
A Lightweight Fusion Distillation Network for Image Deblurring and Deraining †

 , ,
, ,
Abstract
:1. Introduction
- We propose a multi-scale hierarchical information fusion scheme (MSHF) to encode the image with rain and blur. MSHF extracts and fuses the image feature in multiple small-scale spaces, which can eliminate redundant parameters while maintaining the rich image information.
- We propose a very lightweight module named feature distillation normalization block (FDNB) which can constantly filter out useless feature channel information. To the best of our knowledge, it is the first time that the distillation network is adopted in image deblurring and deraining tasks.
- Two attention mechanism based modules are also presented in the decoding process of our approach to exploit the interdependency between the layers and feature channels, which is termed as Multi-feature fusion module based on attention mechanism (MFFD). Through MFFD, a better information fusion can be achieved to compensate for the potential image detail lost in FDNB.
2. Related Work
3. Proposed Method
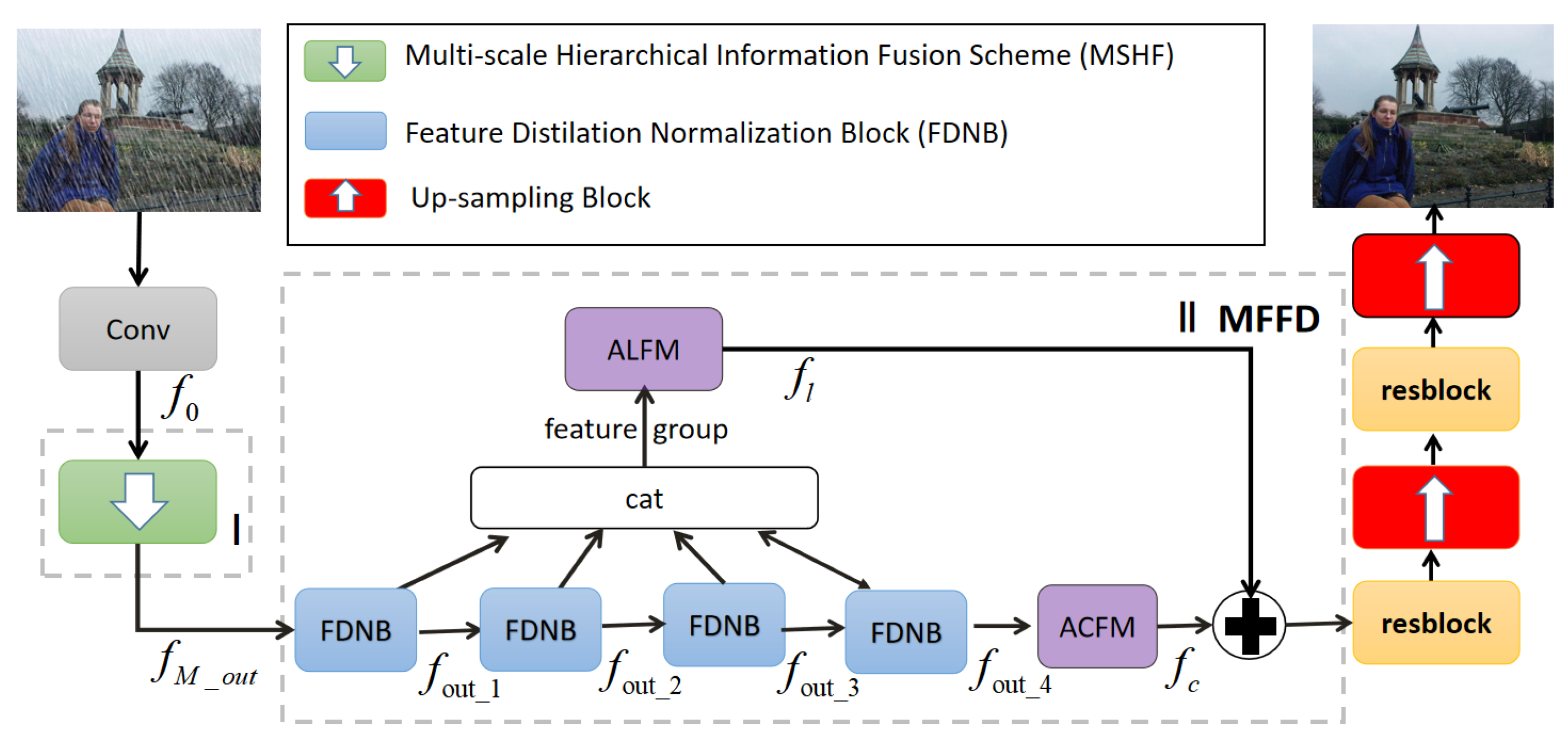
3.1. Overview
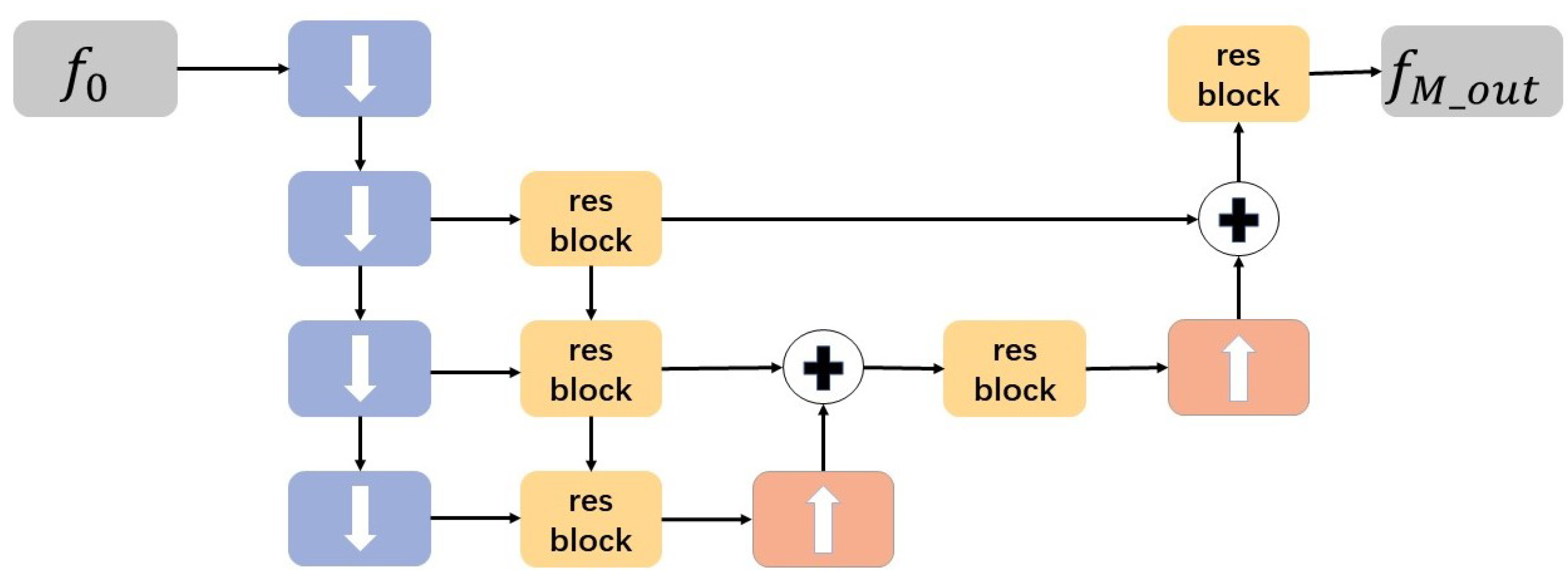
3.2. Multi-Scale Hierarchical Information Fusion Scheme (MSHF)
| Algorithm 1 Multi-scale Hierarchical fusion Algorithm |
Input: Output: The output feature of MLHF 1: For i in range (1, 5) do 2: = downblock () 3: = resblock () 4: End for 5: For i in range (3, 5) do 6: = resblock (+upsampling()) 7: = resblock (+upsampling()) 8: End for 9: = resblock() |
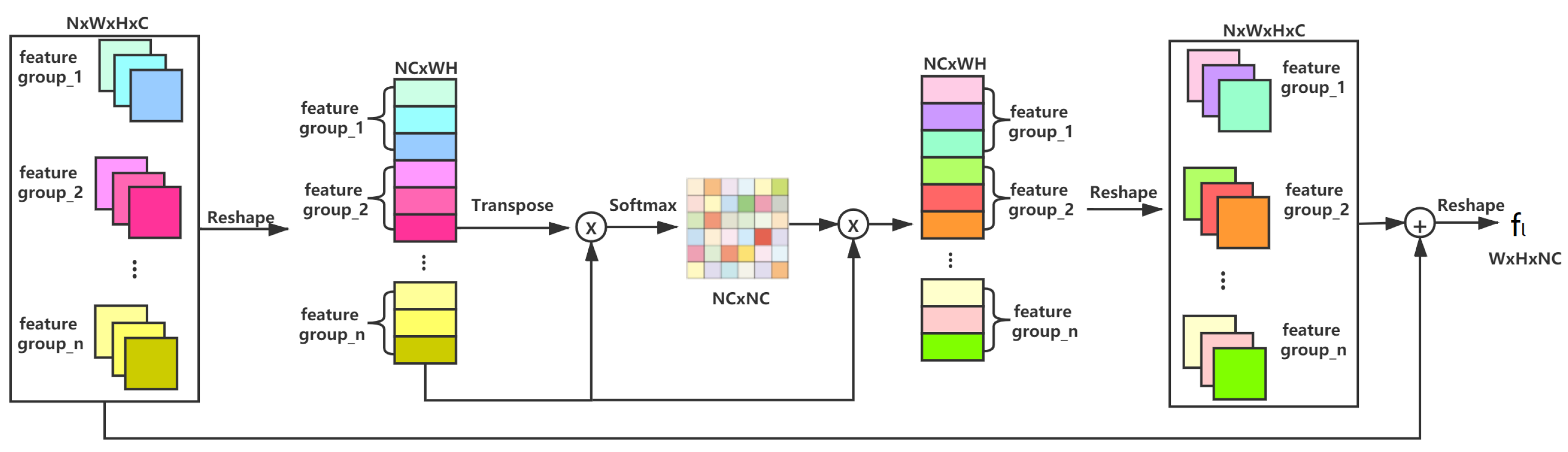
3.3. Multi-Feature Fusion Module Based on Attention Mechanism (MFFD)
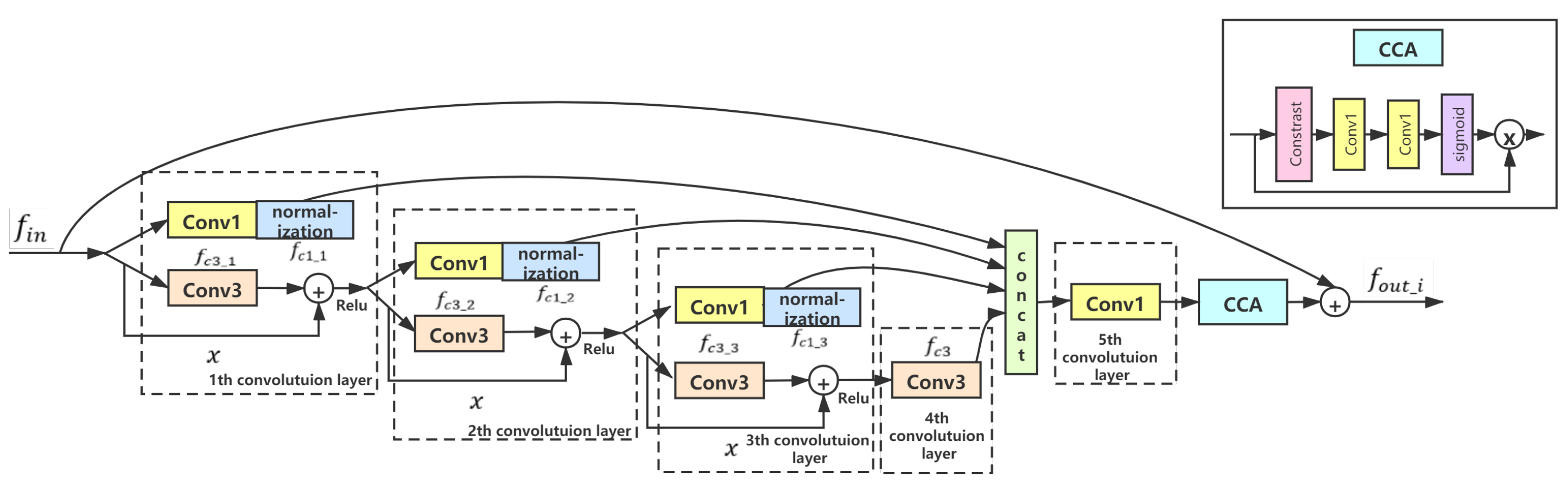
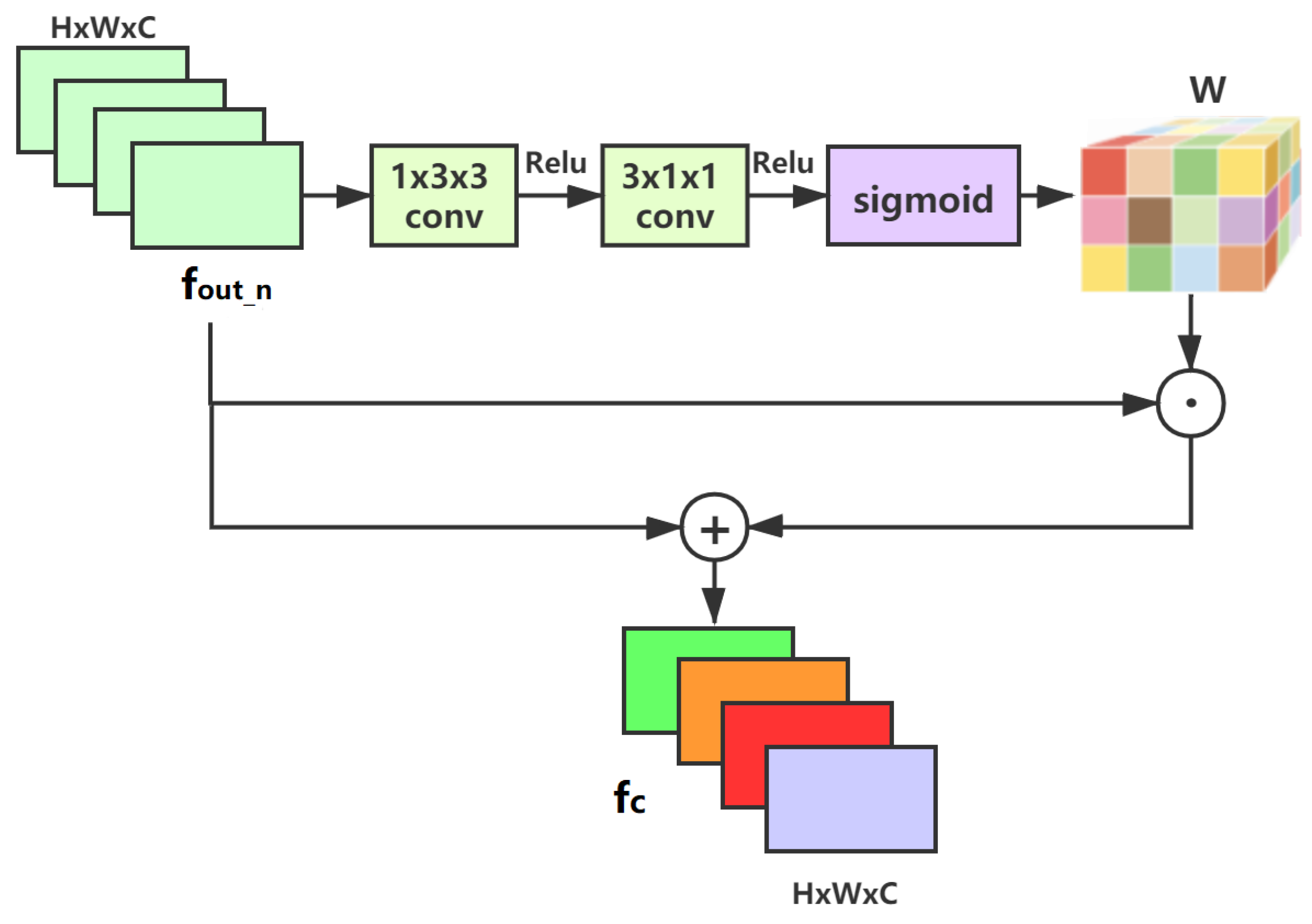
3.3.1. Feature Distillation Normalization Block (FDBN)
3.3.2. Fusion Mechanism
4. Experiments
4.1. Experimental Settings
4.1.1. Image Deblurring Dataset
4.1.2. Image Deraining Dataset
4.2. Quantitative and Qualitative Evaluation on Deraining Task
4.3. Quantitative and Qualitative Evaluation on Deblurring Task
4.3.1. GoPro Dataset
4.3.2. Kohler Dataset
4.3.3. HIDE Dataset
4.4. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xu, L.; Zheng, S.; Jia, J. Unnatural L0 Sparse Representation for Natural Image Deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Li, L.; Pan, J.; Lai, W.; Gao, C.; Sang, N.; Yang, M. Blind Image Deblurring via Deep Discriminative Priors. Int. J. Comput. Vis. 2019, 127, 1025–1043. [Google Scholar] [CrossRef]
- Chen, L.; Fang, F.; Wang, T.; Zhang, G. Blind Image Deblurring With Local Maximum Gradient Prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2019), Long Beach, CA, USA, 16–20 June 2019; Computer Vision Foundation/IEEE: Washington, DC, USA, 2019; pp. 1742–1750. [Google Scholar]
