
Cross-Modality Interaction Network for Equine Activity Recognition Using Imbalanced Multi-Modal Data †

 ,
,  , , and
, , and
Abstract
:1. Introduction
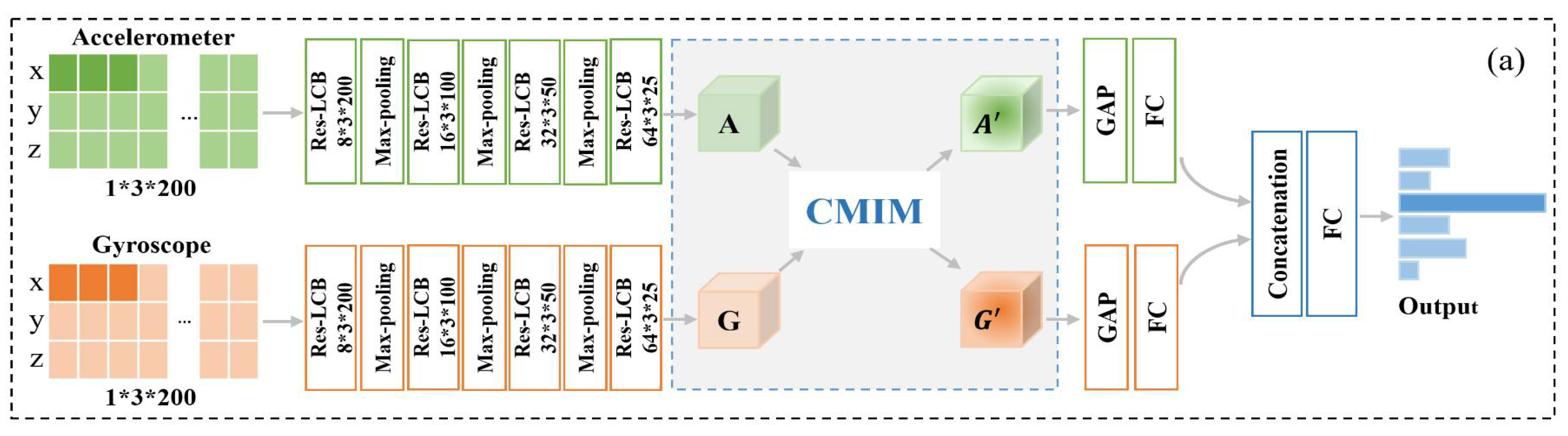
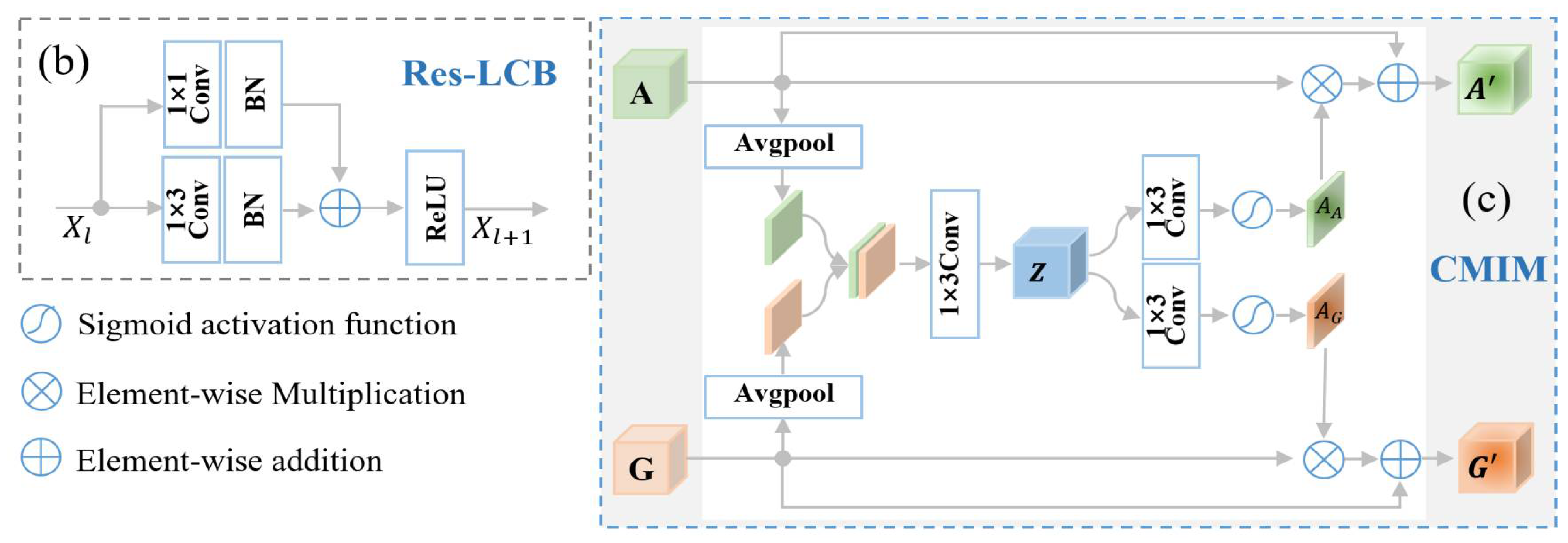
- We proposed a CMI-Net involving a dual CNN trunk architecture and a joint CMIM to improve equine activity recognition performance using accelerometer and gyroscope data. The dual CNN trunk architecture comprised a residual-like convolution block (Res-LCB) which effectively promoted the representation ability and robustness of the model [33]. The CMIM based on attention mechanism enabled CMI-Net to capture complementary information and suppressed unrelated information (e.g., noise, redundant signals, and potentially confusing signals) from multi-modal data.
