A Methodology for Discriminant Time Series Analysis Applied to Microclimate Monitoring of Fresco Paintings



Abstract
:1. Introduction
2. Materials and Methods
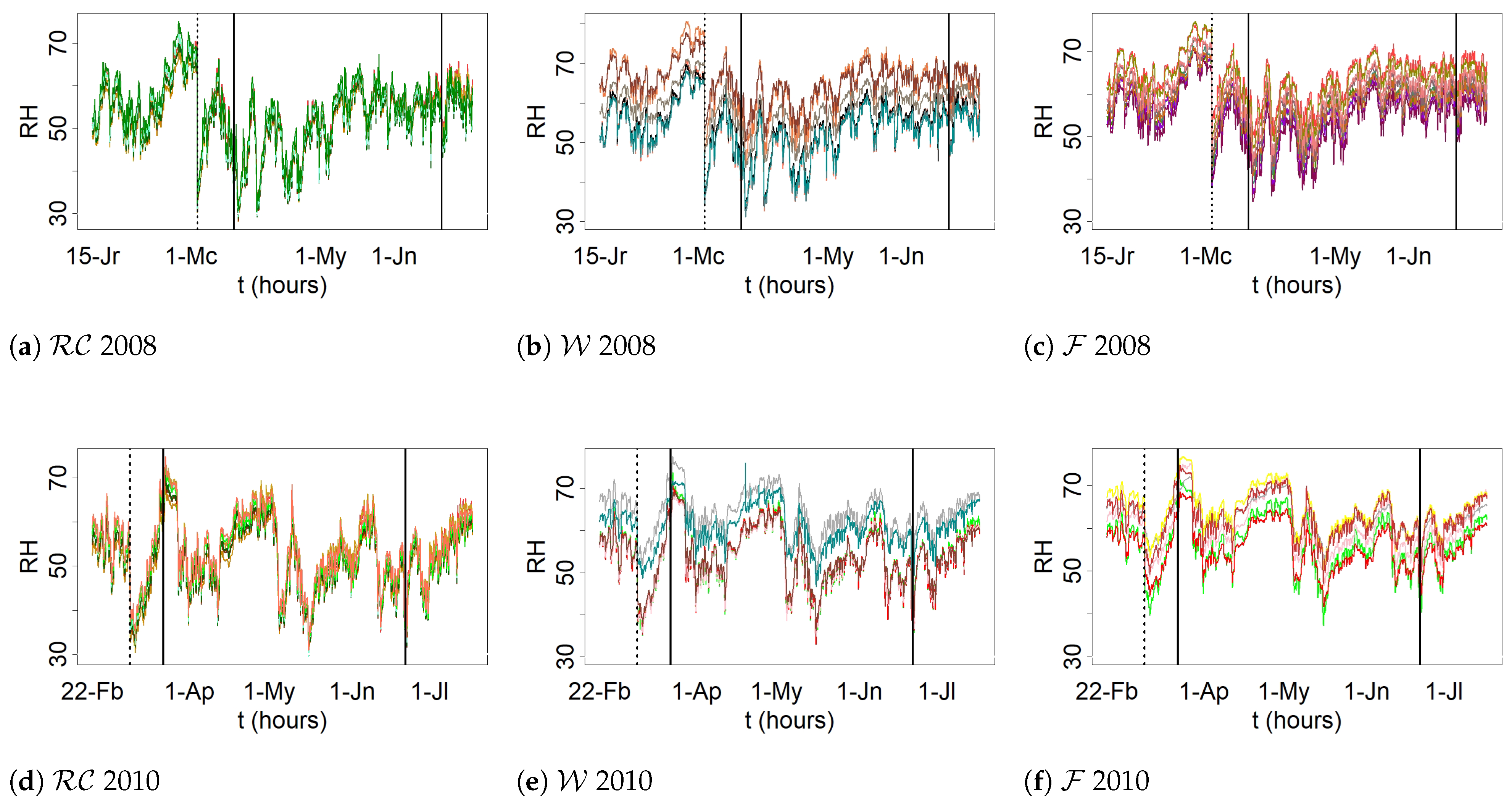
2.1. Materials: Description of the Data Sets
2.2. Statistical Methods
2.2.1. Identification of Structural Breaks in the Time Series
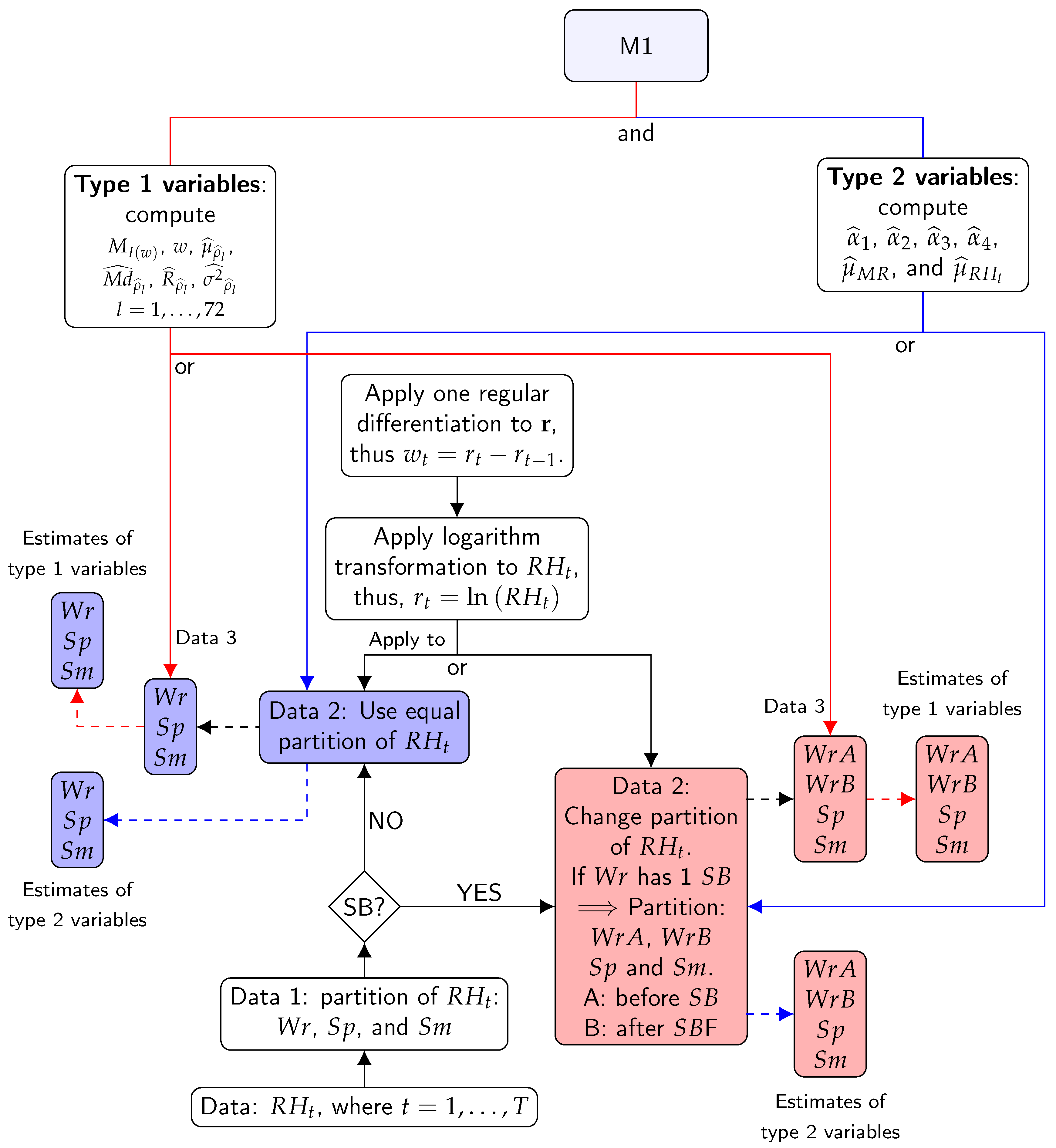
2.2.2. Calculation of Classification Variables—Method M1
- Mean of ().
