
Traffic Accident Data Generation Based on Improved Generative Adversarial Networks


Abstract
:1. Introduction
2. Literature Review
3. Materials and Methods
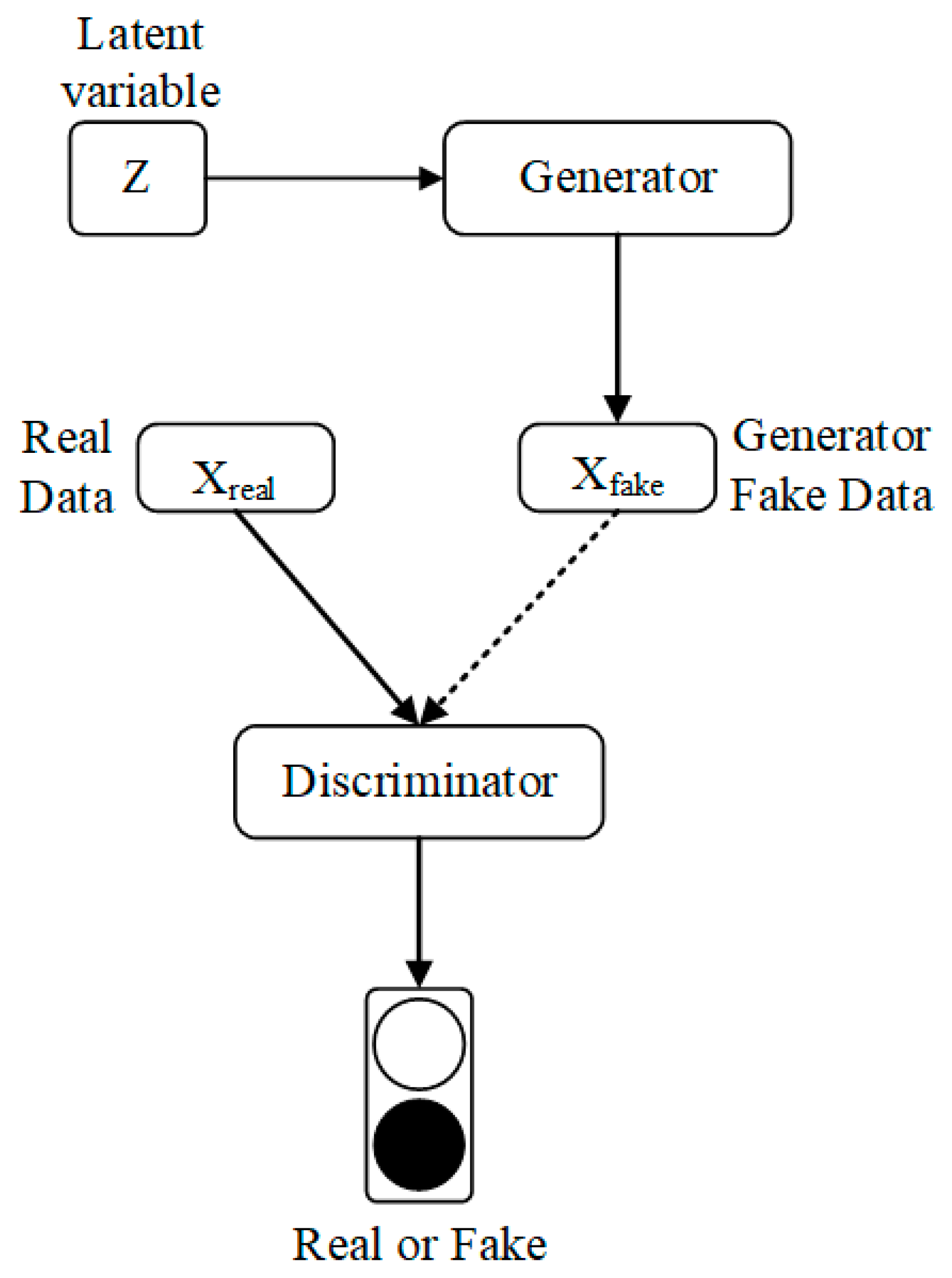
3.1. Generative Adversarial Networks
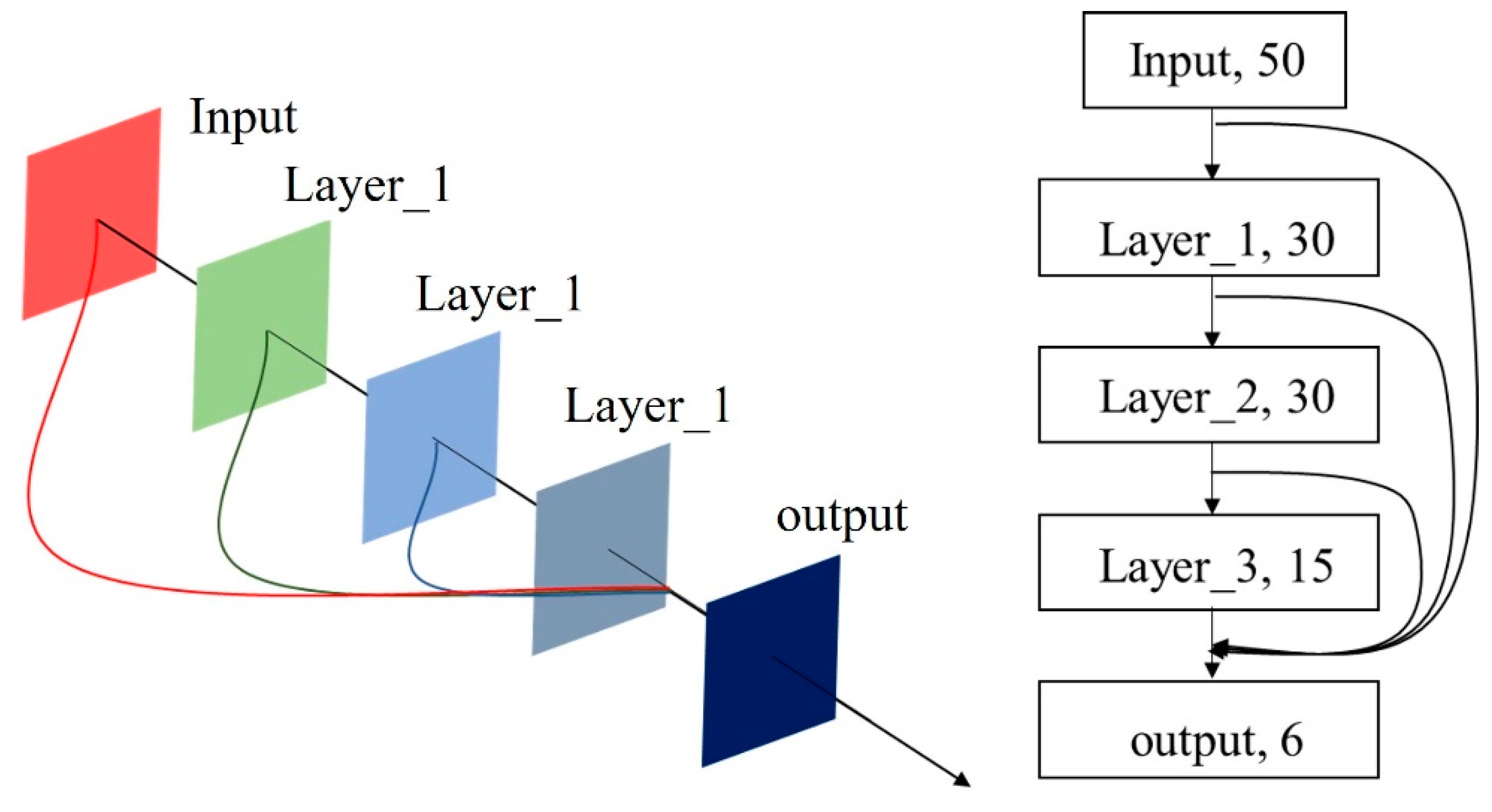
3.2. Improved Generative Adversarial Networks
| Algorithm 1. Traffic Data Generation |
| The stochastic gradient descent training process of the improved GAN. Parameter k: The ratio of the frequency of updating the generator to updating the discriminator. Parameter j: The upper limit of the number of iterations. Begin |
| 1. for j = 1…j |
| 2. for k = 1…k |
| 3. Calculate m samples G1(Z1, Z2...Zm), G2(Z1, Z2...Zm), Gn(Z1, Z2...Zm) generated by Z through different generators, mix them to form the final generated sample G(Z1, Z2...Zm) |
| 4. Extract m real samples X (x1, x2... xm) |
| 5. Updated discriminator parameters: |
| 6. end for |
| 7. Extract m generating samples separately G1(Z1, Z2…Zm), G2(Z1, Z2…Zm), Gn(Z1, Z2…Zm) |
| 8. Update generator parameters: |
| 9. end for |
4. Experimental Setup
4.1. Parameter Settings for Traffic Accident Data Generation
4.2. Typical Classifiers Used in the Experiments
- Convolutional Neural Network (CNN)
- 2.