- We devised a novel attention module, i.e., CMIM, to achieve deep intermodality interaction. The CMIM combined spatial information from two-stream feature maps using basic CNN to produce two spatial attention maps with respect to their importance, which could adaptively recalibrate temporal- and axis-wise features in each modality. To the best of our knowledge, the attention mechanism was employed for the first time in animal activity recognition based on multi-modal data yielded by multiple wearable sensors.
- We adopted a CB focal loss to supervise the training of CMI-Net to mitigate the influence of imbalanced datasets on overall classification performance. The CB focal loss can pay more attention not only to samples of minority classes, diminishing their influence from being overwhelmed during optimization, but also to samples that are hard to distinguish. As far as we know, this is the first time the CB focal loss has been utilized in animal activity recognition based on imbalanced datasets.
- Experiments performed verified the effectiveness of our proposed CMI-Net and CB focal loss. In particular, the experimental results demonstrated that our CMI-Net outperformed the existing algorithms in equine activity recognition with the precision of 79.74%, recall of 79.57%, F1-score of 79.02%, and accuracy of 93.37%, respectively.
2. Materials and Methods
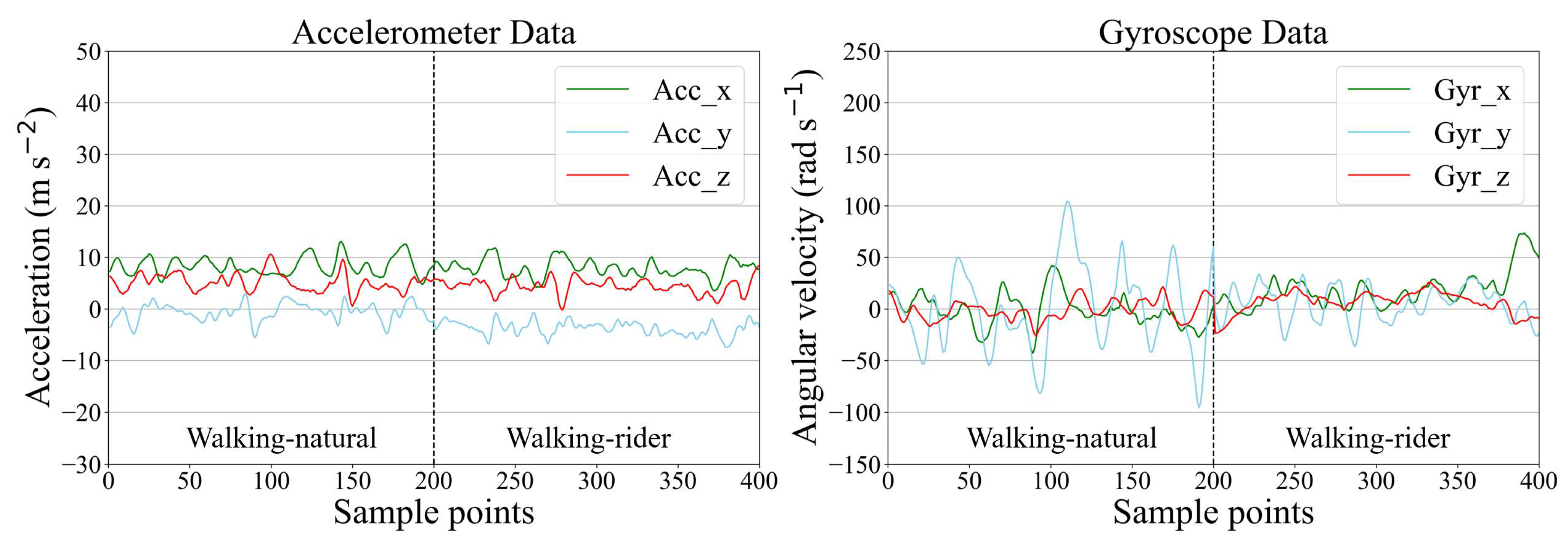
2.1. Data Description
2.2. Cross-Modality Interaction Network
2.2.1. Dual CNN Trunk Architecture
2.2.2. Cross-Modality Interaction Module
2.3. Optimization
2.4. Evaluation Metrics
2.5. Implementation Details
3. Results and Discussion
3.1. Comparison with Existing Methods
3.2. Ablation Study
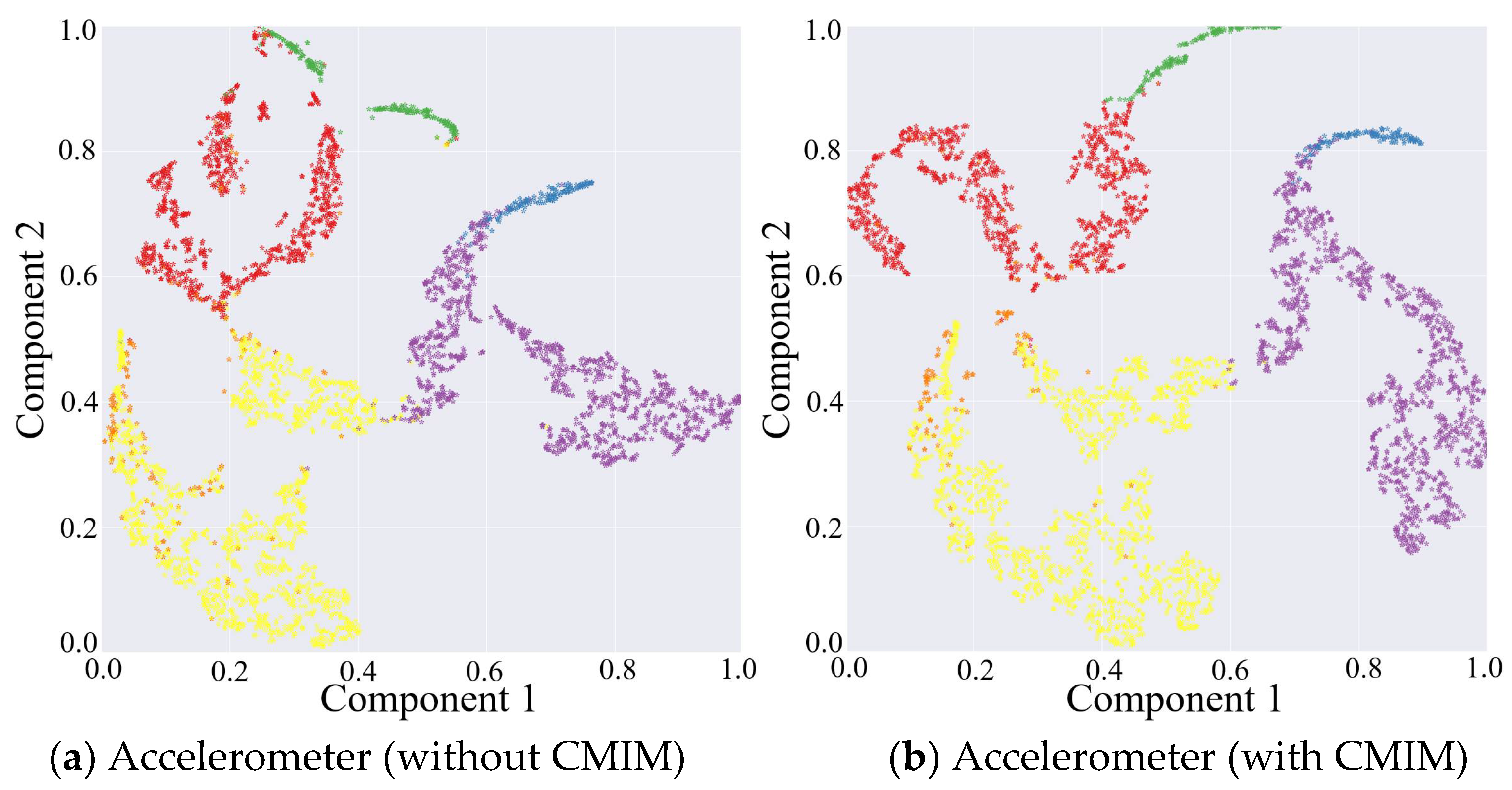
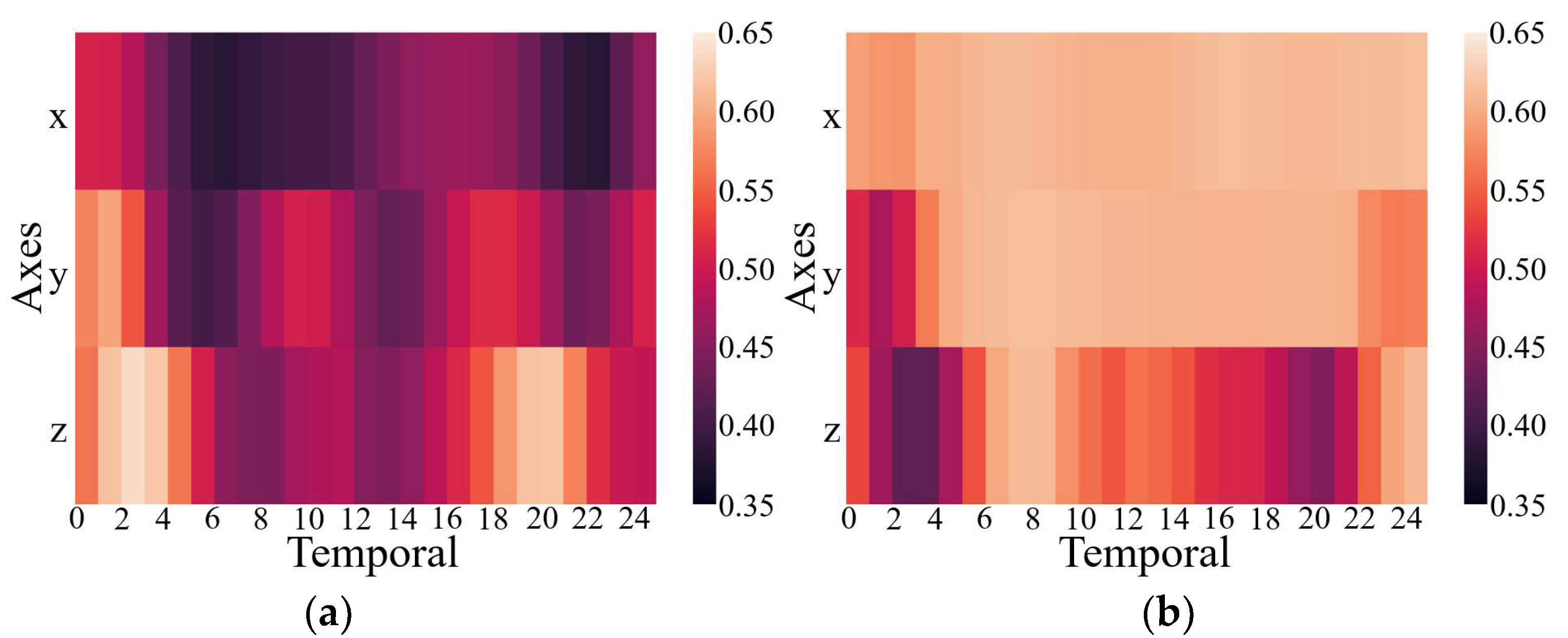
3.2.1. Evaluation of CMIM
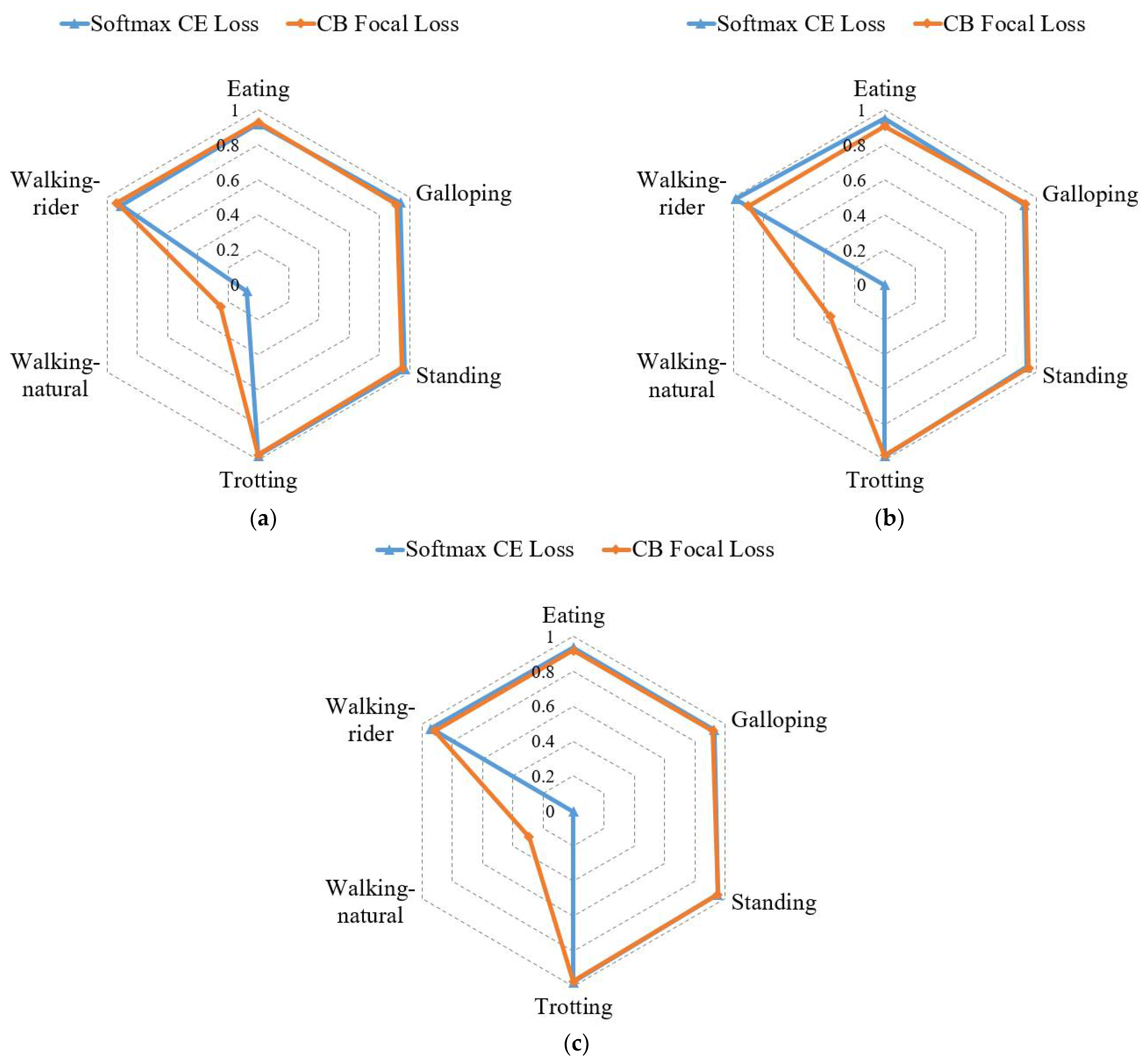
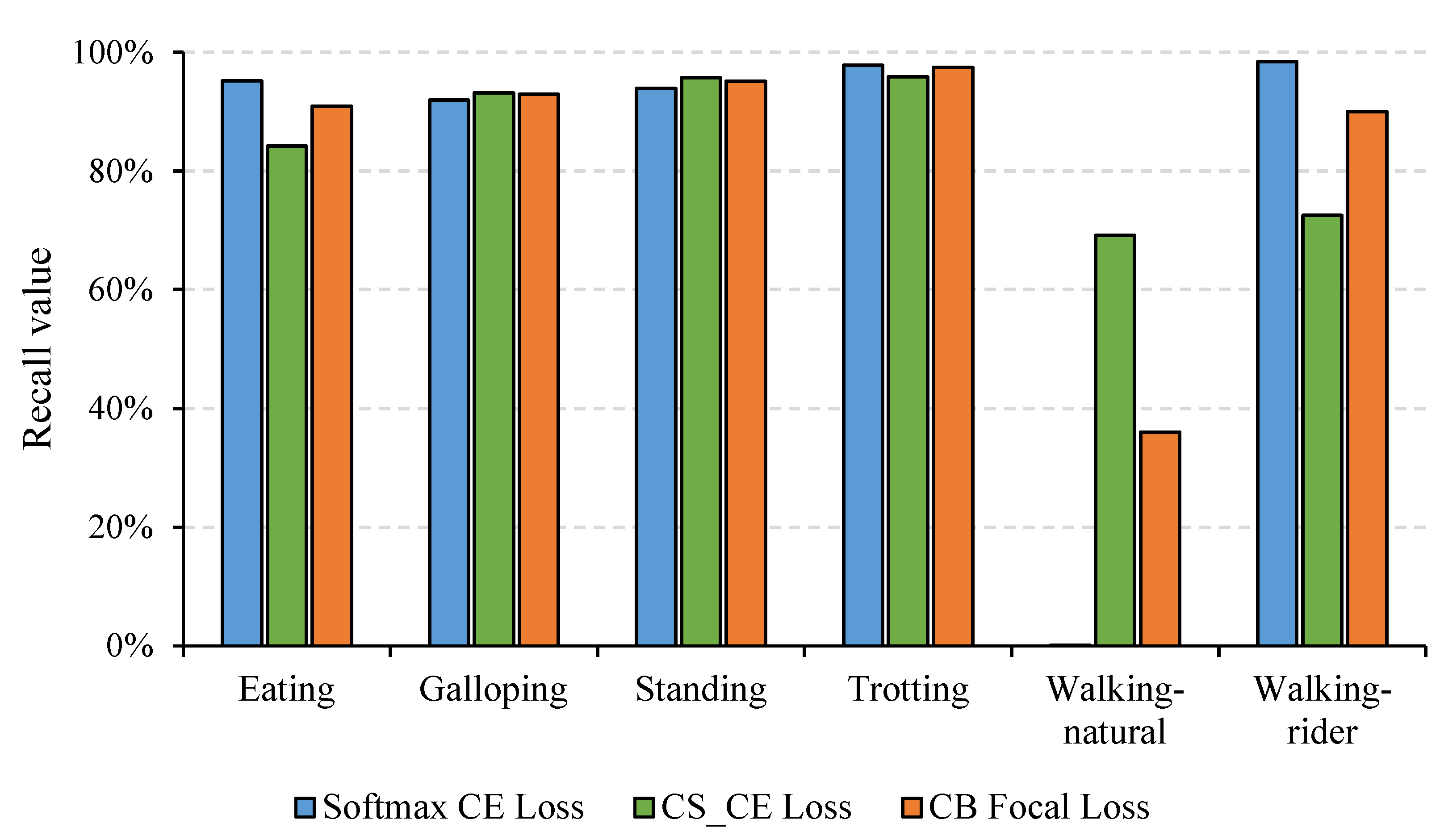
3.2.2. Evaluation of CB Focal Loss
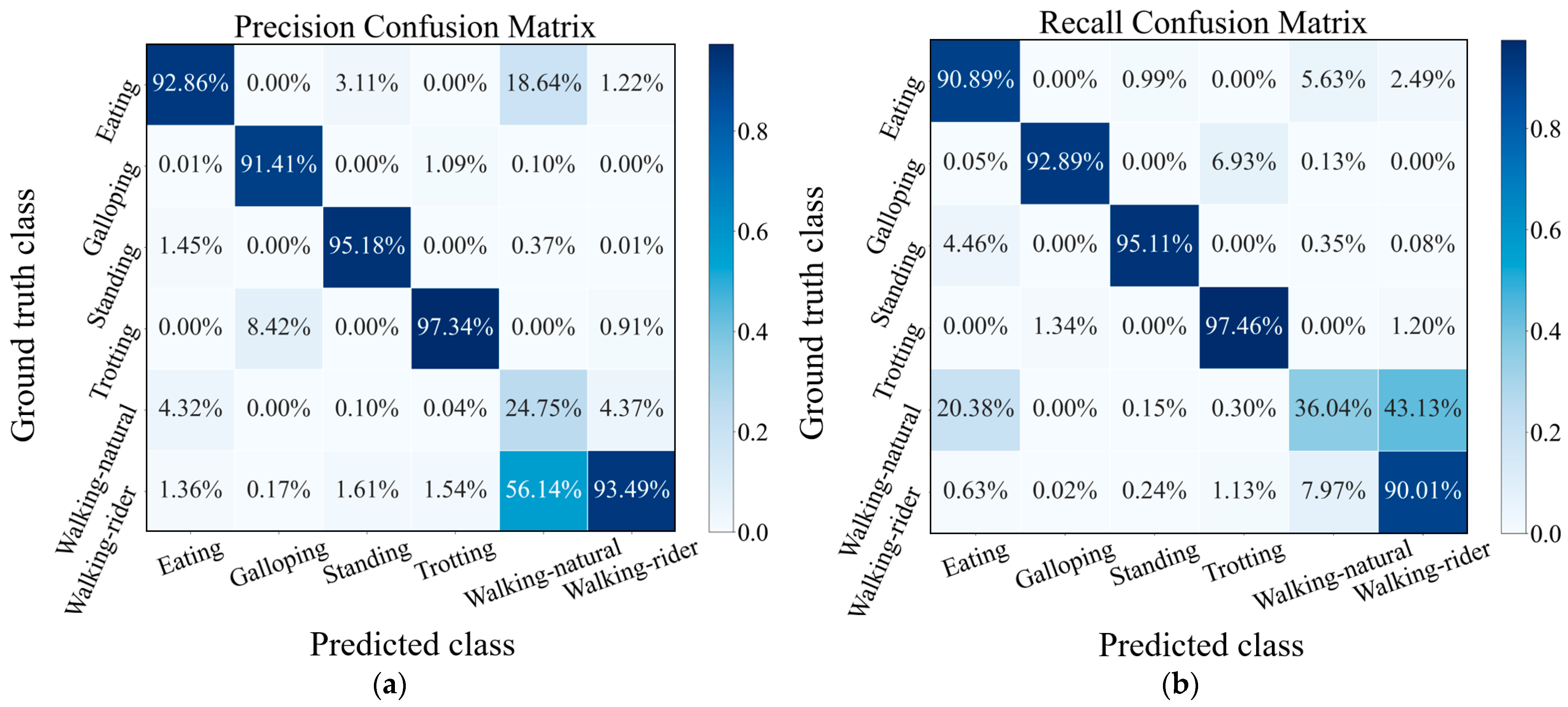
3.3. Classification Performance Analysis
3.4. Limitations and Future Works
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ACS | Adaptive class suppression |
