
A Transformer-Based Neural Machine Translation Model for Arabic Dialects That Utilizes Subword Units


Abstract
:1. Introduction
2. Related Work
3. Background
4. The Proposed Transformer Based-NMT Model for Arabic Dialects That Utilizes Subword Units
4.1. Multi-Head Attention (MHA)
4.2. Segmentation Approach: Wordpiece Model
- Word: “ وين فيي اركب عباص مخرج المدينة”
- Word Translation: “Where can I take a bus to the city exit”
- Wordpieces: “ _ وين_ في ي_ اركب_ ع باص_ مخرج_ المدينة ”
5. Experimental Results
5.1. Data
5.2. Model Setup
5.3. Traning and Inference
5.4. Results
5.4.1. Automatic Metric
5.4.2. Human Evaluation
6. Analysis
6.1. Impact of Hayperparameter n
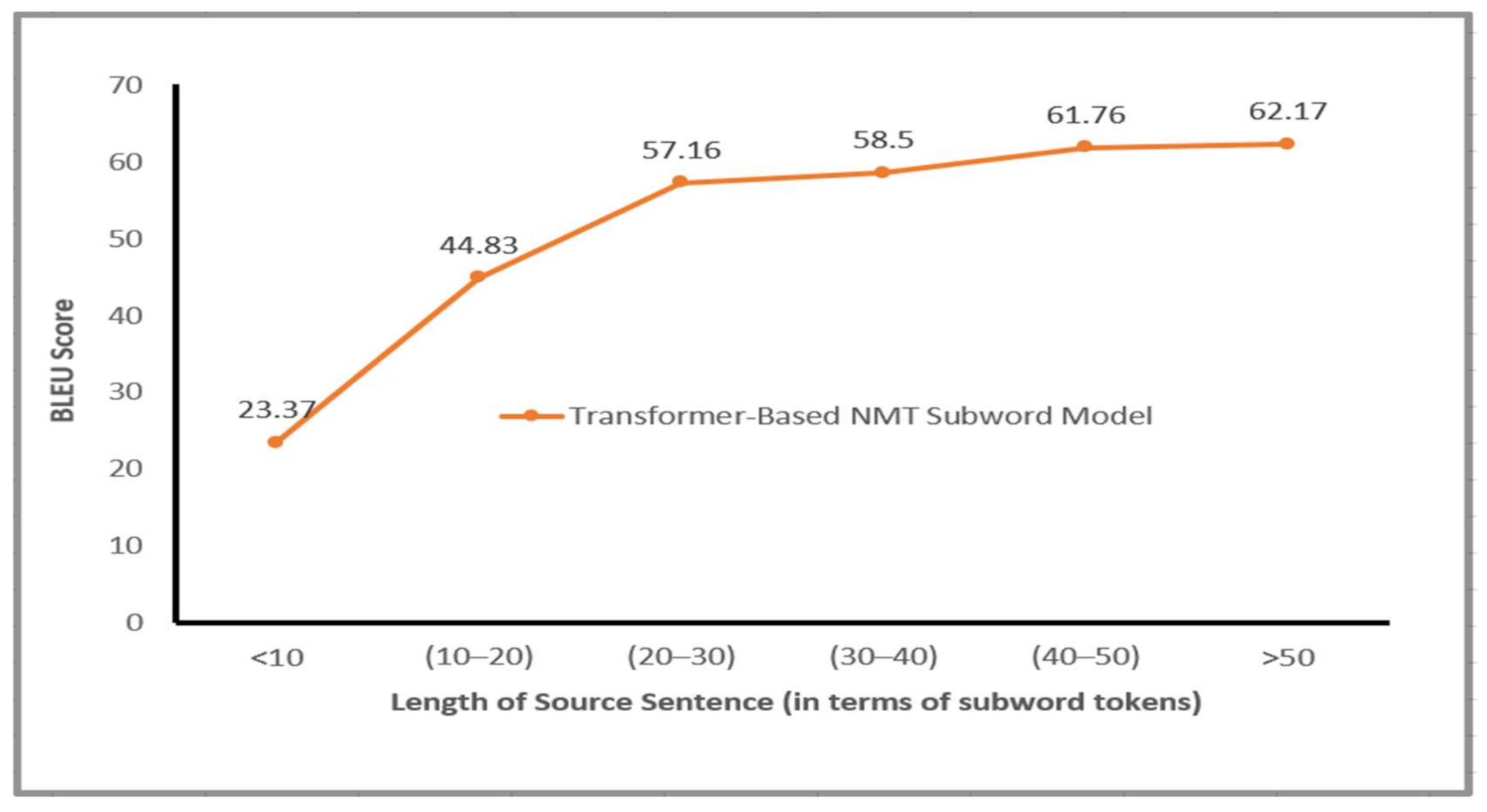
6.2. Length of Source Sentence
6.3. Beam Size Evaluation
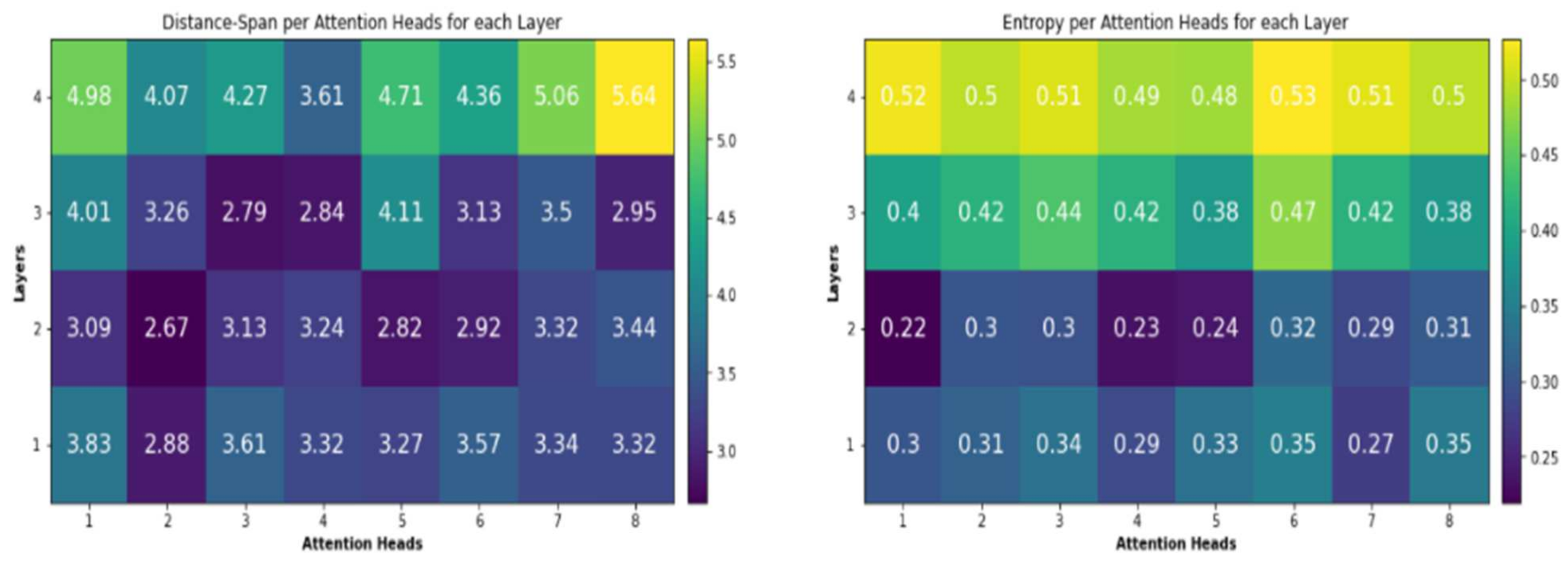
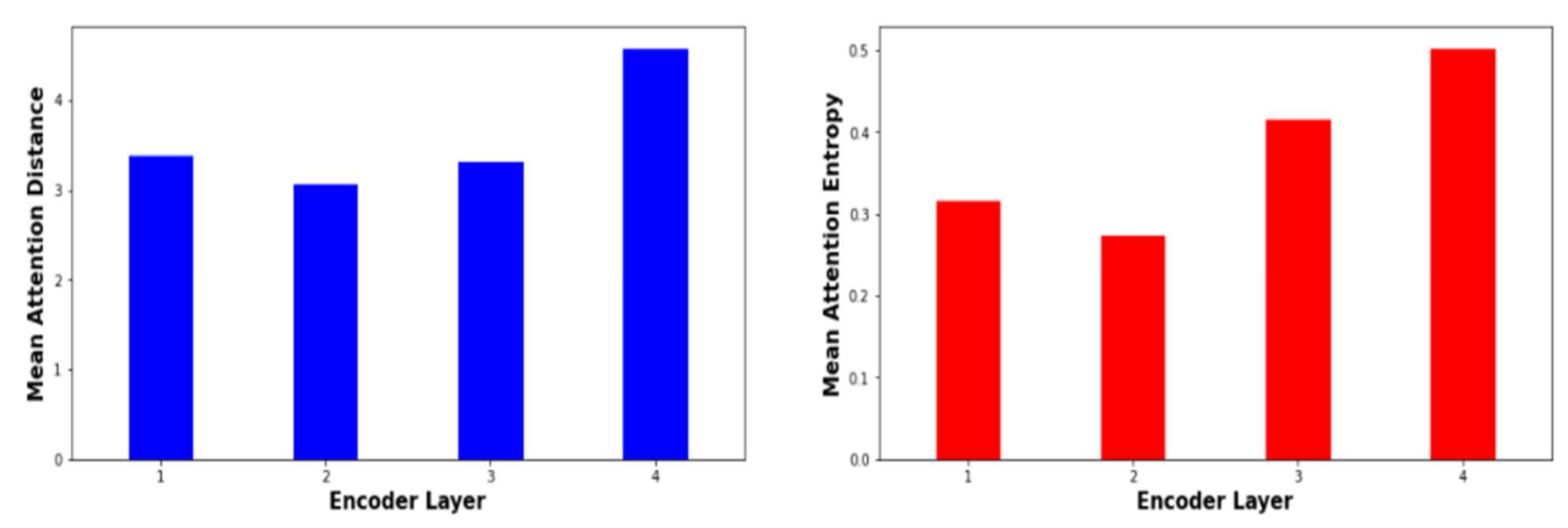
6.4. The Effect of the Encoder Self Attention
6.5. Quantitative Analysis
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bentivogli, L.; Bisazza, A.; Cettolo, M.; Federico, M. Neural versus phrase-based MT quality: An in-depth analysis on English-German and English-French. Comput. Speech Lang. 2019, 49, 52–70. [Google Scholar] [CrossRef] [Green Version]
- Jean, S.; Cho, K.; Memisevic, R.; Bengio, Y. On Using Very Large Target Vocabulary for Neural Machine Translation. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; Volume 1, pp. 1–10. [Google Scholar]
- Luong, M.T.; Sutskever, I.; Le, Q.V.; Vinyals, O.; Zaremba, W. Addressing the rare word problem in neural machine translation. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; pp. 11–19. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–9008. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Cho, K.; van Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 2, pp. 3104–3112. [Google Scholar]
- Gehring, J.; Auli, M.; Grangier, D.; Yarats, D.; Dauphin, Y.N. Convolutional sequence to sequence learning. In Proceedings of the 34th International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017; Volume 70, pp. 1243–1252. [Google Scholar]
- Popović, M.; Arcan, M.; Klubička, F. Language Related Issues for Machine Translation between Closely Related South Slavic Languages. In Proceedings of the Third Workshop on NLP for Similar Languages, Varieties and Dialects (VarDial3), Osaka, Japan, 12 December 2016; pp. 43–52. [Google Scholar]
