1. Introduction
Legged robots can be used as substitutes for human beings and animals for working in harsh conditions. Although bionic structures and state-of-the-art hardware provide legged robots with agility, the full implementation of these robots is hindered by a wide range of potential factors that can destabilize robots in such scenarios. For instance, robots can waggle on aerial or aquatic platforms because of wind and water waves, tremble in post-earthquake rescue situations due to aftershocks, and become unbalanced during planetary exploration from frequent dust storms. To counteract these external disturbances, it is essential for robots to change their distribution of contact points to regulate their trunk posture, thus ensuring good performance in these dynamic environments.
Various approaches have been proposed to achieve multi-contact balancing control for legged robots. In an early exploration of balance in legged locomotion, a relatively simple algorithm is proposed for a one-legged hopping machine based on a spring-loaded inverted pendulum (SLIP) [
1,
2]. This algorithm decomposed the control of legged locomotion into three parts: a vertical height control part, a horizontal velocity part, and an angular attitude control part. Initialized with the one-legged system, one of the most well-known quadruped systems, Bigdog [
3], performed well in self-adapting to external forces. Xu et al. [
4] combined a SLIP with compliant control in terms of posture, allowing quadruped robots to reduce the effects of disturbances. In [
4], inverse dynamics and Raibert’s balance controller [
5] were employed to predict the desired torque of joints. Stephens and Atkeson [
6] proposed a dynamic balance force controller to determine full-body joint torques based on the desired motion of the center of mass (CoM) through inverse kinematics. This approach controls the motion of the CoM and the angular momentum of the robot by computing suitable contact forces with a quadratic optimization problem. The mapping of the contact forces to the joint torques is solved considering the multibody dynamics of the system.
Khorram and Moosavian [
7] proposed a controller for quadruped robots to restore the robot equilibrium in the standing phase when exerting external pushes. The method developed a full-dynamics model, with constraints of the stability, friction and saturation constraints to derive the desired forces/torques which can achieve body balance. Din et al. [
8,
9] presented a control method that estimates the external forces applied to legs to help quadruped robots maintain balance. In this method, a sliding-mode controller was proposed to track a desired gait with high precision in fast varying external disturbances, to calculate the optimized accelerations of the leg joints of the robot.
Another approach for realizing dynamic stabilization is whole-body control (WBC), which casts the locomotion controller as an optimization problem. WBC methods, which exploit all degrees of freedom (DoFs) for legged robots, spread the desired motion tasks globally to all the joints [
10] by incorporating full dynamics. Through a passive WBC approach, Fahmi et al. [
10] considered the full robot rigid body dynamics and achieved dynamic locomotion while compliantly balancing the quadruped robot’s trunk. Henze et al. [
11] presented another WBC controller, which needed to solve an optimization problem for distributing a CoM wrench to the end effectors while considering constraints for the unilaterality, friction and position of the center of pressure.
Despite the fact that these approaches solved the balance control of legged robots to some degree, these controllers which are based on analytical models have strong sensitivity regarding parameters, and require considerable formulation derivation and tedious hand-tuning in the design process. When implemented on physical robots, these methods also need to address random noise and delays in data transmission due to hardware issues. In addition, due to the high specificity, those models need to be redesigned if the size or structure of the robot changes, and the analysis process must be repeated, which calls for additional design delays. Moreover, the difficulty of designing the controller increases dramatically for robots with complex structures, which requires extensive engineering expertise.
Since conventional controllers must infer ideal actions through analytical models designed by prior knowledge on kinematics and dynamics, intuitive actions for human beings and animals, even self-balancing and walking, are regarded as reasoning processes for robots. In recent years, a more direct approach, known as the data-driven method, was developed for achieving effective robotic control.
Data-driven methods, such as deep reinforcement learning (deep RL), have been demonstrated as promising methods to overcome the limitations of prior model-based approaches and develop effective motor skills for robots. Through deep RL, control policies are represented as deep neural networks (DNNs), which exploit the strong fitting ability of DNNs to avoid deriving dozens of kinematic and dynamic formulas. Moreover, the parameters of DNNs are optimized automatically by interacting with the environment iteratively through an RL framework, thus avoiding the hand-tuning necessary in most conventional methods.
A number of works have implemented deep RL on robot training in simulations, thus providing animated characters with remarkable motor skills [
12,
13,
14,
15]. Peng et al. [
12] trained control policies for multiple simulated robots to learn highly dynamic skills by imitating reference motion capture clips. The motions produced by the training process were natural and consistent with those captured in the original data. Tsounis et al. [
14] trained a two-layer perceptron to realize terrain-aware locomotion for quadruped robots, showing high performance in the problem of legged locomotion on non-flat terrain. Hess et al. [
15] found that diverse environmental contexts can be helpful to learn complex behaviors when training locomotion policies for several simulated bodies.
