
A Survey of Human Activity Recognition in Smart Homes Based on IoT Sensors Algorithms: Taxonomies, Challenges, and Opportunities with Deep Learning

 ,
,  , ,
, ,
Abstract
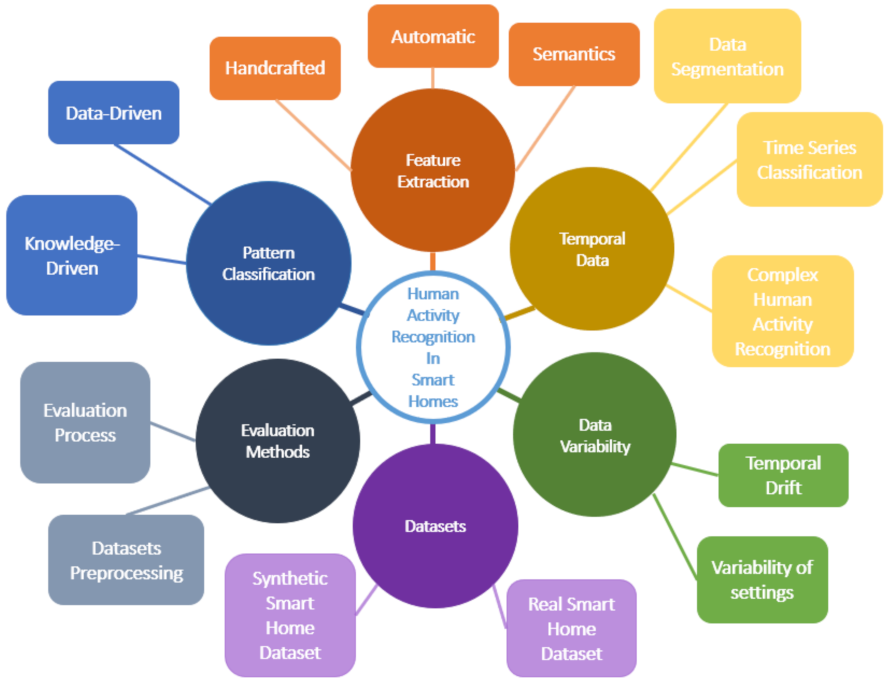
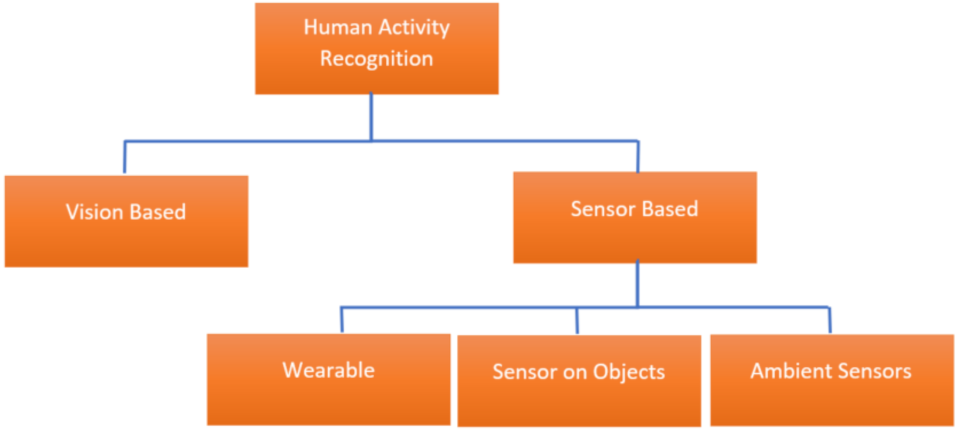
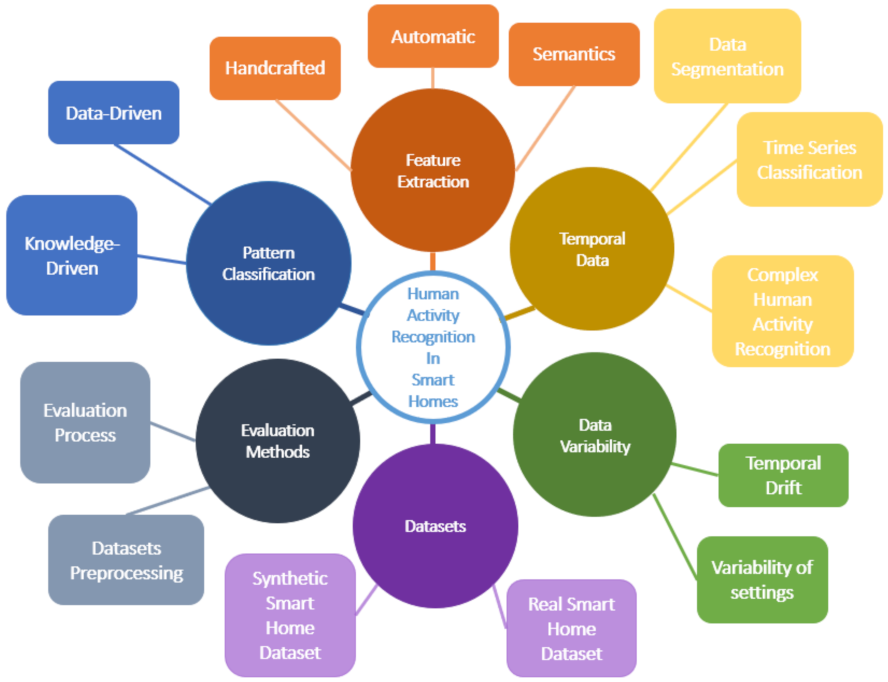
:1. Introduction
1.1. Vision-Based
1.2. Sensor-Based
1.3. Key Contributions
- We conduct a comprehensive survey of recent methods and approaches for human activity recognition in smart homes.
