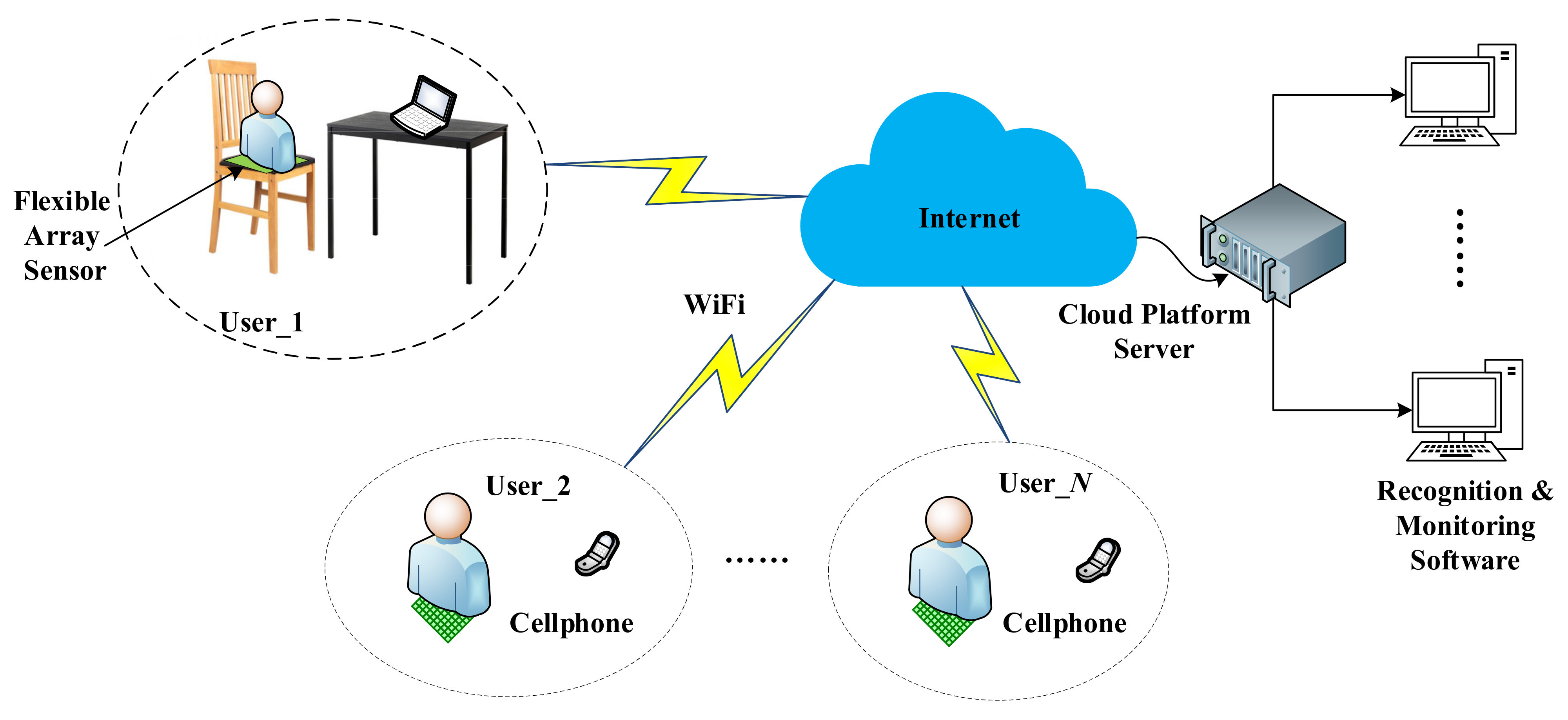
The principle of the sitting posture recognition process is demonstrated in
Figure 9. The original data collected by the pressure acquisition circuit are taken as the original dataset. Each set of data is a matrix with rows and columns of 32. Due to a large amount of data, the sensible first step is to reduce the dimension of data. However, the characteristics of the data should be preserved as much as possible while the data volume is reduced. After the data are reduced in dimensionality, it is classified using the SOM algorithm. SOM algorithm, on the one hand, can put similar data in the same category, on the other hand, maps the input data into two-dimensional discrete graphics in the output layer. These characteristics apply well to the data processing of sitting posture. The collected data are divided into training part and testing part. The actual sitting posture of the human body corresponding to the pressure distribution received by the pressure sensor array is described in
Figure 10. Six sitting postures, namely standard sitting, lean left, lean right, waist bow, right cross-legs, and left cross-legs [
22] are common sitting postures, so classification and detailed data analysis are carried out for these six sitting postures.
3.1. Dimensionality Reduction for Original Data
The number of neurons in the output layer is positively correlated with the number of categories of training samples. If the number of neurons is less than that of categories, it is not enough to distinguish all the categories, hence the results of training are bounded to combine the similar classes into one. On the contrary, if there are more neurons than categories, it is possible to divide them excessive or to have “dead nodes”, i.e., one node never wins and is far away from other winning nodes during the training process, so their weights will never update.
The original pressure distribution data area matrix with 32 rows and 32 columns as following, so the number of input nodes in this network is 1024 theoretically. As a time-varying matrix,
P is changing over time. The following descriptions are all in the state of time t. For the sake of clarity, the variable t is omitted.
