
A Sensor Fused Rear Cross Traffic Detection System Using Transfer Learning


Abstract
:1. Introduction
2. Related Work
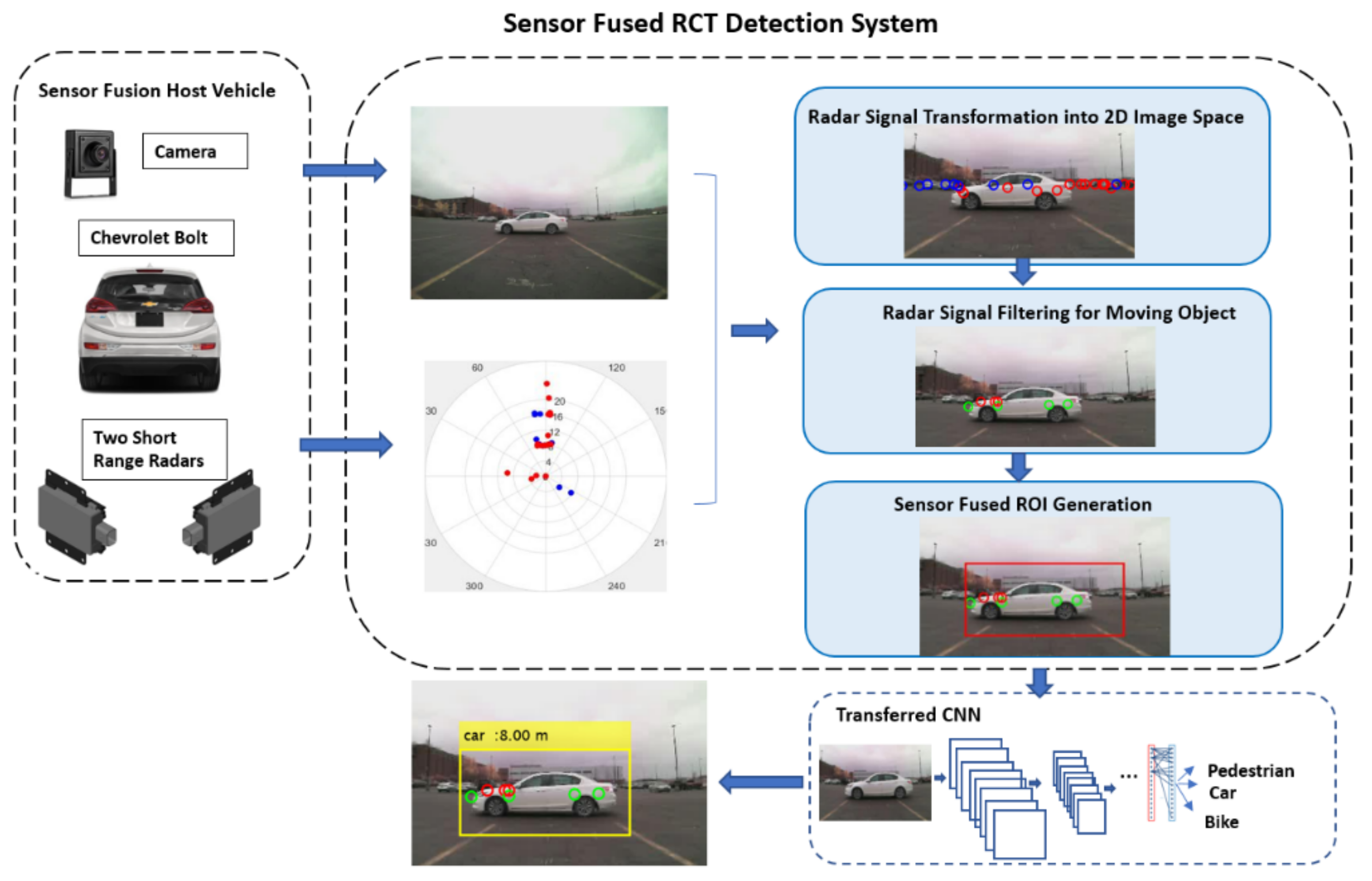
3. The Rear Cross Traffic Detection Methodology
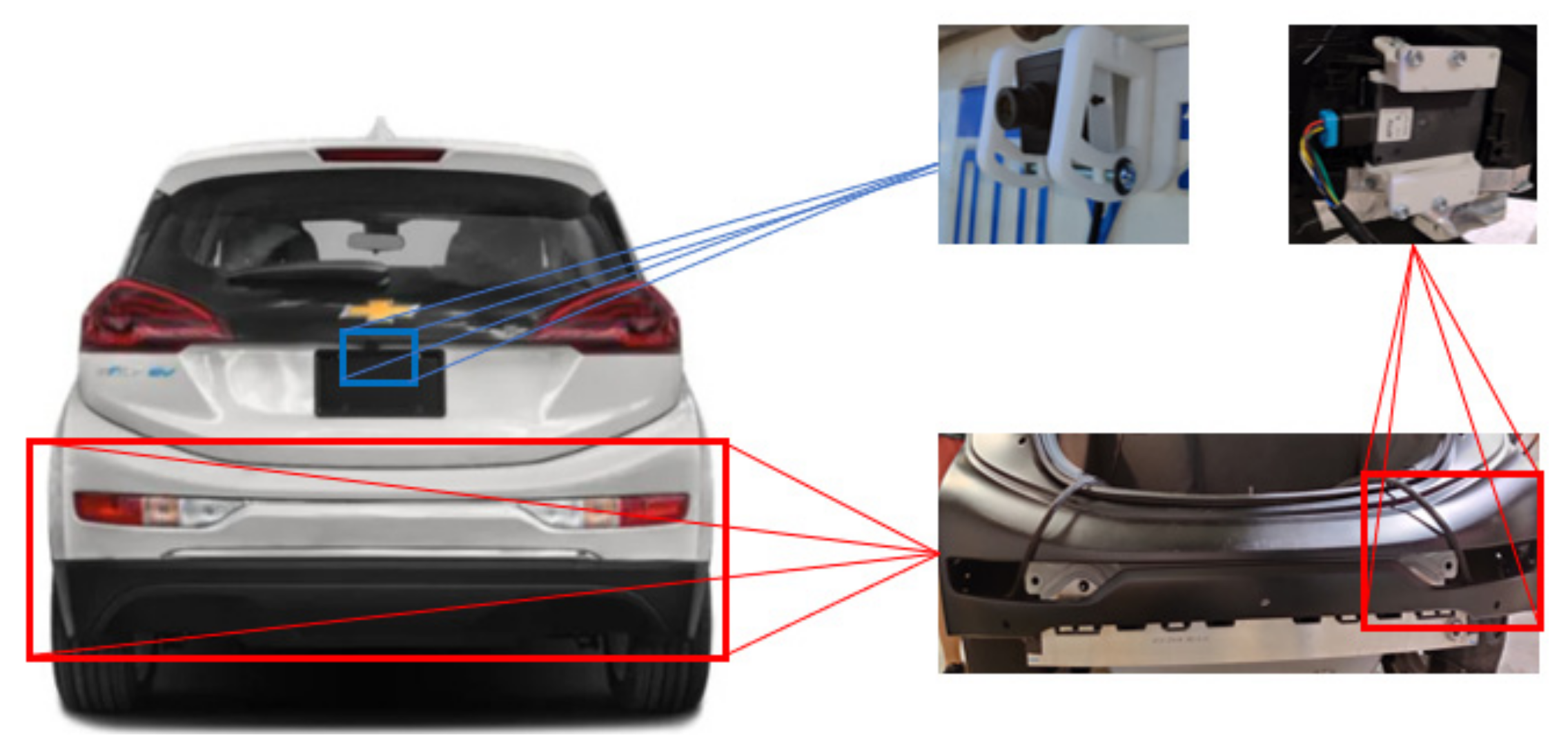
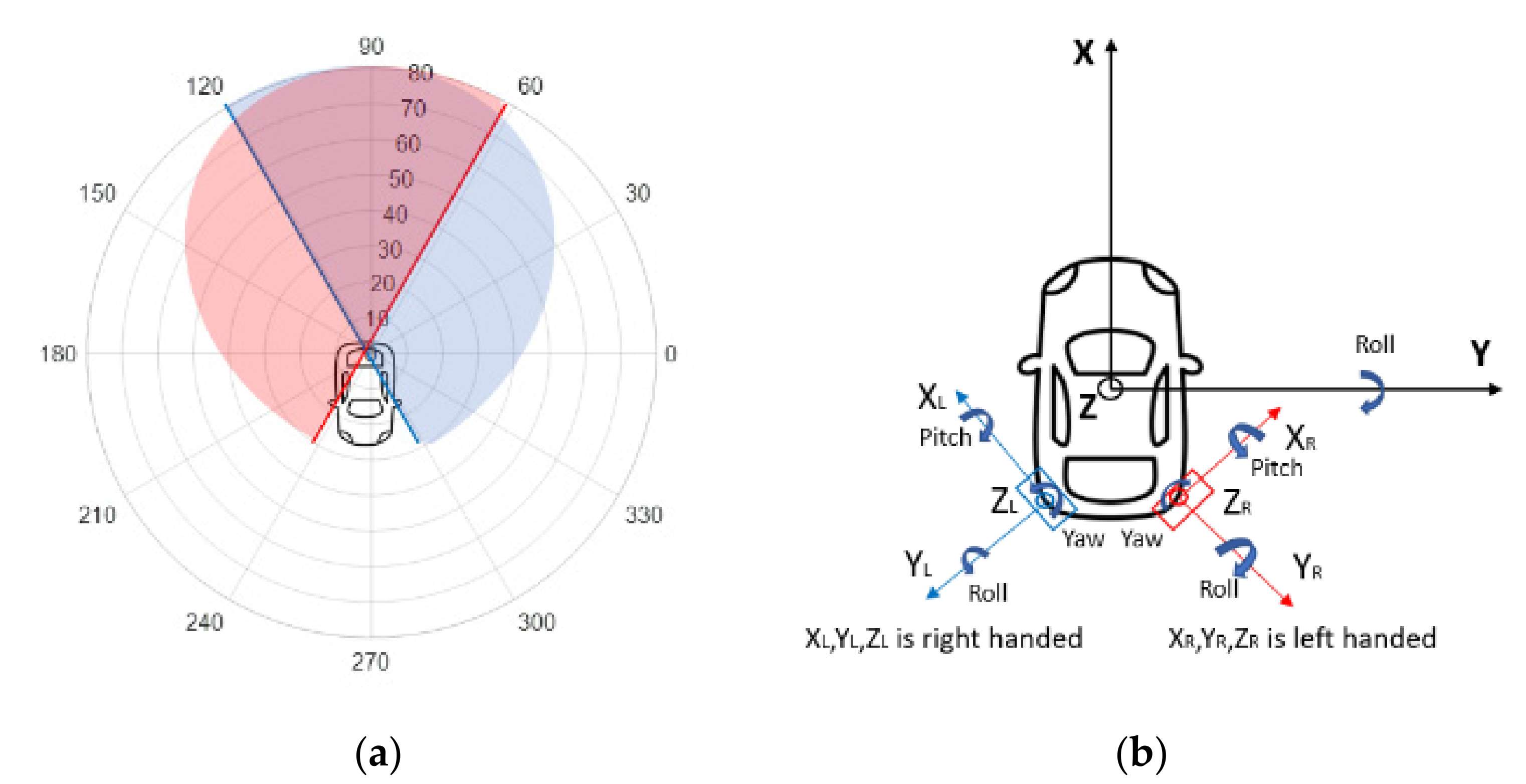
3.1. Hardware Set-Up for the RCT Detection System
3.2. The Sensor Fused RCT Detection System
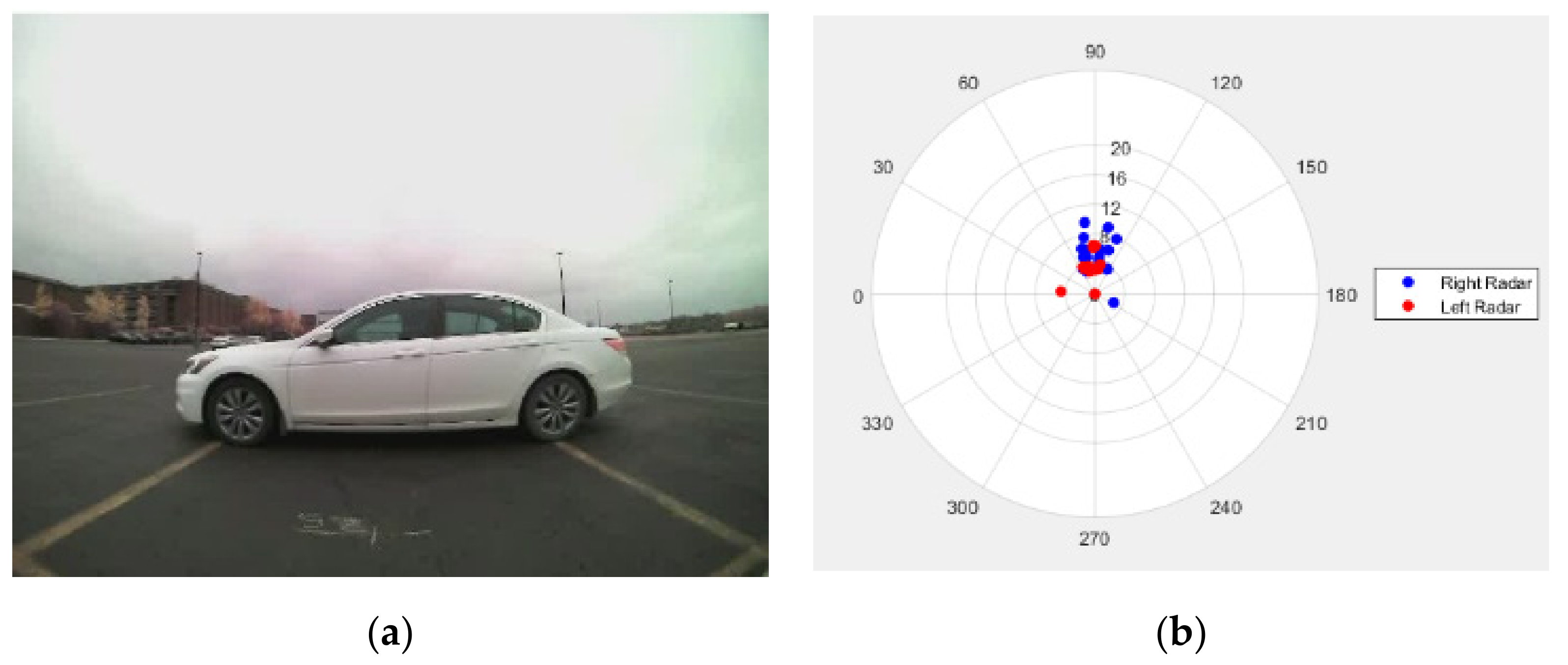
3.2.1. Coordinate Transformation and Radar Signal Filtering
3.2.2. The Proposed ROI Extraction Algorithm
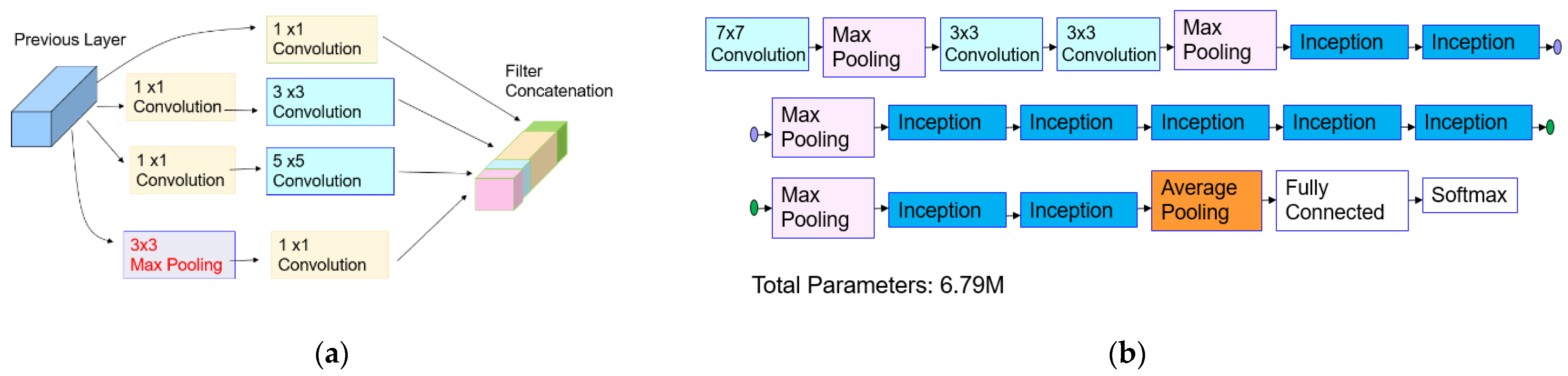
3.2.3. Object Classification Using the Transferred CNN Model
4. Experiments on the RCT Detection System
5. Conclusions and Future Scope
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Singh, S. Driver Attributes and Rear-End Crash Involvement Propensity. DOT HS 809 540; National Center for Statistics and Analysis, S.W.: Washington, DC, USA, 2003. [Google Scholar]