- We propose a new taxonomy of human activity recognition in smart homes in the view of challenges.
- We summarize recent works that apply deep learning techniques for human activity recognition in smart homes.
- We discuss some open issues in this field and point out potential future research directions.
2. Pattern Classification
2.1. Knowledge-Driven Approaches (KDA)
2.2. Data-Driven Approaches (DDA)
2.3. Outlines
3. Features Extraction
3.1. Handcrafted Features
3.1.1. The Baseline Method
3.1.2. The Time Dependence Method
3.1.3. The Sensor Dependency Method
3.1.4. The Sensor Dependency Extension Method
3.1.5. The Past Contextual Information Method
3.1.6. The Latent Knowledge Method
3.2. Automatic Features
3.2.1. Convolutional Neural Networks (CNN)
3.2.2. Autoencoder Method
3.3. Semantics
3.4. Outlines
4. Temporal Data
4.1. Data Segmentation
4.1.1. Explicit Windowing (EW)
4.1.2. Time Windows (TW)
4.1.3. Sensor Event Windows (SEW)
4.1.4. Dynamic Windows (DW)
4.1.5. Fuzzy Time Windows (FTW)
4.1.6. Outlines
4.2. Time Series Classification
4.3. Complex Human Activity Recognition
4.3.1. Sequences of Sub-Activities
4.3.2. Interleave and Concurrent Activities
4.3.3. Multi-User Activities
4.4. Outlines
5. Data Variability
5.1. Temporal Drift
5.2. Variability of Settings
6. Datasets
6.1. Real Smart Home Dataset
6.1.1. Sensor Type and Positioning Problem
6.1.2. Profile and Typology Problem
6.1.3. Annotation Problem
6.2. Synthetic Smart Home Dataset
6.3. Outlines
7. Evaluation Methods
7.1. Datasets Pre-Processing
7.1.1. Unbalanced Datasets Problem
7.1.2. The Other Class Issue
7.1.3. Labeling Issue
7.1.4. Evaluation Metrics
7.2. Evaluation Process
7.2.1. Train/Test
7.2.2. K-Fold Cross Validation
7.2.3. Leave-One-Out Cross-Validation
7.2.4. Multi-Day Segment
7.3. Outlines
8. General Conclusion and Discussions
8.1. Comparison with Other HAR
8.2. Taxonomy and Challenges
8.3. Opportunities
8.4. Discussion
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Chan, M.; Estève, D.; Escriba, C.; Campo, E. A review of smart homes—Present state and future challenges. Comput. Methods Programs Biomed. 2008, 91, 55–81. [Google Scholar] [CrossRef]
- Hussain, Z.; Sheng, M.; Zhang, W.E. Different Approaches for Human Activity Recognition: A Survey. arXiv 2019, arXiv:1906.05074. [Google Scholar]
- Dang, L.M.; Min, K.; Wang, H.; Piran, M.J.; Lee, C.H.; Moon, H. Sensor-based and vision-based human activity recognition: A comprehensive survey. Pattern Recognit. 2020, 108, 107561. [Google Scholar] [CrossRef]
- Beddiar, D.R.; Nini, B.; Sabokrou, M.; Hadid, A. Vision-based human activity recognition: A survey. Multimed. Tools Appl. 2020, 79, 30509–30555. [Google Scholar] [CrossRef]
- Singh, D.; Psychoula, I.; Kropf, J.; Hanke, S.; Holzinger, A. Users’ perceptions and attitudes towards smart home technologies. In International Conference on Smart Homes and Health Telematics; Springer: Berlin/Heidelberg, Germany, 2018; pp. 203–214. [Google Scholar]
- Ordóñez, F.J.; Roggen, D. Deep convolutional and lstm recurrent neural networks for multimodal wearable activity recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, X.; Zhang, Y.; Marsic, I.; Sarcevic, A.; Burd, R.S. Deep learning for rfid-based activity recognition. In Proceedings of the 14th ACM Conference on Embedded Network Sensor Systems CD-ROM, Stanford, CA, USA, 14–16 November 2016; pp. 164–175. [Google Scholar]
- Gomes, L.; Sousa, F.; Vale, Z. An intelligent smart plug with shared knowledge capabilities. Sensors 2018, 18, 3961. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, L.; Hoey, J.; Nugent, C.D.; Cook, D.J.; Yu, Z. Sensor-based activity recognition. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2012, 42, 790–808. [Google Scholar] [CrossRef]
- Aggarwal, J.; Xi, L. Human activity recognition from 3d data: A review. Pattern Recognit. Lett. 2014, 48, 70–80. [Google Scholar] [CrossRef]
- Vrigkas, M.; Nikou, C.; Kakadiaris, I.A. A review of human activity recognition methods. Front. Robot. AI 2015, 2, 28. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Chen, Y.; Hao, S.; Peng, X.; Hu, L. Deep learning for sensor-based activity recognition: A survey. Pattern Recognit. Lett. 2019, 119, 3–11. [Google Scholar] [CrossRef] [Green Version]