- Mean of MR () of order 2 for and .
- Variance of MR () of order 2 for and .
- PACF for the first four lags (, , , and ).
- Maximum of spectral density () and frequency corresponding to the maximum (w).
- Mean (), Median (), range (), and variance of the sample ACF () for the first 72 lags.
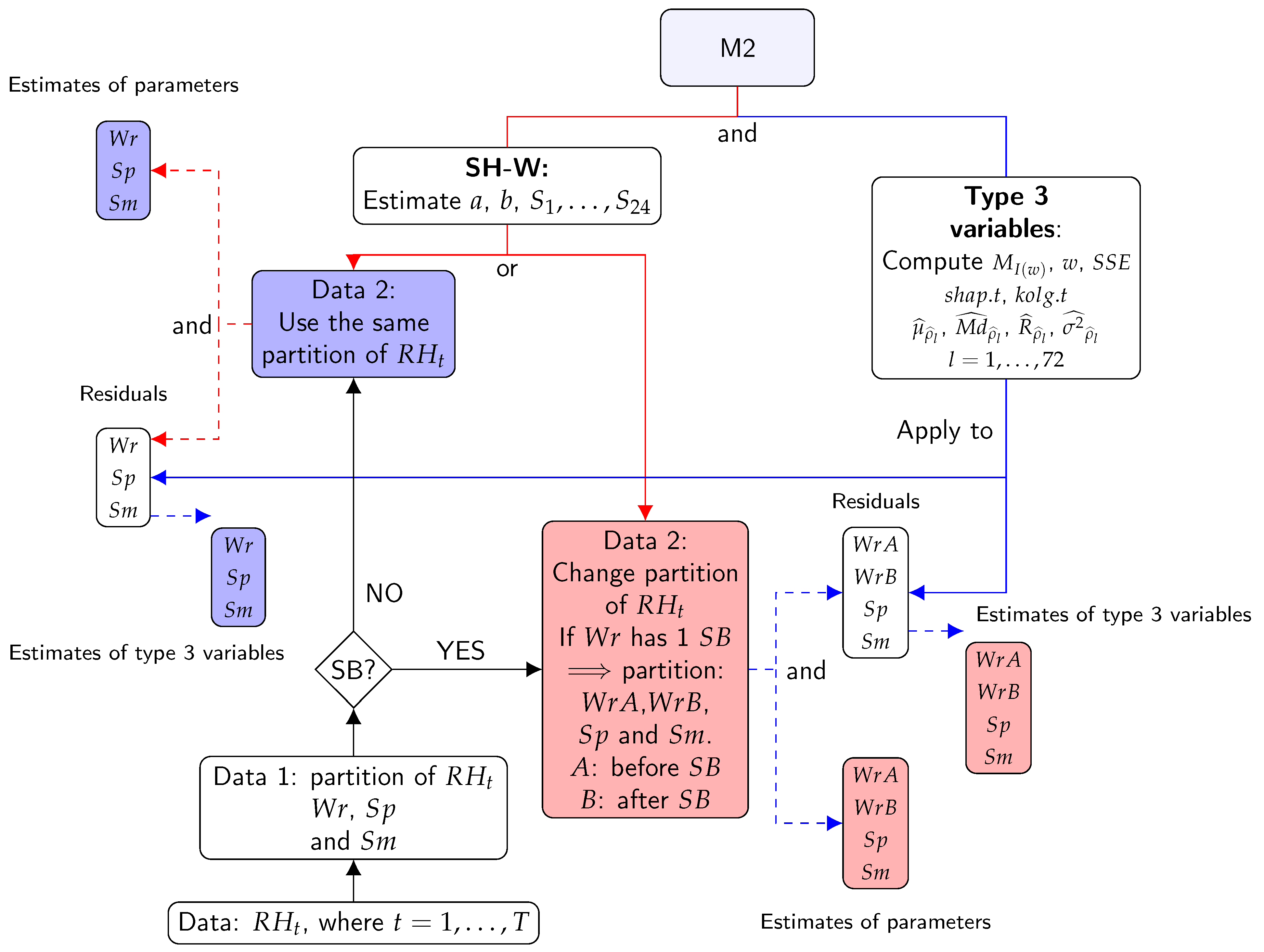
2.2.3. Calculation of Classification Variables—Method M2: Additive SH-W
- Estimates of the parameters of the SH-W method: trend (), level (), and seasonal components ().
- type 3 variables: sum of squared estimate of errors (), maximum of spectral density (), frequency corresponding to maximum of spectral density (), and the mean (), median (), range (), and variance () of sample ACF for 72 lags. The statistic of the SW test (), and the statistic of the KS normality test () are also included in this list.
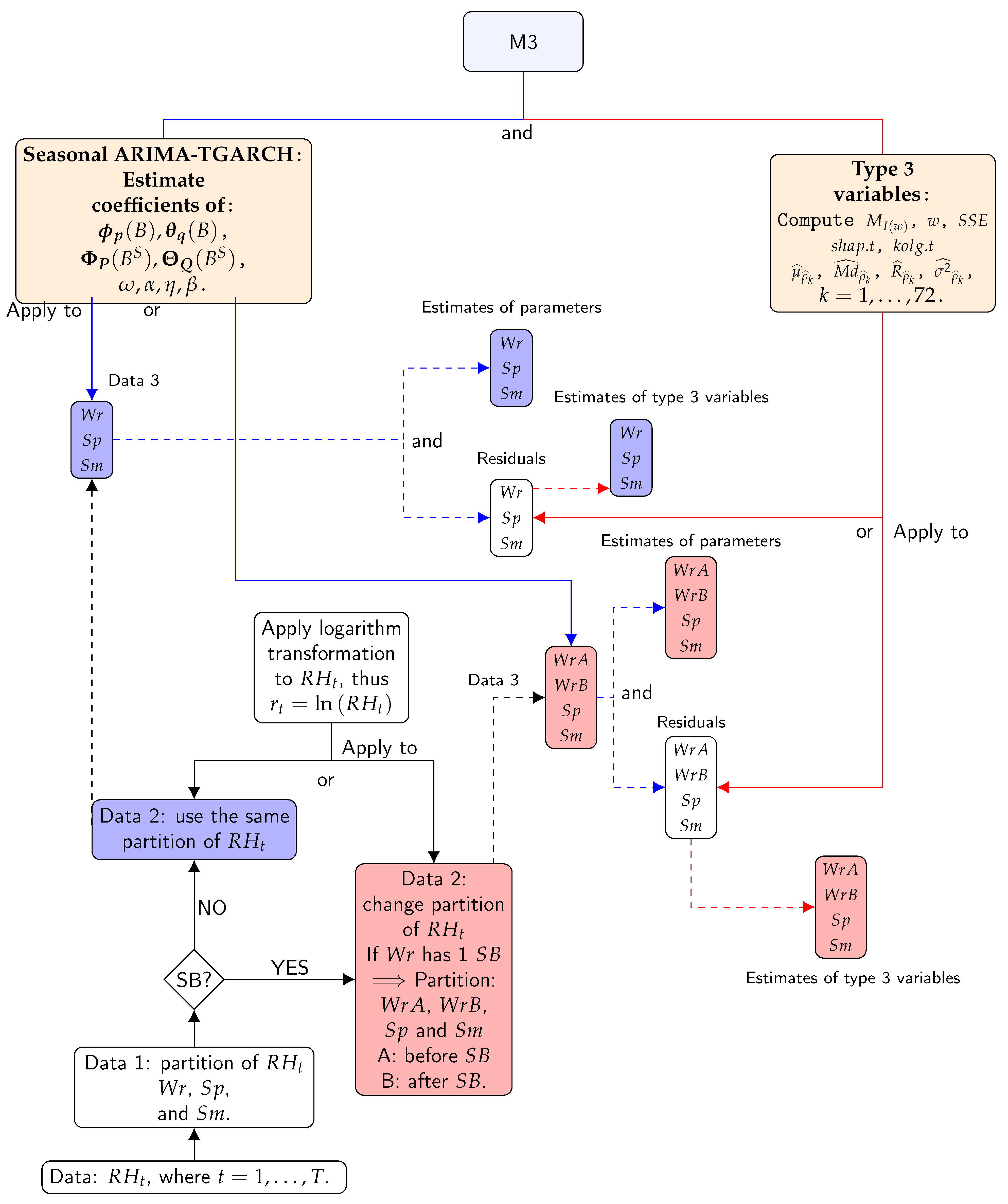
2.2.4. Calculation of Classification Variables—Method M3: Seasonal ARIMA-TGARCH-Student
- The condition of stationarity was checked, that is, whether the statistical characteristics of the time series were preserved across the time period. The null hypothesis was that mean and variance do not depend on time t and the covariance between observations and does not depend on t [38]. To examine this null hypothesis, the augmented Dickey–Fuller (ADF) [79] and LBQ tests were applied for 48 lags. Furthermore, the sample ACF and sample PACF plots were also used.