In physical systems, some works have managed to realize the sim-real transfer of trained policies [
16,
17,
18]. Hwangbo et al. [
16] deployed a DNN-based controller that was trained by an RL algorithm called trust region policy optimization (TRPO), on the quadruped system ANYmal, achieving multiple gaits on flat ground. This work constructed two neural networks—an “actuator net” and a “policy net”—to represent the relationship between actions and torques and that between observations and actions to bridge the reality gap. A similar control policy presented in [
17] was also learned in a physics simulator and then implemented on real robots. To narrow the reality gap, the physics simulator was improved by developing an accurate actuator model and simulating latency, and robust policies were learned by randomizing the physical environments as well as adding perturbations. Lee et al. [
18] trained a controller for legged locomotion over challenge terrains by RL in simulations and indicated its robustness in real-world conditions that were never encountered during training in simulation.
However, current research on RL in real-world legged robots has mainly focused on performance under static environments, such as flat ground [
16] and challenging terrains [
18], while dynamic environments are also a common condition for robots when they are conducting tasks under earthquakes and storms. Unlike static environments, dynamic environments always cause various disturbances for robots. A recent work [
19] observed that RL can be used to design the control algorithm for a quadruped robot to maintain balance in an unstable environment. In [
19], RL was used to optimize a table-based deterministic policy in the finite discrete state and action spaces according to kinematic equations, i.e., the optimal actions were selected from 8 alternative actions through kinematic formulations when the quadruped system reached new states. Then an artificial neural network (ANN) is trained using the obtained pairs of states and actions through supervised learning to approximate the table-based policy, forming a continuous policy. However, there are still some problems to be further discussed. Firstly, although RL and ANN were employed, this method still highly relied on kinematic equations, which led to similar complexity of conventional methods. Another problem is that the exploration ability of RL was reduced due to the use of the deterministic policy and discrete spaces of states and actions, which easily made the policy fall into local optimum. Thirdly, the kinematic equations merely considered the angles of joints and torso, which led to the absence of some vital physical factors (e.g., gravity, force, and velocities and torques of actuators) in RL process, making the obtained policy less robust or even ineffective in different conditions.
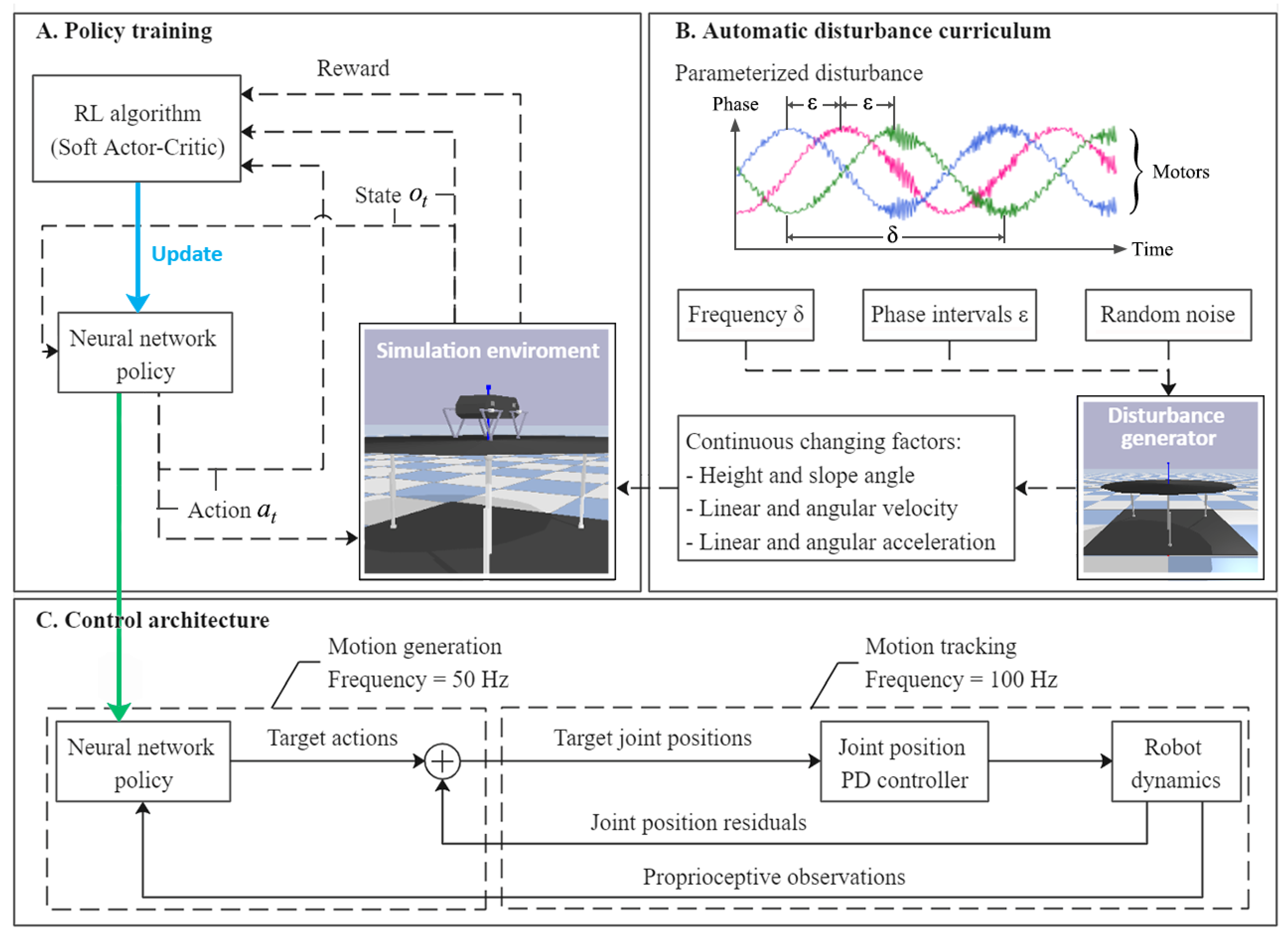
This paper proposes a convenient and adaptable approach to construct a self-balancing controller for quadruped robots. Our method employs RL and ANN for policy design, however, the design concept and process are thoroughly different from those in [