- Chen, K.; Zhang, D.; Yao, L.; Guo, B.; Yu, Z.; Liu, Y. Deep learning for sensor-based human activity recognition: Overview, challenges and opportunities. arXiv 2020, arXiv:2001.07416. [Google Scholar]
- Liciotti, D.; Bernardini, M.; Romeo, L.; Frontoni, E. A Sequential Deep Learning Application for Recognising Human Activities in Smart Homes. Neurocomputing 2020, 396, 501–513. [Google Scholar] [CrossRef]
- Gochoo, M.; Tan, T.H.; Liu, S.H.; Jean, F.R.; Alnajjar, F.S.; Huang, S.C. Unobtrusive activity recognition of elderly people living alone using anonymous binary sensors and DCNN. IEEE J. Biomed. Health Inform. 2018, 23, 693–702. [Google Scholar] [CrossRef] [PubMed]
- Yan, S.; Lin, K.J.; Zheng, X.; Zhang, W. Using latent knowledge to improve real-time activity recognition for smart IoT. IEEE Trans. Knowl. Data Eng. 2020, 32, 574–587. [Google Scholar] [CrossRef]
- Perkowitz, M.; Philipose, M.; Fishkin, K.; Patterson, D.J. Mining models of human activities from the web. In Proceedings of the 13th International Conference on World Wide Web, New York, NY, USA, 17–20 May 2004; pp. 573–582. [Google Scholar]
- Chen, L.; Nugent, C.D.; Mulvenna, M.; Finlay, D.; Hong, X.; Poland, M. A logical framework for behaviour reasoning and assistance in a smart home. Int. J. Assist. Robot. Mechatron. 2008, 9, 20–34. [Google Scholar]
- Chen, L.; Nugent, C.D. Human Activity Recognition and Behaviour Analysis; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Yamada, N.; Sakamoto, K.; Kunito, G.; Isoda, Y.; Yamazaki, K.; Tanaka, S. Applying ontology and probabilistic model to human activity recognition from surrounding things. IPSJ Digit. Cour. 2007, 3, 506–517. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.; Nugent, C.; Mulvenna, M.; Finlay, D.; Hong, X. Semantic smart homes: Towards knowledge rich assisted living environments. In Intelligent Patient Management; Springer: Berlin/Heidelberg, Germany, 2009; pp. 279–296. [Google Scholar]
- Chen, L.; Nugent, C. Ontology-based activity recognition in intelligent pervasive environments. Int. J. Web Inf. Syst. 2009, 5, 410–430. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.; Nugent, C.D.; Wang, H. A knowledge-driven approach to activity recognition in smart homes. IEEE Trans. Knowl. Data Eng. 2011, 24, 961–974. [Google Scholar] [CrossRef]
- Logan, B.; Healey, J.; Philipose, M.; Tapia, E.M.; Intille, S. A long-term evaluation of sensing modalities for activity recognition. In Proceedings of the International Conference on Ubiquitous Computing, Innsbruck, Austria, 16–19 September 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 483–500. [Google Scholar]
- Vail, D.L.; Veloso, M.M.; Lafferty, J.D. Conditional random fields for activity recognition. In Proceedings of the 6th International Joint Conference on Autonomous Agents and Multiagent Systems, Honolulu, HI, USA, 14–18 May 2007; pp. 1–8. [Google Scholar]
- Fleury, A.; Vacher, M.; Noury, N. SVM-based multimodal classification of activities of daily living in health smart homes: Sensors, algorithms, and first experimental results. IEEE Trans. Inf. Technol. Biomed. 2009, 14, 274–283. [Google Scholar] [CrossRef] [Green Version]
- Brdiczka, O.; Crowley, J.L.; Reignier, P. Learning situation models in a smart home. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2008, 39, 56–63. [Google Scholar] [CrossRef] [Green Version]
- van Kasteren, T.; Krose, B. Bayesian activity recognition in residence for elders. In Proceedings of the 2007 3rd IET International Conference on Intelligent Environments, Ulm, Germany, 24–25 September 2007; pp. 209–212. [Google Scholar]
- Cook, D.J. Learning setting-generalized activity models for smart spaces. IEEE Intell. Syst. 2010, 2010, 1. [Google Scholar] [CrossRef] [Green Version]
- Sedky, M.; Howard, C.; Alshammari, T.; Alshammari, N. Evaluating machine learning techniques for activity classification in smart home environments. Int. J. Inf. Syst. Comput. Sci. 2018, 12, 48–54. [Google Scholar]
- Chinellato, E.; Hogg, D.C.; Cohn, A.G. Feature space analysis for human activity recognition in smart environments. In Proceedings of the 2016 12th International Conference on Intelligent Environments (IE), London, UK, 14–16 September 2016; pp. 194–197. [Google Scholar]
