1. Introduction
The world’s population has aged over the past few decades. In 2018, for the first time, there were more people aged 65 and over than those younger than five, and the elderly population is likely to have doubled by 2050 [
1,
2]. Moreover, in 2050, the 1.5 billion people older than 65 will outnumber those aged between 15 and 24. This dramatic increase in the elderly population is due to improved quality of life and better healthcare [
3,
4,
5,
6], especially the decrease in tobacco use in men and cardiovascular disease in recent decades [
3]. Another important factor that affects the growth of the elderly population is the falling birth rate; the average number of live births per woman was only 2.5 worldwide in 2019 and is likely to decrease further [
1]. Studies have shown that both high- and low-income countries are experiencing increased life expectancy [
4,
5].
Elderly people tend to live alone [
7,
8,
9,
10,
11]. For example, in the United States of America, the percentage of elderly people living alone was 40% in 1990 and 36% in 2016 [
12]. In the Republic of Korea, 22.8% of elderly people live alone, almost one in five [
8]. One of the reasons is that some elderly people prefer to preserve their privacy [
13,
14]. However, elderly people living alone are more susceptible to loneliness, illness, and home accidents than those who live with a partner or family [
9,
15]. Early detection of illness and home accidents is crucial if solitarily-living elderly people are to receive timely and potentially life-saving help [
16,
17].
As the latest technological development, the Internet of Things (IoT) enables consumers and businesses to have versatile devices connected to the Internet [
18,
19,
20,
21,
22]. In elderly care and monitoring systems, the use of the IoT is becoming prevalent [
23,
24,
25,
26], and monitoring the activities of daily living (ADLs) of elderly people is crucial in indicating their activity level [
27].
Previous studies have proposed elderly-monitoring systems based on wearable devices [
23,
28,
29,
30,
31,
32] with the main function of classifying the ADLs of elderly people. However, some people are uncomfortable with wearable devices, and if they choose to wear one, then the favorite part of the body for wearing it is the wrist [
33]. In addition to recognizing ADLs, crucial for monitoring elderly people living alone is detecting (i) abnormal activities such as falling [
34,
35], (ii) early signs of some diseases, and (iii) unusual instances for people with certain diseases [
28,
36,
37]. However, although wearable devices provide accurate information about motion, they are inconvenient for daily use because of the problems such as the need to attach sensors to the body or skin, battery life expectancy, and the probability of abandonment in case of curiosity [
38,
39,
40,
41]. Although many different activity classification methods have been suggested for wearable devices, the recent prominence of machine learning (ML) has caused researchers to focus in particular on human activity recognition (HAR) models based on deep learning [
38,
42,
43,
44,
45].
Camera-based monitoring systems [
38,
46,
47,
48,
49] solve the problem of having an inconvenient wearable device attached to one’s body or skin. Although various HAR models have been suggested for recognizing ADLs, those based on ML are now playing a major role [
22,
48,
49,
50,
51,
52]. An example is HAR based on a dynamic Bayesian network for detecting the abnormal actions of elderly people from camera video [
53]. However, although camera-based systems provide accurate information about human posture, privacy is a major concern [
54,
55,
56]. Moreover, previous research [
54] showed that elderly people tend to change their behavior once they are aware of the camera. To minimize the invasion of privacy associated with camera-based technology, low-resolution infrared or depth-camera systems have been suggested [
57,
58,
59,
60]. Privacy concerns mean that elderly people prefer to be monitored unobtrusively rather than by camera-based systems [
56].
One solution to the privacy issue is to install passive infrared (PIR) sensors in the living environment of the elderly to monitor elderly residents unobtrusively with an ADL classification model [
61,
62,
63,
64]. Previous research [
65] suggested a new smart radar sensor system that uses an ultra-wideband signal to detect motion. Such radar sensors have a low signal-to-noise ratio and are highly sensitive to environmental changes.
