performed and the
vector is evaluated:
The new residual is calculated:
The iteration counter t is incremented, and the algorithm checks for the following stop conditions:
If none of those two conditions are met, the algorithm returns to step 2.
The M-OMP algorithm is the quickest to optimize. This is due the fact that the algorithm returns the reached residual value at every iteration and the set of indices utilized. In order to achieve the lowest possible value, the following tasks are performed:
Set the number of iterations of the M-OMP algorithm and run it;
At the last iteration, the algorithm returns a vector of the residuals, each corresponding to an iteration;
Each element of the residuals vector is associated to a subset of ;
A range of residuals is selected, and accordingly, a set of candidate optimized matrices is built by selecting the corresponding subsets;
Set the desired value;
Run the OMP algorithm with all the possible optimized matrix obtained in step 4;
Choose the optimized matrix that achieves the lowest value.
The FOCUSS algorithm aims to find a solution for dictionary optimization that is referred in the literature as a weighted minimum norm solution. This solution is defined as the one that minimizes a weighted norm
, where
is called weight matrix. The algorithm starts by finding a coarse solution for the representation of the sparse signal and at every iteration; this solution is pruned, by means of reducing the dictionary size. This process is implemented using a generalized Affine Scaling Transformation (ASL) in which the weight matrix, chosen initially as an identity matrix, is calculated at every iteration [
29]. The solution is expressed by:
where
and
denotes the Moore–Penrose inverse.
In this work, the utilized FOCUSS algorithm is called regularized FOCUSS because it includes a regularization method called Tikhonov regularization, which is based on the inclusion of a regularization parameter,
. Furthermore, it is assumed that multiple signals are acquired that share a similar sparsity profile and dictionary. Under these assumptions, the model can be posed as an MMV problem as follows:
where
is the Frobenius norm. This version of the algorithm is commonly referred to as M-FOCUSS. At every iteration, the algorithm builds a dictionary matrix with a reduced number of columns with respect to the one obtained from the previous iteration. Since
is chosen as a constant value, the tuning process performed for the M-FOCUSS algorithm is based on the number of iterations and is synthesized in the following steps:
The SPGL1 algorithm is described in detail in [
30]. The algorithm finds the solution of MMV Basis Pursuit (BP) problem by iterative solving an associated MMV Least Square (LS) problem. The BP problem can be expressed as
In order to obtain a sparse solution, the BP problem is redefined as an LS problem:
and
are positive parameters that can be seen as an estimation of the noise level in the data or the error from the ideal BP solution and LS one, where
and
are 0. If the
parameter is set appropriately, namely,
is equal to
, the solution of the BP problem and the LS problem is the same. Choosing the parameter
, the algorithm implements a Newton-based method in order to update
to achieve the value
, where
is the value of the parameter where the BP solutions and the LS solutions coincide. Once the optimal value of the
parameter is found, and the LS solution is equal to the BP solution, a spectral projected-gradient is used to solve (
18).
The SPGL1 takes as an input the desired value of , namely , and returns at each iteration the value reached. At the i-th iteration, this value will be expressed as . Since this parameter can be seen as an estimation of the noise level in the data, must be chosen properly: if the value is too low, the noise level is underestimated, while if the value of is too high, the noise level is overestimated. In the first case, will never reach the objective value , while in the second case, the optimized dictionary is made with too few columns and cannot assure the reconstruction of the signal. In order to assign the correct values to , and proceed with the performance evaluation for the tuning, the following steps are performed:
3.4. ECG Monitoring Phase
In this section, the compression and the reconstruction steps of the ECG signals by means of the CS method proposed in this work are presented.
3.4.1. ECG Signal Compression by Means of CS
In the scientific literature, when dealing with the application of CS for ECG monitoring, often random sensing matrices, based on Bernoulli or Gaussian random probability functions, are used. The performance of these random matrices heavily depends on the correlation between the sensing matrix elements and the acquired samples. The compression algorithm presented in [
18] overcomes this limitation by adopting a deterministic sensing matrix that depends on the ECG signal to be compressed. By constructing a sensing matrix adapted to the ECG signal, it contains more information about the signal features, and therefore exhibits a better reconstruction performance.
