1. Introduction
Wireless sensor networks (WSN) are networks in which data obtained by observing the environment by a large number of sensors deployed in a specific area are sent securely to other sensors or centers in the network. These networks have the following capabilities: not connected to a central node, self-managing and healing, not connected to a specific network topology, multiway routing, preserving the integrity and confidentiality of data, and robustness [
1]. For these reasons, WSNs have been widely used for applications in environmental, health, military, and commercial systems, such as intelligent transportation, smart home, industrial monitoring, logistics, health care, among others [
2,
3]. However, WSNs have serious problems in privacy and security [
4,
5]. In addition, WSNs have some dependability problems because WSNs are increasingly used in critical application scenarios where the level of trust on WSNs becomes an important factor, affecting the success of large-scale industrial WSN applications [
6]. To solve the problems, cryptography is performed to ensure the security and integrity of information in WSNs. These cryptography algorithms require extensive modular multiplication and exponentiation operations, which are much more computationally expensive. Therefore, to obtain high computational power, the circuits for cryptographic algorithms are required. For the accuracy of the cryptographic algorithm, cryptographic circuits must be rigorously tested to guarantee their quality [
7]. Therefore, a scan architecture known as design for testability (DFT) technique, which can obtain high test coverage, is generally used to test the cryptographic circuits [
8]. However, the cryptography circuits consume a high power because they require high computational power. In addition, the power consumption during scan testing is much higher than that in functional operation. According to a study report, the average test power can be three times the power consumed during a functional operation [
9]. Moreover, power consumption during scan testing becomes a more serious problem as the number of transistors and the complexity of chips is increased. Excessive power consumption reduces circuit reliability and results in a yield loss caused by IR drop; therefore, the test power consumption must be minimized.
In this paper, to solve these problems, a novel scan correlation-aware scan cluster reordering method is proposed. The novelty of the proposed method is that using a new scan correlation-aware clustering in order to place highly correlated scan cells adjacent to each other with a small computation time, the proposed method has a significant power reduction effect compared to that of the previous methods. The performance of the proposed method is compared with state-of-the-art methods with experiments on the International Symposium on Circuits and Systems (ISCAS)’89 and OpenRISC (OR)1200 benchmark circuits. The experimental results demonstrated that the total number of shift transitions was reduced by 28.31% on average compared with the pervious methods with minimal computational time, confirming the effectiveness and superiority of the proposed method for shift-power consumption and computational time. Therefore, by improving the reliability of cryptography circuits in WSNs through significant test-power reduction, the proposed method can ensure the security and integrity of information in WSNs and contributes to applications in environmental, health, military, and commercial systems, such as intelligent transportation, smart home, industrial monitoring, logistics, and health care, where WSNs are used.
The remainder of this paper is organized as follows.
Section 2 describes the related works on scan-based testing for low-power testing. The hierarchical agglomerative clustering (HAC) technology and the weighted transition metric (WTM), a background for the proposed method, are introduced in
Section 3. The portion of X-bits in the test patterns and the potential of using X-bits for power consumption are also discussed.
Section 4 discusses the correlation distribution of adjacent scan cells, a motivation for the proposed method. The central concept of the proposed method and a step-by-step example are also presented. In
Section 5, the experimental results of the power consumption and computational time are discussed. Finally,
Section 6 concludes this paper.
2. Related Works
Generally, the test-power consumption problem caused by excessive switching has been solved by the following three methods: (1) automatic test pattern generation (ATPG), (2) hardware modification, and (3) scan chain reordering.
ATPG-based techniques control the configurations of the test pattern generation. Minimum transition (MT)-filling uses X-bits (don’t care bits) in the test patterns to reduce test power [
10]. The concept is to fill X-bits with care bits to lower the shift-in transitions. Li et al. proposed a new X-filling technique, called “iFill,” that considers the impact of X-bits on the switching activities of the circuit nodes and reduces power consumption during both scan-in and -out operations [
11]. Devanathan et al. proposed a glitch-aware pattern generation and optimization framework for a power-safe scan test [
12]. Bosio et al. proposed a power-aware test pattern generation method for at-speed launch-off-shift (LOS) testing [
13]. Furthermore, Girard et al. proposed a test vector ordering technique for switching activity reduction during scan testing [
14]. Sivanandam et al. proposed a new power transition x-filling based selective Huffman encoding technique, which achieves test data compression and switching power reduction [
15]. These methods reduce the test power consumption without requiring any design modification or additional DFT circuitry. However, applying them to an actual test flow is difficult because their power reduction is less effective than the hardware-based or scan chain reordering methods.