| CB | Class-balanced |
| CB_CE | Class-balanced cross-entropy |
| CE | Cross-entropy |
| CMIM | Cross-modality interaction module |
| CMI-Net | Cross-modality interaction network |
| CNN | Convolutional neural network |
| CS_CE | Cost-sensitive cross-entropy |
| DT | Decision tree |
| FN | False negative |
| FNNs | Feed-forward neural networks |
| FP | False positive |
| IMUs | Inertial measurement units |
| LDA | Linear discriminant analysis |
| LOOCV | Leave-one-out cross-validation |
| LSTM | Long short-term memory |
| NB | Naïve Bayes |
| QDA | Quadratic discriminant analysis |
| Res-LCB | Residual-like convolution block |
| RF | Random forest |
| SVM | Support vector machine |
| TN | True negative |
| TP | True positive |
| t-SNE | t-distributed stochastic neighbor embedding |
References
- Eerdekens, A.; Deruyck, M.; Fontaine, J.; Martens, L.; De Poorter, E.; Plets, D.; Joseph, W. A framework for energy-efficient equine activity recognition with leg accelerometers. Comput. Electron. Agric. 2021, 183, 106020. [Google Scholar] [CrossRef]
- Parkes, R.S.V.; Weller, R.; Pfau, T.; Witte, T.H. The effect of training on stride duration in a cohort of two-year-old and three-year-old thoroughbred racehorses. Animals 2019, 9, 466. [Google Scholar] [CrossRef] [Green Version]
- Van Weeren, P.R.; Pfau, T.; Rhodin, M.; Roepstorff, L.; Serra Bragança, F.; Weishaupt, M.A. Do we have to redefine lameness in the era of quantitative gait analysis? Equine Vet. J. 2017, 49, 567–569. [Google Scholar] [CrossRef] [Green Version]
- Bosch, S.; Serra Bragança, F.; Marin-Perianu, M.; Marin-Perianu, R.; van der Zwaag, B.J.; Voskamp, J.; Back, W.; Van Weeren, R.; Havinga, P. Equimoves: A wireless networked inertial measurement system for objective examination of horse gait. Sensors 2018, 18, 850. [Google Scholar] [CrossRef] [Green Version]
- Astill, J.; Dara, R.A.; Fraser, E.D.G.; Roberts, B.; Sharif, S. Smart poultry management: Smart sensors, big data, and the internet of things. Comput. Electron. Agric. 2020, 170, 105291. [Google Scholar] [CrossRef]