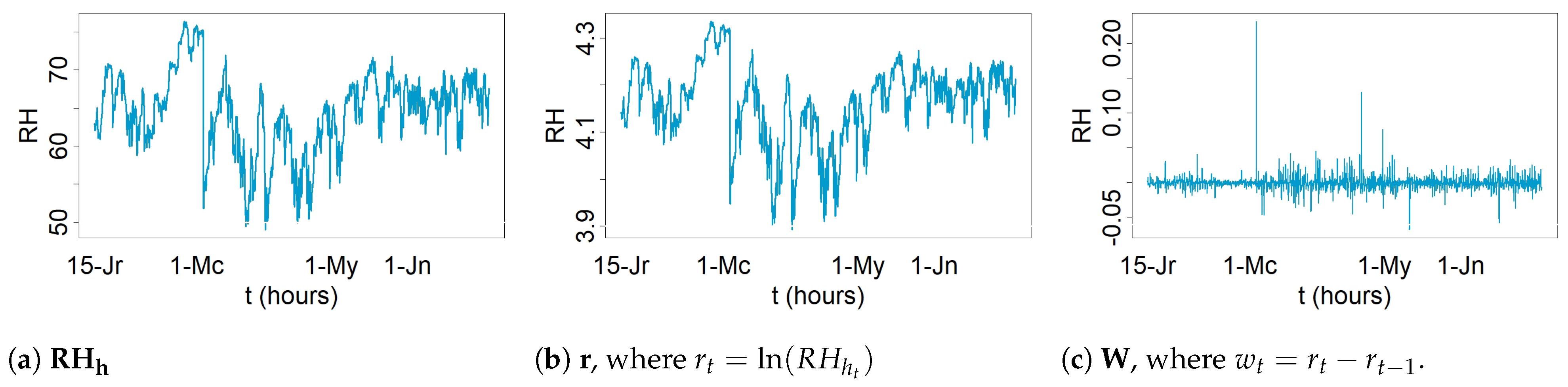
- Transformation and differencing: the logarithmic transformation and regular differentiation were applied to data before fitting ARMA in order to transform nonstationary data into stationary data [59]. The criterion for determining the values of d ( differencing) is explained in the next step. The logarithmic transformation was preferred over other transformations because the variability of a time series becomes more homogeneous using logarithmic transformation, which leads to better forecasts [80].
- Identification of the most appropriate values for () and . Sample ACF and sample PACF plots were used to identify the appropriate values of (). Furthermore, the corrected Akaike information criterion () [60] was useful for evaluating how well a model fits the data and determining the values of both and (), taking into account the restriction that d and D should be 0 or 1. The most successful model for each time series was chosen according to the lowest value. The values were compared for models with the same orders of differencing, that is, equal values of d and D.
- The condition of white noise was checked. Error terms can be regarded as white noise if their mean is zero and the sequence is not autocorrelated [38]. In order to check this issue, the ADF and LBQ tests were applied to the residuals and their squared values for 48 lags. Furthermore, the sample ACF plots were also used.
- To check the distribution of residuals: by means of the Q–Q normal scores plots as well as the SW and KS normality tests.
- WrA (2008): seasonal ARIMA TGARCH(1,1)-Student.
- WrA (2010): ARIMA TGARCH(1,1)-Student.
- WrB (2008 and 2010): seasonal ARIMA TGARCH(1,1)-Student.
- Sp (2008 and 2010): seasonal ARIMA TGARCH(1,1)-Student.
- Sm (2008 and 2010): seasonal ARIMA TGARCH(1,1)-Student.
- Estimated parameters from ARIMA of: (1) the regular autoregressive operator () of order p and the regular moving average operator () of order q: , , , , etc.; (2) the seasonal autoregressive operator () of order P and the seasonal moving average operator of order Q: , , , , etc.
- Estimated parameters from TGARCH (1,1): , , , , and v (for Student distribution).
- Variance of the residuals (), maximum of spectral density of the residuals (), frequency corresponding to maximum of spectral density (), mean (), median (), range (), and variance () of sample ACF for 72 lags. The statistic of the SW test () and the statistic of the KS normality test () are also included.