The hardware-based solution adds extra DFT circuitry or modifies the design. Chiu et al. proposed a jump scan technology that shifts two bits of scan data per clock cycle such that the scan clock frequency is halved without increasing the test time [
16]. Bonhomme et al. proposed a gated clock scheme for the scan path and a clock tree to feed the scan path [
17]. Rosinger et al. proposed a scan architecture with mutually exclusive scan segment activation for shift- and capture-power reduction [
18]. Zhang et al. presented a multiphase clock scan technique for low test power [
19]. Furthermore, Lee et al. proposed a built-in self-test scheme that uses a new scan partitioning technique and a decoding methodology for low test power [
20]. Cao et al. proposed a bypassable scan data retention flip-flop (BPS-DRFF), which prevents the signals from going to the combinational circuit during scan shifting, for low-power testing [
21]. These methods reduce the test power during scan testing but are likely to cause area overhead or performance degradation and serious delays [
22].
Scan chain reordering is a solution that changes the order of scan cells to minimize shift transitions. Although the scan chain reordering method has routing overhead, it is widely applied to reduce test power because of its high performance and simple architecture. Accordingly, Cui et al. described a k-means clustering-based scan chain reordering method under a routing constraint [
23]. Seo et al. presented a statistic-based scan chain reordering method that performs scan partitioning to reduce routing overhead [
24]. Huang et al. described a routing constrained scan chain reordering technique [
25]. These methods determine the optimal scan chain reordering sequence that considers both routing overhead and low-test power. However, these methods can be an overhead of the overall design flow, which are performed using the layout information in a back-end design flow and executes the layout twice to reduce the test power simultaneously under the routing constraint. In addition, these methods do not effectively reduce the test power due to using both routing and test power information.
The method in [
26] used both response and pattern correlations to minimize the scan-out and -in transitions simultaneously. Seo et al. proposed a scan chain reordering-aware X-filling and stitching method for the scan-shift power reduction [
27]. Pathak et al. proposed a logic cluster controllability (LoCCo)-based scan chain stitching method that reduces the shift-in power [
28]. The method in [
29] merged the scan cells with higher care bit density toward the front of scan chains. Kim et al. proposed a new shift mechanism of exclusive scan-shift and the scan chain reordering method considering the number of the scan cell’s fan-outs [
30]. Lee et al. proposed the scan chain stitching method using the circuit topology to analyze the testability of each flip-flop [
31]. However, these methods are not effective in reducing power, and the computational time is also not negligible. Therefore, a scan chain reordering method with a significant reduction in power and a fast computational time must be developed.
In this paper, a novel scan correlation-aware scan cluster reordering method is proposed to significantly reduce the test-power consumption with a small computation time. In order to achieve this, the algorithmic innovation is derived as follows. The proposed method consists of three steps. First, a pairwise distance matrix between scan cells is constructed using test patterns. A weighted distance matrix must be prepared in advance to consider both shift-in and -out transitions. Second, scan correlation clustering is performed using the distance matrix built in the previous step, and a resultant dendrogram tree is obtained after the clustering. The sequence of the leaves of the dendrogram tree, which are the newly aligned scan cells, is used in the third step to reorder the scan chain. Third, scan chain reordering is performed using the sequence of the newly aligned scan cells.
4. Proposed Method
This section first presents the characteristics of the correlation distribution between the adjacent scan cells, which is the motivation of the proposed method. The relationship between the adjacent scan correlation and the power consumption and the possibility of increasing the correlation are also discussed. The details of the proposed method are then described. The proposed algorithm consists of three steps, which are described, including example test patterns. Moreover, the effectiveness of the proposed method is confirmed by comparing the WTMs before and after the scan chain reordering.
4.1. Motivation
Consider the ISCAS benchmark s38584 circuit to illustrate the concept of correlation distribution.
Figure 2 illustrates the correlation distribution of the adjacent scan cells when stitched in alphabetical order. This correlation distribution can be obtained as follows. First, a scan chain is stitched alphabetically (a conventional method), and the ATPG is run to obtain the test patterns. Second, the correlation between the adjacent scan cells is obtained by calculating the normalized hamming distance and subtracting it from 1. This procedure is repeated for all adjacent scan cells to obtain a correlation distribution of a circuit.
