
Machine Learning for Light Sensor Calibration



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
1.1. Motivation
1.2. Solar Irradiance
2. Measurements and Data Sets
3. Machine Learning and Workflow
3.1. Data Preprocessing
3.2. Input Features and Output Targets
| Features | Unit | Min | Max | Mean | StDev |
| Violet (450 nm) | counts | 0 | 2717 | 370.67 | 412.56 |
| Blue (500 nm) | counts | 0 | 4165 | 528.13 | 611.57 |
| Green (550 nm) | counts | 0 | 4619 | 546.68 | 664.90 |
| Yellow (570 nm) | counts | 0 | 4963 | 573.22 | 710.80 |
| Orange (600 nm) | counts | 0 | 3646 | 411.31 | 519.83 |
| Red (650 nm) | counts | 0 | 3826 | 425.41 | 545.63 |
| IR (Infrared) | counts | 0 | 65,535 | 28,500.35 | 27,263.43 |
| Visible | counts | 0 | 51,573 | 12,722.19 | 17,871.05 |
| Lux | lux | −1 | 2207.41 | 127.99 | 381.92 |
| UVA (Raw) | counts | 0 | 40,296 | 2492.98 | 3400.20 |
| UVB (Raw) | counts | 0 | 44,768 | 2682.46 | 3686.13 |
| Visible Compensation | counts | 0 | 12,045 | 782.75 | 1026.57 |
| IR (Infrared) Compensation | counts | 0 | 8596 | 456.58 | 699.96 |
| UV Index | N/A | −1.17 | 1.07 | −0.05 | 0.08 |
| Targets | Unit | Min | Max | Mean | StDev |
| Irradiance at 360 nm | W/m2/nm | 0 | 0.069338 | 0.010471 | 0.011335 |
| … | … | … | … | … | … |
| Irradiance at 780 nm | W/m2/nm | 0 | 0.337675 | 0.032955 | 0.046052 |
3.3. Principal Component Analysis (PCA)
3.4. Artificial Neural Network
3.5. Workflow
4. Machine Learning for Low-Cost Light Sensor Calibration of Wavelength Resolved Irradiance
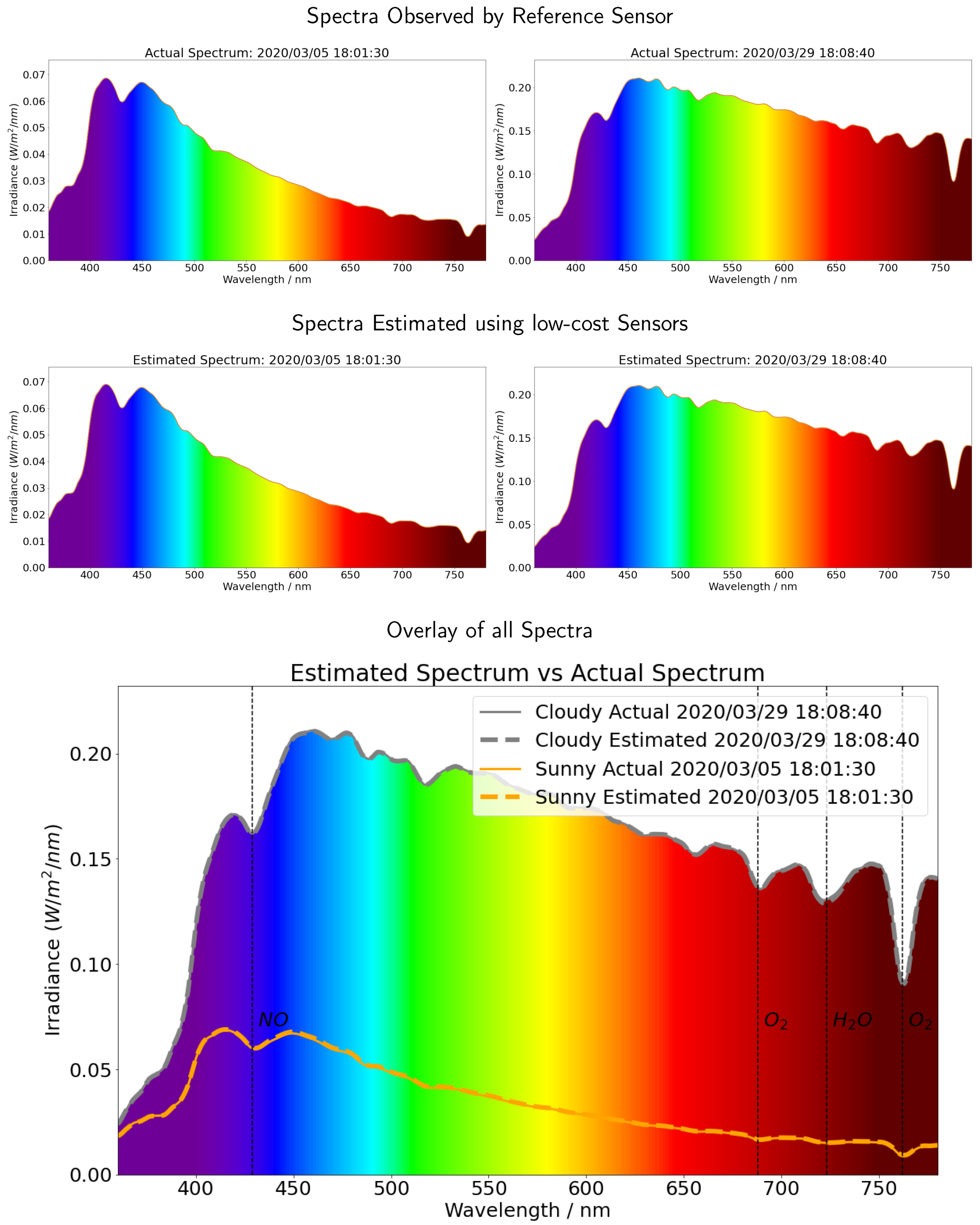
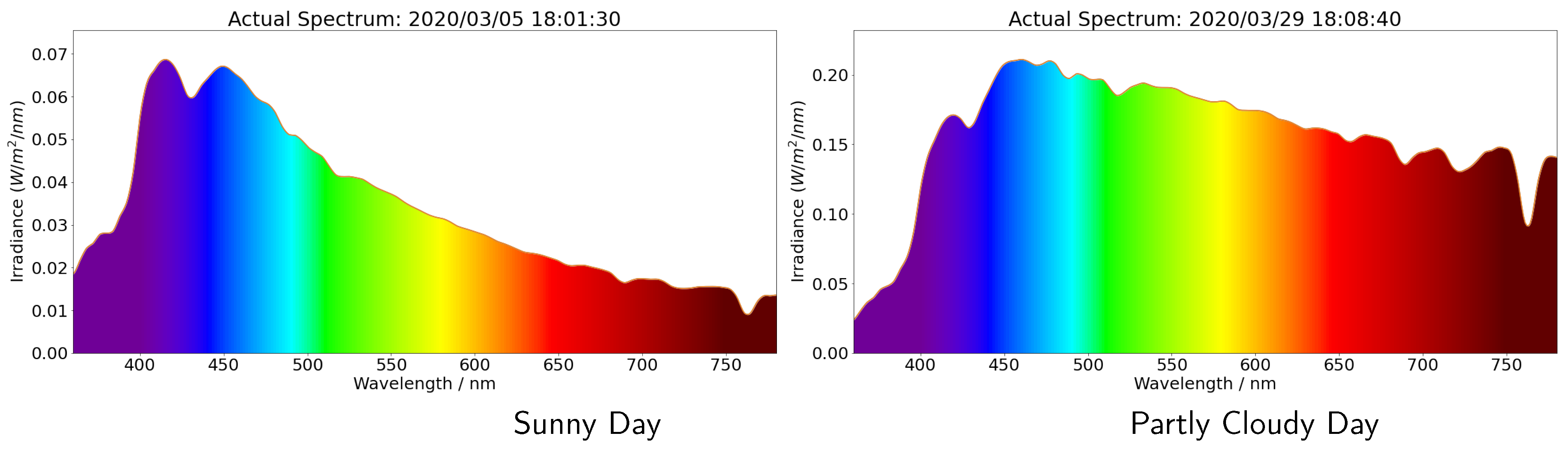
4.1. Whole Spectrum Calibration Model (360–780 nm)
4.2. The Relative Importance of the Machine Learning Inputs
4.2.1. Shapley Value: An Explainer of Machine Learning Models
4.2.2. Feature Importance
4.3. Applying the Calibration to Provide an Irradiance Spectrum
5. The Observed Diurnal Variation in Wavelength Resolved Irradiance
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chandrasekhar, S. Radiative Transfer; Dover Publications: Mineola, NY, USA, 1960. [Google Scholar]