19]. This work aims at learning self-balancing control policy during interaction with a simulated dynamic environment, and transferring the obtained policy to real robots, which abandons the construction of kinematic equations to simplify the design process and enhance the adaptivity of control policy. In this paper, the self-balancing task is regarded as a continuous optimization problem, which consists well with it in the real world. As it is demonstrated that a challenging suite of training scenarios can help the trained policy succeed in a wide range of cases [
14,
18], we design an automatic changing disturbance curriculum to appropriately enhance the level of difficulty. A parameterized stochastic policy based on ANN is directly integrated into the RL process, other than using ANN to approximate a table-based deterministic policy that has already been obtained by RL [
19]. The diversity of actions and exploration ability are ensured thanks to the employment of the changing disturbance curriculum, continuous spaces, a stochastic policy and a maximum-entropy RL framework. During the interaction between the robot and simulated environment, physical factors, such as gravity, collision, force, acceleration, and velocities and torques of actuators, are naturally considered, making the policy adaptive to a wide range of multiple vibration frequencies and amplitudes.
3. Verification Environment
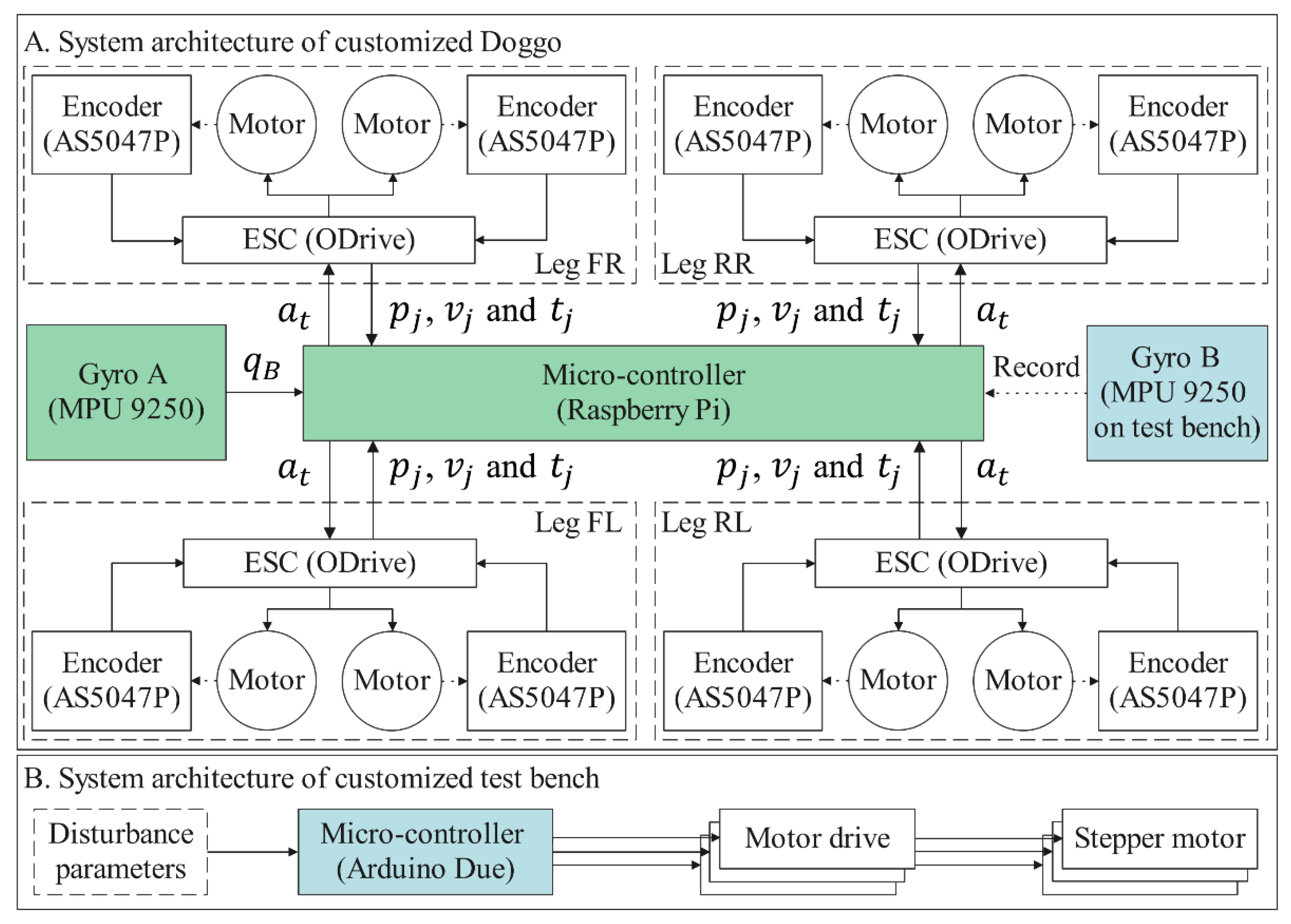
The self-balancing control policy is formed after the training process. The trained policy is deployed in simulated and real robots for validating under multiple conditions for the balance control tasks. In the simulator, the training environment can still be reused for validating, while under real conditions, our method is implemented on a customized physical Stanford Doggo, as shown in
