Abstract
Uncertainty in dense heterogeneous IoT sensor networks can be decreased by applying reputation-inspired algorithms, such as the EWMA (Exponentially Weighted Moving Average) algorithm, which is widely used in social networks. Despite its popularity, the eventual convergence of this algorithm for the purpose of IoT networks has not been widely studied, and results of simulations are often taken in lieu of the more rigorous proof. Therefore the question remains, whether under stable conditions, in realistic situations found in IoT networks, this algorithm indeed converges. This paper demonstrates proof of the eventual convergence of the EWMA algorithm. The proof consists of two steps: it models the sensor network as the UOG (Uniform Opinion Graph) that enables the analytical approach to the problem, and then offers the mathematical proof of eventual convergence, using formalizations identified in the previous step. The paper demonstrates that the EWMA algorithm converges under all realistic conditions.
1. Introduction
Let us consider a dense Internet of Things network, consisting mostly of inexpensive sensors that collectively measure a certain physical phenomenon. By design, this network may comprise some high-quality nodes (characterized, among others, by the low level of uncertainty) as well as a number of nodes of high or unknown uncertainty. In order to improve the overall quality of its measurement, the network may want to learn about the quality of its nodes to decrease the impact of the low-quality ones. In the absence of external reference sources, the network must rely on opinions randomly issued by one node about the other to be converted into a reputation of those nodes. Note that the notion of quality applies equally well to nodes that provide incorrect readings due to the use of low-quality sensors and nodes that provide such readings due to their failure or the failure of their communication links. This makes this approach potentially attractive to IoT networks that use wireless communication.
One of the popular algorithms to perform such conversion is the EWMA one (Exponentially Weighted Moving Average), which is widely used, e.g., in social networks. The algorithm tends to perform well under simulated conditions, but, to the author’s knowledge, there is no proof that it eventually converges, i.e., that the algorithm eventually delivers the stable value (or, e.g., asymptotically approaching the stable value) of the reputation of the node, provided that the network itself is in a stable situation. Undesired behavior of the algorithm may include oscillations (where a stable value is only momentarily achieved), or false assessment (where the algorithm gradually diverges from the assessment), or the failure to provide the assessment (where the outcome of the algorithm becomes unrealistic).
The key contribution of this paper is proof of the eventual convergence of the EWMA algorithm, as applied to IoT sensor networks. The proof is also applicable to other uses of the EWMA, e.g., in social networks, provided that similar conditions are met. The approach presented here can also be applicable in related areas where the EWMA or its derivatives are used, e.g., in combating fake news.
The proof presented here consists of two steps. In the first step, the formal model of the sensor network is introduced. The model, described here as the UOG (Uniform Opinion Graph), enables the analytical approach to the problem of convergence, thus allowing for a deeper analysis than the usual simulation. The UOG also enables the second step of the proof, where the mathematical proof of eventual convergence is provided. The paper demonstrates that the EWMA algorithm converges under all realistic conditions.
This paper starts with a brief literature review that introduces the subject of research. The formalization of the EWMA algorithm, as used in IoT sensor networks, follows. Then the UOG is introduced, and its use is justified to demonstrate that the UOG is a suitable representation of the EWMA for random graphs. The preliminary analysis of the convergence of the EWMA for the UOG is then conducted. From there, the mathematical proof follows. Conclusions close the paper.
2. Literature Review
This literature review is structured as follows. First, it provides certain background into the use of reputation in IoT sensor networks, with a special focus on the use of the EWMA algorithm. Next, it discusses papers that are directly relevant to the convergence of the formula derived from the EWMA algorithm.
The use of reputation and trust has its sources in social networks [1]. However, once networks are designed so that nodes can provide opinions about other nodes, the same concept, as well as the associated algorithms, can also be applied to IoT sensor networks (see the work of [2] for the distinction between sensor networks and IoT sensor networks). Such types of networks increasingly gain popularity, e.g., in sensing air pollution [3]. For a more general overview of technology and applications, see, e.g., the work of [4] or [5]. Considering existing literature, currently, the important focus seems to be the identification of faulty or malicious nodes (e.g., using reputation scoring [6]), i.e., nodes that unintentionally or intentionally deliver incorrect readings. This calls for some form of trust management that allows for identifying and acting on nodes deemed untrustworthy [7]. Various proposed trust models (i.e., reputation-scoring algorithms) are applied to IoT networks. For example, the work of [8] lists no less than 80 algorithms in use. Those algorithms employ various paradigms, be it various versions of averaging, fuzzy logic [9], or neural networks [10].
When it comes to reputation, algorithms that employ averaging, specifically the EWMA one, are among the most popular ones. They demonstrate their robustness while dealing with opinions provided by humans [11]. They have also been used widely to calculate the reputation of automated services [12], as well as in other applications, e.g., to monitor changes in the mean value of the process [13] and in forecasting [14], to name but a few areas. In [15], the applicability of EWMA to the calculation of reputation in dense sensor networks was demonstrated to decrease the uncertainty of data produced by such networks. Note that the EWMA algorithm exists in many variants, namely SMA (Simple Moving Average), EWMA, PEWMA (Probabilistic EWMA) [16], AEWMA (Adaptative EWMA) [17], etc. It is also worth noting that the EWMA algorithm discussed here is similar yet differs in its application in comparison with EWMA smoothing [18], the latter being the variant of exponential smoothing.
The performance, including the convergence of such an algorithm, is a going concern. However, the primary interest seems to be the optimization of the parameters of the algorithm, specifically at its initial phase, where, e.g., the maximum entropy principle can be applied [19]. Regarding the convergence of EWMA, it is assumed and accepted that the algorithm delivers eventual convergence when used in control or data smoothing applications, i.e., in situations where the outcome of the algorithm does not directly affect its input. In such situations, the noise seems to be the primary concern, and the potential for the convergence despite the noise was analyzed, e.g., in the work of [20], using the Markov Chain.
EWMA is equally popular in social networks and in other applications that collate opinions into reputation [21]. This application may be different, as the reputation-scoring algorithms tend to have the inner feedback loop where the nodes of higher reputation are able to affect the scoring of other nodes. Further, the operation of the algorithm over the random graph of opinions differs from its operation in control or data smoothing. Despite its popular use, the authors were unable to find any proof of the eventual convergence of the EWMA algorithm used for the assessment of reputation in sensor (or social) networks, i.e., the proof that under stable conditions, the algorithm eventually converges to the stable assessment of the situation. Instead, simulations under various, often variable conditions, as well as the use of real data sets, are widely used, using available toolkits [22].
This paper proposes that the convergence of the EWMA algorithm in random graphs can be analyzed as a special case of the convergence of linear fractional transformations (homographic functions). The convergence of such functions is known to strongly depend on their parameters. The problem of convergence has been studied from mathematical perspectives in a way that is not always completely relevant to the problem at hand. Differences tend to focus on the range of parameters that are covered by the literature.