- Support Vector Machine (SVM)
- 3.
- K-Nearest Neighbor (KNN)
- 4.
- Ridge Regression (RR)
4.3. Description of the Traffic Accident Dataset
5. Results and Discussion
5.1. Traffic Accident Data Generation
5.2. Comparison Results of Accuracy of Traffic Accident Recognition
5.3. Comparison Results of Traffic Accident Recognition
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Frid-Adar, M.; Diamant, I.; Klang, E.; Amitai, M.; Goldberger, J.; Greenspan, H. GAN-based synthetic medical image augmentation for increased CNN performance in liver lesion classification. Neurocomputing 2018, 321, 321–331. [Google Scholar] [CrossRef] [Green Version]
- Bang, S.; Baek, F.; Park, S.; Kim, W.; Kim, H. Image augmentation to improve construction resource detection using generative adversarial networks, cut-and-paste, and image transformation techniques. Autom. Constr. 2020, 115, 103–198. [Google Scholar] [CrossRef]
- Onan, A. Mining opinions from instructor evaluation reviews: A deep learning approach. Comput. Appl. Eng. Educ. 2019, 28, 117–138. [Google Scholar] [CrossRef]
- Kavakiotis, I.; Tsave, O.; Salifoglou, A.; Maglaveras, N.; Vlahavas, I.; Chouvarda, I. Machine Learning and Data Mining Methods in Diabetes Research. Comput. Struc. Biotechnol. J. 2017, 15, 104–116. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial nets. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2014; pp. 2672–2680. [Google Scholar]
- Shan, H.; Zhang, Y.; Yang, Q.; Kruger, U.; Kalra, M.K.; Sun, L.; Cong, W.; Wang, G. 3D Convolutional Encoder-Decoder Network for Low-Dose CT via Transfer Learning from a 2D Trained Network. IEEE Trans. Med. Imaging 2018, 37, 1522–1538. [Google Scholar] [CrossRef]
- Chen, X.; Li, Z.; Yang, Y.; Qi, L.; Ke, R. High-resolution vehicle trajectory extraction and denoising from aerial videos. IEEE Trans. Intell. Transp. Syst. 2020, 22, 3190–3202. [Google Scholar] [CrossRef]
- Huang, G.; Jafari, A.H. Enhanced balancing GAN: Minority-class image generation. Neural Comput. Appl. 2021, 1–10. [Google Scholar] [CrossRef]
- Zhang, T.; Wu, X.; Lin, M.; Han, J.; Hu, S. Imbalanced sentiment classification enhanced with discourse marker. In Proceedings of the International Conference on Artificial Neural Networks, Munich, Germany, 17–19 September 2019; Springer: Cham, Germany, 2019; pp. 117–129. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. Comput. Sci. 2014, 5, 2672–2680. [Google Scholar]
- Miyato, T.; Koyama, M. cGANs with projection discriminator. arXiv 2018, arXiv:1802.05637. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein GAN. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Miyato, T.; Kataoka, T.; Koyama, M.; Yoshida, Y. Spectral Normalization for Generative Adversarial Networks. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Jolicoeur, M.A. The relativistic discriminator: A key element missing from standard GAN. arXiv 2018, arXiv:1807.00734. [Google Scholar]
- Li, W.; Ding, W.; Sadasivam, R.; Cui, X.; Chen, P. His-GAN: A histogram-based GAN to improve data generation quality. Neural Netw. 2019, 119, 31–45. [Google Scholar] [CrossRef]