- Durrani, N.; Sajjad, H.; Fraser, A.; Schmid, H. Hindi-to-Urdu Machine Translation through Transliteration. In Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, Uppsala, Sweden, 11–16 July 2010; pp. 465–474. [Google Scholar]
- Harrat, S.; Meftouh, K.; Smaili, K. Machine translation for Arabic dialects. Inf. Process. Manag. 2019, 56, 262–273. [Google Scholar] [CrossRef] [Green Version]
- Pourdamghani, N.; Knight, K. Deciphering Related Languages. In Proceedings of the Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 2513–2518. [Google Scholar]
- Costa-Jussà, M.R. Why Catalan-Spanish neural machine translation? Analysis, comparison and combination with standard rule and phrase-based technologies. In Proceedings of the Fourth Workshop on NLP for Similar Languages, Varieties and Dialects, Valencia, Spain, 3 April 2017; pp. 55–62. [Google Scholar]
- Kurdish, H.H. Inter dialect machine translation. In Proceedings of the Fourth Workshop on NLP for Similar Languages, Varieties and Dialects, Valencia, Spain, 3 April 2017; pp. 63–72. [Google Scholar]
- Costa-Jussà, M.R.; Zampieri, M.; Pal, S. A Neural Approach to Language Variety Translation. In Proceedings of the Fifth Workshop on NLP for Similar Languages, Varieties and Dialects, Santa Fe, NM, USA, 20 August 2018; pp. 275–282. [Google Scholar]
- Lakew, S.M.; Erofeeva, A.; Federico, M. Neural machine translation into language varieties. In Proceedings of the Third Conference on Machine Translation, Brussels, Belgium, 31 October–1 November 2018; pp. 156–164. [Google Scholar]
- Meftouh, K.; Harrat, S.; Jamoussi, S.; Abbas, M.; Smaili, K. Machine translation experiments on padic: A parallel Arabic dialect corpus. In Proceedings of the 29th Pacific Asia conference on language, information and computation, Shanghai, China, 30 October–1 November 2015. [Google Scholar]
