Figure 1.
Distribution of ship size on SSDD.
Figure 1.
Distribution of ship size on SSDD.
Figure 2.
Variation of loss during training on the SSDD dataset.
Figure 2.
Variation of loss during training on the SSDD dataset.
Figure 3.
Distribution of ship size on AIR-SARShip.
Figure 3.
Distribution of ship size on AIR-SARShip.
Figure 4.
The architecture of R-Centernet+, which mainly consists of the CBAM-DLA34, FEM, and Improved Detection Head. The numbers in the boxes represent the stride to the image.
Figure 4.
The architecture of R-Centernet+, which mainly consists of the CBAM-DLA34, FEM, and Improved Detection Head. The numbers in the boxes represent the stride to the image.
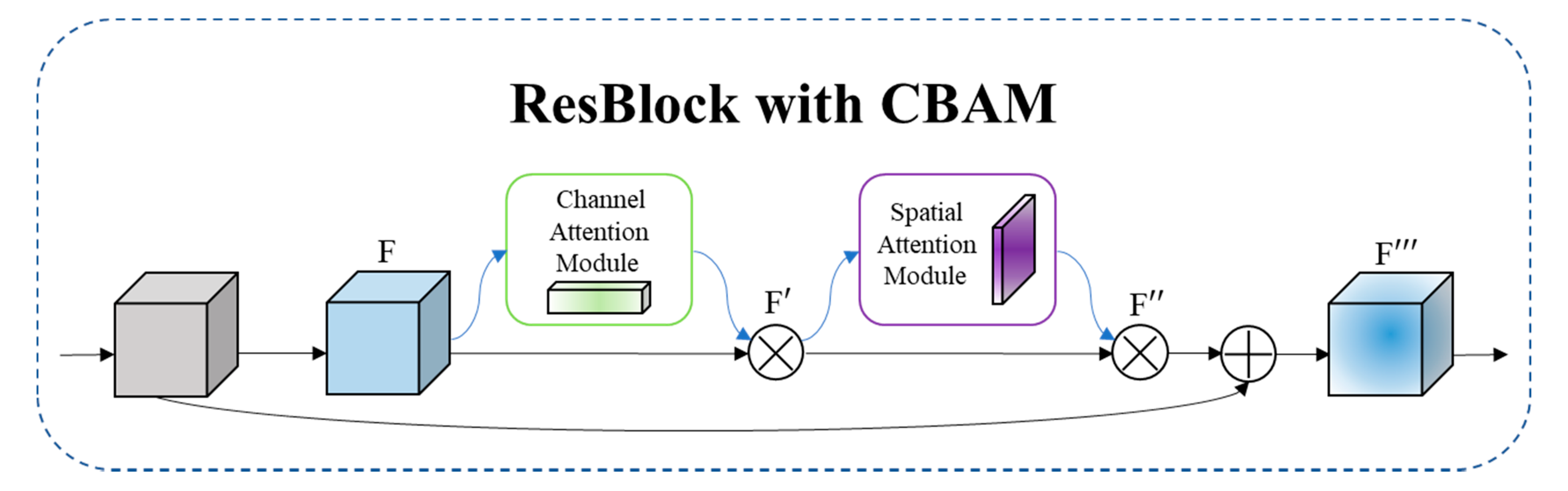
Figure 5.
The overview of CBAM. The module has two sequential sub-modules: channel and spatial. The intermediate feature map is adaptively refined through CBAM at every ResBlock of DLA34.
Figure 5.
The overview of CBAM. The module has two sequential sub-modules: channel and spatial. The intermediate feature map is adaptively refined through CBAM at every ResBlock of DLA34.
Figure 6.
Structure of CBAM-DLA34.
Figure 6.
Structure of CBAM-DLA34.
Figure 7.
Pipeline of FEM.
Figure 7.
Pipeline of FEM.
Figure 8.
The schematic diagram of Foreground segmentation label generation: The Foreground segmentation labels are generated from the bounding box labels.
Figure 8.
The schematic diagram of Foreground segmentation label generation: The Foreground segmentation labels are generated from the bounding box labels.
Figure 9.
The difference between two kinds of labels.
Figure 9.
The difference between two kinds of labels.
Figure 10.
The schematic diagram of the rotating bounding box.
Figure 10.
The schematic diagram of the rotating bounding box.
Figure 11.
Variation of loss during training on the SSDD dataset.
Figure 11.
Variation of loss during training on the SSDD dataset.
Figure 12.
Satisfactory testing results of the SSDD dataset. Both small ships and ships in complex backgrounds can be detected correctly.
Figure 12.
Satisfactory testing results of the SSDD dataset. Both small ships and ships in complex backgrounds can be detected correctly.
Figure 13.