The algorithm described in [
18], creates a sensing matrix
which is chosen in a such way that
represents a sort of auto-correlation of the signal
, containing the ECG samples at the Nyquist rate. More precisely, the compressed vector
is obtained as the cross-correlation of
and a binary vector
, whose elements are 1 if the magnitude of the corresponding sample in
is above a specified threshold and 0 otherwise. The method operates on frames of
N samples and for each record
, an average operation is performed, obtaining
. The average is used for the evaluation of the magnitude
, as:
For each frame, the magnitude is then compared with a threshold value
, which represents a certain percentile of the waveform amplitude.
is evaluated by means of a sorting-based algorithm. When an update of the sensing matrix is needed, the
N-size binary vector
is constructed by comparing the signal magnitude
with the signal threshold
. Hence, the
n-element of
is evaluated as:
The vector is the first row of the sensing matrix , whereas the other rows are a circular shifted version of the vector by an integer quantity equal to the Under Sampling Ratio (USR), where . If a significant change in is found, the sensing matrix is updated; otherwise, the sensing matrix of the previous frame is used. In order to be considered as a significant change, the distance between the threshold value at the current frame and the threshold value at the previous frame must be higher than a specified limit .
In all the frames where the sensing matrix is changed, the vector is sent together with the compressed samples.
3.4.2. ECG Signal Reconstruction by Means of CS
By knowing both the sensing matrix and the optimized dictionary, the OMP algorithm is used to estimate the vector
using (
4). Afterwards, the ECG waveform is reconstructed by using the following formula:
4. Experimental Results
The proposed method has been evaluated experimentally in the MATLAB environment on ECG signals taken from the PhysioNet MIT-BIH Arrhythmia Database [
21]. The MIT-BIH Database has been chosen because it is the most utilized in the literature among the ECG databases available online. This database contains 48 half-hour excerpts of two-channel ambulatory ECG recordings, obtained from 47 subjects studied by the BIH Arrhythmia Laboratory. The recordings have been acquired with a sampling frequency of 360 Hz and a resolution of 11 bit per channel. The signals have been divided into frames with size
and a filtering stage is applied on them in order to remove the first three harmonics of the power line signal (60, 120, 180 Hz). For the tests, ten ECG datasets have been used
which contain the following beat labels: paced beats, normal beats, premature ventricular contraction, fusion of paced and normal beats, fusion of ventricular and normal beats and atrial premature beats. For M-OMP and SPGL1, the unoptimized dictionary matrices utilized are the one expressed in (
9)–(
11), while in the case of M-FOCUSS, only (
9) has been considered, due to the poor performances exhibited by this algorithm while using (
10) and (
11). The optimization algorithms and the corresponding dictionaries have been tested using 10 min of ECG signals from the set S with different values of
. For each dataset, the first 5 min were used in the
Training Phase, while the remaining 5 min were used in the acquisition phase. By checking the annotation of every heartbeat, the signals were acquired by making sure that abnormal beats were present inside both phases. The reconstruction performance has been evaluated by means of the
as a figure of merit which is commonly adopted in the literature. The
is calculated for each frame, as follows:
where
is the acquired ECG signal at Nyquist rate, without being compressed, and
is the reconstructed signal by means of CS according to
Section 3.4.1. Then, the average
on the entire ECG signal has been obtained by taking the average of the
values calculated for each frame. After assessing the performance of the proposed method and algorithms, a comparison has been carried out with other dictionary learning methods, namely [
5,
14,
15]. For this purpose, the Normalized PRD (PRDN) of the MIT-BIH ECG signal labeled No. 117 was evaluated and compared with the results expressed in [
14] obtained using the same signal. The PRDN was defined as follows:
Compared to PRD, PRDN removes the average of the original signal, and thus it is not affected by the dc bias that could be present in some considered signals.