- Sadat, F.; Mallek, F.; Boudabous, M.; Sellami, R.; Farzindar, A. Collaboratively Constructed Linguistic Resources for Language Variants and their Exploitation in NLP Application—The case of Tunisian Arabic and the social media. In Proceedings of the Workshop on Lexical and Grammatical Resources for Language Processing, Dublin, Ireland, 24 August 2014; pp. 102–110. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.-J. BLEU: A method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Abo Bakr, H.; Shaalan, K.; Ziedan, I. A hybrid approach for converting written Egyptian colloquial dialect into diacritized Arabic. In Proceedings of the 6th International Conference on Informatics and Systems, Cairo, Egypt, 27–29 March 2008. [Google Scholar]
- Baniata, L.H.; Park, S.; Park, S.-B. A Neural Machine Translation Model for Arabic Dialects That Utilizes Multitask Learning (MTL). Comput. Intell. Neurosci. 2018, 2018, 10. [Google Scholar] [CrossRef] [PubMed]
- Baniata, L.H.; Park, S.; Park, S.-B. A Multitask-Based Neural Machine Translation Model with Part-of-Speech Tags Integration for Arabic Dialects. Appl. Sci. 2018, 8, 2502. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, Q.; Vo, A.; Shin, J.; Tran, P.; Ock, C. Korean-Vietnamese Neural Machine Translation System with Korean Morphological Analysis and Word Sense Disambiguation. IEEE Access 2019, 7, 32602–32616. [Google Scholar] [CrossRef]
- Park, C.; Lee, C.; Yang, Y.; Lim, H. Ancient Korean Neural Machine Translation. IEEE Access 2020, 8, 116617–116625. [Google Scholar] [CrossRef]
- Luo, G.; Yang, Y.; Yuan, Y.; Chen, Z.; Ainiwaer, A. Hierarchical Transfer Learning Architecture for Low-Resource Neural Machine Translation. IEEE Access 2019, 7, 154157–154166. [Google Scholar] [CrossRef]
- Aqlan, F.; Fan, X.; Alqwbani, A.; Al-Mansoub, A. Arabic Chinese Neural Machine Translation: Romanized Arabic as Subword Unit for Arabic-sourced Translation. IEEE Access 2019, 7, 133122–133135. [Google Scholar] [CrossRef]
- Chen, K.; Wang, R.; Utiyama, M.; Liu, L.; Tamura, A.; Sumita, E.; Zhao, T. Neural machine translation with source dependency representation. In Proceedings of the EMNLP, Copenhagen, Denmark, 7–11 September 2017; pp. 2513–2518. [Google Scholar]
- Eriguchi, A.; Tsuruoka, Y.; Cho, K. Learning to parse and translate improves neural machine translation. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 72–78. [Google Scholar]
- Wu, S.; Zhang, D.; Zhang, Z.; Yang, N.; Li, M.; Zhou, M. Dependency-to-dependency neural machine translation. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 2132–2141. [Google Scholar] [CrossRef]