- Luo, Y.; Xu, Y.; Ji, H. Removing Rain from a Single Image via Discriminative Sparse Coding. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV 2015), Santiago, Chile, 7–13 December 2015; IEEE Computer Society: Washington, DC, USA, 2015; pp. 3397–3405. [Google Scholar]
- Chang, Y.; Yan, L.; Zhong, S. Transformed Low-Rank Model for Line Pattern Noise Removal. In Proceedings of the IEEE International Conference on Computer Vision (ICCV 2017), Venice, Italy, 22–29 October 2017; IEEE Computer Society: Washington, DC, USA, 2017; pp. 1735–1743. [Google Scholar]
- Li, Y.; Tan, R.T.; Guo, X.; Lu, J.; Brown, M.S. Rain Streak Removal Using Layer Priors. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016), Las Vegas, NV, USA, 27–30 June 2016; IEEE Computer Society: Washington, DC, USA, 2016; pp. 2736–2744. [Google Scholar]
- Zhu, Z.; Wei, H.; Hu, G.; Li, Y.; Qi, G.; Mazur, N. A Novel Fast Single Image Dehazing Algorithm Based on Artificial Multiexposure Image Fusion. IEEE Trans. Instrum. Meas. 2021, 70, 1–23. [Google Scholar]
- Zheng, M.; Qi, G.; Zhu, Z.; Li, Y.; Liu, Y. Image Dehazing by An Artificial Image Fusion Method based on Adaptive Structure Decomposition. IEEE Sens. J. 2021, 70, 1–23. [Google Scholar] [CrossRef]
- Nah, S.; Kim, T.H.; Lee, K.M. Deep Multi-scale Convolutional Neural Network for Dynamic Scene Deblurring. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Tao, X.; Gao, H.; Wang, Y.; Shen, X.; Wang, J.; Jia, J. Scale-recurrent Network for Deep Image Deblurring. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Gao, H.; Tao, X.; Shen, X.; Jia, J. Dynamic Scene Deblurring With Parameter Selective Sharing and Nested Skip Connections. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 3843–3851. [Google Scholar]
- Zhang, H.; Dai, Y.; Li, H.; Koniusz, P. Deep Stacked Hierarchical Multi-Patch Network for Image Deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2019), Long Beach, CA, USA, 16–20 June 2019; Computer Vision Foundation/IEEE: Washington, DC, USA, 2019; pp. 5978–5986. [Google Scholar]
- Zhang, J.; Pan, J.; Ren, J.; Song, Y.; Yang, M.H. Dynamic Scene Deblurring Using Spatially Variant Recurrent Neural Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Xu, L.; Ren, J.S.J.; Liu, C.; Jia, J. Deep Convolutional Neural Network for Image Deconvolution. In Proceedings of the Annual Conference on Neural Information Processing Systems 2014, Montreal, QC, Canada, 8–13 December 2014; pp. 1790–1798. [Google Scholar]
