
Fast and Accurate Object Detection in Remote Sensing Images Based on Lightweight Deep Neural Network


Abstract
:1. Introduction
2. Related Work
2.1. Lightweight Object Detection Network
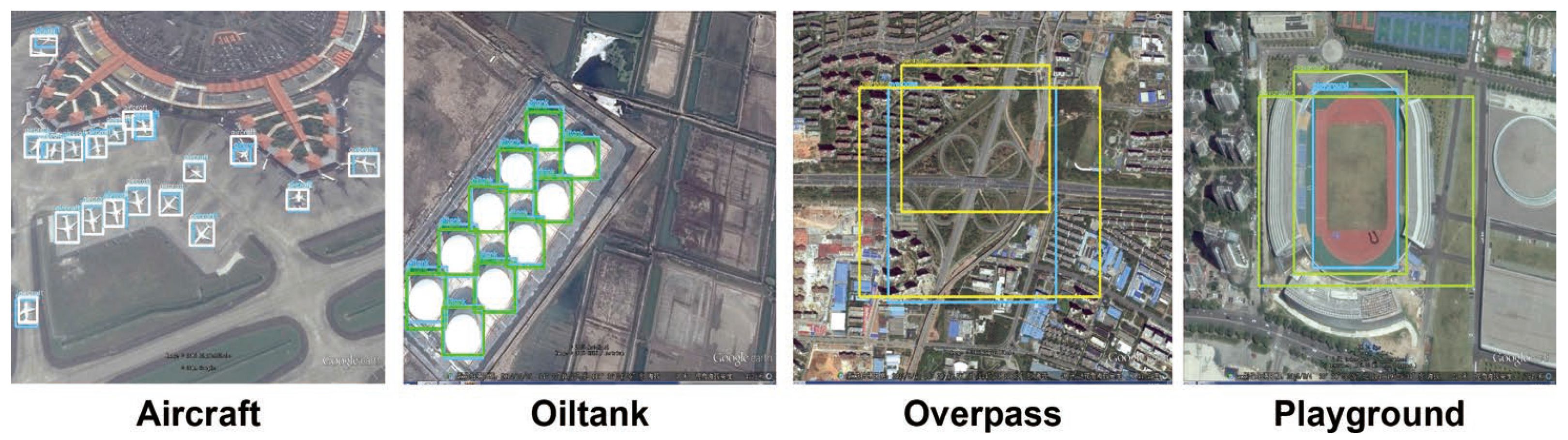
- The shallow backbone and prediction network structures are not sufficient to extract deep semantic information, which limits the performance of the network in complex scenarios, for instance, very small objects or complicated backgrounds [42]. In addition, the simple organization of prediction layers cannot effectively cover objects of various proportions, especially when remote sensing images with dense object distributions were considered.
- The performance of the detector is especially sensitive to anchor configurations, which not only affects the speed of training, but also the robustness of the network. As been explained in previous section, the small amount of anchors with fixed scales in YOLO-Tiny will deliver poor detection results due to the large variation in object scales.
2.2. Visual Attention Mechanism
2.3. Optimized Anchors
- Manual configuration. The anchors selected by the manual correction method are more straightforward and robust. However, it requires the designer to have rich experience in the application field and perform comprehensive manual experiments before determining the best setting.
- Automatic configuration based on optimizations. According to distribution of the data set, this type of scheme can automatically find the best anchor position, which greatly relieves the effort of searching for the optimal configurations and also delivers higher accuracy and faster training speed.