- Strubell, E.; Verga, P.; Andor, D.; Weiss, D.; McCallum, A. Linguistically-informed self-attention for semantic role labeling. In Proceedings of the EMNLP, Brussels, Belgium, 31 October–4 November 2018; pp. 5027–5038. [Google Scholar]
- Neco, R.P.; Forcada, M.L. Asynchronous translations with recurrent neural nets. In Proceedings of the International Conference on Neural Networks, Houston, TX, USA, 9–12 June 1997; pp. 2535–2540. [Google Scholar]
- Schwenk, H.; Dchelotte, D.; Gauvain, J.L. Continuous space language models for statistical machine translation. In Proceedings of the 21st COLING/ACL, Sydney, NSW, Australia, 17–21 July 2006; pp. 723–730. [Google Scholar]
- Kalchbrenner, N.; Blunsom, P. Recurrent continuous translation models. In Proceedings of the EMNLP, Seattle, WA, USA, 18–21 October 2013; pp. 1700–1709. [Google Scholar]
- Passban, P.; Liu, Q.; Way, A. Translating low-resource languages by vocabulary adaptation from close counterparts. ACM Trans. Asian Low Resour. Lang. Inf. Process. 2017, 16, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter, S.; Schmidhuber, L. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Gülçehre, C.; Ahn, S.; Nallapati, R.; Zhou, B.; Bengio, Y. Pointing the unknown words. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 140–149. [Google Scholar]
- Sennrich, R.; Haddow, B.; Birch, A. Neural machine translation of rare words with subword units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 1715–1725. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE CVRP, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. In Proceedings of the Advances in NIPS 2016 Deep Learning Symposium, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Al-Sabahi, K.; Zuping, Z.; Nadher, M. A hierarchical structured self attentive model for extractive document summarization (HSSAS). IEEE Access 2018, 6, 24205–24212. [Google Scholar] [CrossRef]
- Schuster, M.; Nakajima, K. Japanese and Korean voice search. In Proceedings of the ICASSP, Kyoto, Japan, 25–30 March 2012; pp. 5149–5152. [Google Scholar]