Figure 2 illustrates that the correlation distribution is densest near 0.9 and widely distributed with a wide tail stretched far to the left in a correlation area between 0 and 0.9.
The correlation value is an indicator of the degree of similarity between the scan cells. The lower the correlation between the scan cells, the more likely the opposite phase is in the test patterns. A low correlation indicates that switching activities occur mostly between the scan cells during the scan-shift operation. Therefore, a high correlation between adjacent scan cells is advantageous for shift power.
Figure 3 illustrates the heatmap graph of all scan cell-to-cell correlations in four ISCAS benchmark circuits. The closer the color is to green, the higher the correlation. In contrast, the closer the color is to red, the lower the correlation. The scan cells of a weak correlation (red grid,
Figure 3) are expected to cause switching activities to occur excessively during scan testing. Therefore, scan cells with a high correlation must be found and placed adjacent to each other to reduce the switching activities. The proposed method applies this approach using a novel scan correlation clustering algorithm. The technique merges high-correlation scan cells while gradually clustering them using the correlation information between the scan cells. The correlation information is obtained from the test patterns, which accurately indicate the switching activities between the scan cells. Consequently, the proposed method can reduce the shift power.
4.2. Overall Flow
The goal of the proposed method reduces the test-power consumption during scan testing in cryptographic circuits and improve the reliability of cryptographic circuits to guarantee their quality in the manufacturing test. To do this, the proposed method based on the scan chain reordering is performed because of its ability to achieve high power reduction with a simple architecture and can apply to the design circuits with the scan architecture. Therefore, through the proposed method, the scan cells with high correlation are located adjacent to each other to obtain a significant power reduction effect, and, at the same time, reduces the burden on the design because additional hardware is not required.
To perform the proposed method, the test patterns are required as input data, and these test patterns can be easily obtained by using EDA tools. First, the tools synthesize the benchmark circuits and insert scan architectures. Next, the test patterns are obtained after running the ATPG to detect the targeted faults and contain a binary value for each scan cell during the scan-in and -out operations. The input vector is used during the scan-in operation while the response vector is used during the scan-out operation. The switching operation is caused by a logic difference between the adjacent scan cells during the scan-in and -out operations. Therefore, the analysis of the input and response vector reveals each scan cell’s switching behavior during the scan-in and -out operations. The opposite phases between the adjacent scan cells cause switching activities during scan testing; hence, scan cells with a similar phase must be grouped. This grouping information can be obtained by using the correlation distribution between all scan cells. When reordering scan cells based on the correlation distribution, the switching activities will be reduced.
The proposed idea is to group scan cells of high similarity by analyzing the test patterns and place the scan cells adjacently when stitched into scan chains. The proposed method consists of three steps, as shown in
Figure 4. First, the distance matrix of the scan cells is constructed by calculating the pairwise distance of the scan cells using the test patterns. Second, scan correlation clustering is performed using the distance matrix, and the resultant dendrogram tree is obtained. Third, the scan chain is stitched in the order of the first-to-last item of the dendrogram leaves. The scan cells with a high correlation are then stitched sequentially, reducing the total number of scan-shift transitions. After this scan chain reordering, the mean of the adjacent scan correlation distribution is shifted to a high value, and the standard deviation is moved to a low value (depicted experimentally in
Section 5). Additionally, these three steps can be implemented by an automated system such as the EDA tool. The overall flow of the proposed method is explained for each step with an example test pattern.
4.3. Construction of Distance Matrix
If a fault occurs near the scan-in cell, the test stimulus will contain more errors than when a fault occurs near the scan-out cell. Therefore, the failure in the test response would have spread more than in the case where it is close to the scan-out.
Figure 5 illustrates an algorithm for constructing the distance matrix of the scan cells. Both the input and response vectors must be prepared to analyze the correlation between the scan cells during the scan-in and -out operations. The proposed method focuses on reducing shift-power consumption, but the capture power is also critical in digital circuits. Therefore, the 0-filling methodology is applied when generating the test patterns, which is known to reduce the peak capture activity [
33]. However, although 0-filling is used to reduce both capture and shift power, the proposed method can use the test patterns of the various filling methodologies. The objective of this step is to construct the distance matrix between all scan cells, which is required for the scan correlation clustering in Step 2. The distance between the scan cells must be defined before constructing the distance matrix. The test patterns contain a logic value of each scan cell; thus, it is reasonable to define the distance between the scan cells as a normalized Hamming distance. Consider two scan cells,
, which are two randomly chosen flip-flops;
is the normalized hamming distance between the two scan cells and defined as follows:
In Equation (2),
denotes the number of different bits in the test patterns between the
scan cells, and
k denotes the number of patterns. As shown in lines 5 to 10 in
Figure 5, the distance matrix is constructed by calculating
between all the scan cell pair combinations.