Hillam and Thorn [23] demonstrated the convergence of homographic functions over complex support. However, the range of parameters that have been studied does not satisfy the use case presented in this paper, thus limiting the use of the proof demonstrated in the work of [23] only to special cases of only some practical uses.
Mandell and Magnus [24] provide an interesting classification of homographic functions (over the complex support) depending on the properties of their normalized matrices. Four types of functions are analyzed: parabolic, elliptic, hyperbolic, and loxodromic, and conditions for their convergence are identified. The proof demonstrated in this paper significantly improves on the work of [24], as it not only demonstrates convergence but also demonstrates convergence within the range specified by parameters, thus assuring that the result of such convergence always satisfies the use case.
Note, however, that the results presented in the work of [24] do not contradict the results presented here. For particular combinations of parameters and for some stages of the proof, they lead to the same results.
3. The EWMA Algorithm in IoT Networks
The use of the EWMA algorithm to decrease the uncertainty in IoT sensor networks has been introduced in the work of [15]. It is characteristic for the IoT networks, in contrast with professional measurement networks, that they may contain sensors of varied quality and that the maintenance protocols, as well as communication protocols, may not be up to high standards. Consequently, measurement results obtained from such networks tend to bear higher uncertainty, so that the ability to contain this uncertainty is important.
Reference nodes (i.e., nodes of assured high quality) are often used to contain the growth of uncertainty by acting two ways: to provide the set of quality readings and also to judge other nodes and eliminating those that seem to be faulty. However, those solutions are both expensive in operation and sensitive to the failure of one of the reference nodes.
The approach proposed in the work of [15] disposes of the need for reference nodes, but it requires nodes to be over-provisioned. Considering that the cost of the lower-quality node can be significantly lower than the cost of the reference node, such a trade-off can be quite attractive. This approach is based on the ability to tell sensors of low uncertainty from those of high uncertainty, so the high uncertainty of some of them does not overly taint the measurements performed by the network. As the network is autonomous, it cannot use external sources or reference nodes to perform the assessment of nodes to learn about their uncertainty. Instead, it must rely on opinions issued by nodes within the network about each other.
Those opinions are issued by nodes on the basis of their assessment of whether other nodes perform as expected. As the node can issue the opinion only based on its own performance, high-quality nodes tend to issue correct opinions while low-quality nodes tend to issue incorrect ones. What the opinions contain is traditionally called the level of trust, by analogy to subjective trust [1] used in social networks.
The network can employ the algorithm that computes those opinions into the reputation of each node, where the weight of opinion of the node depends on its current reputation at the time the opinion has been issued. That is, the higher the reputation of the node, the more influential its opinion is. One of the formalizations of this algorithm is known as the EWMA, and this is the one analyzed here. This formalization combines weighted averaging of opinions with their decay so that older opinions weigh less toward the current reputation. This formalization, as used through this paper, can be expressed as
where:
- reputation of the sensor a at the moment τ
- n number of opinions about a that are known to the algorithm and that were provided before or at the time τ
- level of trust that the sensor , providing the i-th opinion, had in sensor a at the time the opinion has been provided, τi.
- confidence in the i-th opinion, being the confidence in the sensor b that provided this opinion, calculated for the time the opinion has been provided, . This confidence is calculated as where:
- self-confidence of the sensor b that provided the i-th opinion in its own judgment at the time the opinion has been issued (i.e., ); this self-confidence is used when calculations made by the sensor include elements of doubt.
- reputation of the sensor b that provided the i-th opinion at the time the opinions has been issued,
- the decay function that decreases the influence of opinions that are less current; the function takes as its parameters the time moment when the calculation was performed and time moment when the i-th opinion was issued; for EWMA, the exponential decay function is used so that where is the decay constant.
There are few families of algorithms that can be used to establish what, in fact, is a reputation of the node, out of opinions about such a node, coming from unreliable peers [12]. The EWMA algorithm is a prominent example of the deterministic approach, where the resulting reputation bears no uncertainty. Alternatively, the Bayesian approach can be used (e.g., the work of [25]) so that the reputation of the node can bear its own measure of uncertainty. Fuzzy systems are also used to better reflect the human perception of reputation (e.g., the work of [26]). Machine learning (where examples of various quality are presented to the algorithm) is used as well [27], but usually in the context of determining malicious nodes, not just low-quality ones.
The EWMA is one of the simplest deterministic algorithms, where only direct (first-level) opinions are considered, i.e., opinions resulting from the direct observation of one node by others or from observing the same phenomenon. More complex algorithms may take into account also second- and third-level opinions, i.e., opinions about opinions provided by nodes. The choice of this was dictated by the desire to avoid the second-order considerations about the uncertainty (i.e., the uncertainty introduced by the algorithm itself), while neither the similarity to human reasoning nor the ability to learn from examples was particularly important.
Further, as the research interest was in demonstrating eventual convergence, the EWMA algorithm forms the natural starting point, being both less complicated and better understood than other algorithms.
The decrease in uncertainty provided by the use of the EWMA algorithm is contingent on the IoT network being reasonably “dense”, i.e., on situations where the neighbors of the given node can-at least from time to time-provide opinions about the given node. The underlying assumption is that the network is over-provisioned, i.e., that there are significantly more sensors in the network than would have been normally used. This concept is explained in detail in the work of [15]. It is worth mentioning that examples provided throughout this paper tend to use the over-provisioning of about four, thus assuming a grid-like structure of sensors. Such a level of over-provisioning can be reasonably achieved in networks that measure physical phenomena such as air pollution. Additional costs can be compensated by using lower-quality sensors.
Note that the research presented in this paper demonstrates that the convergence itself is not contingent on any particular level of over-provisioning, but the speed of such convergence is. The convergence is only contingent on opinions being provided, i.e., on the ability of one node to assess the other node.
Modern implementations of IoT networks may rely on wireless multi-hop communication (e.g., mesh networks [28]) to deliver the readings from the sensors to the central processing platform. Such networks may employ their own routing algorithms to optimize their operation and to eliminate misbehaving nodes, e.g., trust-based routing, using their own algorithms. The EWMA algorithm described here neither suffer from nor leverage such solutions. It assumes that the underlying communication network eventually delivers results but requires neither timeliness nor reliability. It is generally immune to delays and incidental omissions, including the disappearance and re-appearance of nodes. Further, it is intended to be implemented at the central processing platform so that it does not increase the workload on the network or on the nodes themselves.
Note that this paper assumes that all the nodes are benevolent. This paper does not study the convergence under adversary attacks where, e.g., malicious nodes are added to the network or benevolent ones became malicious.
4. The Uniform Opinion Graph (UOG)
The realistic model of the IoT sensor network is a random graph, with nodes representing sensors and edges representing opinions. While nodes remain unchanged, edges are created and disappear randomly in time, as new opinions are created, and old ones are discarded.