- Rueß, D.; Rueß, J.; Hümmer, C.; Deckers, N.; Migal, V.; Kienapfel, K.; Wieckert, A.; Barnewitz, D.; Reulke, R. Equine Welfare Assessment: Horse Motion Evaluation and Comparison to Manual Pain Measurements. In Proceedings of the Pacific-Rim Symposium on Image and Video Technology, PSIVT 2019, Sydney, Australia, 18–22 November 2019; pp. 156–169. [Google Scholar] [CrossRef]
- Kamminga, J.W.; Meratnia, N.; Havinga, P.J.M. Dataset: Horse Movement Data and Analysis of its Potential for Activity Recognition. In Proceedings of the 2nd Workshop on Data Acquisition to Analysis, DATA 2019, Prague, Czech Republic, 26–28 July 2019; pp. 22–25. [Google Scholar] [CrossRef] [Green Version]
- Kumpulainen, P.; Cardó, A.V.; Somppi, S.; Törnqvist, H.; Väätäjä, H.; Majaranta, P.; Gizatdinova, Y.; Hoog Antink, C.; Surakka, V.; Kujala, M.V.; et al. Dog behaviour classification with movement sensors placed on the harness and the collar. Appl. Anim. Behav. Sci. 2021, 241, 105393. [Google Scholar] [CrossRef]
- Tran, D.N.; Nguyen, T.N.; Khanh, P.C.P.; Trana, D.T. An IoT-based Design Using Accelerometers in Animal Behavior Recognition Systems. IEEE Sens. J. 2021. [Google Scholar] [CrossRef]
- Maisonpierre, I.N.; Sutton, M.A.; Harris, P.; Menzies-Gow, N.; Weller, R.; Pfau, T. Accelerometer activity tracking in horses and the effect of pasture management on time budget. Equine Vet. J. 2019, 51, 840–845. [Google Scholar] [CrossRef] [PubMed]
- Nweke, H.F.; Teh, Y.W.; Al-garadi, M.A.; Alo, U.R. Deep learning algorithms for human activity recognition using mobile and wearable sensor networks: State of the art and research challenges. Expert Syst. Appl. 2018, 105, 233–261. [Google Scholar] [CrossRef]
- Noorbin, S.F.H.; Layeghy, S.; Kusy, B.; Jurdak, R.; Bishop-hurley, G.; Portmann, M. Deep Learning-based Cattle Activity Classification Using Joint Time-frequency Data Representation. Comput. Electron. Agric. 2020, 187, 106241. [Google Scholar] [CrossRef]
- Peng, Y.; Kondo, N.; Fujiura, T.; Suzuki, T.; Ouma, S.; Wulandari Yoshioka, H.; Itoyama, E. Dam behavior patterns in Japanese black beef cattle prior to calving: Automated detection using LSTM-RNN. Comput. Electron. Agric. 2020, 169, 105178. [Google Scholar] [CrossRef]
