1. Introduction
Multi-sensor systems and related information fusion estimation theory have attracted much attention over the last few decades due to their wide range of applications in many fields, including target tracking, robotics, navigation, big data, and signal processing [
1,
2,
3,
4,
5,
6,
7].
In practice, failures during data transmission are unavoidable and lead to uncertain systems. In this regard, a significant problem is the estimation of the state from systems with random sensor delays (see, for example, ref. [
8,
9,
10,
11,
12,
13]). Such delays may be mainly caused by computational load, heavy network traffic, and the limited bandwidth of the communication channel, as well as other limitations, which mean that the measurements are not always up to date [
8]. It is commonly assumed that measurement delays can be described by Bernoulli distributed random variables with known conditional probabilities, where the values 1 and 0 of these variables indicate the presence or absence of measurement delays in the corresponding sensor [
10].
Traditionally, there have been two basic approaches to process the information from multiple sensors, centralized and distributed fusion. In the former approach, all the measurement data from each sensor are collected in a fusion center where they are fused and processed, whereas in the distributed fusion method, the measurements of each sensor are transmitted to a local processor where they are independently processed before being transmitted to the fusion center. It is well known that centralized fusion methods lead to the best (optimal) solution when all sensors work healthily [
14,
15,
16]. The strength of this approach lies in the fact that it is easy to implement, and it makes possible the best use of the available information. Accordingly, with the purpose of optimal estimation, centralized fusion methodology has received increased attention in recent literature related to multi-sensor fusion estimation (see, for example, ref. [
9,
17,
18,
19]). Notwithstanding the foregoing, the main disadvantage of this approach is the high computational load that may be required, especially when the number of sensors is too large. Alternatively, distributed fusion methodologies are developed with the purpose of designing solutions with a reduced computational load. Although distributed fusion approach presents a better robustness, flexibility and reliability due to its parallel structure; the main handicap of these solutions is that they are suboptimal and, hence, it is desirable to explore other alternatives that can alleviate the computational demand. In this respect, the use of hypercomplex algebras may well offer an ideal framework in which to analyze the properness characteristics of the signals which lead to lower computational costs without losing optimality.
In general, the implementation of hypercomplex algebras in signal processing problems has expanded rapidly because of their natural ability to model multi-dimensional data giving rise to better geometrical interpretations. In this connection, quaternions and tessarines appear as 4D hypercomplex algebras composed of a real part and three imaginary parts, which provide them with the ideal structure for describing three and four-dimensional signals. Nowadays, they play a fundamental role in a variety of applications such as robotics, avionics, 3D graphics, and virtual reality [
20]. In principle, the use of quaternions or tessarines means renouncing some of the usual algebraic properties of the real or complex fields. Thus, while quaternion algebra is non-commutative, tessarines become a non-division algebra. These properties make each algebra more appropriate for every specific problem. With this in mind, in [
21,
22,
23,
24] the application of these two isodimensional algebras is compared with the objective of showing how the choice of a particular algebra may determine the proposed method performance.
In the related literature, quaternion algebra has been widely used as a signal processing tool and it is still a trending topic in different areas. In particular, in the area of multi-sensor fusion estimation, ref. [
25,
26] proposed sensor fusion estimation algorithms based on a quaternion extended Kalman filter, ref. [
27,
28] have provided robust distributed quaternion Kalman filtering algorithm for data fusion over sensor networks dealing with three-dimensional data, and [
29] designed a linear quaternion fusion filter from multi-sensor observations. A common characteristic of all the estimation algorithms above is that their methodologies are based on a strictly linear (SL) processing. However, in the quaternion domain, optimal linear processing is widely linear (WL), which requires the consideration of the quaternion signal and its three involutions. In this framework, ref. [
30] devised WL filtering, prediction and smoothing algorithms for multi-sensor systems with mixed uncertainties of sensor delays, packet dropout and missing observations. Interestingly, when the signal presents properness properties (cancellation of one or more of the three complementary covariance matrices), the optimal processing is SL (if the signal is Q-proper) or semi-widely linear (if the signal is C-proper), which amounts to operate on a vector with reduced dimension, which means a significant reduction in the computational load of the associated algorithms (please review [
31,
32,
33,
34] for further details).