Figure 3A. Stanford Doggo achieves high performance of motor position control at low cost through the combination of eight MN5212 brushless motors (T-motor, Nanchang, China), eight AS5047P magnetic rotary position sensors (ams AG, Premstätten, Austria) and four open-source motor drive boards ODrive V3.5 48V (ODrive Robotics, San Jose, CA, USA). Compared with the original version, we use Raspberry Pi 4B+ as the microcontroller unit (MCU) to conveniently deploy the ANN-based policy with Pytorch, and use the MPU9250 gyro (TDK, Tokyo, Japan) to collect the orientation of the robot trunk. In the real-world experiment, the MPU9250 is raised to 20 cm higher from the motors, as shown in
Figure 3C, because
Z-axis data can be affected by magnetic fields. For the real Doggo, the observations (i.e.,
,
,
and
) are obtained from real sensors, in which
and
are collected from magnetic rotary encoders AS5047P and the gyro MPU9250,
is the differential
, and
is estimated using the current
for motor
measured by ODrive through equation
, where
for the motors MN5212. The embedded system architecture and data flow of the customized experimental setup are shown in
Figure 5.
The customized 3-DoF test bench is also manufactured for the real experiment, on which the prismatic joints are realized by vertically installed ball screw units, as shown in
Figure 3B. Under the control of an Arduino Due MCU, ball screws are actuated to enable the platform to shift along the
Z-axis and tilt around the
X- and
Y-axes. The upper plate of the bench is made of lightweight materials to reduce inertia and increase flexibility. Another MPU9250 (Gyro B in
Figure 3 and