4.1. Convergence Parameters
All the three algorithms used in this work present a convergence parameter to be set, in order to achieve a proper optimization of the dictionary matrix. These parameters are:
Residual threshold, for the M-OMP;
, an estimation of the noise level in the data for the SPGL1;
, a regularization constant for the M-FOCUSS.
These parameters directly affect the performance of the algorithms as expressed in (
14), (
16) and (
17), where it is possible to note that they represent the constraints of the problems. A lower value of these parameters means a more strict constraint which is translated into an optimized matrix with an higher number of columns, while with higher values, the algorithms solve a more relaxed version of the problem. Both extremes are not desirable, the first due to the OMP algorithm in reconstruction, that has to work on a larger domain, degrading its performance, and the latter because it provides an optimized matrix with too few columns, not assuring the reconstruction of the compressed ECG signal. The optimal value to assign depends on the ECG signals that are used in the
Training Phase. So, in order to improve the dictionary optimization, the
Training Phase includes a parameter tuning stage. For the
Training Phase, 5 min of ECG are acquired from the sensors, split into frame and aligned to the R-peak. A set of values of the parameters reported in
Table 1 are chosen:
The corresponding optimization algorithm is executed for each chosen value, and for each of them, a different optimized matrix is obtained. In order to evaluate the contribution of the parameters, the reconstruction stage is executed on all the optimized matrices and the PRD is calculated. The
parameter of M-FOCUSS was chosen as a constant value. This is due to the fact that in order to find a solution to the optimization problem by utilizing the M-FOCUSS algorithm, the values of the regularization parameter
should be found at every iteration of the algorithm, as stated in [