- Kupyn, O.; Budzan, V.; Mykhailych, M.; Mishkin, D.; Matas, J. DeblurGAN: Blind Motion Deblurring Using Conditional Adversarial Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Kupyn, O.; Martyniuk, T.; Wu, J.; Wang, Z. DeblurGAN-v2: Deblurring (Orders-of-Magnitude) Faster and Better. arXiv 2019, arXiv:1908.03826. [Google Scholar]
- Gong, G.; Zhang, K. Local Blurred Natural Image Restoration Based on Self-Reference Deblurring Generative Adversarial Networks. In Proceedings of the 2019 IEEE International Conference on Signal and Image Processing Applications (ICSIPA 2019), Kuala Lumpur, Malaysia, 17–19 September 2019; IEEE: Washington, DC, USA, 2019; pp. 231–235. [Google Scholar]
- Deng, S.; Wei, M.; Wang, J.; Liang, L.; Xie, H.; Wang, M. DRD-Net: Detail-recovery Image Deraining via Context Aggregation Networks. arXiv 2019, arXiv:abs/1908.10267. [Google Scholar]
- Jiang, K.; Wang, Z.; Yi, P.; Chen, C.; Huang, B.; Luo, Y.; Ma, J.; Jiang, J. Multi-Scale Progressive Fusion Network for Single Image Deraining. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2020), Seattle, WA, USA, 13–19 June 2020; IEEE: Washington, DC, USA, 2020; pp. 8343–8352. [Google Scholar]
- Liu, Y.; Luo, Y.; Huang, W.; Qiao, Y.; Li, J.; Xu, D.; Luo, D. Semantic Information Supplementary Pyramid Network for Dynamic Scene Deblurring. IEEE Access 2020, 8, 188587–188599. [Google Scholar] [CrossRef]
- Yuan, Y.; Su, W.; Ma, D. Efficient Dynamic Scene Deblurring Using Spatially Variant Deconvolution Network With Optical Flow Guided Training. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2020), Seattle, WA, USA, 13–19 June 2020; IEEE: Washington, DC, USA, 2020; pp. 3552–3561. [Google Scholar]
- Ren, D.; Zuo, W.; Hu, Q.; Zhu, P.; Meng, D. Progressive Image Deraining Networks: A Better and Simpler Baseline. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2019), Long Beach, CA, USA, 16–20 June 2019; Computer Vision Foundation/IEEE: Washington, DC, USA, 2019; pp. 3937–3946. [Google Scholar]
- Suin, M.; Purohit, K.; Rajagopalan, A.N. Spatially-Attentive Patch-Hierarchical Network for Adaptive Motion Deblurring. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2020), Seattle, WA, USA, 13–19 June 2020; IEEE: Washington, DC, USA, 2020; pp. 3603–3612. [Google Scholar]
- Zhang, H.; Patel, V.M. Density-Aware Single Image De-Raining Using a Multi-Stream Dense Network. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2018), Salt Lake City, UT, USA, 18–22 June 2018; IEEE Computer Society: Washington, DC, USA, 2018; pp. 695–704. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.; Shao, L. Multi-Stage Progressive Image Restoration. arXiv 2021, arXiv:abs/2102.02808. [Google Scholar]