The goal of the proposed method is to reduce the total shift transitions; both the input and response vectors’ Hamming distance matrix must be weighted and summed to build the total Hamming distance matrix, as shown in
Figure 5. If shift-out transitions are higher than shift-in transitions, adding more weight to the response_dist_matrix, which includes the correlation information of the scan cells in the response vector, is advantageous for reducing the total number of shift transitions. However, the number of shift transitions cannot be obtained before the proposed method is applied. Therefore, it is required to determine the weight in advance, which correlates with the number of shift transitions. In the proposed method, the relative standard deviation (
RSD), a standard deviation/mean of the adjacent scan correlation distribution, is used to determine the weight. If
RSD is high, that means the number of shift transitions is also high because the correlation of the adjacent scan cells is low and widely distributed. Conversely, if
RSD is low, that means the number of shift transitions is also low because the correlation of the adjacent scan cells is high and narrowly distributed.
The experiments also demonstrate that
RSD of the adjacent scan correlation distribution is proportional to the number of shift transitions shown in
Figure 6 (discussed in more detail in
Section 5). Therefore, to determine the weight of the Hamming distance matrix, the proposed method calculates the input and response vectors’
RSDs of the adjacent scan correlation distribution and uses these values as
input_weight and
output_weight. Consequently, the
RSD of the adjacent scan correlation distribution can be used as a weighting factor. Finally, the total Hamming distance matrix is created and then used in the next step.
Consider the example of reducing the shift-out transitions using the proposed method. The shift-in transitions are not considered in this example, to simplify the explanation. First, a response vector is prepared by performing scan chain stitching with the conventional method, where scan chains are stitched alphabetically, and by running the ATPG with a 0-fill.
Figure 7a illustrates the example response vector, which has seven scan cells and ten vectors.
The total number of shift-out transitions is 111 based on the WTM, and five out of the six distance values of the adjacent scan cells are greater than or equal to 0.5. Second, a scan cell-to-cell distance matrix is created by calculating the Hamming distance between each scan cell pair, as shown in
Figure 7b. For example, the distance between FF0 and FF1 is 0.5 because 5 out of the 10 binary values in the response vector are different. Based on the distance matrix of
Figure 7b, 9 out of the 21 scan cell pairs have distance values less than or equal to 0.4. Therefore, the correlation between the adjacent scan cells can be increased through scan chain reordering by using a scan cell pair with low distance (high correlation).
4.4. Scan Correlation Clustering
Figure 8 illustrates the scan correlation clustering algorithm. In
Figure 8, step 2 begins with each scan cell in a separate cluster. During each procedure, the two most-similar scan cell clusters are joined into a single new scan cell cluster. The intercluster distance must be defined to find the two most-similar scan cell clusters because the cluster pairs with the closest intercluster distance can be considered most similar and should be merged.
The average intercluster distance metric is used to evenly consider all the scan cells in a cluster and defined as follows:
Equation (3), which is used in the second step of
Figure 8, adds all the distances of the scan cell pairs between the clusters and divides by the number of scan cell pairs. The previously obtained
that represents the Hamming distance between
and
is used to calculate the distance between the scan cell pairs. After selecting and merging pairs of clusters with the minimum distance, the distance matrix must be updated for a new cluster. Moreover, the cluster pairs are never separated once they are combined in each clustering step. This procedure iterates until only one cluster is left. The total number of iterations performing the scan correlation clustering is the total number of scan cells minus 1 because two small clusters are merged at a time. Finally, the dendrogram tree can be obtained. The dendrogram tree represents the successive agglomerations, starting from one scan cell per cluster until all scan cells belong to one cluster. The leaves at the bottom correspond to a scan cell and are used to decide in which order to stitch. The
y-axis of the dendrogram tree denotes the distance of the scan cell cluster pairs, where a larger value indicates a higher level of dissimilarity.
Figure 9a–f illustrates the simple example of a dendrogram tree of the scan correlation clustering process for each step. It begins with each scan cell being assigned to its own cluster. The clustering is performed six times because the clustering process proceeds by repeatedly combining the two small clusters, with a total of seven scan cells. The red line represents two clusters merged at each step. The cluster pair with the shortest distance is found from the distance matrix obtained from the previous step.