On the other hand, the use of tessarines is less common in the signal processing literature and, to the best of the authors’ knowledge, they have never been considered in multi-sensor fusion estimation problems. In general, the use of tessarines in estimation problems has been limited by the fact that it is not being a normed division algebra. This drawback was successfully overcome in [
23] by introducing a metric that guarantees the existence and unicity of the optimal estimator. Moreover, although the optimal processing in the tessarine field is the WL processing, under properness conditions, it is possible to get the optimal solution from estimation algorithms with lower computational costs. In this sense, ref. [
23,
24] introduced the concept of
and
-properness and provided a statistical test to determine whether a signal presents one of these properness properties. According to the type of properness, the most suitable form of processing is
linear processing, which supposes to operate on the signal itself, or
linear processing, based on the augmented vector given by the signal and its conjugate. The application of both
and
linear processing to the estimation problem has provided optimal estimation algorithms of reduced dimension.
Motivated by the above discussions, in this paper we consider a tessarine multiple sensor system where each sensor may be delayed at any time independently from the others. The probability of the occurrence of each delay is dealt by a Bernoulli distribution. Moreover, unlike most sensor fusion estimation algorithms, the observation noises of different sensors can be correlated. In this context, new centralized fusion filtering, prediction and fixed-point smoothing algorithms are designed under both and -properness conditions. The algorithms proposed provide the optimal estimations of the state; meanwhile, the computational load has been reduced with respect to the counterpart tessarine WL (TWL) estimation algorithms. It is important to note that such savings in computational demand cannot be achieved in the real field. The superiority of these algorithms obtained from a linear approach over those derived in the quaternion domain is numerically demonstrated under different conditions of properness.
The remainder of the paper is organized as follows.
Section 2 introduces the notation used throughout the paper and briefly reviews the main concepts related to the processing of tessarine signals and their implications under
properness. Then, in
Section 3, the problem of estimating a tessarine signal in linear discrete stochastic systems with random state delays and multiple sensors is formulated. Concretely, under
-properness conditions, a compact state-space model of reduced dimension is proposed. From this model, and based on
-properness properties,
centralized fusion filtering, step ahead prediction, and fixed-point smoothing algorithms are devised in
Section 4. Furthermore, the goodness of these algorithms in performance is numerically analyzed in
Section 5 by means of a simulation example, where the superiority of the
estimation algorithms above over their counterparts in the quaternion domain is evidenced. The paper ends with a section of conclusions. In order to maintain continuity, all technical proofs have been deferred to the Appendixes
Appendix A,
Appendix B,
Appendix C.
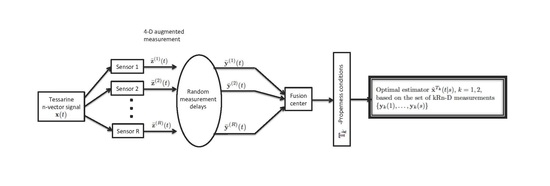
3. Problem Formulation
Consider the class of linear discrete stochastic systems with state delays and multiple sensors
where
R is the number of sensors, ★ is the product defined in (
2),
,
, are deterministic matrices,
is the system state to be estimated,
is a tessarine noise,
is the
ith sensor outputs with tessarine sensor noise
,
is the observation of the
ith sensor,
is a tessarine random vector with components
, for
, composed of independent Bernoulli random variables
,
,
, with known probabilities
, and with possible outcomes
that indicates if the
part of the
jth observation component of the
ith sensor is up-to-date (case
) or there exits one-step delay (case
).
The following assumptions for the above system (
3) are made.