- Lample, G.; Conneau, A. Cross-lingual language model pretraining. In Proceedings of the 33rd Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Bouamor, H.; Habash, N.; Oflazer, K. A Multidialectal Parallel Corpus of Arabic. In Proceedings of the LREC, Reykjavik, Iceland, 26–31 May 2014; pp. 1240–1245. [Google Scholar]
- Bouamor, H.; Habash, N.; Salameh, M.; Zaghouani, W.; Rambow, O.; Abdulrahim, D.; Obeid, O.; Khalifa, S.; Eryani, F.; Erdmann, A.; et al. The madar arabic dialect corpus and lexicon. In Proceedings of the LREC, Miyazaki, Japan, 7–12 May 2018; pp. 3387–3396. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- So, D.; Le, Q.; Liang, C. The Evolved Transformer. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2018; pp. 5877–5886. [Google Scholar]
- Luong, M.-T.; Pham, H.; Manning, C.D. Effective approaches to attention-based neural machine translation. In Proceedings of the Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1412–1421. [Google Scholar]
- Raganato, A.; Tiedemann, J. An analysis of encoder representations in transformer-based machine translation. In Proceedings of the 2018 Empirical Methods in Natural Language Processing Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, Brussels, Belgium, 1 November 2018; pp. 287–297. [Google Scholar]
- Vig, J.; Belinkov, Y. Analyzing the Structure of Attention in a Transformer Language Model. In Proceedings of the Second BlackboxNLP Workshop on Analyzing and Interpreting Neural Networks for NLP, Florence, Italy, 1 August 2019; pp. 63–76. [Google Scholar]
- Ghader, H.; Monz, C. What does Attention in Neural Machine Translation Pay Attention to? In Proceedings of the 8th IJCNLP, Taipei, Taiwan, 27 November–1 December 2017; pp. 30–39. [Google Scholar]
- Alali, M.; Mohd Sharef, N.; Azmi Murad, M.A.; Hamdan, H.; Husin, N.A. Narrow Convolutional Neural Network for Arabic Dialects Polarity Classification. IEEE Access 2019, 7, 96272–96283. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SW-E-D | FS | EL | DL | AH | BLEU |
|---|---|---|---|---|---|
| 512 | 1024 | 4 | 4 | 4 | 61.65 |
| 512 | 1024 | 8 | 8 | 4 | 63.56 |
| 512 | 1024 | 12 | 12 | 4 | 63.71 |
| 1024 | 1024 | 4 | 4 | 4 | 59.68 |
| 1024 | 1024 | 4 | 4 | 8 | 59.53 |
| 512 | 512 | 4 | 4 | 4 | 60.04 |
| SW-E-D | FS | EL | DL | AH | BLEU |
|---|---|---|---|---|---|
| 512 | 1024 | 4 | 4 | 4 | 59.46 |