The distance of cluster FF1–FF3 is the shortest at 0.1; hence, the FF1–FF3 cluster is merged into one cluster, as shown in
Figure 9a. The distance matrix is then updated by recalculating the distance between the FF1–FF3 cluster and the other clusters. In the next step (
Figure 9b), FF1–FF3–FF6 becomes one cluster because the distance of the FF1–FF3 and FF6 clusters is shortest at 0.15. This process is iteratively performed until the last all-inclusive cluster remains, resulting in the rightmost dendrogram tree, as shown in
Figure 9f. The scan cell list (FF1, FF3, FF6, FF4, FF0, FF2, FF5), which corresponds to the leaves of the dendrogram tree, is then obtained.
4.5. Scan Cluster Reordering
The scan cluster reordering is a final step of the proposed method and determines the order of scan cells. Based on the dendrogram leaves in
Figure 9f, the high-correlation scan cells are placed adjacent to each other after the scan correlation clustering. Therefore, the correlation between the adjacent scan cells can be assumed to increase if scan chain stitching is performed in one direction of the leaves. In Step 3, scan chain stitching is performed in the order of the first-to-last item of the dendrogram leaves for low test power. Consider the example response vector after applying the proposed method in
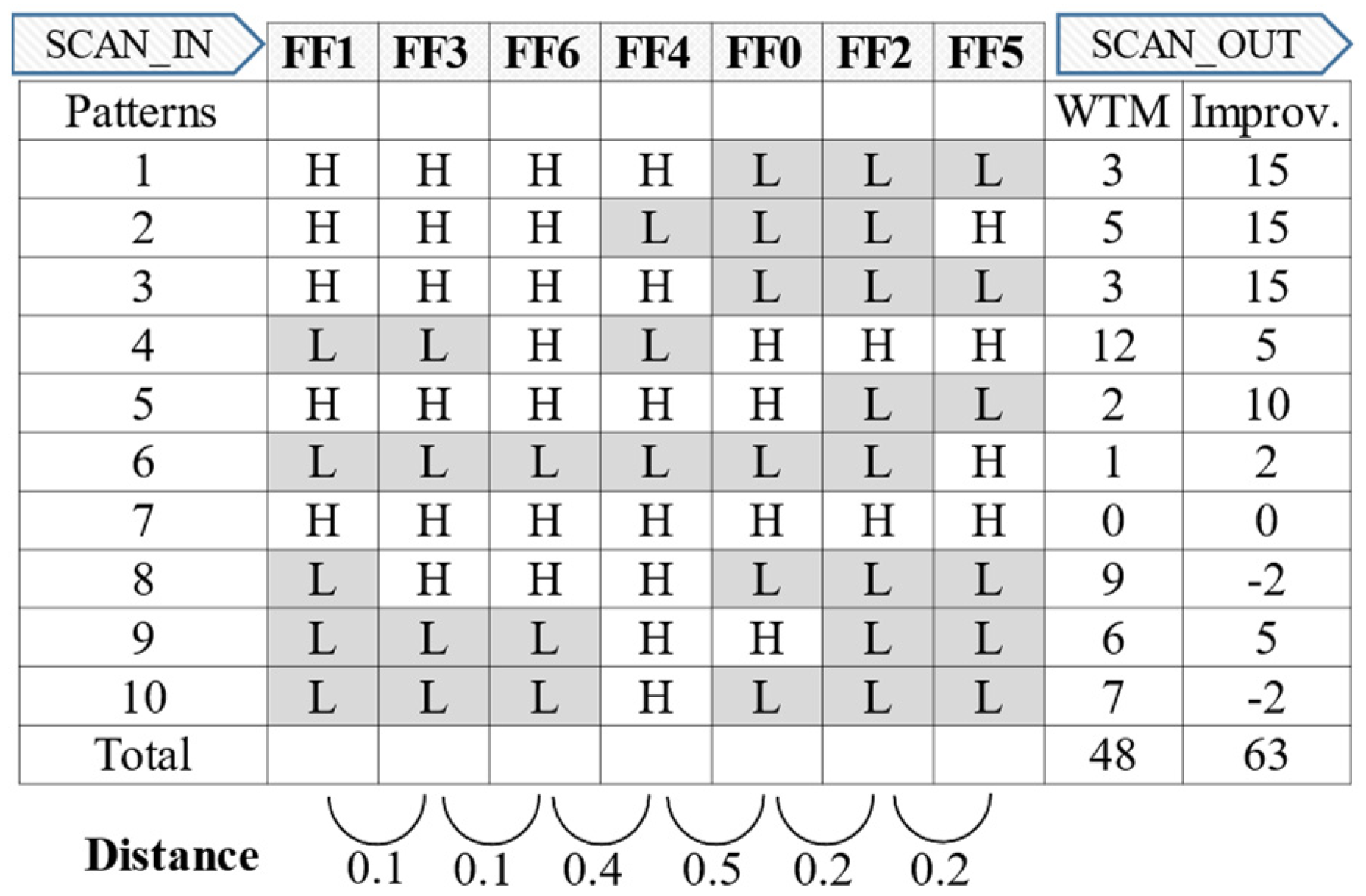
Figure 10. The distance between the adjacent scan cells is less than or equal to 0.5, which is much improved compared with the conventional scan chain stitching in
Figure 7a. When considering the FF4 and FF5 scan cell pair, the distance between those scan cells is 0.9; moreover, they were adjacent before the scan chain reordering, which indicates heavy switching behavior. However, they are relocated to be adjacent to the other scan cell with a similar phase after applying the proposed method. Consequently, the total number of shift-out transitions are reduced from 111 to 48, a 57% reduction when compared with the conventional stitching method.
The proposed method can achieve a significant power reduction effect during the scan testing by reordering the highly correlated scan cells to be adjacent. However, when changing the order of scan cells significantly, the routing length increases compared with that of the conventional stitching method based on the physical design—resulting in performance overhead (e.g., latency). Therefore, it is important to decrease the routing length when the proposed method is applied. In the conventional DFT setup, the placement-aware stitching is generally used to reduce the total routing length. The scan partitioning also is performed to relieve the routing overhead between the scan cells, limiting the range of the scan chain stitching by grouping the near scan cells. In the proposed method, this scan partitioning information is used to minimize the routing length. First, the place-aware stitching and scan partitioning are performed by considering the physical layout similar to the conventional DFT setup, and the information of the scan partitions was extracted. The proposed method limits the range of the scan chain reordering to only the scan cells within the scan partitions where each scan partition has a single scan chain. The proposed method can apply the scan chain reordering within each scan partition since the distance matrix can be calculated according to the scan length in a scan chain.