3. Methodology
3.1. Lightweight Neural Network
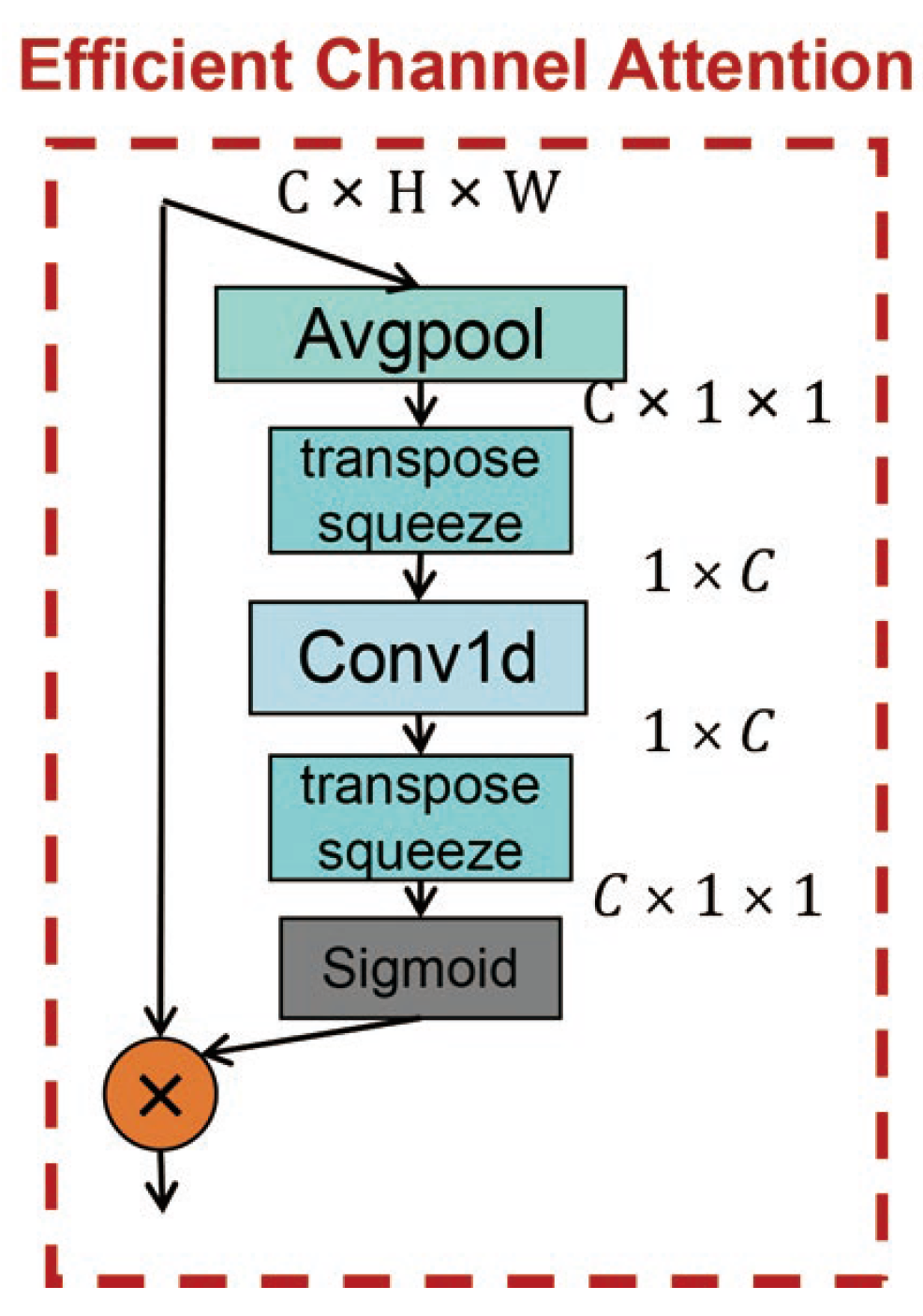
3.2. Efficient Channel Attention
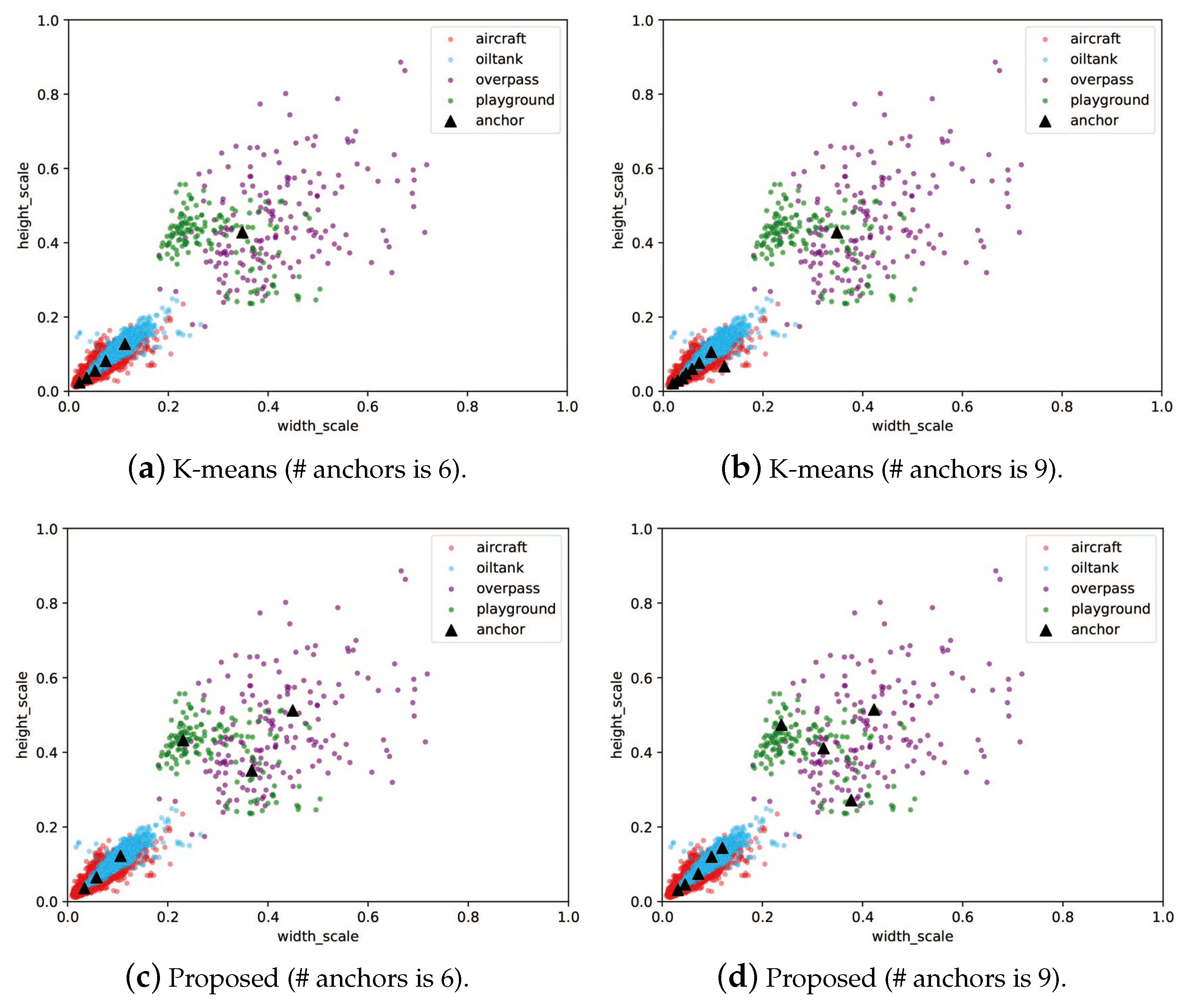
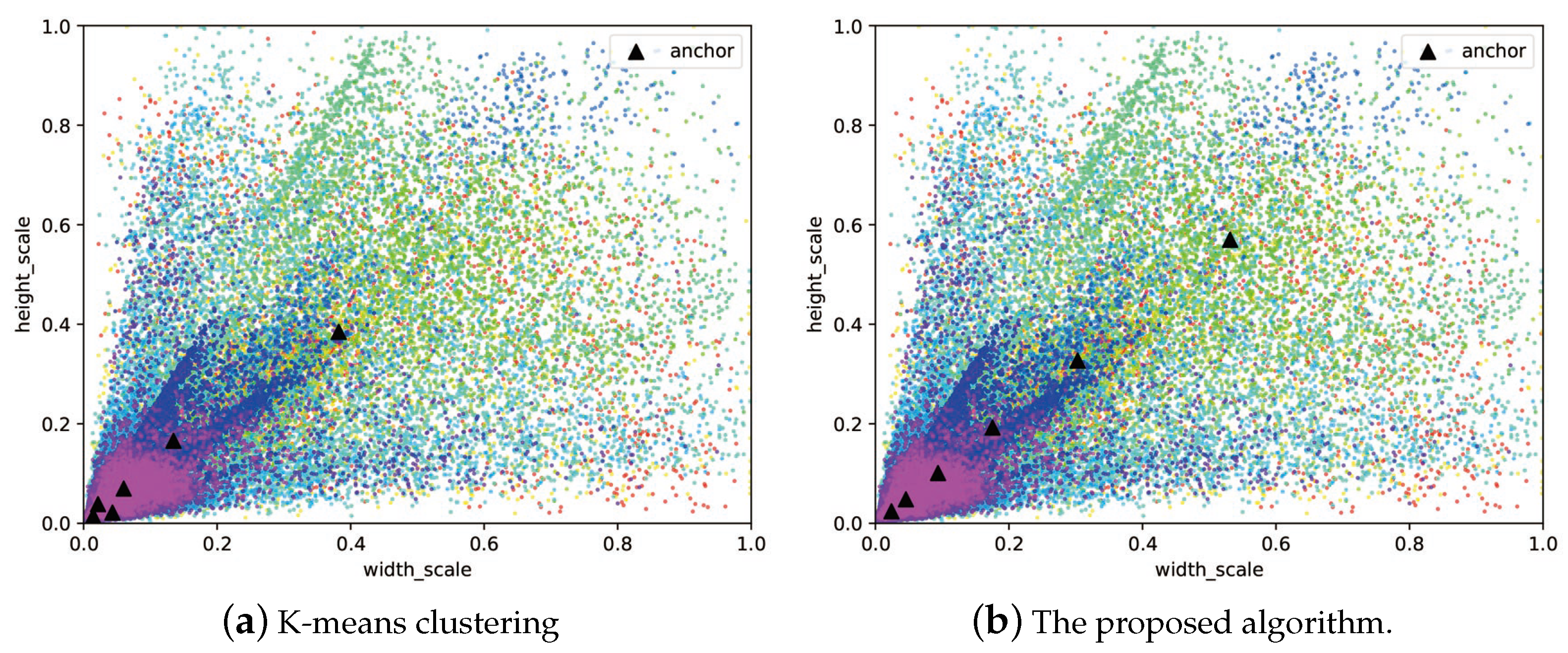
3.3. Optimal Anchor Configuration Based on Differential Evolution
| Algorithm 1 Anchor configurations algorithm based on DE. |
Input: input parameters , , Output: output and
|
4. Experimental Settings
4.1. Hardware Platforms
4.2. Datasets and Training Parameters
4.3. Evaluation Metrics
5. Results
5.1. Improvements by Network Structure
5.2. Improvements by Anchor Configuration
5.3. Comparison with the State-of-the-Art
6. Deployment on Embedded Platform
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Khan, M.J.; Khan, H.S.; Yousaf, A.; Khurshid, K.; Abbas, A. Super-Resolution Modern Trends in Hyperspectral Image Analysis: A Review. IEEE Access 2018, 6, 14118–14129. [Google Scholar] [CrossRef]
- Hong, D.F.; Gao, L.R.; Yokoya, N.; Yao, J.; Chanussot, J.; Du, Q.; Zhang, B. More Diverse Means Better: Multimodal Deep Learning Meets Remote-Sensing Imagery Classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 4340–4354. [Google Scholar] [CrossRef]
- Chen, J.; Wang, G.B.; Luo, L.B.; Gong, W.P.; Cheng, Z. Building Area Estimation in Drone Aerial Images Based on Mask R-CNN. IEEE Geosci. Remote Sens. Lett. 2021, 18, 891–894. [Google Scholar] [CrossRef]
- Afaq, Y.; Manocha, A. Analysis on change detection techniques for remote sensing applications: A review. Ecol. Inform. 2021, 63, 101310. [Google Scholar] [CrossRef]