- Cook, D.J.; Krishnan, N.C.; Rashidi, P. Activity discovery and activity recognition: A new partnership. IEEE Trans. Cybern. 2013, 43, 820–828. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yala, N.; Fergani, B.; Fleury, A. Feature extraction for human activity recognition on streaming data. In Proceedings of the 2015 International Symposium on Innovations in Intelligent SysTems and Applications (INISTA), Madrid, Spain, 2–4 September 2015; pp. 1–6. [Google Scholar]
- Aminikhanghahi, S.; Cook, D.J. Enhancing activity recognition using CPD-based activity segmentation. Pervasive Mob. Comput. 2019, 53, 75–89. [Google Scholar] [CrossRef]
- Pouyanfar, S.; Sadiq, S.; Yan, Y.; Tian, H.; Tao, Y.; Reyes, M.P.; Shyu, M.L.; Chen, S.C.; Iyengar, S. A survey on deep learning: Algorithms, techniques, and applications. ACM Comput. Surv. (CSUR) 2018, 51, 1–36. [Google Scholar] [CrossRef]
- Fang, H.; He, L.; Si, H.; Liu, P.; Xie, X. Human activity recognition based on feature selection in smart home using back-propagation algorithm. ISA Trans. 2014, 53, 1629–1638. [Google Scholar] [CrossRef] [PubMed]
- Irvine, N.; Nugent, C.; Zhang, S.; Wang, H.; Ng, W.W. Neural network ensembles for sensor-based human activity recognition within smart environments. Sensors 2020, 20, 216. [Google Scholar] [CrossRef] [Green Version]
- Tan, T.H.; Gochoo, M.; Huang, S.C.; Liu, Y.H.; Liu, S.H.; Huang, Y.F. Multi-resident activity recognition in a smart home using RGB activity image and DCNN. IEEE Sens. J. 2018, 18, 9718–9727. [Google Scholar] [CrossRef]
- Mohmed, G.; Lotfi, A.; Pourabdollah, A. Employing a deep convolutional neural network for human activity recognition based on binary ambient sensor data. In Proceedings of the 13th ACM International Conference on PErvasive Technologies Related to Assistive Environments, Corfu, Greece, 30 June–3 July 2020; pp. 1–7. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Singh, D.; Merdivan, E.; Hanke, S.; Kropf, J.; Geist, M.; Holzinger, A. Convolutional and recurrent neural networks for activity recognition in smart environment. In Towards Integrative Machine Learning and Knowledge Extraction; Springer: Berlin/Heidelberg, Germany, 2017; pp. 194–205. [Google Scholar]
- Wang, A.; Chen, G.; Shang, C.; Zhang, M.; Liu, L. Human activity recognition in a smart home environment with stacked denoising autoencoders. In Proceedings of the International Conference on Web-Age Information Management, Nanchang, China, 3–5 June 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 29–40. [Google Scholar]
- van Kasteren, T.L.; Englebienne, G.; Kröse, B.J. Human activity recognition from wireless sensor network data: Benchmark and software. In Activity Recognition in Pervasive Intelligent Environments; Springer: Berlin/Heidelberg, Germany, 2011; pp. 165–186. [Google Scholar]
- Ghods, A.; Cook, D.J. Activity2vec: Learning adl embeddings from sensor data with a sequence-to-sequence model. arXiv 2019, arXiv:1907.05597. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2014; pp. 3104–3112. [Google Scholar]
- Bouchabou, D.; Nguyen, S.M.; Lohr, C.; Kanellos, I.; Leduc, B. Fully Convolutional Network Bootstrapped by Word Encoding and Embedding for Activity Recognition in Smart Homes. In Proceedings of the IJCAI 2020 Workshop on Deep Learning for Human Activity Recognition, Yokohama, Japan, 8 January 2021. [Google Scholar]
- Quigley, B.; Donnelly, M.; Moore, G.; Galway, L. A Comparative Analysis of Windowing Approaches in Dense Sensing Environments. Proceedings 2018, 2, 1245. [Google Scholar] [CrossRef] [Green Version]
- van Kasteren, T.L.M. Activity Recognition for Health Monitoring Elderly Using Temporal Probabilistic Models. Ph.D. Thesis, Universiteit van Amsterdam, Amsterdam, The Netherlands, 2011. [Google Scholar]
- Medina-Quero, J.; Zhang, S.; Nugent, C.; Espinilla, M. Ensemble classifier of long short-term memory with fuzzy temporal windows on binary sensors for activity recognition. Expert Syst. Appl. 2018, 114, 441–453. [Google Scholar] [CrossRef]
- Hamad, R.A.; Hidalgo, A.S.; Bouguelia, M.R.; Estevez, M.E.; Quero, J.M. Efficient activity recognition in smart homes using delayed fuzzy temporal windows on binary sensors. IEEE J. Biomed. Health Inform. 2019, 24, 387–395. [Google Scholar] [CrossRef] [PubMed]
- Hamad, R.A.; Yang, L.; Woo, W.L.; Wei, B. Joint learning of temporal models to handle imbalanced data for human activity recognition. Appl. Sci. 2020, 10, 5293. [Google Scholar] [CrossRef]
