1. Introduction
Mobile communication systems can ensure command and control and other information transmission in army mobile warfare [
1,
2,
3]. It can connect various reconnaissance systems, information processing systems, command and control systems and weapon systems scattered across land, sea, air and outer space in order to realize situation sharing and collaborative control among various elements of the battlefield [
4,
5,
6]. Different mobile communication systems support different combat missions and serve different objects, and their network structures; interconnection modes and monitoring modes are also different [
7,
8,
9,
10]. The mobile communication system organization of the army synthetic division or brigade troops in complex terrain environments generally utilizes ultra-shortwave radio, shortwave radio, trunked mobile communication system and satellite communication. They can form a multi-layer network in order to meet the needs of information transmission of different levels of users.
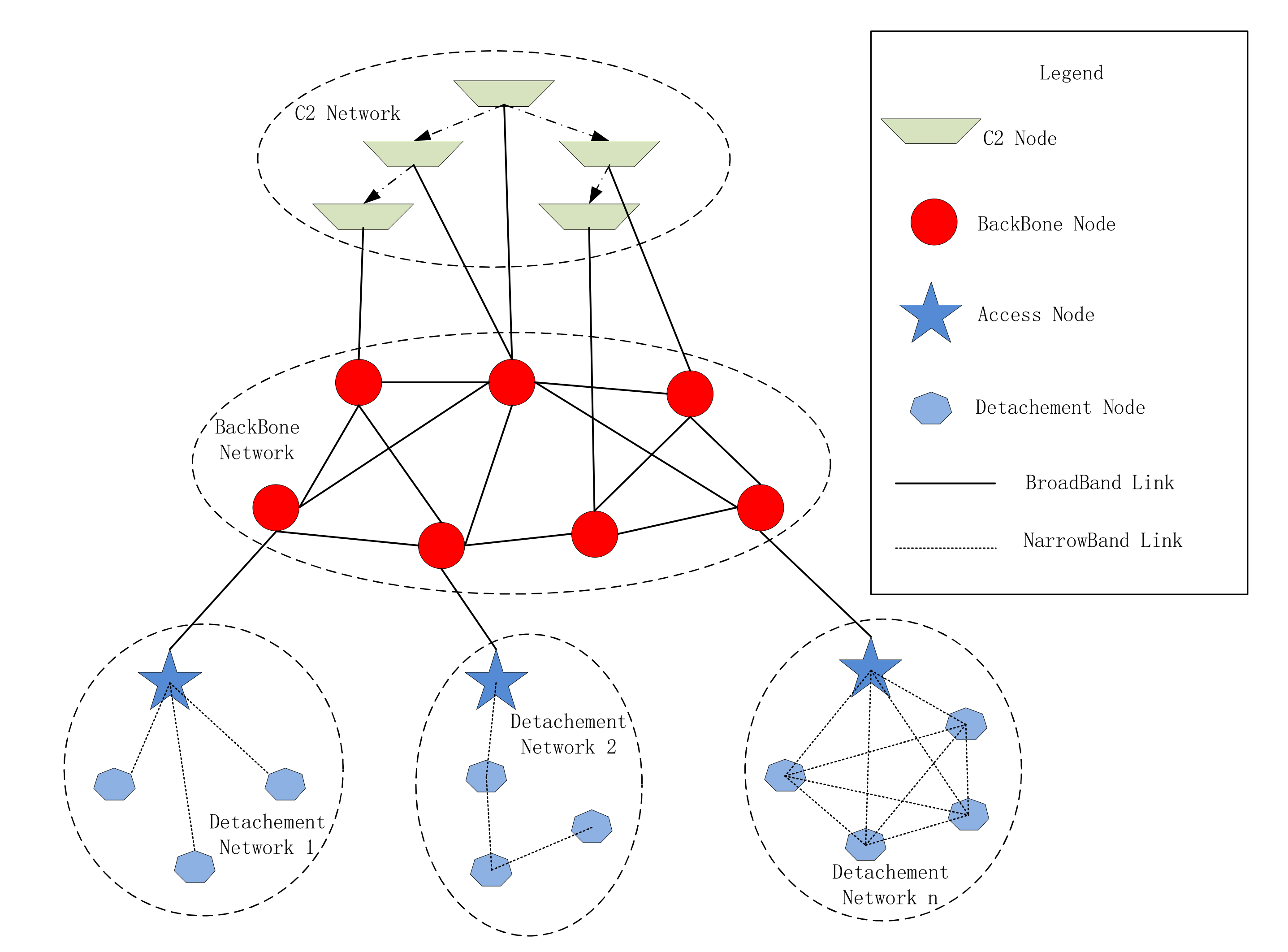
Figure 1 shows a network structure of a real war-game performed in Northern China of a synthetic brigade. This Figure is based on the static network loop model of Xue et al. [
11] and Jeffrey R. Cares [
12].
At the same time, the network structure will be changed according to the combat mission, the number of participating units, terrain restrictions, the number of equipment and other conditions. Different network structures will also result in different network planning parameters, such as network routing, access mode, subnet frequency distribution, encryption mechanism and key distribution method. For example, in
Figure 1, the broadcast protocol is selected in detachment network 1, while detachment network 2 selecs peer-to-peer protocol to form a chain network, and detachment network n selects the Carrier Sense Multiple Access (CSMA) protocol in order to form a fully connected network. Therefore, designing and planning the network completely based on human efforts will be very complicated.