| 512 | 1024 | 8 | 8 | 4 | 63.02 |
| 512 | 1024 | 12 | 12 | 4 | 65.66 |
| 1024 | 1024 | 4 | 4 | 4 | 59.54 |
| 1024 | 1024 | 4 | 4 | 8 | 62.17 |
| 512 | 512 | 4 | 4 | 4 | 56.68 |
| SW-E-D | FS | EL | DL | AH | BLEU |
|---|---|---|---|---|---|
| 512 | 1024 | 4 | 4 | 4 | 47.51 |
| 512 | 1024 | 8 | 8 | 4 | 48.19 |
| 512 | 1024 | 12 | 12 | 4 | 47.58 |
| 1024 | 1024 | 4 | 4 | 4 | 42.02 |
| 1024 | 1024 | 4 | 4 | 8 | 44.08 |
| 512 | 512 | 4 | 4 | 4 | 47.52 |
| SW-E-D | FS | EL | DL | AH | BLEU |
|---|---|---|---|---|---|
| 512 | 1024 | 4 | 4 | 4 | 47.26 |
| 512 | 1024 | 8 | 8 | 4 | 46.66 |
| 512 | 1024 | 12 | 12 | 4 | 47.18 |
| 1024 | 1024 | 4 | 4 | 4 | 43.48 |
| 1024 | 1024 | 4 | 4 | 8 | 43.68 |
| 512 | 512 | 4 | 4 | 4 | 46.35 |
| SW-E-D | FS | EL | DL | AH | BLEU |
|---|---|---|---|---|---|
| 512 | 1024 | 4 | 4 | 4 | 56.50 |
| 512 | 1024 | 8 | 8 | 4 | 49.03 |
| 512 | 1024 | 12 | 12 | 4 | 47.14 |
| 1024 | 1024 | 4 | 4 | 4 | 25.51 |
| 1024 | 1024 | 4 | 4 | 8 | 40.17 |
| 512 | 512 | 4 | 4 | 4 | 55.23 |
| SW-E-D | FS | EL | DL | AH | BLEU |
|---|---|---|---|---|---|
| 512 | 1024 | 4 | 4 | 4 | 57.06 |
| 512 | 1024 | 8 | 8 | 4 | 57.41 |
| 512 | 1024 | 12 | 12 | 4 | 57.85 |
| 1024 | 1024 | 4 | 4 | 4 | 37.15 |
| 1024 | 1024 | 4 | 4 | 8 | 49.47 |
| 512 | 512 | 4 | 4 | 4 | 55.14 |
| SW-E-D | FS | EL | DL | AH | BLEU |
|---|---|---|---|---|---|
| 512 | 1024 | 4 | 4 | 4 | 56.38 |
| 512 | 1024 | 8 | 8 | 4 | 53.98 |
| 512 | 1024 | 12 | 12 | 4 | 57.92 |
| 1024 | 1024 | 4 | 4 | 4 | 44.13 |
| 1024 | 1024 | 4 | 4 | 8 | 56.49 |
| 512 | 512 | 4 | 4 | 4 | 55.46 |
| Model | Pairs | Epochs | Accuracy | BLEU |
|---|---|---|---|---|
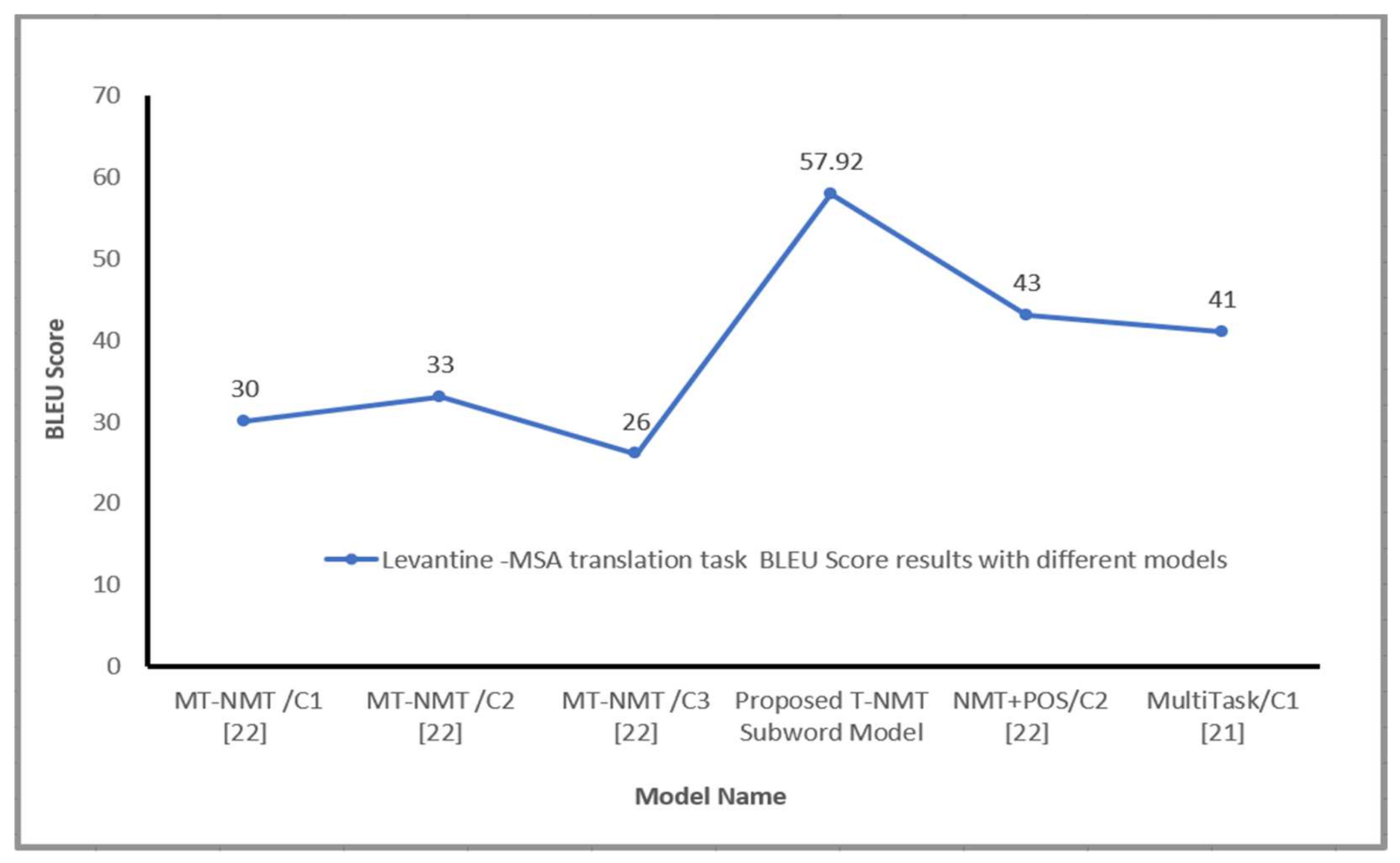
| NMT+POS_LEV | LEV–MSA | 90 | - | 43.00 |
| NMT+POS_LEV | MSA-ENG | 50 | - | 30.00 |
| POS_LEV | POS_LEV | 40 | 98% | - |
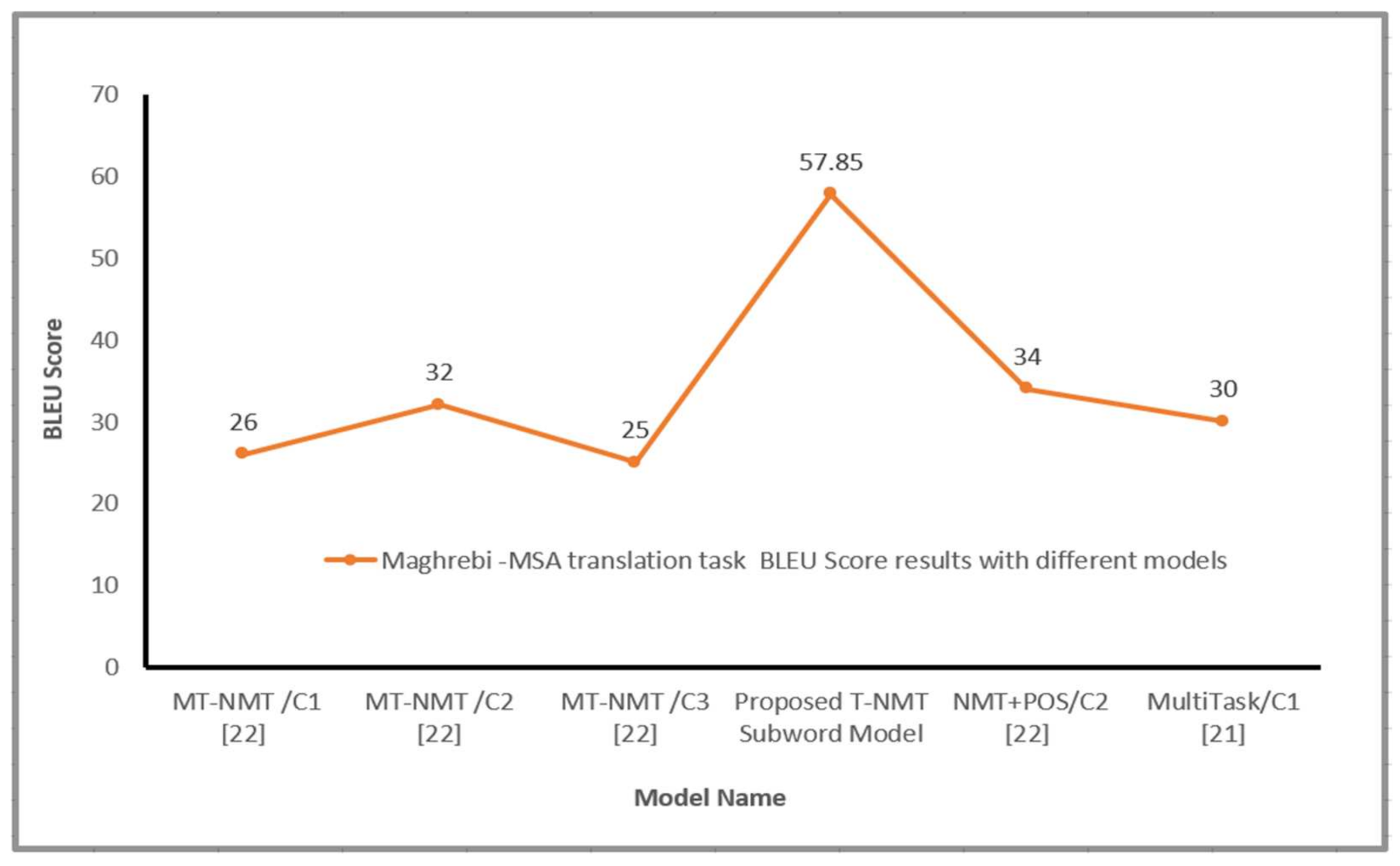
| NMT+POS_MAG | MAG–MSA | 50 | - | 34.00 |
| NMT+POS_MAG | MSA-ENG | 30 | - | 29.00 |
| POS_MAG | POS_MAG | 20 | 99% | - |
| Model | Pairs | Average Score |
|---|---|---|
| Transformer-NMT-Subword | LEV–MSA | 6.35 |
| Transformer-NMT-Subword | MAG–MSA | 6.3 |
| Transformer-NMT-Subword | Gulf–MSA | 5.85 |
| Transformer-NMT-Subword | Nile–MSA | 5.8 |
| Transformer-NMT-Subword | IRQ–MSA | 6.1 |
| Model | Pairs | Average Score |