- Wei, W.; Meng, D.; Zhao, Q.; Xu, Z.; Wu, Y. Semi-Supervised Transfer Learning for Image Rain Removal. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2019), Long Beach, CA, USA, 16–20 June 2019; Computer Vision Foundation/IEEE: Washington, DC, USA, 2019; pp. 3877–3886. [Google Scholar]
- Li, X.; Wu, J.; Lin, Z.; Liu, H.; Zha, H. Recurrent Squeeze-and-Excitation Context Aggregation Net for Single Image Deraining. In Computer Vision—ECCV 2018, Proceedings of the 15th European Conference, Munich, Germany, 8–14 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Proceedings, Part VII; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2018; Volume 11211, pp. 262–277. [Google Scholar]
- Yasarla, R.; Patel, V.M. Uncertainty Guided Multi-Scale Residual Learning-Using a Cycle Spinning CNN for Single Image De-Raining. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2019), Long Beach, CA, USA, 16–20 June 2019; Computer Vision Foundation/IEEE: Washington, DC, USA, 2019; pp. 8405–8414. [Google Scholar]
- Purohit, K.; Rajagopalan, A.N. Region-Adaptive Dense Network for Efficient Motion Deblurring. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, Thirty-Second Innovative Applications of Artificial Intelligence Conference (IAAI 2020), Tenth AAAI Symposium on Educational Advances in Artificial Intelligence (EAAI 2020), New York, NY, USA, 7–12 February 2020; AAAI Press: Menlo Park, CA, USA, 2020; pp. 11882–11889. [Google Scholar]
- Chen, L.; Zhang, H.; Xiao, J.; Nie, L.; Shao, J.; Liu, W.; Chua, T. SCA-CNN: Spatial and Channel-Wise Attention in Convolutional Networks for Image Captioning. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; IEEE Computer Society: Washington, DC, USA, 2017; pp. 6298–6306. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE Computer Society: Washington, DC, USA, 2017. [Google Scholar]
- Zhang, Y.; Kong, J.; Qi, M.; Liu, Y.; Wang, J.; Lu, Y. Object Detection Based on Multiple Information Fusion Net. Appl. Sci. 2020, 10, 418. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.; Choi, J.; Cheon, M.; Lee, J. RAM: Residual Attention Module for Single Image Super-Resolution. arXiv 2018, arXiv:abs/1811.12043. [Google Scholar]
- Khan, S.; Naseer, M.; Hayat, M.; Zamir, S.W.; Khan, F.S.; Shah, M. Transformers in Vision: A Survey. arXiv 2021, arXiv:abs/2101.01169. [Google Scholar]
- Niu, B.; Wen, W.; Ren, W.; Zhang, X.; Yang, L.; Wang, S.; Zhang, K.; Cao, X.; Shen, H. Single Image Super-Resolution via a Holistic Attention Network. In Computer Vision—ECCV 2020, Proceedings of the 16th European Conference, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J., Eds.; Proceedings, Part XII; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12357, pp. 191–207. [Google Scholar]