Various indoor activity detection models have been proposed [
66,
67,
68,
69,
70,
71,
72,
73], most of which use ML to recognize the activities. As stated in [
74], deep learning and RNN models have promising results and need to be investigated further for non-intrusive activity recognition. Open datasets from real-life scenarios are used to train and test these models, and the Aruba dataset from the Center for Advanced Studies in Adaptive Systems (CASAS) at Washington State University is often used [
75,
76].
The authors have published several studies [
55,
58,
77] used CASAS Aruba dataset, where [
55] detected travel patterns of a resident living alone using PIR binary sensory data [
55]; on the contrary, [
58,
77] detected the activities of a resident using converted temporal sensory events of each activity samples into an image that is fed into DCNN (Deep Convolutional Neural Networks). First, features are extracted with convolutional layers, and then activity is classified with FCNN (Fully Connected Neural Network).
The results of the current work proposed in this study outperformed the existing methods on the Aruba dataset [
62,
72,
78,
79]. None of the state-of-the-art (SoTA) methods tested on the Aruba dataset for ADL recognition use temporal features, in particular
previous activity and
begin time-stamp, which depend significantly on the current activity (see
Table 1 and
Figure 1).
Herein, we propose a deep-learning model for classifying ADLs from PIR binary sensor data. The model uses a bidirectional long short-term memory (Bi-LSTM), a type of recurrent neural network (RNN) and a fully connected neural network (FCNN) to extract features and classify activities, respectively. The work is not focused on generalizing the model over different houses and for residents with different habits.
The main contributions of this study are as follows:
Use of the external temporal features, previous activity and begin time-stamp, that are concatenated with extracted features by the Bi-LSTM before being fed into the FCNN for classification;
For Bi-LSTM, an input length is empirically determined to be 20 based on the highest accuracy;
F1 score difference between the models with/without external features was 28.8%;
A comparison study on the model’s different architectures, with/without external features and various number of nodes for Bi-LSTM, is conducted;
For a fair comparison, the proposed model is evaluated on the CASAS Aruba public dataset [
76];
The method outperforms the existing methods [
62,
72,
78,
79] with a relatively high
F1 score of 0.917, which is an improvement of 6.25% compared with the existing best
F1 score.
The rest of this paper is organized as follows.
Section 2 reviews other activity recognition methods, and
Section 3 describes the present method for recognizing ADLs.
Section 4 describes how the model was trained, tested, and compared with the other methods.
Section 5 discusses the results and
Section 6 presents the conclusions.
2. Related Works
Previous studies have proposed models that use ML to recognize and classify ADLs from the main data sources for doing so, namely wearable devices and smart homes equipped with depth cameras and binary sensors.
An algorithm [
31] was suggested for classifying six ADLs with two inertial measurement units. The algorithm has four stages, that is, filtering, phase detection, posture detection, and activity detection. It detects the body posture during static phases and recognizes types of dynamic activities between postures using a rule-based approach. The model achieves an overall accuracy of 84–97% for different types of activities. However, such methods require intensive handcrafting when other activities are added and are sensitive to distortion of input data. Deep-learning methods are used intensively to extract the features for activity recognition. Bianchi et al. [
32] proposed an HAR system based on a wearable IoT sensor, for which the feature extractor was a CNN. The model achieved an accuracy of 92.5% on a standard dataset from the UCI ML Repository. A previous study [
45] suggested a model that detects falling and its precursor activity from an open dataset. For classifying falls, the authors employed various methods that are support vector machines (SVMs), random forest, and k-nearest neighbors, which achieve
F1 scores of 0.997, 0.994, and 0.997, respectively, and for classifying the precursor activities, they achieve
F1 scores of 0.756, 0.799, and 0.671, respectively. The results of activity classification are not as good as those of other models. Furthermore, although the systems based on wearable devices provide accurate information about human activity, complications arise like (i) continuing to wear the device, (ii) maintaining battery level, and (iii) attaching the device to the skin.