27]. Although there are some methods that allow one to choose the values of
to be used for every iteration ([
27]), this leads to a noncomputationally efficient approach [
29].
allows a balance between optimization quality (that translates directly into signal estimation quality) and sparsity (which leads to a faster reconstruction) [
31]. For the tuning of the M-FOCUSS algorithm, in this paper, a very small constant value of
has been chosen, so as to drive the algorithm towards a fine solution. Then, the performance of the reconstruction is analyzed at each iteration and the matrix giving the lowest
is selected.
4.2. Performance Evaluation
The experimental results for each dictionary and algorithm taken into account are shown from
Table 2,
Table 3,
Table 4,
Table 5,
Table 6,
Table 7,
Table 8,
Table 9,
Table 10 and
Table 11. The tests were performed after the tuning phase described in the previous subsection. In
Figure 4,
Figure 5 and
Figure 6, an example of the improvement in terms of
PRD for all three algorithms, used for the training of the dictionary matrix on the signal No. 122, is presented. In particular, in
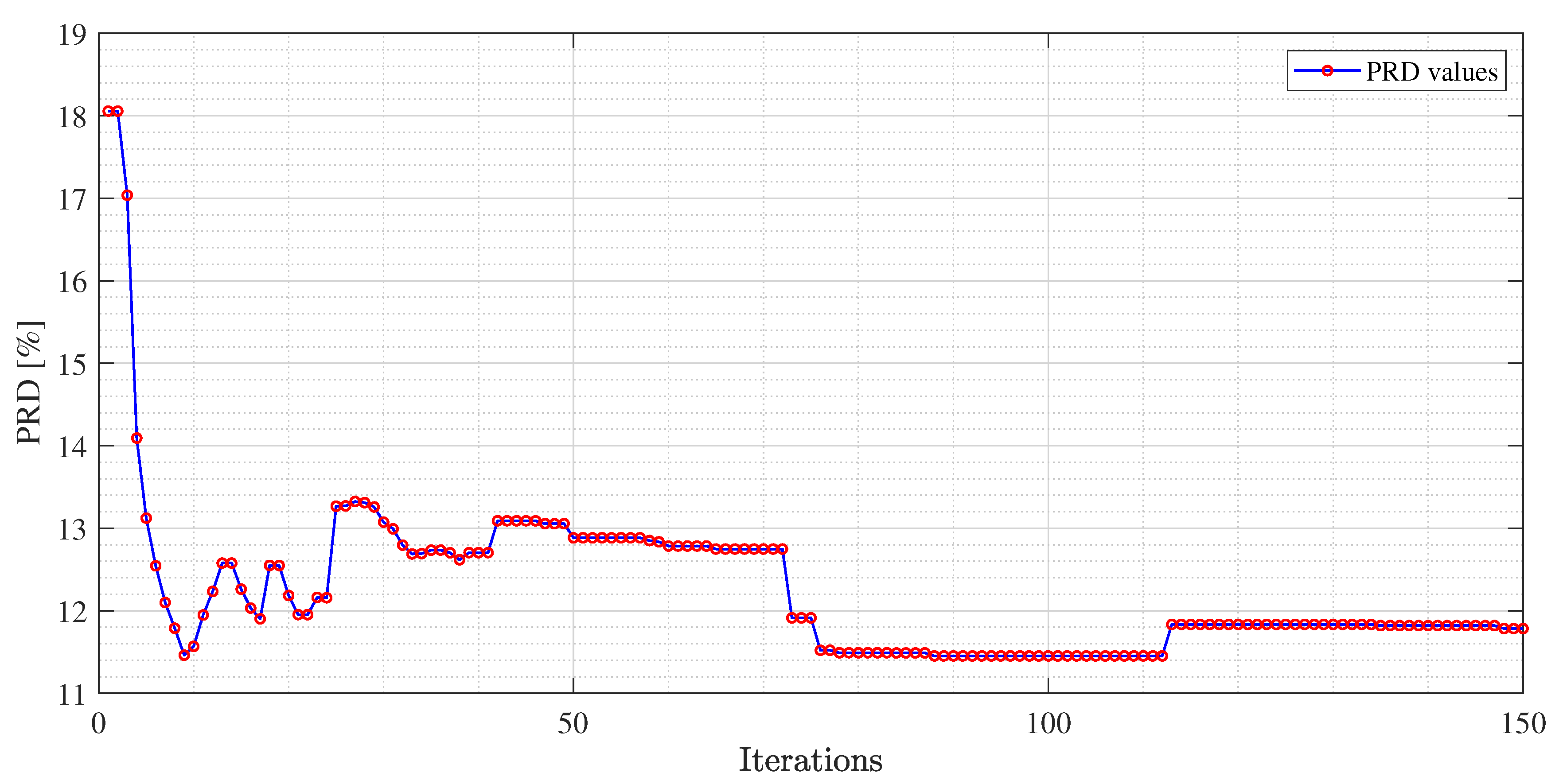
Figure 4, PRD values achieved by the dictionaries that have been provided as output at each iteration of the M-FOCUSS algorithm, are presented. Only the results of 150 iterations are shown instead of the nominal 500 because, in this case, the dictionaries obtained after 150 iterations do not assure a proper reconstruction of the signal. After reaching the minimum of the PRD, around iteration 100, the reconstruction error begins to grow again, due to the further reduction in the dictionary. In
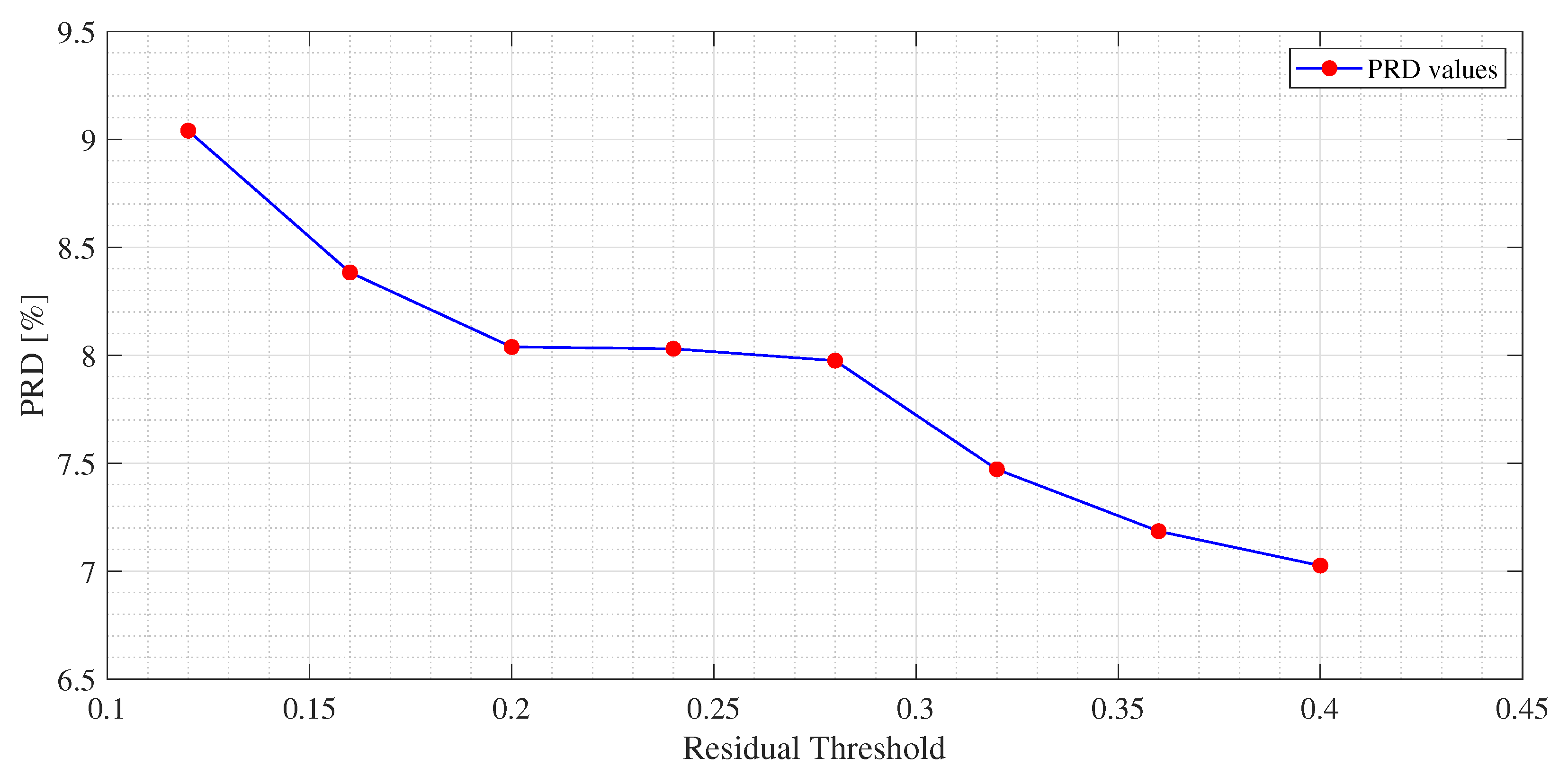
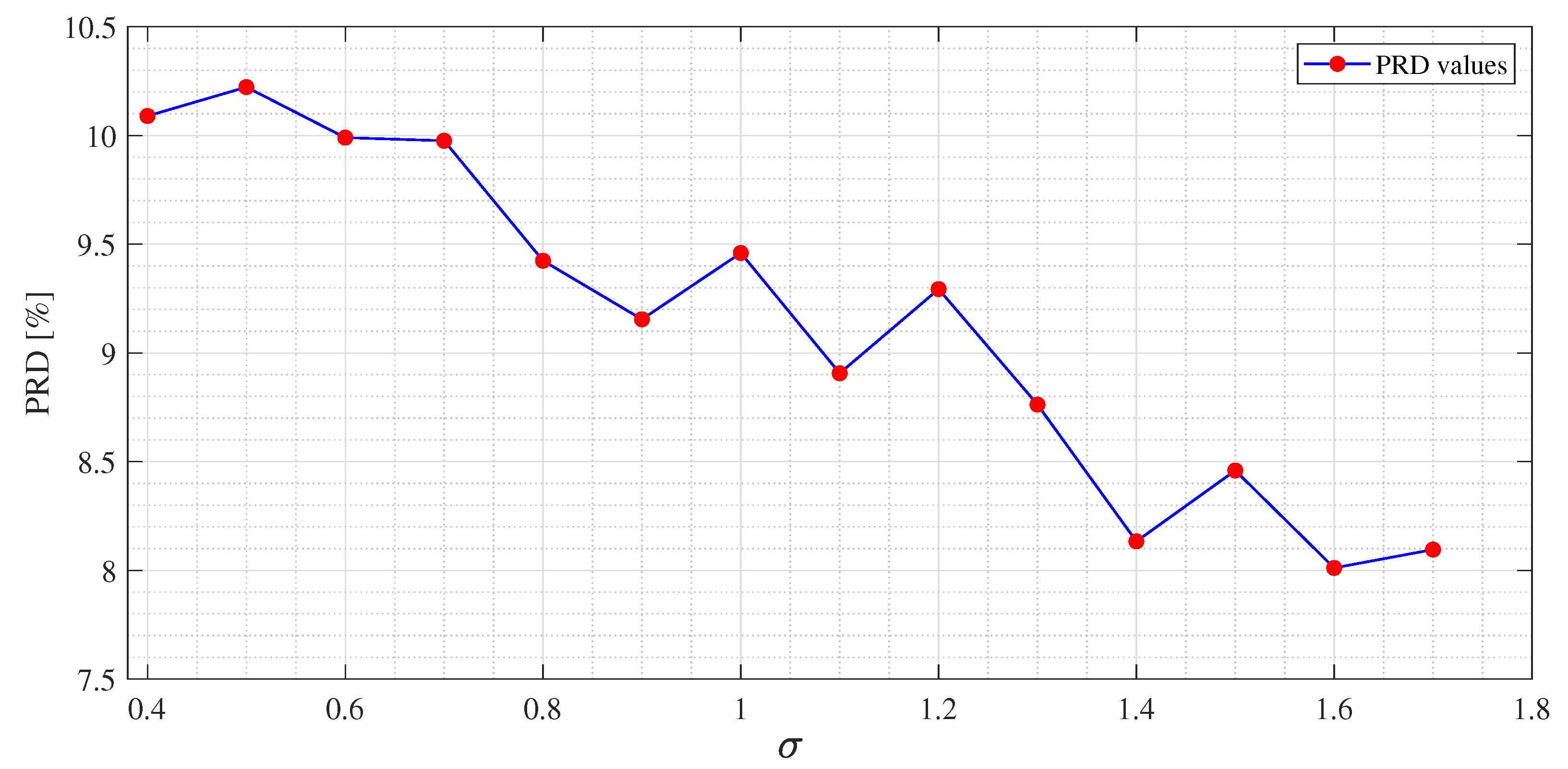
Figure 5 and
Figure 6, not all the nominal values of
and
are shown, due to the fact that the dictionaries obtained with those values could not guarantee the signal recovery. It can be seen that by properly choosing the values of the regularization parameters, the reconstruction performances are enhanced.