- Hui, Z.; Wang, X.; Gao, X. Fast and Accurate Single Image Super-Resolution via Information Distillation Network. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2018), Salt Lake City, UT, USA, 18–22 June 2018; IEEE Computer Society: Washington, DC, USA, 2018; pp. 723–731. [Google Scholar]
- Hui, Z.; Gao, X.; Yang, Y.; Wang, X. Lightweight Image Super-Resolution with Information Multi-distillation Network. In Proceedings of the 27th ACM International Conference on Multimedia (MM 2019), Nice, France, 21–25 October 2019; Amsaleg, L., Huet, B., Larson, M.A., Gravier, G., Hung, H., Ngo, C., Ooi, W.T., Eds.; ACM: New York, NY, USA, 2019; pp. 2024–2032. [Google Scholar]
- Liu, J.; Tang, J.; Wu, G. Residual Feature Distillation Network for Lightweight Image Super-Resolution. In Computer Vision—ECCV 2020 Workshops, Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Bartoli, A., Fusiello, A., Eds.; Proceedings, Part III; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12537, pp. 41–55. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A Style-Based Generator Architecture for Generative Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2019), Long Beach, CA, USA, 16–20 June 2019; Computer Vision Foundation/IEEE: Washington, DC, USA, 2019; pp. 4401–4410. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016), Las Vegas, NV, USA, 27–30 June 2016; IEEE Computer Society: Washington, DC, USA, 2016; pp. 770–778. [Google Scholar]
- Shi, W.; Caballero, J.; Huszar, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016), Las Vegas, NV, USA, 27–30 June 2016; IEEE Computer Society: Washington, DC, USA, 2016; pp. 1874–1883. [Google Scholar]
- Huang, X.; Belongie, S.J. Arbitrary Style Transfer in Real-Time with Adaptive Instance Normalization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV 2017), Venice, Italy, 22–29 October 2017; IEEE Computer Society: Washington, DC, USA, 2017; pp. 1510–1519. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning (ICML 2015), Lille, France, 6–11 July 2015; Volume 37, pp. 448–456. [Google Scholar]
- Qiu, Z.; Yao, T.; Mei, T. Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV 2017), Venice, Italy, 22–29 October 2017; IEEE Computer Society: Washington, DC, USA, 2017; pp. 5534–5542. [Google Scholar]
- Tang, K.; Xu, D.; Liu, H.; Zeng, Z. Context Module Based Multi-patch Hierarchical Network for Motion Deblurring. Neural Process. Lett. 2021, 53, 211–226. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, C.; Maybank, S.J.; Tao, D. Self-supervised Exposure Trajectory Recovery for Dynamic Blur Estimation. arXiv 2020, arXiv:abs/2010.02484. [Google Scholar]