- Zhong, Z.; Liu, S.; Mathew, M.; Dubey, A. Camera radar fusion for increased reliability in adas applications. Electron. Imaging 2018, 17, 258-1–258-4. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Lecture Notes in Computer Science, Proceedings of the Computer Vision—ECCV 2016. ECCV 2016, 17 September 2016; Springer: Cham, Switzerland, 2016; Volume 9905, pp. 21–37. [Google Scholar]
- Meng, Q.; Song, H.; Li, G.; Zhang, Y.A.; Zhang, X. A block object detection method based on feature fusion networks for autonomous vehicles. Complexity 2019, 2019, e4042624. [Google Scholar] [CrossRef]
- Zhang, F.; Li, C.; Yang, F. Vehicle detection in urban traffic surveillance images based on convolutional neural networks with feature concatenation. Sensors 2019, 19, 594. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Guo, Y.; Kumazawa, I.; Kaku, C. Blind spot obstacle detection from monocular camera images with depth cues extracted by CNN. Automot. Innov. 2018, 1, 362–373. [Google Scholar] [CrossRef] [Green Version]
- Lee, D.; Cheung, C.; Pritsker, D. Radar-Based Object Classification Using an Artificial Neural Network. In Proceedings of the 2019 IEEE National Aerospace and Electronics Conference (NAECON), Dayton, OH, USA, 15–19 July 2019; pp. 305–310. [Google Scholar]
- Lombacher, J.; Hahn, M.; Dickmann, J.; Wöhler, C. Potential of radar for static object classification using deep learning methods. In Proceedings of the 2016 IEEE MTT-S International Conference on Microwaves for Intelligent Mobility, San Diego, CA, USA, 19–20 May 2016; pp. 1–4. [Google Scholar]
- Visentin, T.; Sagainov, A.; Hasch, J.; Zwick, T. Classification of objects in polarimetric radar images using CNNs at 77 GHz. In Proceedings of the 2017 IEEE Asia Pacific Microwave Conference (APMC), Kuala Lumpur, Malaysia, 13–16 November 2017; pp. 356–359. [Google Scholar]