4.6. Test Compression Mode
The proposed method only changes the order of scan cells to minimize test-power consumption and can be scalable to the design methodologies related to the scan architecture. Recently, a test compression is widely used to compress the test data, and it is important to manage the test compression architecture. For the designs including the test compression architecture, the proposed method of managing test compression follows. First, the conventional test compression in alphabetical order is performed on the target design, and the original test patterns are generated using the conventional test compression. By using these test patterns, the distance matrices are created to obtain correlation distribution between the scan cells. In addition, to maintain the number of scan chains, the proposed method creates the distance matrices to be as many as the number of scan chains. Next, hierarchical agglomerative clustering (HAC) technology is performed for the distance matrices and the dendrogram trees are obtained. Finally, the order lists of the scan cells for the low-power testing are obtained through the dendrogram trees, and the new test compression is performed by reordering the scan cells. At this time, not only the order of the scan cells is changed, but also the test compression architecture (i.e., de-compressor and compressor logic) is re-created according to the order of scan cells to be changed. In addition, the new test patterns are generated due to the change of the test compression architecture.
6. Conclusions
In this paper, a novel scan correlation-aware scan cluster reordering method is proposed for low test power in cryptographic circuits for wireless sensor networks. The novelty of the proposed method is that it performs scan correlation clustering to place high-correlation scan cells adjacent to each other. The algorithm for the proposed method includes three steps. First, a pairwise distance matrix between scan cells is constructed using test patterns. Second, scan correlation clustering is performed using the distance matrix, and a dendrogram tree is obtained as a clustering result. Third, scan chain reordering is performed by traversing the leaves of the dendrogram tree. The proposed method is expected to achieve, on average, an approximate 70% reduction in test power compared with the conventional method, reduce power consumption by 28.31%, and reduce computational time by 91.72%, for all experimental benchmark circuits compared with the previous methods. Consequently, through significant power reduction effect, the proposed method can improve the reliability of cryptography circuits and ensure the security and integrity of information in WSNs.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}