4.1. Experimental Testbed
The experimental results were obtained considering the device under test relative to LMBA described in [
2]. The input signals relative to the dual-input LMBA were preamplified by using two linear drivers from Minicircuits. As depicted in
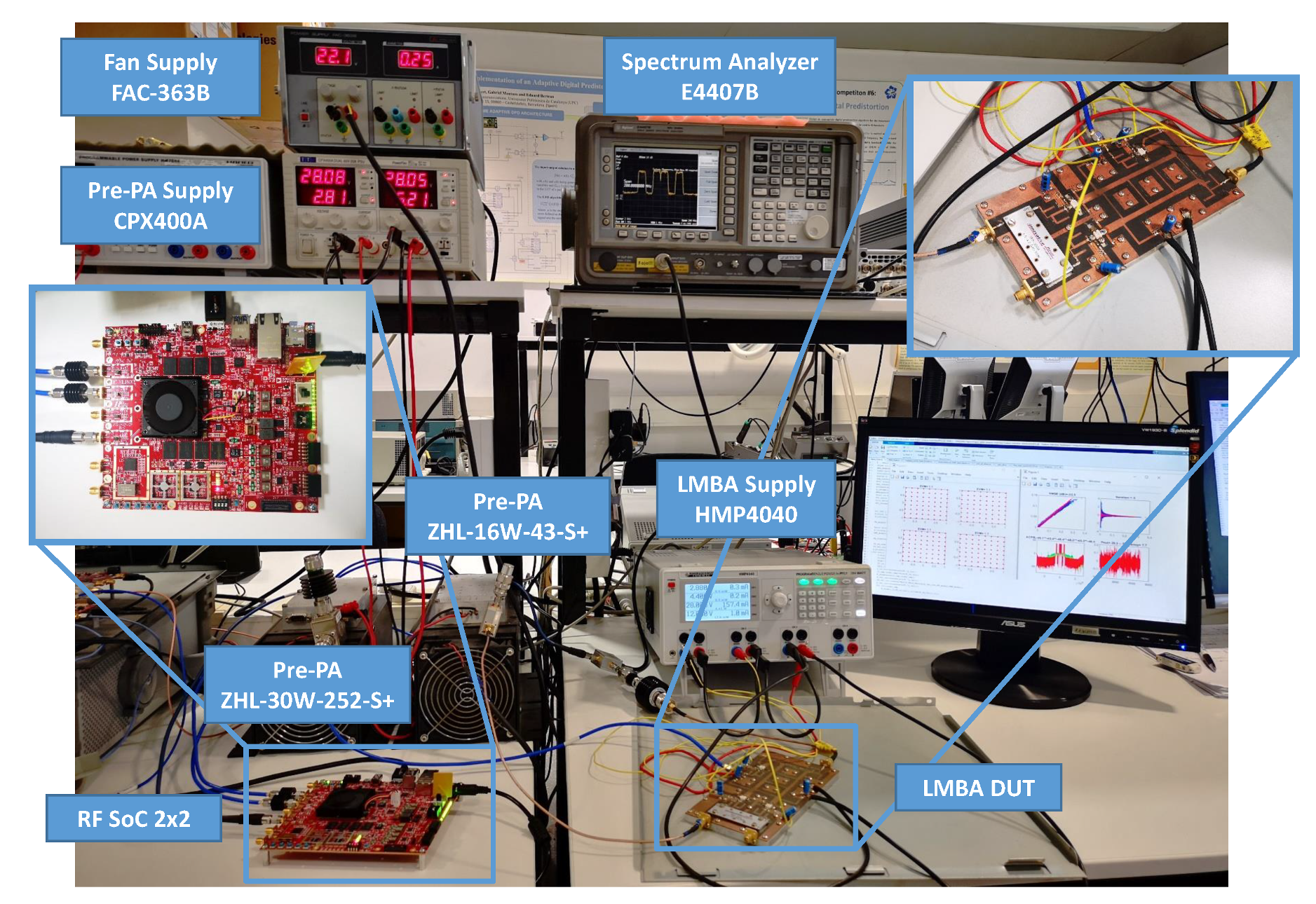
Figure 4, the testbed deployed to obtain experimental results comprises a software defined radio (SDR) platform for waveform playback and data capture, digital-to analog conversion (DAC), I-Q modulator and analog-to-digital conversion (ADC) for direct radio frequency sampling. The testbed is connected to a host PC, which runs as a server providing remote interface for signal generation, transmission and reception.