- Hoeser, T.; Bachofer, F.; Kuenzer, C. Object Detection and Image Segmentation with Deep Learning on Earth Observation Data: A Review-Part II: Applications. Remote Sens. 2020, 12, 3053. [Google Scholar] [CrossRef]
- Wang, P.; Wang, L.G.; Leung, H.; Zhang, G. Super-Resolution Mapping Based on SpatialSpectral Correlation for Spectral Imagery. IEEE Trans. Geosci. Remote Sens. 2021, 59, 2256–2268. [Google Scholar] [CrossRef]
- Zhao, Z.Q.; Zheng, P.; Xu, S.T.; Wu, X. Object Detection with Deep Learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 142–149. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Zhao, Q.; Sheng, T.; Wang, Y.; Tang, Z.; Ling, H. M2det: A single-shot object detector based on multi-level feature pyramid network. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 9259–9266. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems 28 (NIPS 2015), Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Du, P.J.; Xia, J.S.; Zhang, W.; Tan, K.; Liu, Y.; Liu, S.C. Multiple Classifier System for Remote Sensing Image Classification: A Review. Sensors 2012, 19, 4764–4792. [Google Scholar] [CrossRef]
- Tsagkatakis, G.; Aidini, A.; Fotiadou, K.; Giannopoulos, M.; Pentari, A.; Tsakalides, P. Survey of Deep-Learning Approaches for Remote Sensing Observation Enhancement. Sensors 2019, 19, 3929. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.Y.; Wang, Y.Z.; Wu, Y.L.; Zhang, K.; Wang, Q. FRPNet: A Feature-Reflowing Pyramid Network for Object Detection of Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2020, 1–5. [Google Scholar] [CrossRef]