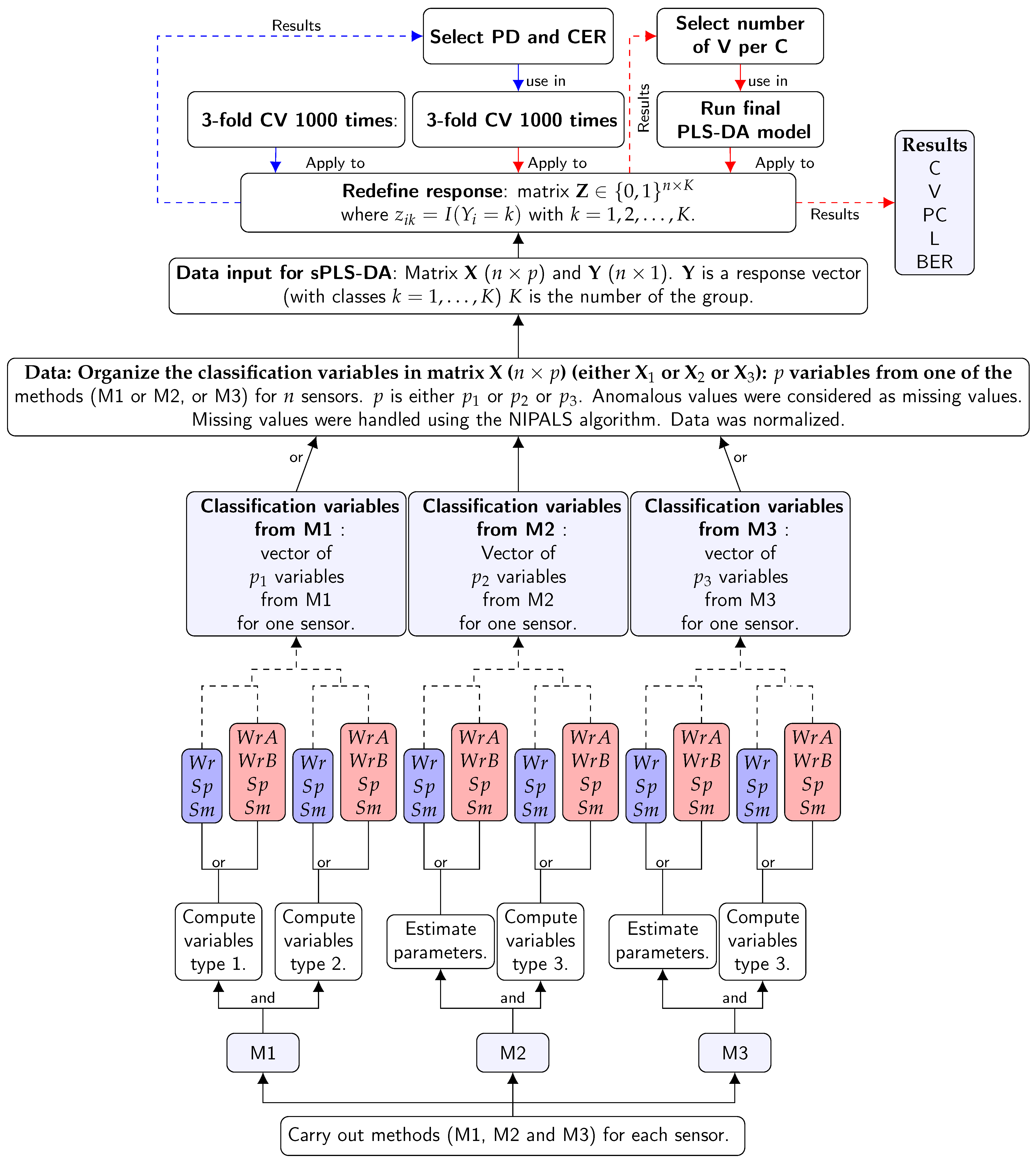
2.2.5. Sensor Classification by Means of sPLS-DA
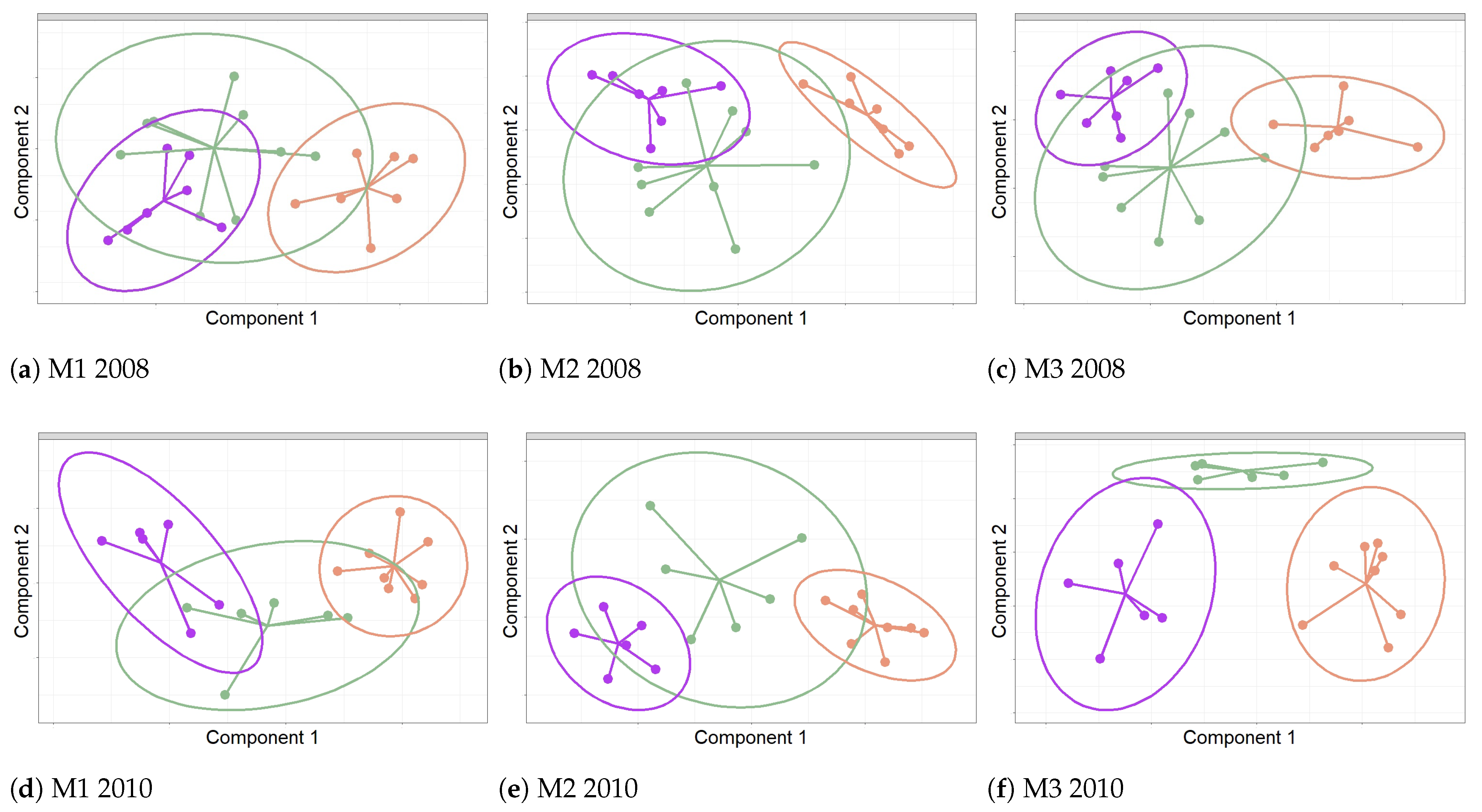
3. Results
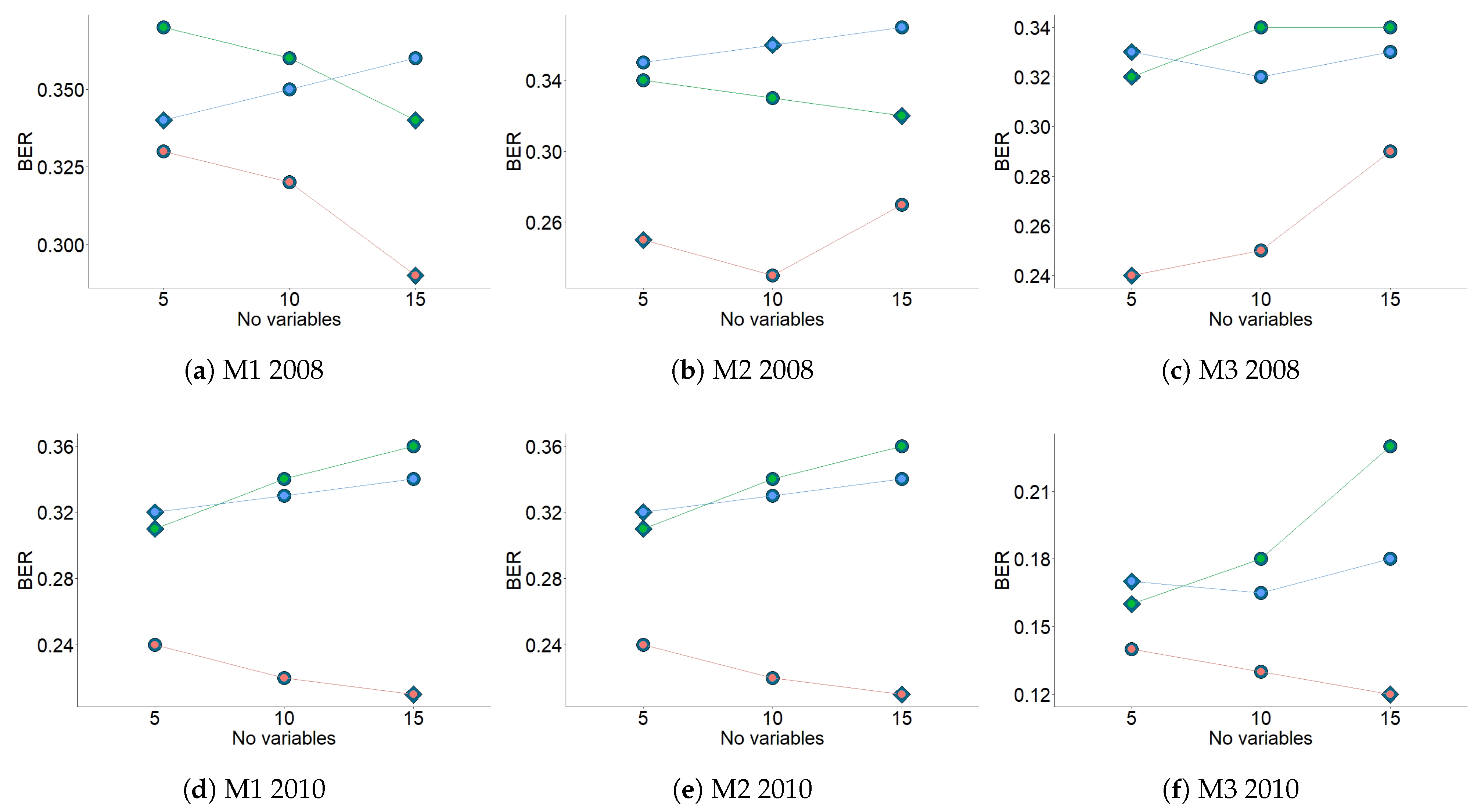
- M1: spec.mx, rMh, rMd, rVh, rVd, and pacf2 (see Table 1). The features rMh and rMd account for changes in the mean of the time series, while rVh and rVd are intended to explain changes in the variance. The rest of the features mentioned provide information about the dynamic structure of each time series. It was found that rMh, rMd, and rVh were important in the four periods considered, both in 2008 and 2010. rMd was relevant for WrA and WrB in 2008. The variable spec.mx was relevant in WrA and WrB for 2008 and 2010, as well as WrB. The variable pacf2 was found in WrB 2010. Hence, consistent results were derived from the two years under study.