- Bocaj, E.; Uzunidis, D.; Kasnesis, P.; Patrikakis, C.Z. On the Benefits of Deep Convolutional Neural Networks on Animal Activity Recognition. In Proceedings of the 2020 International Conference on Smart Systems and Technologies (SST), Osijek, Croatia, 14–16 October 2020; pp. 83–88. [Google Scholar] [CrossRef]
- Eerdekens, A.; Deruyck, M.; Fontaine, J.; Martens, L.; de Poorter, E.; Plets, D.; Joseph, W. Resampling and Data Augmentation for Equines’ Behaviour Classification Based on Wearable Sensor Accelerometer Data Using a Convolutional Neural Network. In Proceedings of the 2020 International Conference on Omni-layer Intelligent Systems (COINS), Barcelona, Spain, 31 August–2 September 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Chambers, R.D.; Yoder, N.C.; Carson, A.B.; Junge, C.; Allen, D.E.; Prescott, L.M.; Bradley, S.; Wymore, G.; Lloyd, K.; Lyle, S. Deep learning classification of canine behavior using a single collar-mounted accelerometer: Real-world validation. Animals 2021, 11, 1549. [Google Scholar] [CrossRef]
- Liu, N.; Zhang, N.; Han, J. Learning Selective Self-Mutual Attention for RGB-D Saliency Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, 14–19 June 2020; pp. 13753–13762. Available online: http://cvpr2020.thecvf.com/ (accessed on 27 August 2021). [CrossRef]
- Ha, S.; Choi, S. Convolutional neural networks for human activity recognition using multiple accelerometer and gyroscope sensors. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 381–388. [Google Scholar] [CrossRef]
- Mustaqeem Kwon, S. MLT-DNet: Speech emotion recognition using 1D dilated CNN based on multi-learning trick approach. Expert Syst. Appl. 2021, 167, 114177. [Google Scholar] [CrossRef]
- Mustaqeem; Kwon, S. Optimal feature selection based speech emotion recognition using two-stream deep convolutional neural network. Int. J. Intell. Syst. 2021, 36, 5116–5135. [Google Scholar] [CrossRef]
- Xu, X.; Li, W.; Duan, Q. Transfer learning and SE-ResNet152 networks-based for small-scale unbalanced fish species identification. Comput. Electron. Agric. 2021, 180, 105878. [Google Scholar] [CrossRef]