The interest of this paper focuses on a directed random graph with a specific average density. Such a graph is a variant of the Erdos-Renyi or Gilbert graphs. It is known that the probability distribution of the degree of the node follows the binomial distribution and reaches its maximum for the degree being equal to twice the average density, evenly split between inbound and outbound edges. If there is a fixed proportion of nodes of specific colors (types), this proportion is also reflected in the distribution of inbound and outbound edges.
The number and the distribution of antecedents are of interest in this paper. For example, using simulated results (see Figure 1.) for random graphs of 20 nodes that have only two types of nodes: 12 nodes of type 1 and 8 nodes of type 2, with the average density of 5, the dominant configuration of a node is that the node has five antecedents of which three are of type 1, and two are of type 2.
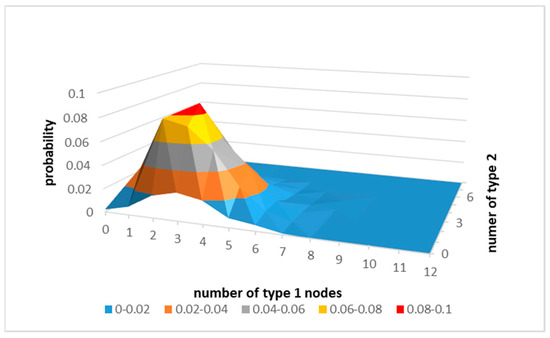
Figure 1.
The simulated probability density distribution of antecedents of the node as a function of the number of “type 1” and “type 2” nodes in random graphs.
Therefore, for the purpose of the analysis presented here, the simple model of a random graph is used that assumes that every node of the graph has exactly the same configuration that follows the dominant one. This model is called the UOG (Uniform Opinion Graph).
- Taking this model further, one can assume that there is a limited set of types of nodes (called further “roles”), each type representing a node of a certain quality. Assuming the uniform and fixed distribution of opinions within the UOG, it is enough to analyze only as many nodes that there are roles, each node being a faithful representative of all nodes with the same role. Further simplifications lead to the UOG graph, whose properties are suitable for mathematical analysis;
- There are only two roles: trustworthy nodes and faulty ones. Trustworthy nodes are of high quality, and faulty nodes are of low quality. Note that the phrase “faulty” does not imply that they failed in any way but that their quality is significantly inferior to those considered trustworthy;
- The complete UOG is defined by three parameters: p-number of trustworthy nodes that provide an opinion about the given one; q-number of faulty nodes that provide an opinion, and a multiplier that allows constructing graphs of different sizes;
- Roles of nodes are fixed; there are p · multiplier trustworthy nodes and q · multiplier faulty ones; neither those roles nor their allocation to nodes change, allowing for stable conditions;
- The graph density is fixed to ; each node receives opinions exactly from p trustworthy and q faulty nodes;
- Opinions can carry only one of two values: t or f; those values represent the value . from the same Equation (1). The value t is reported by a node about the node of the same role (i.e., trustworthy about trustworthy, faulty about faulty); f is reported otherwise;
- Self-confidence of any node is set to 1, i.e., from Equation (1); ;
- Initial reputation of the node is the same for all nodes, set mid-point between t and f;
- The analysis is performed in steps, identified by the index i, where i identifies the current assessment, i − 1 the previous one, and so on;
- In each step, the analysis calculates the new reputation for the representative trustworthy node (value x) and for the representative faulty node (value y).
Figure 2 shows two fragments of the UOG, where and . On the left side, nodes A, B, and C provide opinions about the trustworthy node X. On the right side, nodes P, Q, and R provide opinions about the faulty node Y. In both cases, all the nodes also provide opinions to other nodes and are assessed by other nodes, but those opinions are not shown.
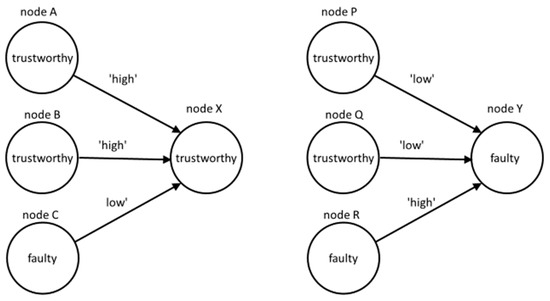
Figure 2.
Example of two types of node configurations in the UOG.
It is characteristic to this UOG that only those two configurations are possible: either the node is trustworthy, or it is faulty, and its role fully determines its behavior. This observation, together with some simplifications already introduced into the UOG, allows for simplifications in the description of the behavior of the reputation of its nodes.
- There are only two types of nodes, and they always receive the same amount of opinions from nodes of known types at regular intervals. Therefore, if the reputation of nodes at step i is known, it is possible to calculate the reputation of nodes at step i + 1 by calculating the reputation of one representative node from each type;
- Opinions depend solely on the type of nodes that provide and receive those opinions, so that trust expressed by those opinions can be determined in advance and is identical for every step;
- As the situation does not change between iterations, long-term decay can be incorporated into levels of trust that nodes report in opinions.
As a result of those simplifications, the original Equation (1), as applied to the UOG, becomes a set of two equations: one applicable for the iterative assessment of the reputation of trustworthy nodes and another for faulty ones.
where
- reputation of a representative “trustworthy” node at the i-th iteration, which is also the reputation of every trustworthy node in the graph
- reputation of a representative faulty node at the i-th iteration, which is also the reputation of every faulty node in the graph
- the number of trustworthy nodes that provide opinions about the node
- the number of faulty nodes that provide opinions about the node
- the level of trust that is reported either by the trustworthy node about another trustworthy node or by the faulty node about another faulty node
- the level of trust that is reported either by the trustworthy node about the faulty node or by the faulty node about the trustworthy one.
Note that there are additional limitations on the values that variables can assume that come from the coding convention used throughout the literature [29], as well as from the application area. Therefore:
- . As the equation describes the graph, there is the requirement that this graph contains at least one node. For empty graphs or for graphs without any edge, the convergence is not assured, yet those graphs hardly represent any useful IoT network;
- . There is a choice of coding conventions for expressing the level of trust. The one chosen here assumes that the level of trust is represented by the real number between 0 and 1 and that “trustworthy” is coded as the value higher than “faulty”. For other conventions, convergence has not been studied;
- Eventually, . The outcome of the calculation should be the reputation of the node, and the coding of such reputation should follow the same limitations as the coding of trust.
5. The Analysis of Convergence in the UOG
The simplification provided by the UOG allowed for the calculation of the convergence of the EWMA algorithm. Figure 3. shows subsequent values of and for the first 15 iterations of the algorithm defined by Equation (2), where parameters are , , and , with the decay constant λ set to 0.7. Both functions seem to converge on values that do not seem to be far off from the values of t and f, respectively.