Assumption 1. For a given sensor i, the Bernoulli variable vector is independent of , for , and also is independent of , for any two sensors .
Assumption 2. For a given sensor i, is independent of , and , for any .
Assumption 3. and are correlated white noises with respective pseudo variances and . Moreover, .
Assumption 4. is independent of , for any two sensors .
Assumption 5. The initial state is independent of the additive noises and , for and .
Remark 1. From the hypotheses established on the Bernoulli random variables it follows that, for any , and , 3.1. One-State Delay System under -Properness
In this section, a TWL one-state delay system, which exploits the full amount second-order statistics information available, is introduced and analyzed in -properness scenarios, .
For this purpose, consider the augmented vectors
,
, and
of
,
, and
, respectively. Then, by applying Property 2 on system (
3), the following TWL one-state delay model can be defined:
where
Moreover, from Assumption 3, the pseudo correlation matrices associated to the augmented noise vectors and are given by
;
;
.
The following result establishes conditions on system (
5), which lead to
-properness properties of the processes involved.
Proposition 1. Consider the TWL one-state delay model (5). If and are -proper, and is a block diagonal matrix of the form then is -proper.
If additionally , , is -proper, and and are cross -proper, then and are jointly -proper.
If and are -proper, and is a block diagonal matrix of the form then is -proper.
If additionally, , , , is -proper and , and are cross -proper, then and are jointly -proper.
Proof. The proof follows immediately from the application of the corresponding conditions on system (
5) and the computation of the augmented
pseudo correlation matrices
and
. □
Remark 2. Note that under -properness conditions, , , is a diagonal matrix of the form , with .
Likewise, under -properness conditions, , , takes the form of a block diagonal matrix as follows: where and .
3.2. Compact State-Space Model
By stacking the observations at each sensor in a global observation vector
, the TWL one-state delay system (
5) can be rewritten in a compact form as
where
and
denote the stacking vector of
and
, for
, respectively. Moreover,
,
and
, with
.
In addition, , with , and , with .
In this paper, our aim is to investigate the centralized fusion estimation problem under conditions of
-properness, with
. In this sense, the use of
-properness properties allows us to consider the observation equation with reduced dimension
where
satisfies the state equation in (
7),
and
, with
and
, where
-proper scenario:
;
.
-proper scenario:
;
.
Remark 3. Note that under -properness conditions, is given by , where with , , given in Remark 2.
Similarly, is given by the block diagonal matrix with .
Accordingly, whereas the optimal linear processing for the estimation of a tessarine signal is the TWL processing based on the set of measurements , under -properness conditions the optimal estimator of , , can be computed by projecting on the set of measurements , for . Thereby, estimators are obtained that have the same performance as TWL estimators, but with a lower computational complexity. More importantly, this computational load saving cannot be achieved with the real approach.
Note that tessarine algebra is not a Hilbert space and, as a consequence, neither the existence nor the uniqueness of the projection on a set of tessarines is guaranteed. Nevertheless, this drawback has been overcome in [
23] by defining a suitable metric, which assures the existence and uniqueness of these projections.
The following property sets the correlations between the noises, and , and both the augmented state and the observations .
Property 3. Under Assumptions 1–4, the following correlations hold.
- 1.
Correlations between noises and the augmented state:
- (a)
;
- (b)
, for ;
- (c)
;
- (d)
, for .
- 2.
Correlations between noises and observations:
- (a)
;
- (b)
;
- (c)
, for ;
- (d)
;
- (e)
;
- (f)
, for .
Remark 4. Observe that, under a -properness setting, the state equation in (7) is equivalent to the state equation where,
In such cases, and , for , where and , with .
Nevertheless, Equation (9) cannot be used together with the observation Equation (8), since the latter involves the augmented state vector . 4. -Proper Centralized Fusion Estimation Algorithms
In this section, the
centralized fusion filter, prediction, and fixed-point smoothing algorithms are designed on the basis of the set of observations
,
, defined in (
8).