- Zhang, S.; Li, Z.; Yan, S.; He, X.; Sun, J. Distribution Alignment: A Unified Framework for Long-tail Visual Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2021, 19–25 June 2021; pp. 2361–2370. Available online: http://cvpr2021.thecvf.com/ (accessed on 27 August 2021).
- Tan, J.; Wang, C.; Li, B.; Li, Q.; Ouyang, W.; Yin, C.; Yan, J. Equalization loss for long-tailed object recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, 14–19 June 2020; pp. 11659–11668. Available online: http://cvpr2020.thecvf.com/ (accessed on 27 August 2021). [CrossRef]
- Khan, S.H.; Hayat, M.; Bennamoun, M.; Sohel, F.A.; Togneri, R. Cost-sensitive learning of deep feature representations from imbalanced data. IEEE Trans. Neural Netw. Learn. Syst. 2017, 29, 3573–3587. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cui, Y.; Jia, M.; Lin, T.Y.; Song, Y.; Belongie, S. Class-balanced loss based on effective number of samples. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 16–20 June 2019; pp. 9260–9269. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 42, 318–327. [Google Scholar] [CrossRef] [Green Version]
- Wang, T.; Zhu, Y.; Zhao, C.; Zeng, W.; Wang, J.; Tang, M. Adaptive Class Suppression Loss for Long-Tail Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2021, 19–25 June 2021; pp. 3103–3112. Available online: http://cvpr2020.thecvf.com/ (accessed on 27 August 2021).
- Mao, A.X.; Huang, E.D.; Xu, W.T.; Liu, K. Cross-modality Interaction Network for Equine Activity Recognition Using Time-Series Motion Data. In Proceedings of the 2021 International Symposium on Animal Environment and Welfare (ISAEW), Chongqing, China, 20–23 October 2021. in press. [Google Scholar]
- Zhang, Z.; Lin, Z.; Xu, J.; Jin, W.D.; Lu, S.P.; Fan, D.P. Bilateral Attention Network for RGB-D Salient Object Detection. IEEE Trans. Image Process. 2021, 30, 1949–1961. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision, ECCV 2018, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar] [CrossRef] [Green Version]