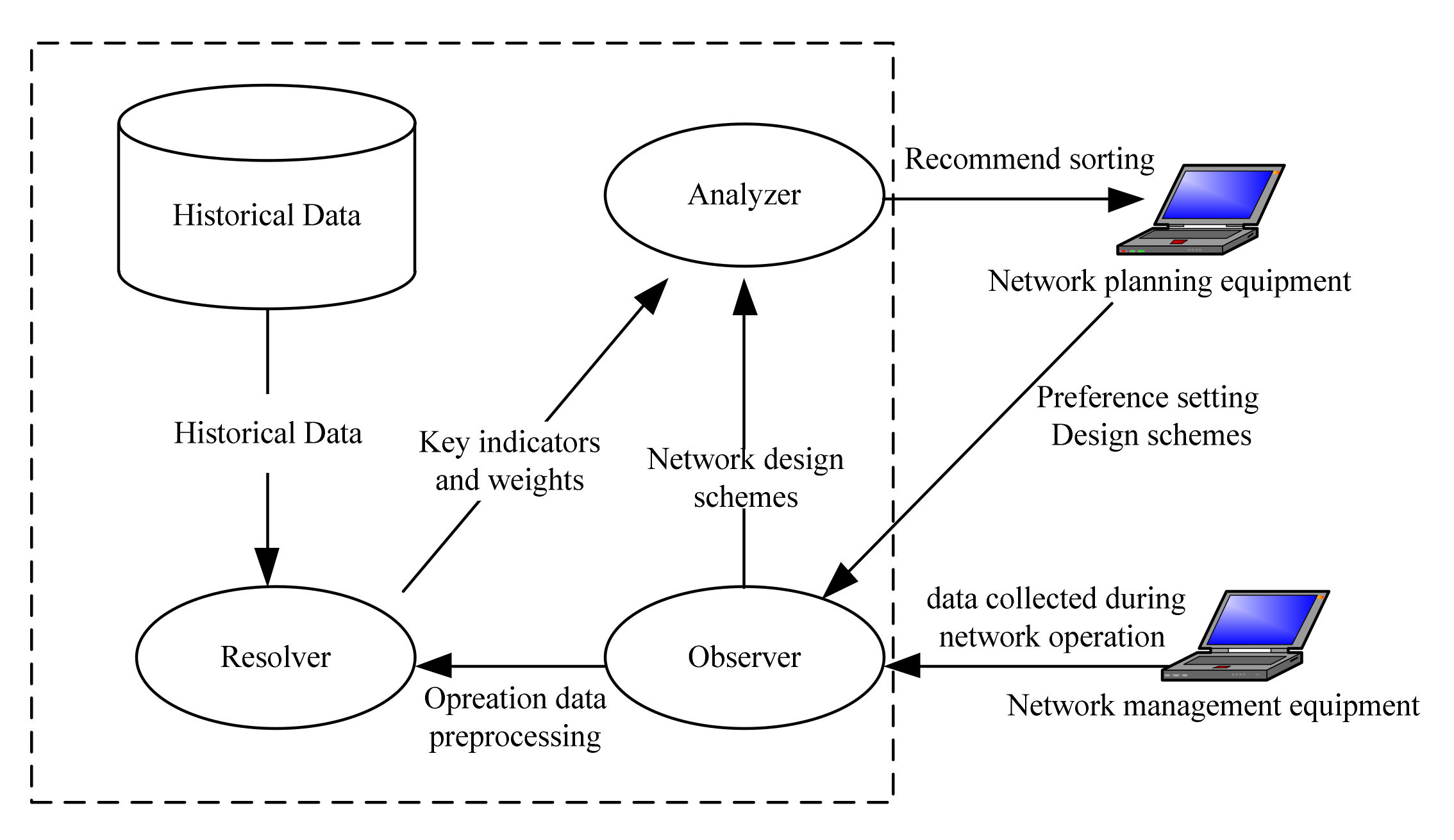
We study a semi-automatic network planning assistant optimization system for the mobile communication network of army divisions or brigade troops. As shown in
Figure 2, the system is connected with network planning equipment and network management equipment of mobile communication system. The system uses multi-agent system technology to simulate and evaluate the network design schemes generated by network planning equipment and finally generates the preferred ranking scheme for network planning equipment [
13]. The modules related to the content of this paper include three agents (Observer, Resolver and Analyzer) and a historical database.
The observer is used to receive and preprocess data and is the interface of external information input. Its main task is to receive the network design schemes and preference setting input by network planning equipment and to export the schemes to the Analyzer. In addition, it also receives the real operation data of the actual operation process of the network imported from the management equipment and exports the operation data to the Resolver after simple preprocessing.
The Resolver is used to analyze historical data, and it is also the implementation part of the effectiveness evaluation method based on factor analysis in this paper. It mainly carries out factor analysis on historical data in order to determine the key parameters and weights.
The Analyzer is used to simulate and deduce the network design schemes. It mainly deduces the schemes and obtains a little bit of statistics according to the key parameters determined by the Resolver. After each scheme is simulated, quantitative calculation is carried out according to the weight determined by Resolver and the schemes are sorted according to the preferences.
Based on the above network planning assistant optimization system design, the mobile communication system networking scheme needs to be evaluated quickly and recommended in the order of the decision makers’ preferences. Therefore, there is an urgent need for a fast, objective and favorite-supporting network effectiveness evaluation method [
14,
15,
16,
17].