The SDR platform consists of a radio frequency system-on-chip (RFSoC) 2 × 2 board. The platform features a Xilinx Zynq UltraScale+ RFSoC ZU28DR FPGA device, which is supported by two 12-bit (4 GSa/s.) and two 14-bit (6.4 GSa/s.) ports. The board supports Multi-Tile Synchronization of the ADC/DAC channels; thus, we can use it to simultaneously generate the reliable RF signal and the LMBA control signal, which are phase locked and time aligned. The board uses the PYNQ framework, which is a Linux-based Python environment that eases the use of driver interfaces. We developed our custom overlay (i.e., FPGA Bitstream) to implement a pattern generator and a signal receiver that can send and receive a long signal pattern. The board can work alone or as a server. Clients (PCs) can send and receive pattern signals by using HTTP APIs. Once the pattern is loaded, the RFSoC simultaneously generates the RF signal in a cyclic mode.
For our particular validation tests, the RFSoC board was configured with a baseband sampling rate of 614.4 MSa/s. for both the ADC and the DAC tiles. In the transmission path, the baseband signals are digital up-converted and interpolated to RF signals of 4.9152 GSa/s. by the radio frequency data converter (RFDC) IP from Xilinx. In the receive path, the ADC samples, sampled at a rate of 2.4576 GSa/s, are decimated and digital down-converted by the RFDC. Since the centering LMBA is operated at a center frequency of 2 GHz, the second Nyquist zone of the ADC is used.
4.2. Behavioral Model, Test Data and Evaluation Metrics
The feature selection techniques presented in previous sections allow us to reduce the number of coefficients of a given behavioral model at the price of some degradation of the modeling or linearization performance. In this paper, the GMP behavioral model [
25] has been considered in order to evaluate the performance of the dimensionality reduction algorithms under study. Unlike simpler behavioral models such as the MP, the GMP includes bi-dimensional kernels that take into account cross-term products between the complex signal and the lagging and leading envelope terms. This property increases the accuracy of the modeling at the price of increasing the number of coefficients. However, its complexity does not scale as quickly as the original Volterra series when considering high order kernels. Following the behavioral modeling notation, the estimated output considering a GMP can be described as follows:
where
and
are the nonlinearity orders of the polynomials and
and
determine the memory and cross-memory length.
,
and
are the complex coefficients describing the model, and
,
and
(with
and
) are the most significant delays of the input signal
that better contribute in characterizing memory effects. The total number of coefficients of GMP model is
.
The initial configuration of the GMP from which the most relevant parameters are selected include the following:
;
;
.
This configuration provides an initial number of coefficients of .
The comparison of feature selecting techniques was carried out by considering long term evolution (LTE) (OFDM-like) waveforms. When comparing the different feature selection techniques for PA behavioral modeling, we used input-output data of the LMBA excited with a noncontiguous intra-band carrier-aggregated (CA) LTE system consisting in four channels of 64 QAM modulated LTE-20 signals (CA-4 × LTE-20) spread in 200 MHz instantaneous bandwidth at 2 GHz RF frequency and a PAPR of 10.7 dB. Different datasets were used to train and validate the PA behavioral models when considering different coefficients. Please note that although the test signal holds four channels, the model under test does not consider cross-term products of the bands but the entire bandwidth. The use of a four-dimensional model would rocket the number of coefficients to an unmanageable number, and since the single-band GMP is able to achieve a satisfactory level of linearization while still highlighting the differences between the techniques under comparison, it is considered as adequate for the experimental benchmark.
In the validation of feature selection techniques for DPD purposes, we considered the same non contiguous intra-band CA LTE system consisting of four channels of 64 QAM modulated LTE-20 signals but spread in 120 MHz. For each signal, the training dataset consisted in 307,200 complex-valued data samples, which, considering a baseband clock of 614.4 MSa/s, corresponded to 0.5 mseconds of an OFDM waveform (i.e., approximately eight OFDM symbols in LTE). The obtained LMBA configuration was later validated (including DPD linearization) by considering different batches of data of 307,200 complex-valued data samples.