- Kim, S.; Lee, S.; Doo, S.; Shim, B. Moving target classification in automotive radar systems using convolutional recurrent neural networks. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018; pp. 1482–1486. [Google Scholar]
- Bi, X.; Tan, B.; Xu, Z.; Huang, L. A new method of target detection based on autonomous radar and camera data fusion. In SAE Technical Paper; SAE International: Warrendale, PA, USA, 23 September 2017. [Google Scholar]
- Hyun, E.; Jin, Y.; Jeon, H.; Shin, Y. Radar-Camera Sensor Fusion Based Object Detection for Smart Vehicles. In Proceedings of the ACCSE 2018: The Third International Conference on Advanced in Computation, Communications and Services, Barcelona, Spain, 22–26 July 2018. [Google Scholar]
- Chadwick, S.; Maddern, W.; Newman, P. Distant vehicle detection using radar and vision. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 8311–8317. [Google Scholar]
- Kim, J.; Emeršič, Ž.; Han, D.S. Vehicle Path Prediction based on Radar and Vision Sensor Fusion for Safe Lane Changing. In 2019 International Conference on Artificial Intelligence in Information and Communication (ICAIIC); IEEE: Okinawa, Japan, 2019; pp. 267–271. [Google Scholar]
- Huang, P.-Y.; Lin, H.-Y.; Chang, C.-C. Depth-Based Rear-Obstacle Detection Approach for Driving in the Reverse Gear. Int. J. Innov. Comput. Inf. Control. ICIC 2020, 16, 1225–1235. [Google Scholar]
- Takahashi, Y.; Komoguchi, T.; Seki, M.; Patel, N.; Auner, D.; Campbell, B. Alert Method for Rear Cross Traffic Alert System in North America; SAE International: Warrendale, PA, USA, 2013. [Google Scholar]
- Spinel Camera. Available online: https://www.spinelelectronics.com (accessed on 19 December 2020).