- Mustaqeem Kwon, S. Att-Net: Enhanced emotion recognition system using lightweight self-attention module. Appl. Soft Comput. 2021, 102, 107101. [Google Scholar] [CrossRef]
- Kamminga, J.W.; Janßen, L.M.; Meratnia, N.; Havinga, P.J.M. Horsing around—A dataset comprising horse movement. Data 2019, 4, 131. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Kamminga, J.W.; Le, D.V.; Havinga, P.J.M. Towards deep unsupervised representation learning from accelerometer time series for animal activity recognition. In Proceedings of the 6th Workshop on Mining and Learning from Time Series, MiLeTS 2020, San Diego, CA, USA, 24 August 2020. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified Linear Units Improve Restricted Boltzmann Machines Vinod. In Proceedings of the 27th International Conference on Machine Learning, ICML 2010, Haifa, Israel, 21–24 June 2010. [Google Scholar] [CrossRef]
- Joze, H.R.V.; Shaban, A.; Iuzzolino, M.L.; Koishida, K. MMTM: Multimodal transfer module for CNN fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, 14–19 June 2020; pp. 13286–13296. Available online: http://cvpr2020.thecvf.com/ (accessed on 27 August 2021). [CrossRef]
- Casella, E.; Khamesi, A.R.; Silvestri, S. A framework for the recognition of horse gaits through wearable devices. Pervasive Mob. Comput. 2020, 67, 101213. [Google Scholar] [CrossRef]
- Zeng, M.; Nguyen, L.T.; Yu, B.; Mengshoel, O.J.; Zhu, J.; Wu, P.; Zhang, J. Convolutional Neural Networks for human activity recognition using mobile sensors. In Proceedings of the 6th international conference on mobile computing, applications and services, MobiCASE 2014, Austin, TX, USA, 6–7 November 2014; pp. 197–205. [Google Scholar] [CrossRef] [Green Version]
- Wolpert, D.H.; Macready, W.G. No free lunch theorems for optimization. IEEE Trans. Evol. Comput. 1997, 1, 67–82. [Google Scholar] [CrossRef] [Green Version]
- Wei, J.; Wang, Q.; Li, Z.; Wang, S.; Zhou, S.K.; Cui, S. Shallow Feature Matters for Weakly Supervised Object Localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2021, 19–25 June 2021; pp. 5993–6001. Available online: http://cvpr2021.thecvf.com/ (accessed on 27 August 2021).