- Qi, G. Loss-Sensitive Generative Adversarial Networks on Lipschitz Densities. Comp. Vis. Pattern Recognit. 2017, 128, 1357–1365. [Google Scholar] [CrossRef] [Green Version]
- Brock, A.; Donahue, J.; Simonyan, K. Large scale gan training for high fidelity natural image synthesis. arXiv 2018, arXiv:1809.11096. [Google Scholar]
- Akbari, M.; Liang, J. Semi-recurrent CNN-based VAE-GAN for sequential data generation. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 2321–2325. [Google Scholar]
- Chen, Z.; Chen, D.; Zhang, Y.; Cheng, X.; Zhang, M.; Wu, C. Deep learning for autonomous ship-oriented small ship detection. Saf. Sci. 2020, 130, 104812. [Google Scholar] [CrossRef]
- Chen, Z.; Zhang, Y.; Wu, C.; Ran, B. Understanding individualization driving states via latent Dirichlet allocation model. IEEE Intell. Transp. Syst. Mag. 2019, 11, 41–53. [Google Scholar] [CrossRef]
- Chen, Z.; Cai, H.; Zhang, Y.; Wu, C.; Mu, M.; Li, Z.; Sotelo, M.A. A novel sparse representation model for pedestrian abnormal trajectory understanding. Expert Syst. Appl. 2019, 138, 112753. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhu, R.; Chen, Z.; Gao, J.; Xia, D. Evaluating and selecting features via information theoretic lower bounds of feature inner correlations for high-dimensional data. Eur. J. Oper. Res. 2021, 290, 235–247. [Google Scholar] [CrossRef]
- Liu, R.W.; Yuan, W.; Chen, X.; Lu, Y. An enhanced CNN-enabled learning method for promoting ship detection in maritime surveillance system. Ocean Eng. 2021, 235, 109435. [Google Scholar] [CrossRef]
- Chen, X.; Qi, L.; Yang, Y.; Luo, Q.; Postolache, O.; Tang, J.; Wu, H. Video-based detection infrastructure enhancement for automated ship recognition and behavior analysis. J. Adv. Transp. 2020, 2020, 12. [Google Scholar] [CrossRef] [Green Version]
- Liang, X.; Meng, X.; Zheng, L. Investigating conflict behaviours and characteristics in shared space for pedestrians, conventional bicycles and e-bikes. Accid. Anal. Prev. 2021, 158, 106167. [Google Scholar] [CrossRef]
- Tang, T.; Guo, Y.; Zhou, X.; Labi, S.; Zhu, S. Understanding electric bike riders’ intention to violate traffic rules and accident proneness in China. Travel Behave. Soc. 2021, 23, 25–38. [Google Scholar] [CrossRef]
- Zhu, D.; Sze, N.N.; Feng, Z. The trade-off between safety and time in the red light running behaviors of pedestrians: A random regret minimization approach. Accid. Anal. Prev. 2021, 158, 106214. [Google Scholar] [CrossRef] [PubMed]
- Wu, C.; Chen, L.; Wang, G.; Chai, S.; Jiang, H.; Peng, J.; Hong, Z. Spatiotemporal Scenario Generation of Traffic Flow Based on LSTM-GAN. IEEE Access 2020, 8, 186191–186198. [Google Scholar] [CrossRef]
- Nguyen, T.; Le, T.; Vu, H.; Phung, D. Dual discriminator generative adversarial nets. Advances in Neural Information Processing Systems. arXiv 2017, arXiv:1709.03831. [Google Scholar]
- Hong, Y.; Hwang, U.; Yoo, J.; Yoon, S. How generative adversarial networks and their variants work: An overview. ACM Comput. Surv. CSUR 2019, 52, 1–43. [Google Scholar] [CrossRef] [Green Version]