Systems based on RGB (red–green–blue) cameras [
46,
47,
48] solve the aforementioned problems associated with wearable devices. In a previous study [
49], automated ML and transfer learning were used to detect ADLs by analyzing the video from an RGB camera. However, the use of RGB cameras raises privacy concerns.
Activity detection based on depth cameras is another popular method with high precision and less invasion of privacy compared to normal camera images. Anitha et al. [
53] proposed an elderly-monitoring system that detects abnormal activities such as falls, chest pain, headache, and vomiting from video sequences with a model based on a dynamic Bayesian network. Image silhouettes are extracted from a normal video sequence that is input to the model, and the model achieves an activity detection accuracy of 82.2%. Jalal et al. [
59] developed an HAR model using multiple hidden Markov models that are trained for each specific action. For training and recognizing, the model extracts the features from human depth silhouettes and body-joint information for human activities. The model achieved recognition accuracies of 98.1% and 66.7% on the MSR Action 3D open dataset and a self-annotated dataset, respectively. Hbali et al. [
51] presented a method that extracts a human-body skeletal model from depth-camera images, with the classifier being the extremely-randomized-trees algorithm. Although it does not outperform similar models, it provides the promising results with an accuracy of 73.43% on the MSR Daily Activity 3D dataset. Activity recognition systems based on depth cameras are applicable and preferable for the detailed activities such as arm waving or forward kicking, but they do not address the privacy issue fully.
Equipping the living environment of an elderly person with binary sensors invades her/his privacy less than the depth camera does, and it offers greater comfort by avoiding the need to support a wearable device. Yala et al. [
61] introduced several traditional ML methods preceded with different feature-extraction techniques, where the highest
F1 score among the experimented methods was 0.662. Machot et al. [
78] proposed an activity recognition model that finds the best sensor set for each activity. They used an SVM as the classifier and achieved an
F1 score of 0.82 on the Aruba dataset. Yatbaz et al. [
72] suggested two ADL recognition methods based on scanpath trend analysis (STA), one of which gives the highest
F1 score of 0.863 among the existing SoTA models [
62,
78,
79] that are tested on the Aruba dataset. Krishnan et al. [
64] proposed a term
previous activity in their two step activity recognition method.
However, none of the aforementioned methods, except [
64], use temporal features such as
begin time-stamp and
previous activity.
Figure 2 represents the prominence of external features with stacked column chart, from correlation matrix of feature elements, where vertical axis represents the sum of absolute values of each element for the matrix columns, extracted and external features. External feature elements, with smallest values in the chart, shows that they have less correlation with other features. Our proposed model concatenates these temporal features,
begin time-stamp and previous value, with the features extracted by the RNN, and it outperforms the existing SoTA models with an
F1 score of 0.917 on the Aruba dataset.
3. Methods
The proposed model uses Bi-LSTM, a type of RNN, to extract the feature vectors from an input data sequence, which are then combined with external features including
previous activity and
begin time-stamp. The activity recognition is performed by an FCNN. The model structure is empirically selected from extensive experiments over on different combinations of modules (See
Section 4.5 and Table 7).
3.1. Model Architecture
Figure 3 shows the architecture of the proposed model, where a pre-processed sequence of sensor data
iT = {
i0,
i1,
i2, …,
i19} (see
Section 3.3) is inputted to a Bi-LSTM, which consists of an RNN with 60 nodes. Sensors does not send sensor status with consistent frequency. Instead, they send sensor events with “ON” and “OFF” message upon activations. Therefore, the length of the sensor data sequence is inconsistent for activity instances. In order to align data sequence length, zero padding is used in front of the data when the size is less than 20. For sequences longer than 20, the last 20 elements in the sequence form the input data, formulated as follows:
where
s is the activity sequence with length
l.
The vector z represents the zero padding which converts the length of the input sequence to 20 if it was shorter than 20.