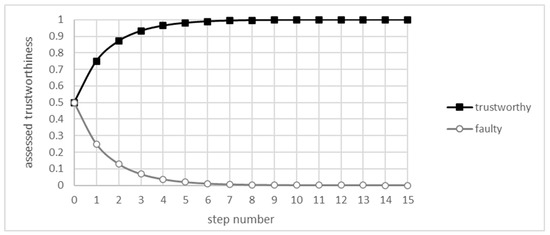
Figure 3.
First steps of the algorithm for the UOG.
The overall shape is very similar to the one presented in simulations provided in the work of [15], except for the lack of fluctuations, as there is no randomness in this analysis. Comparing with simulations using the same set of parameters, the difference between simulated and calculated results rapidly diminishes. The loss function, e.g., the MSE (Mean Squared Error), rapidly decreases, as shown in Figure 4.
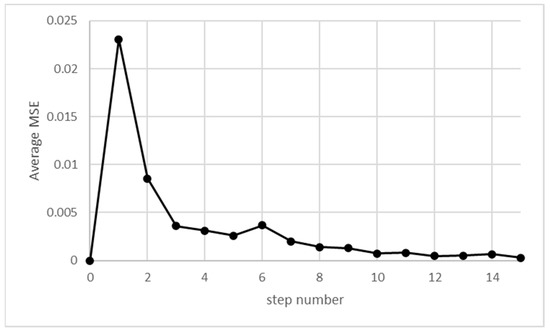
Figure 4.
MSE between simulated and analytical results as a function of simulation steps.
While the comparison of analytical data with simulation can provide only limited assurance, this comparison demonstrates that, indeed, the UOG can serve as a suitable model of what occurs in the random graph when the EWMA algorithm is used.
Note that while there is a visible convergence in the assessment of both trustworthy and faulty nodes, they do not converge at t and f, respectively. Actual values (x*, y*) that the analytical formula derived from the UOG converges to can be determined by solving the set of Equation (3).
where
- x* the convergence value for the reputation of the representative trustworthy (“good”) node, which is also the convergence value of every trustworthy node in the UOG;
- y* the convergence value for the reputation of the representative faulty (bad) node, which is also the convergence value of every faulty node in the UOG.
6. The Proof of Convergence
This section demonstrates that for a non-trivial, realistic set of parameters, the set of functions (2) is convergent to its fixed point. The value of this fixed point is determined by the function’s parameters, but it always lies within their useful range. For reference, those ranges were defined as , and . They refer to the real-life limitations already described earlier in this paper.
Referring back to the model, “trivial” cases are those that effectively preclude the use of the algorithm in the first place because of the lack of differentiation. These are the cases where either there is no differentiation between nodes (all are of the same type) or where there is no differentiation between opinions about nodes (i.e., both t and f are zero). Otherwise, the ability to converge for all non-trivial cases depends only on the choice of t and f, both being a coding convention only. In practice, t is assumed to be greater than f; e.g., throughout most of this paper, it was usually assumed that and .
The proof defines the interval
where
- M the interval within which the function converges so that all subsequent values of xi and yi belong to this interval;
- max{}, min{} maximum and minimum functions over the set of parameters.
It demonstrates that for and , the sequence starting from any is convergent to a single fixed point in . For (and ), the sequence oscillates around a single fixed point and is convergent only when it is constant and starts exactly from that fixed point. For (and ) and the sequence is always convergent to one end of the interval (attractive fixed point), while the other end is also a fixed point, but only reachable by the constant sequence starting exactly from this point (repulsive fixed point). For (and ) and every point of the interval is a fixed point and every sequence starting from any is always constant and converges to this point. For all cases, if the starting point lies outside the interval (but is greater than zero), the first iteration, , will fall into the interval . Identical conclusions also apply to the sequence .
The proof starts with the reformulation of the problem, moving it from analyzing a set of two iterative functions into one iterative function (Section 6.1). Section 6.2, after dealing with trivial cases and potential truncation, demonstrates that the function has a support over the range . The monotonicity of the function is then demonstrated, together with its two fixed points. It is demonstrated that only one of them lies within M and that it is the point to which the function converges (for and ). The remaining part of the proof (Section 6.3 onwards) demonstrates the convergence by demonstrating that values returned by the function from its subsequent iterations form a Cauchy sequence in a complete metric space .
6.1. The Formulation of the Problem
The starting point of the proof is Equation (2), which contains a pair of iterative functions and representing the reputation of a trustworthy (high-quality) and a faulty (low-quality) node, respectively. Those functions have four parameters: p, q, t, and f, described earlier in this paper. The parameters meet the following conditions: , , and (there is at least one node), and . Additionally, we assume that .
This pair of functions is a special case of a pair of linear fractional transformations that belong to the family of homographic functions. The behavior of this class of functions is known to strongly depend on the actual values of parameters. Therefore, the proof will concentrate on the behavior of those functions with respect to the values of their parameters.
Conversion. Note that for . This means that it is enough to analyze the one-dimensional sequence that starts at x0, defined as
Truncation. Note, that for . However, this does not always apply to . This irregularity is limited only to as always satisfy the equation. It has been already mentioned, as an observation, earlier in this paper. It is, therefore, enough to disregard the first element of a sequence without losing the generality.
Trivial cases. Let us consider the following trivial cases (for , for any ):
In all these cases, the sequences and are constant from onwards and converge to and , respectively. Therefore, in further considerations, these cases can be excluded.
Support over the range. It is possible now to determine that the sequence operates over a certain range in ℜ. It has been already assumed that and , and , but they cannot be zero at the same time (i.e., ). These conditions lead to the following inequalities: & .
Expressions in both inequalities are nominators and denominators of (2), respectively. This means that & .
By replacing in the second inequality with the expression of , an additional condition can be obtained .
This leads to the following bracketing condition that must be satisfied by every for :
where
- m− lower bracket (i.e., the minimum bracketing value) for any ;
- m+ upper bracket (i.e., the maximum bracketing value) for any .
With the truncation in mind, it is convenient to assume that as well. To simplify further the analysis, this paper will use the symbol to denote the interval .
6.2. The Introduction of the Function
Note that for the equation that defines the sequence determines the function 𝑔 defined as follows. This is the function that captures the iterative calculation of xi and yi from their previous values, but without cross-referencing, so that xi+1 depends only on xi while yi+1 depends only on yi
For the function 𝑔 becomes linear (as it was assumed that ):
Now the series can be expressed as .
6.2.1. Support over M
It was already established that it is enough to consider the interval and a function with a support restricted to this interval. If , then the zero of the 𝑔’s denominator . If , then the zero of the 𝑔’s denominator because . For there is no risk of zero in the denominator (if only ). Therefore, zero of the 𝑔’s denominator is never inside the interval and we can consider the function 𝑔 in this interval without further considering its denominator equal to zero. Therefore, .