- Hamad, R.A.; Kimura, M.; Yang, L.; Woo, W.L.; Wei, B. Dilated causal convolution with multi-head self attention for sensor human activity recognition. Neural Comput. Appl. 2021, 1–18. [Google Scholar]
- Krishnan, N.C.; Cook, D.J. Activity recognition on streaming sensor data. Pervasive Mob. Comput. 2014, 10, 138–154. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Al Machot, F.; Mayr, H.C.; Ranasinghe, S. A windowing approach for activity recognition in sensor data streams. In Proceedings of the 2016 Eighth International Conference on Ubiquitous and Future Networks (ICUFN), Vienna, Austria, 5–8 July 2016; pp. 951–953. [Google Scholar]
- Cook, D.J.; Schmitter-Edgecombe, M. Assessing the quality of activities in a smart environment. Methods Inf. Med. 2009, 48, 480. [Google Scholar]
- Philipose, M.; Fishkin, K.P.; Perkowitz, M.; Patterson, D.J.; Fox, D.; Kautz, H.; Hahnel, D. Inferring activities from interactions with objects. IEEE Pervasive Comput. 2004, 3, 50–57. [Google Scholar] [CrossRef]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Singh, D.; Merdivan, E.; Psychoula, I.; Kropf, J.; Hanke, S.; Geist, M.; Holzinger, A. Human activity recognition using recurrent neural networks. In Proceedings of the International Cross-Domain Conference for Machine Learning and Knowledge Extraction, Reggio, Italy, 29 August–1 September 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 267–274. [Google Scholar]
- Park, J.; Jang, K.; Yang, S.B. Deep neural networks for activity recognition with multi-sensor data in a smart home. In Proceedings of the 2018 IEEE 4th World Forum on Internet of Things (WF-IoT), Singapore, 5–8 February 2018; pp. 155–160. [Google Scholar]
- Hong, X.; Nugent, C.; Mulvenna, M.; McClean, S.; Scotney, B.; Devlin, S. Evidential fusion of sensor data for activity recognition in smart homes. Pervasive Mob. Comput. 2009, 5, 236–252. [Google Scholar] [CrossRef]
- Asghari, P.; Soelimani, E.; Nazerfard, E. Online Human Activity Recognition Employing Hierarchical Hidden Markov Models. arXiv 2019, arXiv:1903.04820. [Google Scholar] [CrossRef] [Green Version]
- Devanne, M.; Papadakis, P.; Nguyen, S.M. Recognition of Activities of Daily Living via Hierarchical Long-Short Term Memory Networks. In Proceedings of the International Conference on Systems Man and Cybernetics, Bari, Italy, 6–9 October 2019; pp. 3318–3324. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Liu, R. Human Activity Recognition Based on Wearable Sensor Using Hierarchical Deep LSTM Networks. Circuits Syst. Signal Process. 2020, 39, 837–856. [Google Scholar] [CrossRef]
- Tayyub, J.; Hawasly, M.; Hogg, D.C.; Cohn, A.G. Learning Hierarchical Models of Complex Daily Activities from Annotated Videos. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1633–1641. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. arXiv 2018, arXiv:1802.05365. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Safyan, M.; Qayyum, Z.U.; Sarwar, S.; García-Castro, R.; Ahmed, M. Ontology-driven semantic unified modelling for concurrent activity recognition (OSCAR). Multimed. Tools Appl. 2019, 78, 2073–2104. [Google Scholar] [CrossRef]
- Li, X.; Zhang, Y.; Zhang, J.; Chen, S.; Marsic, I.; Farneth, R.A.; Burd, R.S. Concurrent activity recognition with multimodal CNN-LSTM structure. arXiv 2017, arXiv:1702.01638. [Google Scholar]
- Alhamoud, A.; Muradi, V.; Böhnstedt, D.; Steinmetz, R. Activity recognition in multi-user environments using techniques of multi-label classification. In Proceedings of the 6th International Conference on the Internet of Things, Stuttgart, Germany, 7–9 November 2016; pp. 15–23. [Google Scholar]
- Tran, S.N.; Zhang, Q.; Smallbon, V.; Karunanithi, M. Multi-resident activity monitoring in smart homes: A case study. In Proceedings of the 2018 IEEE International Conference on Pervasive Computing and Communications Workshops (PerCom Workshops), Athens, Greece, 19–23 March 2018; pp. 698–703. [Google Scholar]
- Natani, A.; Sharma, A.; Perumal, T. Sequential neural networks for multi-resident activity recognition in ambient sensing smart homes. Appl. Intell. 2021, 51, 6014–6028. [Google Scholar] [CrossRef]