The general definition of effectiveness is that the system or equipment can achieve the expected use target ability under the specific use conditions and within the specified time [
18,
19]. However, the mobile communication system faces many tasks, which presents some characteristics such as diversity, complexity and science. Many scholars have performed relevant research and proposed evaluation methods and ideas for communication systems under different tasks and application scenarios. Some effective and typical evaluation methods and models can be summarized as follows: generalized index method; principal component analysis method [
20,
21]; analytic hierarchy process (AHP) method [
22,
23]; fuzzy comprehensive evaluation method [
24,
25,
26]; grey correlation analysis evaluation method [
27]; neural network [
28,
29,
30]; and ADC method [
31]. These methods have certain effects on effectiveness evaluation and are usually used with different synthetic strategies to solve different types of problems. For example, the reference [
32] evaluated the security of the LTE-R communication system with AHP and the fuzzy comprehensive evaluation method and achieved the security status objectively and reasonably. Aiming at the multicriteria decision making (MCDM) problems, reference [
33] used the fuzzy grey Choquet integral (FGCI) method to evaluate MCDM problems with many interactive and qualitative indexes; this method can reduce the influence of experts’ subjective preference. The reference [
34] combines AHP, grey correlation technique and TOPSIS to solve the problem of green decoration materials selection, this method can obtain the weight vector of hierarchical index structure reasonably. However, the evaluation index system is difficult to construct in complicated problems. The reference [
35] uses the data envelopment analysis (DEA) model to describe undesirable indicators and to obtain more reasonable results with Shannon’s entropy in order to assess the operational efficiency of public bus transportation. Furthermore, when considering the communication system effectiveness evaluation, the large number of influencing factors and their complex relationship renders this type of work difficult. The reference [
36] used an analytic network process (ANP) to aggregate and calculate complex indicators in order to solve the problem that the dependency of elements within the hierarchy and the feedback influence of lower elements on upper elements should be considered in a complex system. The reference [
37] proposed a robust mobility management scheme for (TCN) and developed a physical test-bed environment. It used service availability, network throughput and first recover packet arrival time in order to evaluate the effectiveness of the management scheme. The reference [
38] proposed a fast algorithm for performance analysis for optimizing tactical communications networks in a timely fashion. For each class of traffic, this paper discussed three measures and analytical algorithms for performance ability evaluation, such as average call-arrival rate, average call-holding time and service priority. The reference [
39] proposed a unified T&E framework for the test and evaluation of the tactical communication networks. It studied a visual and modular radio software programming tool that supports easy and fast test and evaluation ranges from simulations to the use of over-the-air wireless testbeds and hardware-in-the-loop network emulation tests.
Therefore, it can be observed that there is currently no unified and fixed mode for the evaluation of tactical mobile communication networks, and the selection of evaluation methods and indicators is largely related to the tasks undertaken; however, simple and rapid evaluation methods are focuses of research. In addition, most of these studies used the method of simulation, statistically calculated the indexes according to the comparison matrix or weight [
40,
41,
42] and then evaluated the advantages and disadvantages of the system according to the comprehensive score results [
43,
44]. None of these approaches takes full advantage of the historical data of network operation. These historical data, which are recorded through previous exercises and task implementation, possess real network guarantee situations and task completion effect evaluation, and the historical possess great reference value. However, the amount of historical data is very large, and the evaluation conclusion must be generated quickly in the process of network scheme design and optimization; thus, we have to convert the large amount of data into fewer and easier to calculate indicators and algorithms. Factor analysis can transform a large amount of data into a small number of independent factors. These independent factors can reflect most of the information of the original data, which is within the scope of a reasonable research idea.
Factor analysis is a multivariate statistical method that extracts public factors from the evaluation data set and describes the original variables with public factors [
45]. It is an objective evaluation method completely starting from the data set, which can better overcome the influence of personnel’s subjective consciousness and improve the objectivity and science of the evaluation conclusion [
46].
The factor analysis model is defined as a linear model showing the relationship between common factors and variables. In general, the factor analysis model is shown with Equation (1).
The matrix form is expressed as follows:
where
,
…
represents random data of
p original indexes and
,
…
are the extracted common factor scores that are unobservable random variables.
ε is the special factor and represents the part that cannot be explained by common factors. The coefficient
aij is the factor loading and its size indicates the importance of the common factor relative to the original indexes [
47].
Data dimensionality reduction cannot reduce the collection of original data but also brings in the complexity of calculation. However, the mobile communication system networking scheme needs to be evaluated quickly and recommended in the order of the decision makers’ preferences. Therefore, there is an urgent need for a fast, objective and favorite-supporting network effectiveness evaluation method.
The main contributions of this paper can be summarized as follows:
We study an effectiveness evaluation method of mobile communication network design schemes and propose a design scheme for the evaluation and optimization of network plans.
We propose an improved method of effectiveness evaluation based on factor analysis. It can not only effectively use the historical data but also greatly reduce the amount of data collection and calculation.
We propose a decision preference setting method based on cluster analysis.
The rest of the paper is structured as follows:
Section 2 presents the background for our paper.
Section 3 introduces the traditional effectiveness evaluation method of factor analysis.
Section 4 proposes an improved method of effectiveness evaluation based on factor analysis and verifies its validity by an example.