- M2: sse, kolg.d, and spec.mx (computed from the residuals), as well as b, s1, s18, s19, s20, and s24 (from the models). From the residuals, sse accounts for the variance that is not explained by the models. This parameter appeared as important in all periods considered, except WrA 2010. kolg.d quantifies the deviation from normality for the residuals, and was relevant in all periods except Sp 2008 and WrB 2010. The third feature, spec.mx, which provides information about the dynamic structure of each time series, was relevant for all periods except WrB 2008, WrA 2010, and Sp 2010. Regarding the parameters computed from the models, b is related to the trend component of the time series, which was important in WrA 2010. The other variables mentioned are related to the seasonal components of the time series, which were shown to be important in Sm 2010.
- M3: res.v, shape, spec.mx, acf.m, and acf.md (computed from the residuals), as well as omega and alpha (from the model). From the residuals, res.v is aimed to explain the variance not explained by the models. It was relevant in all periods except Sp and Sm 2008. The variable shape provides information about the distribution of residuals, but it was only relevant in WrA 2010. The other features (i.e., spec.mx, acf.m, and acf.md) are intended to describe the dynamic structure of each time series. Spec.mx was important in all periods except Sp and Sm 2008, while the last two only appeared in Sp 2010. Regarding the parameters from the models, omega explains the changes in the mean of the conditional variance, while alpha quantifies the impact of the rotation on the conditional variance. The variable alpha only appeared in WrA 2010. Again, the fact that most variables were common in the three periods and in both years suggests strong consistency in the underlying phenomena explaining the discrimination between sensors.
4. Discussion
- Cepstral coefficients: Ioannou et al. [105] studied several clustering techniques in the context of the semiparametric model: spectral density ratio. They found that the cepstral- based techniques performed better than all the other spectral-domain-based methods, even for relatively small subsequences.
- Structural time series model: the flexibility required from this model can be achieved by letting the regression coefficients change over time [106].
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zarzo, M.; Fernández-Navajas, A.; García-Diego, F.J. Long-term monitoring of fresco paintings in the cathedral of Valencia (Spain) through humidity and temperature sensors in various locations for preventive conservation. Sensors 2011, 11, 8685–8710. [Google Scholar] [CrossRef] [PubMed]
- García-Diego, F.J.; Zarzo, M. Microclimate monitoring by multivariate statistical control: The renaissance frescoes of the cathedral of Valencia (Spain). J. Cult. Herit. 2010, 11, 339–344. [Google Scholar] [CrossRef]
- Verticchio, E.; Frasca, F.; García-Diego, F.D.; Siani, A.M. Investigation on the use of passive microclimate frames in view of the climate change scenario. Climate 2019, 7, 98. [Google Scholar] [CrossRef] [Green Version]
- Sesana, E.; Gagnon, A.S.; Bertolin, C.; Hughes, J. Adapting cultural heritage to climate change risks: Perspectives of cultural heritage experts in Europe. Geosciences 2018, 8, 305. [Google Scholar] [CrossRef] [Green Version]
- Camuffo, D. Microclimate for Cultural Heritage, 1st ed.; Elsevier: Amsterdam, The Netherlands, 1998. [Google Scholar]
- Camuffo, D. Indoor dynamic climatology: Investigations on the interactions between walls and indoor environment. Atmos. Environ. (1967) 1983, 17, 1803–1809. [Google Scholar] [CrossRef]
- Camuffo, D.; Bernardi, A. Study of the microclimate of the hall of the giants in the carrara palace in padua. Stud. Conserv. 1995, 40, 237–249. [Google Scholar] [CrossRef]
- Camuffo, D.; Pagan, E.; Bernardi, A.; Becherini, F. The impact of heating, lighting and people in re-using historical buildings: A case study. J. Cult. Herit. 2004, 5, 409–416. [Google Scholar] [CrossRef]
- Bernardi, A. Microclimate in the british museum, London. Mus. Manag. Curatorship 1990, 9, 169–182. [Google Scholar] [CrossRef]
- Bernardi, A.; Camuffo, D. Microclimate in the chiericati palace municipal museum Vicenza. Mus. Manag. Curatorship 1995, 14, 5–18. [Google Scholar] [CrossRef]
- Camuffo, D.; Bernardi, A.; Sturaro, G.; Valentino, A. The microclimate inside the Pollaiolo and Botticelli rooms in the Uffizi Gallery. J. Cult. Herit. 2002, 3, 155–161. [Google Scholar] [CrossRef]
- Merello, P.; García-Diego, F.D.; Beltrán, P.; Scatigno, C. High frequency data acquisition system for modelling the impact of visitors on the thermo-hygrometric conditions of archaeological sites: A Casa di Diana (Ostia Antica, Italy) case study. Sensors 2018, 18, 348. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Frasca, F.; Siani, A.M.; Casale, G.R.; Pedone, M.; Bratasz, L.; Strojecki, M.; Mleczkowska, A. Assessment of indoor climate of Mogita Abbey in Kraków (Poland) and the application of the analogues method to predict microclimate indoor conditions. Environ. Sci. Pollut. Res. 2017, 24, 13895–13907. [Google Scholar] [CrossRef] [PubMed]
- Tabunschikov, Y.; Brodatch, M. Indoor air climate requirements for Russian churches and cathedrals. Indoor Air 2004, 14 (Suppl. 7), 168–174. [Google Scholar] [CrossRef] [PubMed]
- Camuffo, D.; Sturaro, G.; Valentino, A. Thermodynamic exchanges between the external boundary layer and the indoor microclimate at the Basilica of Santa Maria Maggiore, Rome, Italy: The problem of conservation of ancient works of art. Bound.-Layer Meteorol. 1999, 92, 243–262. [Google Scholar] [CrossRef]
- Vuerich, E.; Malaspina, F.; Barazutti, M.; Georgiadis, T.; Nardino, M. Indoor measurements of microclimate variables and ozone in the church of San Vincenzo (Monastery of Bassano Romano Italy): A pilot study. Microchem. J. 2008, 88, 218–223. [Google Scholar] [CrossRef]
- Loupa, G.; Charpantidou, E.; Kioutsioukis, I.; Rapsomanikis, S. Indoor microclimate, ozone and nitrogen oxides in two medieval churches in Cyprus. Atmos. Environ. 2006, 40, 7457–7466. [Google Scholar] [CrossRef]
- Bernardi, A.; Todorov, V.; Hiristova, J. Microclimatic analysis in St. Stephan’s church, Nessebar, Bulgaria after interventions for the conservation of frescoes. J. Cult. Herit. 2000, 1, 281–286. [Google Scholar] [CrossRef]
- EN16883. Conservation of Cultural Heritage. Guidelines for Improving the Energy Performance of Historic Buildings. 2017. Available online: https://standards.cen.eu/dyn/www/f?p=204:110:0::::FSP_PROJECT:36576&cs=113EECDB855EBEF2097C9F626231290BE (accessed on 1 January 2021).