Figure 5) is installed on the bottom surface of this plate to record the tilt angle of the test bench, which does not interact with the control algorithm.
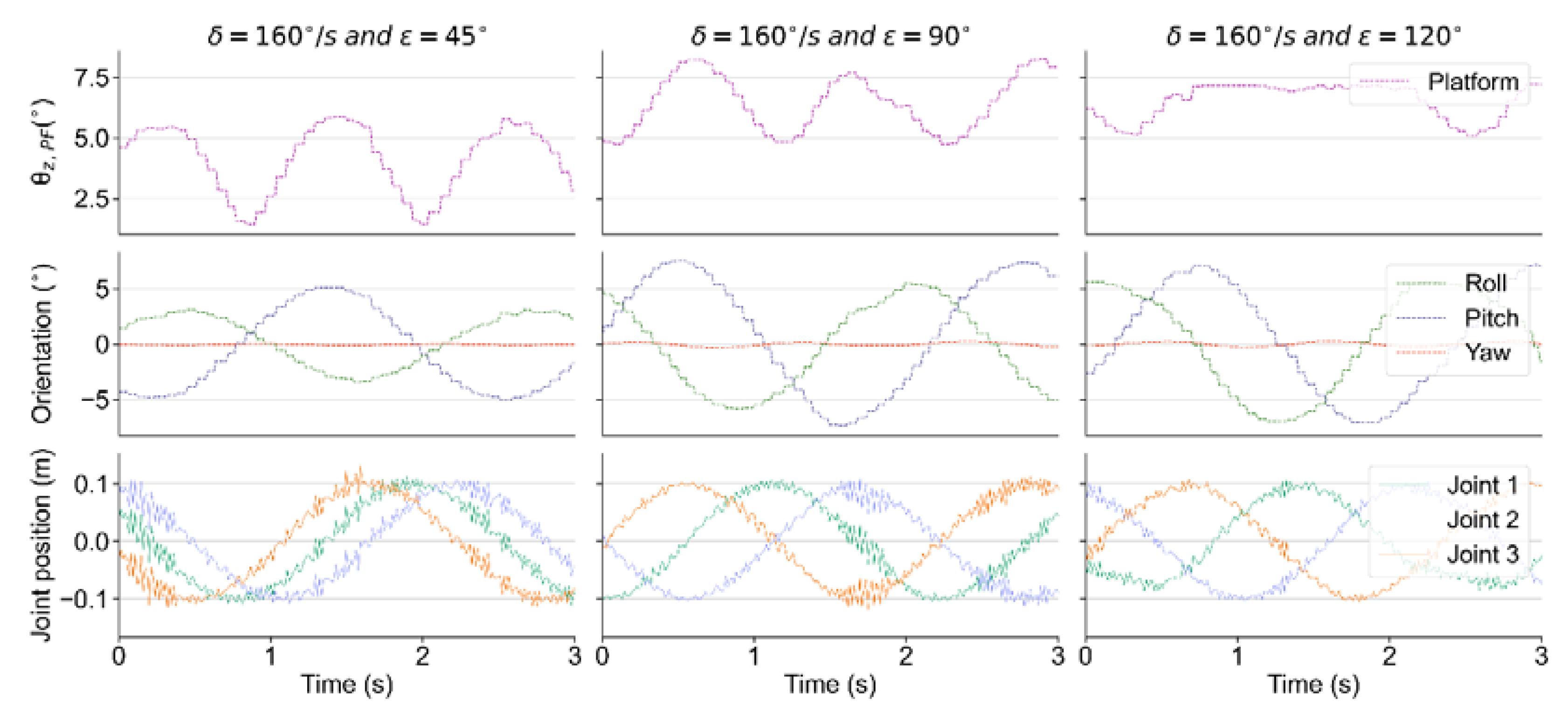
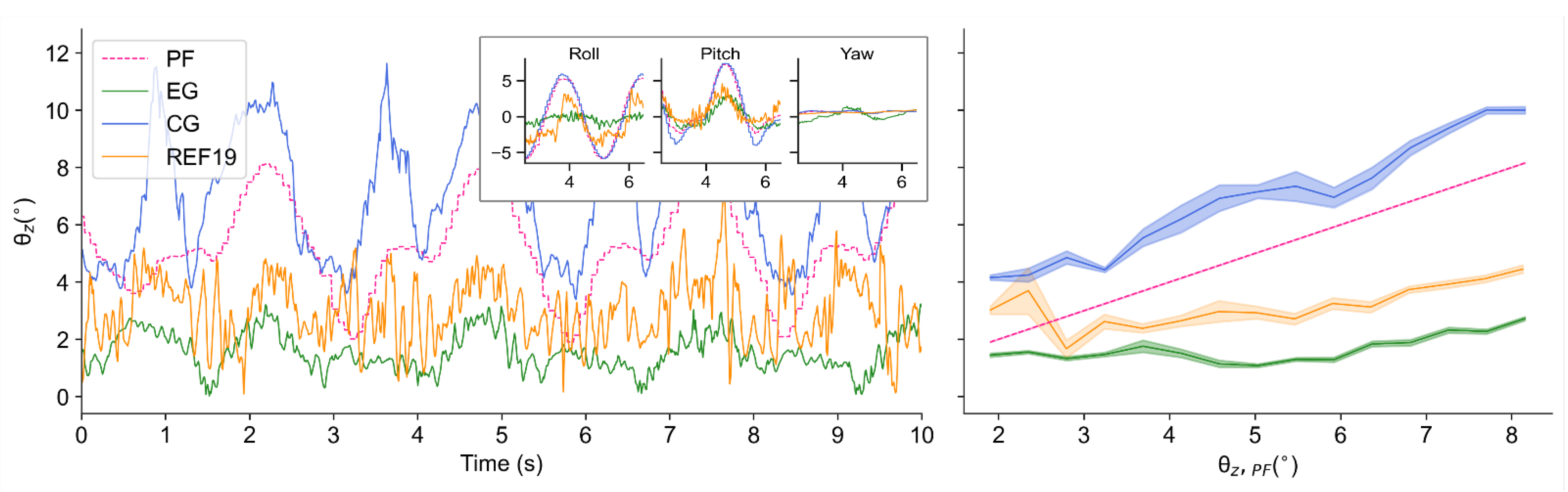
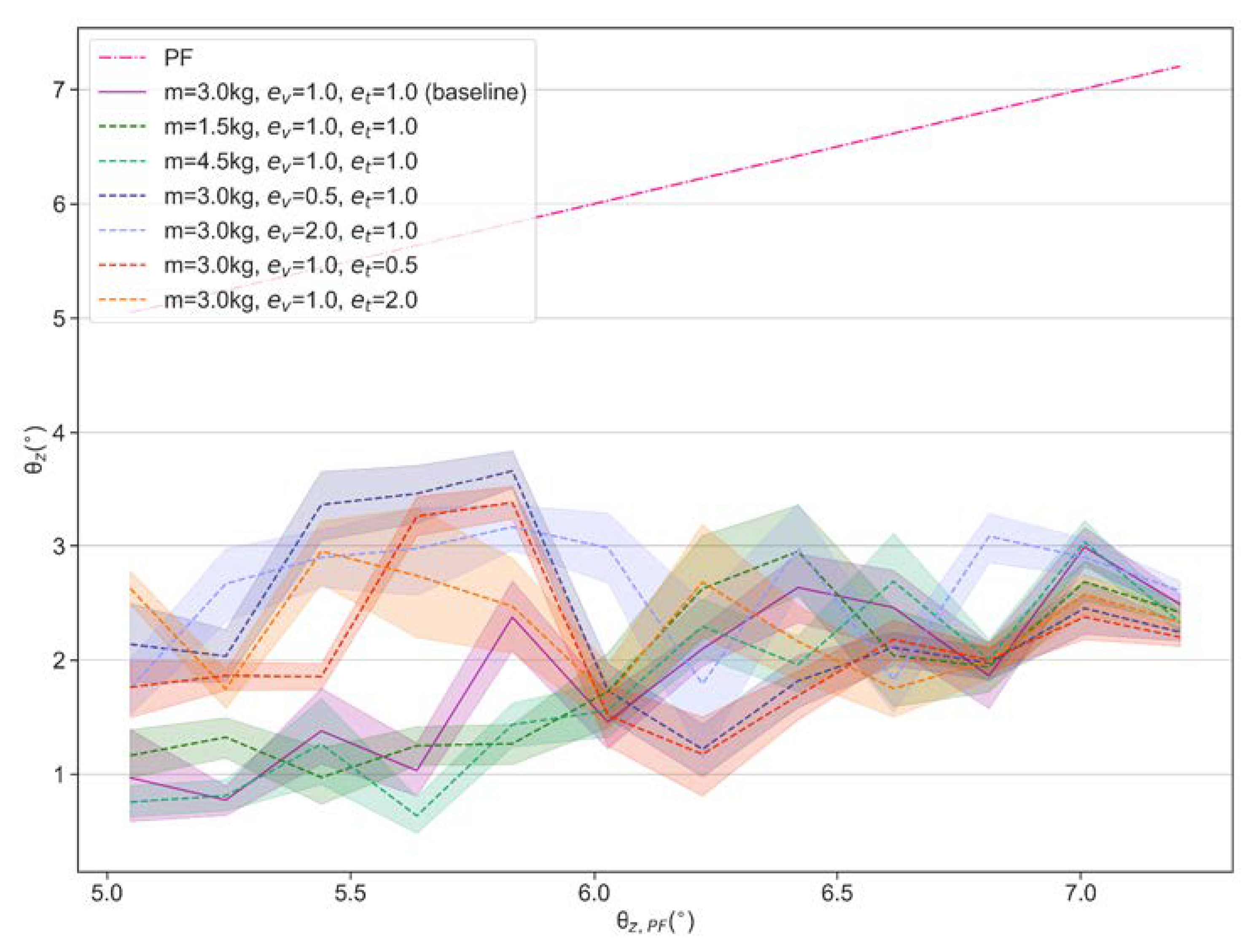
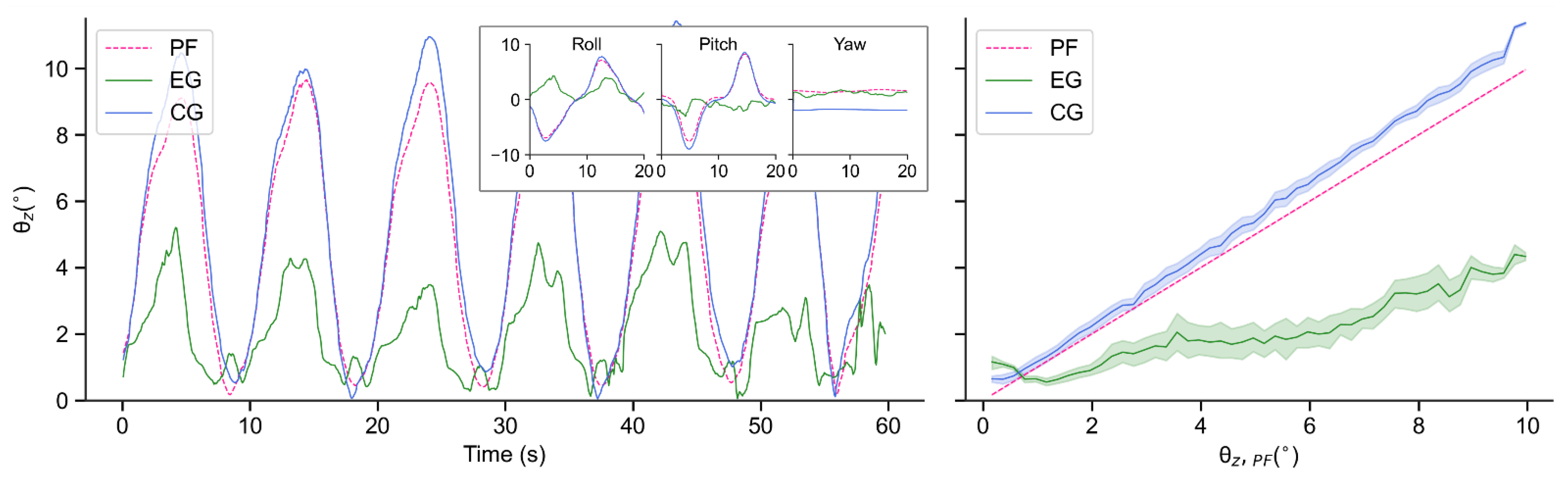
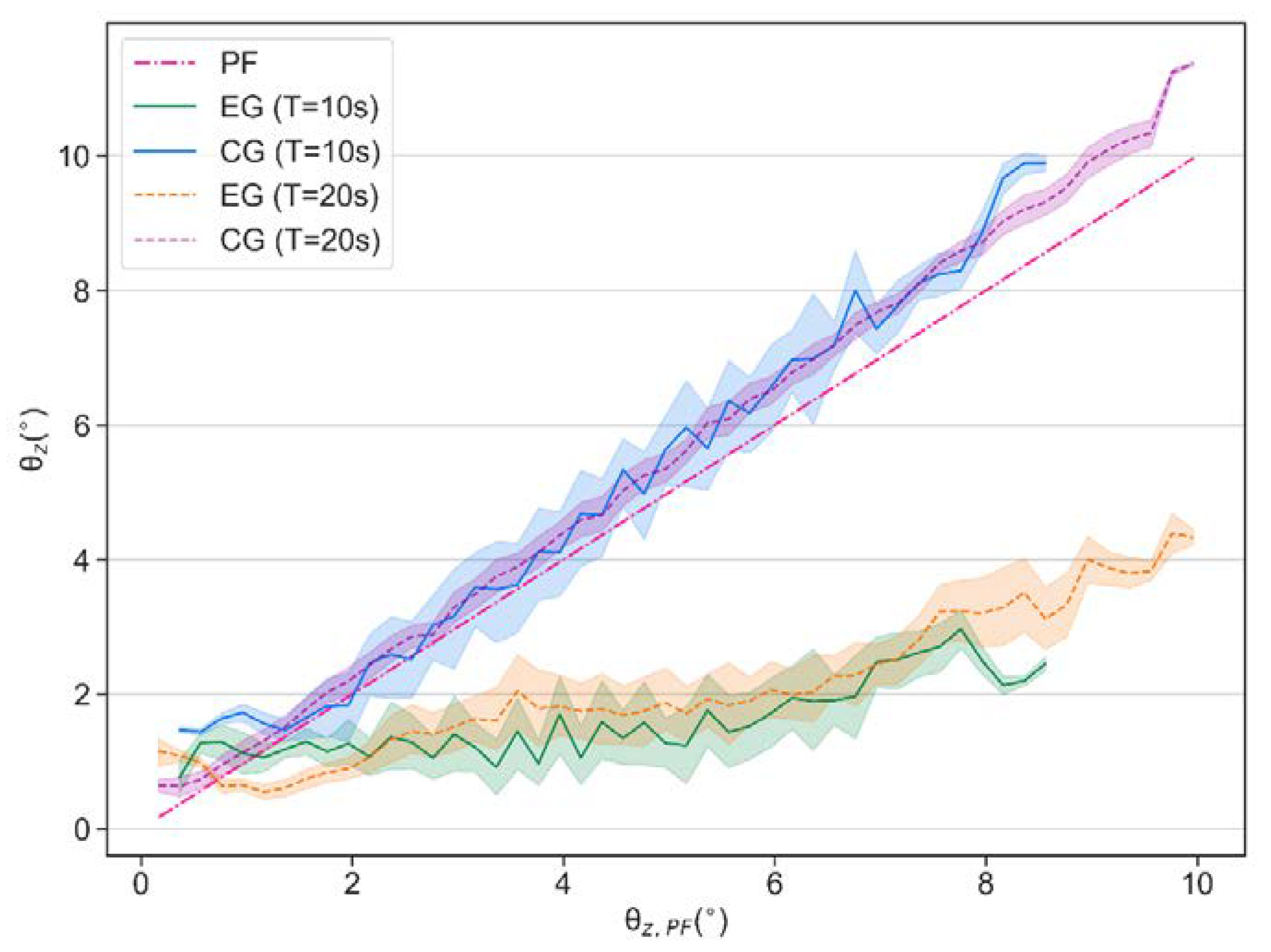
Although the trained policy is obtained from only one disturbance condition, various disturbance configurations are used to evaluate its performance in different conditions. In all the experiments, the robots are divided into three groups: One is the experimental group (EG), i.e., the robot using the control policy presented in this paper, the other one is the control group (CG), i.e., the robot without any control policy, and the other one is the robot using the method proposed in [
19], which is called REF19 in the paper. The robot joints in CG are fixed to the initial angular position, as shown in
Figure 3C.
In order to quantitatively analyze the experimental data, herein, we define indicators
and
, as the balance efficiencies which represent the reduction ratios of the tilt amplitude of controlled robots compared with those of the platform of test bench (PF) and those of the uncontrolled CG, and can be calculated by Equations (9)–(12).
and
describe the balancing ability of policies from different perspectives. Moreover, if the tilt angle of external disturbance or uncontrolled robot is known, we can use the corresponding balance efficiency to estimate the tilt angle after adopting this policy to estimate whether it is worth trying to implement this policy on actual application conditions.
can be replaced by
and
to calculate the balance efficiencies for robots that using the policies presented in this paper and [
19].
5. Conclusions
In this study, a balance control policy is obtained through training with a maximum-entropy RL framework in a simulated dynamic environment, and validated in simulation and on a real robot, which avoids some drawbacks in the design process of conventional balance control models.
Compared with conventional methods which require tedious tuning, our method significantly simplified the design process. In our method, the learned balance control policy can be obtained by training in a simulator using an animated dynamic environment and simplified virtual robot models. There is no human involvement needed in the training process, and the engineer can carry out other work during the training. Moreover, for robots with different structures, only corresponding robot models are needed for training. These advantages greatly enhance the reusability and universality of the design process and improve the design efficiency of the balance controller.
In addition, this paper establishes an end-to-end implicit mapping of robot proprioception to action commands and proposes an ANN-based balance controller. Conventional balance control models generate action commands through the mathematical models constructed by engineers after analyzing the structure of the robot, and complete each action based on analytical models. Those hierarchical models need to be executed sequentially. In contrast, our policy can be deployed to parallel computing architecture, such as the tensor processing unit, which can greatly lower the computational time complexity and achieve an intuitive response speed in theory.