Empirically, we chose Bi-LSTM over LSTM because of the higher performance, where
F1 score LSTM is 0.842 (See Table 7). Moreover, the number of nodes (60) was chosen empirically at the value where the
F1 score is stabilized (
Figure 4). Because the RNN is bidirectional (Bi-LSTM), its output dimensionality (120) is twice its number of nodes (60).
The output vectors of the Bi-LSTM form a matrix B, where each row represents a feature value and each column is a feature vector generated by the Bi-LSTM from the corresponding element of the input sequence. Therefore, the size of matrix B (120 × 20) is the result of the 60 nodes of the Bi-LSTM and 2 time steps in the input.
On top of this, the feature vector is formed by selecting the maximum value by the max-pooling layer from each row of matrix
B. This eliminates the time-step dependency of the features for an activity and selects the maximum value of the feature after taking the whole sequence into account. Each element of the feature vector is selected as
where
k is the number of elements in the vector, which is the same as the row number of rows of
B.
The external feature vector
e consists of
previous activity p and
begin time-stamp ts [Equation (3)]. Vector
e and the extracted feature vector m are concatenated to form vector
d [Equation (4)], which is then fed into the FCNN classifier:
Previous activityp is given in 9 × 1 one-hot vector form where each element represents an activity.
Begin time-stamp ts, the beginning hour of the activity, corresponds to the current activity, whereas current activity is known to be dependent on
previous activity.
Table 1 tabulates the number of
previous activities’ instances with respect to the current activity in the balanced dataset, where the values present a clear association between the current activity and those that preceded it; for example, Sleeping happens mostly before Bed_to_Toilet. Moreover, the stacked column chart of absolute values (
Figure 2) from the correlation matrix for all features, including extracted and external, reveals that