The first column of all tables represents the
value chosen for the compression of the ECG signal. The second column contains the
value, obtained using the unoptimized dictionary matrix expressed as (
9) as in [
18]. In the subsequent columns, the
values achieved using the matrices optimized by means of the proposed method are reported. In particular,
,
and
are obtained, starting from
,
and
, respectively. For
values of 2 and 3, the performance obtained with the optimized matrices are comparable with that obtained with the unoptimized one. The situation changes when taking into account higher values of
. A significant reduction in the
can be observed with the optimized dictionaries. By assessing the overall performance, the best results are achieved by
followed by
and
for M-OMP and by
for SPGL1 with M-FOCUSS right behind. In particular, the M-OMP exhibits the lowest values of PRD, with the matrix
for signals Nos. 105 (
Table 2), No. 107 (
Table 5), No. 122 (
Table 6), No. 100 (
Table 7), No. 106 (
Table 9) and No. 112 (
Table 10), with the matrix
for signals No. 103 (
Table 3), No. 102 (
Table 4), No. 101 (
Table 8) and with the matrix
for signals No. 113 (
Table 11). The second lowest values of PRD are achieved by the SPGL1 with the matrix
for the signal Nos. 103, 107, 122 and 100, with the matrix
for signal Nos. 101 while for signal No. 112 the two matrices exhibit comparable results. Lastly, M-FOCUSS exhibits the second lowest values of PRD for signals Nos. 102, 106 and 113. By taking into account the
values achieved by the utilized algorithms, the best performance is obtained by deploying the M-OMP algorithm with the
dictionary for ECG signal No. 105, (
Table 2) where it is possible to remain below the 9% threshold with an
of 10, while the worst was obtained for ECG signal No. 101, where the maximum possible exploitable value of the
is 6. In order to show the range of the obtained PRDs,
Table 12 reports, for each
USR, the lowest and highest obtained PRDs among the considered signals.
In
Table 13, a comparison between the proposed method and the ECG compression techniques based on CS presented in [
5,
14] is reported. All the results have been obtained using the signal No. 117. It is possible to observe that the proposed method exhibits lower values of the PRDN for
USRs lower than 8. The method in [
14] achieves better results than the proposed one for
USRs greater than 8. However, the obtained values of PRDN are high, such that the clinical content of the signal could be compromised. This makes such
USRs not practically usable. In
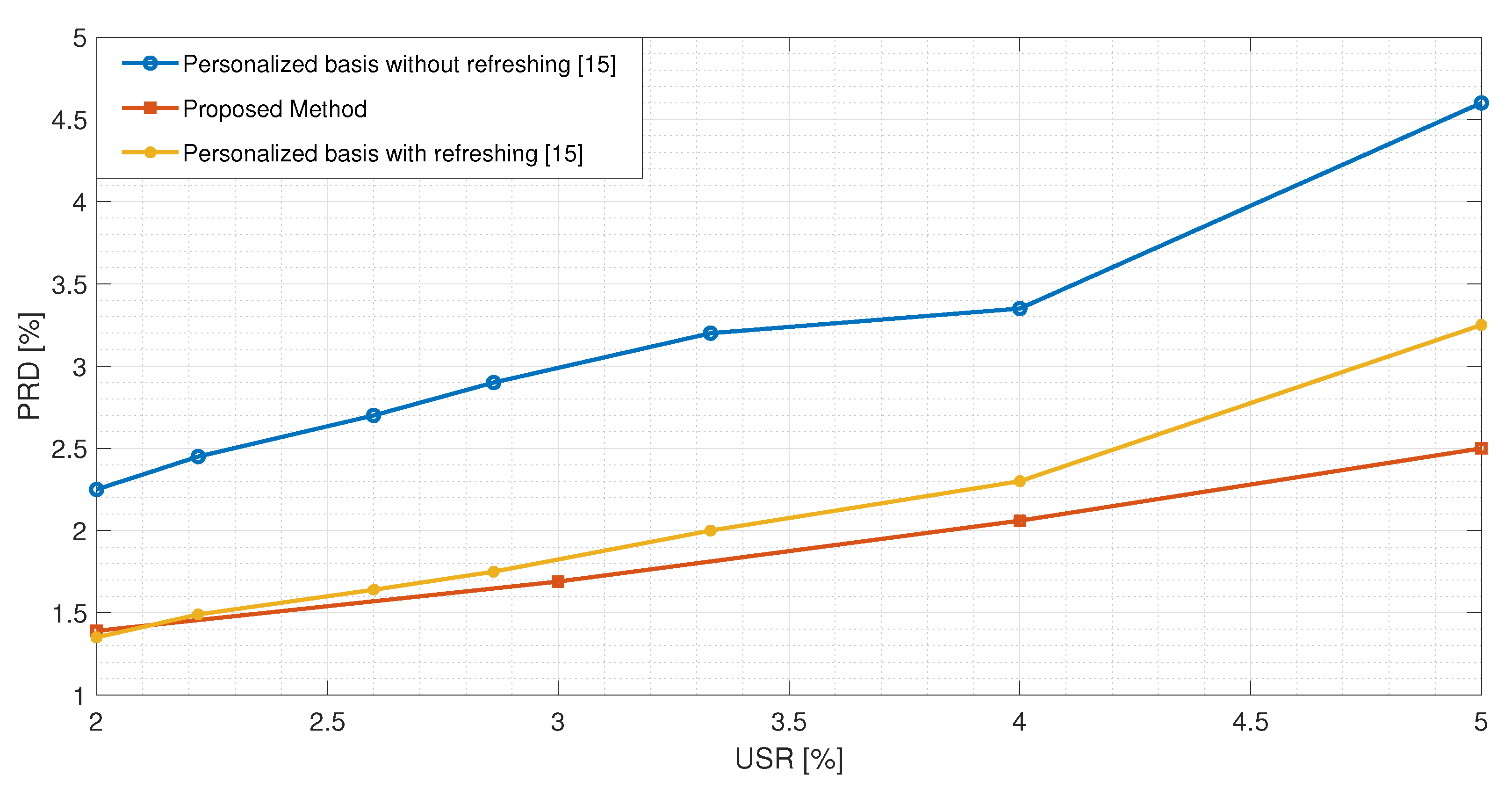
Figure 7, the best performance exhibited by the proposed method is compared with the one presented in [
15]. The authors implemented a CS-based reconstruction method for ECG signals based on dictionary learning with the possibility of updating the matrix if the reconstruction error is too high. Even by considering this additional feature, the proposed method exhibits a better performance.