With this purpose in mind, the observation Equation (
8) is used to devise filtering, prediction, and smoothing algorithms for the augmented state vector
. Then, by applying
-properness properties, the recursive formulas for the filtering, prediction, and smoothing estimators of
are easily determined. Finally, the desired
centralized fusion filtering, prediction and fixed-point smoothing estimators are obtained as a subvector of them.
Theorems 1–3 summarize the recursive formulas for the computation of these estimators as well as their associated error variances.
4.1. Centralized Fusion Filter
Theorem 1. The optimal centralized fusion filter and one-step predictor for the state are obtained by extracting the first n components of the optimal estimator and , respectively, which are recursively computed from the expressions
with and , and where , with and , , defined in Remark 2 for .Moreover, are the innovations calculated as followswith , , and where , , with . In addition, , where is computed through the equation,
with , and the innovations covariance matrix is obtained aswithwherewith , and ,
,
,
,
where , , with entries given in (4), andwhere is recursively computed from Finally, thefiltering and prediction error pseudo covariance matricesand, respectively, are obtained from the filtering and prediction error pseudo covariance matricesand, calculated from the recursive expressions
with , and with .
Remark 5. In the implementation of the above algorithm, the particular structure ofunder-properness conditions should be taken into consideration. In this regard, it is not difficult to check thatis a block diagonal matrix of the form
-properness: ;
-properness: ,
with , , where is recursively computed from
4.2. Centralized Fusion Predictor
Theorem 2. The optimal centralized fusion predictor for the state is obtained by extracting the first n components of the optimal estimator , which is recursively computed from the expression with the initialization the one-step predictor given by (11). Moreover, the -proper prediction error pseudo covariance matrix is obtained from the prediction error pseudo covariance matrix , computed from the recursive expression with the initialization the one-step prediction error pseudo covariance matrix given by (18). 4.3. Centralized Fusion Smoother
Theorem 3. The optimal centralized fusion fixed-point smoother , for a fixed instant , for the state is obtained by extracting the n first components of the optimal estimator , which is recursively computed from the expressions with initial condition given by (10), and where the innovations are recursively computed from (12) and with obtained from the recursive expression (14) and with initialization given by (13) and . Furthermore, the fixed-point smoothing error pseudo covariance matrix is recursively computed through the expression with the filtering error pseudo covariance matrix (17). As mentioned above, the main advantage of the proposed centralized fusion algorithms is that the resulting centralized fusion estimators coincide with the optimal TWL counterparts; meanwhile, they lead to computational savings with respect to the one derived from a TWL approach.
Remark 6. The computational demand of the proposed tessarine estimation algorithms under , for properness conditions is similar to that of their counterparts in the quaternion domain, i.e., the QSL and QSWL estimation algorithms, respectively, (review [34] for a comparative analysis of the computational complexity of quaternion estimators). Therefore, the computational load of TWL estimation algorithms is of order , whereas the , for , algorithms are of order , with . 5. Simulation Examples
In this section, the effectiveness of the above -proper centralized fusion estimation algorithms is experimentally analyzed. With this aim, the following simulation examples have be chosen to reveal the superiority of the proposed -proper estimators over their counterparts in the quaternion domain, when -properness conditions are present.
Let us consider the following tessarine system with three sensors:
with
. The following assumptions are made on the initial state and additive noises.
- 1.
The initial state
is a tessarine Gaussian variable determined by the real covariance matrix
- 2.
is a tessarine white Gaussian noise with a real covariance matrix
- 3.
The measurement noises
of the three sensors are tessarine white Gaussian noises defined as
where the coefficients
are the constant scalars
,
, and
and
,
, are
-proper tessarine white Gaussian noises with mean zeros and real covariance matrices
with
,
, and
, and independent of
. Note that, if
, then the noises
and
are uncorrelated. In the opposite case, when
becomes more different from 0, the correlation between
and
is stronger.