- Huang, W.; Li, G.; Chen, Q.; Ju, M.; Qu, J. CF2PN: A Cross-Scale Feature Fusion Pyramid Network Based Remote Sensing Target Detection. Remote Sens. 2021, 13, 847. [Google Scholar] [CrossRef]
- Chen, L.C.; Liu, C.S.; Chang, F.L.; Li, S.; Nie, Z.Y. Multiscale object detection in high-resolution remote sensing images via rotation invariant deep features driven by channel attention. Int. J. Remote Sens. 2021, 42, 5754–5773. [Google Scholar]
- Qing, Y.H.; Liu, W.Y.; Feng, L.Y.; Gao, W.J. Improved YOLO Network for Free-Angle Remote Sensing Target Detection. Remote Sens. 2021, 13, 2171. [Google Scholar] [CrossRef]
- Li, X.G.; Li, Z.X.; Lv, S.S.; Cao, J.; Pan, M.; Ma, Q.; Yu, H.B. Ship detection of optical remote sensing image in multiple scenes. Int. J. Remote Sens. 2021. [Google Scholar] [CrossRef]
- Chen, L.C.; Liu, C.S.; Chang, F.L.; Li, S.; Nie, Z.Y. Adaptive multi-level feature fusion and attention-based network for arbitrary-oriented object detection in remote sensing imagery. Neurocomputing 2021, 415, 67–80. [Google Scholar] [CrossRef]
- Tian, Z.; Zhan, R.; Hu, J.; Wang, W.; He, Z.; Zhuang, Z. Generating Anchor Boxes Based on Attention Mechanism for Object Detection in Remote Sensing Images. Remote Sens. 2020, 12, 2416. [Google Scholar] [CrossRef]