- Cook, D.J.; Crandall, A.S.; Thomas, B.L.; Krishnan, N.C. CASAS: A smart home in a box. Computer 2012, 46, 62–69. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tapia, E.M.; Intille, S.S.; Larson, K. Activity recognition in the home using simple and ubiquitous sensors. In Proceedings of the International Conference on Pervasive Computing, Linz and Vienna, Austria, 21–23 April 2004; Springer: Berlin/Heidelberg, Germany, 2004; pp. 158–175. [Google Scholar]
- Ordóñez, F.; De Toledo, P.; Sanchis, A. Activity recognition using hybrid generative/discriminative models on home environments using binary sensors. Sensors 2013, 13, 5460–5477. [Google Scholar] [CrossRef] [PubMed]
- Wang, A.; Zhao, S.; Zheng, C.; Yang, J.; Chen, G.; Chang, C.Y. Activities of Daily Living Recognition With Binary Environment Sensors Using Deep Learning: A Comparative Study. IEEE Sens. J. 2020, 21, 5423–5433. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Perslev, M.; Jensen, M.H.; Darkner, S.; Jennum, P.J.; Igel, C. U-time: A fully convolutional network for time series segmentation applied to sleep staging. arXiv 2019, arXiv:1910.11162. [Google Scholar]
- Schlimmer, J.C.; Granger, R.H. Incremental learning from noisy data. Mach. Learn. 1986, 1, 317–354. [Google Scholar] [CrossRef]
- Thrun, S.; Pratt, L. Learning to Learn; Springer US: Boston, MA, USA, 1998. [Google Scholar]
- Parisi, G.I.; Kemker, R.; Part, J.L.; Kanan, C.; Wermter, S. Continual lifelong learning with neural networks: A review. Neural Netw. 2019, 113, 54–71. [Google Scholar] [CrossRef]
- Duminy, N.; Nguyen, S.M.; Zhu, J.; Duhaut, D.; Kerdreux, J. Intrinsically Motivated Open-Ended Multi-Task Learning Using Transfer Learning to Discover Task Hierarchy. Appl. Sci. 2021, 11, 975. [Google Scholar] [CrossRef]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3, 9. [Google Scholar] [CrossRef] [Green Version]
- Fawaz, H.I.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P.A. Transfer learning for time series classification. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 1367–1376. [Google Scholar]
- Cook, D.; Feuz, K.; Krishnan, N. Transfer Learning for Activity Recognition: A Survey. Knowl. Inf. Syst. 2013, 36, 537–556. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hospedales, T.; Antoniou, A.; Micaelli, P.; Storkey, A. Meta-Learning in Neural Networks: A Survey. arXiv 2020, arXiv:2004.05439. [Google Scholar]
- Gjoreski, H.; Kozina, S.; Gams, M.; Lustrek, M.; Álvarez-García, J.A.; Hong, J.H.; Ramos, J.; Dey, A.K.; Bocca, M.; Patwari, N. Competitive live evaluations of activity-recognition systems. IEEE Pervasive Comput. 2015, 14, 70–77. [Google Scholar] [CrossRef]
- Espinilla, M.; Medina, J.; Nugent, C. UCAmI Cup. Analyzing the UJA Human Activity Recognition Dataset of Activities of Daily Living. Proceedings 2018, 2, 1267. [Google Scholar] [CrossRef] [Green Version]
- Alemdar, H.; Ertan, H.; Incel, O.D.; Ersoy, C. ARAS human activity datasets in multiple homes with multiple residents. In Proceedings of the 2013 7th International Conference on Pervasive Computing Technologies for Healthcare and Workshops, Venice, Italy, 5–8 May 2013; pp. 232–235. [Google Scholar]
- Cumin, J.; Lefebvre, G.; Ramparany, F.; Crowley, J.L. A dataset of routine daily activities in an instrumented home. In Proceedings of the International Conference on Ubiquitous Computing and Ambient Intelligence, Philadelphia, PA, USA, 7–10 November 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 413–425. [Google Scholar]
- De-La-Hoz-Franco, E.; Ariza-Colpas, P.; Quero, J.M.; Espinilla, M. Sensor-based datasets for human activity recognition—A systematic review of literature. IEEE Access 2018, 6, 59192–59210. [Google Scholar] [CrossRef]
- Helal, S.; Kim, E.; Hossain, S. Scalable approaches to activity recognition research. In Proceedings of the 8th International Conference Pervasive Workshop, Mannheim, Germany, 29 March–2 April 2010; pp. 450–453. [Google Scholar]
- Helal, S.; Lee, J.W.; Hossain, S.; Kim, E.; Hagras, H.; Cook, D. Persim-Simulator for human activities in pervasive spaces. In Proceedings of the 2011 Seventh International Conference on Intelligent Environments, Nottingham, UK, 25–28 July 2011; pp. 192–199. [Google Scholar]
- Mendez-Vazquez, A.; Helal, A.; Cook, D. Simulating events to generate synthetic data for pervasive spaces. Workshop on Developing Shared Home Behavior Datasets to Advance HCI and Ubiquitous Computing Research. 2009. Available online: https://dl.acm.org/doi/abs/10.1145/1520340.1520735 (accessed on 2 July 2021).