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Van der Maaten, L.; Hinton, G. Visualizing Data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar] [CrossRef]
- De Cocq, P.; Van Weeren, P.R.; Back, W. Effects of girth, saddle and weight on movements of the horse. Equine Vet. J. 2004, 36, 758–763. [Google Scholar] [CrossRef] [PubMed]
- Geng, C.; Huang, S.-J.; Chen, S. Recent Advances in Open Set Recognition: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 14, 1. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yoshihashi, R.; You, S.; Shao, W.; Iida, M.; Kawakami, R.; Naemura, T. Classification-Reconstruction Learning for Open-Set Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 16–20 June 2019; pp. 4016–4025. [Google Scholar]
- Cardoso, D.O.; Gama, J.; França, F.M.G. Weightless neural networks for open set recognition. Mach. Learn. 2017, 106, 1547–1567. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Precision (%) | Recall (%) | F1-Score (%) | Accuracy (%) |
|---|---|---|---|---|
| Machine learning | ||||
| Naïve Bayes | 70.90 | 72.41 | 69.42 | 76.60 |
| Decision tree | 75.67 | 73.90 | 74.35 | 88.83 |
| Support vector machine | 73.92 | 71.30 | 72.19 | 89.65 |
| Deep learning | ||||
| CNN [15] | 72.07 | 76.91 | 73.42 | 82.94 |
| ConvNet7 [14] | 79.03 | 77.79 | 77.90 | 91.27 |
| Our methods # | ||||
| CMI-Net + softmax CE loss | 79.74 | 79.57 | 79.02 | 93.37 |
| CMI-Net + CB focal loss (γ = 0.5) * | 82.50 | 83.73 | 82.94 | 90.68 |
| Methods & | Precision (%) | Recall (%) | F1-Score (%) | Accuracy (%) |
|---|---|---|---|---|
| Variant0 # | 79.02 | 77.09 | 76.88 | 91.76 |
| Variant1 * | 78.18 | 77.07 | 77.40 | 92.17 |
| Variant2 * | 77.50 | 78.44 | 77.91 | 92.92 |
| Variant3 * | 78.36 | 76.94 | 77.02 | 92.62 |
| CMI-Net + softmax CE loss | 79.74 | 79.57 | 79.02 | 93.37 |
| Loss Functions | Precision (%) | Recall (%) | F1-Score (%) | Accuracy (%) |
|---|---|---|---|---|
| Softmax CE Loss (baseline) | 79.74 | 79.57 | 79.02 | 93.37 |
| CB focal loss (γ = 0.1) | 81.31 | 83.60 | 81.97 | 89.57 |
| CB focal loss (γ = 0.5) | 82.50 | 83.73 | 82.94 | 90.68 |
| CB focal loss (γ = 1) | 80.42 | 82.03 | 81.05 | 89.89 |
| CB focal loss (γ = 2) | 78.92 | 78.48 | 77.97 | 91.05 |
| Loss Functions # | Precision (%) | Recall (%) | F1-Score (%) | Accuracy (%) |
|---|---|---|---|---|
| Softmax CE loss | 79.74 | 79.57 | 79.02 | 93.37 |
| Class-level | ||||
| CS_CE loss [24] | 80.47 | 85.11 | 79.91 | 83.79 |
| CB_CE loss [25] | 75.35 | 75.70 | 75.47 | 90.61 |
| Sample-level | ||||
| Focal loss [26] | 78.84 | 77.99 | 78.25 | 93.30 |
| ACS loss [27] | 77.03 | 76.54 | 76.60 | 92.05 |
| CB focal loss (γ = 0.5) | 82.50 | 83.73 | 82.94 | 90.68 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mao, A.; Huang, E.; Gan, H.; Parkes, R.S.V.; Xu, W.; Liu, K. Cross-Modality Interaction Network for Equine Activity Recognition Using Imbalanced Multi-Modal Data. Sensors 2021, 21, 5818. https://doi.org/10.3390/s21175818
Mao A, Huang E, Gan H, Parkes RSV, Xu W, Liu K. Cross-Modality Interaction Network for Equine Activity Recognition Using Imbalanced Multi-Modal Data. Sensors. 2021; 21(17):5818. https://doi.org/10.3390/s21175818
Chicago/Turabian StyleMao, Axiu, Endai Huang, Haiming Gan, Rebecca S. V. Parkes, Weitao Xu, and Kai Liu. 2021. "Cross-Modality Interaction Network for Equine Activity Recognition Using Imbalanced Multi-Modal Data" Sensors 21, no. 17: 5818. https://doi.org/10.3390/s21175818
APA StyleMao, A., Huang, E., Gan, H., Parkes, R. S. V., Xu, W., & Liu, K. (2021). Cross-Modality Interaction Network for Equine Activity Recognition Using Imbalanced Multi-Modal Data. Sensors, 21(17), 5818. https://doi.org/10.3390/s21175818