- Lenoble, J. Radiative Transfer in Scattering and Absorbing Atmospheres: Standard Computational Procedures; A. DEEPAK Publishing: Hampton, VA, USA, 1985. [Google Scholar]
- Lary, D.J.; Pyle, J.A. Diffuse radiation, twilight, and photochemistry—I. J. Atmos. Chem. 1991, 13, 373–392. [Google Scholar] [CrossRef]
- Lary, D.J.; Pyle, J.A. Diffuse radiation, twilight, and photochemistry—II. J. Atmos. Chem. 1991, 13, 393–406. [Google Scholar] [CrossRef]
- Deutschmann, T.; Beirle, S.; Friess, U.; Grzegorski, M.; Kern, C.; Kritten, L.; Platt, U.; Prados-Roman, C.; Puķīte, J.; Wagner, T.R.; et al. The Monte Carlo atmospheric radiative transfer model McArtim: Introduction and validation of Jacobians and 3D features. J. Quant. Spectrosc. Radiat. Transf. 2011, 112, 1119–1137. [Google Scholar] [CrossRef]
- Hartmann, D.L. (Ed.) Atmospheric Radiative Transfer and Climate. In International Geophysics; Elsevier: Amsterdam, The Netherlands, 2016. [Google Scholar]
- Buehler, S.; Mendrok, J.; Eriksson, P.; Perrin, A.; Larsson, R.; Lemke, O. ARTS, the Atmospheric Radiative Transfer Simulator—Version 2.2, the planetary toolbox edition. Geosci. Model Dev. 2017, 11, 1537–1556. [Google Scholar] [CrossRef] [Green Version]
- Zhang, F.; Shi, Y.; Wu, K.; Li, J.; Li, W. Atmospheric Radiative Transfer Parameterizations. In Understanding of Atmospheric Systems with Efficient Numerical Methods for Observation and Prediction; IntechOpen: London, UK, 2019. [Google Scholar]
- Gordon, I.E.; Babikov, Y.L.; Barbe, A.; Benner, D.C.; Bernath, P.F.; Birk, M.; Bizzocchi, L.; Boudon, V.; Brown, L.R.; Chance, K.; et al. The HITRAN2012 molecular spectroscopic database. J. Quant. Spectrosc. Radiat. Transf. 2013, 130, 4–50. [Google Scholar]
- Noelle, A.; Hartmann, G.; Fahr, A.; Lary, D.; Lee, Y.P.; Limão-Vieira, P.; Locht, R.; Martín-Torres, F.J.; McNeill, K.; Orlando, J.; et al. UV/Vis+ Spectra Data Base (UV/Vis+ Photochemistry Database), 12th ed.; Science-softCon: Maintal, Germany, 2019; ISBN 978-3-00-063188-7. [Google Scholar]
- Brasseur, G.; Solomon, S. Aeronomy of the Middle Atmosphere, 2nd ed.; D.Reidel Publishing Company: Dordrecht, The Netherlands, 1986. [Google Scholar]