- EN16141. Conservation of Cultural Heritage. Guidelines for Management of Environmental Conditions. Open Storage Facilities: Definitions and Characteristics of Collection Centres Dedicated to the Preservation and Management of Cultural Heritage. 2012. Available online: https://standards.cen.eu/dyn/www/f?p=204:110:0::::FSP_PROJECT:30978&cs=19D7899D83F3E1FAFF740C53B6D9C068F (accessed on 1 January 2021).
- EN16242. Conservation of Cultural Heritage. Procedures and Instruments for Measuring Humidity in the Air and Moisture Exchanges between Air and Cultural Property. 2012. Available online: https://standards.cen.eu/dyn/www/f?p=204:110:0::::FSP_PROJECT:34048&cs=1000E6B80FEC23200296847848BFD8390 (accessed on 1 January 2021).
- EN15898. Conservation of Cultural Property. Main General Terms and Definitions. 2019. Available online: https://standards.cen.eu/dyn/www/f?p=204:110:0::::FSP_PROJECT:61301&cs=1BFEBDBB425EAF8FEDC7D300B26CB0F1E (accessed on 1 January 2021).
- EN15758. Conservation of Cultural Property. Procedures and iNstruments for measuRing Temperatures of the Air and the Surfaces of Objects. 2010. Available online: https://standards.cen.eu/dyn/www/f?p=204:110:0::::FSP_PROJECT:28488&cs=18FBB4BE512863FD1F25E8415D5BA9ACE (accessed on 1 January 2021).
- EN15757. CoNservation of Cultural Property. Specifications for Temperature And Relative Humidity to Limit Climate-Induced Mechanical Damage in Organic Hygroscopic Materials. 2010. Available online: https://standards.cen.eu/dyn/www/f?p=204:110:0::::FSP_PROJECT:28487&cs=1CA6AC7E107FE7F852A4F9C8D11CCD217 (accessed on 1 January 2021).
- EN16893. COnservation of Cultural Heritage. Specifications for Location, Construction And Modification of Buildings or Rooms Intended for The Storage or Use of Heritage Collections. 2018. Available online: https://standards.cen.eu/dyn/www/f?p=204:110:0::::FSP_PROJECT:35659&cs=15B18B1A035AB93FB36262CA746F5F7EC (accessed on 1 January 2021).
- Corgnati, S.P.; Filippi, M. Assessment of thermo-hygrometric quality in museums: Method and in-field application to the Duccio di Buoninsegna exhibition at Santa Maria della Scala (Siena, Italy). J. Cult. Herit. 2010, 11, 345–349. [Google Scholar] [CrossRef]
- Collectioncare.eu. Available online: https://www.collectioncare.eu/ (accessed on 1 January 2021).
- Dunia, R.; Qin, S.J.; Edgar, T.F.; McAvoy, T.J. Use of principal component analysis for sensor fault identification. Comput. Chem. Eng. 1996, 20, S713–S718. [Google Scholar] [CrossRef]
- Zhu, D.; Bai, J.; Yang, S. A multi-fault diagnosis method for sensor systems based on principle component analysis. Sensors 2009, 10, 241–253. [Google Scholar] [CrossRef]
- Venables, W.N.; Ripley, B.D. Modern Applied Statistics with S, 4th ed.; Springer: New York, NY, USA, 2002. [Google Scholar]
- Box, G.E.P.; Jenkins, G.M. Time Series Analysis: Forecasting and Control, Revised ed.; Holden-Day: San Francisco, CA, USA, 1976. [Google Scholar]
- Brockwell, P.J.; Davis, R.A. Time Series: Theory and Methods, 2nd ed.; Springer: New York, NY, USA, 1987. [Google Scholar]
- Kovalevsky, S. Package ‘QuantTools’; R Core Team: Vienna, Austria, 2020; Available online: https://quanttools.bitbucket.io/_site/index.html (accessed on 1 January 2021).
- Holt, C.C. Forecasting seasonals and trends by exponentially weighted moving averages. J. Econ. Soc. Meas. 2004, 20, 5–10. [Google Scholar] [CrossRef]
- Winters, P.R. Forecasting sales by exponentially weighted moving averages. Manag. Sci. 1960, 6, 324–342. [Google Scholar] [CrossRef]
- Hannan, E.J.; Rissanen, J. Recursive Estimation of Mixed Autoregressive-Moving Average Order. Biometrika 1982, 69, 81–94. [Google Scholar] [CrossRef]
- Ghalanos, A. Introduction to the Rugarch Package (Version 1.4-3); R Core Team: Vienna, Austria, 2020; Available online: https://cran.r-project.org/web/packages/rugarch/vignettes/Introduction_to_the_rugarch_package.pdf (accessed on 1 January 2021).
- Palma, W. Time Series Analysis. Wiley Series in Probability and Statistics, Har/Psc ed.; John Wiley & Sons Inc.: Hoboken, NJ, USA, 2016. [Google Scholar]
- Hamilton, J.D. Time Series Analysis, 1st ed.; Princeton University Press: Princeton, NJ, USA, 1994. [Google Scholar]
- Lê Cao, K.A.; Boitard, S.; Besse, P. Sparse PLS discriminant analysis: Biologically relevant feature selection and graphical displays for multiclass problems. BiomMed Cent. Bioinform. 2011, 12, 253. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2014. [Google Scholar]
- Qiu, D. Package ‘aTSA’; R Core Team: Vienna, Austria, 2015; Available online: https://cran.r-project.org/web/packages/aTSA/index.html (accessed on 1 January 2021).
- Hyndman, R.J.; Khandakar, Y. Automatic time series forecasting: The forecast package for R. J. Stat. Softw. 2008, 26, 1–23. [Google Scholar] [CrossRef]
- Hyndman, R.; Athanasopoulos, G.; Bergmeir, C.; Caceres, G.; Chhay, L.; OHara-Wild, M.; Petropoulos, F.; Razbash, S.; Wang, E.; Yasmeen, F. Package ’Forecast: Forecasting Functions for Time Series and Linear Models’; R Core Team: Vienna, Austria, 2020; Available online: https://cran.r-project.org/web/packages/forecast/ (accessed on 1 January 2021).