- Mo, N.; Yan, L.; Zhu, R.; Xie, H. Class-Specific Anchor Based and Context-Guided Multi-Class Object Detection in High Resolution Remote Sensing Imagery with a Convolutional Neural Network. Remote Sens. 2019, 11, 272. [Google Scholar] [CrossRef] [Green Version]
- Long, Y.; Gong, Y.; Xiao, Z.; Liu, Q. Accurate object localization in remote sensing images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2486–2498. [Google Scholar] [CrossRef]
- Mhangara, P.; Mapurisa, W. Multi-Mission Earth Observation Data Processing System. Sensors 2019, 19, 3831. [Google Scholar] [CrossRef] [Green Version]
- Han, W.Y.; Liu, X.H. Clustering Anchor for Faster R-CNN to Improve Detection Results. In Proceedings of the IEEE International Conference on Artificial Intelligence and Computer Applications (ICAICA), Dalian, China, 27–29 June 2020; pp. 749–752. [Google Scholar]
- Chen, L.; Zhou, L.; Liu, J. Aircraft Recognition from Remote Sensing Images Based on Machine Vision. J. Inf. Process. Syst. 2020, 16, 795–808. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Al-Naji, A.; Perera, A.; Mohammed, S.L.; Chahl, J. Life Signs Detector Using a Drone in Disaster Zones. Remote Sens. 2019, 11, 2441. [Google Scholar] [CrossRef] [Green Version]
- Nikulin, A.; de Smet, T.S.; Baur, J.; Frazer, W.D.; Abramowitz, J.C. Detection and Identification of Remnant PFM-1 ’Butterfly Mines’ with a UAV-Based Thermal-Imaging Protocol. Remote Sens. 2018, 10, 1672. [Google Scholar] [CrossRef] [Green Version]
- NVIDIA Developer. NVIDIA Embedded-Computing. Available online: https://developer.nvidia.com/embedded-computing (accessed on 20 May 2021).