- Liu, H.; Hussain, F.; Tan, C.L.; Dash, M. Discretization: An Enabling Technique. Data Min. Knowl. Discov. 2002, 6, 393–423. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Gatys, L.; Ecker, A.; Bethge, M. Image style transfer using convolutional face generational neural networks. In Proceedings of the International Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 441–450. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Geoffrey, E. Image Net Classification with Deep Convolutional Neural Networks. E-Print 2012, 302, 84–90. [Google Scholar]
- Cox, D.R. Regression Models and Life-Tables. J. R. Stat. Soc. Ser. B Methodol. 1972, 34, 187–202. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| G1 | G2 | G3 |
|---|---|---|
| Input fc, 50, sigmoid | Input fc, 50, sigmoid | Input fc, 50, sigmoid |
| Fc, 30, Relu | fc, 30, Relu | fc, 30, Relu |
| fc, 30, Relu | fc, 30, Relu | |
| fc, 15, Relu | ||
| Concat | ||
| fc, 6, Relu | ||
| Prediction Category | Accident | Normal | |
|---|---|---|---|
| True Category | |||
| Accident | True Positives (TP) | False Negatives (FN) | |
| Normal | False Positives (FP) | True Negatives (TN) | |
| Feature Name | Abbreviation | Definition | Instruction |
|---|---|---|---|
| Average of Speed (km/h) | Va | Average of instantaneous speeds of vehicles over some time. | |
| Variance of Speed (km2/h2) | Var_V | The range of instantaneous speed value of the model in an instant. | |
| Standard deviation of Speed (km/h) | Std_V | The standard deviation of the instantaneous speed value of the vehicle over some time. | |
| Average of Acceleration (m/s2) | aa | The average value of the instantaneous acceleration value of the vehicle over some time. | |
| Variance of Acceleration (m2/s4) | Var_a | The variance of the instantaneous acceleration value of the vehicle over some time. | |
| Standard deviation of Acceleration (m/s2) | Std_a | The standard deviation of the instantaneous acceleration value of the vehicle over some time. |
| Features | Average | Maximum | Minimum | Median | Variance | |
|---|---|---|---|---|---|---|
| Average of speed (km/h) | normal | 87.39 | 101.64 | 68.69 | 88.45 | 75.49 |
| accident | 69.97 | 105.4 | 43.5 | 68.29 | 188.63 | |
| Average of acceleration (m/s2) | normal | 0 | 0.13 | −0.13 | 0.007 | 0.004 |
| accident | −0.19 | −0.011 | −0.394 | −0.19 | 0.006 | |
| standard deviation of Speed (km/h) | normal | 7.52 | 18.87 | 1.76 | 7.16 | 12.77 |
| accident | 29.79 | 47.2 | 3.65 | 30.25 | 88.26 | |
| Standard deviation of acceleration (m/s2) | normal | 0.5 | 1.02 | 0.12 | 0.58 | 0.050 |
| accident | 1.18 | 1.91 | 0.72 | 1.11 | 0.12 | |
| Variance of velocity (km2/h2) | normal | 69.10 | 355.96 | 3.09 | 51.19 | 4269.10 |
| accident | 973.96 | 2227.84 | 13.35 | 915.37 | 261,835.13 | |
| variance of Acceleration (m2/s4) | normal | 0.35 | 1.04 | 0.01 | 0.33 | 0.061 |
| accident | 1.50 | 3.65 | 0.52 | 1.22 | 0.82 | |
| Features | Average | Maximum | Minimum | Median | Variance | ||
|---|---|---|---|---|---|---|---|
| Average of speed (km/h) | normal | original | 87.39 | 101.64 | 68.69 | 88.45 | 75.49 |