6.2.2. Monotonicity
For p ≠ q, the function 𝑔 is a homographic transformation continuous in the interval M. Therefore, the function 𝑔 and its first and second derivatives 𝑔′ and 𝑔″ can be defined as follows:
are strictly monotone in the domain . Hence, extreme values (maximum and minimum) of both derivatives are reached at the ends of the interval : for and .
Further, if then 𝑔 is linear, and its first derivative is constant, so its second derivative is equal to zero
6.2.3. Fixed Points
Fixed points of the equation that are in are as follows. For and there is one fixed point as a solution of a linear equation . For and , the function 𝑔 is an identity function , and the whole interval becomes a set of fixed points. For there can be no more than two fixed points on the real numbers axis because the function 𝑔 is a homographic transformation. Solving the equation , i.e.,
leads to the formula:
It remains to be demonstrated that for a minus sign before the square root, the fixed point , assuming ; for a plus sign .
Note that throughout the rest of the text, fixed points will be denoted as follows:
- the fixed point calculated by using the plus sign in the above equation,
- the fixed point calculated by using the minus sign in the above equation,
- the pair of and .
6.2.4. for f = 0
For the fixed points of function 𝑔 are equal to:
and they are the ends of the interval M, which is equal to [0, t] when f = 0: for p > q or for p < q.
6.2.5. for f > 0
To demonstrate that ∉ M for f > 0, let us assume the opposite: ∉ M. Then and . Consider the product: .
We introduce ξ as . We estimate the expression described by a square root . Hence for p > q: and for p < q (p = q does not apply to this case): .
So the product of , ξ < 0, if only f > 0, but a product of two non-negative numbers cannot be negative. It means that for f > 0, there must be ∉ M.
6.2.6. for f > 0
Let us show that ∉ M for f > 0 (for f = 0 we have just shown it). It means that we should prove: .
We will prove in turn that (1) , and (2) , and (3) and finally (4) . We will prove each of these inequalities for two cases: p > q and p < q (bearing in mind that the case p = q has been considered separately, and now it can be omitted).
Lemma 1.
. For p > q, we obtain estimates (notice that then):
For p < q, we obtain estimates (notice that then):
Therefore.
Lemma 2.
.
This lemma will be considered in two steps: for p > q; t + f > 1; and for p < q; t + f > 1. Let us notice first that the proof is necessary only for t + f > 1; as for the opposite, Lemma 1 applies. For the case of p > q and t + f > 1, it is possible to write (because all subtractions provide non-negative results):
so that
Because , square root can be applied to both sides of the last inequality:
so that
therefore,
For the case of p < q (and t + f > 1) it is possible to write (because only p − q < 0 and all other subtractions provide non-negative results):
so that
Because and (p − q)(t – 2) + 2pf = (q − p)(2 − t) + 2pf ≥ 0 square root can be applied to both sides of the last inequality
so that
hence,
Lemma 1 and Lemma 2 demonstrate that . Now it remains to show that . It is performed in two steps: Lemma 3 and Lemma 4.
Lemma 3.
.
For p > q, , so that:
For p < q, in a similar way, , so that:
Lemma 4.
.
It has been shown that , so to show that it is enough to consider t + f > 1. Note that for p > q and t + f > 1, we can write (because all subtractions provide non-negative results):
For p < q and t + f > 1, we can write (because only p – q < 0 and all other subtractions provide non-negative results):
Lemmas 1 to 4 demonstrate that so that . Moreover, for f > 0, is the only fixed point of the function 𝑔 in the interval .
6.3. Convergence
Now it is possible to prove that for t ≠ 0 and f ≠ 0, any sequence (xi)i=0…∞ starting with ≥ 0 is convergent to a single fixed point ∈ M, denoted below as x*. Of course, this also implies the convergence of the sequence (yi)i=0…∞ starting with ≥ 0 to y* = t + f − x* ∈ M.
One has to remember that we have assumed that xi ≥ 0 (where i = 0…∞) and p, q > 0, and t, f ∈ [0, 1], but they cannot be zero at the same time (i.e., t + f > 0). Because we demonstrated that ∈ M for any ≥ 0, we can limit our considerations to ∈ M (in a way, we can treat as ).
The proof of convergence applies different methods depending on the ranges of values of parameters. It starts from some simple cases and then demonstrates convergence either by determining that the function is a concave function or by demonstrating that subsequent iterations form a Cauchy sequence.
6.3.1. The Case of and
This case uses the coding that is not typical, with “good” being reported as zero and “bad” as non-zero (effectively as greater than zero). This kind of coding leads to the lack of convergence and should be excluded.
It will be now demonstrated that for t = 0 and f ≠ 0, subsequent values of alternate between two values so that the function does not converge. It will allow excluding this case from further considerations. Note that this case counters the assumption about the rationality of the coding: trustworthiness is here encoded as zero, and fault as a value greater than zero. We have:
Let us calculate :
So for t = 0, the iteration sequence takes the form of ... and is not convergent unless it is constant, i.e., for i = 0…∞. All the subsequent cases assume that .
6.3.2. The Case of and and
This case refers to the situation where the coding scheme has been chosen in a rational way and where the number of “good” nodes is not equal to the number of “bad” ones. Therefore, it is the case that may be considered typical. Note that it is not relevant for the convergence whether there are more “bad” or “good” nodes, even though it may lead to unexpected results.
In order to demonstrate the convergence of 𝑔(x) for f = 0 and t ≠ 0 and p ≠ q, the sequence is introduced. For f = 0 and the sequence , where , it is possible to describe its every element belonging to the interval M = [0, t] as = · t, where ∈ [0, 1].
The corresponding sequence is as follows:
To prove the convergence of the sequence for any ∈ M = [0, t] it is enough to show the convergence of the sequence for any ∈ [0, 1].
The sequence can also be defined without resorting to recursion:
which is easy to prove by mathematical induction.
If = 0 ( = 0) then = 0 for i = 0…∞, which is easy to prove by mathematical induction.
If = 0 ( = 0) then = 0 for i = 0…∞ and both sequences ()i=0…∞ and ()i=0…∞ are constant and converge to 0. If = 1 ( = t) then = 1 for i = 0…∞ and the sequences ()i=0…∞ and ()i=0…∞ are constant and convergent to 1 and t, respectively.
For ∈ (0, 1), two cases should be considered (note the assumption that p ≠ q):
Combining both cases together, we obtain that for p ≠ q and 0 < < t, the sequence (xi)i=0…∞ is always convergent to .
It means that for f = 0 and t ≠ 0 and p ≠ q the sequence (xi)i=0…∞ is always convergent to if ∈ M\{} (i.e., ) or to if (the constant sequence ).