(a,b) Undesired results in the SSDD. Blue bounding box means ships that were detected, red bounding box means ships that were missed, and orange bounding box means false alarms.
Figure 13.
(a,b) Undesired results in the SSDD. Blue bounding box means ships that were detected, red bounding box means ships that were missed, and orange bounding box means false alarms.
Figure 14.
The P-R curves of the SSDD dataset.
Figure 14.
The P-R curves of the SSDD dataset.
Figure 15.
Variation of loss during training on the AIR-SARShip dataset.
Figure 15.
Variation of loss during training on the AIR-SARShip dataset.
Figure 16.
Satisfactory detection results on the AIR-SARShip dataset. Both small ships and ships in complex backgrounds can be detected correctly.
Figure 16.
Satisfactory detection results on the AIR-SARShip dataset. Both small ships and ships in complex backgrounds can be detected correctly.
Figure 17.
(a,b) Undesired result on the AIR-SARShip. Blue bounding box indicates the detected ships, red bounding box indicates the missed ships, and orange bounding box indicates false alarms.
Figure 17.
(a,b) Undesired result on the AIR-SARShip. Blue bounding box indicates the detected ships, red bounding box indicates the missed ships, and orange bounding box indicates false alarms.
Figure 18.
The P-R curves of AIR-SARShip dataset.
Figure 18.
The P-R curves of AIR-SARShip dataset.
Figure 19.
The effect of CBAM. (a) The detection result of the experiment setting of NO CBAM and NO FEM. (b) The detection result of the experiment setting of NO CBAM and YES FEM. (c) The detection result of the experiment setting of YES CBAM and NO FEM. (d) The detection result of the experiment setting of YES CBAM and YES FEM. The blue rectangles indicate detected ships. The red rectangles indicate missed ships.
Figure 19.
The effect of CBAM. (a) The detection result of the experiment setting of NO CBAM and NO FEM. (b) The detection result of the experiment setting of NO CBAM and YES FEM. (c) The detection result of the experiment setting of YES CBAM and NO FEM. (d) The detection result of the experiment setting of YES CBAM and YES FEM. The blue rectangles indicate detected ships. The red rectangles indicate missed ships.
Figure 20.
The effect of FEM. (a) The detection result of the experiment setting of NO CBAM and NO FEM. (b) The detection result of the experiment setting of YES CBAM and NO FEM. (c) The detection result of the experiment setting of NO CBAM and YES FEM. (d) The detection result of the experiment setting of YES CBAM and YES FEM. The blue rectangles indicate detected ships. The orange rectangles indicate the false alarms.
Figure 20.
The effect of FEM. (a) The detection result of the experiment setting of NO CBAM and NO FEM. (b) The detection result of the experiment setting of YES CBAM and NO FEM. (c) The detection result of the experiment setting of NO CBAM and YES FEM. (d) The detection result of the experiment setting of YES CBAM and YES FEM. The blue rectangles indicate detected ships. The orange rectangles indicate the false alarms.
Table 1.
The SSDD dataset.
Table 1.
The SSDD dataset.
| Parameter | Value |
|---|
| Sensors | TerraSAR-X, RardarSat-2, Sentinel-1 |
| Resolution (m) | 1~15 |
| Polarization | HH, VV, VH, HV |
| Scene | Inshore, Offshore |
| Sea condition | Good, bad |
| Images Size (pixel) | 196~524 × 214~668 |
| Images | 1160 |
| Ships | 2578 |
Table 2.
Statistical results of multiscale ships in SSDD.
Table 2.
Statistical results of multiscale ships in SSDD.
| Dataset | Ship Size |
|---|
| Small | Medium | Large |
|---|
| SSDD | 1877 | 559 | 142 |
Table 3.
SSDD-inshore and SSDD-offshore.
Table 3.
SSDD-inshore and SSDD-offshore.
| Datasets | Images | Ships |
|---|
| SSDD-inshore | 227 | 668 |
| SSDD-offshore | 933 | 1910 |
| SSDD | 1160 | 2578 |
Table 4.
AIR-SARShip dataset.
Table 4.
AIR-SARShip dataset.
| Parameter | Value |
|---|
| Sensors | GF-3 |
| Resolution (m) | 1~3 |
| Polarization | Single |
| Scene | Inshore, Offshore |
| Sea condition | Good, bad |
| Images Size (pixel) | 3000 × 3000 |
| Images | 31 |
| Ships | 1585 |
Table 5.
Statistical results of multiscale ships in AIR-SARShip.
Table 5.
Statistical results of multiscale ships in AIR-SARShip.
| Dataset | Ship Size |
|---|
| Small | Medium | Large |
|---|
| AIR-SARShip | 318 | 1094 | 173 |
Table 6.
AIR-SARShip-inshore and AIR-SARShip-offshore.
Table 6.