| generated | 86.99 | 102.18 | 66.26 | 87.24 | 54.29 | ||
| accident | original | 69.97 | 105.4 | 43.5 | 68.29 | 188.63 | |
| generated | 71.24 | 100.8 | 48.05 | 71.90 | 142.01 | ||
| Average of acceleration (m/s2) | normal | original | 0 | 0.13 | −0.13 | 0.007 | 0.004 |
| generated | 0.006 | 0.14 | −0.11 | 0.010 | 0.003 | ||
| accident | original | −0.19 | −0.011 | −0.394 | −0.19 | 0.006 | |
| generated | −0.18 | −0.01 | −0.323 | −0.17 | 0.005 | ||
| standard deviation of speed (km/h) | normal | original | 7.52 | 18.87 | 1.76 | 7.16 | 12.77 |
| generated | 8.74 | 17.21 | 1.06 | 8.82 | 15.94 | ||
| accident | original | 29.79 | 47.2 | 3.65 | 30.25 | 88.26 | |
| generated | 30.88 | 47.12 | 13.23 | 30.77 | 49.66 | ||
| Standard deviation of acceleration (m/s2) | normal | original | 0.5 | 1.02 | 0.12 | 0.58 | 0.050 |
| generated | 0.656 | 1.06 | 0.15 | 0.68 | 0.039 | ||
| accident | original | 1.18 | 1.91 | 0.72 | 1.11 | 0.12 | |
| generated | 1.13 | 1.88 | 0.59 | 1.08 | 0.09 | ||
| Variance of velocity (km2/h2) | normal | original | 69.10 | 355.96 | 3.09 | 51.19 | 4269.10 |
| generated | 80.96 | 232.34 | 3.80 | 68.89 | 2541.35 | ||
| accident | original | 973.96 | 2227.84 | 13.35 | 915.37 | 261,835.13 | |
| generated | 1127.51 | 2702.43 | 175.11 | 1067.94 | 355,275.85 | ||
| Variance of Acceleration (m2/s4) | normal | original | 0.35 | 1.04 | 0.01 | 0.33 | 0.061 |
| generated | 0.44 | 1.07 | 0.02 | 0.40 | 0.059 | ||
| accident | original | 1.50 | 3.65 | 0.52 | 1.22 | 0.82 | |
| generated | 1.31 | 2.84 | 0.35 | 1.16 | 0.43 | ||
| Features | p-Val (F-Test) | p-Val (t-Test) | Significant Differences | |
|---|---|---|---|---|
| Average of speed (km/h) | normal | 0.1260 | 0.8032 | NO |
| accident | 0.1618 | 0.6250 | NO | |
| Average of acceleration (m/s2) | normal | 0.1268 | 0.5479 | NO |
| accident | 0.3434 | 0.7360 | NO | |
| Standard deviation of speed (km/h) | normal | 0.2201 | 0.1099 | NO |
| accident | 0.1233 | 0.5139 | NO | |
| Standard deviation of acceleration (m/s2) | normal | 0.2266 | 0.1138 | NO |
| accident | 0.1748 | 0.4630 | NO | |
| Variance of velocity (km2/h2) | normal | 0.1362 | 0.3120 | NO |
| accident | 0.1444 | 0.1700 | NO | |
| Variance of Acceleration (m2/s4) | normal | 0.4760 | 0.0581 | NO |
| accident | 0.1136 | 0.2244 | NO | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Z.; Zhang, J.; Zhang, Y.; Huang, Z. Traffic Accident Data Generation Based on Improved Generative Adversarial Networks. Sensors 2021, 21, 5767. https://doi.org/10.3390/s21175767
Chen Z, Zhang J, Zhang Y, Huang Z. Traffic Accident Data Generation Based on Improved Generative Adversarial Networks. Sensors. 2021; 21(17):5767. https://doi.org/10.3390/s21175767
Chicago/Turabian StyleChen, Zhijun, Jingming Zhang, Yishi Zhang, and Zihao Huang. 2021. "Traffic Accident Data Generation Based on Improved Generative Adversarial Networks" Sensors 21, no. 17: 5767. https://doi.org/10.3390/s21175767
APA StyleChen, Z., Zhang, J., Zhang, Y., & Huang, Z. (2021). Traffic Accident Data Generation Based on Improved Generative Adversarial Networks. Sensors, 21(17), 5767. https://doi.org/10.3390/s21175767