Section 4 proposes a decision preference setting method based on cluster analysis.
Section 5 Synthesizes the above studies and provides the detailed process of effectiveness evaluation of mobile communication network design schemes.
Section 6 concludes this study and mentions future research implications.
3. An Improved Effectiveness Evaluation Method Based on Factor Analysis
3.1. Traditional Factor Analysis
By using this process, we have obtained the evaluation data for each application of the Tactical Mobile Communications System. We collected 31 groups of real data from participating units in several war-games performed in Northern China. In analyzing the eight evaluation indexes, data standardization is required prior to the evaluation because the dimensions and numerical ranges expressed are different.
Data standardization includes assimilation processing and dimensionless processing [
50,
51]. The assimilation processing of indexes is also called forward processing [
52]. In the evaluation, the larger the value of some indexes, the better the effectiveness is. In some situations, the larger the value of some indexes, the worse the effectiveness is [
53]. Moreover, the closer some indexes are to the middle range, the better the effectiveness is and the more they are above or below the middle range, the worse the effectiveness is [
54].
We first process the collected evaluation data into the assimilation matrix. Then, the Z-core method is adopted to conduct dimensionless processing on the data set, and the data set shown in
Table 2 is obtained. All calculation and analysis diagrams in this paper are produced by R of version 3.6.3.
The KMO value is 0.788 ≥ 0.5 and Bartlett value is 0.000 ≤ 0.05, which meets the criteria, indicating that the data set is suitable for factor analysis.
From the data set in
Table 2, the eigenvalues of the correlation coefficient matrix are 5.1925, 1.2606, 0.6471, 0.3883, 0.2346, 0.1462, 0.0879 and 0.0428. By calculating the variance contribution rate of the factor, we observe that the cumulative variance contribution rate of the first three factors is more than 85%. Therefore, the first three components were selected as the main factors for factor analysis.
According to the eigenvectors corresponding to the selected factors, the non-rotated factor loading matrix on the left side of
Table 3 is generated.
Factor loading is one of the important indexes in factor analysis, and it is the data source of factor naming. It can be observed from the
Table 3 that the loading of factor 1 on most indexes is large, which indicates that factor 1 is an important comprehensive factor. However, some indexes, such as
X7, have larger loads on factor 1 and factor 2, which cannot directly explain the factors. It is necessary to rotate the factor load matrix so that indexes can only show a larger load on one factor and a smaller load on other factors.
The orthogonal rotation method of maximum variance is used to rotate the data to obtain the factor loading on the right side of
Table 3.
It can be observed from the factor load matrix after rotation in
Table 3 that factor 1 has larger loads on indexes
X2,
X3,
X7 and
X8, which indicates that factor 1 mainly reflects the characteristics of four indexes: network throughput, end to end average delay, voice interruption rate and voice link building time. According to the specific meaning and characteristics of these indexes, factor 1 is named as the information transmission factor.
Factor 2 has a larger load on indexes X4, X5 and X6, which indicates that factor 2 mainly reflects the characteristics of three indexes: ‘network state perception’, ‘timeliness of network adjustment‘ and ‘success rate of temporary network access‘. According to the specific meaning and characteristics of these indexes, factor 2 is named as network control factor.
Factor 3 has a larger load on index X1, which indicates that factor 3 mainly reflects the characteristic of information encryption intensity. According to the specific meaning of the index, factor 3 is named as security protection factor.
Next, we used the Bartlett factor scoring method to calculate the score of the rotated factor and obtained
Table 4.
The factor score is the sum of the product of the standardized index value and the score coefficient. For example, the score of factor 1 is as follows:
Other factor scores were calculated similarly and scores of each factor can be obtained. By using the following equation to calculate the overall score, the calculated results are shown in
Table 2.
is the factor score,
is the factor variance contribution rate and
is the cumulative variance contribution rate of factors.
3.2. Analysis on the Importance of Evaluation Index
The square sum of the loads of the
ith index on all m factors is called the commonness of the index [
55], which reflects the effect of the index on all factors, that is, the importance of each original index. The calculation expression is shown as follows.
aij is the load of the
ith index on the
jth factor,
m is the number of factors and
p is the number of original indexes.
By comparing the commonness of the indexes, we can observe which variable plays a greater role. Therefore, the commonality of all variables can be normalized to the weight of the variable.
is commonness of the index
i and
p is the number of original indexes.
According to the factor loading matrix of
Table 3, the weight of each index can be calculated as shown in
Table 5.
According to the data in
Table 5, the top four indexes in terms of weight are as follows: Voice link building time, information encryption intensity, end to end average delay and network state perception. By observing the factor load after rotation in
Table 5, it can be observed that the load of the ‘voice link building time’ index is 0.9032, 0.3425 and 0.1302, respectively. This means that this index has a higher influence on the three factors. Similarly, the reason why
X3 and
X4 have higher weights is that they have higher influence factors among the three factors. The load of
X1 index in three factors is 0.0833, 0.1625 and 0.9299, which means that this index has a higher influence on the second and third factors.
3.3. Correlation Analysis
Previously, factor 1 has been named as the information transmission factor, which is mainly determined by index X2, X3, X7 and X8. Factor 2 is named as the network control factor, which is mainly determined by index X4, X5 and X6. Factor 3 is named as the security protection factor, which is mainly determined by index X1.