AIR-SARShip-inshore and AIR-SARShip-offshore.
| Datasets | Images | Ships |
|---|
| AIR-SARShip-inshore | 168 | 396 |
| AIR-SARShip-offshore | 551 | 1189 |
| AIR-SARShip | 719 | 1585 |
Table 7.
Experimental results on different weight assignments.
Table 7.
Experimental results on different weight assignments.
| | | | | AP (%) |
|---|
| 1.0 | 0.1 | 1.0 | 0.1 | 0.1 | 94.83 |
| 1.0 | 0.1 | 1.0 | 0.1 | 1.0 | 95.11 |
| 1.0 | 0.1 | 1.0 | 1.0 | 0.1 | 79.32 |
| 1.0 | 0.1 | 1.0 | 1.0 | 1 | 81.18 |
Table 8.
Experimental results on the SSDD dataset.
Table 8.
Experimental results on the SSDD dataset.
| Datasets | Models | Precision | Recall | | | | |
|---|
| SSDD | R-Centernet+ | 95.21 | 95.58 | 95.11 | 93.01 | 97.87 | 98.52 |
| Centernet | 93.44 | 94.28 | 93.82 | 92.15 | 96.08 | 96.14 |
| Faster-RCNN | 89.48 | 89.80 | 88.96 | 86.95 | 89.53 | 87.02 |
| SSDD-inshore | R-Centernet+ | 93.64 | 92.65 | 93.72 | 92.05 | 94.53 | 94.92 |
| Centernet | 91.50 | 92.11 | 92.08 | 90.43 | 92.66 | 94.08 |
| Faster-RCNN | 87.92 | 87.42 | 86.98 | 85.91 | 87.55 | 85.39 |
| SSDD-offshore | R-Centernet+ | 96.75 | 97.85 | 97.84 | 97.24 | 99.83 | 99.72 |
| Centernet | 94.62 | 94.85 | 95.32 | 93.07 | 96.96 | 97.26 |
| Faster-RCNN | 89.42 | 91.18 | 90.05 | 88.84 | 91.36 | 89.78 |
Table 9.
Experimental results on the AIR-SARShip dataset.
Table 9.
Experimental results on the AIR-SARShip dataset.
| Datasets | Models | Precision | Recall | | | | |
|---|
| AIR-SARShip | R-Centernet+ | 86.99 | 86.08 | 84.89 | 75.41 | 89.76 | 70.44 |
| Centernet | 83.07 | 85.10 | 83.71 | 74.87 | 88.35 | 70.12 |
| Faster-RCNN | 79.96 | 83.33 | 79.18 | 73.96 | 84.58 | 67.33 |
| AIR-SARShip-inshore | R-Centernet+ | 72.92 | 76.09 | 68.45 | 67.77 | 83.18 | 63.91 |
| Centernet | 71.97 | 75.70 | 66.83 | 66.04 | 82.97 | 62.88 |
| Faster-RCNN | 80.39 | 55.16 | 58.72 | 56.38 | 69.86 | 62.02 |
| AIR-SARShip-offshore | R-Centernet+ | 85.45 | 88.68 | 87.43 | 83.24 | 90.19 | 70.84 |
| Centernet | 85.23 | 86.27 | 85.56 | 80.29 | 89.51 | 70.03 |
| Faster-RCNN | 84.73 | 83.04 | 83.16 | 78.36 | 86.82 | 69.23 |
Table 10.
Comparisons of detection performance with state-of-the-art models on SAR images.
Table 10.
Comparisons of detection performance with state-of-the-art models on SAR images.
| Models | Backbone | SSDD | AIR-SARShip | FPS |
|---|
| Faster-RCNN | Resnet34 | 88.96 | 79.18 | 14 |
| Centernet | DLA34 | 93.82 | 83.71 | 36 |
| R-Centernet+ | CBAM-DLA34 | 95.11 | 84.89 | 33 |
Table 11.
Model comparisons with state-of-the-art models.
Table 11.
Model comparisons with state-of-the-art models.
| Models | Parameters | GFLOPs | Model Size (MB) |
|---|
| Faster-RCNN | 192,764,867 | 23.93 | 539.06 |
| Centernet | 16,520,998 | 28.28 | 75.15 |
| R-Centernet+ | 17,100,223 | 30.64 | 77.92 |
Table 12.
Ablation experiments and results.
Table 12.
Ablation experiments and results.
| CBAM | FEM | Precision | Recall | AP (%) |
|---|
| No | No | 92.05 | 92.63 | 93.82 |
| Yes | No | 94.52 | 93.62 | 94.62 |
| No | Yes | 94.37 | 94.58 | 94.91 |
| Yes | Yes | 95.21 | 95.58 | 95.11 |























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}