|---|---|---|
| Transformer-NMT-Subword | LEV–MSA | 6.0 |
| Transformer-NMT-Subword | MAG–MSA | 6.2 |
| Multi-Task Learning-NMT [22] | LEV–MSA | 1.4 |
| Multi-Task Learning-NMT [22] | MAG–MSA | 1.3 |
| MTL-NMT+POS [22] | LEV-MAG | 5.9 |
| MTL-NMT+POS [22] | MAG–MSA | 4.4 |
| Source Language: MAG (Maghrebi) | واخا بلحاق هاد الشي بزاف وانا اصلا واكل بزاف |
| English Translation (MAG) | Yeah, but that’s so much and I ate lot |
| Target Language: MSA | اجل ولكن هذا كثير جدا ولقد شبعت بالفعل |
| Transformer-NMT Subword Model | اجل ولكن هذا كثير جدا ولقد شبعت بالفعل |
| English translation for output of the Transformer-NMT Subword model | Yes, but that’s too much and I’m already full |
| Source Language: LEV (Levantine) | انا مع صحابي |
| English Translation (LEV) | I am with my dudes |
| Target Language: MSA | انني مع اصدقائي |
| Transformer-NMT Subword Model | انا مع بعض الاصدقاء |
| English translation for output of the Transformer-NMT Subword model | I am with some Friends |
| Source Language: GULF | عندك جوازك وتذكرتك؟ مثل ما تشوف هذي سوق حرة |
| English Translation (GULF) | You got your passport and your ticket? as you see, this is a duty-free market |
| Target Language: MSA | هل معك جواز السفر والتذكرة ؟ انت ترى فهذا متجر معفى من الرسوم |
| Transformer-NMT Subword Model | هل لديك جواز سفرك وتذكرتك ؟ لن يكون عندك متجر معفى من الرسوم |
| English translation for output of the Transformer-NMT Subword model | Do you have your passport and ticket? You see, this is a duty-free shop |
| Source Language: Nile (Egypt, Sudan) | عاوز اعمل مكالمة لليابان |
| English Translation (Nile) | I wanna do a call to Japan |
| Target Language: MSA | اريد الاتصال هاتفيا باليابان |
| Transformer-NMT Subword Model | اريد الاتصال هاتفيا باليابان |
| English translation for output of the Transformer-NMT Subword model | I want to do a phone call to Japan |
| Source Language: IRQ (Iraqi) | احس ببرودة ومعدتي تاذيني كلش |
| English Translation (IRQ) | I feel cold and my stomach is hurting me a lot |
| Target Language: MSA | اشعر ببرودة وتؤلمني معدتي جدا |
| Transformer-NMT Subword Model | اشعر ببرودة وتؤلمني معدتي جدا |
| English translation for output of the Transformer-NMT Subword model | I feel cold and my stomach hurts so much |