previous activity vector elements and
begin time stamp are less correlated to other features.
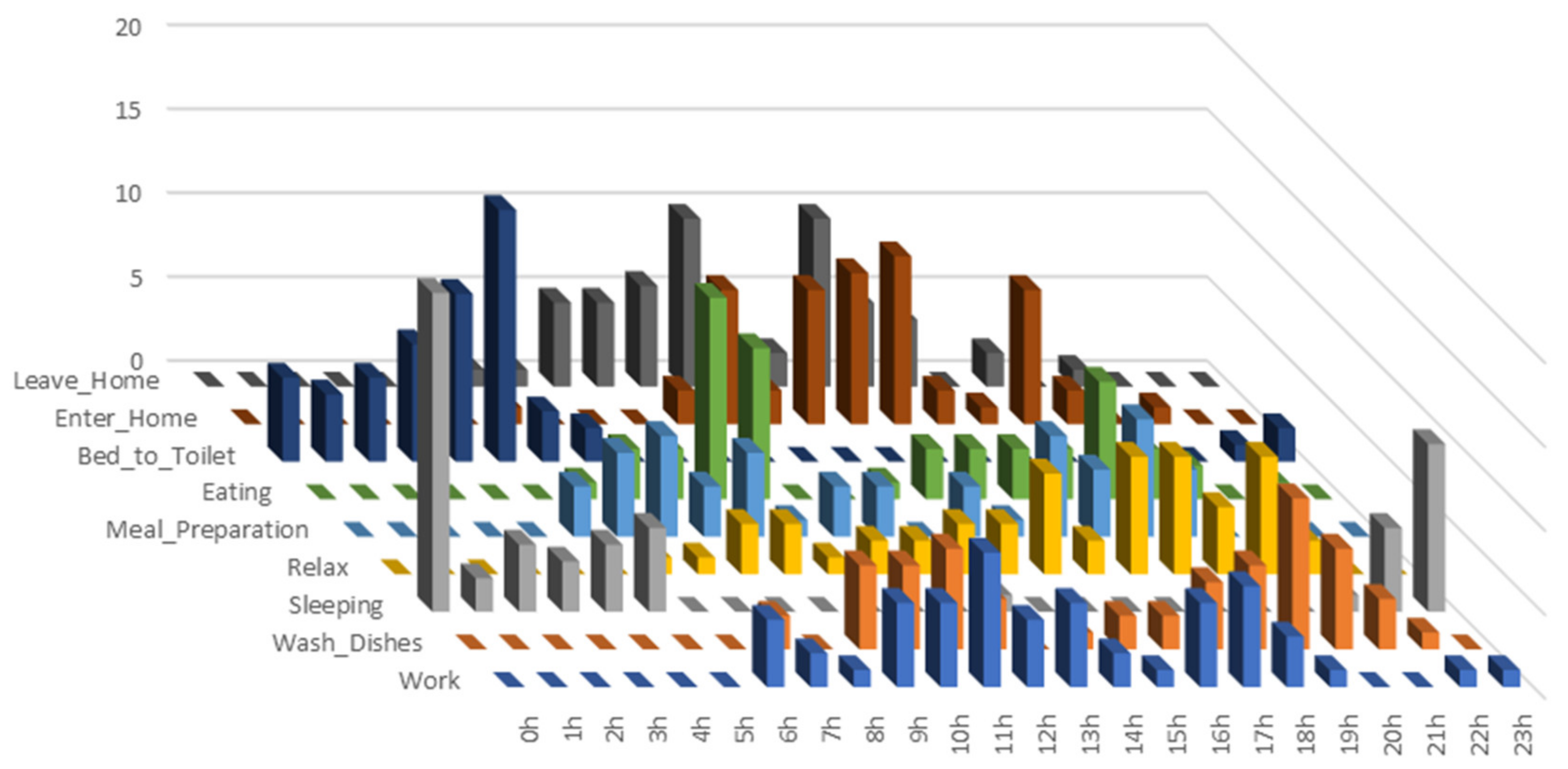
The number of instances of
begin time-stamp in terms of daily hours is represented in
Figure 1, where the three-dimensional graph exposes the associations between activities and their starting time interval.
The FCNN executes the classification and consists of a 50-node hidden layer and a nine-node output layer. Activation functions of the hidden and output layers are ReLu and Sigmoid, respectively. The input vector
d consists of three elements [Equations (3) and (4)]: the feature vector
m, the
previous activity p, and the
begin time-stamp ts. The fully connected classification network is defined as
where
ah and
ao are the outputs of the hidden and output layers, respectively, of the network.
3.2. Dataset
We used Aruba open data set from CASAS smart home project [
76] to train and evaluate our model. CASAS assembled 64 open datasets from equipped smart houses inhabited by single or multiple residents for certain amounts of time. Its inhabitancy duration and frequent use in model evaluations led us to use the Aruba testbed dataset in the present work. As shown in
Figure 5, Aruba is a smart house in which an elderly lady lived alone for seven months. This house is equipped with 31 wireless binary motion sensors, four temperature sensors, and four door sensors. Because we used only motion sensor data, from all 31 motion sensors and four door sensors, the temperature sensors are not depicted in
Figure 5 [
77].
The open dataset is formatted as shown in
Figure 6, where each instance consists of date, time, sensor status, and annotations. The dataset is a list of actions lasting for 219 days from 4 November 2010 to 6 November 2011, and it comprises 1′719′557 registered events in total.
Figure 6 lists the sensor instances of two actions, namely Sleeping and Bed_to_Toilet, which happened during the night of 15 May 2011. Here, the activity Bed_to_Toilet happens between two Sleeping activities, which is intuitive.