- Shanmugam, V.; Shanmugam, P.; He, X. New algorithm for computation of the Rayleigh-scattering radiance for remote sensing of water color from space. Opt. Exp. 2019, 27, 30116–30139. [Google Scholar] [CrossRef]
- Krishnan, R.S. The scattering of light by particles suspended in a medium of higher refractive index. Proc. Indian Acad. Sci.—Sect. A 1934, 1, 147–155. [Google Scholar] [CrossRef]
- Laeng, B.; Sirois, S.; Gredebäck, G. Pupillometry: A Window to the Preconscious? Perspect. Psychol. Sci. J. Assoc. Psychol. Sci. 2012, 7, 18–27. [Google Scholar] [CrossRef]
- Boxwell, M. Solar Electricity Handbook: A Simple, Practical Guide to Solar Energy: How to Design and Install Photovoltaic Solar Electric Systems; Greenstream Publishing: Coventry, UK, 2012. [Google Scholar]
- Wayne, R.P. Chemistry of Atmospheres, 3rd ed.; Oxford University Press: Oxford, UK, 2000. [Google Scholar]
- Brasseur, G.P.; Orlando, J.J.; Tyndall, G.S. Atmospheric Chemistry and Global Change; Oxford University Press: Oxford, UK, 1999. [Google Scholar]
- Koza, J.R.; Bennett, F.H.; Andre, D.; Keane, M.A. Automated Design of Both the Topology and Sizing of Analog Electrical Circuits Using Genetic Programming. In Artificial Intelligence in Design ’96; Springer: Cham, The Netherlands, 1996; pp. 151–170. [Google Scholar] [CrossRef]
- Fayyad, U.; Piatetsky-Shapiro, G.; Smyth, P. From data mining to knowledge discovery in databases. AI Mag. 1996, 17, 37. [Google Scholar]
- Samuel, A.L. Some studies in machine learning using the game of checkers. II—Recent progress. In Comput. Games I; Springer: Berlin/Heidelberg, Germany, 1988; pp. 366–400. [Google Scholar]
- Dudoit, S.; Fridlyand, J.; Speed, T.P. Comparison of discrimination methods for the classification of tumors using gene expression data. J. Am. Stat. Assoc. 2002, 97, 77–87. [Google Scholar] [CrossRef] [Green Version]
- Yarkoni, T.; Poldrack, R.A.; Nichols, T.E.; Van Essen, D.C.; Wager, T.D. Large-scale automated synthesis of human functional neuroimaging data. Nat. Methods 2011, 8, 665. [Google Scholar] [CrossRef] [Green Version]