In order to ensure that there is no information overlap between the selected indexes, the correlation analysis of the main indexes of each factor is further screened. The correlation coefficients of factors 1 and 2 are shown in
Table 6 and
Table 7.
The correlation between X3 and other indexes is greater than the critical value (0.5), which indicates that the end-to-end transmission delay (X3) of the system has a strong correlation with the network throughput (X2), voice interruption rate (X7) and voice link building time (X8). Moreover, the correlation coefficient between the end-to-end transmission delay (X3) and voice link building time (X8) is the largest. In fact, these two indexes are the measurements of system transmission from two different scenarios. The end-to-end transmission delay is the average transmission delay of fixed length packets between any node in the network. The voice of the system studied is based on VoIP, and the time from call initiation to successful chain construction is roughly equal to the sum of the transmission delay of call instruction packets between source and destination. Therefore, it has a strong correlation. Considering that the voice link establishment time (X8) includes the end-to-end data transmission process from the link establishment process, additionally, the comprehensive weight of index X8 in the importance analysis of the last section is the largest, and the influence on the three factors are large. Thus, the index X8 is retained and the index X3 is discarded.
Similarly, the correlation between X2 and X8 is also large, and the correlation coefficient is 0.877. In fact, X2 reflects the total data transmission volume per unit time of the network. The larger the total data transmission volume of the network, the busier the lines between the nodes of the network, and the longer the packet queue in the nodes. As a result, the transmission and forwarding time of each packet increases when the voice call link is established; thus, the voice link establishment time (X8) also increases. In addition, in the importance analysis of the previous section, the comprehensive weight of index X8 is the largest; thus, the index X8 is retained and the index X2 is discarded. After analysis, the simplified indexes of information transmission factor indexes are determined as X7 and X8.
The correlation coefficients between X4, X5 and X6 are greater than the critical value (0.5), indicating that there is a great correlation between the network situation awareness, the timeliness of network state adjustment and the success rate of temporary network access. In fact, the network state awareness measures the correctness and data transmission delay of the network management agent in each network device when the network state changes. The timeliness of network adjustment is that the network management equipment sends the network adjustment instruction data to the network management agent, and the network management agent outputs the adjustment instruction to the device controller in order to implement the device control. It can be considered as the reverse information transmission and control of network perception information, and thus it has strong relevance. The success rate of temporary network access measures the success rate of new network users sending network access applications to the network management device, which assigns the corresponding parameters to them, and the device network management agent receives and outputs them to the device controller to implement the device control and to finally complete the network access. Therefore, the actual data transmission and control process is similar to the network state perception. In addition, considering that the comprehensive weight of the index X4 in the importance analysis of the previous section is larger, therefore, the index X4 is retained and the indexes X5 and X6 are discarded. After analysis, the simplified index of network control factor is X4.
3.4. Simplified Algorithm Model
By the analysis of the importance and correlation of the indexes, the evaluation indexes of operational effectiveness of mobile communication system can be simplified as
X1,
X3,
X7 and
X8, and the comprehensive weight of these four indexes needs to be adjusted to
Wi*.
Wi* is the new normalized commonness of the index
i,
Wi is the original normalized commonness of the index
i and
k is the number of simplified indexes.
According to the weight of each index and the standardized data set, the weighted sum can obtain the total score of each unit.
is the simplified index score of each unit,
is the normalized data of each unit and
n is the number of units.
By calculating the score values of each unit and arranging them by the simplified algorithm model, the comparison with the ranking results of factor comprehensive scores in
Table 2 is shown in
Table 8.
Table 8 shows that the maximum deviation between the evaluation ranking of the simplified algorithm model and the ranking results obtained by the previous factor analysis method is 3, in which 42% (13 units) of the evaluation ranking possessed no change, 39% (12 units) of the evaluation ranking possessed one difference, 13% (4 units) of the evaluation ranking possessed two differences and 6% (2 units) of the evaluation ranking possessed three differences. This shows that the evaluation conclusion of the simplified algorithm model is reliable and ideal. In the first stage, the method can be used to evaluate historical data and to calculate simplified algorithmic models. In the second stage, the simplified indexes are used to evaluate the simulation data of the design scheme, which greatly reduces the workload of data recording, statistics and calculation, greatly facilitates the implementation of the late evaluation and has strong economic benefits.
This method can be applied to the semi-automatic network planning assistant optimization system of mobile communication network of army division/brigade troops. The latest simplified indexes and weights can be obtained by using the historical data and stored in database.
When network planning needs to be performed again, the network plan set generated by the planning equipment is imported into the system, and the system simulates all the network plans. It only requires a small amount of simulation data to be collected according to the simplified index and can directly calculate the effectiveness of each network plan according to the simplified model.
After each network operation, data will be imported into the system through the network management device so as to update the indexes and weights and to keep the system updated iteratively.
4. Preference Strategy
By using the factor scores and ranking in
Table 8, we can produce specific evaluations on the operational efficiency of a mobile communication system of each participating unit. The result is a comprehensive ranking result, which is suitable for most cases, and the performance of all aspects of the network scheme is relatively balanced. In the actual application process, more emphasis may be placed on the efficiency of information transmission in some cases. In other cases, more emphasis may be placed on the perception or security of the network. Therefore, it is very important to propose preference strategies under different requirements. We first analyze the data results of this paper and then propose a preference strategy method.