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Santiago, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. arXiv 2019, arXiv:1904.01355. [Google Scholar]
- Joseph, R.; Ali, F. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Gao, J.F.; Chen, Y.; Wei, Y.M.; Li, J.N. Detection of Specific Building in Remote Sensing Images Using a Novel YOLO-S-CIOU Model. Case: Gas Station Identification. Sensors 2021, 21, 1375. [Google Scholar] [CrossRef]
- Hu, X.L.; Liu, Y.; Zhao, Z.X.; Liu, J.T.; Yang, X.T.; Sun, C.H.; Chen, S.H.; Li, B.; Zhou, C. Real-time detection of uneaten feed pellets in underwater images for aquaculture using an improved YOLO-V4 network. Comput. Electron. Agric. 2021, 185, 106135. [Google Scholar] [CrossRef]
- Singh, S.; Ahuja, U.; Kumar, M.; Kumar, K.; Sachdeva, M. Face mask detection using YOLOv3 and faster R-CNN models: COVID-19 environment. Multimed. Tools Appl. 2021, 80, 19753–19768. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Wang, X.; Tang, X. Residual attention network for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3156–3164. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. arXiv 2021, arXiv:2103.02907. [Google Scholar]
- Junos, M.H.; Khairuddin, A.; Thannirmalai, S.; Dahari, M. An optimized YOLO-based object detection model for crop harvesting system. IET Image Process. 2021. [Google Scholar] [CrossRef]
- Zlocha, M.; Dou, Q.; Glocker, B. Improving RetinaNet for CT Lesion Detection with Dense Masks from Weak RECIST Labels. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention (MICCAI), Shenzhen, China, 13–17 October 2019; pp. 402–410. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11531–11539. [Google Scholar]
- Price, K.V. Differential evolution: A fast and simple numerical optimizer. In Proceedings of the North American Fuzzy Information Processing, Berkeley, CA, USA, 19–22 June 1996; pp. 524–527. [Google Scholar]
- Opara, K.R.; Arabas, J. Differential Evolution: A survey of theoretical analyses. Swarm Evol. Comput. 2019, 44, 546–558. [Google Scholar] [CrossRef]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Cheng, G.; Si, Y.J.; Hong, H.L.; Yao, X.W.; Guo, L. Cross-Scale Feature Fusion for Object Detection in Optical Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2021, 18, 431–435. [Google Scholar] [CrossRef]
- Li, L.; Cao, G.; Liu, J.; Tong, Y. Efficient Detection in Aerial Images for Resource-Limited Satellites. IEEE Geosci. Remote Sens. Lett. 2021, 1–5. [Google Scholar] [CrossRef]
- Xu, T.; Sun, X.; Diao, W.H.; Zhao, L.J.; Fu, K.; Wang, H.Q. ASSD: Feature Aligned Single-Shot Detection for Multiscale Objects in Aerial Imagery. IEEE Trans. Geosci. Remote Sens. 2021, 1–17. [Google Scholar] [CrossRef]
- Huang, Z.; Li, W.; Xia, X.G.; Wang, H.; Tao, R. LO-Det: Lightweight Oriented Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 99, 1–15. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Params/Bytes | mAP/% | |||