- Köhler, R.; Hirsch, M.; Mohler, B.J.; Schölkopf, B.; Harmeling, S. Recording and Playback of Camera Shake: Benchmarking Blind Deconvolution with a Real-World Database. In Computer Vision—ECCV 2012, Proceedings of the 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Fitzgibbon, A.W., Lazebnik, S., Perona, P., Sato, Y., Schmid, C., Eds.; Proceedings, Part VII; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7578, pp. 27–40. [Google Scholar]
- Shen, Z.; Wang, W.; Lu, X.; Shen, J.; Shao, L. Human-Aware Motion Deblurring. In Proceedings of the ICCV2019, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Yang, W.; Tan, R.T.; Feng, J.; Liu, J.; Guo, Z.; Yan, S. Deep Joint Rain Detection and Removal from a Single Image. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; IEEE Computer Society: Washington, DC, USA, 2017; pp. 1685–1694. [Google Scholar]
- Martin, D.R.; Fowlkes, C.C.; Tal, D.; Malik, J. A Database of Human Segmented Natural Images and its Application to Evaluating Segmentation Algorithms and Measuring Ecological Statistics. In Proceedings of the Eighth International Conference on Computer Vision (ICCV-01), Vancouver, BC, Canada, 7–14 July 2001; IEEE Computer Society: Washington, DC, USA, 2001; Volume 2, pp. 416–425. [Google Scholar]
- Fu, X.; Huang, J.; Zeng, D.; Huang, Y.; Ding, X.; Paisley, J.W. Removing Rain from Single Images via a Deep Detail Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; IEEE Computer Society: Washington, DC, USA, 2017; pp. 1715–1723. [Google Scholar]
- Schaefer, G.; Stich, M. UCID: An uncompressed color image database. In Proceedings of the Storage and Retrieval Methods and Applications for Multimedia 2004, San Jose, CA, USA, 20 January 2004; Volume 5307, pp. 472–480. [Google Scholar]
- Arbelaez, P.; Maire, M.; Fowlkes, C.C.; Malik, J. Contour Detection and Hierarchical Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 898–916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, H.; Sindagi, V.; Patel, V.M. Image De-raining Using a Conditional Generative Adversarial Network. IEEE Trans. Circuits Syst. Video Technol. 2017, 30, 3943–3956. [Google Scholar] [CrossRef] [Green Version]
- Fu, X.; Huang, J.; Ding, X.; Liao, Y.; Paisley, J.W. Clearing the Skies: A Deep Network Architecture for Single-Image Rain Removal. IEEE Trans. Image Process. 2017, 26, 2944–2956. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cai, J.; Zuo, W.; Zhang, L. Dark and Bright Channel Prior Embedded Network for Dynamic Scene Deblurring. IEEE Trans. Image Process. 2020, 29, 6885–6897. [Google Scholar] [CrossRef]