6.3.3. The Case of and and
This is the case of the rational coding scheme, but of the specific network where the number of “good” and “bad” nodes is equal. For reference, the actual simulation (not the UOG) shows that the function randomly “wobbles” around a certain fixed level.
For f = 0 and t ≠ 0 and p = q, the function 𝑔 is an identity function , and a set of fixed points is the whole interval M. This means that any sequence for i = 0…∞ is constant and convergent to .
6.3.4. The Case of and and
This case considers the situation of the network with equal numbers of “good” and “bad” nodes, where the coding is rationally chosen. In a manner similar to the previous case, the actual simulation shows the function “wobbles” around a certain value. For the UOG, this value can be determined from the following analysis.
We have shown previously that for f ≠ 0 and t ≠ 0 and p = q, a fixed point is x* = ∈ M. However, we have not shown how the sequence (xi)i=0…∞ behaves for this case:
This sequence can also be defined not recursively:
which can be easily proved by mathematical induction.
This case of the current concern is f ≠ 0. We have already considered separately the case t = 0, so now we can assume that t ≠ 0. For t, f > 0 we have −t − f < t − f < t + f and . This means that:
Hence for the case f ≠ 0 and t ≠ 0 and p = q:
and both sequences ()i=0…∞ and ()i=0…∞ are constant and converge to 0. If = 1 ( = t) then = 1 for i = 0…∞ and the sequences ()i=0…∞ and ()i=0…∞ are constant and convergent to 1 and t, respectively.
For ∈ (0, 1), two cases should be considered (note the assumption that p ≠ q):
Combining both cases together, we obtain that for p ≠ q and 0 < < t the sequence ()i=0…∞ is always convergent to .
It means that for f = 0 and t ≠ 0 and p ≠ q, the sequence ()i=0…∞ is always convergent to if ∈ M\{}(i.e., ) or to if (the constant sequence ).
6.3.5. The Case of and and
This case describes the network with an unequal number of “good” and “bad” nodes. In reference to Section 6.3.2, this case can also be called a typical one. Note that the fact of convergence does not depend on the choice of a coding scheme.
To prove the convergence of the sequence ()i=0…∞ for f ≠ 0 and t ≠ 0 and p ≠ q, it is enough to show that the sequence ()i=0…∞ is a Cauchy sequence (because M is a complete metric space).
First, we calculate (𝑔(x)):
Let us estimate a distance between and according to the distance between and :
Note that for the denominator is always positive:
It is obvious for p > q, while for p < q, it results from the inequality:
It is necessary at this point to break down the analysis into four more specific sub-cases, provided below as Section 6.3.6, Section 6.3.7, Section 6.3.8 and Section 6.3.9. It is because the way the convergence occurs depends on both the coding scheme as well as on the relative number of “good” and “bad” nodes.
6.3.6. The Case of and
This is the case of the ill-chosen (yet possible) coding, where “good” is indicated by the lower value than “bad”. Further, the network has more “good” nodes than “bad” ones.
For p > q (and xi ≥ 0, p ≥ 0, q ≥ 0, t > 0):
If t < f (and p + q > 0, t > 0) then
because 0 < p(f − t) < p(f − t) + (p + q)t.
It means that for p > q and t < f, the sequence ()i=0…∞ is a Cauchy sequence in the interval M, i.e., for i = 0…∞ and some , and it is convergent.
6.3.7. The Case of and
This is the case of the ill-chosen (yet possible) coding, where “good” is indicated by the lower value than “bad”. Further, the network has more “bad” nodes than “good” ones. This situation may be hard for the outcome of the algorithm (as the excess of “bad” nodes may not allow for the correct identification of the quality of nodes), but it is important that the convergence still occurs.
For p < q (and ≤ t + f, p ≥ 0, q ≥ 0, t > 0) we have:
If t < f (and p + q > 0, t > 0), then
because 0 < q(f − t) < q(f − t) + (p + q)t.
It means that for p < q and t < f the sequence ()i=0…∞ is a Cauchy sequence in the interval M, i.e., for i = 0…∞ and some , and it is convergent.
6.3.8. The Case of and
This is the case of the coding that may be considered a rational one, where “good” is indicated by a higher value than “bad”. Further, the network has more “good” nodes than “bad” ones. In a way, this is a typical and the desired situation.
We still have to consider case t > f and p ≠ q. Unfortunately, it is a bit more complicated and has to be split again into two cases, for p > q and p < q.
For p > q and t > f, the fixed point is . From the obvious fact that for t > f:
it is easy to show that
For p > q and t > f the function is a concave function in the interval M. Indeed, its second-degree derivative is equal to 𝑔″(x) and negative in this interval:
This means that a minimum of this function is reached at one of the ends of a considered range. Therefore for the initial part of the interval M: we can estimate the distance from below by , i.e.,
Hence,
So for , the sequence ()i=0…∞ is strictly increasing and while :
Thus if then . Similarly, if then . Generalizing, if then . This means that if for i ≤ n, where (⌈⌉ denotes a ceiling function) all , then . In other words, among the n + 1 first elements of the sequence ()i=0…∞, there must appear an element greater than . So some element of the sequence ()i=0…∞ lies above . Let us denote the first such element with the index j.
Now, assuming t > f, we can write for :
If t > f and , then
because p²t + q²t + 2pqf > 2pq(t − f) > 0, since (p − q)²t > −4pqf.
It means that for p > q and t > f, the sequence ()i=0…∞ is a Cauchy sequence in the interval M, i.e., for i = j…∞ and some , and it is convergent.
6.3.9. The Case of and
This is the case of coding that can be considered rational, where “good” is indicated by a higher value than “bad”. However, the network has more “bad” nodes than “good” ones, so that the resulting value may not be as expected. Still, it is important that convergence occurs.
For p < q and t > f, the fixed point . From the obvious fact that for t > f:
it is easy to show that
For p < q and t > f the function is a convex function in the interval M. Indeed, its second-degree derivative is equal to 𝑔″(x) and positive in this interval:
because for x ∈ M, we have:
This means that a maximum of this function is reached at one of the ends of a considered range. Therefore for the final part of the interval M: we can estimate the value from above by , i.e.,
Hence,
So for , the sequence ()i=0…∞ is strictly decreasing and while :
Thus, if , then . Similarly, if , then . Generalizing, if , then . This means that if for i ≤ n, where (⌈⌉ denotes a ceiling function) all , then . In other words, among the n + 1 first elements of the sequence ()i=0…∞, there must appear an element less than . So some element of the sequence ()i=0…∞ lies below . Let us denote the first such element with the index j.
Now assuming t > f, we can write for :
If t > f and , then
because p²t + q²t + 2pqf > 2pq(t − f) > 0, since (p − q)²t > −4pqf.
It means that for p < q and t > f, the sequence ()i=0…∞ is a Cauchy sequence in the interval M, i.e., for i = j…∞ and some , and it is convergent.