|---|---|---|---|---|---|
| CSPA1 | CSPA2 | CSPA3 | Total | ||
| None | 0 | 0 | 0 | 0 | 80.02 |
| SE | 128 | 512 | 2048 | 2688 | 83.12 |
| ECA | 96 | 192 | 384 | 672 | 83.34 |
| Device | NVIDIA GeForce RTX2080Ti Desktop GPU | NVIDIA Jeteson Xavier |
|---|---|---|
| GPU | 4352 NVIDIA CUDA cores | 384-core NVIDIA Volta GPU and 48 Tensorc cores |
| CPU | Intel Core i9-7960x | 6-core NVIDIA Carmel ARM®v8.2 64-bit CPU 6 MB L2 + 4 MB L3 |
| Memory | 11 GB 352-bit GDDR6 616 GB/s | 8 GB 128-bit LPDDR4 51.2 GB/s |
| Storage | 4T Hard Disk Drive | microSD |
| Power | 285 W | 10 W (low-power mode)/15 W |
| Num. | Params | FLOPs | mAP/% | FPS | Aircraft | Oiltank | Overpass | Playground |
|---|---|---|---|---|---|---|---|---|
| 2 | 5.881 M | 3.42 G | 80.02 | 285.3 | 72.46 | 97.85 | 51.56 | 98.22 |
| 3 | 6.527 M | 5.06 G | 82.00 | 230.4 | 74.73 | 95.99 | 59.30 | 97.98 |
| 4 | 6.732 M | 9.83 G | 83.09 | 182.5 | 78.88 | 96.84 | 59.67 | 96.96 |
| Methods | Params | FLOPs | mAP/% | FPS |
|---|---|---|---|---|
| None | 0 bytes | 0 k | 80.02 | 285.3 |
| CBAM | 2988 bytes | 422 k | 79.94 | 268.9 |
| CA | 5424 bytes | 351 k | 79.95 | 273.5 |
| SE | 2688 bytes | 2.94 k | 83.12 | 277.1 |
| ECA | 672 bytes | 0.89 k | 83.34 | 280.8 |
| 3 | 5 | 7 | 9 | Adaptive | |
|---|---|---|---|---|---|
| mAP/% | 83.34 | 81.70 | 82.97 | 80.75 | 81.56 |
| Population Size | Average Value of the Fitness Function | Average of Convergence Time (s/Iteration) |
|---|---|---|
| 100 | 0.2718 | 7.99 |
| 200 | 0.2713 | 15.29 |
| 300 | 0.2697 | 25.73 |
| 400 | 0.2710 | 36.37 |
| 500 | 0.2700 | 46.04 |
| 600 | 0.2729 | 53.67 |
| 700 | 0.2714 | 58.69 |
| 800 | 0.2727 | 59.98 |
| Anchor () | Best Decision Variables | Anchor Settings |
|---|---|---|
| Methods | K | mAP(%) | Anchors |
|---|---|---|---|
| K-means | 6 | 81.55 | (9,10), (15,15), (22,23), (31,34), (47,53), (145,178) |
| 9 | 82.00 | (8,9), (12,12), (16,15), (19,20), (24,25), (30,32), (40,44), (51,58), (145,178) | |
| Proposed | 6 | 81.69 | (14,15), (24,27), (44,51), (96,180), (153,146), (187,213) |
| 9 | 83.13 | (13,13), (19,19), (30,31), (41,50), (50,60), (134,171), (99,197), (157,113), (176,214) |
| Methods | C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | C10 | C11 | C12 | C13 | C14 | C15 | C16 | C17 | C18 | C19 | C20 | mAP/% |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| K-means | 42.06 | 54.45 | 71.06 | 68.67 | 20.22 | 71.78 | 43.83 | 54.48 | 47.50 | 58.18 | 55.90 | 47.84 | 44.90 | 38.59 | 50.08 | 33.87 | 64.52 | 34.99 | 23.67 | 48.74 | 48.74 |
| DE | 57.98 | 57.80 | 71.43 | 74.94 | 22.83 | 72.43 | 43.73 | 56.71 | 49.14 | 59.38 | 64.80 | 51.72 | 47.06 | 42.68 | 54.70 | 38.08 | 79.72 | 37.53 | 26.69 | 53.64 | 53.15 |
| Methods | Size | Params | FLOPs | mAP/% | FPS | Aircraft | Oiltank | Overpass | Playground |
|---|---|---|---|---|---|---|---|---|---|