In order to compare the different dimensionality reduction techniques, it is crucial to define accurate metrics to evaluate their performance. Several metrics have been proposed for both behavioral modeling and DPD linearization.
Some key metrics for PA design, such as the peak and mean output power, gain or power efficiency, are not used for the comparison of the different feature selection techniques since all of them are tested with the same DUT operated with the same configuration. However, for the sake of reference, with the LMBA used in this paper, when considering the CA-4 × LTE-20 signal with 200 MHz instantaneous bandwidth and PAPR of 10.5 dB, the linearity specifications (ACPR < −45 dBc) are met after linearization with a mean output power of around 33 dBm and a power efficiency of around 22%, as reported in [
23].
For PA behavioral modeling, some of the most commonly used performance indicators are the NMSE and the adjacent channel error power ratio (ACEPR). The NMSE indicates how well the model is approximating the reality, i.e., the difference between the estimated and the real (measured) output squared, normalized by the measured output squared. The NMSE is normally expressed in dB as follows:
where
denotes the measured signal at the PA output,
denotes the modeled output and N the number of samples. Since NMSE is dominated by the in-band error, it is generally used to evaluate the in-band performance of the model.
In order to highlight the out-of-band modeling capabilities, the ACEPR metric is proposed. This metric calculates power of the error between the modeled and the measured signals in the adjacent channels normalized by the in-band channel power. The ACEPR is commonly measured in dB:
where
is the Fourier transform of the measured output signal and
is the Fourier transform of the modeled output signal. In the numerator, the operation is performed by taking into account the adjacent channels, while we take into account the transmission channel in the denominator.
For DPD linearization, the metrics for evaluating the in-band and out-of-band distortion are the error vector magnitude (EVM) and adjacent channel power ratio (ACPR), respectively.
The EVM is defined as the square root of the ratio between the mean error vector power to the mean reference vector power
;
N is the number of samples:
where
and
are the in-phase (
) and quadrature (
) components of the measured PA output, respectively.
The expansion of the signal to the adjacent channels is characterized by the ACPR, also known as the adjacent channel leakage ratio (ACLR). The ACPR is the ratio of the power in the adjacent channels (upper and lower bands, i.e.,
UB and
LB) to the power of the main channel (in-band, i.e.,
B):
Regarding the computational complexity assessment, it is common to use the Landau notation to represent the complexity (in terms of number of operations) of the algorithms. The main issue for using this figure of merit is that, for heuristic algorithms, it is very difficult to perform a complexity analysis using the Landau notation on the results. A simpler approach consists in calculating the running time of the different algorithms. Although this figure of merit strongly depends on the hardware from where the code is being executed, in this benchmark the running time is obtained by using the same hardware to make a fair comparison.
4.3. Experimental Results
In a first approach, a comparison of feature selection algorithms in the context of PA behavioral modeling was conducted. Therefore, despite the specific particularities of each of the previously-described algorithms it was possible to compare their performance in terms of NMSE and ACEPR versus the number of coefficients. In a second approach, after identifying some trends, a selection of the three most promising feature selection algorithms (from different families) was carried out in order to test them for DPD linearization purposes. Consequently, these algorithms were compared again, but this time in terms of key linearization indicators such as EVM and ACPR.
Figure 5 and
Figure 6 show the NMSE and ACEPR, respectively, for different number of parameters of the GMP behavioral model and by considering the aforementioned dimensionality reduction algorithms. As observed, the ones showing better NMSE and ACEPR when reducing the number of coefficients are the matching pursuit family (in particular, the DOMP and SP), the DMS and the LASSO. It is important to highlight that some of these search algorithms require tuning certain hyperparameters that determine the final results, which is the case of global probabilistic optimization algorithms (e.g., adaLIPO, SA and GA) or the heuristic local search methods (DMS and HC).