To recapitulate, the paper shows that for f ≠ 0 and t ≠ 0, the sequence ()i=0…∞ starting from any ∈ M is convergent to a single fixed point in M, but for f = 0 or t = 0, it is not true. For t = 0, the sequence (xi)i=0…∞ generally oscillates around a single fixed point and is convergent only when it is constant and starts exactly from the fixed point. For f = 0 and p ≠ q, the sequence ()i=0…∞ is always convergent to one of the specific ends of the interval M, while the other end is also a fixed point but only reachable by the constant sequence starting exactly from this point. For f = 0 and p = q, every point of the interval M is a fixed point, and every sequence ()i=0…∞ starting from any ∈ M is always constant and converges to this point.
If the starting point lies outside the interval M (but is greater than zero), its first iteration will fall into the interval M, so the above conclusions are also valid for . Identical conclusions also apply to the sequence ()i=0…∞.
7. Discussion
It is of special interest to wireless multi-hop IoT networks to see whether the process of convergence can be negatively affected by the dynamics of the transport layer. Specifically, phenomena such as delays and repetitions of opinions, as well as the disappearance of nodes, are of certain concern.
The convergence itself seems to be resilient to the majority of such negative cases. Neither the algorithm nor its convergence makes any assumption about the timeliness or order of appearance of opinions. It also makes no assumption about the continuity of the existence of nodes so that it is resilient to the appearance and disappearance of nodes. The eventuality of convergence implies that delays in the delivery of opinions should make no impact on the process of convergence, barring the decrease in the speed of this process.
The algorithm itself relies on benevolent nodes having stable identities and sharing the approximately correct clock. It shares those assumptions with several reputation-based schemes. Consequently, attacks on identity may have an impact on the calculation of reputation. The assurance regarding the identity can be achieved, e.g., by using cryptography (see, e.g., the work of [30]). Note, however, that those attacks should not have an impact on the convergence itself, only on the value the algorithm converges to.
8. Conclusions
This paper presents the analysis and the proof of eventual convergence for the EWMA algorithm, as used in IoT sensor networks. Such an algorithm can be used in over-provisioned (“dense”) sensor networks to decrease the uncertainty of measurements reported by the networks, even if low-cost sensors are used, and no reference nodes are present.
The novelty of this paper lies in the demonstration of the proof of the convergence of the EWMA algorithm, as it can be used in IoT sensor networks. The convergence of the EWMA algorithm has been studied before, but those results are not directly applicable to the way this algorithm can be used in IoT sensor networks. For uses cases similar to the IoT networks, the convergence is usually assumed and demonstrated through the simulation. The demonstration of the mathematical proof means that the algorithm can be safely used in situations where the assurance of convergence is required.
The paper starts by describing the EWMA algorithm in a way applicable to IoT sensor networks. Then the UOG is introduced as a model of random graphs that well represents IoT sensor networks while allowing for formalization. It is the formalization provided by the UOG that bridges the application and the mathematics of the EWMA. The preliminary analysis of the convergence of the EWMA for the UOG is then conducted. From there, the mathematical proof follows. It demonstrates that, apart from some inapplicable cases, the algorithm assures eventual convergence.
The EWMA algorithm, as described in this paper, does not rely on any particular configuration of the transport layer. The sensitivity of the convergence to the variability of the IoT network is currently being studied. It is already visible that the eventuality of the convergence makes it resilient to negative aspects of the dynamics of wireless multi-hop networks, such as delays, repetitions, disappearance, and non-delivery. The suggested implementation does not require a significant increase in the computing power of the nodes, and its impact on the required bandwidth can be contained as well. Models such as the work of [31] can be used to further optimize the energy consumption, if required.
The algorithm assumes that all the nodes are benevolent, even though some of them may be faulty or of lower quality. The behavior of the algorithm suggests that in case of an adversary attack where, e.g., malicious nodes are added to the network or benevolent ones became malicious, the algorithm may still deliver convergence, but it may not converge on the correct vector of values. The behavior of the algorithm in such situations is currently being studied.
Author Contributions
Conceptualization, P.C. and J.L.; methodology, P.C.; formal analysis, J.L.; resources, C.O.; writing—original draft preparation, J.L. and P.C.; writing—review and editing, C.O.; administration, C.O. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding. It was partially supported by internal funding of respective Universities.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
Glossary
| Abbreviation | Meaning |
| AEWMA | Adaptative EWMA, see the work of [17] |
| EWMA | Exponentially Weighted Moving Average |
| IoT | Internet of Things |
| PEWMA | Probabilistic EWMA, see the work of [16] |
| SMA | Simple Moving Average |
| UOG | Uniform Opinion Graph |
| Symbol | Meaning |
| a, b,.. | the sensor within the sensor network |
| τ | moment in time |
| w | reputation |
| u | level of trust |
| conf | level of confidence of one sensor into the other |
| c | level of self-confidence |
| fd | decay function |
| λ | decay constant used by the fd |
| xi | reputation of a representative trustworthy node at the iteration i |
| yi | reputation of a representative faulty node at the iteration i |
| p | the number of trustworthy nodes that provide opinions about a given node |
| q | the number of faulty nodes that provide opinions about a given node |
| t | the level of trust reported by the compatible node |
| i | the level of trust reported by the incompatible node |
| (x*, y*) | the convergence vector |
| M | the convergence interval |
| m-, m+ | bracketing values of M |
| g(x) | substitute function replacing vectors with a sequence |
| x-*, x+* | fixed points of g(x) |