- Pereira, F.; Mitchell, T.; Botvinick, M. Machine learning classifiers and fMRI: A tutorial overview. Neuroimage 2009, 45, S199–S209. [Google Scholar] [CrossRef] [Green Version]
- Bhavsar, P.; Safro, I.; Bouaynaya, N.; Polikar, R.; Dera, D. Machine learning in transportation data analytics. In Data Analytics for Intelligent Transportation Systems; Elsevier: Amsterdam, The Netherlands, 2017; pp. 283–307. [Google Scholar]
- Hagenauer, J.; Helbich, M. A comparative study of machine learning classifiers for modeling travel mode choice. Exp. Syst. Appl. 2017, 78, 273–282. [Google Scholar] [CrossRef]
- Lary, D.J.; Alavi, A.H.; Gandomi, A.H.; Walker, A.L. Machine learning in geosciences and remote sensing. Geosci. Front. 2016, 7, 3–10. [Google Scholar] [CrossRef] [Green Version]
- Huang, C.; Davis, L.; Townshend, J. An assessment of support vector machines for land cover classification. Int. J. Remote Sens. 2002, 23, 725–749. [Google Scholar] [CrossRef]
- Zhang, Y. MINTS Light Sensor Calibration Dataset; Zenodo: Genève, Switzerland, 2021. [Google Scholar] [CrossRef]
- Rao, C.R. The use and interpretation of principal component analysis in applied research. Sankhyā Indian J. Statis. 1964, 12, 329–358. [Google Scholar]
- Pearson, K.L., III. On lines and planes of closest fit to systems of points in space. Lond. Edinb. Dublin Philos. Mag. J. Sci. 1901, 2, 559–572. [Google Scholar] [CrossRef] [Green Version]
- Haykin, S.O. Neural Networks and Learning Machines; Prentice Hall: New York, NY, USA, 2009. [Google Scholar]
- Liakos, K.; Busato, P.; Moshou, D.; Pearson, S.; Bochtis, D. Machine learning in agriculture: A review. Sensors 2018, 18, 2674. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hecht-Nielsen, R. Theory of the backpropagation neural network. In Proceedings of the International 1989 Joint Conference on Neural Networks, Washington, DC, USA, 18–22 June 1989; Volume 1, pp. 593–605. [Google Scholar]
- Widrow, B.; Lehr, M.A. 30 years of adaptive neural networks: Perceptron, Madaline, and backpropagation. Proc. IEEE 1990, 78, 1415–1442. [Google Scholar] [CrossRef]