- Park, J.; Raguraman, S.J.; Aslam, A.; Gotadki, S. Robust Sensor Fused Object Detection Using Convolutional Neural Networks for Autonomous Vehicles; SAE International: Warrendale, PA, USA, 2020. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; Volume 1, pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR); Curran Associates Inc.: Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Krause, J.; Stark, M.; Deng, J.; Fei-Fei, L. 3D Object Representations for Fine-Grained Categorization. In Proceedings of the 2013 IEEE International Conference on Computer Vision (ICCV) Workshops, Sydney, Australia, 1–8 December 2013; pp. 554–561. [Google Scholar]
- Wang, L.; Shi, J.; Song, G.; Shen, I. Object Detection Combining Recognition and Segmentation. In Lecture Notes in Computer Science, Proceedings of the Computer Vision—ACCV 2007; Yagi, Y., Kang, S.B., Kweon, I.S., Zha, H., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 189–199. [Google Scholar]
- INRIA Person Dataset. Available online: http://pascal.inrialpes.fr/data/human/ (accessed on 11 January 2021).
- Li, X.; Flohr, F.; Yang, Y.; Xiong, H.; Braun, M.; Pan, S.; Li, K.; Gavrila, D.M. A New Benchmark for Vision-Based Cyclist Detection. In Proceedings of the 2016 IEEE Intelligent Vehicles Symposium (IV), Gothenburg, Sweden, 19–22 June 2016; pp. 1028–1033. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, Canada, 7–12 December 2015; Volume 1, pp. 91–99. [Google Scholar]
- Udacity Vehicle Dataset. Available online: https://github.com/udacity/self-driving-car/tree/master/annotations (accessed on 3 May 2021).



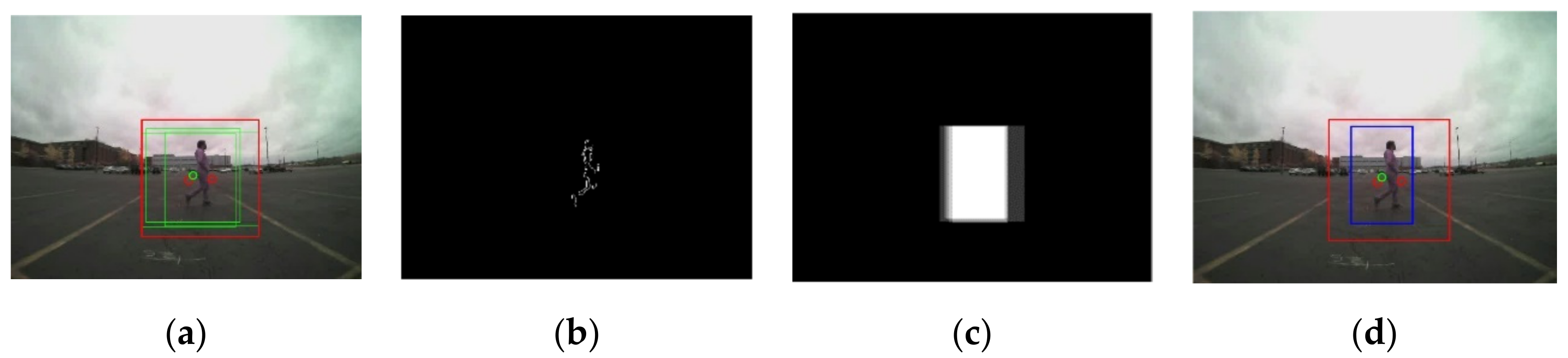








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description | Value |
|---|---|---|
| dx | Physical x pixel length in the image coordinate | - |
| dy | Physical y pixel length in the image coordinate | - |
| u0 | x pixel coordinate of the intersection point between axis and image plane | 640 |
| v0 | y pixel coordinate of the intersection point between axis and image plane | 480 |
| f | Camera focal length | 0.0021 m |
| u | x pixel coordinate of radar detection plotted on the image | - |
| v | y pixel coordinate of radar detection plotted on the image | - |
| Layer | AlexNet | VGG-16 | VGG-19 | DarkNet | ResNet-50 |