| Source Language: MAG (Maghrebi) | الى نتي قبلتي تضحي ب هاد الطريقة ف حتى هو خاصو يقدر هاد الامر و ميتخلاش عليك |
| English Translation (MAG) | If you accept to sacrifice in this way, he is also obliged to appreciate this matter and not abandon you |
| Target Language: MSA | اذا انت قبلت بان تضحي بهذه الطريقة فهو كذلك مجبر على ان يقدر هذا الامر و الا يتخلى عنك |
| Transformer-NMT Subword Model | اذا انت قبلت بان تضحي بهذه الطريقة فهو كذلك مجبر على ان يقدر هذا الامر و الا يتخلى عنك |
| English translation for output of the Transformer-NMT Subword model | If you accept to sacrifice in this way, he is also obliged to appreciate this matter and not abandon you |
| Source Language: LEV (Levantine) | اه ريحتها زي ريحة العطر منيحة في اليوم الاول بس بعد هيك |
| English Translation (LEV) | yeah, it smells like perfume, good on the first day, but later on |
| Target Language: MSA | نعم رائحتها كرائحة العطر جيدة في اليوم الاول لكن فيما بعد |
| Transformer-NMT Subword Model | نعم رائحتها كرائحة العطر جيدة في اليوم الاول لكن فيما بعد |
| English translation for output of the Transformer-NMT Subword model | Yes, it smells as good as perfume on the first day, but later on |
| Beam Size | BLEU |
|---|---|
| 1 | 52.82 |
| 2 | 58.10 |
| 3 | 59.69 |
| 4 | 60.31 |
| 5 | 61.70 |
| 6 | 65.66 |
| 7 | 61.22 |
| 8 | 61.35 |
| 9 | 60.72 |
| 10 | 61.36 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Baniata, L.H.; Ampomah, I.K.E.; Park, S. A Transformer-Based Neural Machine Translation Model for Arabic Dialects That Utilizes Subword Units. Sensors 2021, 21, 6509. https://doi.org/10.3390/s21196509
Baniata LH, Ampomah IKE, Park S. A Transformer-Based Neural Machine Translation Model for Arabic Dialects That Utilizes Subword Units. Sensors. 2021; 21(19):6509. https://doi.org/10.3390/s21196509
Chicago/Turabian StyleBaniata, Laith H., Isaac. K. E. Ampomah, and Seyoung Park. 2021. "A Transformer-Based Neural Machine Translation Model for Arabic Dialects That Utilizes Subword Units" Sensors 21, no. 19: 6509. https://doi.org/10.3390/s21196509
APA StyleBaniata, L. H., Ampomah, I. K. E., & Park, S. (2021). A Transformer-Based Neural Machine Translation Model for Arabic Dialects That Utilizes Subword Units. Sensors, 21(19), 6509. https://doi.org/10.3390/s21196509