3.3. Preprocessing of Dataset
For a fair comparison, we used the same data preprocessing method as the one described in [
72]. The Aruba dataset contains 1′719′557 raw sensor samples in total. First, we removed all irrelevant samples, i.e., temperature sensor samples, from the dataset, leaving 1′602′981 samples. Moreover, for the sake of formatting, the door sensor statuses of “OPEN” and “CLOSE” were replaced with “ON” and “OFF”, respectively. Various incorrect labels of the sensor status “OFF” (e.g., “OF” and “OFF5”) were replaced with “OFF”. After these steps, the external features, i.e.,
previous activity and
begin time stamp, of each activity, are extracted from the dataset and merged with sensory data of each activity instances. We employed 10-fold cross-validation to evaluate the proposed method, ignoring the activities of Housekeeping and Respirate because they had only 33 and six samples, respectively. The Aruba dataset is imbalanced in terms of the number of samples for each class, ranging from six to 2919 as shown in
Table 2. To balance the dataset, 60 samples were selected randomly from each class; thus, six samples were allocated for each fold. Therefore, for each fold evaluation, 90% (54 samples) and 10% (six samples) of the particular class samples were used as the training set and the testing set, respectively.
Figure 7 represents a
F1 scores vs. input data length graph. Empirically, the highest
F1 score of 0.917 is given against input data length of 20. Therefore we set the input data length as 20 for reducing the computational complexity. In case of the data length of an activity which is less than 20 zero padding is used to fit the sequence to the model input.
3.4. Evaluation Measures
Via one of the most commonly used model-validation techniques, we used stratified 10-fold cross-validation to assess our model. For a fair comparison, we selected 60 samples randomly from each activity sample set, resulting in 540 random samples in total. The selected sample set was partitioned into two subsets, namely the training set and the testing set, with 90% and 10%, respectively, of the samples of each activity. Therefore, 54 and six samples were allocated for train and test sets, respectively.
The proposed model was evaluated in terms of the following measures: Recall, Precision,
F1 score, Specificity, Accuracy, and Error. These measures were calculated from the model’s numbers of true and false prediction: TP (true positive), TN (true negative), FP (false positive), and FN (false negative) [
62]. Evaluation scores of the model are averaged scores from the results of five different models trained and tested on five different sample sets.
3.5. Technical Specifications
Model training was performed on a DGX1 supercomputer, whereas the testing was performed on an ordinary server computer. The server computer was a Dell Workstation 7910 with a six-core Intel(R) Xeon(R) CPU E5-2603 v3 @ 1.60 GHz, 16 GB RAM, and GTX Titan X GPU.
5. Discussion
Concatenating the external features of previous activity and begin time-stamp to the extracted features from Bi-LSTM gives remarkable results on classifying ADLs from binary sensor data. Our model outperforms all the SoTA models on the Aruba testbed dataset, where its F1 scores range between 0.821 and 0.998 with an average of 0.917.
The model predicts some activities much better than do other models, such as Meal_Preparation, Eating, Wash_Dishes, Enter_Home, and Leave_Home, because of adding extra features, especially
previous activity. For example, the Enter_Home activity is classified with 99.96% accuracy (
Table 3) because it always occurs after Leave_Home.
We chose to have 60 nodes in the Bi-LSTM as a trade-off between computational complexity and accuracy (see
Figure 4). As it can be seen from
Table 7, the
F1 score of the model decreases to 0.905 and 0.855 when only 50 and 20 nodes are respectively used.