Moreover, at every sensor i, the Bernoulli random variables , , have the constant probabilities , for all .
In this framework, a comparative study between tessarine and quaternion approaches is carried out to evaluate the performance of the proposed filtering, prediction and smoothing algorithms under and properness conditions. Specifically, besides the filtering, the 3-step prediction and fixed-point smoother at problems are considered in our simulations.
5.1. Study Case 1: -Proper Systems
Consider the values
in (
25) and
and
in (
26), and the Bernoulli probabilities
;
;
.
Note that, under these conditions, both and , , are jointly -proper.
For the purpose of comparison, the error variances of both and QSL estimators have been computed for different Bernoulli probabilities , . We denote the QSL error variances by . Then, as a performance measure, we compute the difference between the and QSL error variances associated to the filter, , the 3-step predictor, , and the fixed-point smoother at , , for .
Firstly, these differences are displayed in
Figure 1 considering different degrees of correlations between the state and measurement noises: independent noises (
), low correlations (
,
,
), and high correlations (
,
,
) and two levels of uncertainties: high delay probabilities (case
,
,
) and low delay probabilities (case
,
,
). As we can see, in all situations these differences are positive, which indicate that the proposed
estimators outperform the QSL estimators. Moreover, this superiority in performance increases when the correlation between the system noises is higher. With respect to the levels of uncertainties, a better behavior of the
estimators over the QSL counterparts is generally observed in the scenario of high delays probabilities, i.e., when the Bernoulli probabilities are smaller.
Next, in order to evaluate the performance of the proposed estimators versus the probability of delay, we consider the same Bernoulli probabilities in the three sensors
, and the difference between the
and QSL error variances are computed for different values of
p.
Figure 2 illustrates these differences for
. In these figures, the superiority in performance of
estimators over QSL estimators is confirmed since
in every case. Additionally, in the filtering and prediction problems it is observed that this superiority is higher for the smallest Bernoulli probabilities, i.e., when the delay probabilities are greater. On the other hand, in the fixed-point smoothing problem, a similar behavior for Bernoulli probabilities
p and
is obtained, the advantages of the
smoothing algorithm being higher than the QSL one at intermediate values of
p (case
and
). These results are examined in detail below.
Our aim now is to analyze the benefits of our
estimation algorithms in terms of the Bernoulli probabilities of the three sensors
p. In this analysis, different values of
c in (
26) are also considered. Then, the means of the difference between the
and QSL filtering, prediction, and fixed-point smoothing error variances have been computed as
Filtering problem: ;
3-step prediction problem: ;
Fixed-point smoothing problem: ;
for
p varying from 0 to 1 and the values of
, and
, and where
,
and
denote the difference between the
and QSL filtering, 3-step prediction, and fixed-point smoothing error variances, respectively, for a value of the Bernoulli probability
p. Note that in the case
, the noise
is, besides being
-proper,
-proper, and a higher value of
c means that the noise
moves further away from the
-properness condition. The results of this analysis are depicted in
Figure 3 where, on the one hand, we can clearly observe how the best performance of
filtering and prediction estimators over the QSL counterparts is obtained for the smallest Bernoulli probabilities. Specifically, except for the case
, the maximum difference between
and QSL errors is achieved when the Bernoulli probability takes the value 0, i.e., when only one-step delay exists in the measurements. However, in the fixed-point smoothing problem
is more advantageous when the Bernoulli probabilities
p tend to
. On the other hand, in every case, the superiority of our
estimation algorithms is more evident as the parameter
c in (
26) grows, i.e., the noise
is further away from the
-properness condition.
5.2. Study Case 2: -Proper Systems
Consider the values
in (
25),
in (
26), and the Bernoulli probabilities for the three sensors as in
Section 5.1. Note that, under these conditions, both
and
,
, are jointly
-proper.