| α | substitute sequence used to express g(x) |
References
- O’Donovan, J. Capturing Trust in Social Web Applications. In Computing with Social Trust; Human—Computer Interaction Series; Golbeck, J., Ed.; Springer: London, UK, 2009; ISBN 978-1-84800-356-9. [Google Scholar] [CrossRef]
- Cofta, P.; Karatzas, K.; Orłowski, C. A Conceptual Model of Measurement Uncertainty in IoT Sensor Networks. Sensors 2021, 21, 1827. [Google Scholar] [CrossRef] [PubMed]
- Yun, J.; Woo, J. IoT-Enabled Particulate Matter Monitoring and Forecasting Method Based on Cluster Analysis. IEEE Internet Things J. 2021, 8, 7380–7393. [Google Scholar] [CrossRef]
- Syed, A.S.; Sierra-Sosa, D.; Kumar, A.; Elmaghraby, A. IoT in Smart Cities: A Survey of Technologies, Practices and Challenges. Smart Cities 2021, 4, 24. [Google Scholar] [CrossRef]
- D’Amico, G.; L’Abbate, P.; Liao, W.; Yigitcanlar, T.; Ioppolo, G. Understanding Sensor Cities: Insights from Technology Giant Company Driven Smart Urbanism Practices. Sensors 2020, 20, 4391. [Google Scholar] [CrossRef]
- Ma, Z.; Liu, L.; Meng, W. DCONST: Detection of Multiple-Mix-Attack Malicious Nodes Using Consensus-Based Trust in IoT Networks. In Proceedings of the Australasian Conference on Information Security and Privacy (ACISP 2020), Perth, Australia, 30 November–2 December 2020. [Google Scholar] [CrossRef]
- Djedjig, N.; Tandjaoui, D.; Romdhani, I.; Medjek, F. Trust Management in the Internet of Things. In Security and Privacy in Smart Sensor Networks; Maleh, Y., Ezzati, A., Belaissaoui, M., Eds.; IGI Global: Hershey, PA, USA, 2018; pp. 122–146. [Google Scholar] [CrossRef]
- Azzedin, F.; Ghaleb, M. Internet-of-Things and Information Fusion: Trust Perspective Survey. Sensors 2019, 19, 1929. [Google Scholar] [CrossRef]
- Chen, D.; Chang, G.; Sun, D.; Li, J.; Jia, J.; Wang, X. TRM-IoT: A Trust Management Model Based on Fuzzy Reputation for Internet of Things. ComSIS 2011, 8, 1207–1228. [Google Scholar] [CrossRef]
- Awan, K.A.; Din, I.U.; Almogren, A.; Almajed, H.; Mohiuddin, I.; Guizani, M. NeuroTrust-Artificial Neural Network-based Intelligent Trust Management Mechanism for Large-Scale Internet of Medical Things. IEEE Internet Things J. 2020. [Google Scholar] [CrossRef]
- Jøsang, A.; Ismail, R.; Boyd, C. A survey of trust and reputation systems for online service provision. Decis. Support Syst. 2007, 43, 618–644. [Google Scholar] [CrossRef]
- Chang, E.; Dillon, T.; Hussain, F. Trust and Reputation for Service-Oriented Environments. Technologies for Building Business Intelligence and Consumer Confidence; John Wiley and Sons: Hoboken, NJ, USA, 2006; ISBN 978-0-470-01547-6. [Google Scholar] [CrossRef]
- Sukparungsee, S.; Areepong, Y.; Taboran, R. Exponentially weighted moving average—Moving average charts for monitoring the process mean. PLoS ONE 2020, 15, e0228208. [Google Scholar] [CrossRef] [PubMed]
- Yu, J.; Kim, S.B.; Bai, J.; Han, S.W. Comparative Study on Exponentially Weighted Moving Average Approaches for the Self-Starting Forecasting. Appl. Sci. 2020, 10, 7351. [Google Scholar] [CrossRef]
- Cofta, P.; Orłowski, C.; Lebiedź, J. Trust-Based Model for the Assessment of the Uncertainty of Measurements in Hybrid IoT Networks. Sensors 2020, 20, 956. [Google Scholar] [CrossRef]
- Renshaw, J. Anomaly Detection Using aws iot and aws Lambda. 2019. Available online: https://aws.amazon.com/blogs/iot/anomaly-detection-using-aws-iot-and-aws-lambda/ (accessed on 1 September 2021).
- Capizzi, G.; Masarotto, G. An Adaptive Exponentially Weighted Moving Average Control Chart. Technometrics 2003, 45, 199–207. [Google Scholar] [CrossRef]
- Eckner, A. Algorithms for Unevenly Spaced Time Series: Moving Averages and Other Rolling Operators. 2015. Available online: https://www.semanticscholar.org/paper/Algorithms-for-Unevenly-Spaced-Time-Series-%3A-Moving-Eckner/882e93570eae184ae737bf0344cb50a2925e353d (accessed on 10 March 2018).
- Vinod, H.D. Maximum entropy ensembles for time series inference in economics. J. Asian Econ. 2006, 17, 955–978. [Google Scholar] [CrossRef]
- Steiner, S.H. Exponentially Weighted Moving Average Control Charts with Time-Varying Control Limits and Fast Initial Response. J. Qual. Technol. 1999, 31, 75–86. [Google Scholar] [CrossRef]
- Hosseini, S.S.; Noorossana, R. Performance evaluation of EWMA and CUSUM control charts to detect anomalies in social networks using average and standard deviation of degree measures. Qual. Reliab. Eng. 2018, 34, 477–500. [Google Scholar] [CrossRef]
- West, A.G.; Lee, I.; Kannan, S.; Sokolsky, O. An Evaluation Framework for Reputation Management Systems. In Trust Modeling and Management in Digital Environments: From Social Concept to System Development; Zheng, Y., Ed.; Information Science Reference: Hershey, PA, USA, 2010; pp. 282–308. [Google Scholar] [CrossRef]
- Hillam, K.L.; Thron, W.J. A general convergence criterion for continued fractions K (an/bn). Proc. Am. Math. Soc. 1965, 16, 1256–1262. [Google Scholar]
- Mandell, M.; Magnus, A. On convergence of sequences of linear fractional transformations. Math. Z. 1970, 115, 11–17. [Google Scholar] [CrossRef]
- Mui, L. Computational Models of Trust and Reputation: Agents, Evolutionary Games, and Social Networks. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2002. [Google Scholar]
- Carbo, J.; Molina, J.; Davila, J. Trust Management Through Fuzzy Reputation. Int. J. Coop. Inf. Syst. 2003, 12, 135–155. [Google Scholar] [CrossRef]
- Akbani, R.; Korkmaz, T.; Raju, G.V.S. A Machine Learning Based Reputation System for Defending Against Malicious Node Behavior. In Proceedings of the IEEE GLOBECOM 2008—2008 IEEE Global Telecommunications Conference, New Orleans, LA, USA, 30 November–4 December 2008. [Google Scholar] [CrossRef]
- Alnumay, W.; Ghosh, U.; Chatterjee, P. A Trust-Based Predictive Model for Mobile Ad Hoc Network in Internet of Things. Sensors 2019, 19, 1467. [Google Scholar] [CrossRef]
- Cofta, P. Trust, Complexity and Control: Confidence in a Convergent World; John Wiley and Sons: Chichester, UK, 2007; ISBN 978-0470061305. [Google Scholar]
- Verri Lucca, A.; Mariano Sborz, G.A.; Leithardt, V.R.Q.; Beko, M.; Albenes Zeferino, C.; Parreira, W.D. A Review of Techniques for Implementing Elliptic Curve Point Multiplication on Hardware. J. Sens. Actuator Netw. 2021, 10, 3. [Google Scholar] [CrossRef]
- dos Anjos, J.C.S.; Gross, J.L.G.; Matteussi, K.J.; González, G.V.; Leithardt, V.R.Q.; Geyer, C.F.R. An Algorithm to Minimize Energy Consumption and Elapsed Time for IoT Workloads in a Hybrid Architecture. Sensors 2021, 21, 2914. [Google Scholar] [CrossRef]




Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).