Excessive data input may introduce unnecessary noises, increase computation complexity, thus slow down the speed of data processing. Therefore, we pre-process the input data and compress the data by principal component analysis (PCA) [
23].
can also be thought of as 32-dimensional vectors, each of which has 32 elements,
The covariance matrix is defined as follows:
Every member
in the covariance matrix is a covariance between
and
, the calculation method [
24,
25] is as follows:
The eigenvectors
and their corresponding eigenvalues of the matrix
R are calculated. If the eigenvectors are over-reserved, the noise will also be retained, and the amount of data will not be reduced significantly, thus the calculation speed will be negatively affected. However, the difference between the samples will not be observed if too few eigenvectors are selected. After calculation and analysis, the top 8 eigenvectors were selected without affecting the characteristics of the data, and the calculation speed of classification is improved at the same time. The 8 eigenvectors corresponding to the 8 largest eigenvalues are constructed into a matrix
. Finally, the data matrix
Pr after dimensionality reduction is calculated as follows:
Pr is a 32 by 8 matrix, the amount of data has been reduced from 1024 to 256.
3.2. Data Classification
PCA is a traditional data compression method under the condition of retaining data characteristics to the maximum extent. After the data arecompressed, the noise will be reduced, and the calculation speed of the SOM network will be improved.
The elements of the matrix Pr are connected from head to tail to construct the input vector of the SOM network. Each vector in the input layer has 256 elements. The input vector can be written as , Mdenotes the number of input neurons, which is the number of training samples, the connected weights between input neuron i and j in the competitive layer can be written as , where N is the number of output neurons, since the output layer is designed to have 6 nodes, so N is set to 6.
The first step is to normalize the selected samples and weights as Equation (7) and Equation (8) [
26]. Normalization eliminates the adverse effects caused by singular samples and different data sizes, helps to improve the solution convergence speed, and improves the efficiency of model training.
The Euclidean distance
between the input
and the weight
[
26] is calculated as following:
where
is the smallest distance among
, and the neuron with the minimal distance will be the winner
.
The neighborhood function is used to determine the influence of the winning node on its near neighbor node, hence update range of each node in the winning neighborhood. The most common choice is the Gaussian function [
26].
The Gaussian based winning neighborhood function is shown in Equation (11), where is the distance between neuron c and neuron j, denotes the location of winning neuron , and denotes the location of the near neighbor neuron . refers to the number of neurons centered on the winning neuron, which is determined by the neighborhood function. is the initial neighborhood value.
We use the exponential function to define the wining neighborhood function’s decay rate,
The learning rate is
, the initial value is
. The updates are applied for all the training process. Finally, we will iterate the process until the learning rate converges to 0.
The weight is adjusted to all neurons in the winning neighborhood. If one neuron is in the winner’s neighborhood, the weight will change as the first equation of Equation (15); otherwise, the weight will change as the second equation of Equation (15).
3.3. SOM Based Sitting Posture Recognition Algorithm (SOM-SPR)
The arrangement form of neuron nodes in the output layer depends on the needs of practical applications, and the arrangement form should reflect the physical meaning of practical problems as intuitively as possible.
Six sitting postures, including left cross legs, right cross legs, lean left, lean right, waist bow, and standard sitting, are arranged to identify, so the number of output nodes is 6. Moreover, the neurons are connected via hexagonal topology [
27], as
Figure 11. All the data are distributed on a two-dimensional plane. If the posture is similar, the distance will be closer in topology. For instance, the center is “standard sitting”, “left cross legs” and “lean left” are above “standard sitting”. This structure is also in line with human experience and cognition.
The results of
Figure 12 show that the sitting posture clustering results make two classes with high similarity closer to each other, the more similar the two categories are, the closer the distance is. As shown in
Figure 12, the color ranges from red to orange and then to yellow. The lighter the color, the higher the similarity of their features. As a result, the distance between “standard sitting” and “waist bow” is very small, while the distance between “standard sitting” and “waist bow” is very big. In terms of results, the accuracy of SOM-SPR is excellent, however, we have made improvements to the SOM network in pursuit of better results, details in
Section 3.4.
3.4. Improved SOM Based Sitting Posture Recognition Algorithm (ISOM-SPR)
As we know, SOM algorithm is an unsupervised learning method, which has good characteristics of self-organizing and visualization. However, there are still some apparent limitations, such as the network structure is fixed and cannot change dynamically. Therefore, an improved SOM approach to solve this problem is studied to achieve better recognition results of sitting posture.
Once the SOM-SPR algorithm finished once clustering, the weights will not change. Therefore, we recalculate the Euclidean distances between the input
and the fixed weight
.
Hence, the difference
between adjacent nodes of the same data is calculated.
and
are the labels of two adjacent nodes, respectively.
The degree of differentiation of the same data relative to two nodes is defined as
. As the number
gets bigger, the difference gets bigger and bigger. Onthecontrary, the smaller the
, the less significant the difference. The corresponding set of data will be removedwhen
is less than certain threshold value
. The flow charts of SOM-SPR algorithm and ISOM-SPR algorithm are shown in
Figure 13.
After that, we use the retained data to complete the learning process again. In this way, the result characteristics of final clustering will be more obvious. In other words, the distance between nodes in the output layer will be larger, as
Figure 14.
The parameters in the training process for SOM-SPR and ISOM-SPR algorithms are listed in
Table 1.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}