Thus, we are interested in comparing the behavior of centralized fusion estimators with their counterparts in the quaternion domain, i.e., the quaternion semi-widely linear (QSWL) estimators. For this purpose, the and QSWL error variances, and , respectively, have been computed by considering different Bernoulli probabilities for the three sensors.
Specifically, we consider the filtering, the 3-step prediction, and the fixed-point smoothing problems at , and, as a measure of comparison, we use the difference between both QSWL and error variances, which are defined as (filtering), (3-step prediction), and (fixed-point smoothing).
Figure 4 and
Figure 5 compare the difference between QSWL and
centralized estimation error variances for different Bernoulli probabilities
,
and
. Specifically,
Figure 4 analyzes the filtering and 3-step prediction error variance differences
and
for the following cases:
- 1.
Case 1: for values of in three situations: and , and , and ;
- 2.
Case 2: for values of in three situations: and , and , and ;
- 3.
Case 3: for values of in three situations: and , and , and .
It should be highlighted that similar results are obtained with any other combination of Bernoulli probabilities , .
From these figures, we can reaffirm that
processing is a better approach than the QSWL processing in terms of performance (
). Moreover, in the filtering and 3-step prediction problems (
Figure 4), this fact is more evident when the probabilities of the Bernoulli variables decrease (that is, the delay probabilities increase).
The differences between both QSWL and
error variances for the fixed-point smoothing problem are illustrated in
Figure 5. Note that, since the behavior of the differences between QSWL and
fixed-point smoothing errors is similar for Bernoulli probabilities values
and
, these differences are analyzed in the following cases:
- 1.
Case 4: for values of in three situations: and , and , and .
- 2.
Case 5: for values of in three situations: and , and , and .
- 3.
Case 6: for values of in three situations: and , and , and .
In every situation, the better behavior of processing over the QSWL processing is verified, and also this superiority increases when the Bernoulli probabilities tends to , i.e., when there is a similar chance of receiving updated and delayed information.
6. Discussion
From among the different sensor fusion methods, it is the centralized fusion techniques that provide the optimal estimators from measurements of all sensors. Nevertheless, to avoid the computational load involved in these estimates, especially in systems with a large number of sensors, suboptimum estimation algorithms have been traditionally designed by using a decentralized fusion approach. This paper has overcome the above computational difficulties without renouncing to obtain the optimal solution, by considering hypercomplex algebras. Quaternions and, more recently, tessarines are the most usual 4D hypercomplex algebra employed in signal processing. Commonly, since both quaternions and tessarines are isomorfic spaces to , they involve the same computational complexity. Interestingly, under properness conditions, this complexity in terms of dimension is reduced to a half for QSWL and -proper methods and four times for QSL and -proper methods, which leads to a significant reduction in the computational load of our algorithms. Precisely, it is in this context that the use of hypercomplex algebras becomes an ideal tool with computational advantages over the existing methods to address the centralized fusion estimation problem.
In general, neither of these algebras always performs better than the other, and the choice of the most suitable one is conditioned by the characteristics of the signal. Due to the commutativity and reduced computational complexity, the tessarine algebra makes it particularly interesting for our purposes. Thus, under conditions of -properness, filtering, prediction, and fixed-point smoothing algorithms of reduced dimension have been devised for the estimation of a vectorial tessarine signal based on one-step randomly delayed observations coming from multiple sensors stochastic systems with different delay rates and correlated noises. The reduction of the dimension of the problem under -properness scenarios makes it possible for these algorithms to facilitate the computation of the optimal estimates with a lower computational cost in comparison with the real processing approach. It should be highlighted that this computational saving cannot be attained in the real field.
The good performance of the algorithms proposed has been experimentally illustrated by means of two simulation examples, where the better behavior of the proposed estimates over their counterparts in the quaternion domain under -properness conditions has been evidenced.
In future research, we will set out to explore the design of decentralized fusion estimation algorithms for hypercomplex signals and investigate the use of new hypercomplex algebras in this field.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