- Rohart, F.; Gautier, B.; Singh, A.; Lê Cao, K.A. mixOmics: An R package for omics feature selection and multiple data integration. PLoS Comput. Biol. 2017, 13, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Le Cao, K.A.; Dejean, S. mixOmics: Omics Data Integration Project; Bioconductor: Vienna, Austria, 2020; Available online: http://www.bioconductor.org/packages/release/bioc/html/mixOmics.html (accessed on 1 January 2021).
- Ghalanos, A.; Kley, T. Package ‘Rugarch’; R Core Team: Vienna, Austria, 2020; Available online: https://cran.r-project.org/web/packages/rugarch/index.html (accessed on 1 January 2021).
- Zeileis, A. Implementing a class of structural change tests: An econometric computing approach. Comput. Stat. Data Anal. 2006, 50, 2987–3008. [Google Scholar] [CrossRef] [Green Version]
- Trapletti, A.; Hornik, K. Package: ’Tseries: Time Series Analysis and Computational Finance’; R Core Team: Vienna, Austria, 2020; Available online: https://cran.r-project.org/web/packages/tseries/ (accessed on 1 January 2021).
- Leisch, F.; Hornik, K.; Kuan, C.M. Monitoring structural changes with the generalized fluctuation test. Econom. Theory 2000, 16, 835–854. [Google Scholar] [CrossRef] [Green Version]
- Chow, G.C. Tests of equality between sets of coefficients in two linear regressions. Econometrica 1960, 28, 591–605. [Google Scholar] [CrossRef]
- Hansen, B.E. Tests for parameter instability in regressions with I(1) processes. J. Bus. Econ. Stat. 2002, 20, 45–59. [Google Scholar] [CrossRef]
- Andrews, D.W.K. Tests for parameter instability and structural change with unknown change point. Econometrica 1993, 61, 821–856. [Google Scholar] [CrossRef] [Green Version]
- Andrews, D.W.K.; Ploberger, W. Optimal tests when a nuisance parameter is present only under the alternative. Econometrica 1994, 62, 1383–1414. [Google Scholar] [CrossRef]
- Zeileis, A.; Leisch, F.; Hornik, K.; Kleiber, C. Strucchange: An R package for testing for structural change in linear regression models. J. Stat. Softw. 2002, 7, 1–38. [Google Scholar] [CrossRef] [Green Version]
- Cryer, J.D.; Chan, K.S. Time Series Analysis: With Applications in R; Springer Texts in Statistics; Springer: New York, NY, USA, 2008. [Google Scholar]
- Royston, J.P. Algorithm AS 181: The W test for normality. J. R. Stat. Soc. Ser. C Appl. Stat. 1982, 31, 176–180. [Google Scholar] [CrossRef]
- Gaetano, D. Forecast combinations in the presence of structural breaks: Evidence from U.S. equity markets. Mathematics 2018, 6, 34. [Google Scholar] [CrossRef] [Green Version]
- Cowpertwait, P.S.P.; Metcalfe, A.V. Introductory Time Series with R; Springer Series: Use R; Springer: New York, NY, USA, 2009. [Google Scholar]
- Hyndman, R.; Koehler, A.B.; Ord, J.K.; Snyder, R.D. Forecasting with Exponential Smoothing: The State Space Approach; Springer: Berlin, Germany, 2008. [Google Scholar]
- Ljung, G.M.; Box, G.E.P. On a measure of Lack of fit in time series models. Biometrika 1978, 65, 297–303. [Google Scholar] [CrossRef]
- Conover, W.J. Practical Nonparametric Statistics, 1st ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 1999. [Google Scholar]
- Royston, J.P. An extension of Shapiro and Wilk’s W test for normality to large samples. J. R. Stat. Soc. Ser. C Appl. Stat. 1982, 31, 115–124. [Google Scholar] [CrossRef]
- Royston, P. Remark AS R94: A remark on algorithm AS 181: The W-test for normality. J. R. Stat. Soc. Ser. C Appl. Stat. 1995, 44, 547–551. [Google Scholar] [CrossRef]
- Anderson, O.D. Time series analysis: Forecasting and control: (Revised Edition) by George E.P. Box and Gwilym M. Jenkins. J. Frankl. Inst. 1980, 310. [Google Scholar] [CrossRef]
- Yaziz, S.R.; Azizan, N.A.; Zakaria, R.; Ahmad, M.H. The performance of hybrid ARIMA-GARCH modeling in forecasting gold price. In Proceedings of the 20th International Congress on Modelling and Simulation, Adelaide, Australia, 1–6 December 2013; pp. 1–6. [Google Scholar]
- Tseng, J.J.; Li, S.P. Quantifying volatility clustering in financial time series. Int. Rev. Financ. Anal. 2012, 23, 11–19. [Google Scholar] [CrossRef]
- Engle, R. Risk and volatility: Econometric models and financial practice. Am. Econ. Rev. 2004, 94, 405–420. [Google Scholar] [CrossRef] [Green Version]
- Engle, R.F. Autoregressive conditional heteroscedasticity with estimates of the variance of United Kingdom inflation. Econometrica 1982, 50, 987–1007. [Google Scholar] [CrossRef]
- Bollerslev, T. Generalized autoregressive conditional heteroskedasticity. J. Econom. 1986, 31, 307–327. [Google Scholar] [CrossRef] [Green Version]
- Engle, R.F.; Bollerslev, T. Modelling the persistence of conditional variances. Econom. Rev. 1986, 5, 1–50. [Google Scholar] [CrossRef]
- Yusof, F.; Kane, I.L. Volatility modeling of rainfall time series. Theor. Appl. Climatol. 2013, 113, 247–258. [Google Scholar] [CrossRef]
- Yaziz, R.S.; Azlinna, N.A.; Ahmad, M.; Zakaria, R. Modelling gold price using ARIMA-TGARCH. Appl. Math. Sci. 2016, 10, 1391–1402. [Google Scholar] [CrossRef]
- Hor, C.L.; Watson, S.J.; Majithias, S. Daily load forecasting and maximum demand estimation using ARIMA and GARCH. In Proceedings of the International Conference on Probabilistic Methods Applied to Power Systems, Stockholm, Sweden, 11–15 June 2006; pp. 1–6. [Google Scholar] [CrossRef]
- Xing, J. The research on stock market volatility in China based on the model of ARIMA-EARCH-M (1, 1) and ARIMA-TARCH-M (1, 1). In Proceedings of the International Conference on Advances in Education and Management. ISAEBD 2011: Education and Management, Dalian, China, 6–7 August 2011; Volume 210. [Google Scholar] [CrossRef]
- Zakoian, J.M. Threshold heteroskedastic models. J. Econ. Dyn. Control. 1994, 18, 931–955. [Google Scholar] [CrossRef]
- Johnston, K.; Scott, E. GARCH models and the stochastic process underlying exchange rate price change. J. Financ. Strateg. Decis. 2000, 13, 13–24. [Google Scholar]
- Bollerslev, T. A conditionally heteroskedastic time series model for speculative prices and rates of return. Rev. Econ. Stat. 1987, 69, 542–547. [Google Scholar] [CrossRef] [Green Version]
- Fuller, W.A. Introduction to Statistical Time Series, 2nd ed.; John Wiley & Sons: New York, NY, USA, 1996. [Google Scholar]
- Lütkepohl, H.; Xu, F. The role of the log transformation in forecasting economic variables. Empir. Econ. 2012, 42, 619–638. [Google Scholar] [CrossRef] [Green Version]
- McLeod, A.I.; Li, W.K. Diagnostic cheking ARMA time series models using squared-residual autocorrelations. J. Time Ser. Anal. 1983, 4, 269–273. [Google Scholar] [CrossRef]