- Armac, I.; Retkowitz, D. Simulation of smart environments. In Proceedings of the IEEE International Conference on Pervasive Services, Istanbul, Turkey, 15–20 July 2007; pp. 257–266. [Google Scholar]
- Fu, Q.; Li, P.; Chen, C.; Qi, L.; Lu, Y.; Yu, C. A configurable context-aware simulator for smart home systems. In Proceedings of the 2011 6th International Conference on Pervasive Computing and Applications, Port Elizabeth, South Africa, 26–28 October 2011; pp. 39–44. [Google Scholar]
- Alshammari, N.; Alshammari, T.; Sedky, M.; Champion, J.; Bauer, C. Openshs: Open smart home simulator. Sensors 2017, 17, 1003. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lee, J.W.; Cho, S.; Liu, S.; Cho, K.; Helal, S. Persim 3d: Context-driven simulation and modeling of human activities in smart spaces. IEEE Trans. Autom. Sci. Eng. 2015, 12, 1243–1256. [Google Scholar] [CrossRef]
- Synnott, J.; Chen, L.; Nugent, C.D.; Moore, G. The creation of simulated activity datasets using a graphical intelligent environment simulation tool. In Proceedings of the 2014 36th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Chicago, IL, USA, 26–30 August 2014; pp. 4143–4146. [Google Scholar]
- Synnott, J.; Nugent, C.; Jeffers, P. Simulation of smart home activity datasets. Sensors 2015, 15, 14162–14179. [Google Scholar] [CrossRef]
- Richter, S.R.; Vineet, V.; Roth, S.; Koltun, V. Playing for data: Ground truth from computer games. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 102–118. [Google Scholar]
- Richter, S.R.; Hayder, Z.; Koltun, V. Playing for benchmarks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2213–2222. [Google Scholar]
- Roitberg, A.; Schneider, D.; Djamal, A.; Seibold, C.; Reiß, S.; Stiefelhagen, R. Let’s Play for Action: Recognizing Activities of Daily Living by Learning from Life Simulation Video Games. arXiv 2021, arXiv:2107.05617. [Google Scholar]
- Das, S.; Dai, R.; Koperski, M.; Minciullo, L.; Garattoni, L.; Bremond, F.; Francesca, G. Toyota smarthome: Real-world activities of daily living. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 833–842. [Google Scholar]
- Katz, S. Assessing self-maintenance: Activities of daily living, mobility, and instrumental activities of daily living. J. Am. Geriatr. Soc. 1983, 31, 721–727. [Google Scholar] [CrossRef] [PubMed]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Fernández, A.; García, S.; Galar, M.; Prati, R.C.; Krawczyk, B.; Herrera, F. Learning from Imbalanced Data Sets; Springer: Berlin/Heidelberg, Germany, 2018; Volume 10. [Google Scholar]
- He, H.; Ma, Y. Imbalanced Learning: Foundations, Algorithms, and Applications; University of Rhode Island: Kingston, RI, USA, 2013. [Google Scholar]
- Bolleddula, N.; Hung, G.Y.C.; Ma, D.; Noorian, H.; Woodbridge, D.M.k. Sensor Selection for Activity Classification at Smart Home Environments. In Proceedings of the 2020 42nd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Montreal, QC, Canada, 20–24 July 2020; pp. 3927–3930. [Google Scholar]
- Balta-Ozkan, N.; Davidson, R.; Bicket, M.; Whitmarsh, L. Social barriers to the adoption of smart homes. Energy Policy 2013, 63, 363–374. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
| Segmentation Type | Usable for | Require Resamplig | Time Representation | Usable on | Capture Long | Capture Dependence | # Steps |
|---|---|---|---|---|---|---|---|
| Real Time | Raw Data | Term Dependencies | between Sensors | ||||
| EW | No | No | No | Yes | only inside the sequence | Yes | 1 |
| SEW | Yes | No | No | Yes | depends of the size | Yes | 1 |
| TW | Yes | Yes | Yes | Yes | depends of the size | No | 1 |
| DW | Yes | No | No | Yes | only inside the pre-segmented sequence | Yes | 2 |
| FTW | Yes | Yes | Yes | Yes | Yes | No | 2 |
| Ref | Segmentation | Data Representation | Encoding | Feature Type | Classifier | Dataset | Real-Time |
|---|---|---|---|---|---|---|---|
| [14] | EW | Sequence | Integer sequence (one integer | Automatic | Uni LSTM, Bi LSTM, Cascade | CASAS [75]: | No |
| for each possible | LSTM, Ensemble LSTM, | Milan, Cairo, Kyoto2, | |||||
| sensors activations) | Cascade Ensemble LSTM | Kyoto3, Kyoto4 | |||||