4.1. Analysis of Evaluation Results
In this paper, we selected the most commonly used system clustering method [
56], which is to divide n samples into several categories. The system clustering method first clusters the samples or variables as a group, then it determines the statistics of similarity between class and class, and then it selects the closest two or several classes merged into a new class of computing similarity between a new class and other kinds of statistics. Finally, it then chooses the one closest to the group of two or several groups merged into a new class until all of the samples or variables are merged into a class. K-means clustering algorithm is an iteratively solved clustering analysis algorithm. It requires the specification of the number of data groups K, it then calculate the distance between each object and each seed clustering center, and then it assigns each object to the nearest clustering center.
Due to the variety of data sources, it is difficult to determine the appropriate group number in advance, and the selection of appropriate classification value results in the inaccuracy of clustering results and affects the accuracy of the subsequent recommendation algorithm. In the selection of the system clustering method, results can be presented by clustering, and the user can select the appropriate number of groups, which is convenient to improve the accuracy of the subsequent recommendation algorithm.
- (1)
First, n samples are regarded as one category;
- (2)
The distance between categories is calculated;
- (3)
Select the two categories with the smallest distance to merge into a new category;
- (4)
Repeat steps 2 and 3 to reduce one category at a time until all samples become one category.
A Euclidean distance is used to calculate the distance between two samples.
is the distance between sample
i and
j,
and
are the scores of samples
i and
j on the factor
t.
The shortest distance method is used to calculate the distance
Dpq between category
Gp and
Gq.
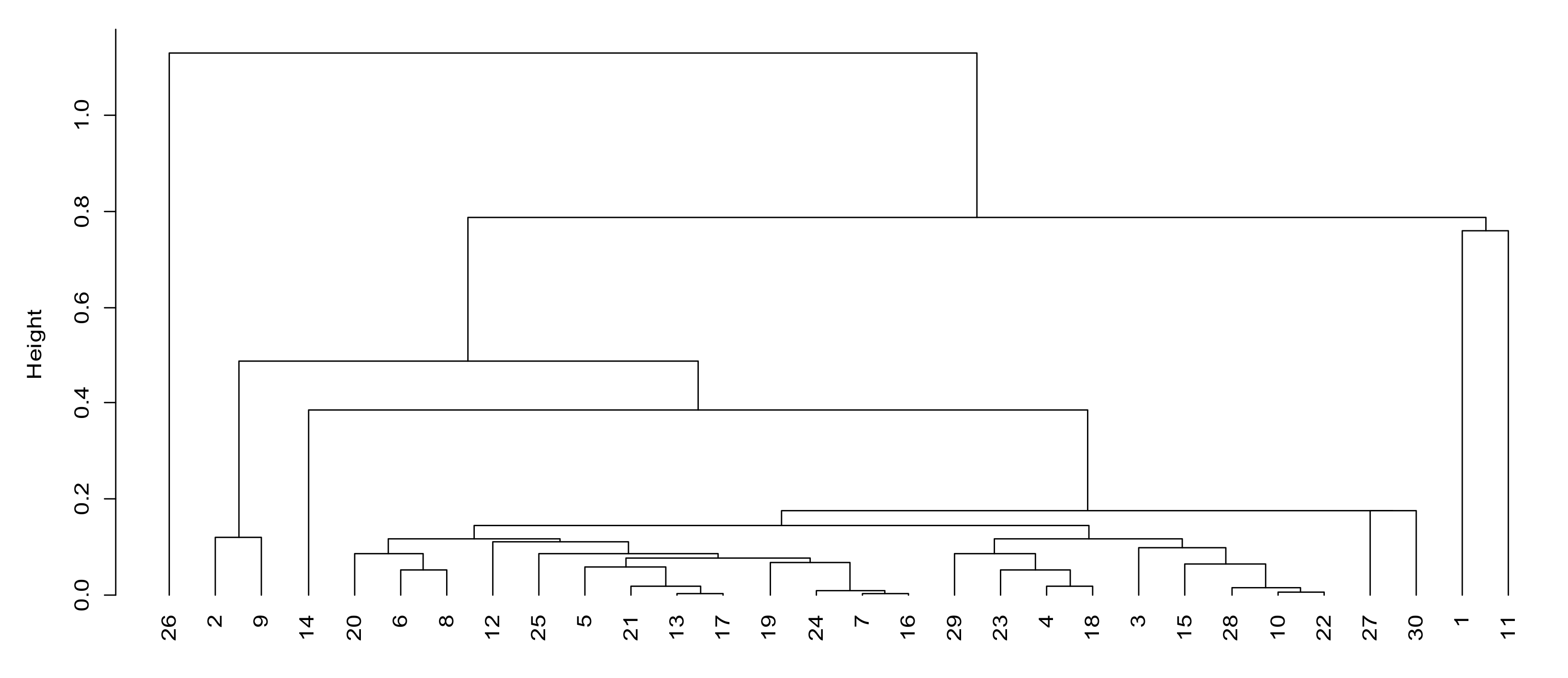
According to the information transmission factor (factor 1), we can see that units 19, 9, 26 and 13 have higher scores in factor 1. From
Figure 3, the distance between these four units and other units in factor 1 is also large, which indicates that the communication systems of these three units possess large data transmission capacity, small delay, low voice interruption rate, strong battlefield communication ability and good voice communication performance. The rest of the units are roughly divided into four levels of the following: 1, 2, 11, 18, 20 and 25 are the second levels; 10, 12, 14, 21, 22 and 23 are the third levels; 5, 6, 7, 15, 16, 24, 29 and 31 are the fourth levels; 3, 4, 8, 27, 28 and 30 are the fifth levels.