5. Conclusions
In this paper, a new approach for the optimization of a dictionary used in real-time ECG signal compression and reconstruction system based on CS was presented. The proposed approach is an alternative to fully data driven dictionary optimization methods, where the dictionary is constructed from the training data, and utilizes an overcomplete wavelet dictionary that is reduced by means of dictionary optimization algorithm, in order to leave only the highest impact columns for the purpose of the reconstruction of the ECG signals. Furthermore, in order to exploit the different scaling features of the ECG waves, an alignment of the frames according to the R-peak was used. Starting from an unoptimized dictionary matrix expressed by the Mexican Hat function using three different combination of its parameters, the proposed method includes a Training Phase where three different algorithms have been used for the dictionary optimization: M-OMP, SPGL1 and M-FOCUSS. The training phase also includes an experimental tuning of the convergence parameter of each algorithm, in order to ensure the most suitable condition for the optimization of the dictionary and the reconstruction of the ECG signals. The paper presented highlights the advantages of using an optimized dictionary matrix, assesses the influence of convergence parameters on the algorithms, and, therefore, on the dictionary optimization, and evaluates the performances of the proposed method with different optimization algorithms by comparing the results of the proposed method with other state of the art methods. The optimization allows one to reach a much higher performance due to the elimination of redundant columns from the dictionary and by decreasing the domain in which the reconstruction OMP algorithm works. Moreover, the introduced tuning stage allows ensuring that each considered algorithm works in its most suitable conditions, thus providing the best reconstruction results. For the performance evaluation of each algorithm, several ECG signals from the PhysioNet MIT-BIH Arrhythmia Database were considered, evaluating the PRD for several USR values. The analysis demonstrated that: (i) even on abnormal beats, the utilization of an optimized dictionary matrix improves the reconstruction performance of the ECG signals, and (ii) this performance is further increased by the tuning of the convergence parameters, which is fundamental for a correct dictionary optimization. Furthermore, among the considered cases, the best performance on average was achieved by the M-OMP algorithm while using the dictionary. By comparing the performance of the proposed method with other state of the art methods, it was proven to outperform the other reconstruction methods based on dictionary learning and patient-specific dictionaries, for USRs lower than 8.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}