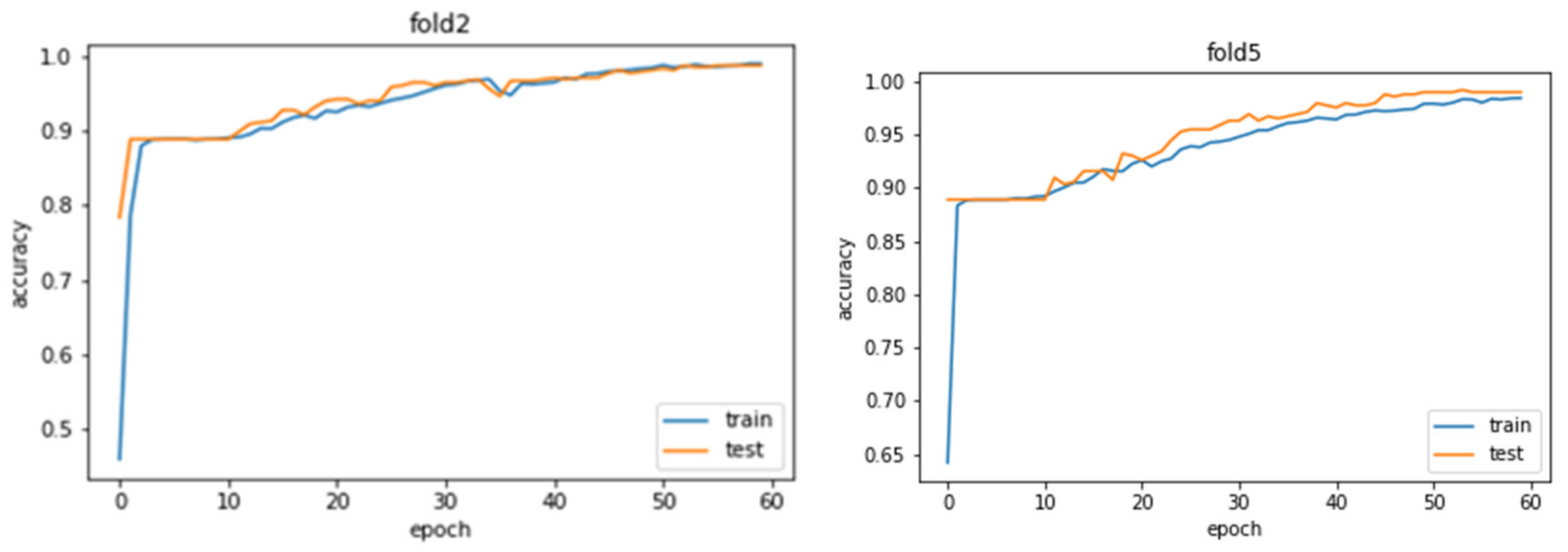
Training and testing accuracy and loss graphs represent good fit of the model by converging and having high values greater than 0.9 for accuracy and low values, less than 0.1, for loss function (
Figure 8).
The worst activity recognition of our model is on Wash_Dishes with an
F1 score of 0.821; nevertheless, this is 0.12% and 3.92% higher than the average
F1 scores of existing models [
62,
78], respectively.
The model is tested on remaining dataset which was not part of the balanced dataset to train and test the model. Instead of taking F1 score as the main measure, the performance measure Recall represents reasonable results since the remaining part of the dataset is imbalanced.
The model is evaluated with a predicted (not the ground truth)
previous activity feature on weekly activity sequences to simulate a real-life scenario activity recognition (
Table 6), as well. The results show a reasonably high Recall of 0.927. However, as expected, the best and worst Recall measures were degraded down 2.14% and 15.54%, respectively, compared to the model performance with ground truth
previous activity feature (
Table 5).
As well as outperforming the SoTA models, the classification latency of the proposed model is less than 30 ms, which is fast enough for an IoT-based real-time privacy-preserving activity recognition system.
The model’s worst performance is on classifying between the activities of Meal_Preparation and Wash_Dishes due to the two actions occurring in the same location in the house, namely the kitchen. This classification could be improved by placing other sensors (e.g., temperature, humidity) in the kitchen.
Although the external feature
begin time-stamp improved the performance of the model, its contribution to the
F1 score was not as great as that of the external feature
previous activity (
Table 7). Despite the fact that the external feature
previous activity has prominent effect on the model performance, it might mislead to misclassification when wrong
previous activity is generated automatically from previous step of classification.
Due to lack of similar datasets, our model is trained and tested only on CASAS dataset. If the model is employed to classify daily activities of a new resident, it is necessary for the model to have a learning phase in order to capture the resident’s daily activity pattern.



 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}