The proposed controller is validated in simulation and real-world experiments with the customized Stanford Doggo, respectively. The proposed balance controller effectively reduces the impact of external disturbance brought by the dynamic environment on robot balance. When tested under 18 conditions in the simulator, the policy reduces the external disturbance by 47.69% to 72.19% compared to the control group by 60.72% to 78.90% in terms of the median of tilt amplitude. When applied directly to the real robot, the effect is similar to that in the simulation environment: on the customized 3-DoF test bench, the average tilt angle can be reduced by 57.89% to 66.21% under regularly generated disturbances, and by 57.27% under a randomly generated disturbance.
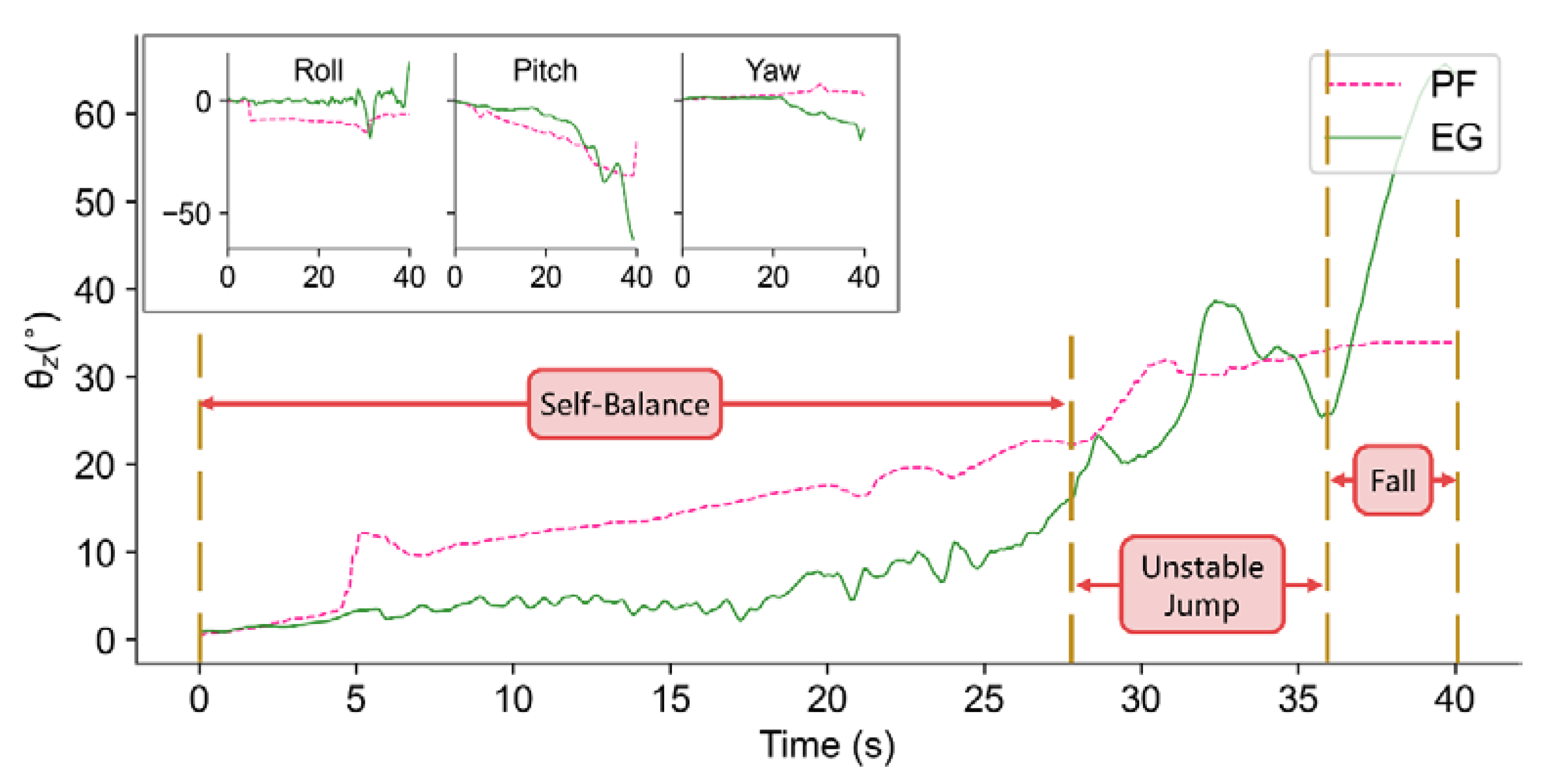
However, the controller has a bounded input of 25° disturbance, and enhancing the difficulty of training curriculum might be one of the solutions to make it learn more to react in that condition. Moreover, it is not always sensitive when the test bench runs at a small tilt angle of less than 1.5°. Although at small tilt angles, both the test bench and the robot can be regarded as balance, some applications will demand higher accuracy and balance efficiency. For this reason, future studies can be concentrated on improving the balancing performance at small tilt angles by some techniques such as adding torque control and acceleration perception and improving the network structures. In addition, research on more complex tasks, such as self-balancing when walking in dynamic environments, will be conducted based on this work.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}