As an example,
Figure 7 shows the different NMSE results obtained for the different cases evaluated by the GA. In order to include the results of this search in the comparison of
Figure 5 and
Figure 6, the Pareto front, which contains the best NMSE for a given number of coefficients, is extracted as depicted in
Figure 7. These results were obtained after fine tuning of the hyperparameters in the fitness score, in the selection, crossover or mutation processes. It is difficult to guarantee that these are the best results that can be found, but at least they are relevant enough for showing the trend. For selecting the most suitable algorithm for DPD linearization, the necessity, or not, of tuning certain hyperparameters has to be also taken into account. For example, the regularization-based algorithms or the family of the matching pursuit do not require any critical hyperparameter tuning.
As an example to evidence the modeling capabilities when using the GMP model with the most relevant 100 coefficients selected using the DOMP,
Figure 8 and
Figure 9 show the AM-AM characteristic and the spectra, respectively, for both the measured and modeled PA output data. As observed, it is possible to achieve −33 dB of NMSE and −37.5 dB of ACEPR with 100 coefficients.
As discussed before, for a proper comparison of the computational complexity introduced by the algorithms, the Landau notation should be employed. However, given the difficulty of performing this study for heuristic algorithms, a comparison in relative terms taking into account the running time is provided instead. In order to obtain an idea of the order of magnitude of the running time consumed by one or another algorithm,
Figure 10 shows a relative comparison by taking into account the running time of each of the algorithms normalized by the time consumed by the SP since it is the algorithm presenting the faster execution time. This comparison was obtained in the same processing hardware, by using the same training data and by considering the same initial configuration of coefficients for the greedy and regularization algorithms. Acknowledging the fact that several factors could vary the reported running time results (e.g., optimized coding, different hyperparameters and limiting the number of search iterations, etc.), the reported results in
Figure 10 already provide useful information for approximately comparing the running time among the different algorithms. For example, it is quite evident that the global probabilistic optimization algorithms are the ones consuming more running time, followed by the family of the heuristic local search methods, since the number of possible combinations in the former and the possibility to explore new neighbors in the latter renders them more time consuming by nature. Instead, the family of regularization techniques or greedy pursuits exhibit a significantly lower running time since they select the most relevant ones from an original set of coefficients, which are large enough, however, to achieve good performance.
From the previous comparison of feature selection techniques in the context of PA behavioral modeling, the best three candidates were selected in order to conduct an additional comparison among them, but this time in the context of DPD linearization. These candidates are as follows: the LASSO regularization technique, the DOMP belonging to greedy pursuits and the DMS from the family of heuristic local search methods.
Figure 11 shows a comparison of the out-of-band distortion compensation evaluated in terms of ACPR (worst and best cases) versus the number of coefficients for the three feature selection techniques. Similarly,
Figure 12 shows the shows a comparison of the in-of-band distortion compensation evaluated in terms of EVM (worst case) versus the number of coefficients. As observed, the best linearity—in both ACPR and EVM—versus the number of coefficients is obtained with DOMP, having DMS showing almost the same performance. The degradation suffered with LASSO when reducing the number of coefficients is significantly higher than with DOMP or DMS. As listed in
Table 2, with only 17 properly selected coefficients using the DOMP algorithm, it is already possible to meet the out-of-band linearity specifications (i.e., ACPR < −45 dBc), while a few more coefficients are required to meet the specs with DMS. Again, with LASSO, considering 17 coefficients, the worst-case ACPR is 4 dB higher than with DOMP.
Despite the DOMP and DMS showing a similar trend in linearization performance versus the number of coefficients (slightly better in the case of DOMP), when focusing in the running time, the DOMP is around 10 times faster than the DMS and around two times slower than LASSO, as shown in
Figure 13. Again, the normalized running time shown in
Figure 13, was obtained by using the same hardware, data and number of coefficients. However, these results can only be taken as a reference given the fact that by tuning some hyperparameters of the DMS or by optimizing some of the coding of all three algorithms, the running time may change.
Finally,
Figure 14 and
Figure 15 show the output spectra and the 64-QAM constellations for each of the bands of the CA-4 × LTE-20 signal, respectively, before and after DPD linearization. The GMP DPD behavioral model used was composed by 41 coefficients after applying DOMP dimensionality reduction. The ACPR values without DPD linearization are listed in
Table 2. As observed, thanks to DPD linearization, it is possible to achieve up to 14 dB of ACPR reduction and an improvement of around two percentage points of EVM.






























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}