| [60] | TW | Multi-channel | Binary matrix | Automatic | Uni LSTM | Kasteren [43] | Yes |
| [61] | EW | Sequence | Integer sequence (one | Automatic | Residual LSTM, | MIT [76] | No |
| integer for each sensor Id) | Residual GRU | ||||||
| [49] | FTW | Multi-channel | Real values matrix (computed | Manual | LSTM | Ordonez [77], CASAS A & | Yes |
| values inside each FTW) | CASAS B [75] | ||||||
| [15] | EW + SEW | Multi-channel | Binary picture | Automatic | 2D CNN | CASAS [75]: Aruba | No |
| [51] | FTW | Multi-channel | Real values matrix (computed | Manual | Joint LSTM + 1D CNN | Ordonez [77], | Yes |
| values inside each FTW) | Kasteren [43] | ||||||
| [41] | TW | Multi-channel | Binary matrix | Automatic | 1D CNN | Kasteren [43] | Yes |
| [78] | TW | Multi-channel/Sequence | Binary matrix, Binary vector, | Automatic/Manual | Autoencoder, 1D CNN, | Ordonez [77] | Yes |
| Numerical vector, Probability vector | Automatic/Manual | 2D CNN, LSTM, DBN | |||||
| [34] | SEW | Sequence | Categorical values | Manual | Random Forest | CASAS [75]: HH101-HH125 | Yes |
| Ref | Multi-Resident | Resident Type | Duration | Sensor Type | # of Sensors | # of Activity | # of Houses | Year |
|---|---|---|---|---|---|---|---|---|
| [43] | No | Elderly | 12–22 days | Binary | 14–21 | 8 | 3 | 2011 |
| [92] | Yes | Young | 2 months | Binary | 20 | 27 | 3 | 2013 |
| [93] | No | Young | 2 weeks | Binary, Scalar | 236 | 20 | 1 | 2017 |
| [75] | Yes | Elderly | 2–8 months | Binary, Scalar | 14–30 | 10–15 | >30 | 2012 |
| [77] | No | Elderly | 14–21 days | Binary | 12 | 11 | 2 | 2013 |
| [76] | No | Elderly | 2 weeks | Binary, Scalar | 77–84 | 9–13 | 2 | 2004 |
| Date | Time | Sensor ID | Value | Label |
|---|---|---|---|---|
| 2010-01-05 | 08:25:37.000026 | M003 | OFF | |
| 2010-01-05 | 08:25:45.000001 | M004 | ON | Read begin |
| ... | ... | ... | ... | ... |
| 2010-01-05 | 08:35:09.000069 | M004 | ON | |
| 2010-01-05 | 08:35:12.000054 | M027 | ON | |
| 2010-01-05 | 08:35:13.000032 | M004 | OFF | (Read should end) |
| 2010-01-05 | 08:35:18.000020 | M027 | OFF | |
| 2010-01-05 | 08:35:18.000064 | M027 | ON | |
| 2010-01-05 | 08:35:24.000088 | M003 | ON | |
| 2010-01-05 | 08:35:26.000002 | M012 | ON | (Kitchen Activity should begin) |
| 2010-01-05 | 08:35:27.000020 | M023 | ON | |
| ... | ... | ... | ... | ... |
| 2010-01-05 | 08:45:22.000014 | M015 | OFF | |
| 2010-01-05 | 08:45:24.000037 | M012 | ON | Kitchen Activity end |
| 2010-01-05 | 08:45:26.000056 | M023 | OFF |
| Ref | Train/Test Spilt | K-Fold | Leave-One-Out | Multi-Day | Respect Time | Sensitive to Data | Real Time | Offline Recognition | Usable on |
|---|---|---|---|---|---|---|---|---|---|
| Cross-Validation | Cross-Validation | Segment | Order of Activities | Drift Problem | Recognition | Small Datasets | |||
| [16] | ✓ | Yes | Yes | Yes | Yes | No | |||
| [14,15,61] | ✓ | No | No | No | Yes | No | |||
| [41,49,51,60,78] | ✓ | Not necessarily | No | Yes | Yes | Yes | |||
| [34] | ✓ | Yes | No | Yes | Yes | No |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bouchabou, D.; Nguyen, S.M.; Lohr, C.; LeDuc, B.; Kanellos, I. A Survey of Human Activity Recognition in Smart Homes Based on IoT Sensors Algorithms: Taxonomies, Challenges, and Opportunities with Deep Learning. Sensors 2021, 21, 6037. https://doi.org/10.3390/s21186037
Bouchabou D, Nguyen SM, Lohr C, LeDuc B, Kanellos I. A Survey of Human Activity Recognition in Smart Homes Based on IoT Sensors Algorithms: Taxonomies, Challenges, and Opportunities with Deep Learning. Sensors. 2021; 21(18):6037. https://doi.org/10.3390/s21186037
Chicago/Turabian StyleBouchabou, Damien, Sao Mai Nguyen, Christophe Lohr, Benoit LeDuc, and Ioannis Kanellos. 2021. "A Survey of Human Activity Recognition in Smart Homes Based on IoT Sensors Algorithms: Taxonomies, Challenges, and Opportunities with Deep Learning" Sensors 21, no. 18: 6037. https://doi.org/10.3390/s21186037
APA StyleBouchabou, D., Nguyen, S. M., Lohr, C., LeDuc, B., & Kanellos, I. (2021). A Survey of Human Activity Recognition in Smart Homes Based on IoT Sensors Algorithms: Taxonomies, Challenges, and Opportunities with Deep Learning. Sensors, 21(18), 6037. https://doi.org/10.3390/s21186037