- Sun, J.; Cao, W.; Xu, Z.; Ponce, J. Learning a convolutional neural network for non-uniform motion blur removal. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2015), Boston, MA, USA, 7–12 June 2015; IEEE Computer Society: Washington, DC, USA, 2015; pp. 769–777. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Task | Deraining | Deblurring | |||||
|---|---|---|---|---|---|---|---|
| Datasets | Rain14000 [51] | Ranin100L [49] | Rain100H [49] | RainTest100 [54] | GoPro [9] | HIDE [48] | Kolher [47] |
| Train samples | 11,200 | 0 | 0 | 0 | 2103 | 0 | 0 |
| Test samples | 2800 | 100 | 100 | 100 | 1111 | 2025 | 64 |
| Methods | Rain100H [49] | Rain100L [22] | Rain14000 [51] | Test100 [54] | Ave. Inf. Time (s) | ||||
|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | ||
| DerainingNet [55] | 14.92 | 0.592 | 27.03 | 0.884 | 24.31 | 0.961 | 22.77 | 0.810 | - |
| SEMI [26] | 16.56 | 0.486 | 25.03 | 0.842 | 24.43 | 0.782 | 22.35 | 0.788 | 4.567 |
| DIDMDN [24] | 17.35 | 0.524 | 25.23 | 0.741 | 28.13 | 0.867 | 22.56 | 0.818 | 2.789 |
| UMRL [28] | 26.01 | 0.832 | 29.18 | 0.923 | 29.97 | 0.923 | 24.41 | 0.829 | 2.552 |
| RESCAN [27] | 26.36 | 0.786 | 29.80 | 0.881 | 31.29 | 0.904 | 25.00 | 0.835 | 1.530 |
| PreNet [22] | 26.77 | 0.858 | 32.44 | 0.950 | 31.75 | 0.916 | 24.81 | 0.851 | 0.760 |
| MSPFN [19] | 28.66 | 0.860 | 32.40 | 0.933 | 32.82 | 0.930 | 27.50 | 0.876 | 0.230 |
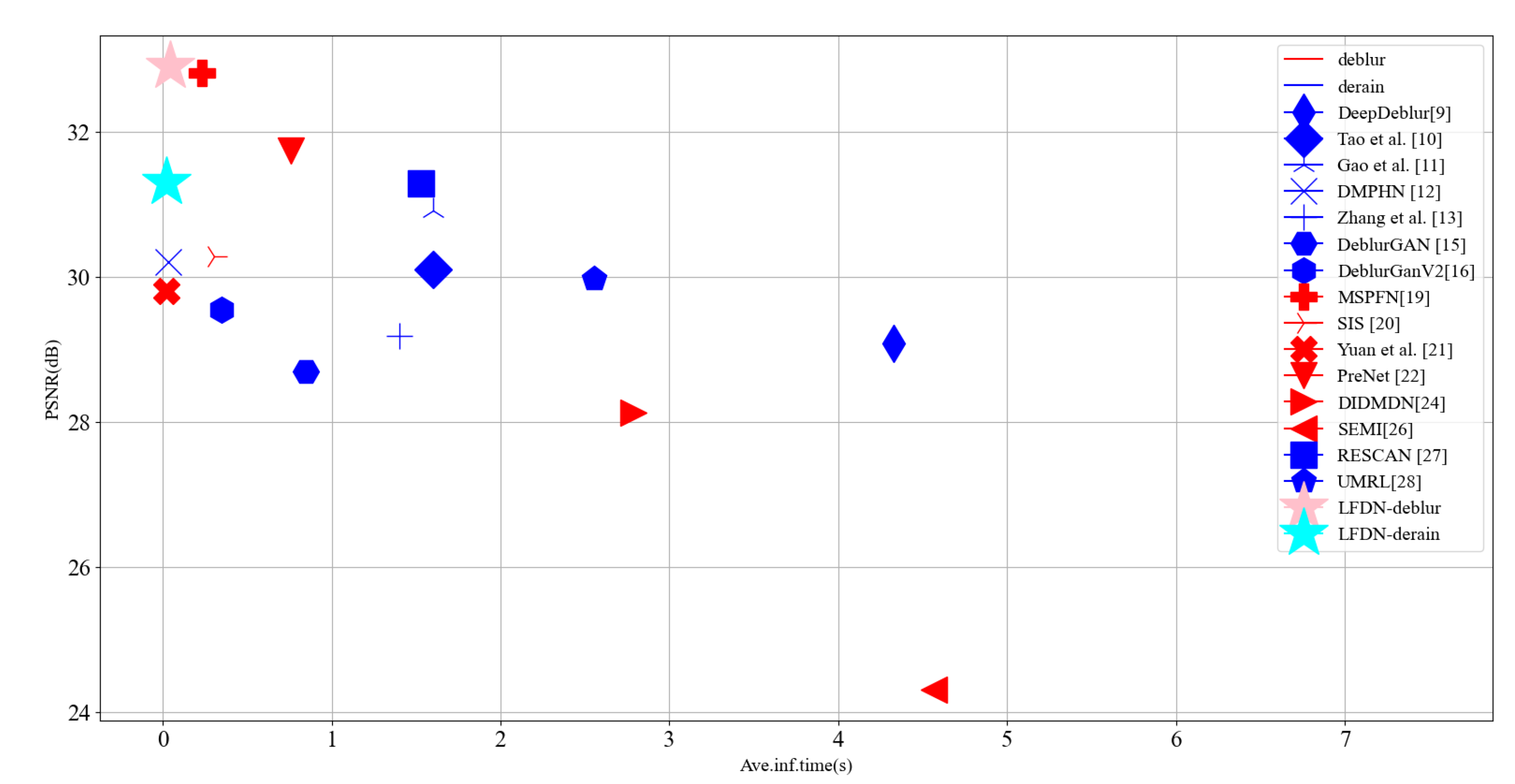
| LFDN (Ours) | 29.12 | 0.893 | 32.79 | 0.961 | 32.90 | 0.935 | 28.44 | 0.880 | 0.043 |
| Methods | PSNR | SSIM | Model Size (MB) | Ave. Inf. Time (s) |
|---|---|---|---|---|
| DeepDeblur [9] | 29.08 | 0.841 | 303.6 | 15 |
| Zhang et al. [13] | 29.19 | 0.9306 | 37.1 | 1.4 |
| Gao et al. [11] | 30.92 | 0.9421 | 2.84 | 1.6 |
| DeblurGAN [15] | 28.70 | 0.927 | 37.1 | 0.85 |
| Tao et al. [10] | 30.10 | 0.9323 | 33.6 | 1.6 |
| DeblurGANv2 [16] | 29.55 | 0.934 | 15 | 0.35 |
| DMPHN [12] | 30.21 | 0.9345 | 21.7 | 0.03 |
| SIS [20] | 30.28 | 0.912 | 36.54 | 0.303 |
| Yuan et al. [21] | 29.81 | 0.9368 | 3.1 | 0.01 |
| Tang et al. [45] | 31.13 | 0.9507 | 31.1 | 0.088 |
| Zhang et al. [46] | 31.05 | 0.9485 | 26.3 | - |
| LFDN (Ours) | 31.60 | 0.932 | 1.55 | 0.029 |
| Methods | PSNR | SSIM | Model Size (MB) | Ave. Inf. Time (s) |
|---|---|---|---|---|
| DeepDeblur [9] | 26.48 | 0.807 | 303.6 | 15 |
| Tao et al. [10] | 26.57 | 0.8373 | 33.6 | 1.6 |
| Zhang et al. [13] | 24.21 | 0.7562 | 37.1 | 1.4 |
| DeblurGAN [15] | 26.10 | 0.807 | 37.1 | 0.85 |
| DeblurGANv2 [16] | 26.97 | 0.830 | 15 | 0.35 |
| Cai et al. [56] | 28.92 | 0.893 | - | 1200 |
| Xu et al. [1] | 27.47 | 0.811 | - | 13.41 |