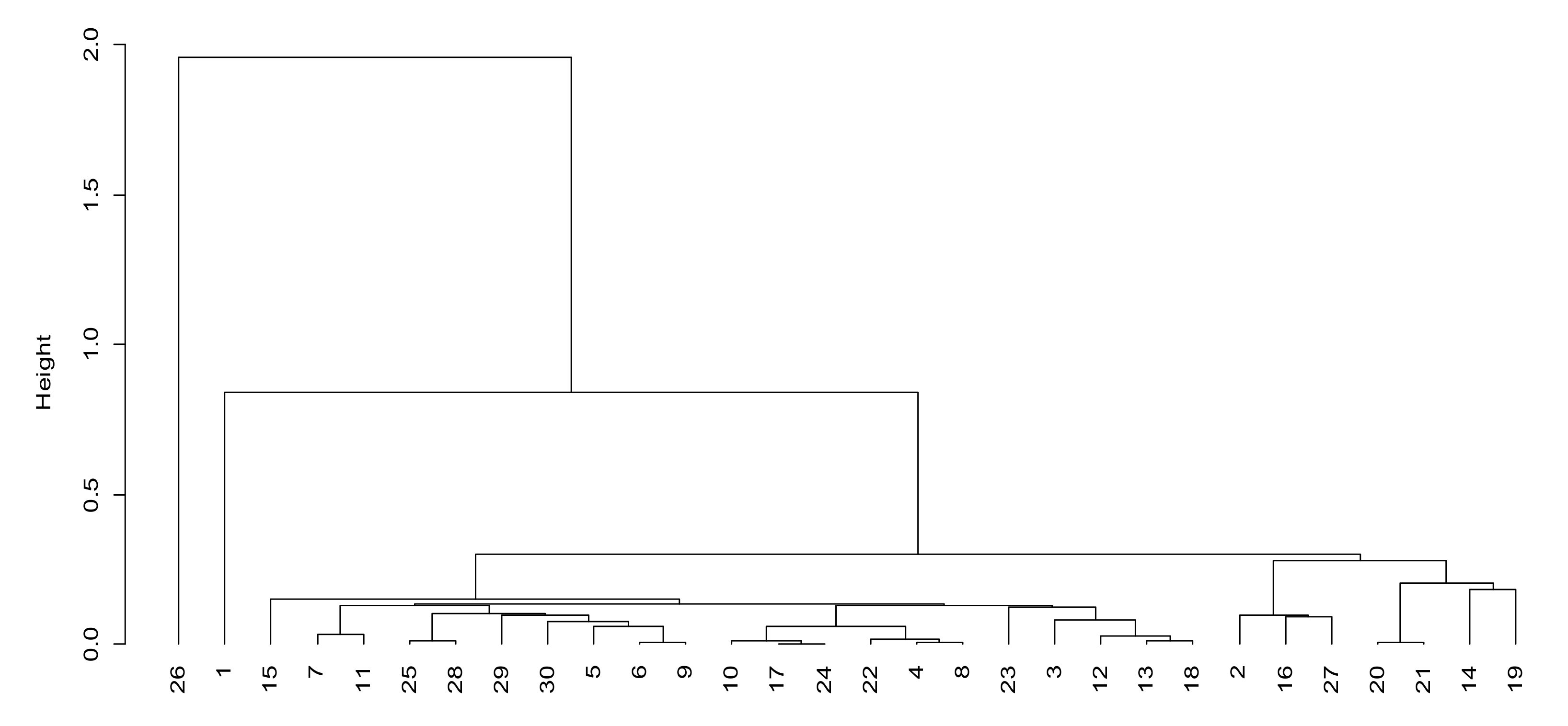
According to the network management and control factor (factor 2), we can observe that units 1, 11, 2 and 9 have higher scores in factor 2. From
Figure 4, it can be observed that the distance between the four units and other units in factor 2 is also large, which indicates that the four units have strong battlefield control abilities when using mobile communication systems, can better grasp the whole network operation state and can timely adjust the network as needed. They can support members’ random access and temporary access requests. The remaining units are roughly divided into four levels of the following: 3, 10, 15, 22, 27, 28 and 30 are the second levels; 4, 18, 23 and 29 are the third levels; 5, 6, 7, 8, 12, 13, 16, 17, 19, 20, 21, 24, 25 and 31 are the fourth levels; 14 and 26 are the fifth levels.
According to the security protection factor (factor 3), we can observed that unit 26 and 1 have higher scores in factor 3. From
Figure 5, the distance between these two units and other units in factor 3 is also large, which indicates that these two units have strong security protection ability, high network robustness, strong information encryption and can be used to transmit information with higher security levels. The remaining units are roughly divided into four levels of the following: 5, 6, 7, 9, 15, 25 and 28–31 are the second levels; 4, 8, 10, 17, 22 and 24 are the third levels; 3, 12, 13, 18 and 23 are the fourth levels; and 2, 14, 16, 19–21 and 27 are the fifth levels.