|---|---|---|---|---|---|
| Convolution | 5 | 13 | 16 | 19 | 49 |
| Max Pooling | 3 | 5 | 5 | 5 | 1 |
| Avg. Pooling | - | - | - | 1 | 1 |
| Fully Connected | 2 | 3 | 3 | - | 1 |
| Softmax | 1 | 1 | 1 | 1 | 1 |
| Parameters (Millions) | 62 M | 138 M | 144 M | 20.8 M | 25.5 M |
| CNN Models | Training Time for Transfer Learning (min) | Validation Accuracy (%) | ||
|---|---|---|---|---|
| α = 0.0001 | α = 0.0002 | α = 0.0001 | α = 0.0002 | |
| AlexNet | 10 | 8 | 93.28 | 92.41 |
| VGG-16 | 115 | 115 | 96.52 | 95.40 |
| VGG-19 | 390 | 385 | 97.01 | 95.65 |
| Darknet-19 | 50 | 49 | 87.81 | 87.56 |
| Resnet-50 | 57 | 57 | 93.28 | 93.91 |
| GoogLeNet | 27 | 27 | 96.89 | 96.89 |
| Class | Accuracy (%) per Class Type | Overall Accuracy (%) | ||
|---|---|---|---|---|
| Bike | Car | Pedestrian | ||
| AlexNet | 92.91 | 87.48 | 99.17 | 93.78 |
| VGG-16 | 92.47 | 97.72 | 95.77 | 95.04 |
| VGG-19 | 96.96 | 94.60 | 97.16 | 96.42 |
| Darknet-19 | 88.05 | 78.72 | 90.55 | 86.54 |
| Resnet-50 | 95.23 | 93.91 | 78.31 | 88.70 |
| GoogLeNet | 94.83 | 95.77 | 97.82 | 96.17 |
| Vehicle Detection System | Processing Time per Fame (s) | Precision∗100 | Recall∗100 | |
|---|---|---|---|---|
| Sensor Fused detection System | VGG-16 | 0.0052 | 97.97 | 96.32 |
| VGG-19 | 0.0057 | 97.98 | 96.68 | |
| GoogLeNet | 0.0047 | 97.97 | 96.20 | |
| Camera only detection system: | VGG-16faster R-CNN | 0.0931 | 99.86 | 85.89 |
| VGG-19faster R-CNN | 0.1170 | 98.81 | 81.84 | |
| GoogLeNetfaster R-CNN | 0.4095 | 98.64 | 80.37 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, J.; Yu, W. A Sensor Fused Rear Cross Traffic Detection System Using Transfer Learning. Sensors 2021, 21, 6055. https://doi.org/10.3390/s21186055
Park J, Yu W. A Sensor Fused Rear Cross Traffic Detection System Using Transfer Learning. Sensors. 2021; 21(18):6055. https://doi.org/10.3390/s21186055
Chicago/Turabian StylePark, Jungme, and Wenchang Yu. 2021. "A Sensor Fused Rear Cross Traffic Detection System Using Transfer Learning" Sensors 21, no. 18: 6055. https://doi.org/10.3390/s21186055
APA StylePark, J., & Yu, W. (2021). A Sensor Fused Rear Cross Traffic Detection System Using Transfer Learning. Sensors, 21(18), 6055. https://doi.org/10.3390/s21186055