- Feng, X.; Li, Q.; Zhu, Y.; Hou, J.; Jin, L.; Wang, J. Artificial neural networks forecasting of PM2.5 pollution using air mass trajectory based geographic model and wavelet transformation. Atmos. Environ. 2015, 107, 118–128. [Google Scholar] [CrossRef]
- Wijeratne, L.O.; Kiv, D.R.; Aker, A.R.; Talebi, S.; Lary, D.J. Using machine learning for the calibration of airborne particulate sensors. Sensors 2020, 20, 99. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liang, X.; Liu, Q.M. Applying Deep Learning to Clear-Sky Radiance Simulation for VIIRS with Community Radiative Transfer Model—Part 2: Model Architecture and Assessment. Remote Sens. 2020, 12, 3825. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Wan, L.; Zeiler, M.D.; Zhang, S.; LeCun, Y.; Fergus, R. Regularization of Neural Networks using DropConnect. In Proceedings of the International Conference on Machine Learning ICML, Atlanta, GA, USA, 16–21 June 2013. [Google Scholar]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Srivastava, N.; Hinton, G.E.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Shapley, L.S. Notes on the n-Person Game—II: The Value of an n-Person Game; RAND Corporation: Santa Monica, CA, USA, 1951. [Google Scholar]
- Miyauchi, M. Properties of Diffuse Solar Radiation under Overcast Skies with Stratified Cloud. J. Meteorol. Soc. Jpn. Ser. II 1985, 63, 1083–1095. [Google Scholar] [CrossRef] [Green Version]
- yichigo. yichigo/Light-Sensors-Calibration: MINTSLightSensorsCalibration; Zenodo: Genève, Switzerland, 2021. [Google Scholar] [CrossRef]











Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Wijeratne, L.O.H.; Talebi, S.; Lary, D.J. Machine Learning for Light Sensor Calibration. Sensors 2021, 21, 6259. https://doi.org/10.3390/s21186259
Zhang Y, Wijeratne LOH, Talebi S, Lary DJ. Machine Learning for Light Sensor Calibration. Sensors. 2021; 21(18):6259. https://doi.org/10.3390/s21186259
Chicago/Turabian StyleZhang, Yichao, Lakitha O. H. Wijeratne, Shawhin Talebi, and David J. Lary. 2021. "Machine Learning for Light Sensor Calibration" Sensors 21, no. 18: 6259. https://doi.org/10.3390/s21186259