- Wold, H. Path models with latent variables: The NIPALS approach. Quantitative Sociology; Elsevier: Amsterdam, The Netherlands, 1975. [Google Scholar] [CrossRef]
- Piccolo, D. A distance measure for classifying arima models. J. Time Ser. Anal. 1990, 11, 153–164. [Google Scholar] [CrossRef]
- Maharaj, E.A. A significance test for classifying ARMA models. J. Stat. Comput. Simul. 1996, 54, 305–331. [Google Scholar] [CrossRef]
- Maharaj, E.A. Comparison of non-stationary time series in the frequency domain. Comput. Stat. Data Anal. 2002, 40, 131–141. [Google Scholar] [CrossRef] [Green Version]
- Kakizawa, Y.; Shumway, R.H.; Taniguchi, M. Discrimination and clustering for multivariate time series. J. Am. Stat. Assoc. 1998, 93, 328–340. [Google Scholar] [CrossRef]
- Vilar, J.A.; Pértega, S. Discriminant and cluster analysis for gaussian stationary processes: Local linear fitting approach. J. Nonparametric Stat. 2004, 16, 443–462. [Google Scholar] [CrossRef]
- Struzik, Z.R.; Siebes, A. The haar wavelet in the time series similarity paradigm. In Proceedings of the Principles of Data Mining and Knowledge Discovery. PKDD 1999. Lecture Notes in Computer Science, Prague, Czech Republic, 15–18 September 1999; Volume 1704, pp. 12–22. [Google Scholar]
- Galeano, P.; Peña, D. Multivariate analysis in vector time series. Stat. Econom. Ser. 2000, 15, 1–19. [Google Scholar]
- Caiado, J.; Crato, N.; Peña, D. A periodogram-based metric for time series classification. Comput. Stat. Data Anal. 2006, 50, 2668–2684. [Google Scholar] [CrossRef] [Green Version]
- Douzal, C.A.; Nagabhushan, P. Adaptive dissimilarity index for measuring time series proximity. Adv. Data Anal. Classif. 2007, 1, 5–21. [Google Scholar] [CrossRef]
- Uspensky, V.A.; Shen, A.; Li, M.; Vitányi, P. An introduction to Kolmogorov complexity and its applications. Texts and monographs in computer science. J. Symb. Log. 1995, 60, 1017–1020. [Google Scholar] [CrossRef]
- Li, M.; Badger, J.H.; Chen, X.; Kwong, S.; Kearney, P.; Zhang, H. An information-based sequence distance and its application to whole mitochondrial genome phylogeny. Bioinformatics 2001, 17, 149–154. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, M.; Chen, X.; Li, X.; Ma, B.; Vitanyi, P. The similarity metric. IEEE Trans. Inf. Theory 2004, 50, 3250–3264. [Google Scholar] [CrossRef]
- Cilibrasi, R.C.; Vitãnyi, P.M. Clustering by compression. IEEE Trans. Inf. Theory 2005, 51, 1523–1545. [Google Scholar] [CrossRef] [Green Version]
- Keogh, E.; Lonardi, S.; Ratanamahatana, C.A.; Wei, L.; Lee, S.H.; Handley, J. Compression based data mining of sequential data. Data Min. Knowl. Discov. 2007, 14, 99–129. [Google Scholar] [CrossRef]
- Brandmaier, A.M. Permutation Distribution Clustering and Structural Equation Model Trees. Ph.D. Thesis, Universitat des Saarlandes, Saarbrücken, Germany, 2011. Available online: https://publikationen.sulb.uni-saarland.de/handle/20.500.11880/26345 (accessed on 1 January 2021).
- Alonso, A.M.; Berrendero, J.R.; Hernández, A.; Justel, A. Time series clustering based on forecast densities. Comput. Stat. Data Anal. 2006, 51, 762–776. [Google Scholar] [CrossRef]
- Vilar, J.A.; Alonso, A.M.; Vilar, J.M. Non-linear time series clustering based on non-parametric forecast densities. Comput. Stat. Data Anal. 2010, 54, 2850–2865. [Google Scholar] [CrossRef]
- Batista, G.; Wang, X.; Keogh, E. A complexity-invariant distance measure for time series. In Proceedings of the eleventh SIAM international conference on data mining, SDM11, Mesa, AZ, USA, 28–30 April 2011; pp. 699–710. [Google Scholar] [CrossRef] [Green Version]
- Otranto, E. Clustering heteroskedastic time series by model-based procedures. Comput. Stat. Data Anal. 2008, 52, 4685–4698. [Google Scholar] [CrossRef] [Green Version]
- Maharaj, E.A. Cluster of time series. J. Classif. 2000, 17, 297–314. [Google Scholar] [CrossRef]
- Kalpakis, K.; Gada, D.; Puttagunta, V. Distance measures for effective clustering of arima time-series. In Proceedings of the Data Mining, 2001. ICDM 2001. IEEE International Conference, San Jose, CA, USA, 29 November–2 December 2001; pp. 273–280. [Google Scholar] [CrossRef] [Green Version]
- Xiong, Y.; Yeung, D.Y. Mixtures of arma models for model-based time series clustering. In Proceedings of the 2002 IEEE International Conference on Data Mining, Maebashi City, Japan, 9–12 December 2002; pp. 717–720. [Google Scholar] [CrossRef]
- Ioannou, A.; Fokianos, K.; Promponas, V.J. Spectral density ratio based clustering methods for the binary segmentation of protein sequences: A comparative study. Biosystems 2010, 100, 132–143. [Google Scholar] [CrossRef]
- Harvey, A.C.; Shephard, N. 10 Structural time series models. In Econometrics; Handbook of Statistics; Elsevier Science Publishers B.V.: Amsterdam, The Netherlands, 1993; Volume 11, pp. 261–302. [Google Scholar] [CrossRef]
- Bühlmann, P.; McNeil, A.J. An algorithm for nonparametric GARCH modelling. Comput. Stat. Data Anal. 2002, 40, 665–683. [Google Scholar] [CrossRef] [Green Version]
- Rohan, N.; Ramanathan, T.V. Nonparametric estimation of a time-varying GARCH model. J. Nonparametric Stat. 2013, 25, 33–52. [Google Scholar] [CrossRef]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. B Stat. Methodol. 2005, 67, 301–320. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (a) Results from sPLS-DA (2008). | ||
| Method | Variables | BER |
| M1 | , , , , , , | 30.02% |
| , , , , , , , | ||
| M2 | , , , , , , | 24.05% |
| , , | ||
| M3 | , , , , | 22.60% |
| (b) Results from sPLS-DA (2010). | ||
| Method | Variables | BER |
| M1 | , , , , , , | 24.08% |
| , , , , , , , | ||
| M2 | , , , , , , , | 21.17% |
| , , , , , , | ||
| M3 | , , , , , , | 12.81% |
| , , , , , | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ramírez, S.; Zarzo, M.; Perles, A.; García-Diego, F.-J. A Methodology for Discriminant Time Series Analysis Applied to Microclimate Monitoring of Fresco Paintings. Sensors 2021, 21, 436. https://doi.org/10.3390/s21020436
Ramírez S, Zarzo M, Perles A, García-Diego F-J. A Methodology for Discriminant Time Series Analysis Applied to Microclimate Monitoring of Fresco Paintings. Sensors. 2021; 21(2):436. https://doi.org/10.3390/s21020436
Chicago/Turabian StyleRamírez, Sandra, Manuel Zarzo, Angel Perles, and Fernando-Juan García-Diego. 2021. "A Methodology for Discriminant Time Series Analysis Applied to Microclimate Monitoring of Fresco Paintings" Sensors 21, no. 2: 436. https://doi.org/10.3390/s21020436
APA StyleRamírez, S., Zarzo, M., Perles, A., & García-Diego, F.-J. (2021). A Methodology for Discriminant Time Series Analysis Applied to Microclimate Monitoring of Fresco Paintings. Sensors, 21(2), 436. https://doi.org/10.3390/s21020436