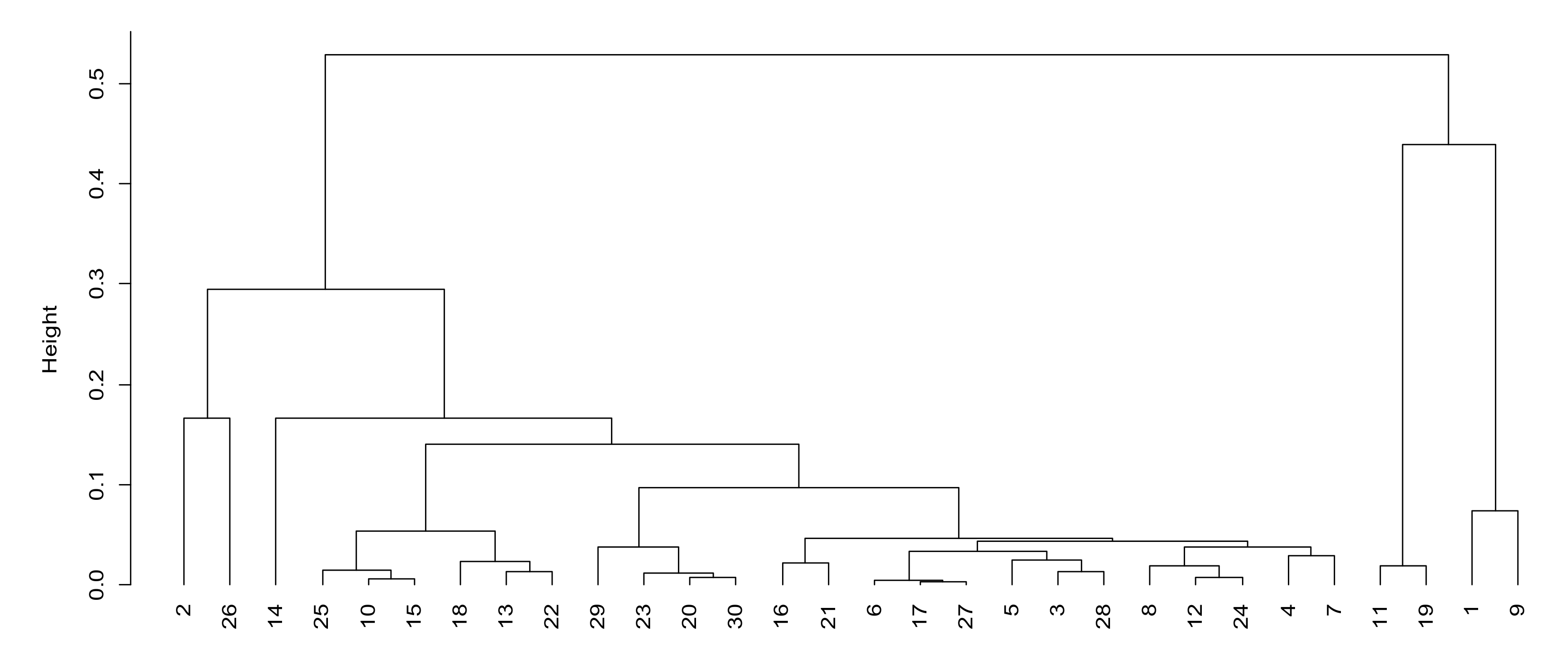
From the ranking of comprehensive scores, it can be observed that the comprehensive scores of 1, 9, 19 and 11 are the highest. From
Figure 6, it can be observed that these four units are also far away from other units; that is to say, the comprehensive application effect of the mobile communication systems of these four units is the best. The remaining units are roughly divided into four levels of the following: 2, 10, 13, 15, 22, 25 and 26 are the second levels; 20, 23 and 29–31 are the third levels; 3–8, 12, 17, 24, 27 and 28 are the fourth levels; and 14, 16 and 21 are the fifth levels.
4.2. Preference Selection Algorithm
According to the results of the above cluster analysis, we can choose four preference strategies: information transmission, network control, security protection and comprehensive scores. According to the comprehensive scores, the best performances are observed in units 1, 9, 19 and 11. The comprehensive score of unit 19 ranks third, with the highest score of factor 1, but the scores of factor 2 and factor 3 are very low, which means that the information transmission ability of unit 19 is very strong while the network control ability and security protection ability are poor. Therefore, the optimization of network design scheme should be based on a certain preference and refer to other factors.
The preference selection algorithm proposed in this paper is shown as follows.
- (1)
According to the preference strategy (information transmission, network control, security protection and integration), perform cluster analysis on the evaluation results and obtain n-level data set (the number of grades can be specified by users based on the cluster analysis results);
- (2)
Select the first two levels of the corresponding cluster analysis as initial ranking;
- (3)
Delete schemes at the lower 2 levels among other preferences;
- (4)
Output the remaining schemes in order as the result.
Based on the above algorithm, when the preference of comprehensive scores is selected, the optimal results are 1, 9, 11, 10 and 22. When the preference of information transmission is selected, the optimal results are 9, 1 and 11. When preference of network control is selected, the optimal results are 1, 11, 9, 10 and 22. When preference of security protection is selected, the optimal results are 1, 9 and 15. Compared with the traditional factor analysis comprehensive score method, the preference selection algorithm proposed in this paper can avoid other low scores except when considering the factors of user preference or comprehensive scores, rendering the output optimization result more reasonable and feasible.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}