| SSD300 [8] | 300 | 24.15 M | 30.64 G | 84.71 | 54.2 | 70.12 | 90.34 | 78.43 | 100.00 |
| YOLOv4 [35] | 416 | 63.95 M | 29.89 G | 92.50 | 44.8 | 96.13 | 98.38 | 75.78 | 99.71 |
| YOLOv4-Tiny [35] | 416 | 5.881 M | 3.42 G | 80.02 | 285.3 | 72.46 | 97.85 | 51.56 | 98.22 |
| Proposed | 416 | 6.527 M | 5.06 G | 85.13 | 227.9 | 87.10 | 98.97 | 56.58 | 97.86 |
| C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | C10 |
|---|---|---|---|---|---|---|---|---|---|
| Airplane | Airport | Baseball field | Basketball court | Bridge | Chimney | Dam | Expressway service area | Expressway toll station | Golf course |
| C11 | C12 | C13 | C14 | C15 | C16 | C17 | C18 | C19 | C20 |
| Ground track field | Harbor | Overpass | Ship | Stadium | Storage tank | Tennis court | Train station | Vehicle | Wind mill |
| Methods | C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | C10 | C11 | C12 | C13 | C14 | C15 | C16 | C17 | C18 | C19 | C20 | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv4-Tiny [35] | 58.61 | 55.99 | 71.57 | 74.52 | 22.19 | 72.11 | 47.26 | 54.83 | 48.50 | 60.11 | 64.46 | 51.09 | 46.92 | 41.93 | 55.42 | 37.18 | 79.78 | 36.27 | 26.49 | 52.23 | 52.87 |
| Proposed | 58.16 | 55.62 | 72.39 | 76.01 | 25.86 | 73.03 | 43.31 | 55.43 | 51.39 | 58.94 | 66.03 | 51.30 | 48.69 | 70.41 | 51.82 | 53.34 | 82.46 | 38.78 | 32.60 | 63.33 | 56.45 |
| Approach | CSFF [53] | CF2PN [16] | Simple-CNN [54] | ASSD-Lite [55] | LO-Det [56] | Proposed |
|---|---|---|---|---|---|---|
| Year | 2021 | 2021 | 2021 | 2021 | 2021 | 2021 |
| Backbone | ResNet-101 | VGG16 | VGG16 | MobileNetv2 | MobileNetv2 | 17-layer-CNN |
| Parameters | >46 M | 91.6 M | 23.53 M | >24 M | 6.93 M | 6.5 M |
| FPS | 15.21 | 19.7 | 13 | 35 | 64.52 | 227.9 |
| mAP | 68 | 67.25 | 66.5 | 63.3 | 58.73 | 56.45 |
| Device | RTX3090 | RTX2080Ti | GT710 | GTX 1080Ti | RTX3090 | RTX2080Ti |
| Methods | mAP (FP32) | mAP (FP16) | FPS (FP16) | Efficiency (100%) |
|---|---|---|---|---|
| YOLOv4-Tiny | 80.02% | 80.22% | 63.28 | 43.2% |
| Proposed | 85.13% | 85.33% | 58.17 | 58.8% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lang, L.; Xu, K.; Zhang, Q.; Wang, D. Fast and Accurate Object Detection in Remote Sensing Images Based on Lightweight Deep Neural Network. Sensors 2021, 21, 5460. https://doi.org/10.3390/s21165460
Lang L, Xu K, Zhang Q, Wang D. Fast and Accurate Object Detection in Remote Sensing Images Based on Lightweight Deep Neural Network. Sensors. 2021; 21(16):5460. https://doi.org/10.3390/s21165460
Chicago/Turabian StyleLang, Lei, Ke Xu, Qian Zhang, and Dong Wang. 2021. "Fast and Accurate Object Detection in Remote Sensing Images Based on Lightweight Deep Neural Network" Sensors 21, no. 16: 5460. https://doi.org/10.3390/s21165460
APA StyleLang, L., Xu, K., Zhang, Q., & Wang, D. (2021). Fast and Accurate Object Detection in Remote Sensing Images Based on Lightweight Deep Neural Network. Sensors, 21(16), 5460. https://doi.org/10.3390/s21165460