| LFDN (Ours) | 30.98 | 0.9032 | 1.55 | 0.029 |
| Methods | Sun et al. [57] | DeepDeblur [9] | Tao et al. [10] | Kupyn et al. [15] | Suin et al. [23] | DMPHN [12] | LFDN (Ours) |
|---|---|---|---|---|---|---|---|
| PSNR | 23.21 | 27.43 | 28.60 | 26.44 | 29.98 | 29.09 | 30.07 |
| SSIM | 0.797 | 0.902 | 0.928 | 0.890 | 0.930 | 0.924 | 0.932 |
| modle size (MB) | - | 303.6 | 33.6 | 37.1 | - | 86.8 | 1.55 |
| Ave. Inf. Time (s) | 23.45 | 4.33 | 1.6 | 0.85 | 0.77 | 0.98 | 0.029 |
| MSHF | FDNB | ALFM/ACFM | PSNR on GroPro | SSIM on GroPro | PSNR on Rain100H | SSIM on Rain100H | Model Size (MB) |
|---|---|---|---|---|---|---|---|
| X | X | X | 28.71 | 0.901 | 27.36 | 0.862 | 33.6 |
| X | ✓ | ✓ | 30.84 | 0.917 | 28.92 | 0.885 | 1.8 |
| ✓ | X (RFDB) | ✓ | 29.28 | 0.891 | 28.48 | 0.871 | 2.9 |
| ✓ | X (CNN) | ✓ | 28.56 | 0.882 | 28.04 | 0.867 | 4.3 |
| ✓ | ✓ | X | 31.01 | 0.921 | 28.98 | 0.886 | 2.4 |
| ✓ | ✓ | ✓ | 31.60 | 0.932 | 29.12 | 0.893 | 1.55 |
| 0.002 | 0.001 | 0 | −0.001 | −0.002 | −0.0015 | −0.0008 | |
|---|---|---|---|---|---|---|---|
| PSNR on GoPro | 31.48 | 31.51 | 31.51 | 31.56 | 31.55 | 31.60 | 31.23 |
| PSNR on Rain100H | 28.95 | 28.97 | 29.01 | 29.10 | 29.07 | 29.01 | 29.12 |
| 0.3 | 0.2 | 0.1 | 0 | 0.1724 | 0.1137 | |
|---|---|---|---|---|---|---|
| PSNR on GoPro | 31.37 | 31.55 | 31.48 | 31.25 | 31.60 | 31.53 |
| PSNR on Rain100H | 28.44 | 29.02 | 29.09 | 28.99 | 29.03 | 29.12 |
| Distillation Blocks Setting | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| PSNR on GroPro | 29.82 | 29.73 | 30.77 | 31.60 | 31.52 | 31.61 |
| PSNR on Rain100H | 28.03 | 28.14 | 28.88 | 29.12 | 29.11 | 29.13 |
| Model Size (MB) | 1.46 | 1.49 | 1.52 | 1.55 | 1.58 | 1.61 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Liu, Y.; Li, Q.; Wang, J.; Qi, M.; Sun, H.; Xu, H.; Kong, J. A Lightweight Fusion Distillation Network for Image Deblurring and Deraining. Sensors 2021, 21, 5312. https://doi.org/10.3390/s21165312
Zhang Y, Liu Y, Li Q, Wang J, Qi M, Sun H, Xu H, Kong J. A Lightweight Fusion Distillation Network for Image Deblurring and Deraining. Sensors. 2021; 21(16):5312. https://doi.org/10.3390/s21165312
Chicago/Turabian StyleZhang, Yanni, Yiming Liu, Qiang Li, Jianzhong Wang, Miao Qi, Hui Sun, Hui Xu, and Jun Kong. 2021. "A Lightweight Fusion Distillation Network for Image Deblurring and Deraining" Sensors 21, no. 16: 5312. https://doi.org/10.3390/s21165312
APA StyleZhang, Y., Liu, Y., Li, Q., Wang, J., Qi, M., Sun, H., Xu, H., & Kong, J. (2021). A Lightweight Fusion Distillation Network for Image Deblurring and Deraining. Sensors, 21(16), 5312. https://doi.org/10.3390/s21165312